堆原理決議
堆一般指二叉堆,是使用完全二叉樹這種資料結構構建的一種實際應用,通過它的特性,分為最大堆和最小堆兩種,
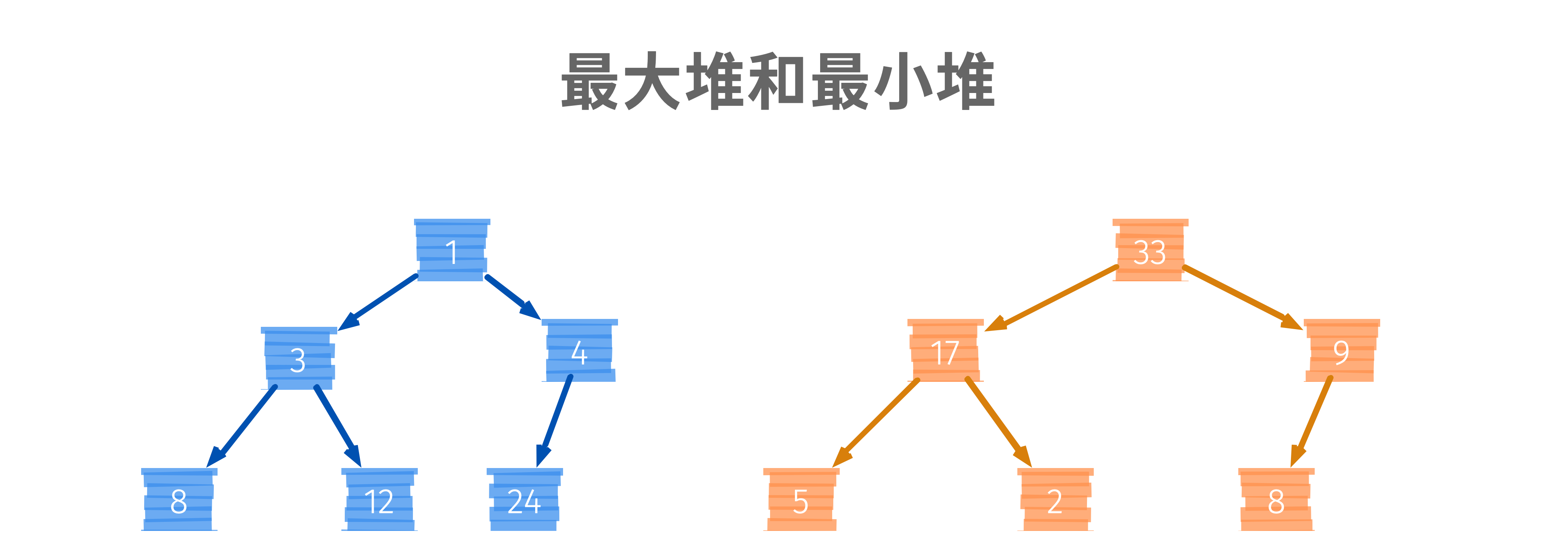
如上圖可知,最小堆就是在這顆二叉樹中,任何一個節點的值比其所在子樹的任意一個節點都要小,最大堆就是在這顆二叉樹中,任何一個節點的值都比起所在子樹的任意一個節點值都要大,
那么如何構建一個堆呢?首先要將所有的元素構建為一個完全二叉樹,完全二叉樹是指除葉子節點,所有層級是滿節點,葉子節點從左向右排列填滿,
在一個完全二叉樹中,將資料重新按照堆的的特性排列,就可以將完全二叉樹變成一個堆,這個程序叫做“堆化”,
在堆中,我們要洗掉一個元素一般從堆頂洗掉(可以取到最大值/最小值),洗掉之后,資料集就不能算作一個堆了,因為最頂層的元素沒有了,資料集不符合完全二叉樹的定義,這時,我們需要將堆的資料進行重新排列,也就是重新“堆化”,同樣的,在堆中新添加一個元素也需要重新做“堆化”的操作,來將資料集恢復到滿足堆定義的狀態,
所以,在堆這種資料結構中,最重要的是“堆化”的這個演算法操作,其次,堆化資料如何存盤也是很重要的,接下來,詳細說一下,
完全二叉樹的存盤方式
對于二叉樹來說,存盤方式有2種,一種使用陣列的形式來存盤,一種使用鏈表的方式存盤,同樣的,這兩種方式繼承了這兩種資料結構的壞處和好處,鏈表的方式相對浪費存盤空間,因為要存盤左右子樹的指標,但擴縮容方便,而陣列更加節省空間,更加方便定位節點,缺點則是擴縮容不便,
我們以陣列的方式來做示例,了解存盤的細節:
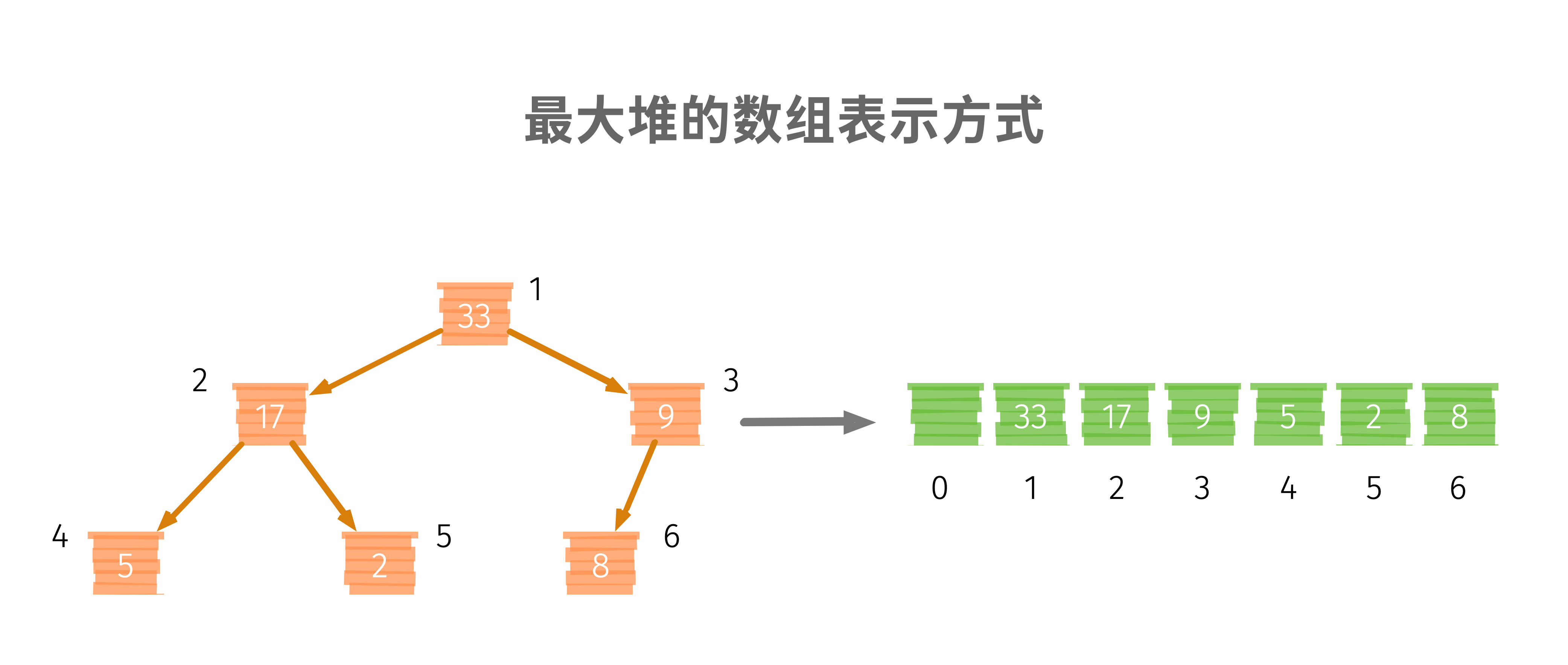
我們不用 \(index = 0\) 的位置來存盤資料,而是從 \(index = 1\) 開始,這樣,對于任意一個節點 \(i\) 來說,就有 左節點 \(2*i\),右節點 \(2*i+1\),而父節點就是 \(\frac i 2\),
堆的操作
我們先介紹兩種常用的堆操作:pop & push,添加一個元素和洗掉一個元素,
假如我們有如下的一個最大堆,當我們添加了一個元素之后,就需要做“堆化”,使得堆滿足定義,
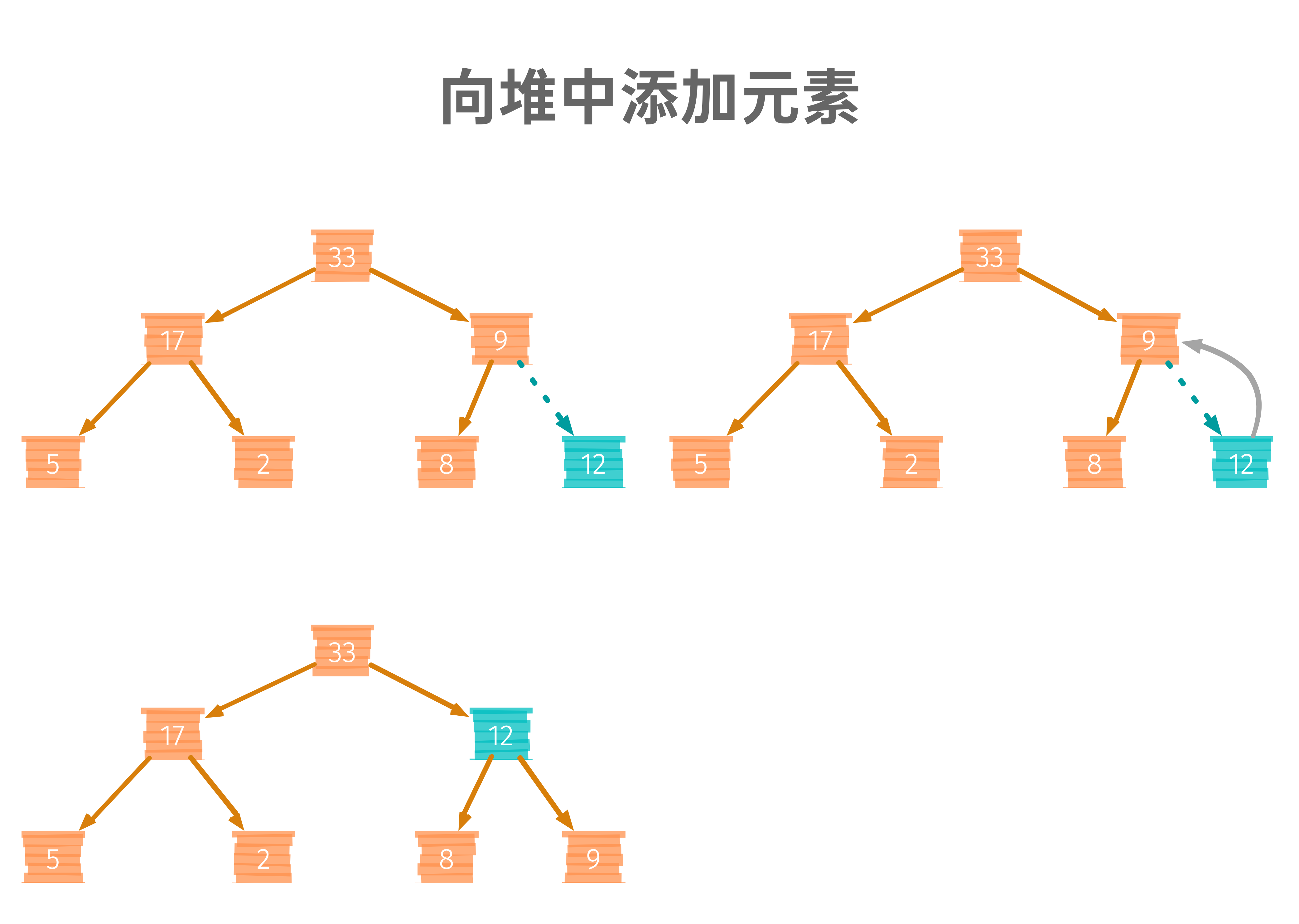
這種從堆底向上堆化的程序,叫做“從下到上堆化”,我把這個程序實作為代碼,如下:
// 從下到上堆化
func (h *Heap) downToUpHeapify(pos int) {
for pos / 2 > 0 && h.data[pos/2].Less(h.data[pos]) { // 如果存在父節點 & 值大于父節點
h.swap(pos, pos/2) // 交換兩個值的位置
pos = pos /2 // 將操作節點變為父節點的位置
}
}
當我們想要從堆頂 pop 一個元素的時候,我們需要先將元素pop,然后把堆中最后一個元素放到堆頂,然后進行一次“堆化”,
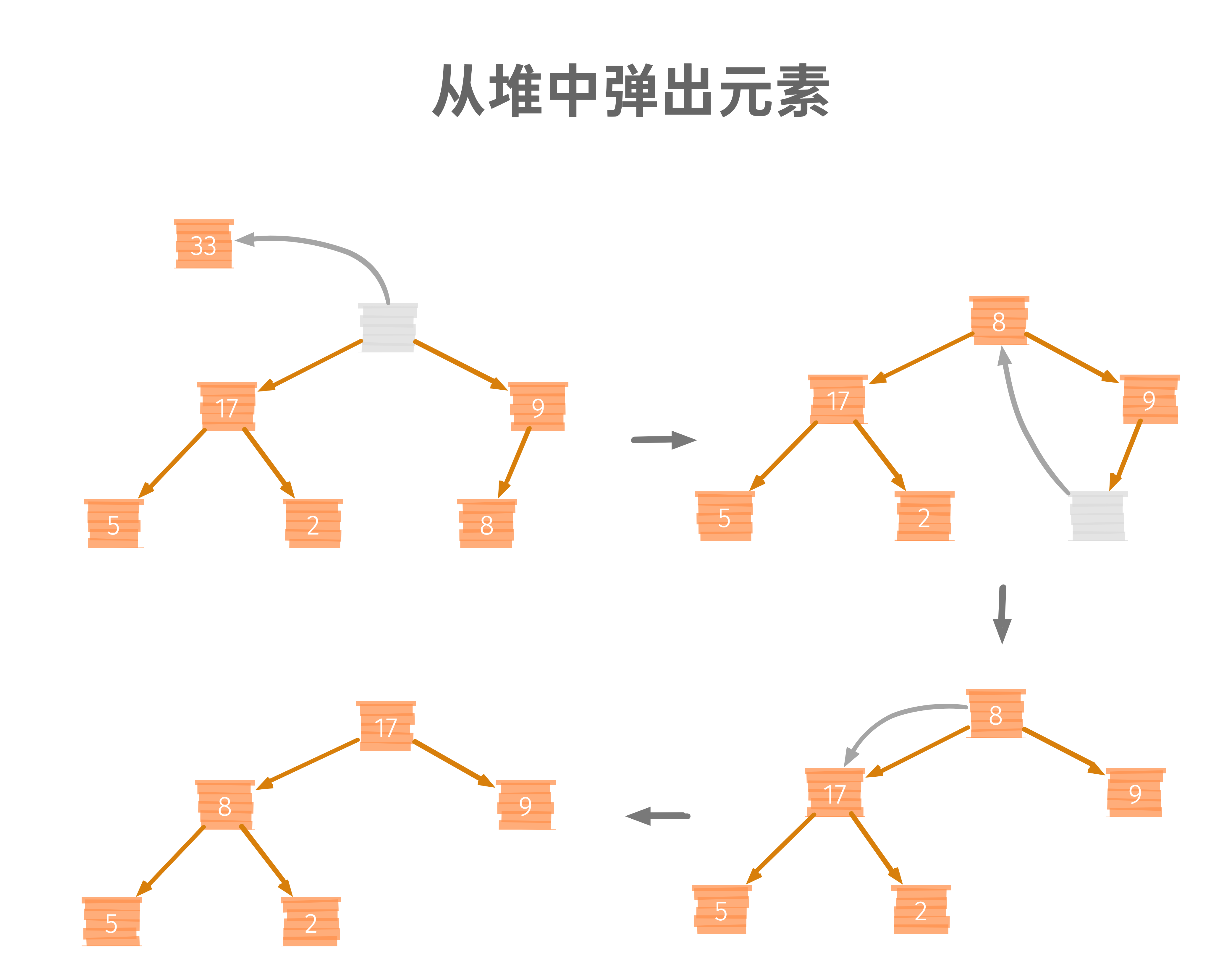
這種從堆頂向下堆化的程序,叫做“從上到下堆化”,我把這個程序實作為代碼,如下:
// 從上到下堆化
func (h *Heap) upToDownHeapify() {
max := h.len
i := 1
pos := i
for {
if i * 2 <= max && h.data[i].Less(h.data[i*2]) { // 如果有左子樹,且自己小于左子樹
pos = i*2
}
if i *2 +1 <= max && h.data[pos].Less(h.data[i*2+1]) { // 如果有右子樹,且自己小于右子樹
pos = i*2+1
}
if pos == i { // 如果位置沒有變化,說明堆化結束
break
}
h.swap(i, pos) // 交換當前位置和下一個位置的內容
i = pos // 操作下一個位置
}
}
Golang 的 container.heap 包
注意,上述的講述中,為了方便表示,我們在陣列的索引0沒有存盤內容,從索引1開始存盤,
而 Golang 的實作中,索引0 是存盤了資料的,這樣的話,每一個元素的左子樹和右子樹就分別變成了 \(2*i+1\) 和 \(2*i+2\),
Golang 的 Container.heap 是一個實作了通用最小堆的包,任何資料集只要實作了其 Interface 介面,即可使用這個包將其堆化,并進行一系列的操作,
type Interface interface {
sort.Interface
Push(x interface{}) // 把元素添加到 Len() 的位置
Pop() interface{} // 洗掉并回傳 Len() - 1 的元素.
}
// sort.Interface
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
Interface 的資料結構如上,要求實作 sort.Interface 和 Push Pop 兩個方法,
sort.Interface 的定義,同樣貼在了上面,主要是三個方法:
Len回傳資料集的長度;Less回傳 index i 是否小于 index j;Swap交換 index i 和 j 的值;
接下來,我們看一下 Push 操作:
func Push(h Interface, x interface{}) {
h.Push(x) // 向資料集添加一個元素
up(h, h.Len()-1) // 從下向上堆化
}
// 從下向上堆化的內容
func up(h Interface, j int) {
// h 表示堆,j 代表需要堆化的元素 index
for {
i := (j - 1) / 2 // 定義 j 的父 index
if i == j || !h.Less(j, i) { // 如果兩個元素相等 或者 父元素小于當前元素
break // 堆化完成
}
h.Swap(i, j) // 交換父元素和當前元素
j = i // index 變為父元素的 index
}
}
上面在 push 元素之后,做了 “從下到上”的堆化,
接下來,是 Pop 操作:
// 回傳堆頂的元素,并刪掉它
func Pop(h Interface) interface{} {
n := h.Len() - 1 // 獲取最終堆長度(去掉最后一個元素)
h.Swap(0, n) // 交換堆頂和最后一個元素
down(h, 0, n) // 從上到下堆化
return h.Pop() // 彈出最后一個元素
}
func down(h Interface, i0, n int) bool {
i := i0 // 堆頂 index
for {
j1 := 2*i + 1 // 左孩子 index
if j1 >= n || j1 < 0 { // j1 大于堆長度 或 溢位
break // 堆化結束
}
j := j1 // j = 左孩子
if j2 := j1 + 1; j2 < n && h.Less(j2, j1) {
// j2 = 右孩子;j 小于堆長度 && 右孩子小于左孩子
j = j2 // j = 2*i + 2 = 右孩子
}
// 上面是從左右孩子選出小的那個,將 index 賦值給 j
if !h.Less(j, i) { // 如果 堆頂小于 j , 堆化結束
break
}
h.Swap(i, j) // 交換堆頂元素和 j
i = j // 切換到下一個操作 index
}
// 回傳 元素是否有移動
// 此處是一個特殊設計,用來判斷向下堆化是否真的有操作
// 當洗掉中間的元素時,如果向下堆化沒有操作的話,就需要再做向上堆化
return i > i0
}
Golang 還提供了之前原理講述中沒有的方法: Remove Fix
Remove是洗掉堆中指定元素,不一定是堆頂;Fix是當某一個元素的值有變化時,用來重新堆化;
func Remove(h Interface, i int) interface{} {
n := h.Len() - 1 // 堆的長度
if n != i { // 如果不是堆頂
h.Swap(i, n) // 交換洗掉元素 和 最后一個元素
if !down(h, i, n) { // 從上到下堆化
up(h, i) // 如果沒有成功,就從下島上堆化
}
}
return h.Pop() // 彈出最后一個元素
}
func Fix(h Interface, i int) {
// i 是值被改變的 index
if !down(h, i, h.Len()) { // 從上到下堆化
up(h, i) // 如果沒有成功,就從下島上堆化
}
}
這里有一個內容需要注意,就是 Remove 中, \(n = Len() -1\) 來表示堆長度,而在 Fix 則使用 \(n = Len()\) 來表示,這是因為 Remove 中,最后一個元素是要被洗掉掉,所以最終的堆長度是 \(Len() - 1\),
上面我們已經了解了 Golang 中,對于一個堆的所有操作,只剩下最后一個方法:Init,初始化一個資料集,變成堆,
func Init(h Interface) {
n := h.Len() // n 是堆長度
// i = 最后一個非葉子節點的 index; i >= 堆頂; index 自減
for i := n/2 - 1; i >= 0; i-- {
// 從當前節點開始,從上到下堆化
down(h, i, n)
}
}
根據堆的特性可知,葉子節點不可以從上到下堆化,所以,我們找到最后非葉子節點的索引值,從這里開始做堆化操作,
至此,container.heap 包中的內容就全部講解完畢,了解了堆的原理之后,其實會發現并不難理解,
堆的應用
在堆排序中,就需要用到堆演算法來將資料級堆化,然后一個個的彈出元素,以達到排序的目的,
堆也可以用于實作優先級佇列,優先級佇列在實際開發程序中有著廣泛的應用,在很多時候,都可以用它來實作處理帶優先級的事件,處理定時任務等等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288200.html
標籤:其他
上一篇:Go--Sync.Once的應用