Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542
Python學習交流群:1039649593
scrapy 框架結構
思考
- scrapy 為什么是框架而不是庫?
- scrapy是如何作業的?
專案結構
在開始爬取之前,必須創建一個新的Scrapy專案,進入您打算存盤代碼的目錄中,運行下列命令:
注意:創建專案時,會在當前目錄下新建爬蟲專案的目錄,
這些檔案分別是:
- scrapy.cfg:專案的組態檔
- quotes/:該專案的python模塊,之后您將在此加入代碼
- quotes/items.py:專案中的item檔案
- quotes/middlewares.py:爬蟲中間件、下載中間件(處理請求體與回應體)
- quotes/pipelines.py:專案中的pipelines檔案
- quotes/settings.py:專案的設定檔案
- quotes/spiders/:放置spider代碼的目錄
Scrapy原理圖
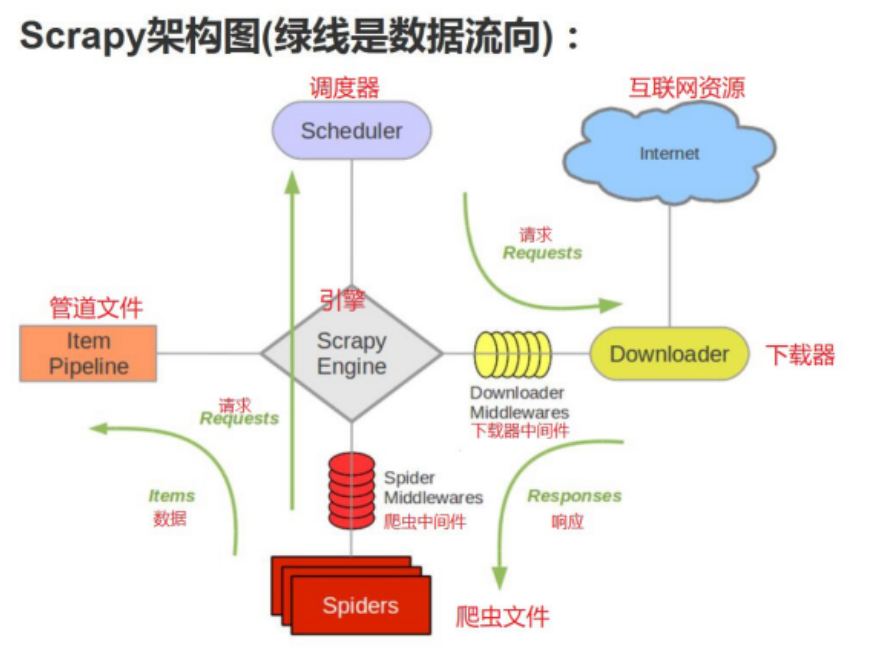
各個組件的介紹
-
Engine,引擎,處理整個系統的資料流處理、觸發事務,是整個框架的核心,
-
ltem,專案,它定義了爬取結果的資料結構,爬取的資料會被賦值成該ltem物件,
-
Scheduler,調度器,接受引擎發過來的請求并將其加入佇列中,在引擎再次請求的時候將請求提供給引擎,
-
Downloader,下載器,下載網頁內容,并將網頁內容回傳給蜘蛛,
-
Spiders,蜘蛛,其內定義了爬取的邏輯和網頁的決議規則,它主要負責決議回應并生成提結果和新的請求,
-
Item Pipeline,專案管道,負責處理由蜘蛛從網頁中抽取的專案,它的主要任務是清洗、驗證和存盤資料,
-
Downloader Middlewares,下載器中間件,位于引擎和下載器之間的鉤子框架,主要處理引擎與下載器之間的請求及回應,
-
Spider Middlewares,蜘蛛中間件,位于引擎和蜘蛛之間的鉤子框架,主要處理蜘蛛輸入的回應和輸出的結果及新的請求,
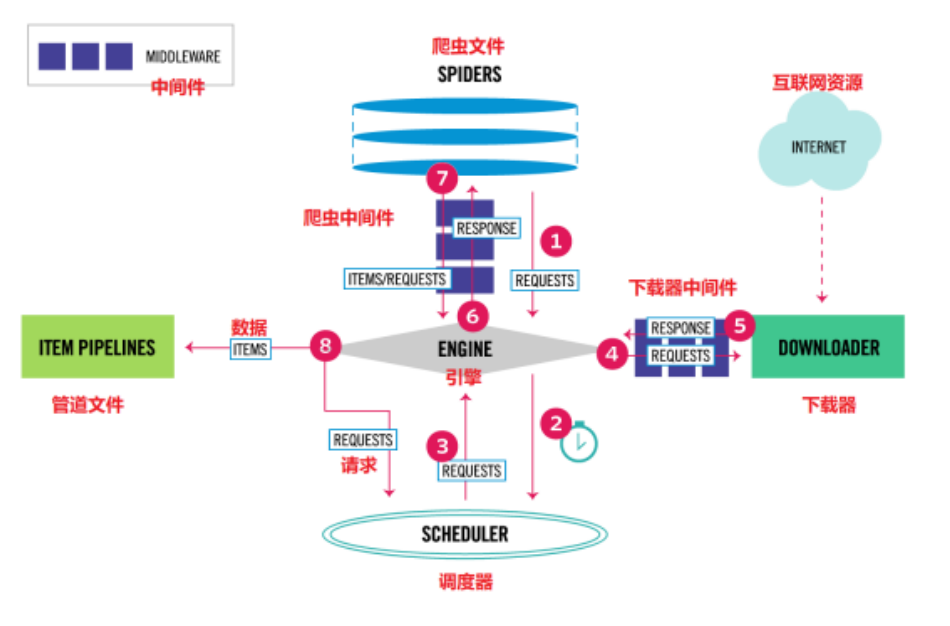
資料的流動
-
Scrapy Engine(引擎):負責Spider、ltemPipeline、Downloader、Scheduler中間的通訊,信號、資料傳遞等,
-
Scheduler(調度器):負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎,
-
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
-
Spider(爬蟲)︰負責處理所有Responses,從中分析提取資料,獲取ltem欄位需要的資料,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器),
-
ltem Pipeline(管道):負責處理Spider中獲取到的ltem,并進行進行后期處理(詳細分析、過濾、存盤等)的地方.
-
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件,
-
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288357.html
標籤:Python
上一篇:pycharm代碼洗掉恢復
下一篇:記賬程式2.0