前言
主要目標是爬取Github上指定用戶的粉絲資料以及對爬取到的資料進行一波簡單的可視化分析,
讓我們愉快地開始吧~

開發工具
Python版本:3.6.4
相關模塊:
bs4模塊;
requests模塊;
argparse模塊;
pyecharts模塊;
以及一些python自帶的模塊,
環境搭建
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
資料爬取
感覺好久沒用beautifulsoup了,所以今天就用它來決議網頁從而獲得我們自己想要的資料唄,以我自己的賬戶為例:
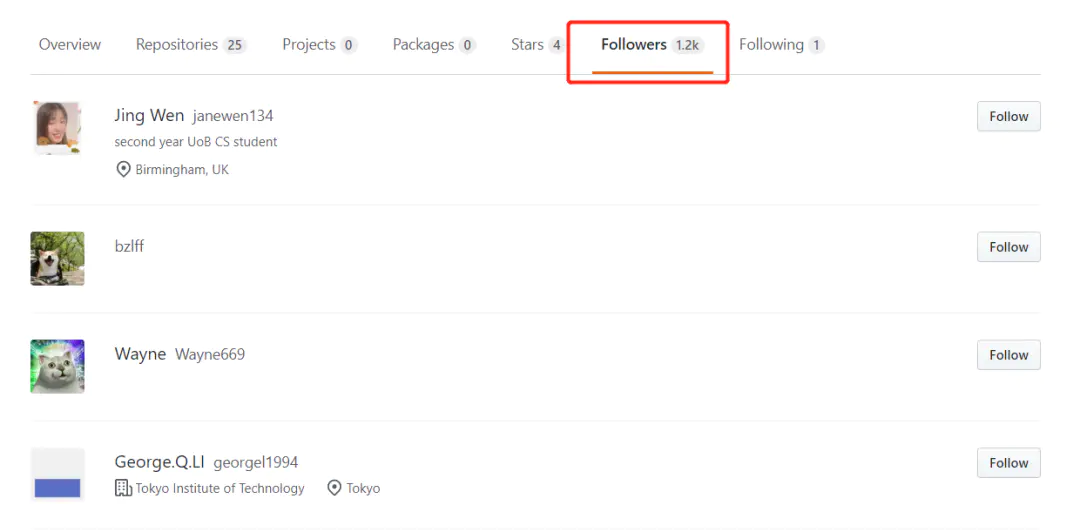
我們先抓取所有關注者的用戶名,它在類似如下圖所示的標簽中:
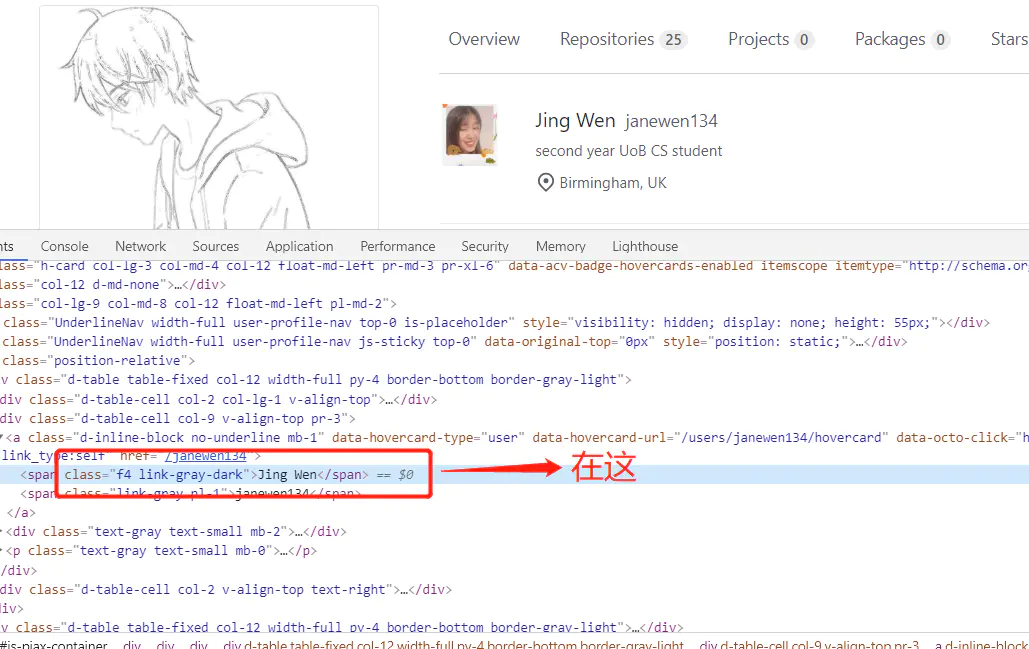
用beautifulsoup可以很方便地提取它們:
'''獲得followers的用戶名'''
def getfollowernames(self):
print('[INFO]: 正在獲取%s的所有followers用戶名...' % self.target_username)
page = 0
follower_names = []
headers = self.headers.copy()
while True:
page += 1
followers_url = f'https://github.com/{self.target_username}?page={page}&tab=followers'
try:
response = requests.get(followers_url, headers=headers, timeout=15)
html = response.text
if 've reached the end' in html:
break
soup = BeautifulSoup(html, 'lxml')
for name in soup.find_all('span', class_='link-gray pl-1'):
print(name)
follower_names.append(name.text)
for name in soup.find_all('span', class_='link-gray'):
print(name)
if name.text not in follower_names:
follower_names.append(name.text)
except:
pass
time.sleep(random.random() + random.randrange(0, 2))
headers.update({'Referer': followers_url})
print('[INFO]: 成功獲取%s的%s個followers用戶名...' % (self.target_username, len(follower_names)))
return follower_names
接著,我們就可以根據這些用戶名進入到他們的主頁來抓取對應用戶的詳細資料了,每個主頁鏈接的構造方式為:
https://github.com/ + 用戶名
例如: https://github.com/CharlesPikachu
我們想要抓取的資料包括:
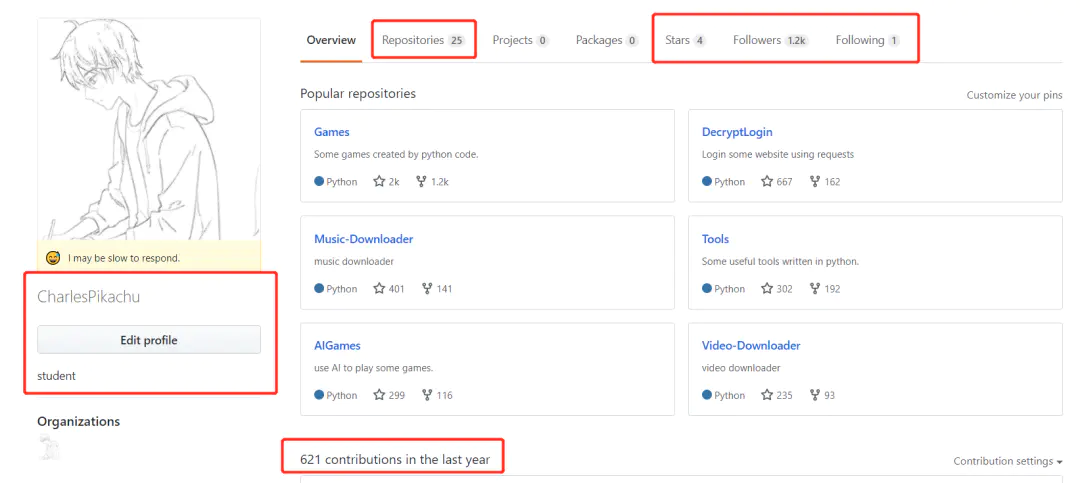
同樣地,我們利用beautifulsoup來提取這些資訊:
for idx, name in enumerate(follower_names):
print('[INFO]: 正在爬取用戶%s的詳細資訊...' % name)
user_url = f'https://github.com/{name}'
try:
response = requests.get(user_url, headers=self.headers, timeout=15)
html = response.text
soup = BeautifulSoup(html, 'lxml')
# --獲取用戶名
username = soup.find_all('span', class_='p-name vcard-fullname d-block overflow-hidden')
if username:
username = [name, username[0].text]
else:
username = [name, '']
# --所在地
position = soup.find_all('span', class_='p-label')
if position:
position = position[0].text
else:
position = ''
# --倉庫數, stars數, followers, following
overview = soup.find_all('span', class_='Counter')
num_repos = self.str2int(overview[0].text)
num_stars = self.str2int(overview[2].text)
num_followers = self.str2int(overview[3].text)
num_followings = self.str2int(overview[4].text)
# --貢獻數(最近一年)
num_contributions = soup.find_all('h2', class_='f4 text-normal mb-2')
num_contributions = self.str2int(num_contributions[0].text.replace('\n', '').replace(' ', ''). \
replace('contributioninthelastyear', '').replace('contributionsinthelastyear', ''))
# --保存資料
info = [username, position, num_repos, num_stars, num_followers, num_followings, num_contributions]
print(info)
follower_infos[str(idx)] = info
except:
pass
time.sleep(random.random() + random.randrange(0, 2))
資料可視化
這里以我們自己的粉絲資料為例,大概1200條吧,
先來看看他們在過去一年里提交的代碼次數分布吧:
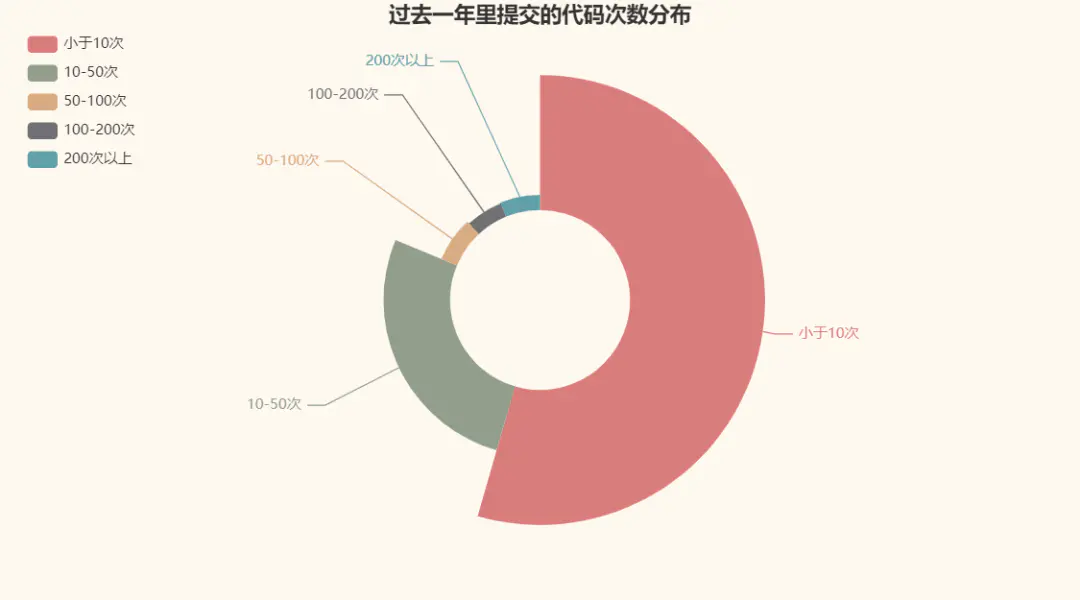
提交最多的一位名字叫fengjixuchui,在過去一年一共有9437次提交,平均下來,每天都得提交20多次,也太勤快了,
再來看看每個人擁有的倉庫數量分布唄:
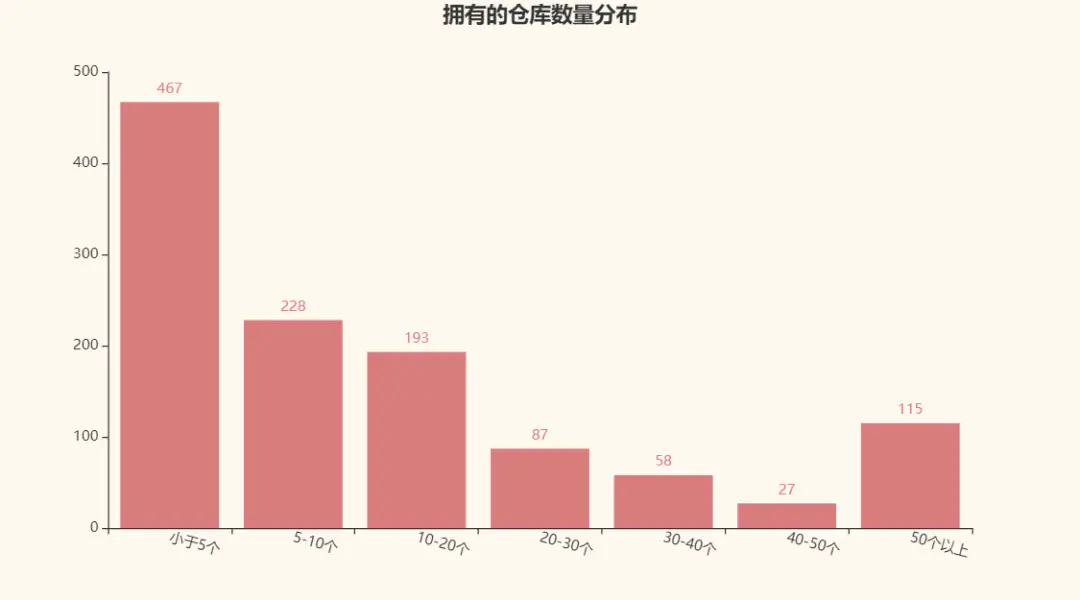
本以為會是條單調的曲線,看來低估各位了,
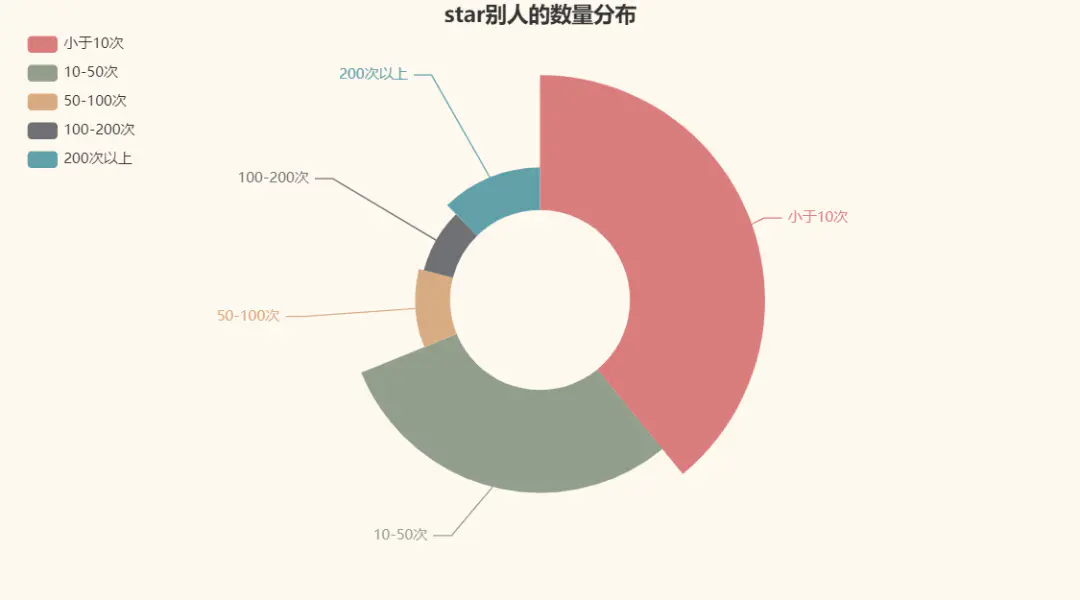
接著來看看star別人的數量分布唄:
再來看看這1000多個人擁有的粉絲數量分布唄:
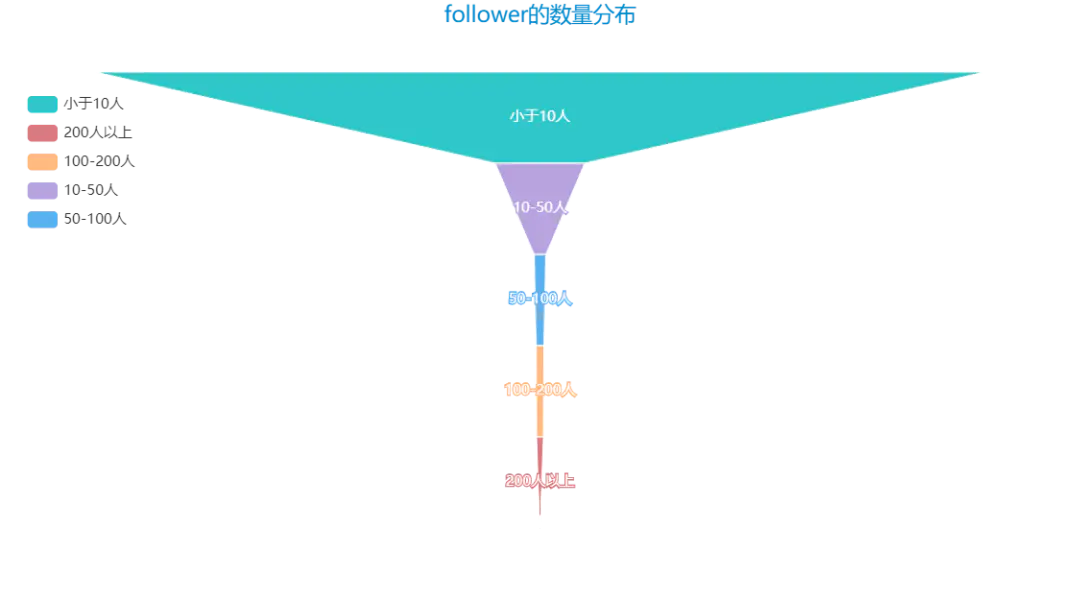
簡單看了下,有不少小伙伴的followers數量比我還多,果然高手在民間,
文章到這里就結束了,感謝你的觀看,Python小案例系列暫停更新,下個篇章將分享Python小工具系列
為了感謝讀者們,我想把我最近收藏的一些編程干貨分享給大家,回饋每一個讀者,希望能幫到你們,
干貨主要有:
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
⑥ Python為期兩天的爬蟲訓練營直播權限
All done~完整源代碼+干貨詳見個人簡介或者私信獲取相關檔案,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288495.html
標籤:Python