簡述
CloudCanal 近期實作了 MySQL(RDS) 到 ClickHouse 實時同步的能力,功能包含全量資料遷移、增量資料遷移、結構遷移能力,以及附帶的監控、告警、HA等能力(平臺自帶),
ClickHouse 本身并不直接支持 Update 和 Delete 能力,但是他自帶的 MergeTree 系串列中 CollapsingMergeTree 和 VersionedCollapsingMergeTree 可變相實作實時增量的目的,并且性能完全夠用,能夠比較輕松達到 1k RPS 以上的能力,
接下來的文章,簡要介紹 CloudCanal 是如何實作這個能力,以及作為用戶我們怎么比較好的使用這個能力,
技術點
結構遷移
CloudCanal 默認提供結構遷移,默認選擇 CollapsingMergeTree 作為表引擎,并增加一個默認欄位 __cc_ck_sign,源主鍵作為 sortKey,如下示例:
CREATE TABLE console.worker_stats
(
`id` Int64,
`gmt_create` DateTime,
`worker_id` Int64,
`cpu_stat` String,
`mem_stat` String,
`disk_stat` String,
`__cc_ck_sign` Int8 DEFAULT 1
)
ENGINE = CollapsingMergeTree(__cc_ck_sign)
ORDER BY id
SETTINGS index_granularity = 8192
ClickHouse 表引擎中,CollapsingMergeTree 和 VersionedCollapsingMergeTree 都能通過標記位按規則折疊資料,從而達到更新和洗掉的效果,VersionedCollapsingMergeTree 相比 CollapsingMergeTree 優勢在于同一條資料的不同變更可以亂序寫入,但是 CloudCanal 選擇 CollapsingMergeTree 主要原因在于2點
-
- CloudCanal 中同一條記錄必定是按源庫變更順序寫入,不存在亂序情況
-
- 不需要維護 VersionedCollapsingMergeTree 中的 Version 欄位(版本,也可以起其他名字)
所以 CloudCanal 選擇了 CollapsingMergeTree 作為默認表引擎,
寫資料
CloudCanal 寫資料主要包含全量和增量兩種,即單次搬遷存量資料和長期同步,兩者寫入略有不同,全量寫入對端主要作業是批量和多執行緒,因為 CloudCanal 結構遷移默認設定了標記位欄位 __cc_ck_sign default 值為 1, 所以就不需要做特殊處理,
對于增量, CloudCanal 則需要做 3 件事情,
- 轉換 Update、Delete 操作為 Insert
這一步有兩件事情要做,第一件是按照操作型別,填充標記欄位值,其中 Insert 和 Update 為 1 ,Delete 為 -1 ,第二件是將對應增量資料的前鏡像或者后鏡像填充到結果記錄中,以便后續 insert 寫入,
for (CanalRowChange rowChange : rowChanges) {
switch (rowChange.getEventType()) {
case INSERT: {
for (CanalRowData rowData : rowChange.getRowDatasList()) {
rowData.getAfterColumnsList().add(nonDeleteCol);
records.add(rowData.getAfterColumnsList());
}
break;
}
case UPDATE: {
for (CanalRowData rowData : rowChange.getRowDatasList()) {
rowData.getBeforeColumnsList().add(deleteCol);
records.add(rowData.getBeforeColumnsList());
rowData.getAfterColumnsList().add(nonDeleteCol);
records.add(rowData.getAfterColumnsList());
}
break;
}
case DELETE: {
for (CanalRowData rowData : rowChange.getRowDatasList()) {
rowData.getBeforeColumnsList().add(deleteCol);
records.add(rowData.getBeforeColumnsList());
}
break;
}
default:
throw new CanalException("not supported event type,eventType:" + rowChange.getEventType());
}
}
- 按表歸組
因為 IUD 操作已全部轉換為 Insert, 且為全鏡像(所有欄位都填充了值),所以可以按表歸組,然后批量寫入,即使單執行緒也能滿足大部分場景的同步性能要求,
protected Map<TableUnit, List<CanalRowChange>> groupByTable(IncrementMessage message) {
Map<TableUnit, List<CanalRowChange>> data = https://www.cnblogs.com/clougence/archive/2021/06/30/new HashMap<>();
for (ParsedEntry entry : message.getEntries()) {
if (entry.getEntryType() == CanalEntryType.ROWDATA) {
CanalRowChange rowChange = entry.getRowChange();
if (!rowChange.isDdl()) {
List changes = data.computeIfAbsent(new TableUnit(entry.getHeader().getSchemaName(), entry.getHeader().getTableName()), k -> new ArrayList<>());
changes.add(rowChange);
}
}
}
return data;
}
- 并行寫入
將按表歸組的資料使用并行執行框架執行,具體不詳述,
舉個"栗子"
- 添加資料源
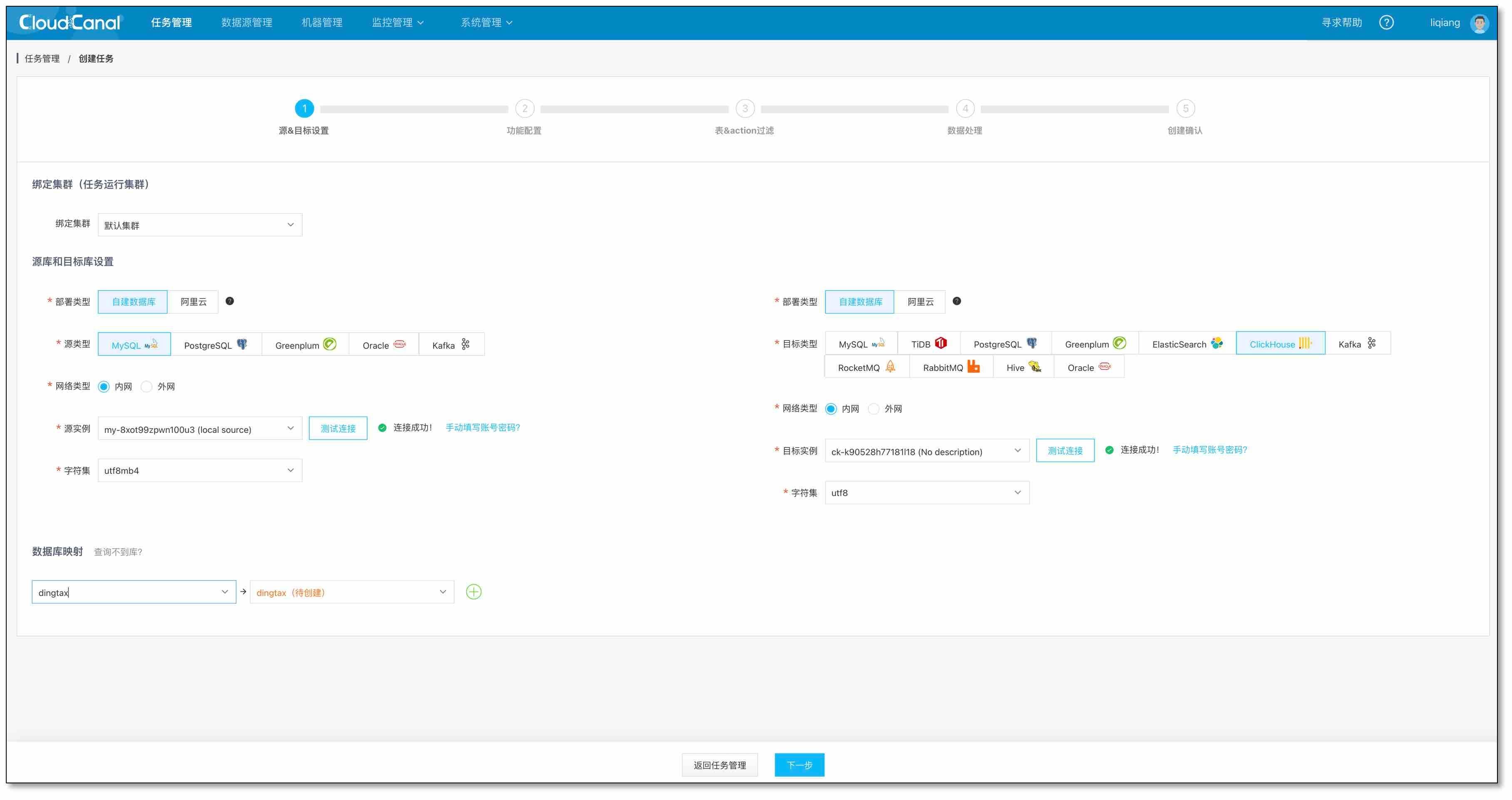
- 創建任務,選擇資料源和庫,并連接成功,點擊下一步
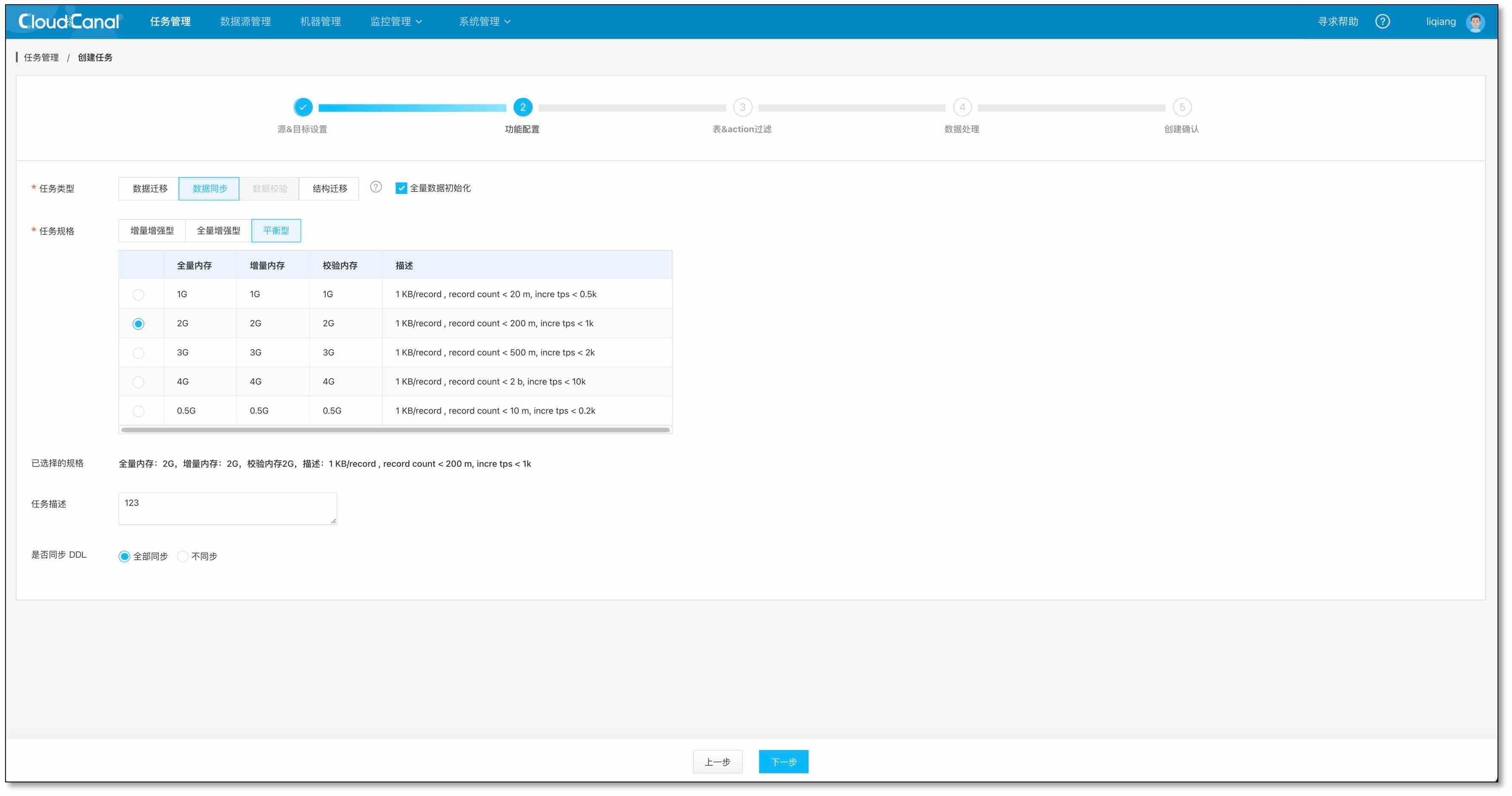
- 選擇資料同步,建議規格至少選擇 1 GB.目前 MySQL->ClickHouse 結構遷移自動過濾,所以選擇無效,點擊下一步
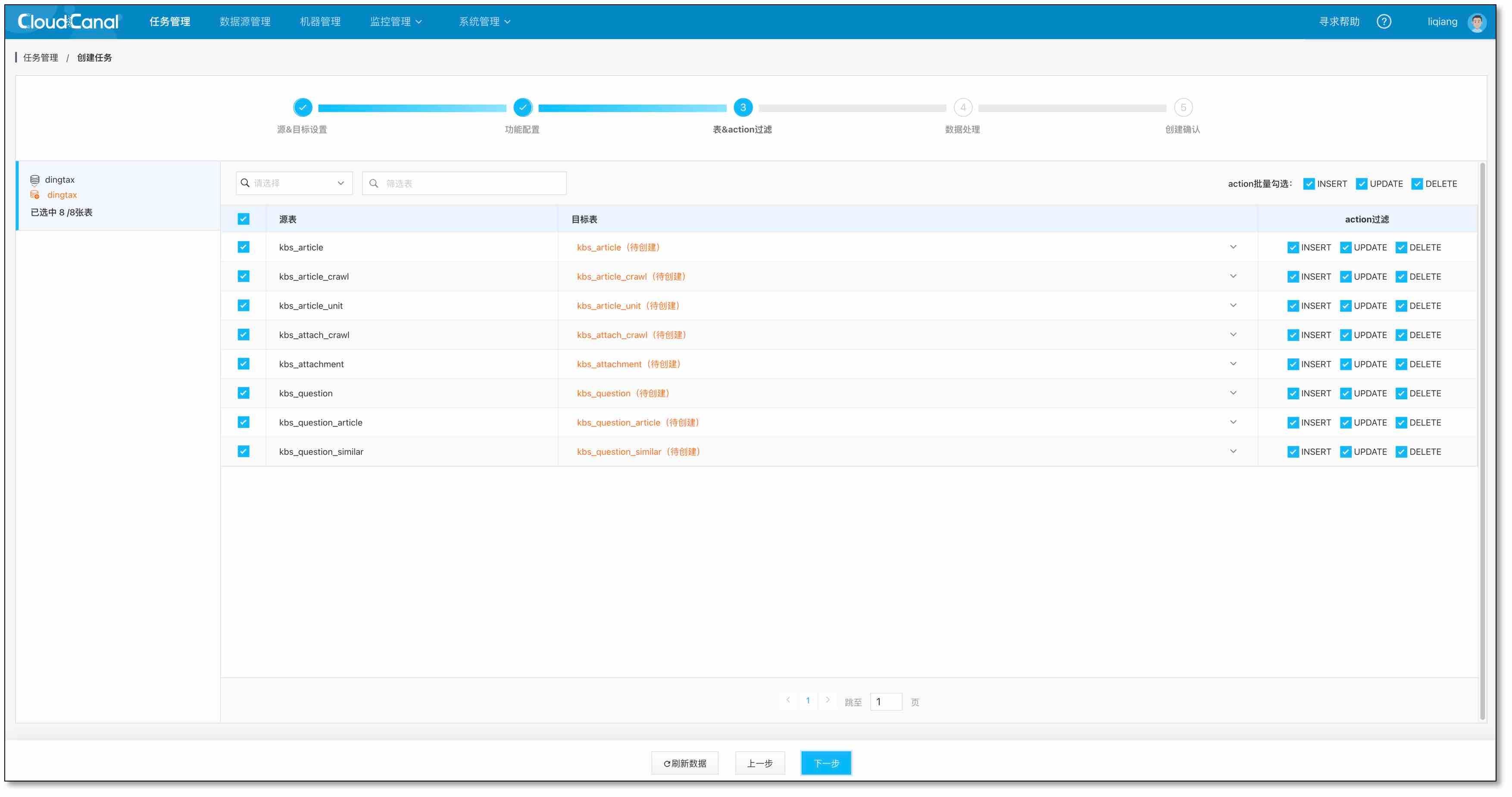
- 選擇表,默認 ClickHouse 上創建
CollapsingMergeTree表引擎,并自動添加__cc_ck_sign折疊標記欄位,點擊下一步
- 選擇欄位,點擊下一步
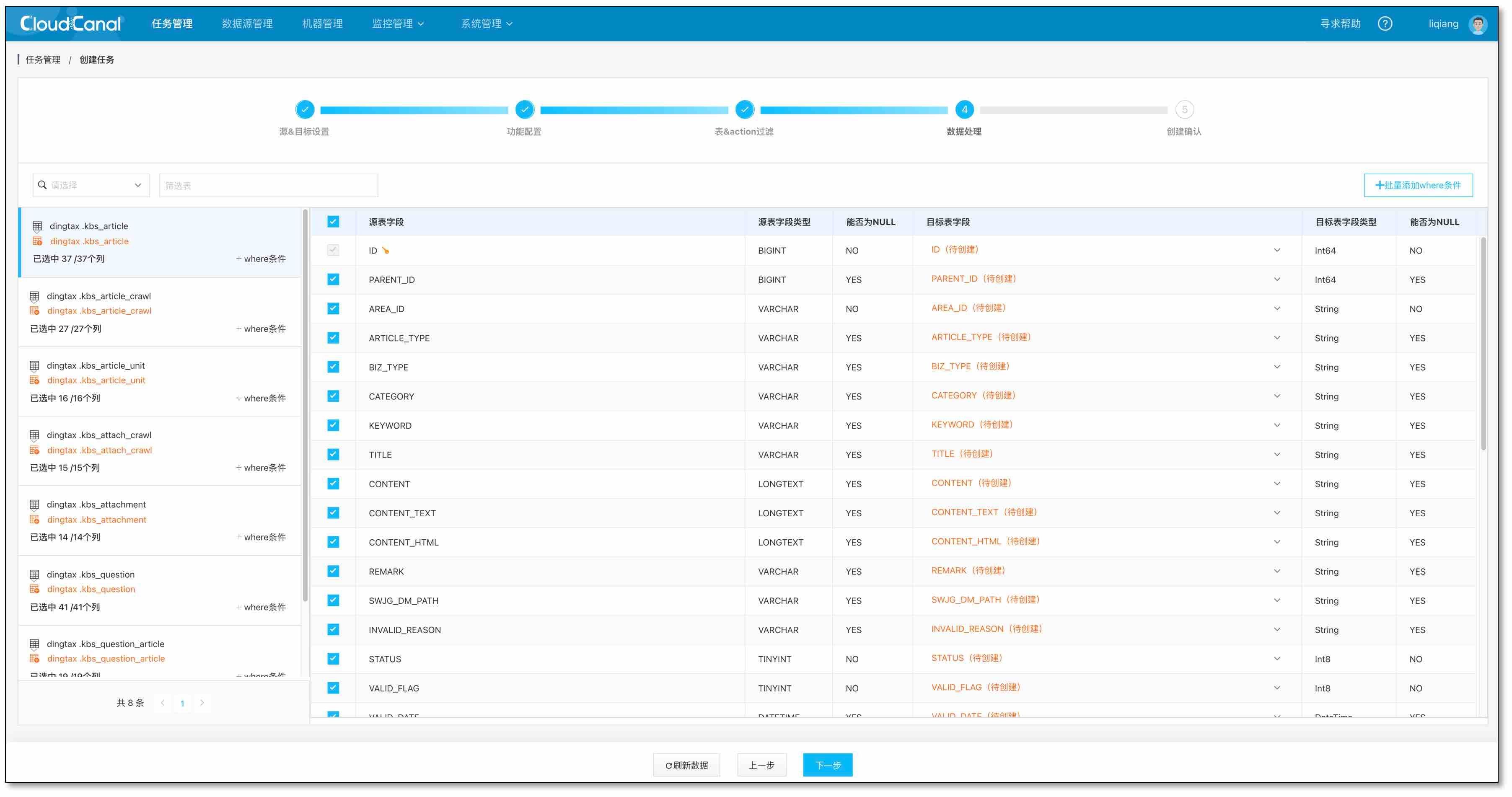
- 創建任務
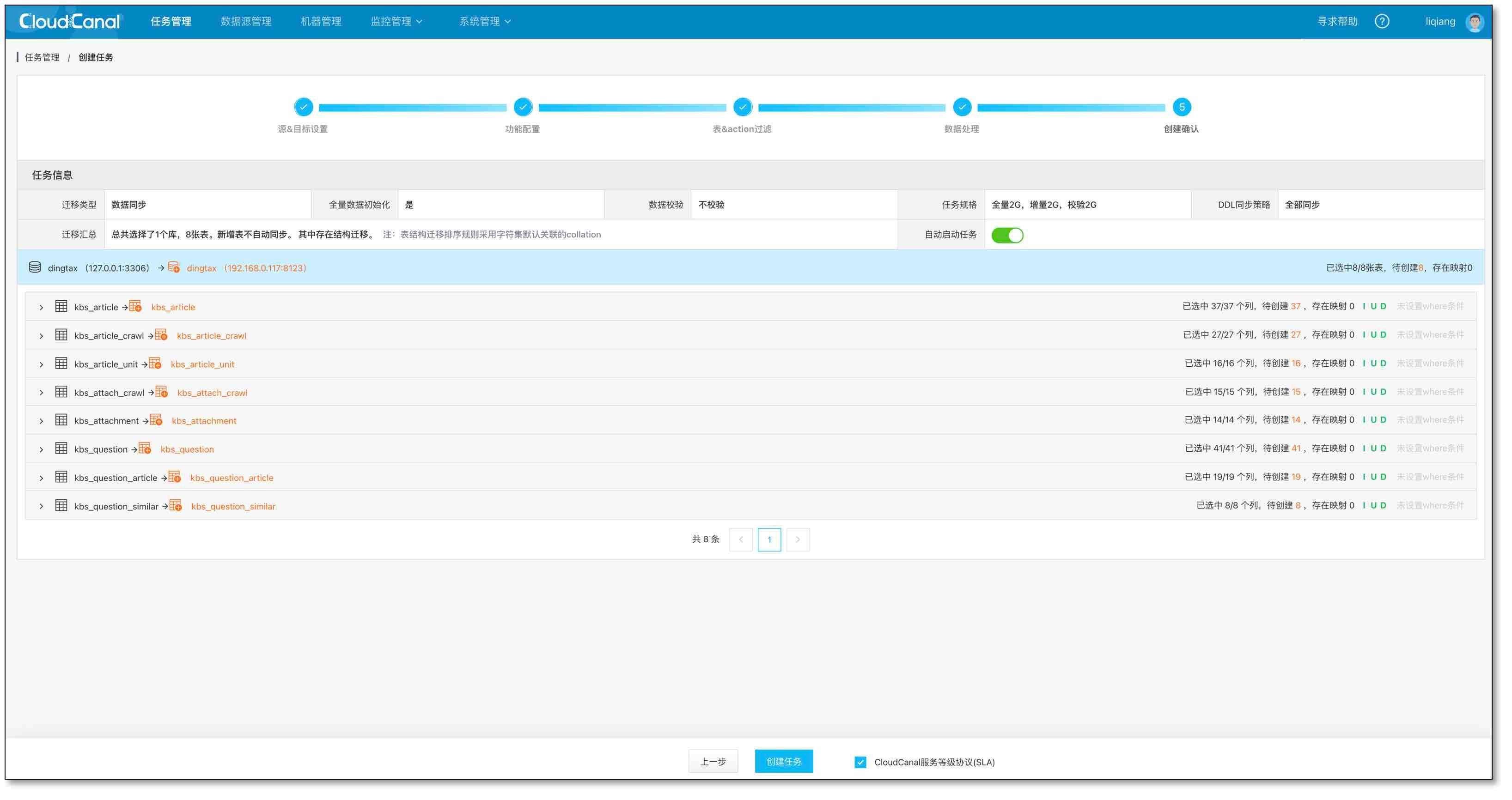
- 等待任務自動結構遷移、全量遷移、資料同步追上
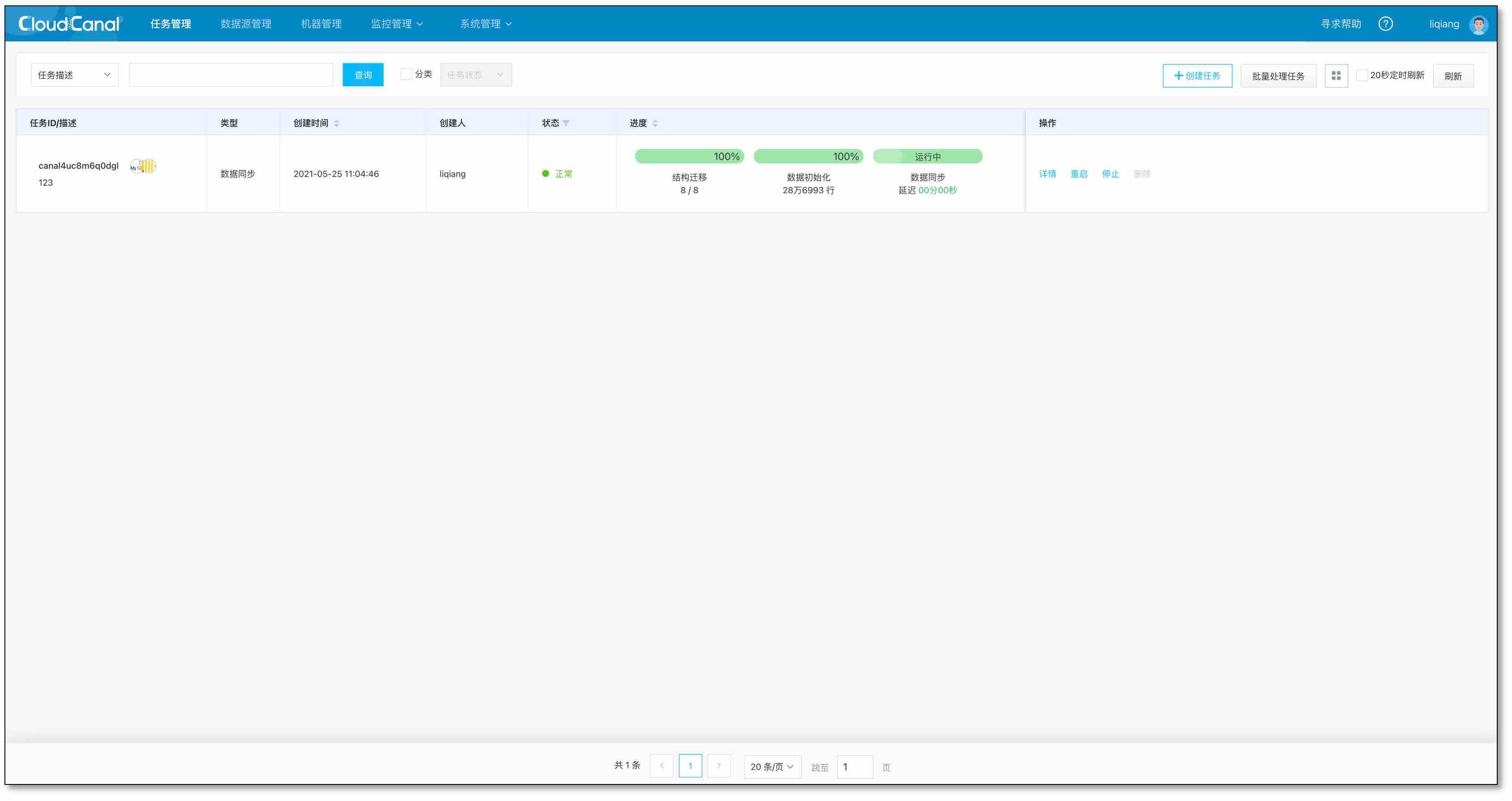
- 造點 Insert、Update、Delete 負載

- 延遲追平狀態,停止負載
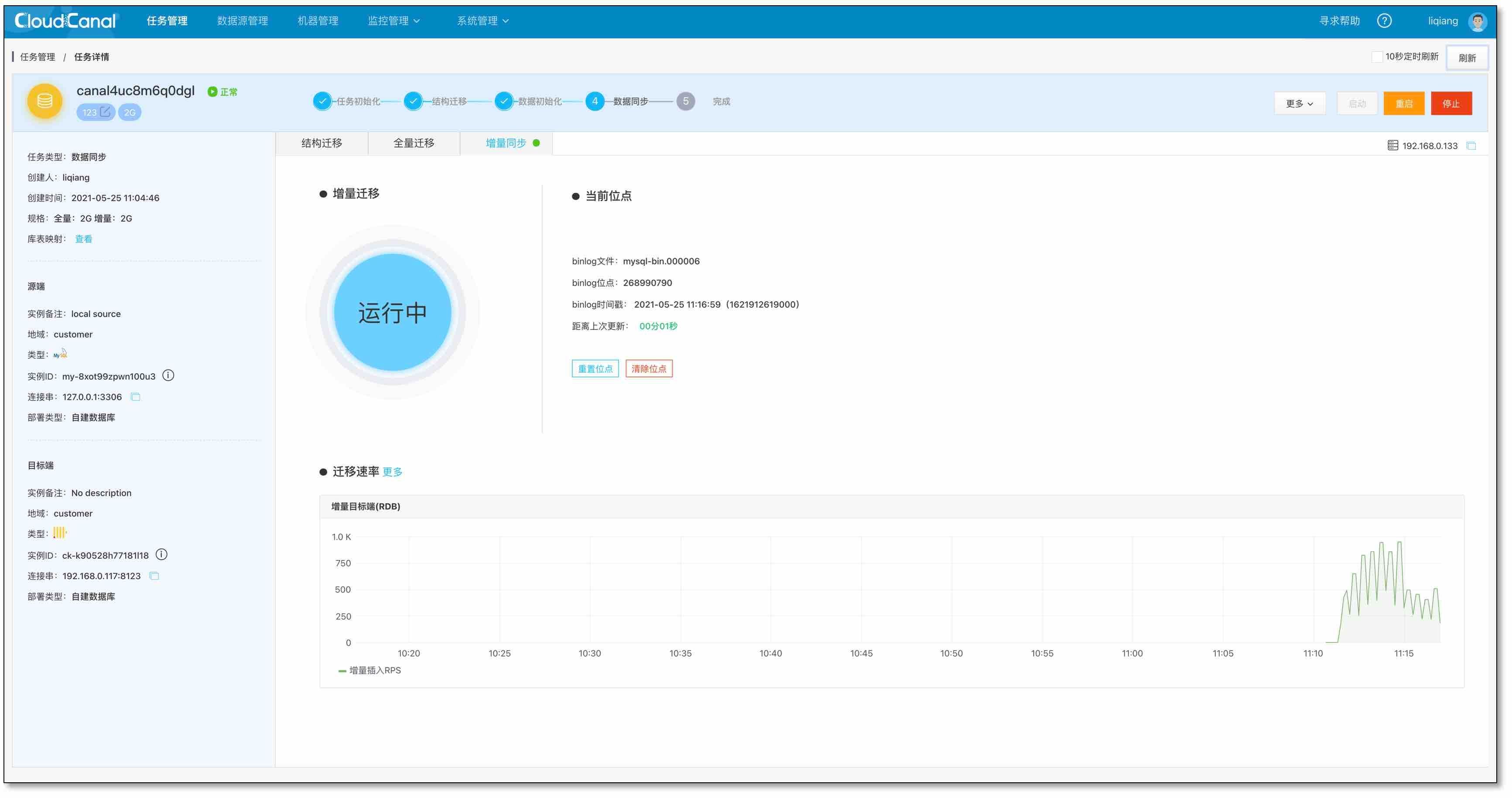
- 檢查源端 MySQL 表資料,以其中一張表為例
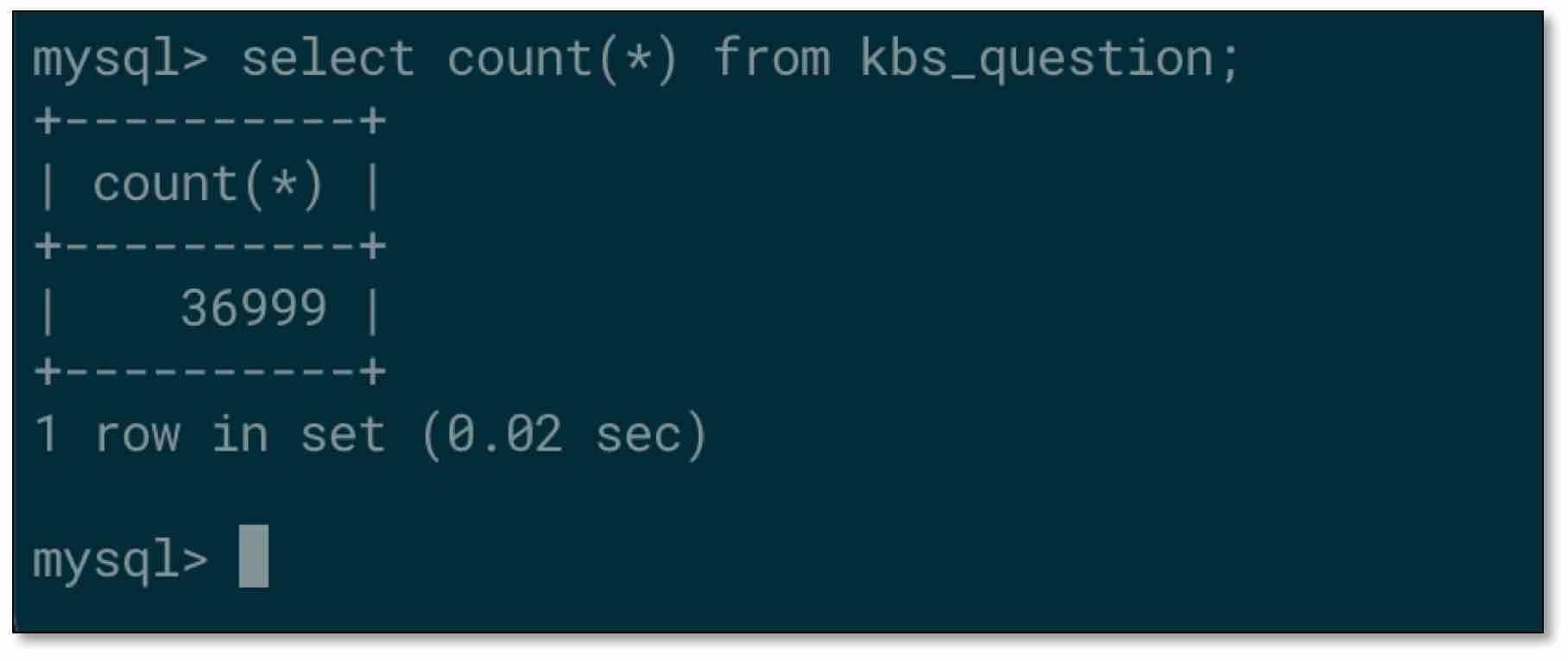
- 檢查對端 ClickHouse 表資料,不一致?!!
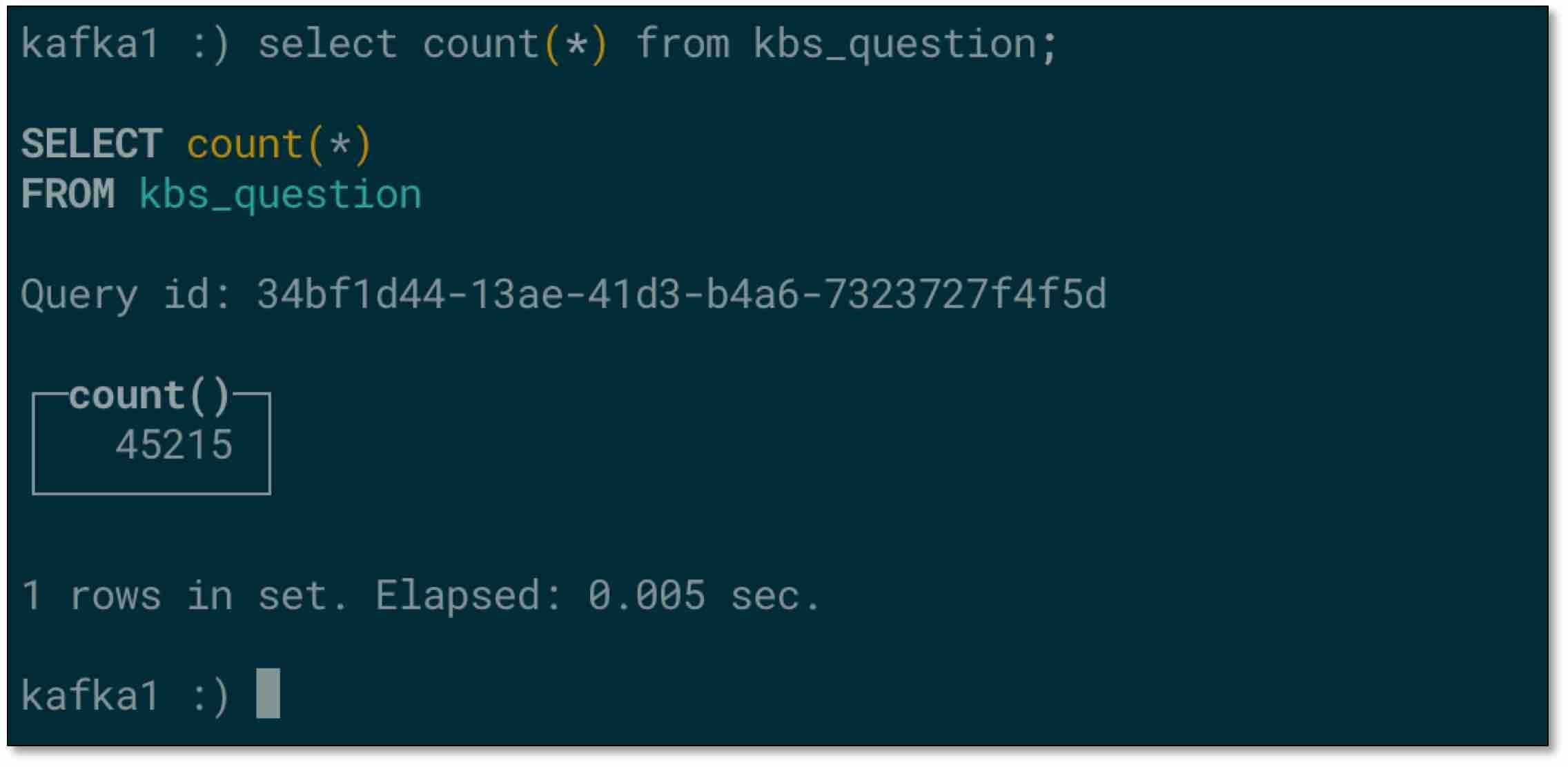
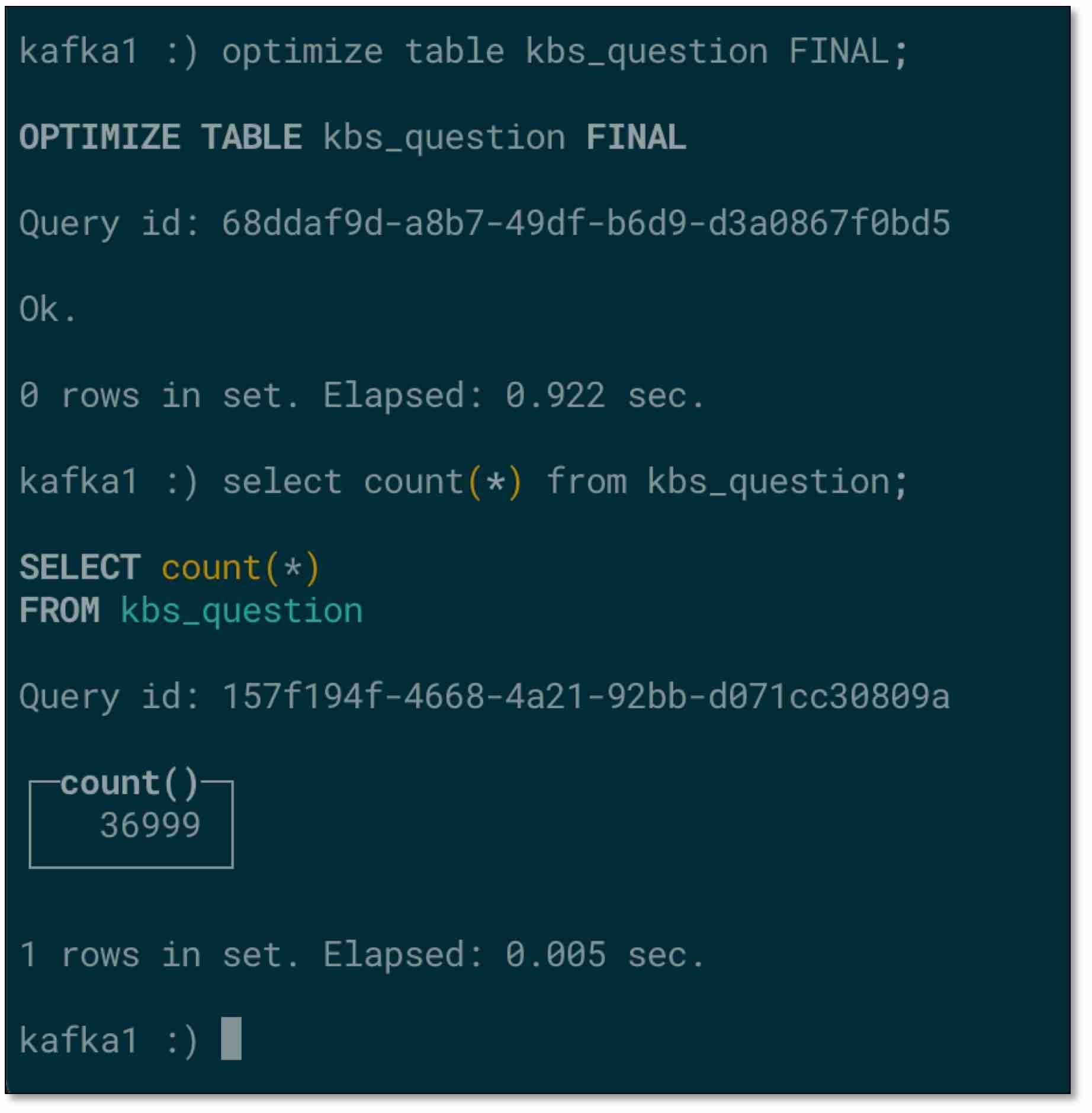
- 手動優化下表,資料一致,雖然可以等待 ClickHouse 自動優化,但是如果需要直接得到準確結果,可手動優化(注意:手動優化可能導致資料庫機器壓力過大)
常見問題
我在ClickHouse上已經創建了表怎么辦?
目前比較建議直接使用 CloudCanal 自動結構遷移的方式來創建任務,
如果已建表為 CollapsingMergeTree 表引擎,請將標記位欄位改成 __cc_ck_sign Int8 DEFAULT 1`,再創建任務(此時就不再自動結構遷移,而是使用已存在表),
如果為其他表引擎,暫時不支持(主要是不支持增量能力,需要 CloudCanal 進一步探索),
同步過去的資料什么時候合并?
當 CloudCanal 同步資料到 ClickHouse 時,ClickHouse 并不會實時合并資料,也沒有一致性可言,所以一般情況是等待合并,或者直接手動合并(造成機器高負載、高IO),如 optimize table worker_stats FINAL,
DDL 怎么做?
目前 CloudCanal 還未支持到 ClickHouse 的 DDL 同步,產品實作上,目前是忽略的,所以如果做 DDL ,加欄位建議對端先加,再加源端,減欄位反之,
總結
本文簡要介紹了 CloudCanal 實作 MySQL(RDS) 到 ClickHouse 資料遷移同步的能力,具備一站式、資料實時特點,從技術點、例子、以及常見問題角度展開,文章如有錯誤,煩請大家勘誤,后續也歡迎大家試用,提供寶貴的意見和建議,
CloudCanal-免費好用的企業級資料同步工具,歡迎品鑒,
了解產品可以查看官方網站: http://www.clougence.com
CloudCanal社區:https://www.askcug.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288717.html
標籤:其他
上一篇:23天設計模式之抽象工廠模式