歡迎訪問我的GitHub
https://github.com/zq2599/blog_demos
內容:所有原創文章分類匯總及配套原始碼,涉及Java、Docker、Kubernetes、DevOPS等;
《hive學習筆記》系列導航
- 基本資料型別
- 復雜資料型別
- 內部表和外部表
- 磁區表
- 分桶
- HiveQL基礎
- 內置函式
- Sqoop
- 基礎UDF
- 用戶自定義聚合函式(UDAF)
- UDTF
本篇概覽
本文是《hive學習筆記》系列的第四篇,要學習的是hive的磁區表,簡單來說hive的磁區就是創建層級目錄的一種方式,處于同一磁區的記錄其實就是資料在同一個子目錄下,磁區一共有兩種:靜態和動態,接下來逐一嘗試;
靜態磁區(單欄位磁區)
先嘗試用單個欄位磁區,t9表有三個欄位:名稱city、年齡age、城市city,以城市作為磁區欄位:
- 建表:
create table t9 (name string, age int)
partitioned by (city string)
row format delimited
fields terminated by ',';
- 查看:
hive> desc t9;
OK
name string
age int
city string
# Partition Information
# col_name data_type comment
city string
Time taken: 0.159 seconds, Fetched: 8 row(s)
- 創建名為009.txt的文本檔案,內容如下,可見每行只有name和age兩個欄位,用來磁區的city欄位不在這里設定,而是在執行匯入命令的時候設定,稍后就會見到:
tom,11
jerry,12
- 匯入資料的命令如下,可見匯入命令中制定了city欄位,也就是說一次匯入的所有資料,city欄位值都是同一個:
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t9
partition(city='shenzhen');
- 再執行一次匯入操作,命令如下,city的值從前面的shenzhen改為guangzhou:
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t9
partition(city='guangzhou');
- 查詢資料,可見一共四條資料,city共有兩個值:
hive> select * from t9;
OK
t9.name t9.age t9.city
tom 11 guangzhou
jerry 12 guangzhou
tom 11 shenzhen
jerry 12 shenzhen
Time taken: 0.104 seconds, Fetched: 4 row(s)
- 前面曾提到磁區實際上是不同的子目錄,來看一下是不是如此,如下圖,紅框是t9的檔案目錄,下面有兩個子目錄city=guangzhou和city=shenzhen:
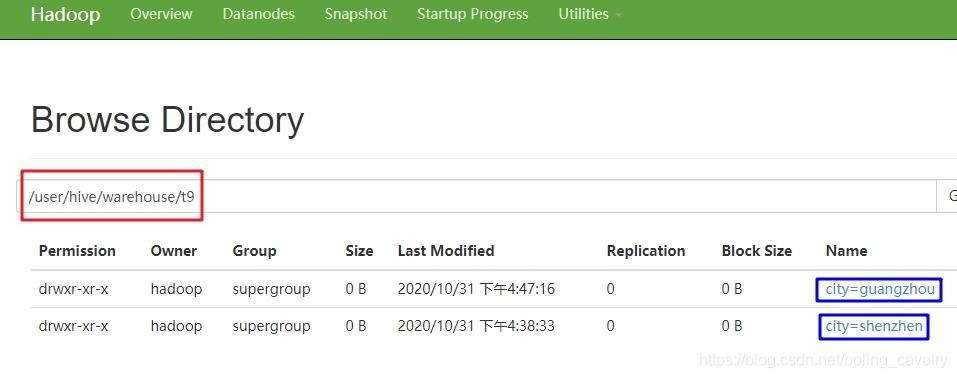
- 查看子目錄里面檔案的內容,可見每條記錄只有name和age兩個欄位:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/t9/city=guangzhou
Found 1 items
-rwxr-xr-x 3 hadoop supergroup 16 2020-10-31 16:47 /user/hive/warehouse/t9/city=guangzhou/009.txt
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t9/city=guangzhou/009.txt
tom,11
jerry,12
[hadoop@node0 bin]$
以上就是以單個欄位做靜態磁區的實踐,接下來嘗試多欄位磁區;
靜態磁區(多欄位磁區)
- 新建名為t10的表,有兩個磁區欄位:province和city,建表陳述句:
create table t10 (name string, age int)
partitioned by (province string, city string)
row format delimited
fields terminated by ',';
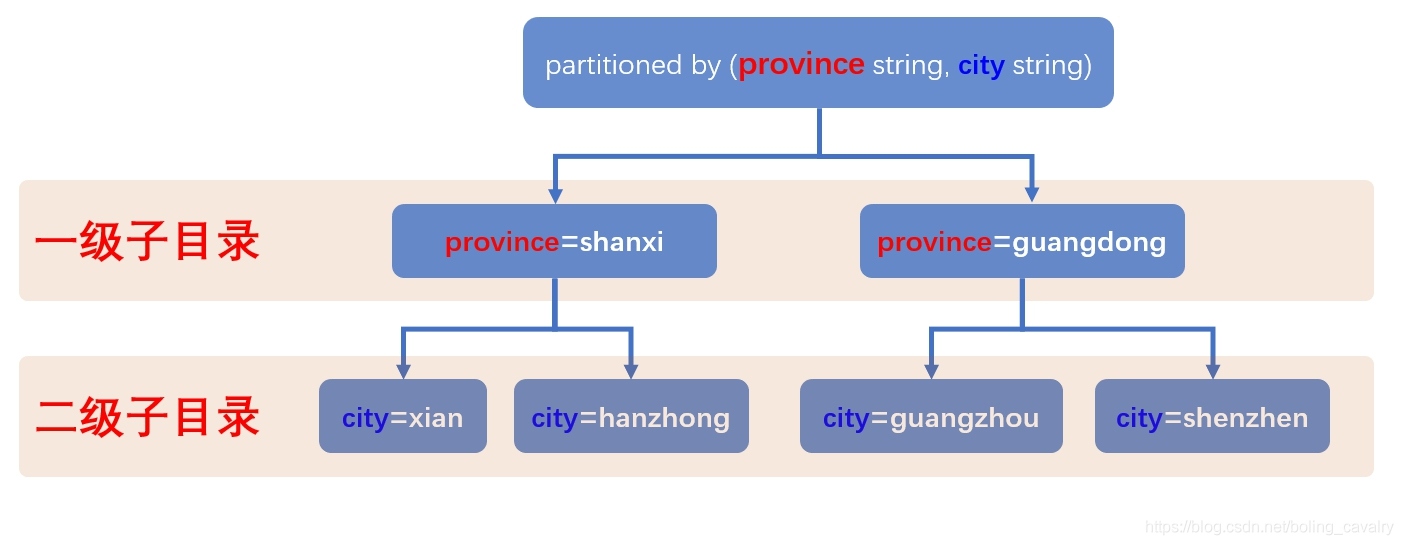
- 上述建表陳述句中,磁區欄位province寫在了city前面,這就意味著第一級子目錄是province值,每個province子目錄,再按照city值建立二級子目錄,圖示如下:
3. 第一次匯入,province='shanxi', city='xian':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='shanxi', city='xian');
- 第二次匯入,province='shanxi', city='xian':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='shanxi', city='hanzhong');
- 第三次匯入,province='guangdong', city='guangzhou':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='guangdong', city='guangzhou');
- 第四次匯入,province='guangdong', city='shenzhen':
load data
local inpath '/home/hadoop/temp/202010/25/009.txt'
into table t10
partition(province='guangdong', city='shenzhen');
- 全部資料如下:
hive> select * from t10;
OK
t10.name t10.age t10.province t10.city
tom 11 guangdong guangzhou
jerry 12 guangdong guangzhou
tom 11 guangdong shenzhen
jerry 12 guangdong shenzhen
tom 11 shanxi hanzhong
jerry 12 shanxi hanzhong
tom 11 shanxi xian
jerry 12 shanxi xian
Time taken: 0.129 seconds, Fetched: 8 row(s)
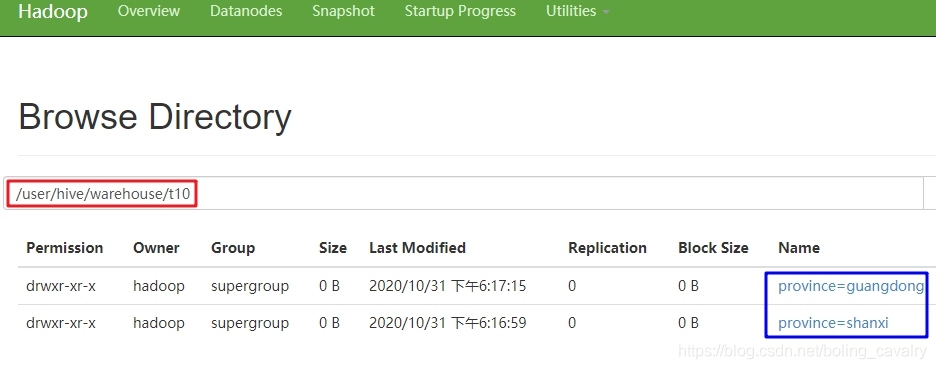
- 查看hdfs檔案夾,如下圖,一級目錄是province欄位的值:
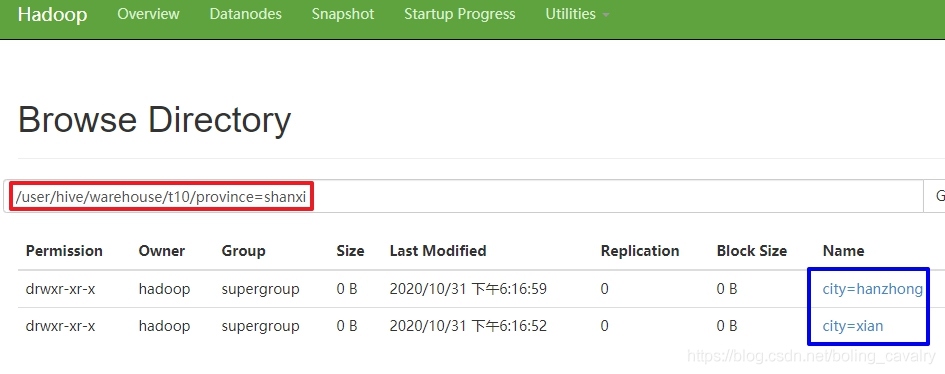
- 打開一個一級目錄,如下圖,可見二級目錄是city的值:
10. 查看資料:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t10/province=shanxi/city=hanzhong/009.txt
tom,11
jerry,12
- 以上就是靜態磁區的基本操作,可見靜態磁區有個不便之處:新增資料的時候要針對每一個磁區單獨使用load命令去操作,這時候使用動態磁區來解決這個麻煩;
動態磁區
- 動態磁區的特點就是不用指定磁區目錄,由hive自己選擇;
- 執行以下命令開啟動態磁區功能:
set hive.exec.dynamic.partition=true
- 名為hive.exec.dynamic.partition.mode的屬性,默認值是strict,意思是不允許磁區列全部是動態的,這里改為nostrict以取消此禁制,允許全部磁區都是動態磁區:
set hive.exec.dynamic.partition.mode=nostrict;
- 建一個外部表,名為t11,只有四個欄位:
create external table t11 (name string, age int, province string, city string)
row format delimited
fields terminated by ','
location '/data/external_t11';
- 創建名為011.txt的檔案,內容如下:
tom,11,guangdong,guangzhou
jerry,12,guangdong,shenzhen
tony,13,shanxi,xian
john,14,shanxi,hanzhong
- 將011.txt中的四條記錄載入表t11:
load data
local inpath '/home/hadoop/temp/202010/25/011.txt'
into table t11;
- 接下來要,先創建動態磁區表t12,再把t11表的資料添加到t12中;
- t12的建表陳述句如下,按照province+city磁區:
create table t12 (name string, age int)
partitioned by (province string, city string)
row format delimited
fields terminated by ',';
- 執行以下操作,即可將t11的所有資料寫入動態磁區表t12,注意,要用overwrite:
insert overwrite table t12
partition(province, city)
select name, age, province, city from t11;
- 通過hdfs查看檔案夾,可見一級和二級子目錄都符合預期:
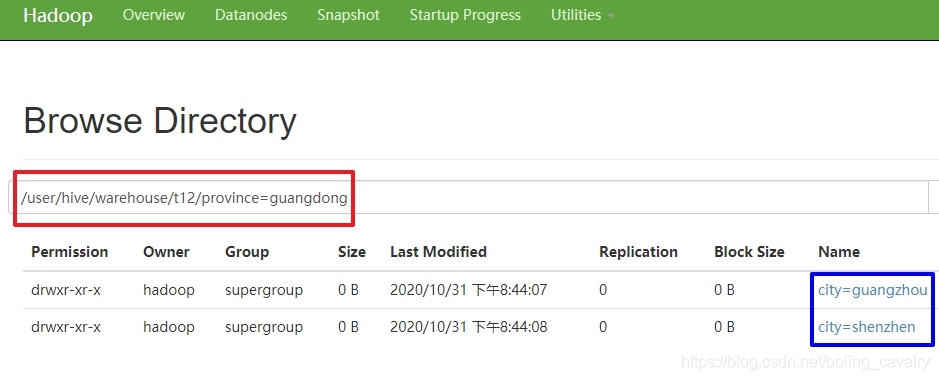
11. 最后檢查二級子目錄下的資料檔案,可以看到該磁區下的記錄:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t12/province=guangdong/city=guangzhou/000000_0
tom,11
至此,磁區表的學習就完成了,希望能給您一些參考;
你不孤單,欣宸原創一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 資料庫+中間件系列
- DevOps系列
歡迎關注公眾號:程式員欣宸
微信搜索「程式員欣宸」,我是欣宸,期待與您一同暢游Java世界...
https://github.com/zq2599/blog_demos
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288828.html
標籤:Java
上一篇:Java方法的多載