作者:mageek
來源:http://mageek.cn/archives/88/
前言
分布式中一致性是非常重要的,分為弱一致性和強一致性,
現在主流的一致性協議一般都選擇的是弱一致性的特殊版本:最終一致性,下面就從分布式系統的基本原則講起,再整理一些遵循這些原則的協議或者機制,爭取通俗易懂,
但是要真正實施起來把這些協議落地,可不是一篇文章能說清楚的,有太多的細節,要自己去看論文吶(順著維基百科找就行了),
基本原則與理論
CAP(Consistency一致性,Availability可用性,Partition tolerance磁區容錯性)理論是當前分布式系統公認的理論,亦即一個分布式系統不可能同時滿足這三個特性,只能三求其二,對于分布式系統,P是基本要求,如果沒有P就不是分布式系統了,所以一般都是在滿足P的情況下,在C和A之間尋求平衡,
ACID(Atomicity原子性,Consistency一致性,Isolation隔離性,Durability持久性)是事務的特點,具有強一致性,一般用于單機事務,分布式事務若采用這個原則會喪失一定的可用性,屬于CP系統,
BASE(Basically Availabe基本可用,Soft state軟狀態,Eventually consistency最終一致性)理論是對大規模的互聯網分布式系統實踐的總結,用弱一致性來換取可用性,不同于ACID,屬于AP系統,
2PC
2 Phase Commit,兩階段提交,系統有兩個角色協調者和參與者,事務提交程序分為兩階段:
-
提交事務請求(投票階段)
-
- 協調者向參與者發送事務內容,詢問是否可以執行事務提交操作,等待回應
- 參與者執行事務操作,并將undo和redo日志記錄
- 參與者回復協調者,執行成功則回Yes否則No
-
執行事務提交(執行階段)
-
- 如果都是參與者都回復Yes,則協調者向參與者發送提交請求,否則發送回滾請求
- 參與者根據協調者的請求執行事務提交或回滾,并向協調者發送Ack訊息
- 協調者收到所有的Ack訊息過后判斷事務的完成或者中斷
該協議可以視為強一致的演算法,通常用來保證多份資料操作的原子性,也可以實作資料副本之間的一致性,實作簡單,但是缺點也很多,比如單點故障(協調者掛了整個系統就沒法對外服務,任一節點掛了事務就沒法執行,沒有容錯機制)、阻塞(兩個階段都涉及同步等待阻塞,極大降低了吞吐量)、資料不一致(參與者回復Yes/No后如果因為網路原因沒有收到提交/中斷請求,此時它就不知道該如何操作了,導致集群資料不一致)……
2PC有些優化手段:超時判斷機制,比如協調者發出事務請求后等待所有參與者反饋,若超過時間沒有搜集完畢所有回復則可以多播訊息取消本次事務;互詢機制,參與者P回復yes后,等待協調者發起最終的commitabort,如果沒收到那么可以詢問其他參與者Q來決定自身下一步操作,避免一直阻塞(如果其他參與者全都是等待狀態,那么P也只能一直阻塞了),所以2PC的阻塞問題是沒辦法徹底解決的,
當然,如果網路環境較好,該協議一般還是能很好的作業的,2PC廣泛應用于關系資料庫的分布式事務處理,如mysql的內部與外部XA都是基于2PC的,一般想要把多個操作打包未原子操作也可以用2PC,
3PC
3 Phase Commit,三階段提交,是二階段提交的改進,系統也有兩個角色協調者和參與者,事務提交程序分為三階段:
-
事務詢問(canCommit)
-
- 協調者向參與者發送一個包含事務內容的詢問請求,詢問是否可以執行事務并等待
- 參與者根據自己狀態判斷并回復yes、no
-
執行事務預提交(preCommit)
-
- 若協調者收到全是yes,就發送preCommit請求否則發布abort請求
- 參與者若收到preCommit則執行事務操作并記錄undo和redo然后發送Ack,若收到abort或者超時則中斷事務
-
執行事務提交(doCommit)
-
- 協調者收到所有的Ack則發送doCommit請求,若收到了No或者超時則發送abort請求
- 參與者收到doCommit就執行提交并發送ACk,否則執行回滾并發送Ack
- 協調者收到Ack判斷是完成事務還是中斷事務

三階段相對于兩階段的改善就是把準備階段一分為二,亦即多了一個canCommit階段,按我理解這樣就類似于TCP的三步握手,多了一次確認,增大了事務執行成功的概率,而且3PC的協調者即使出了故障,參與者也能繼續執行事務所以解決了2PC的阻塞問題,但是也可能因此導致集群資料不一致,
Paxos
上面兩個協議的協調者都需要人為設定而無法自動生成,是不完整的分布式協議,而Paxos 就是一個真正的完整的分布式演算法,系統一共有幾個角色:Proposer(提出提案)、Acceptor(參與決策)、Learner(不參與提案,只負責接收已確定的提案,一般用于提高集群對外提供讀服務的能力),實踐中一個節點可以同時充當多個角色,提案選定程序也大概分為2階段:
-
Prepare階段
-
- Proposer選擇一個提案編號M,向Acceptor某個超過半數的子集成員發送該編號的Prepare請求
- Acceptor收到M編號的請求時,若M大于該Acceptor已經回應的所有Prepare請求的編號中的最大編號N,那么他就將N反饋給Proposer,同時承諾不會再批準任何編號小于M的提案
-
Accept階段
-
- 如果Proposer收到超過半數的Acceptor對于M的prepare請求的回應,就發送一個針對[M,V]提案的Accept請求給Acceptor,其中V是收到的回應編號中編號的最大的提案值,如果回應中不包括任何提案值,那么他就是任意值
- Acceptor收到這個針對[M,V]的Accept請求只要改Acceptor尚未對大于M編號的提案做出過回應,他就通過這個提案
-
Learn階段(本階段不屬于選定提案的程序)
-
- Proposer將通過的提案同步到所有的Learner

Paxos協議的容錯性很好,只要有超過半數的節點可用,整個集群就可以自己進行Leader選舉,也可以對外服務,通常用來保證一份資料的多個副本之間的一致性,適用于構建一個分布式的一致性狀態機,
Google的分布式鎖服務Chubby就是用了Paxos協議,而開源的ZooKeeper使用的是Paxos的變種ZAB協議,
Raft
Raft協議對標Paxos,容錯性和性能都是一致的,但是Raft比Paxos更易理解和實施,系統分為幾種角色:Leader(發出提案)、Follower(參與決策)、Candidate(Leader選舉中的臨時角色),
剛開始所有節點都是Follower狀態,然后進行Leader選舉,成功后Leader接受所有客戶端的請求,然后把日志entry發送給所有Follower,當收到過半的節點的回復(而不是全部節點)時就給客戶端回傳成功并把commitIndex設定為該entry的index,所以是滿足最終一致性的,
Leader同時還會周期性地發送心跳給所有的Follower(會通過心跳同步提交的序號commitIndex),Follower收到后就保持Follower狀態(并應用commitIndex及其之前對應的日志entry),如果Follower等待心跳超時了,則開始新的Leader選舉:首先把當前term計數加1,自己成為Candidate,然后給自己投票并向其它結點發投票請求,直到以下三種情況:
- 它贏得選舉;
- 另一個節點成為Leader;
- 一段時間沒有節點成為Leader,
在選舉期間,Candidate可能收到來自其它自稱為Leader的寫請求,如果該Leader的term不小于Candidate的當前term,那么Candidate承認它是一個合法的Leader并回到Follower狀態,否則拒絕請求,
如果出現兩個Candidate得票一樣多,則它們都無法獲取超過半數投票,這種情況會持續到超時,然后進行新一輪的選舉,這時同時的概率就很低了,那么首先發出投票請求的的Candidate就會得到大多數同意,成為Leader,
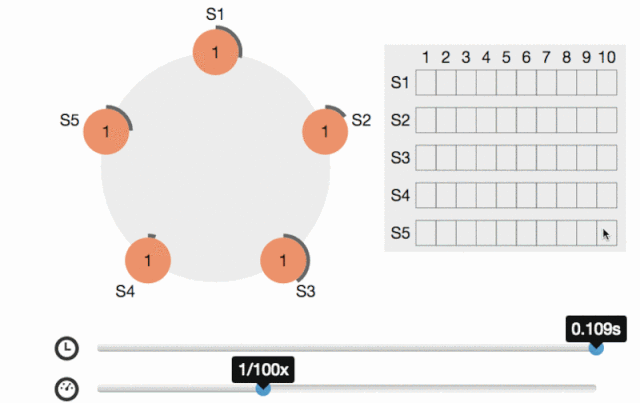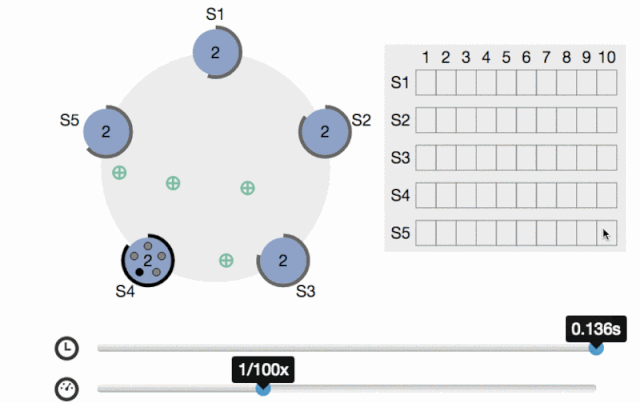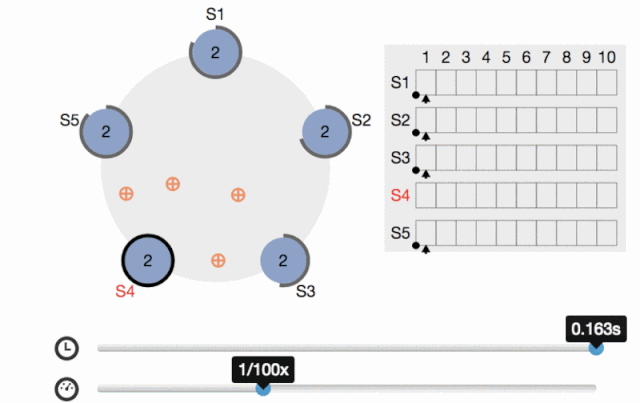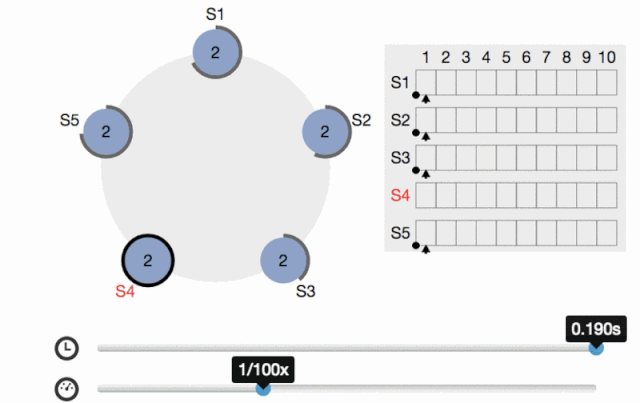
在Raft協議出來之前,Paxos是分布式領域的事實標準,但是Raft的出現打破了這一個現狀(raft作者也是這么想的,請看論文),Raft協議把Leader選舉、日志復制、安全性等功能分離并模塊化,使其更易理解和工程實作,將來發展怎樣我們拭目以待(挺看好),
Raft協議目前被用于 cockrouchDB,TiKV等專案中,據我聽的一些報告來看,一些大廠自己造的分布式資料庫也在使用Raft協議,
Gossip
Gossip協議與上述所有協議最大的區別就是它是去中心化的,上面所有的協議都有一個類似于Leader的角色來統籌安排事務的回應、提交與中斷,但是Gossip協議中就沒有Leader,每個節點都是平等的,

每個節點存放了一個key,value,version構成的串列,每隔一定的時間,節點都會主動挑選一個在線節點進行上圖的程序(不在線的也會挑一個嘗試),兩個節點各自修改自己較為落后的資料,最終資料達成一致并且都較新,節點加入或退出都很容易,
去中心化的Gossip看起來很美好:沒有單點故障,看似無上限的對外服務能力……本來隨著Cassandra火了一把,但是現在Cassandra也被拋棄了,去中心化的架構貌似難以真正應用起來,歸根到底我覺得還是因為去中心化本身管理太復雜,節點之間溝通成本高,最終一致等待時間較長……往更高處看,一個企業(甚至整個社會)不也是需要中心化的領導(或者制度)來管理嗎,如果沒有領導(或者制度)管理,大家就是一盤散沙,難成大事啊,
事實上現代互聯網架構只要把單點做得足夠強大,再加上若干個強一致的熱備,一般問題都不大,
NWR 機制
首先看看這三個字母在分布式系統中的含義:
N:有多少份資料副本;
W:一次成功的寫操作至少有w份資料寫入成功;
R:一次成功的讀操作至少有R份資料讀取成功,
NWR值的不同組合會產生不同的一致性效果,當W+R>N的時候,讀取操作和寫入操作成功的資料一定會有交集,這樣就可以保證一定能夠讀取到最新版本的更新資料,資料的強一致性得到了保證,如果R+W<=N,則無法保證資料的強一致性,因為成功寫和成功讀集合可能不存在交集,這樣讀操作無法讀取到最新的更新數值,也就無法保證資料的強一致性,
版本的新舊需要版本控制演算法來判別,比如向量時鐘,
當然R或者W不能太大,因為越大需要操作的副本越多,耗時越長,
Quorum 機制
Quorom機制,是一種分布式系統中常用的,用來保證資料冗余和最終一致性的投票演算法,主要思想來源于鴿巢原理,在有冗余資料的分布式存盤系統當中,冗余資料物件會在不同的機器之間存放多份拷貝,但是同一時刻一個資料物件的多份拷貝只能用于讀或者用于寫,
分布式系統中的每一份資料拷貝物件都被賦予一票,每一個操作必須要獲得最小的讀票數(Vr)或者最小的寫票數(Vw)才能讀或者寫,如果一個系統有V票(意味著一個資料物件有V份冗余拷貝),那么這最小讀寫票必須滿足:
- Vr + Vw > V
- Vw > V/2
第一條規則保證了一個資料不會被同時讀寫,當一個寫操作請求過來的時候,它必須要獲得Vw個冗余拷貝的許可,而剩下的數量是V-Vw 不夠Vr,因此不能再有讀請求過來了,同理,當讀請求已經獲得了Vr個冗余拷貝的許可時,寫請求就無法獲得許可了,
第二條規則保證了資料的串行化修改,一份資料的冗余拷貝不可能同時被兩個寫請求修改,
Quorum機制其實就是NWR機制,
Lease機制
master給各個slave分配不同的資料,每個節點的資料都具有有效時間比如1小時,在lease時間內,客戶端可以直接向slave請求資料,如果超過時間客戶端就去master請求資料,一般而言,slave可以定時主動向master要求續租并更新資料,master在資料發生變化時也可以主動通知slave,不同方式的選擇也在于可用性與一致性之間進行權衡,
租約機制也可以解決主備之間網路不通導致的雙主腦裂問題,亦即:主備之間本來心跳連線的,但是突然之間網路不通或者暫停又恢復了或者太繁忙無法回復,這時備機開始接管服務,但是主機依然存活能對外服務,這是就發生爭奪與磁區,但是引入lease的話,老主機頒發給具體server的lease必然較舊,請求就失效了,老主機自動退出對外服務,備機完全接管服務,
參考:
https://en.wikipedia.org/wiki/Two-phase_commit_protocol
https://en.wikipedia.org/wiki/Three-phase_commit_protocol
https://en.wikipedia.org/wiki/Paxos_(computer_science)
https://raft.github.io/
https://en.wikipedia.org/wiki/Raft_(computer_science)
https://lamport.azurewebsites.net/pubs/paxos-simple.pdf
http://www.infoq.com/cn/articles/raft-paper
https://en.wikipedia.org/wiki/Gossip_protocol
https://book.douban.com/subject/26292004/
https://book.douban.com/subject/4848587/
https://book.douban.com/subject/25984046/
http://m635674608.iteye.com/blog/2343038
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.阿里 Mock 工具正式開源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式發布,全新顛覆性版本!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288911.html
標籤:其他
上一篇:Python 使用rsa類別庫基于RSA256演算法生成JWT
下一篇:Python基礎之GUI編程