Redis集群搭建
介紹
- 使用6.2.4 搭建 主從、哨兵、集群模式,
準備
-
準備三臺電腦
IP地址 主機名稱 172.16.241.2 linux1 172.16.241.3 linux2 172.16.241.4 linux3 172.16.241.5 linux4 172.16.241.6 linux5 172.16.241.7 linux6 -
機器配置
-
linux 系統

-
關閉防火墻
systemctl stop firewalld.service// 關閉systemctl disable firewalld.service// 禁止開啟自動systemctl status firewalld.service// 查看防火墻狀態 -
修改 linux配置
net.core.somaxconn = 2048
vm.overcommit_memory=1
-
-
下載redis 包,解壓并make(如果make指令缺失,執行
yum install -y gcc automake autoconf libtool make)$ wget https://download.redis.io/releases/redis-6.2.4.tar.gz $ tar xzf redis-6.2.4.tar.gz $ cd redis-6.2.4 $ make -
檔案目錄目錄如下:

主從模式
-
修改三臺機器的redis.conf
-
master(linux1)
bind * //允許其他服務器訪問 -
其他兩個Salve(linux2, linux3)
slaveof linux1 6379 // 配置兩個slave屬于哪個master
-
-
啟動
啟動master,然后啟動兩個salve
進入src目錄執行
./redis-server ../redis.conf -
驗證主從模式是否搭建完畢
訪問其中任意一個redis-cli:
./redis-cli然后輸入./redis-server ../redis.conf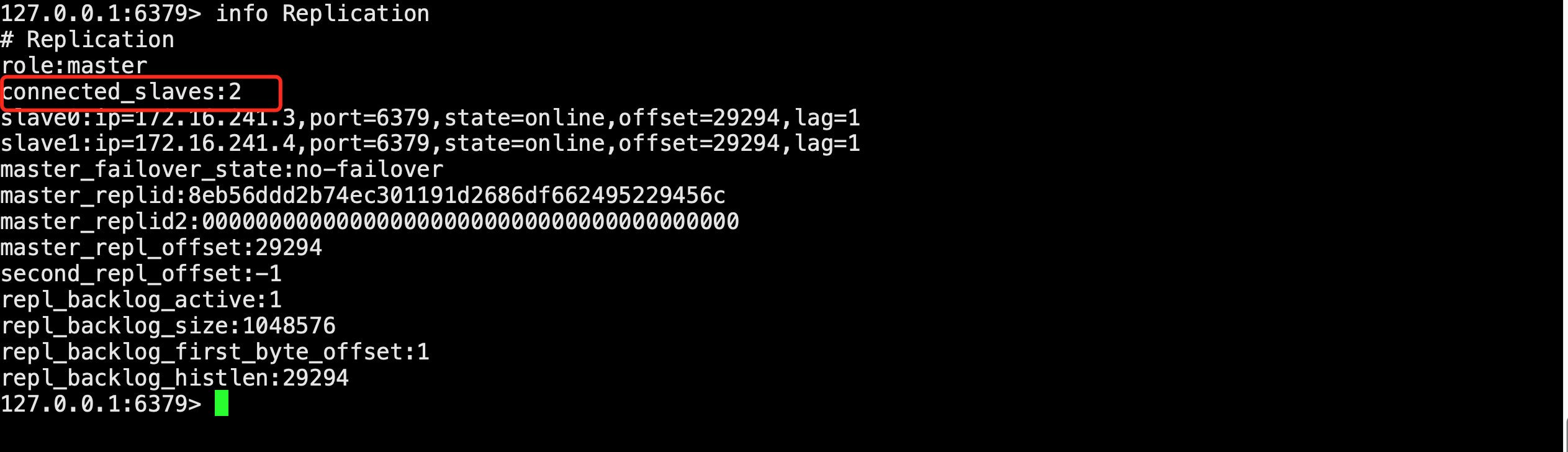
兩個salve已經存在,
-
Java呼叫
-
pom引入
-
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.6.1</version> </dependency> -
核心代碼
// 主從模式 // 1. 向master寫 Jedis jedis = new Jedis("linux1", 6379); jedis.set("a", "accccc"); jedis.close(); // 2.從slave讀取 Jedis readJedis = new Jedis("linux2", 6379); String a = readJedis.get("a"); System.out.println("獲取從master中寫入的資料a = " + a); readJedis.close();
-
Sentinel哨兵模式
-
按照主從模式的配置,啟動三個節點
-
修改sentinel.conf, 監控master主機
sentinel monitor mymaster 172.16.241.2 6379 2
-
啟動master(linux1)的sentinel
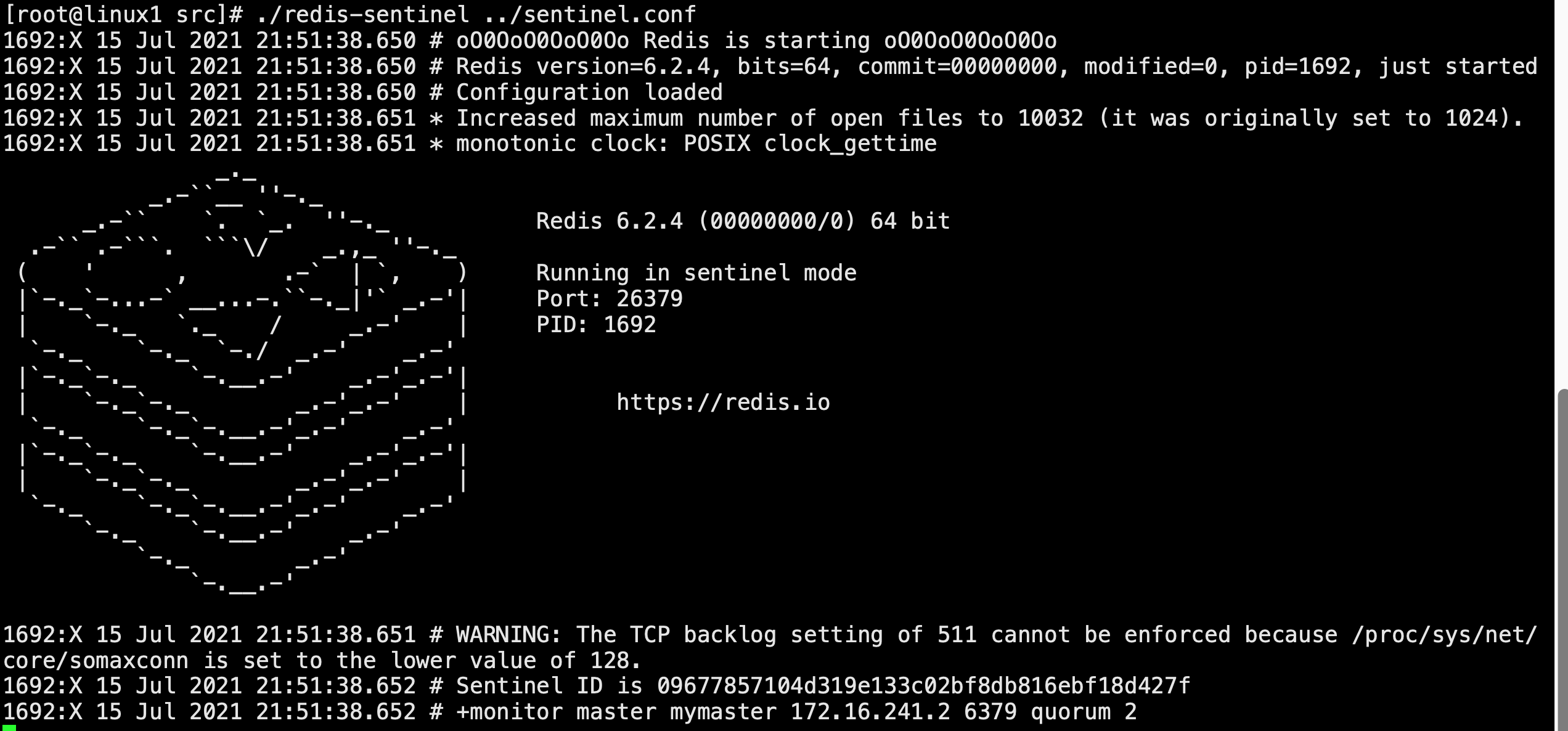
-
啟動slave1, slave2, 查看master日志
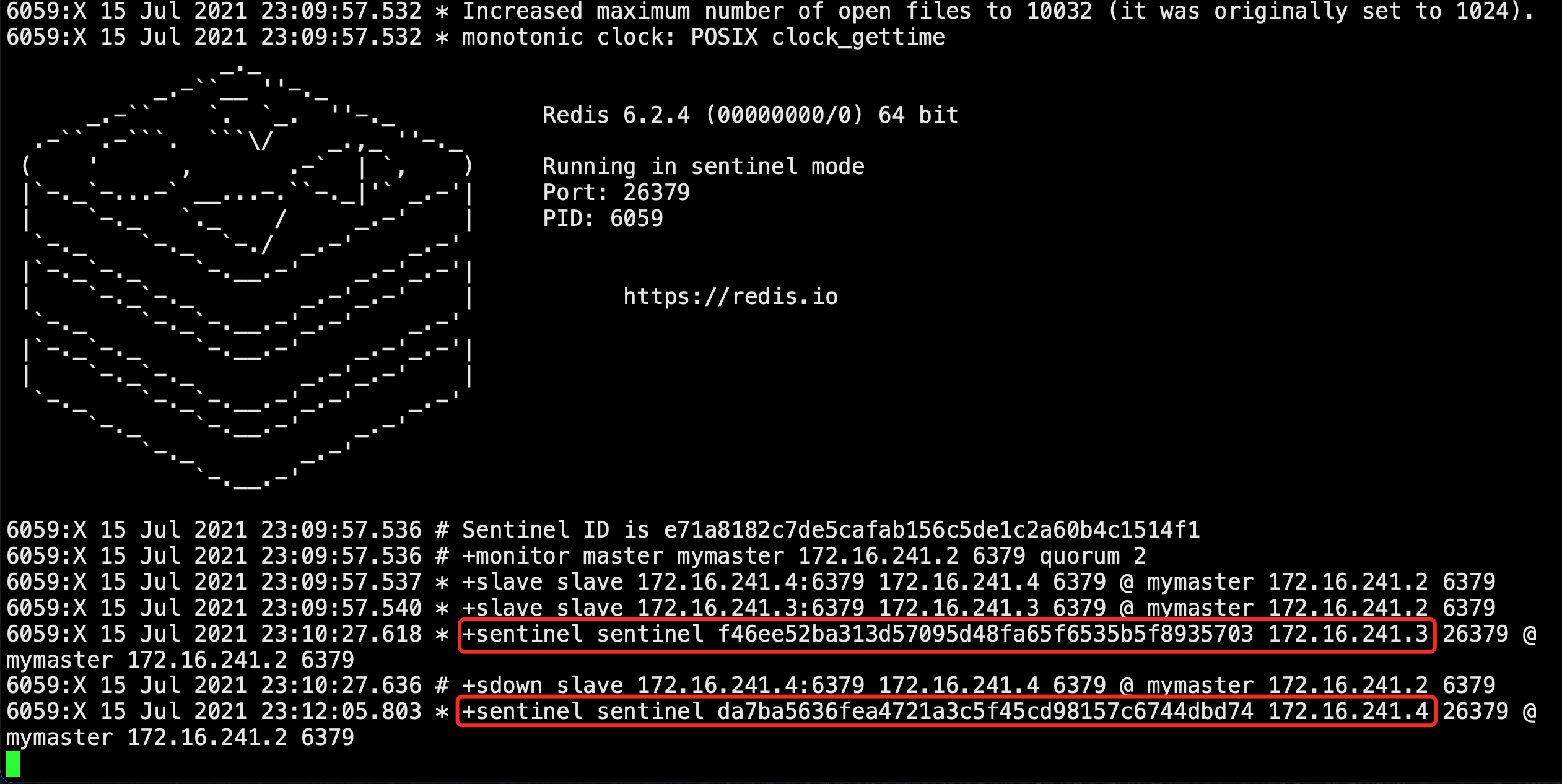
-
測驗
-
停止slave1,查看master的日志
-

-
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); jedisPoolConfig.setMaxIdle(5); jedisPoolConfig.setMaxTotal(10); jedisPoolConfig.setMinIdle(5); Set<String> sentinels = new HashSet<>(); sentinels.add("linux1:26379"); sentinels.add("linux2:26379"); sentinels.add("linux3:26379"); JedisSentinelPool jedisSentinelPool = new JedisSentinelPool("mymaster", sentinels, jedisPoolConfig); Jedis pj = jedisSentinelPool.getResource(); pj.set("a", "sentinel"); String sentinelStored = pj.get("a"); System.out.println("使用sentinel模式存盤的a=" + sentinelStored); -
重啟master,sentinel會選擇其中一個slave升級為master,原master重啟后,會變為slave不會重新升級為master,
-
Cluster 集群
-
跟著官網教程(https://redis.io/topics/cluster-tutorial)
-
配置說明
- cluster-enabled
<yes/no>:啟用集群支持 - cluster-config-file
<filename>:該檔案無需用戶編輯,是Cluster集群節點變化后時自動持久化集群配置 - cluster-node-timeout
<milliseconds>:Redis集群節點不可用的最長時間,如果主節點在指定的時間內無法訪問,那么由從節點進行故障轉移 - luster-slave-validity-factor
<factor>:如果設定為0,那么從節點始終認為自己有效,將始終嘗試對主節點進行故障轉移 - cluster-migration-barrier
<count>:一個主節點的將保持連接的最小從節點數量,以便另一個從節點遷移到不再被任何從站覆寫的主節點 - cluster-require-full-coverage
<yes/no>:如果將其設定為 yes,默認情況下,如果任何節點未覆寫一定百分比的密鑰空間,則集群將停止接受寫入,如果該選項設定為 no,即使只能處理有關密鑰子集的請求,集群仍將提供查詢服務, - luster-allow-reads-when-down
<yes/no>:如果設定為 no,默認情況下,當集群被標記為失敗時,Redis 集群中的節點將停止服務所有流量,或者當節點無法訪問時達到法定人數或未達到完全覆寫時,這可以防止從不知道集群中的變化的節點讀取可能不一致的資料,可以將此選項設定為 yes 以允許在失敗狀態期間從節點讀取,這對于希望優先考慮讀取可用性但仍希望防止不一致寫入的應用程式非常有用,它也可以用于使用只有一個或兩個分片的 Redis Cluster 時,因為它允許節點在主節點發生故障但無法自動故障轉移時繼續提供寫入服務,
- cluster-enabled
-
配置和使用Redis集群(官網教程是在一個機器上啟動多個服務的偽集群,本文使用之前準備的三臺虛擬機)
-
在三臺節點上,解壓之前的壓縮包為redis-cluster, 并執行
make指令, -
三臺機器都配置redis.conf(因為我之前在這三臺機器上啟動了redis,我又不想改埠號,所以講之前的redis和sentinel都關閉)
最小配置:
cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes -
分別啟動redis
-
使用redis-cli啟動集群:
./redis-cli --cluster create 172.16.241.2:6379 172.16.241.3:6379 172.16.241.4:6379 172.16.241.5:6379 172.16.241.6:6379 172.16.241.7:6379 --cluster-replicas 1日志資訊如下:
Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.16.241.6:6379 to 172.16.241.2:6379
Adding replica 172.16.241.7:6379 to 172.16.241.3:6379
Adding replica 172.16.241.5:6379 to 172.16.241.4:6379
M: b31d4478d5b521e289491a89da26976a85b1f3c9 172.16.241.2:6379
slots:[0-5460] (5461 slots) master
M: 2cdbe3aba12a65444a00a2170390d1dbf108a865 172.16.241.3:6379
slots:[5461-10922] (5462 slots) master
M: 31ac1ad83587697634bae2a363dfdcd58b15d63e 172.16.241.4:6379
slots:[10923-16383] (5461 slots) master
S: da22af2f724033b2e7cec8fd49d4e80aae4712f3 172.16.241.5:6379
replicates 31ac1ad83587697634bae2a363dfdcd58b15d63e
S: 732ce03d83245d0a0a9b002bbfa8bf959aeb7720 172.16.241.6:6379
replicates b31d4478d5b521e289491a89da26976a85b1f3c9
S: 546e7ed39dc7427bed062e5529e5831c9a35bdcb 172.16.241.7:6379
replicates 2cdbe3aba12a65444a00a2170390d1dbf108a865
Can I set the above configuration? (type 'yes' to accept): yes
Nodes configuration updated
Assign a different config epoch to each node
Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
..
Performing Cluster Check (using node 172.16.241.2:6379)
M: b31d4478d5b521e289491a89da26976a85b1f3c9 172.16.241.2:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 2cdbe3aba12a65444a00a2170390d1dbf108a865 172.16.241.3:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 546e7ed39dc7427bed062e5529e5831c9a35bdcb 172.16.241.7:6379
slots: (0 slots) slave
replicates 2cdbe3aba12a65444a00a2170390d1dbf108a865
S: 732ce03d83245d0a0a9b002bbfa8bf959aeb7720 172.16.241.6:6379
slots: (0 slots) slave
replicates b31d4478d5b521e289491a89da26976a85b1f3c9
S: da22af2f724033b2e7cec8fd49d4e80aae4712f3 172.16.241.5:6379
slots: (0 slots) slave
replicates 31ac1ad83587697634bae2a363dfdcd58b15d63e
M: 31ac1ad83587697634bae2a363dfdcd58b15d63e 172.16.241.4:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
Check for open slots...
Check slots coverage...
[OK] All 16384 slots covered.截圖:

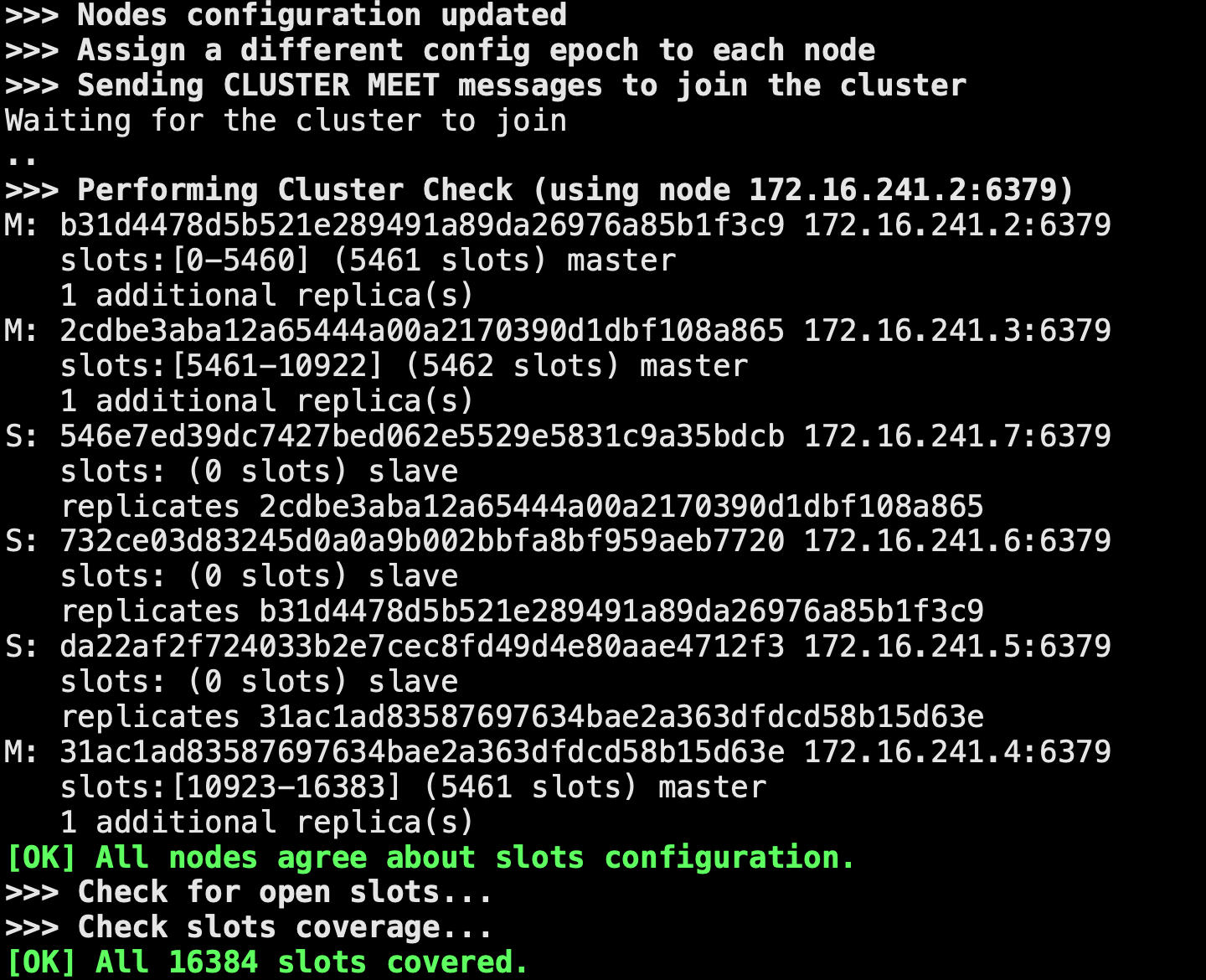
看到上面的資訊,即代表集群搭建成功,
-
查看集群節點資訊

綠色:master幾點,黃色代表slave節點
-
查看集群資訊
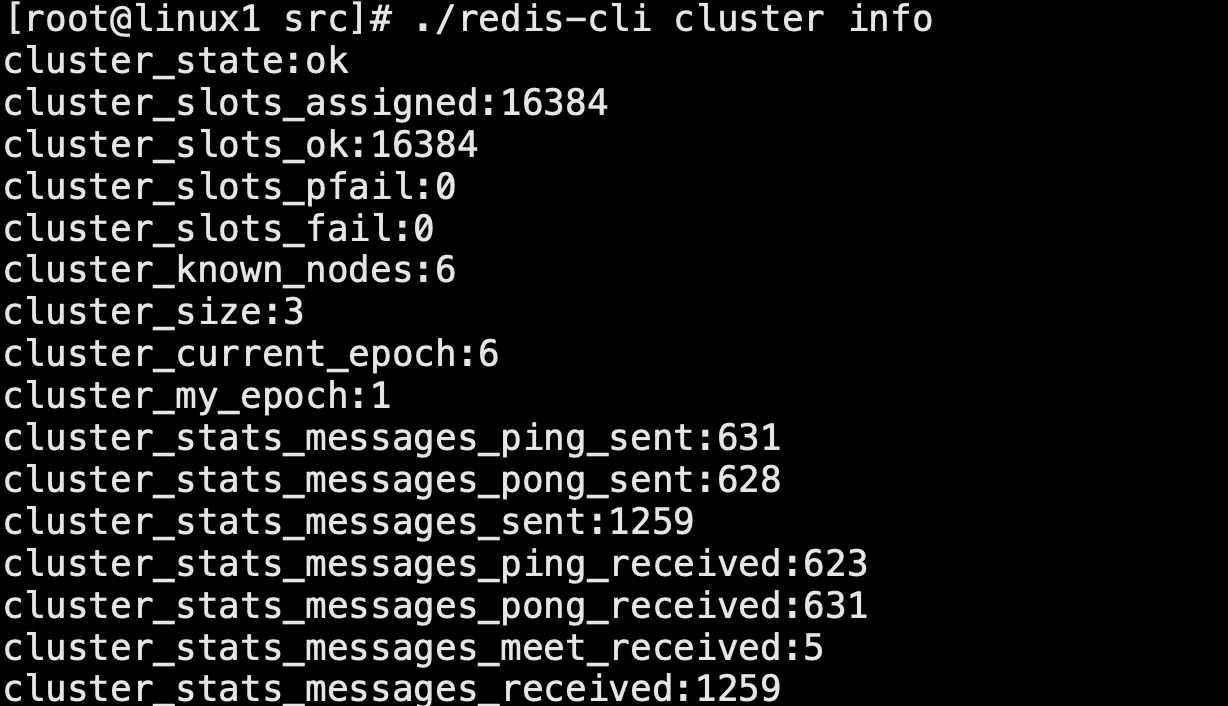
-
Redis-cli 演示set操作
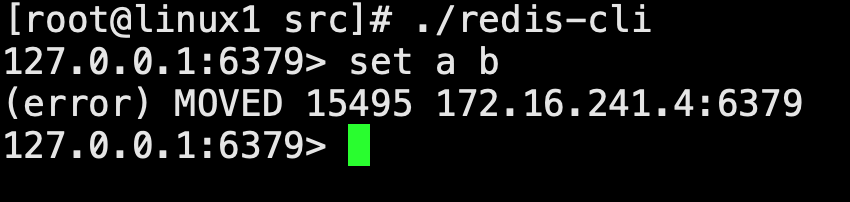
這是什么意思? 原因是a的不會放到該節點上,使用
cluster keyslot a,結果是16475,通過上面創建集群啟動日志中我們看到,16475會放到linux3節點上,那么去linux3節點連接redis-cli,./redis-cli執行set a b,發現沒有問題,如圖: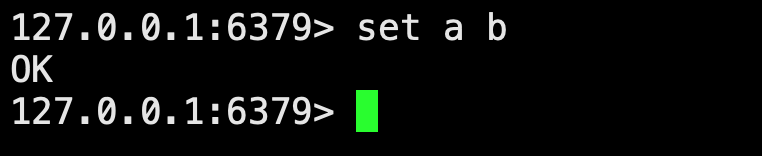
那么問題來了,如何連接的時候讓其自動去查找槽位呢?
./redist-cli -c即可,打開linux1,進入src目錄執行./redis-cli -c,輸入set a b執行結果如下:
可以看到redis自動重定向到指定槽位的節點,
-
java代碼示例
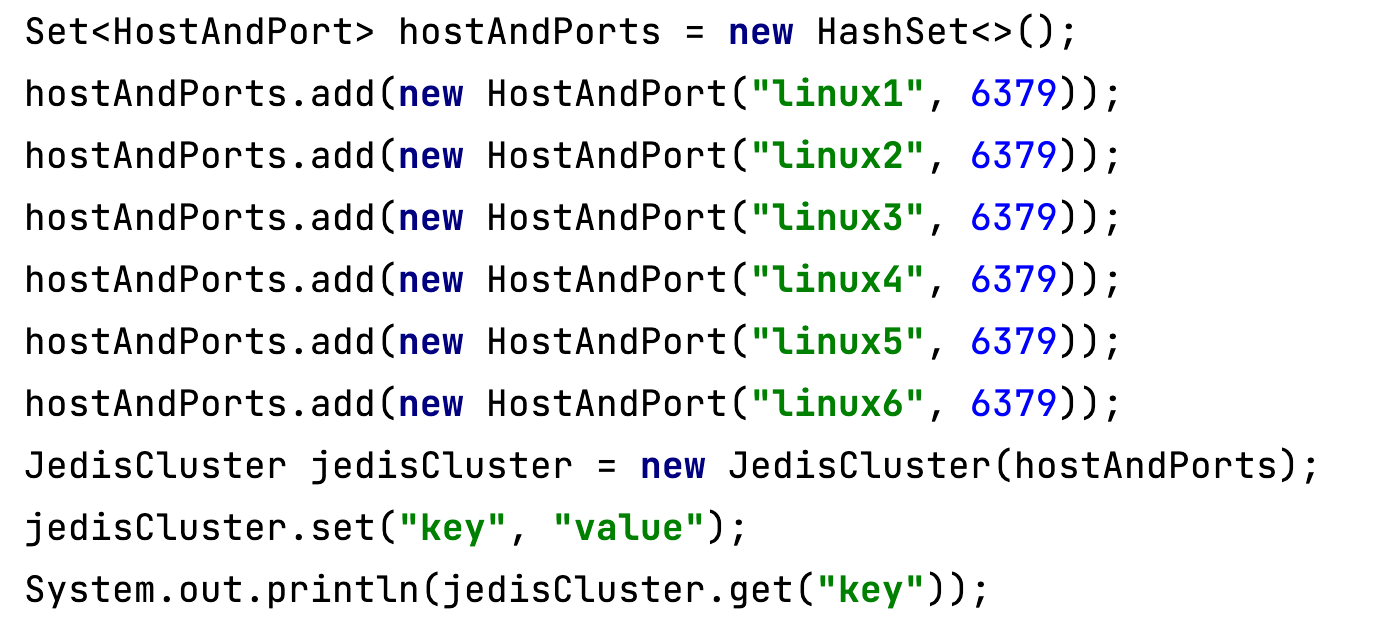
-
使用create-cluster腳本創建集群
如果不想通過如上所述手動配置和執行單個實體來創建 Redis 集群,則有一個更簡單的方法,使用
utils/create-cluster這是個shell腳本,用于創建偽集群, -
-
幾種集群對比
-
主從模式:
優點:Master能自動將資料同步到slave,可以進行讀寫分離,分擔master的壓力
? master、slave之間的同步是以非阻塞的方式進行的,同步期間,客戶端仍然可以提交查詢或更新請求
缺點:不具備自動容錯與恢復功能,master和slave的宕機都可能導致客戶端請求失敗,需要等待機器重啟或手動切換客戶端ip才能恢復
-
哨兵(sentinel)模式
優點:具有主從模式的所有優點,同時master掛掉可以自動切換,高可用,
缺點:因為根本是在主從模式上增加了一層sentinel,擴容困難,
-
cluster模式
優點:無中心結構,資料通過計算分布到不同的slot,分布在不同的節點上,
? 集群的節點都是平等關系,每個節點保存各自的資料以及這個集群的狀態等資訊
? 擴容方便,節點可動態添加和洗掉
? 自動故障轉移,通過投票機制選舉master
缺點: 比如客戶端實作復雜,資料異步復制(無法保證強制性)、但依然可解,不支持多資料庫等等,
- 實際生產中,引數配置、容災處理等要求都是很高的,學海無涯,變禿了也變強了,加油吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/289146.html
標籤:Java
下一篇:c++ vector用法詳解