一. 事件背景
我最近運維了一個網上的實時介面服務,最近經常出現Address already in use (Bind failed)的問題,
很明顯是一個埠系結沖突的問題,于是大概排查了一下當前系統的網路連接情況和埠使用情況,發現是有大量time_wait的連接一直占用著埠沒釋放,導致埠被占滿(最高的時候6w+個),因此HttpClient建立連接的時候會出現申請埠沖突的情況,
具體情況如下:
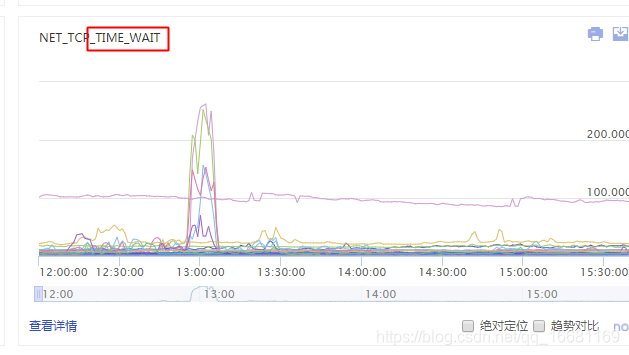
于是為了解決time_wait的問題,網上搜索了些許資料加上自己的思考,于是認為可以通過連接池來保存tcp連接,減少HttpClient在并發情況下隨機打開的埠數量,復用原來有效的連接,但是新的問題也由連接池的設定引入了,
二. 問題程序
在估算連接池最大連接數的時候,參考了業務高峰期時的請求量為1分鐘1.2w pv,介面平響為1.3s(復雜的廣告推廣效果模擬系統,在這種場景平響高是業務所需的原因),
因此qps為12000*1.3\60=260
然后通過觀察了業務日志,每次連接建立耗時1.1s左右, 再留70%+的上浮空間(怕連接數設定小出系統故障),最大連接數估計為2601.1*1.7約等于500,
為了減少對之前業務代碼最小的改動,保證優化的快速上線驗證,仍然使用的是HttpClient3.1 的MultiThreadedHttpConnectionManager,然后在線下手寫了多執行緒的測驗用例,測驗了下并發度確實能比沒用執行緒池的時候更高,然后先在我們的南京機房小流量上線驗證效果,效果也符合預期之后,就開始整個北京機房的轉全,結果轉全之后就出現了意料之外的系統例外,,,
三. 案情回顧
在當天晚上流量轉全之后,一起情況符合預期,但是到了第二天早上就看到用戶群和相關的運維群里有一些人在反饋實況頁面打不開了,這個時候我在路上,讓值班人幫忙先看了下大概的情況,定位到了耗時最高的部分正是通過連接池呼叫后端服務的部分,于是可以把這個突發問題的排查思路大致定在圍繞執行緒池的故障來考慮了,
于是等我到了公司,首先觀察了一下應用整體的情況:
- 監控平臺的業務流量表現正常,但是部分機器的網卡流量略有突增
- 介面的平響出現了明顯的上升
- 業務日志無明顯的例外,不是底層服務超時的原因,因此平響的原因肯定不是業務本身
- 發現30個機器實體竟然有9個出現了掛死的現象,其中6個北京實體,3個南京實體
四. 深入排查
由于發現了有近 1/3的實體行程崩潰,而業務流量沒變,由于RPC服務對provider的流量進行負載均衡,所以引發單臺機器的流量升高,這樣會導致后面的存活實體更容易出現崩潰問題,于是高優看了行程掛死的原因,
由于很可能是修改了HttpClient連接方式為連接池引發的問題,最容易引起變化的肯定是執行緒和CPU狀態,于是立即排查了執行緒數和CPU的狀態是否正常
1、CPU狀態
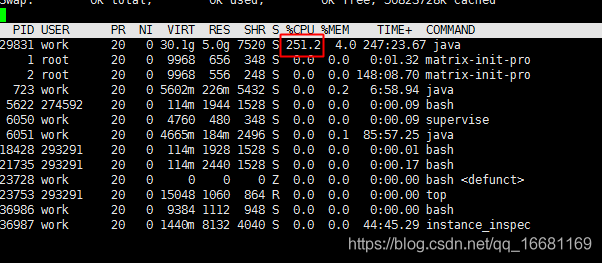
如圖可見Java行程占用cpu非常高,是平時的近10倍
2、執行緒數監控狀態:
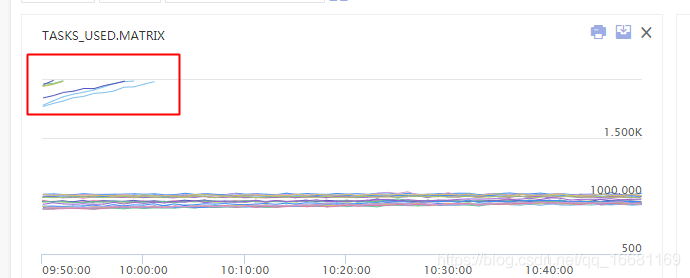
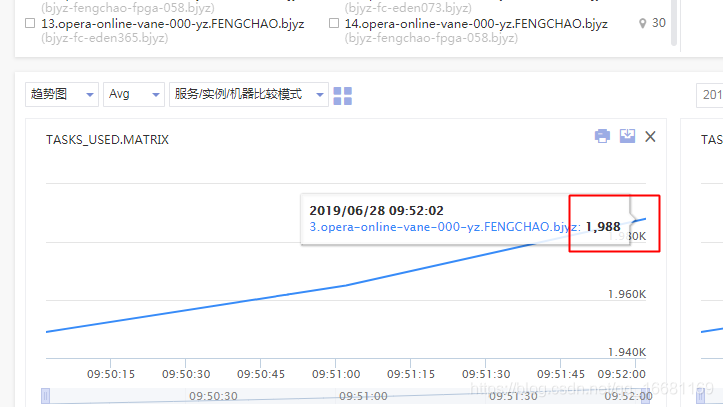
圖中可以看到多個機器大概在10點初時,出現了執行緒數大量飆升,甚至超出了虛擬化平臺對容器的2000執行緒數限制(平臺為了避免機器上的部分容器執行緒數過高,導致機器整體夯死而設定的熔斷保護),因此實體是被虛擬化平臺kill了,之前為什么之前在南京機房小流量上線的時候沒出現執行緒數超限的問題,應該和南京機房流量較少,只有北京機房流量的1/3有關,
接下來就是分析執行緒數為啥會快速積累直至超限了,這個時候我就在考慮是否是連接池設定的最大連接數有問題,限制了系統連接執行緒的并發度,為了更好的排查問題,我回滾了線上一部分的實體,于是觀察了下線上實體的 tcp連接情況和回滾之后的連接情況
回滾之前tcp連接情況:

回滾之后tcp連接情況:

發現連接執行緒的并發度果然小很多了,這個時候要再確認一下是否是連接池設定導致的原因,于是將沒回滾的機器進行jstack了,對Java行程中分配的子執行緒進行了分析,總于可以確認問題
jstack狀態:
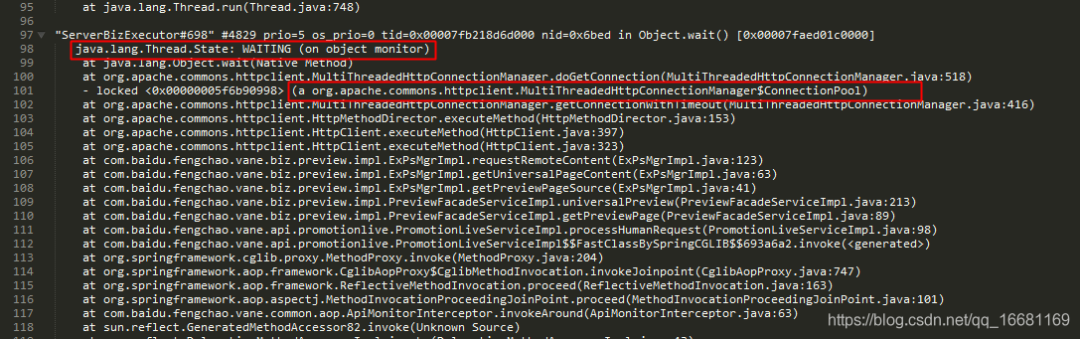
從jstack的日志中可以很容易分析出來,有大量的執行緒在等待獲取連接池里的連接而進行排隊,因此導致了執行緒堆積,因此平響上升,由于執行緒堆積越多,系統資源占用越厲害,介面平響也會因此升高,更加劇了執行緒的堆積,因此很容易出現惡性回圈而導致執行緒數超限,
那么為什么會出現并發度設定過小呢?之前已經留了70%的上浮空間來估算并發度,這里面必定有蹊蹺!
于是我對原始碼進行了解讀分析,發現了端倪:
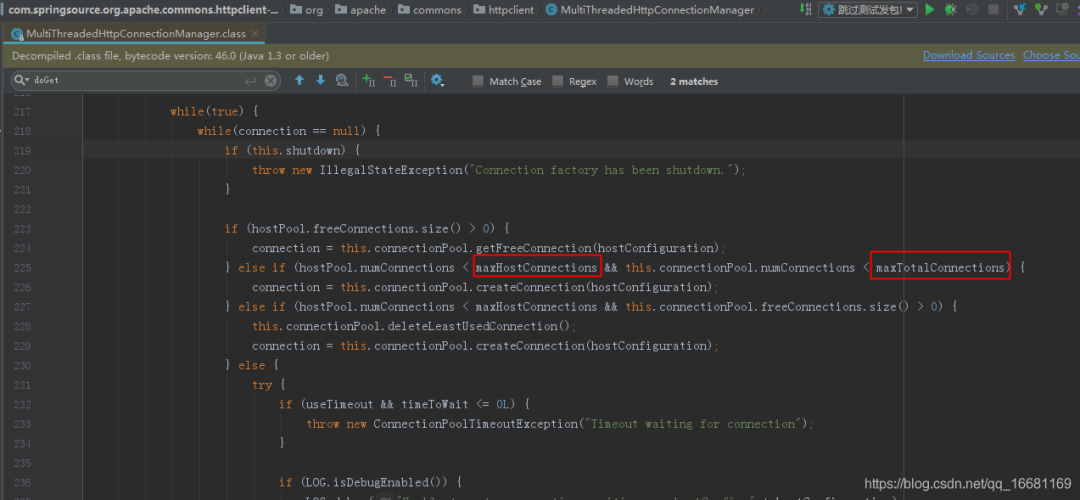
如MultiThreadedHttpConnectionManager原始碼可見,連接池在分配連接時呼叫的doGetConnection方法時,對能否獲得連接,不僅會對我設定的引數maxTotalConnections進行是否超限校驗,還會對maxHostConnections進行是否超限的校驗,
于是我立刻網上搜索了下maxHostConnections的含義:每個host路由的默認最大連接,需要通過setDefaultMaxConnectionsPerHost來設定,否則默認值是2,
所以并不是我對業務的最大連接數計算失誤,而是因為不知道要設定DefaultMaxConnectionsPerHost而導致每個請求的Host并發連接數只有2,限制了執行緒獲取連接的并發度(所以難怪剛才觀察tcp并發度的時候發現只有2個連接建立 ?? )
五. 案情總結
到此這次雪崩事件的根本問題已徹底定位,讓我們再次精煉的總結一下這個案件的全程序:
- 連接池設定錯引數,導致最大連接數為2
- 大量請求執行緒需要等待連接池釋放連接,出現排隊堆積
- 夯住的執行緒變多,介面平響升高,占用了更多的系統資源,會加劇介面的耗時增加和執行緒堆積
- 最后直至執行緒超限,實體被虛擬化平臺kill
- 部分實體掛死,導致流量轉移到其他存活實體,其他實體流量壓力變大,容易引發雪崩
關于優化方案與如何避免此類問題再次發生,我想到的方案有3個:
- 在做技術升級前,要仔細熟讀相關的官方技術檔案,最好不要遺漏任何細節
- 可以在網上找其他可靠的開源專案,看看別人的優秀的專案是怎么使用的,比如github上就可以搜索技術關鍵字,找到同樣使用了這個技術的開源專案,要注意挑選質量高的專案進行參考
- 先在線下壓測,用控制變數法對比各類設定的不同情況,這樣把所有問題在線下提前暴露了,再上線心里就有底了
以下是我設計的一個壓測方案:
a. 測驗不用連接池和使用連接池時,分析整體能承受的qps峰值和執行緒數變化
b. 對比setDefaultMaxConnectionsPerHost設定和不設定時,分析整體能承受的qps峰值和執行緒數變化
c. 對比調整setMaxTotalConnections,setDefaultMaxConnectionsPerHost 的閾值,分析整體能承受的qps峰值和執行緒數變化
d. 重點關注壓測時實體的執行緒數,cpu利用率,tcp連接數,埠使用情況,記憶體使用率
綜上所述,一次連接池引數導致的雪崩問題已經從分析到定位已全部解決,在技術改造時我們應該要謹慎對待升級的技術點,在出現問題后,要重點分析問題的特征和規律,找到共性去揪出根本原因,
原文鏈接:https://blog.csdn.net/qq_16681169/article/details/94592472
著作權宣告:本文為CSDN博主「zxcodestudy」的原創文章,遵循CC 4.0 BY-SA著作權協議,轉載請附上原文出處鏈接及本宣告,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.阿里 Mock 工具正式開源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式發布,全新顛覆性版本!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/289447.html
標籤:Java