您好,我是碼農飛哥,感謝您閱讀本文,歡迎一鍵三連哦,
本文將介紹Python函式的高級知識點:重點介紹函式引數傳遞機制以及函式式編程,
干貨滿滿,建議收藏,需要用到時常看看, 小伙伴們如有問題及需要,歡迎踴躍留言哦~ ~ ~,
文章目錄
- 前言
- Python函式引數傳遞機制
- 遞回函式
- 變數作用域
- 獲取指定作用域范圍中的變數
- 如何在函式中使用同名的全域變數
- 如何防止"遮蔽"的情況呢?
- 函式的高級用法
- 函式賦值給其他變數
- 將函式以引數的形式傳遞給其他函式
- 區域函式(內部函式)及用法
- lambda運算式
- 函式式編程
- map()函式
- filter()函式
- reduce()函式
- 總結
- Python知識圖譜
前言
上一篇文章其實也介紹了Python函式,不過都是些函式基本知識點,還沒看的小伙伴抽空看下【Python從入門到精通】(十一)Python的函式的方方面面【收藏下來保證有用!!!】,這篇文章將重點介紹函式引數傳遞機制,lambda運算式以及函式式編程等深入一點的知識點,從入門到精通,不能老是搞些簡單的知識,也要來點硬貨,更深入的扎進知識的汪洋中,
Python函式引數傳遞機制
上一篇文章我們說到Python函式引數傳遞機制有兩種:分別是值傳遞和參考傳遞,那么這兩種方式有啥區別呢?各自具體的引數傳遞機制又是啥呢?這個章節就將來解答這兩個問題,首先來看看值傳遞,如下代碼定義了一個swap函式,有兩個入參a,b,這個函式的作業就是交換入參a,b的值,
def swap(a, b):
a, b = b, a
print("形參a=", a, 'b=', b)
return a, b
a, b = '碼農飛哥', '加油'
print("呼叫函式前實參的a=", a, 'b=', b)
swap(a, b)
print("呼叫函式后實參的a=", a, 'b=', b)
運行結果是:
呼叫函式前實參的a= 碼農飛哥 b= 加油
形參a= 加油 b= 碼農飛哥
呼叫函式后實參的a= 碼農飛哥 b= 加油
可以看出形參被成功的改變了,但是并沒有影響到實參,這到底是為啥呢?這其實是由于swap函式中形參a,b的值分別是實參a,b值的副本,也就是說在呼叫swap之后python會對入參a,b分別copy一份給swap函式的形參,對副本的改變當然不影響原來的數值啦, 語言的描述是空洞的,畫個圖說明下吧:在Python中一個方法對應一個堆疊幀,堆疊是一種后進先出的結構,上面說的程序可以用下面的呼叫圖來表示:
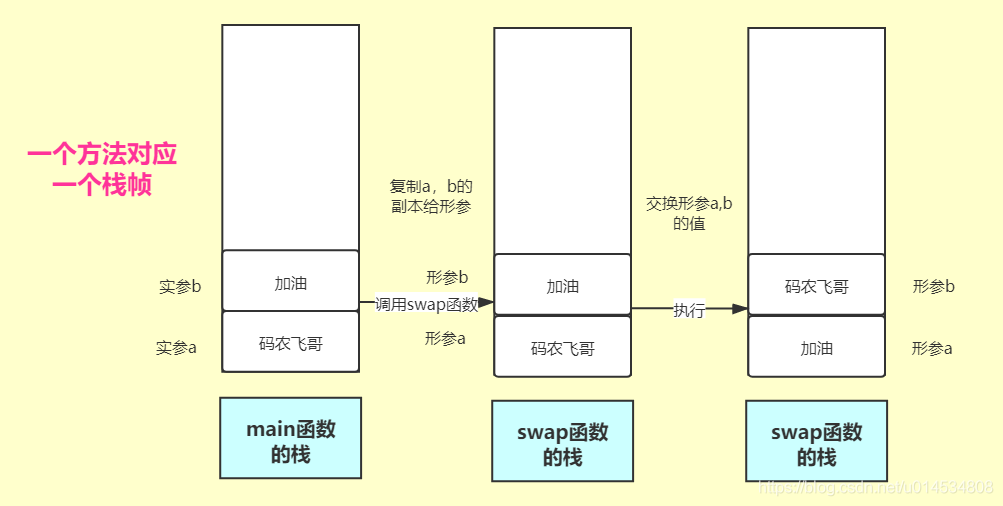
可以看出當執行a, b = '碼農飛哥', '加油' 代碼是,Python會在main函式堆疊中初始化a,b的值,當呼叫swap函式時,又把main函式中a,b的值分別copy一份傳給swap函式堆疊,當swap函式對a,b的值進行交換時,也就只影響到a,b的副本了,而對a,b本身沒影響,
但是對于串列,字典這兩的資料型別的話,由于資料是存盤在堆中,堆疊中只存盤了參考,所以在修改形參資料時實參會改變,,如下代碼演示:
def swap(dw):
# 下面代碼實作dw的a、b兩個元素的值交換
dw['a'], dw['b'] = dw['b'], dw['a']
print("swap函式里,a =", dw['a'], " b =", dw['b'])
dw = {'a': '碼農飛哥', 'b': '加油'}
print("呼叫函式前外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
swap(dw)
print("呼叫函式后外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
運行結果是:
呼叫函式前外部 dw 字典中,a = 碼農飛哥 b = 加油
swap函式里,a = 加油 b = 碼農飛哥
呼叫函式后外部 dw 字典中,a = 加油 b = 碼農飛哥
可以清晰的看出呼叫函式之后傳入的實參dw的值確實改變了,這說明他是參考傳遞的,那么參考傳遞與值傳遞有啥區別呢?
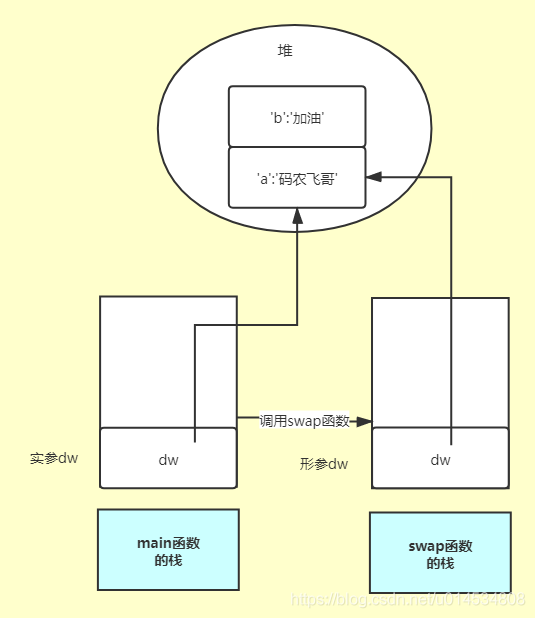
從上圖可以看出字典的資料是存盤在堆中的,在main函式的堆疊中通過參考來指向字典存盤的記憶體區域,當呼叫swap函式時,python會將dw的參考復制一份給形參,當然復制的參考指向的是同一個字典存盤的記憶體區域,當通過副本參考來操作字典時,字典的資料當然也改變,綜上所述:參考傳遞本質上也是值傳遞,只不過這個值是指參考指標本身,而不是參考所指向的值, 為了驗證這個結論我們可以稍微改造下上面的代碼:
def swap(dw):
# 下面代碼實作dw的a、b兩個元素的值交換
dw['a'], dw['b'] = dw['b'], dw['a']
print("swap函式里,a =", dw['a'], " b =", dw['b'])
dw = None
print("洗掉形參對字典的參考",dw)
dw = {'a': '碼農飛哥', 'b': '加油'}
print("呼叫函式前外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
swap(dw)
print("呼叫函式后外部 dw 字典中,a =", dw['a'], " b =", dw['b'])
運行的結果是:
呼叫函式前外部 dw 字典中,a = 碼農飛哥 b = 加油
swap函式里,a = 加油 b = 碼農飛哥
洗掉形參對字典的參考
呼叫函式后外部 dw 字典中,a = 加油 b = 碼農飛哥
洗掉了形參對字典的參考后,實參還是能獲取到字典的值,這就充分說明了傳給形參的是實參的參考的副本,
遞回函式
遞回函式相信不少小伙伴都不陌生,遞回函式是指在函式內部呼叫它自身的函式,遞回函式常常被運用到數列計算,遍歷省市區,遍歷檔案夾等場景下,需要注意的是:遞回函式必須能夠在滿足某個條件下不再呼叫他自身,不然的話就可能會出現不斷呼叫,陷入死回圈的境地, 比如:現在有一個數列:f(0) = 1,f(1) = 4,f(n + 2) = 2*f(n+ 1) +f(n),其中 n 是大于 0 的整數,求 f(5) 的值,這道題可以使用遞回來求得,下面程式將定義一個 fn() 函式,用于計算 f(5) 的值,根據f(n + 2) = 2*f(n+ 1) +f(n) 公式可以推導得到 f(n)=2*f(n-1)+f(n-2)公式,
def fn(n):
if n == 0:
return 1
if n == 1:
return 4
return 2 * fn(n - 1) + fn(n - 2)
print(fn(5))
運行結果是128 ,下面來推導下函式執行程序:
n=5時,函式回傳的是 2fn(4)+f(3),
n=4時,函式回傳的是 2fn(3)+f(2),
n=3時,函式回傳的是 2fn(2)+f(1),
n=2時,函式回傳的是 2fn(1)+f(0)
n=1時,函式回傳4
n=0時,函式回傳1,
所以,fn(2)=9,f(3)=22,f(4)=53,f(5)=128,他的呼叫程序是層層遞回的直到得到對里層的結果,然后反推得到外層的結果,
變數作用域
變數的作用域->說白了就是變數能作用的范圍,Python中變數分兩種:區域變數和全域變數,
定義在函式內部的變數被稱為區域變數,其作用域在函式內部,隨函式生隨函式死,就像一線員工一樣,你的權責范圍就在本部門(函式),部門外的事情你管不到,
區域變數的初始化程序是:當函式執行時,Python會為其分配一塊臨時的存盤空間,所有在函式內部定義的變數都會被存盤在這塊空間中,當函式執行完畢之后,這塊臨時存盤空間隨即被釋放并回收,該空間中存盤的變數自然也就無法再被使用,
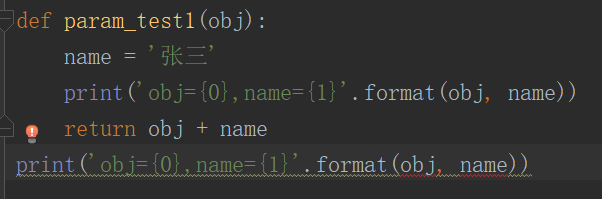
正如上面代碼中的obj變數和name變數,在函式內部可以正常使用,在函式外部則會提示NameError: name 'obj' is not defined,所以可以得出區域變數不能在函式外使用并且形參變數也是區域變數的結論,
定義在函式外部的變數被稱為全域變數,其作用域在整個應用程式,即全域變數既可以在各個函式的外部使用,也可以在各個函式內部使用,就像老板可以對全公司(整個應用程式)發號施令一樣,那各個小部門(函式)肯定也得聽他的話,就像下面代碼中的name變數這樣,在函式param_test1內外都能使用,
name='碼農飛哥'
def param_test1(obj):
print('name=', name)
print('name=', name)
獲取指定作用域范圍中的變數
- 通過
global()函式獲取python檔案內的全域變數,其結果是一個字典, - 在函式內部通過呼叫
locals()函式可以獲取該函式內的區域變數,舉個例子吧!
def param_test1(obj):
name = '張三'
print('區域變數有=', locals())
return obj + name
param_test1('李四')
name2 = '張三'
print('全域變數有', globals())
運行結果是:
區域變數有= {'name': '張三', 'obj': '李四'}
全域變數有 {'__name__': '__main__', '__doc__': '@date: 2021/7/19 21:23\n@desc: \n', '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00000226B627B208>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/python_demo_1/demo/function/param_test_fun.py', '__cached__': None, 'param_test1': <function param_test1 at 0x00000226B6221EA0>, 'name2': '張三'}
如何在函式中使用同名的全域變數
當函式內部的區域變數和函式外部的全域變數同名時,在函式內部,區域變數會”遮蔽“同名的全域變數,正所謂強龍不壓地頭蛇,在函式內部區域變數就是地頭蛇,全域變數這個強龍的風頭也會被它壓住,
name = "張三"
def test_1():
# 訪問全域變數
print(name)
name = "李四"
test_1()
運行該函式會報如下錯誤:
Traceback (most recent call last):
File "python_demo_1/demo/function/param_test_fun.py", line 33, in <module>
test_1()
File "/python_demo_1/demo/function/param_test_fun.py", line 31, in test_1
print(name)
UnboundLocalError: local variable 'name' referenced before assignment
上面的錯誤提示告訴我們在執行print(name)時,name還沒有定義,因為name是在第五行定義的,其實我們期望在第四行列印全域變數name的值,但是由于第五行函式中定義了一個同名的區域變數name(Python語法規定,在函式內部對不存在的變數賦值時,默認就是重新定義新的區域變數),而區域變數name"遮蔽"了全域變數name,同時區域變數name在print(name)后才被初始化,違反了"先定義后使用"的原則,因此程式會報錯,
如何防止"遮蔽"的情況呢?
那么如何防止在函式內部全域變數被同名的區域變數"遮蔽"呢?這里有兩種方式:
- 直接訪問被遮蔽的全域變數,如果希望程式依然能訪問name全域變數,且在函式中可重新定義name區域變數,可以通過globals()函式來實作,
name = "張三"
def test_1():
name = "李四"
print('區域變數name=', name)
# 訪問全域變數
print('全域變數name=', globals()['name'])
test_1()
運行結果是:
區域變數name= 李四
全域變數name= 張三
通過globals()['name'] 直接訪問全域變數name,就實作了和區域變數name井水不犯河水的效果,
2. 在函式中通過 global關鍵字宣告全域變數,為了避免在函式中對全域變數賦值(不是重新定義區域變數),可使用global陳述句來宣告全域變數,
name = "碼農飛哥"
def test_2():
global name
# 訪問全域變數
print('全域變數name=', name)
name = "小偉偉"
print('區域變數name=', name)
print('全域變數name=', globals()['name'])
test_2()
運行結果是:
全域變數name= 碼農飛哥
區域變數name= 小偉偉
全域變數name= 小偉偉
通過global關鍵字同樣可以區域變數遮蔽同名的全域變數,通過global 修飾全域變數之后,在同名的區域變數定義之前,都使用的是全域變數,
函式的高級用法
函式賦值給其他變數
函式不僅僅可以直接呼叫,還可以直接將函式賦值給其他變數,就像下面定義了一個名為my_fun的函式,首先將函式名my_fun賦值給變數other,然后通過other來間接呼叫my_fun()函式,
def my_fun():
print("正在執行my_fun函式")
# 將函式賦值給其他變數
other = my_fun
# 間接呼叫my_fun()函式
other()
運行結果是:正在執行my_fun函式
將函式以引數的形式傳遞給其他函式
Python還支持將函式以引數的形式傳遞給其他函式,也就是說將可以將函式作為一個形參傳遞,舉個栗子吧!
def my_fun1():
return '加油,你一定行'
def my_fun2(name, my_fun1):
return name + my_fun1
print(my_fun2('碼農飛哥', my_fun1()))
運行結果是碼農飛哥加油,你一定行,
上面代碼首先定義了一個函式my_fun1,接著將函式my_fun1作為引數傳遞給函式my_fun2,代碼可以正常運行,
區域函式(內部函式)及用法
Python不僅支持在函式內部定義區域變數,還支持在函式內部定義函式,這類函式就稱之為區域函式,舉個例子吧!
# 全域函式
def outer_fun():
def inner_fun():
print('呼叫區域函式')
return inner_fun
# 呼叫區域函式
new_inner_fun = outer_fun()
new_inner_fun()
上面代碼首先定義了全域函式outer_fun,然后在該函式內部定義了一個區域函式inner_fun,接著回傳該區域函式,根據前面函式可以賦值給變數的知識,就可以順利呼叫到區域函式inner_fun,
需要注意的是,區域函式中定義有和所在函式中變數同名的變數,也會發生”遮蔽“的問題,避免這種問題的方式不再是使用global關鍵字,而需要通過 nonlocal關鍵字,就像下面這樣!
# 全域函式
def outer_fun():
name = '碼農飛哥'
def inner_fun():
print('呼叫區域函式')
nonlocal name
print('全域變數name=', name)
name = '小偉偉'
print('區域變數name=', name)
return inner_fun
# 呼叫區域函式
new_inner_fun = outer_fun()
new_inner_fun()
運行結果是:
呼叫區域函式
全域變數name= 碼農飛哥
區域變數name= 小偉偉
lambda運算式
Python是支持lambda運算式的,lambda運算式又稱為匿名函式,常用來表示內部包含1行運算式的函式,其語法結構是:
name=lambda [list]:運算式
其中,定義lambda運算式,必須使用lambda關鍵字;[list]作為可選引數,等同于定義函式是指定的引數串列;name為該運算式的名稱,例如現在有如下一個add函式,入參是x,y,回傳是 x+y,
def add(x, y):
return x + y
可以將該函式改寫成一個lambda運算式,其結果是lambda x,y:x+y,然后將其賦值給一個add變數,就像下面這樣,
add = lambda x, y: x + y
print(add(2, 3))
當然,lambda運算式遠不止這點技能,它與接下來介紹的函式式編程結合會產生別樣的效果,接下來就來看看函式式編程吧,
函式式編程
普通的函式當入參是串列或者字典時,當對形參進行修改時,則實參也會改變,就像下面這樣:
test_list = [1, 2, 3, 4]
def second_multi(test_list):
for i in range(len(test_list)):
test_list[i] = test_list[i] * 2
return test_list
for i in range(3):
print('第{0}次運行的結果是:'.format(str(i)), second_multi(test_list))
運行結果是:
第0次運行的結果是: [2, 4, 6, 8]
第1次運行的結果是: [4, 8, 12, 16]
第2次運行的結果是: [8, 16, 24, 32]
可以看出每次傳入相同的引數test_list,3次得到的結果都不一樣,這是由于函式內部對test_list做了改變,要想避免這種情況,只能在函式內部重新定義一個新的串列new_list,函式只對new_list進行修改,
test_list = [1, 2, 3, 4]
def second_multi(test_list):
new_list = []
for i in range(len(test_list)):
new_list.append(test_list[i] * 2)
return new_list
for i in range(3):
print('第{0}次運行的結果是:'.format(str(i)), second_multi(test_list))
運行結果是:
第0次運行的結果是: [2, 4, 6, 8]
第1次運行的結果是: [2, 4, 6, 8]
第2次運行的結果是: [2, 4, 6, 8]
不過現在有了函式式編程,可以通過函式式編程來實作上述代碼的效果,函式式編程是指代碼中每一塊都是不可變的,是由純函式的形式組成,這里的純函式,是指函式本身相互獨立,互不影響,對于相同的輸入,總會有相同的輸出,將上面的函式改造成函式式編程會如何呢?上述函式等價于下面的函式式編程map(lambda x: x * 2, test_list)
test_list = [1, 2, 3, 4]
for i in range(3):
print('第{0}次運行的結果是:'.format(str(i)), list(map(lambda x: x * 2, test_list)))
運行結果是:
第0次運行的結果是: [2, 4, 6, 8]
第1次運行的結果是: [2, 4, 6, 8]
第2次運行的結果是: [2, 4, 6, 8]
從上述結果可以看出,函式式編程對于相同的輸入總會有相同的輸出,
Python有如下三個函式用于函式式編程,
map()函式
map()函式的功能 是對可迭代物件中的每個元素,都呼叫指定的函式,并回傳一個map物件,但是這個map物件是不能直接輸出的,可以通過for回圈或者list()函式來表示,
map()函式的語法格式是:map(function,iterable)
其中,function引數表示要傳入一個函式,其可以是內置函式,自定義函式或者lambda匿名函式,iterable表示一個或多個可迭代物件,可以是串列,字串等,就像下面這樣:
test_list1 = [1, 3, 5]
test_list2 = [2, 4, 6]
new_map = map(lambda x, y: x + y, test_list1, test_list2)
print(list(new_map))
運行結果是:[3, 7, 11]
上面的代碼是對兩個串列中的每個元素進行求和,得到一個新的串列,相當于下面的函式
def add(test_list1, test_list2):
new_list = []
for index in range(len(test_list1)):
new_list.append(test_list1[index] + test_list2[index])
return new_list
print(add(test_list1, test_list2))
運行結果是[3, 7, 11]

filter()函式
filter()函式的功能是對iterable中每個元素,都使用function函式判斷,并回傳True或者False,最后將回傳True的元素組成一個新的可遍歷的集合filter物件,同樣這個filter物件是不能直接輸出的,可以通過for回圈或者list()函式來表示,filter函式一般用于過濾資料的場景 其語法格式是:filter(function,iterable)
其中,function引數表示要傳入一個函式,其可以是內置函式,自定義函式或者lambda函式;iterable表示一個或多個可迭代的物件,可以是串列,字串等,下面就是過濾出串列中的所有偶數,
test_list3 = [1, 2, 3, 4, 5]
new_filter = filter(lambda x: x % 2 == 0, test_list3)
print(list(new_filter))
運行結果是:[2, 4]
reduce()函式
reduce()函式通常用于對一個集合做一些累積操作,其語法結構是:
import functools
functools.reduce(function, iterable)
其中,function引數表示要傳入一個函式,其可以是內置函式,自定義函式或者lambda函式;iterable表示一個或多個可迭代的物件,可以是串列,字串等,
import functools
test_list4 = [1, 2, 3, 4, 5]
product = functools.reduce(lambda x, y: x + y, test_list4)
print(product)
運行結果是:15,

總結
本文詳細介紹了Python函式一些常見的高級知識點,包括函式引數的傳遞機制,變數的作用域,lambda運算式,以及函式式編程,都是些對實際開發有幫助的知識點,希望對讀者朋友們有所幫助,也歡迎大家一件三連,

Python知識圖譜
為了更好幫助更多的小伙伴對Python從入門到精通,我從CSDN官方那邊搞來了一套 《Python全堆疊知識圖譜》,尺寸 870mm x 560mm,展開后有一張辦公桌大小,也可以折疊成一本書的尺寸,有興趣的小伙伴可以了解一下------掃描下圖中的二維碼即可購買,
我本人也已經用上了,感覺非常好用,圖譜桌上放,知識心中留,
我是碼農飛哥,再次感謝您讀完本文,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/289603.html
標籤:python