十行代碼幫助小姐姐給偶像送上最真摯的禮物----爬蟲詞云齊上陣,熬夜精心制作
這是本文思路,謝謝觀看
- 十行代碼幫助小姐姐給偶像送上最真摯的禮物----爬蟲詞云齊上陣,熬夜精心制作
- 故事背景
- 制作程序
- 1.爬蟲的幫助
- 2.詞云的幫助
- 成果展示
首先,最近河南暴雨嚴重,希望河南的小伙伴們保護好自己,也希望大家少一點關注娛樂圈毫無意義的瓜,多去關注一下河南的暴雨救援情況,貢獻出自己的力所能及的幫助,加油,We are always by your side!!!
hello,大家好,我又來了,快上車!別問我是誰,問就是迷一樣的男人!
故事背景
最近嘛,有位朋友找我幫忙嘛,希望我幫她做一份禮物,送給一直鼓舞著她不斷向前,不斷努力奮斗的偶像…,好家伙,我直接感動了,優質偶像的作用竟是如此之大!(一定要追有意義的優質明星,當一個理智的粉絲,而不是一群(nao can)粉)
就沖她是個小姐姐,這個忙我一定幫! 于是我爽快地答應了!
了解到這位小姐姐的偶像是一位歌手后,我以歌曲為出發點,開始準備這份特別的禮物,(由于不太方便透露資訊,以后都以我的偶像原創歌手薛之謙來寫,希望大家諒解)
話不多說,開干!
制作程序
首先,我覺得作為一名優秀的歌手,歌曲的質量是放在第一位的,無關顏值無關綜藝感,更無關演技,當然還是要以人品為首位!所以我打算從歌曲評論為出發點去制作這個禮物!
1.爬蟲的幫助
說到評論,最先想到的便是爬蟲了,把評論爬取下來,于是我打開了網易云音樂官網,找到了我最近比較喜歡的歌《變廢為寶》 正常套路,檢測其埠,獲取相關資料:
正常套路,檢測其埠,獲取相關資料:
這是最終的代碼:利用 requests 進行網頁請求;利用json 進行格式轉換
我把爬取來的評論放到了一個名為:變廢為寶.txt的txt文本檔案中
import requests
import json
def get_hot_comments(res):
comments_json = json.loads(res.text)
hot_comments = comments_json['hotComments']
with open('變廢為寶.txt', 'w', encoding='utf-8') as file:
for each in hot_comments:
file.write(each['user']['nickname'] + ':\n\n')
file.write(each['content'] + '\n')
file.write("---------------\n")
def get_comments(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400',
'referer': 'https://music.163.com/'
}
params = "Brz3HT85JisY8LDEnLmxi / xmif2K6blJa6S98 / yJLqJC57FXl3 / X2 / N4o7f + rI6X + XrTVC7x8LcajFJFdaJGEYAzGbBN6WQLsJSqWbi5PYjJ0DHpXPSqZk0o / +GOJigre4SPFZy1sAQvV + BNovPMpsaKevgNxMftnwzEictv6k2arH0y5XLZZ0y8P3FNYYgZ + s70qhLJHf8B5bfjf23uSiFaclQFGpM / Sn202q / iHgxXSq4f7y1NkFXlXXMfNn8io09KCa1yynKed9W1ptPI5q4Jj + 5\
FQQgDYyXKHAvl1SisUm3Pj8rtl + VIGJFvyIVE"
encSecKey = "d180e107a8c7d417d1a27bc23f2321b97d1744df31c17415843a41015fbec1ae3b681d45fc3d98974f05e1b552d5a5b54c750637f68d0b36e74596211e8db6d9d9969b52589a57c48c98a1c87dfaf3f93a228be636def04e36fd8ea2fe4c345b0951a9fe5fc8043937b753bbe5339a7d7180b0813b31af734668ab6f08eaa8c5"
data = {
"params ": params,
"encSecKey": encSecKey
}
name_id = url.split('=')[1]
target_url = "https://music.163.com/api/v1/resource/comments/R_SO_4_{}?csrf_token=".format(name_id)
res = requests.post(target_url, headers=headers, data=data) # 傳入它的關鍵字引數
return res
def main():
url = input("請輸入鏈接地址:")
res = get_comments(url) # 回傳給相關獲取的網頁資源
get_hot_comments(res)
if __name__ == "__main__":
main()
這些都是一個個評論: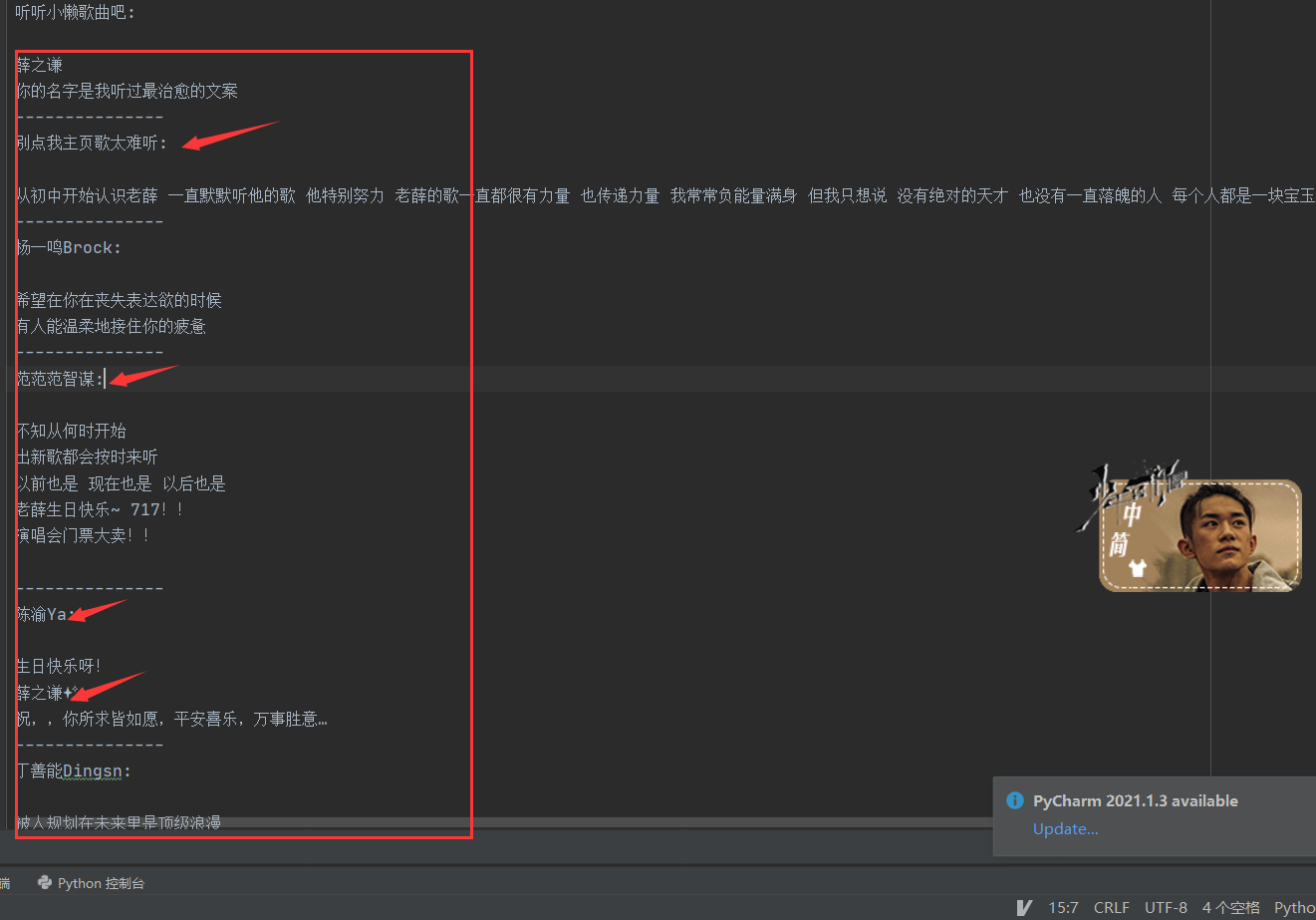
2.詞云的幫助
如何快速的看出一首歌的影響力,主要在于看這首歌的評論趨向,到底是稱贊多呢還是拉跨多呢,又或者評論趨向于那幾點呢?這個時候詞云的作用是十分巨大的,他可以把關鍵詞集中在一起,并且出現關鍵詞的次數越多的話,在詞云中的顯現會更加明顯,
話不多說,我們直接開搞:

# -*-coding:utf-8 -*-
# @Author:到點了,心疼徐哥哥
# 奧利給干!!!
import wordcloud #匯入詞云庫
import numpy as np
import matplotlib.pyplot as plt
import PIL
import jieba
import re
with open(r'變廢為寶.txt',encoding='utf8') as fp:
text1 = fp.readlines()#打開我們之前爬蟲爬下來的txt檔案
image1 = PIL.Image.open(r'a.jpg')#匯入圖片,作為詞云的形狀,不是背景圖,只影響詞云的形狀
MASK = np.array(image1)#把圖片轉化為陣列格式,需要用img=np.array(img)做轉換,才能看到shape屬性,是(height,width,channel)陣列,channel的通道順序為RGB,
WC = wordcloud.WordCloud(font_path = 'simkai.ttf',max_words=200,
max_font_size=200,mask = MASK,height= 4000,width=4000,
background_color='white',repeat=False,mode='RGB',random_state = 42)
st1 = re.sub('[,,、“”‘ ’]','',str(text1)) #使用正則運算式將符號替換掉,
#re.sub共有五個引數,其中三個必選引數:pattern, repl, string兩個可選引數:count, flags
# 第一個引數:pattern,表示正則中的模式字串,這個沒太多要解釋的,
#第二個引數:repl,就是replacement,被替換,的字串的意思,
# 第三個引數:string,即表示要被處理,要被替換的那個string字串,
conten = ' '.join(jieba.lcut(st1))
con = WC.generate(conten)
plt.imshow(con)
plt.axis('off')#隱藏坐標軸
plt.show() #顯示圖片
path = r'C:\Users\xuyip\PycharmProjects\pythonProject33\pyecharts'
con.to_file(path+r'\beautifulcloud.png')#保存圖片
這里我們主要使用了wordcloud這個詞云庫,我們詳細的說一下詞云的各種可修改的格式和風格
WC = wordcloud.WordCloud(font_path = 'simkai.ttf',max_words=200,
max_font_size=200,mask = MASK,height= 4000,width=4000,
background_color='white',repeat=False,mode='RGB',random_state = 42)
width:畫布寬度(默認為400像素)
height:畫布高度(默認為200)
margin:每個單詞間的間隔 (默認為2)
prefer_horizontal :詞語水平方向排版出現的頻率(默認為0.9,注意水平排版和垂直排版概率之和為1,因此默認垂直方向排版為0.1)
mask:nd-array or None (default=None), 簡單理解為繪制模板,當mask不為0時,那么之前依據height和width設定的畫布則作廢,此時“畫布”形狀大小由mask決定,
scale:float (default=1). 計算和繪圖之間的比例(就是放大畫布的尺寸,也可以叫比例尺)
max_words:number (default=200) 最大顯示單詞字數,
max_font_size:int or None (default=None) 最大單詞的字體大小,如果沒有設定的話,直接使用畫布的大小,
stopwords:set of strings or None 被淘汰不用于顯示的詞語,默認使用內置的stopwords,
background_color:color value (default=”black”) 詞云影像的背景色,默認為黑色,
mode:string (default=”RGB”) 當mode=“RGBA”且background_color=“None”時,將生成透明的背景,
relative_scaling:float (default=’auto’) 詞頻大小對字體大小的影響度,如果設定為1的話,如果一個單詞出現兩次那么其字體大小為原來 的兩倍,
random_state:設定有多少種隨機生成狀態,即有多少種配色方案
這里我們將背景色設為了白色:background_color=‘white’(也有別的顏色,可以隨意設定) 最大單詞數我們設定為max_words=200,最多配色數設定為random_state = 42,最大單詞字體型號設定為:max_font_size=200
然后大功告成!
成果展示
讓我們來看看最終成果吧:
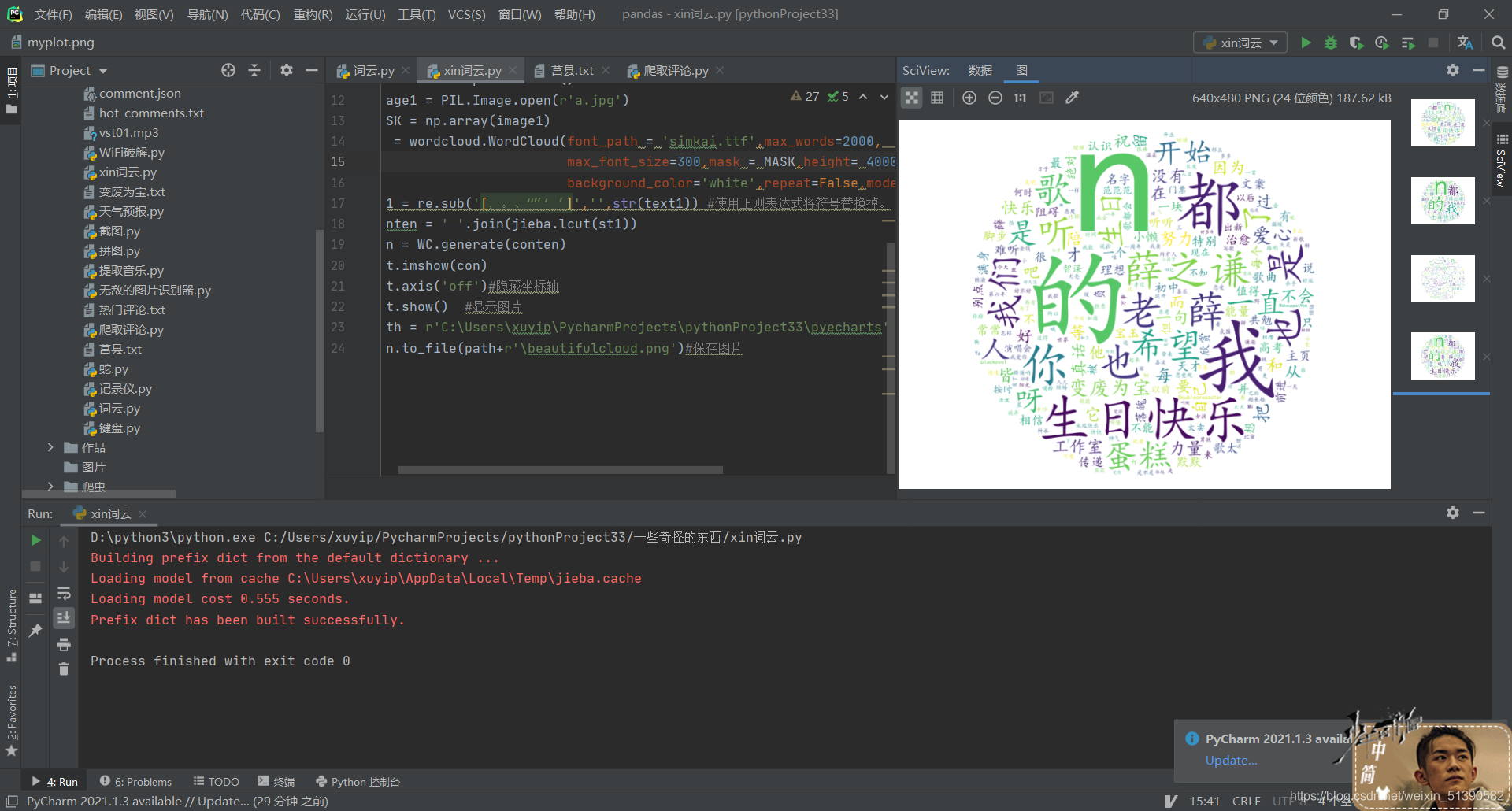

這便是一個簡單的詞云了,從中我們可以看出大家對這首歌評論的關鍵詞,因為我們的背景圖片只是一個圓,這樣多少有點low,能不能換成別的呢,答案是:能!
我們接著看:
我們找到薛之謙的一張圖片,已之為背景圖,但這張圖片必須只有人物,也就是把背景去掉,把人物摳出來(需要一丟丟的摳圖技術,不要說不會喲,我默認你會ps),詞云才會以人物身體來作為背景

DuangDuangDuang:

啥也不說,先鼓三分鐘掌,然后我又為小姐姐陸陸續續做了十張左右,小姐姐直接感激的痛哭流涕!其實這是我花了一個晚上熬夜制作的,不過沒事,幫助他人是一件非常快樂的事,希望大家也為他人伸出援助之手,我們一起加油!
哈哈哈,這就是今天要給大家分享的全部內容了
如果你喜歡的話,就不要吝惜你的一鍵三連了~

學廢了嗎,歡迎大家觀看這一欄目其他文章:
Python跨年表白神器
挑戰用純python寫一個王者榮耀小游戲?
震驚!鄰桌的程式猿比我能淦,帶著好奇心我打開了他的電腦,發現驚天秘密,原因竟是
好家伙!弟弟竟然背著我用電腦干這個,我用python輕松的識破他的謊言,阿姨對我贊不絕口!~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/289872.html
標籤:python
上一篇:萬字爆肝python基礎知識
下一篇:Python自帶的小demo