專案來源:
https://www.kaggle.com/anthonypino/melbourne-housing-market
專案簡介:
利用以往的房屋銷售資訊,分析哪種房屋最值得推薦給投資者進行投資,
PS: 本次專案是在jupyter上運行的,(文末附資源鏈接)
匯入模塊:
%matplotlib inline
import pandas as pd
import seaborn as sns
import statsmodels.formula.api as smf
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn.model_selection import train_test_split
import numpy as np
from scipy.stats import norm # for scientific Computing
from scipy import stats, integrate
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 設定漢字字體,優先使用黑體
plt.rcParams['font.size'] = 12 # 設定字體大小
plt.rcParams['axes.unicode_minus'] = False # 設定正常顯示負號
加載資料:
melbourne_data = pd.read_csv("./Melbourne_housing_FULL.csv")
melbourne_data.head(10)
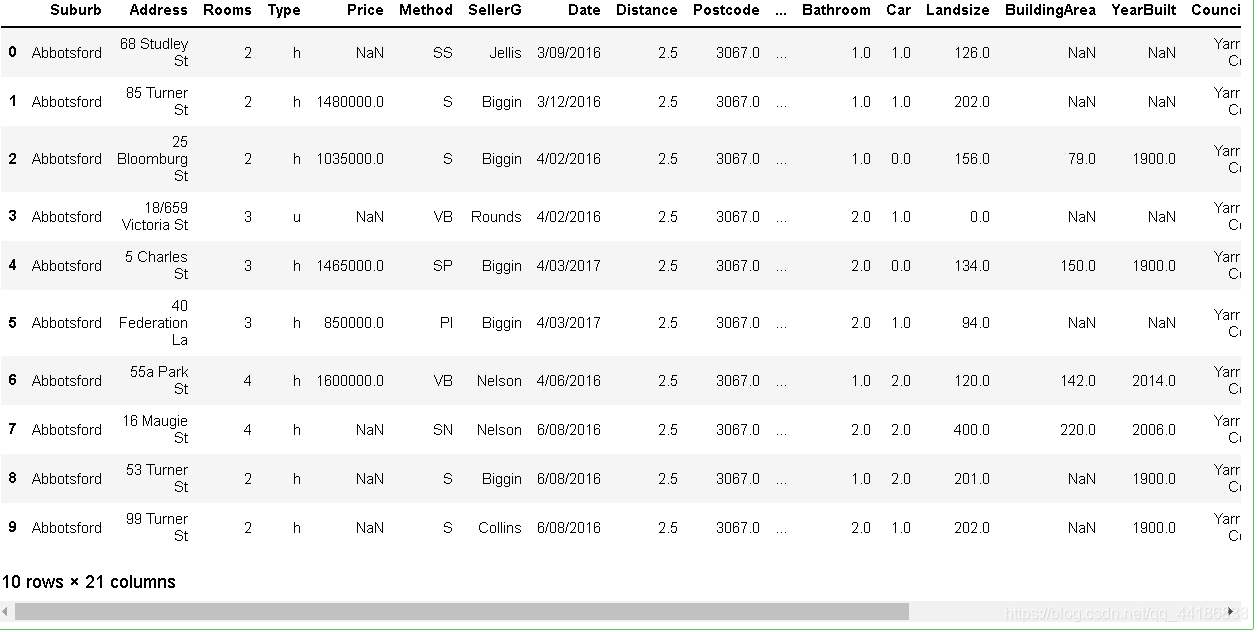
接下來正式開始進行分析啦!
1 資料探索與資料清洗
1.1 資料探索
melbourne_data.shape
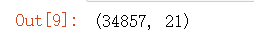
melbourne_data.info()
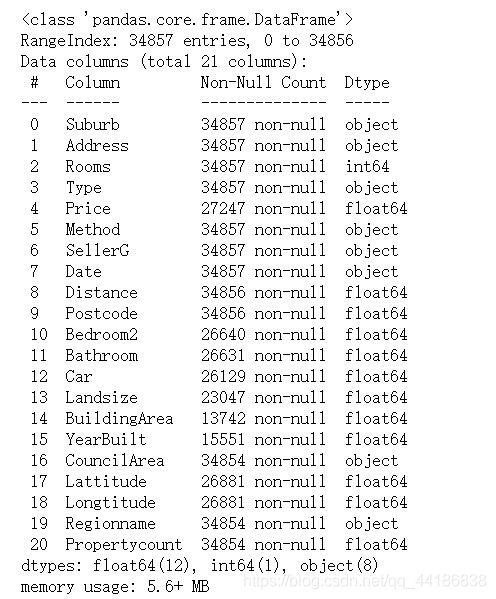
從上面的資料資訊可以看出,非數值資料被視為物件,該串列包括以下列:“suburban”、“Address”、“Type”、“Method”、“SellerG”、“Date”、“councileArea”、“Regionname”,在接下來的幾個步驟中,我們將把物件資料型別更改為category和Date資料型別,
# 驗證字串型別的資料
melbourne_data.select_dtypes(["object"]).columns

1.2 更換資料型別
# 將所有字串資料型別更改為類別-此步驟對于能夠繪制類別資料以進行分析是必需的
objdtype_cols = melbourne_data.select_dtypes(["object"]).columns
melbourne_data[objdtype_cols] = melbourne_data[objdtype_cols].astype('category')
melbourne_data.info()
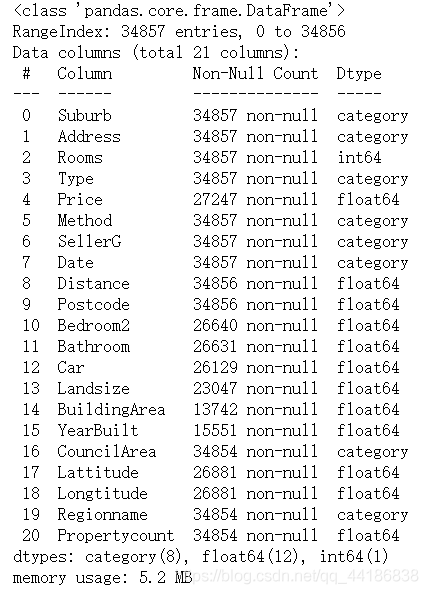
## 看上面的資料資訊,我們可以注意到“資料”也被轉換成了類別,
## 在這一步中,我們將將日期轉換為datetime
melbourne_data['Date'] = pd.to_datetime( melbourne_data['Date'])
melbourne_data.info()
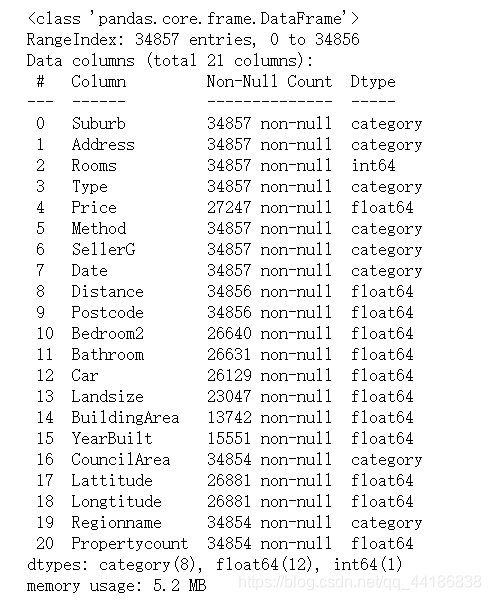
在接下來的幾個步驟中,我們將對數值特征變數進行資料預處理,
melbourne_data.describe().T
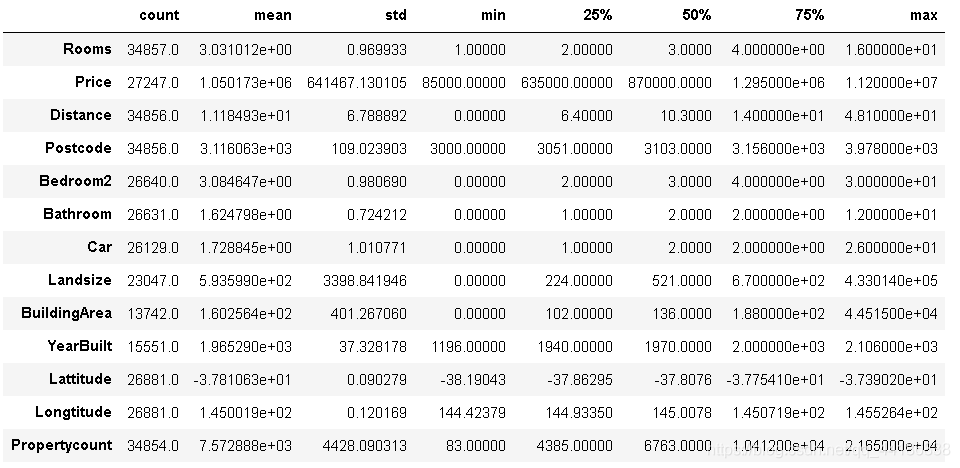
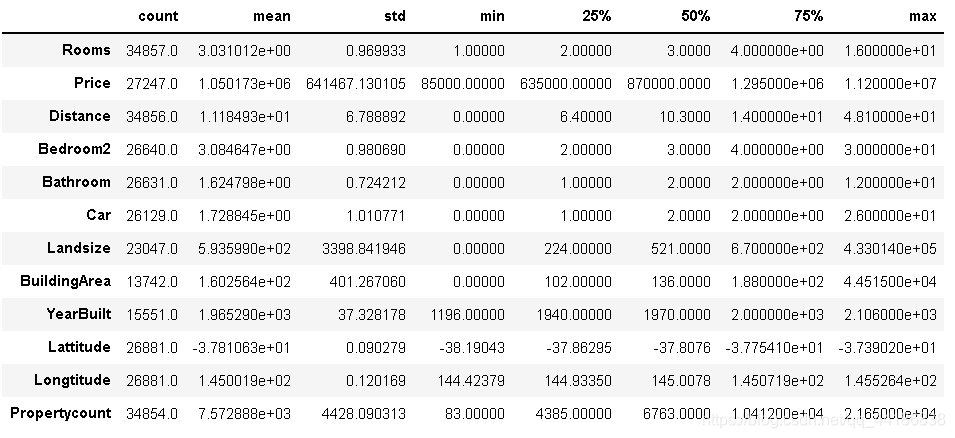
觀察以上有關數字資料的資訊,可以注意到郵政編碼也被視為數字資料,既然我們知道郵政編碼是一個分類資料,我們將把它分類,
melbourne_data["Postcode"] = melbourne_data["Postcode"].astype('category')
melbourne_data.describe().T
仔細評估資料后,可以注意到變數“Rooms”和“Bedroom2”非常相似,應該洗掉其中一列以避免重復資料,
## 在這一步中,我們將首先通過觀察“Rooms”和“Bedroom2”來確認我們的上述宣告
melbourne_data['b 2 r'] = melbourne_data["Bedroom2"] - melbourne_data["Rooms"]
melbourne_data[['b 2 r', 'Bedroom2', 'Rooms']].head()
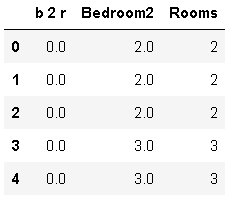
## 我們可以看到,這里的差別非常小,洗掉這兩列中的一列是明智的
melbourne_data = melbourne_data.drop(['b 2 r', 'Bedroom2'], 1)
1.3 缺失值處理
我們可以使用多種方法來探索缺失的資料,在這里,我們將首先使用一個可視化的方式來獲得一些提示,在后面的步驟中,我們將進行一些計算,以獲得每個變數中丟失資料的確切數量,根據資料、我們的經驗和業務需要,我們要么填寫缺失的值,要么洗掉具有空值的行或列,
## 可視化缺失值
fig, ax = plt.subplots(figsize=(15,7))
sns.heatmap(melbourne_data.isnull(), yticklabels=False,cmap='viridis')
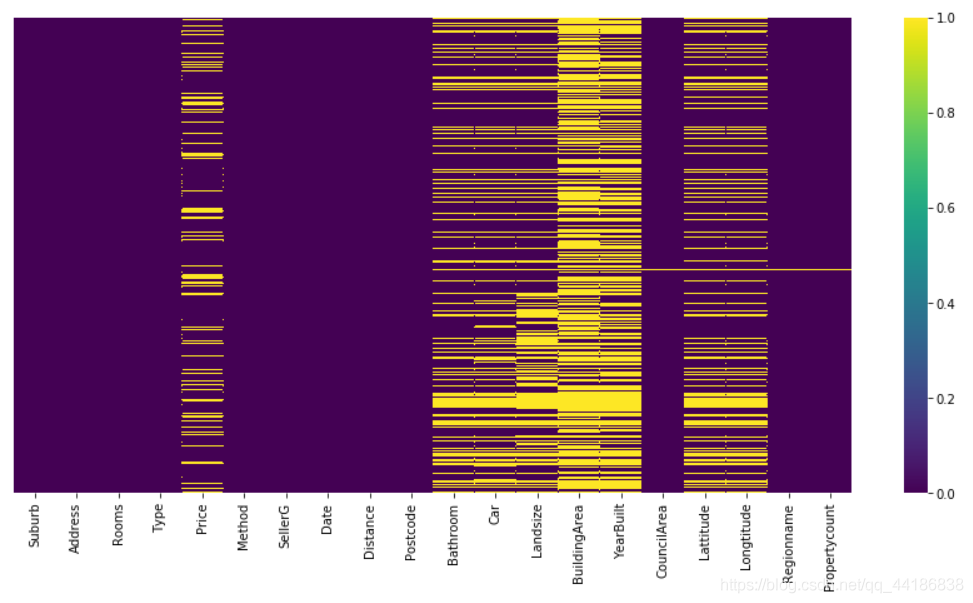
從上圖可以得出結論,price,bathroom,car和landsize,lattitude和longtitude有部分缺失值,在buildingarea和bulityear中有許多缺少的值,在下一步中,讓我們研究缺失值的計數,
# 百分比缺失值
melbourne_data.isnull().sum()/len(melbourne_data)*100
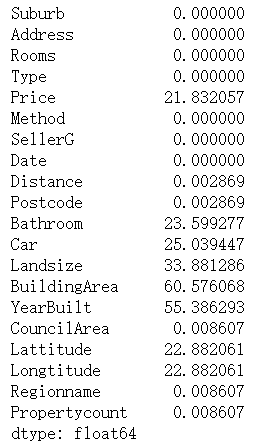
從上面的資訊中,我們可以注意到很少的特性變數仍然有很大比例的缺失值,此時我們將忽略它,但在稍后的狀態中,如果我們將這些作為后續的特征變數,我們將探索填充這些資訊或從資料中洗掉這些資訊的方法,
melbourne_data = melbourne_data.drop(["Landsize", "BuildingArea", "YearBuilt"], axis=1)
# 另外,因為我們的目標變數是price,所以在缺少price值時,洗掉price列的行是有意義的
melbourne_data.dropna(subset=["Price"], inplace=True)
melbourne_data['Car']=melbourne_data['Car'].fillna(melbourne_data['Car'].mode()[0])
melbourne_data['Bathroom']=melbourne_data['Bathroom'].fillna(melbourne_data['Bathroom'].mode()[0])
melbourne_data.shape
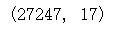
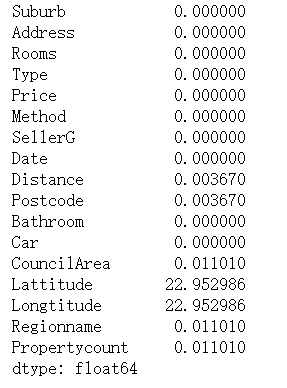
# 百分比缺失值
melbourne_data.isnull().sum()/len(melbourne_data)*100
1.4 尋找例外資料
例外值可以顯著影響資料分析,也可以影響資料的規范化,在資料預處理程序中,識別和洗掉它們是非常重要的,在接下來的幾個步驟中,我們將在資料中處理例外值(如果有的話),
melbourne_data.describe().T
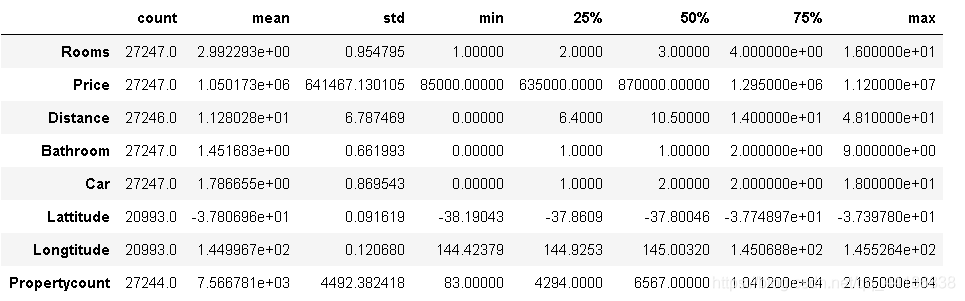
從上面的統計總結中我們可以看到,我們資料中的最高價格接近1120萬美元,這看起來像是一個明顯的例外值,但是在洗掉它之前,讓我們首先確保在這個范圍內只有很少的值,
# 為了找出例外值,我們將資料劃分為不同的價格范圍,以確定不同價格范圍內資料出現的次數
melbourne_data['PriceRange'] = np.where(melbourne_data['Price'] <= 100000, '0-100,000',
np.where ((melbourne_data['Price'] > 100000) & (melbourne_data['Price'] <= 1000000), '100,001 - 1M',
np.where((melbourne_data['Price'] > 1000000) & (melbourne_data['Price'] <= 3000000), '1M - 3M',
np.where((melbourne_data['Price']>3000000) & (melbourne_data['Price']<=5000000), '3M - 5M',
np.where((melbourne_data['Price']>5000000) & (melbourne_data['Price']<=6000000), '5M - 6M',
np.where((melbourne_data['Price']>6000000) & (melbourne_data['Price']<=7000000), '6M - 7M',
np.where((melbourne_data['Price']>7000000) & (melbourne_data['Price']<=8000000), '7M-8M',
np.where((melbourne_data['Price']>8000000) & (melbourne_data['Price']<=9000000), '8M-9M',
np.where((melbourne_data['Price']>9000000) & (melbourne_data['Price']<=10000000), '9M-10M',
np.where((melbourne_data['Price']>10000000) & (melbourne_data['Price']<=11000000), '10M-11M',
np.where((melbourne_data['Price']>11000000) & (melbourne_data['Price']<=12000000), '11M-12M', '')
))))))))))
melbourne_data.groupby(['PriceRange']).agg({'PriceRange': ['count']})
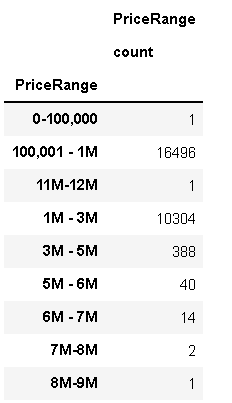
通過研究上表,可以得出以下結論:
- 1個資料項,范圍0-100,00
- 7M-8M范圍內有2個資料
- 8M-9M范圍內有1個資料
- 11M-12M范圍內有1個資料,
為了本研究的目的,讓我們洗掉符合上述條件的行,
melbourne_data.info()
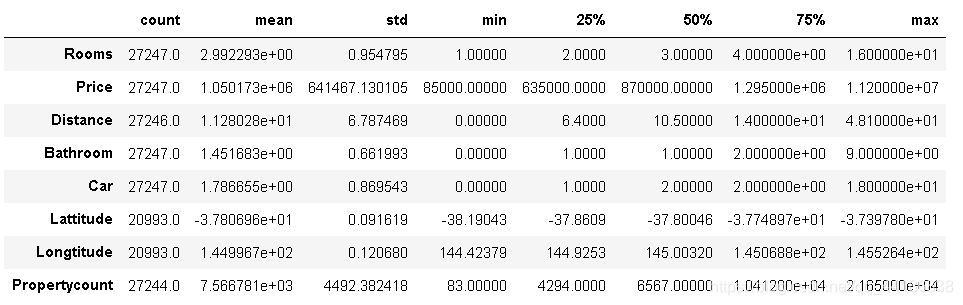
melbourne_data.describe().T
melbourne_data.drop(melbourne_data[(melbourne_data['PriceRange'] == '0-100,000') |
(melbourne_data['PriceRange'] == '7M-8M') |
(melbourne_data['PriceRange'] == '8M-9M') |
(melbourne_data['PriceRange'] == '11M-12M')].index, inplace=True)
melbourne_data.describe().T
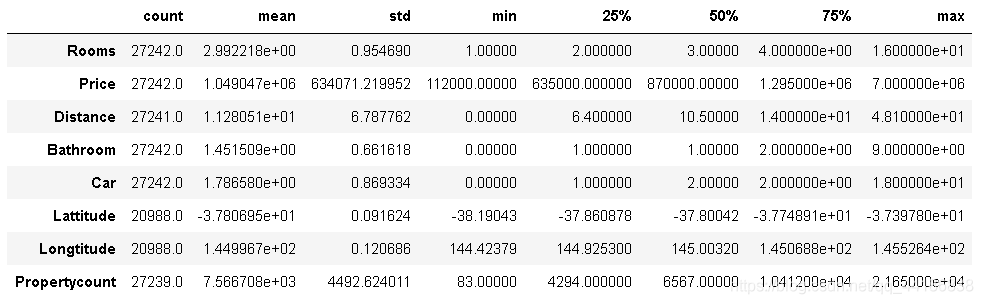
melbourne_data.groupby(['Rooms'])['Rooms'].count()

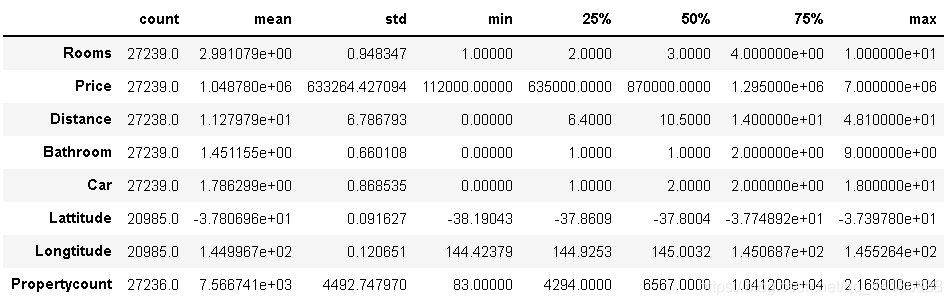
melbourne_data.drop(melbourne_data[(melbourne_data['Rooms'] == 12) |
(melbourne_data['Rooms'] == 16)].index, inplace=True)
melbourne_data.describe().T
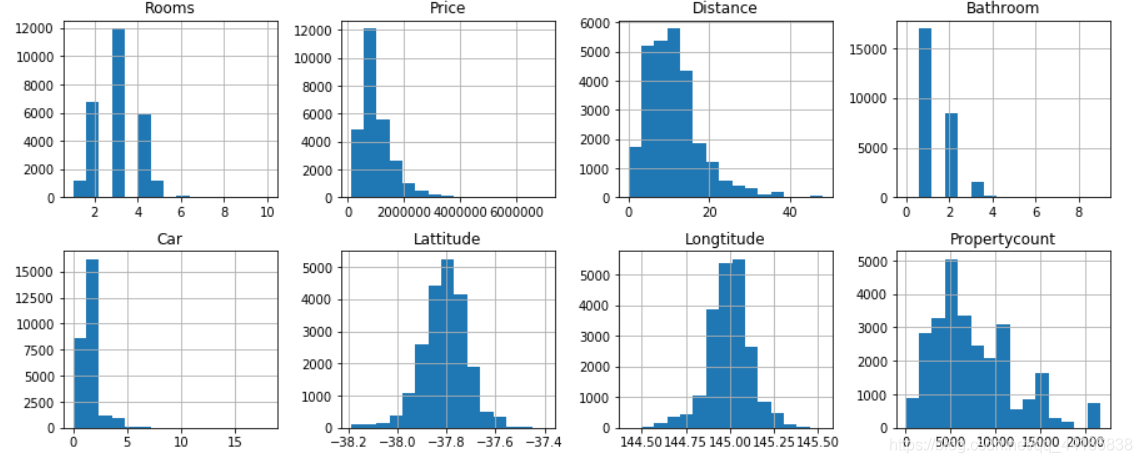
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
melbourne_data.select_dtypes(include = numerics).hist(bins=15, figsize=(15, 6), layout=(2, 4))
melbourne_data['Distance'] = round(melbourne_data['Distance'])
melbourne_data.shape
2 資料呈現與關系
2.1 我們考慮的第一個因素是價格與年份和季節的關系,然后利用線性函式預測2019年和2020年的價格,
2.1.1 每種型別的房子價格年趨勢
## 從日期中提取年出來
melbourne_data['Year']=melbourne_data['Date'].apply(lambda x:x.year)
melbourne_data.head(5)
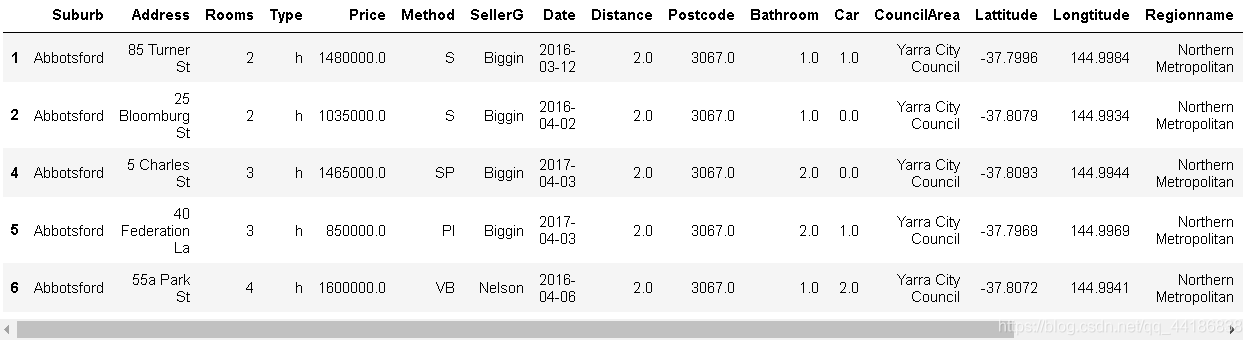
# house
melbourne_data_h=melbourne_data[melbourne_data['Type']=='h']
# condo
melbourne_data_u=melbourne_data[melbourne_data['Type']=='u']
# townhouse
melbourne_data_t=melbourne_data[melbourne_data['Type']=='t']
# house,condo and townhouse price groupby year,求平均
melbourne_data_h_y=melbourne_data_h.groupby('Year').mean()
melbourne_data_u_y=melbourne_data_u.groupby('Year').mean()
melbourne_data_t_y=melbourne_data_t.groupby('Year').mean()
melbourne_data_h_y.head()
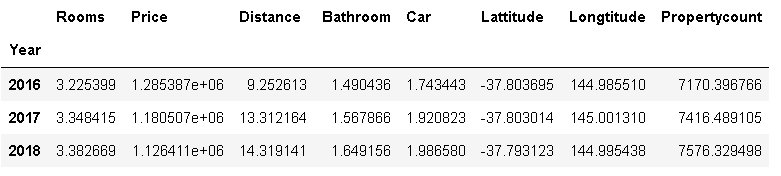
melbourne_data_h_y['Price'].plot(kind='line', color='r',label='House')
melbourne_data_u_y['Price'].plot(kind='line', color='g',label='Condo')
melbourne_data_t_y['Price'].plot(kind='line', color='b',label='Townhouse')
year_xticks=[2016,2017,2018]
plt.ylabel('Price')
plt.xticks(year_xticks)
plt.title('每種型別的房子價格年趨勢')
plt.legend()
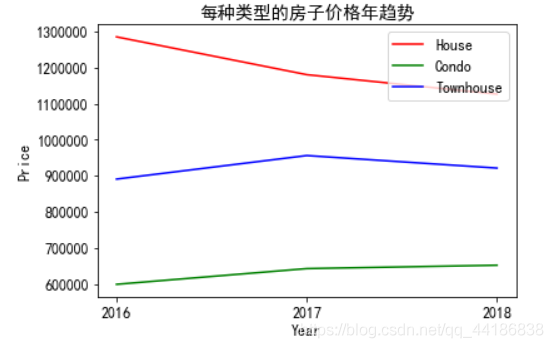
House大幅下跌10萬套,Condo價格緩慢攀升,而Townhouse價格保持穩定,從這張圖上可以看出,預計House會下降,但坡度較小的Townhouse房價會下降,不變的Condo價格會上升,對開發商來說,是時候在2019年建更多的公寓了,購房者的住房預算需要削減,是時候在2019年買房了,
2.2 預測2019年和2020年Southern Metropolitan所有型別的房屋、Southern Metropolitan的Condo和Eastern Metropolitan的Condo價格
melbourne_data.shape
melbourne_data.columns

melbourne_data_South_M=melbourne_data[melbourne_data['Regionname']=='Southern Metropolitan']
melbourne_data_South_M_average=melbourne_data_South_M.groupby(['Year'])['Price'].mean()
X = melbourne_data_South_M[[ 'Year']]
y = melbourne_data_South_M[['Price']]
lm2 = LinearRegression()
lm2.fit(X, y)
lm2.intercept_
lm2.coef_

X_new = pd.DataFrame({'Year': [2019,2020,2021]})
lm2.predict(X_new)

根據這一粗略估算,2019年和2020年墨爾本房屋平均價格將為1557639、1630019,
2.2.1 Southern Metropolitan的Condo價格預測
melbourne_data_SM=melbourne_data[melbourne_data['Regionname']=='Southern Metropolitan']
melbourne_data_SM_u=melbourne_data_SM[melbourne_data_SM['Type']=='u']
melbourne_data_SM_u.shape
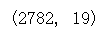
lm1 = smf.ols(formula='Price ~ Year', data=melbourne_data_SM_u).fit()
lm1.params
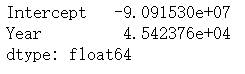
X_new = pd.DataFrame({'Year': [2016,2017,2018,2019,2020,2021]})
lm1.predict(X_new)

# 擬合度
lm1.rsquared

這擬合度,看看就得了,
2.2.2 Eastern Metropolitan的Condo價格預測
melbourne_data_E=melbourne_data[melbourne_data['Regionname']=='Eastern Metropolitan']
melbourne_data_E_u=melbourne_data_E[melbourne_data_E['Type']=='u']
lme = smf.ols(formula='Price ~ Year', data=melbourne_data_E_u).fit()
lme.params

melbourne_data_E_u.shape
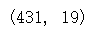
X_new = pd.DataFrame({'Year': [2016,2017,2018,2019,2020,2021]})
lme.predict(X_new)

對于Eastern Metropolitan,預計2016年至2017年價格將增長10%,2018年至2019年價格將增長7.7%,雖然和南部地區相比,這個數字要少一些,
2.3 Seasonal performance
melbourne_data['Month']=pd.DatetimeIndex(melbourne_data['Date']).month
melbourne_data_2016=melbourne_data[melbourne_data['Year']==2016]
melbourne_data_2017=melbourne_data[melbourne_data['Year']==2017]
melbourne_data_2018=melbourne_data[melbourne_data['Year']==2018]
melbourne_data_2016_count=melbourne_data_2016.groupby(['Month']).count()
melbourne_data_2017_count=melbourne_data_2017.groupby(['Month']).count()
melbourne_data_2018_count=melbourne_data_2018.groupby(['Month']).count()
Comparison={2016:melbourne_data_2016.shape,2017:melbourne_data_2017.shape,2018:melbourne_data_2018.shape}
Comparison
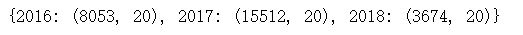
label_2016=['January','March','April','May','June','July','August','September','October','November','December']
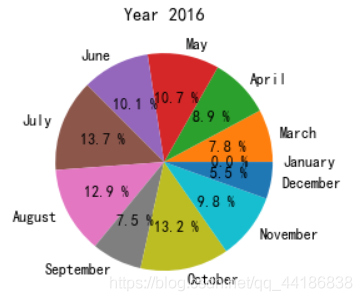
plt.pie(melbourne_data_2016_count['Price'],labels=label_2016,autopct='%.1f %%')
plt.title('Year 2016')
plt.show()
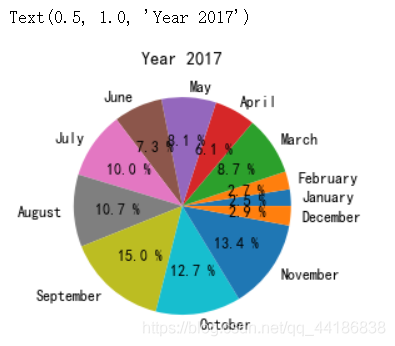
label_2017=['January','February','March','April','May','June','July','August','September','October','November','December']
plt.pie(melbourne_data_2017_count['Price'],labels=label_2017,autopct='%.1f %%')
plt.title('Year 2017')
label_2018=['January','February','March','June','October']
plt.pie(melbourne_data_2018_count['Price'],labels=label_2018,autopct='%.1f %%')
plt.title('Year 2018')
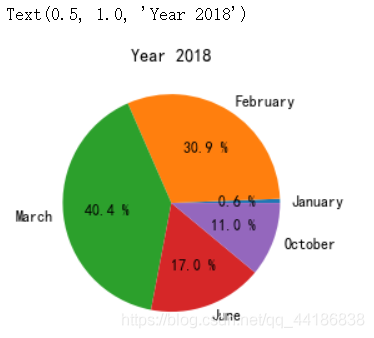
總的來說,2016年和2017年的冬季似乎銷量最少,這意味著從5月到11月房屋銷售將有更多優惠,2018年的資料缺失較多,與其他年份相比只有三分之一左右,因此很難得出結論,
2.4 Region versus Price
# 取個短一點的名字
melbourne_data['Regionabb'] = melbourne_data['Regionname'].map({'Northern Metropolitan':'N Metro',
'Western Metropolitan':'W Metro',
'Southern Metropolitan':'S Metro',
'Eastern Metropolitan':'E Metro',
'South-Eastern Metropolitan':'SE Metro',
'Northern Victoria':'N Vic',
'Eastern Victoria':'E Vic',
'Western Victoria':'W Vic'})
2.4.1每種型別的地區價格變化與年份
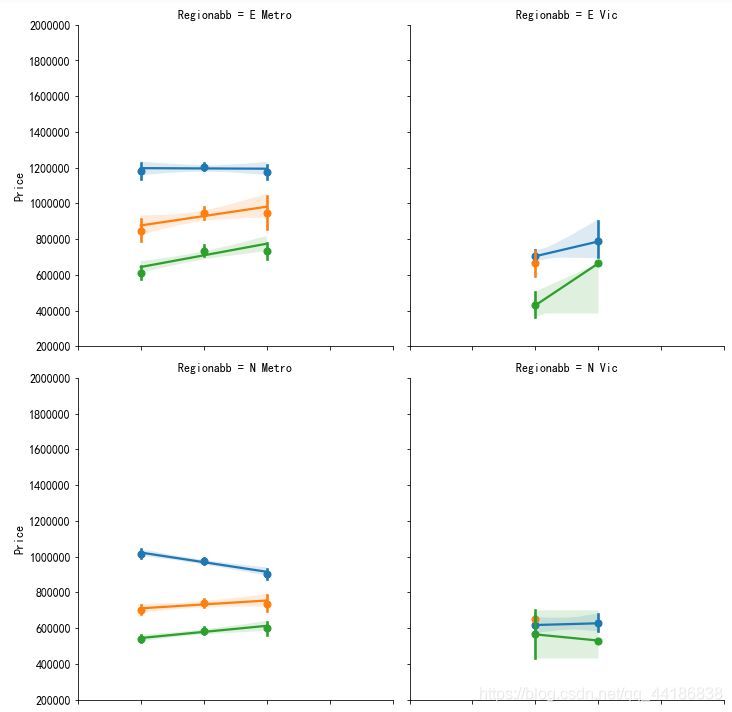
總的來說,東、北、南和西Metropolitan都是受歡迎的地區, 接下來看看每種型別的地區價格,
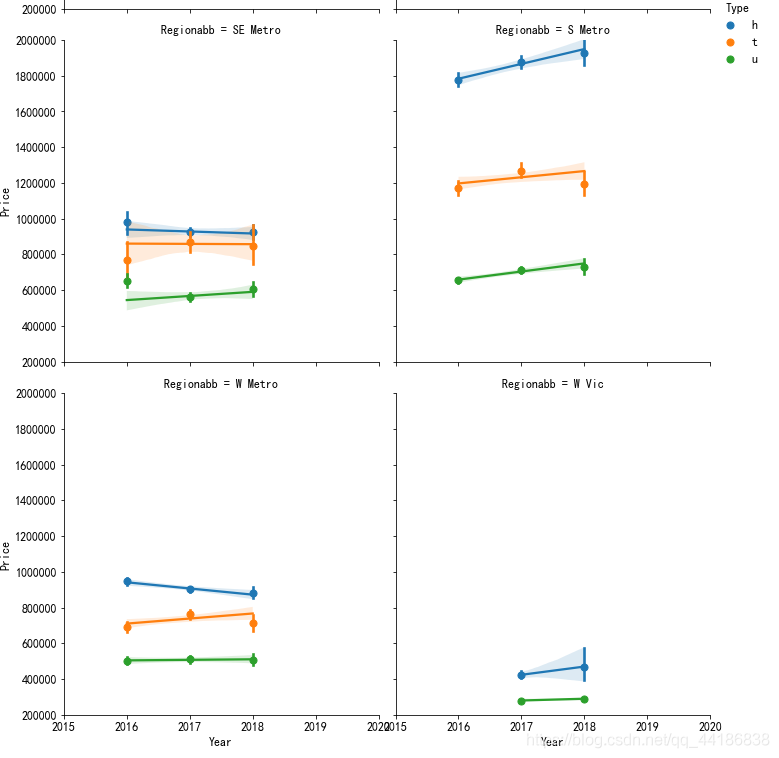
sns.lmplot(x="Year", y="Price",hue="Type", data=melbourne_data,col='Regionabb', x_estimator=np.mean,col_wrap=2)
plt.ylim(200000, 2000000)
plt.xlim(2015,2020)
sns.lmplot(x="Year", y="Price",hue="Type", data=melbourne_data[melbourne_data['Regionabb']=='S Metro'], x_estimator=np.mean);
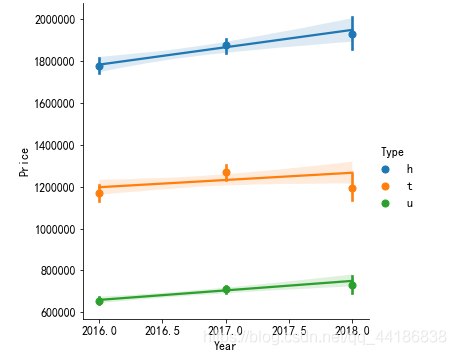
總體而言, Townhouse in E Metro, Condo in East Metro, House in S Metro, Condo in S Metro and Condo in N Metro每年都在增長,
melbourne_data_S=melbourne_data[melbourne_data['Regionabb']=='S Metro']
sns.lmplot(x="Year", y="Price", data=melbourne_data_S[melbourne_data_S['Type']=='u'], x_estimator=np.mean)
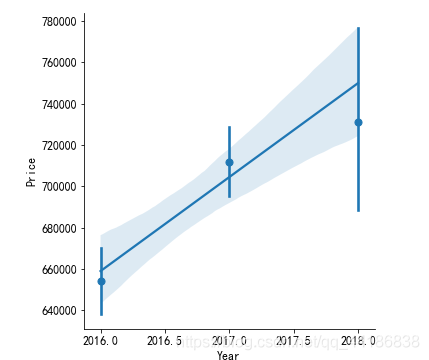
2.4.2 特征工程,以獲得每個地區和型別的年數量增長率和價格增長率
Pct_change=melbourne_data.groupby(['Year','Regionabb','Type'],as_index=False)['Price'].mean()
Pct_change = Pct_change.sort_values(['Regionabb', 'Type','Year']).set_index(np.arange(len(Pct_change.index)))
Pct_change.info()

melbourne_data_count_region_y=melbourne_data.groupby(['Year','Regionabb','Type'],as_index=False)['Price'].count()
melbourne_data_count_region_y = melbourne_data_count_region_y.sort_values(['Regionabb', 'Type','Year']).set_index(np.arange(len(melbourne_data_count_region_y.index)))
melbourne_data_count_region_y.rename(columns={'Price':'Count'}, inplace=True)
def PCTM(gg):
df=pd.DataFrame(gg['Price'].pct_change())
df['Year']=gg['Year']
df['region']=gg['Regionabb']
df['Type']=gg['Type']
df=df[df['Year']!=2016]
return df
2.4.2.1 每個地區和型別的價格增長率超過5%
melboune_growthrate_y_t=PCTM(Pct_change)
melboune_growthrate_y_t1=melboune_growthrate_y_t[melboune_growthrate_y_t['region'].isin(['N Metro','S Metro','E Metro','SE Metro','W Metro','S Metro'])]
melboune_growthrate_y_t1.rename(columns={'Price':'Price Growth Rate'}, inplace=True)
melboune_growthrate_y_t1[melboune_growthrate_y_t1['Price Growth Rate']>0.05]
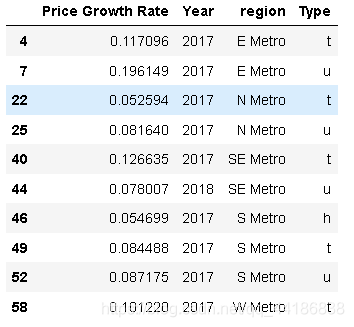
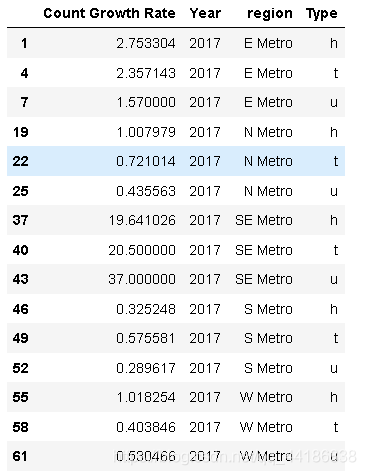
由于2018年大量資料缺失,S Metro的condo在2017年和2018年分別為8.7%和2.7%,如果選擇2017年來看價格的增長,E Metro、SE Metro和S Metro的condo和townhouse、W Metro的townhouse和S Metro的house均呈現超過5%的正增長,展望2018年,人們似乎轉向在SE、E Metro或者S Metro購買更多,
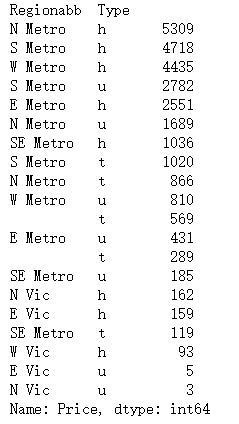
2.4.2.2 按型別劃分,數量最多的20個地區
Sales_count=melbourne_data.groupby(['Regionabb','Type'])['Price'].count()
Sales_count.nlargest(20)
def PCTMC(gg):
df=pd.DataFrame(gg['Count'].pct_change())
df['Year']=gg['Year']
df['region']=gg['Regionabb']
df['Type']=gg['Type']
df=df[df['Year']!=2016]
return df
2.4.2.3 每個地區和型別的計數增長率超過20%
melboune_growthrate_y_c=PCTMC(melbourne_data_count_region_y)
melboune_growthrate_y_c1=melboune_growthrate_y_c[melboune_growthrate_y_c['region'].isin(['N Metro','S Metro','E Metro','SE Metro','W Metro','S Metro'])]
melboune_growthrate_y_c1.rename(columns={'Count':'Count Growth Rate'}, inplace=True)
melboune_growthrate_y_c1[melboune_growthrate_y_c1['Count Growth Rate']>0.2]
2.4.2.4 按年份地區和型別劃分,實際計數超過1000
melboune_count1=melbourne_data_count_region_y[melbourne_data_count_region_y['Regionabb'].isin(['S Metro','E Metro','SE Metro','W Metro','S Metro','N Metro'])]
melboune_count1[melboune_count1['Count']>1000]
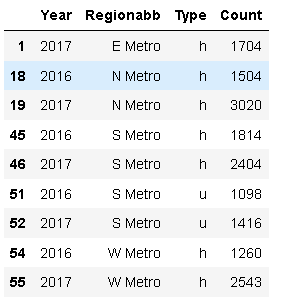
從以上資訊統計的增長百分比和實際銷售額按年度計算,S Metro和N Metro似乎是人們傾向于支付更多,購買更多的地區,但隨著價格不斷上漲,那些住在南部的試圖轉移到E Metro和SE Metro,
本節結論: 1.house方面,S Metro 2017年價格增長5%以上,三年銷售4718套,排名第二;Condo方面,S Metro 2017年銷售2782套,排名第四,價格增長8.7%, 2.E Metro和SE Metro的condo和townhouse潛力很大,現在沒有S Metro那么吸引人,他們的數量增長率超過100%,價格增長率超過8%,
2.5 其他數值特征與價格間的關系
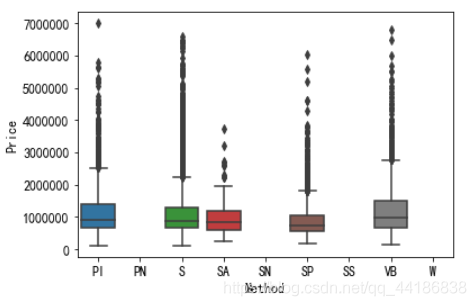
2.5.1 Method vs Price
sns.boxplot(x = 'Method', y = 'Price', data = melbourne_data)
plt.show()
# 銷售方式不影響價格
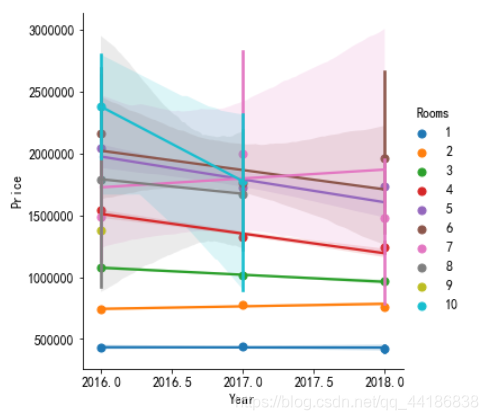
2.5.2 Rooms
sns.lmplot(x="Year", y="Price", hue="Rooms", data=melbourne_data, x_estimator=np.mean)
# impact on Prcie VS Year
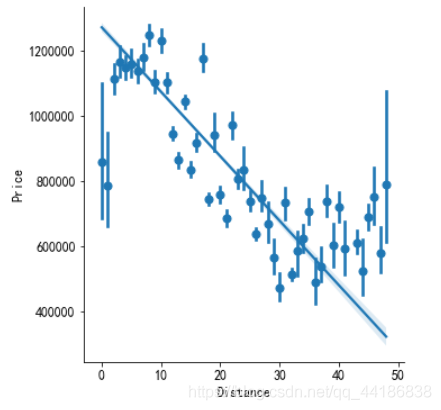
2.5.3 Distance vs Price
結論:離城中心越遠,價格越低,
sns.lmplot(x="Distance", y="Price", data=melbourne_data, x_estimator=np.mean);
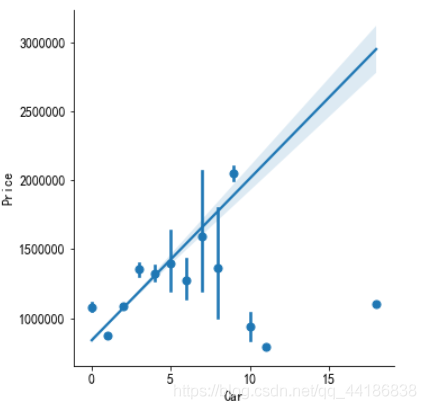
2.5.4 Car spot vs Price
sns.lmplot(x="Car", y="Price", data=melbourne_data, x_estimator=np.mean)
# 車位越多,價格越貴
2.6 Ideal house type
找出最理想的房子型別,
2.6.1 在S Metro,按型別、rooms、bathroom統計排名前10的房子型別
Ideal_House=melbourne_data.groupby(['Regionabb','Type','Rooms','Bathroom'])['Price'].count()
Ideal_House.loc[['S Metro'],'h'].nlargest(10)
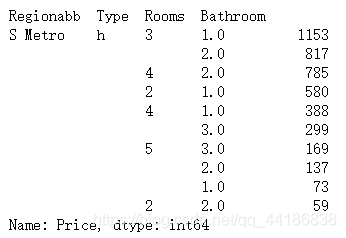
結論:在S Metro,3房1衛或2衛的房子和4房2衛的房子銷量最大,
2.6.2 按型別、rooms、bathroom統計排名前10的房子型別
Ideal_House.nlargest(10)
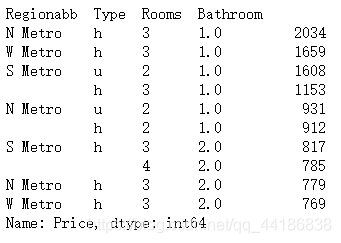
結論:其中,N Metro房最受歡迎,W Metro緊隨其后,一般來說,house比其他型別的好,擁有兩間臥室和一間浴室的S Metro的condo被列為銷量前三名,
2.6.3 在E Metro的condo中,按型別、rooms、bathroom統計排名前10的房子型別
Ideal_House.loc[['E Metro'],'u'].nlargest(10)

E Metro區最好的公寓型別是兩室一廳,
2.7 關系熱圖
corrmat=melbourne_data.corr()
fig,ax=plt.subplots(figsize=(12,10))
sns.heatmap(corrmat,annot=True,annot_kws={'size': 12})
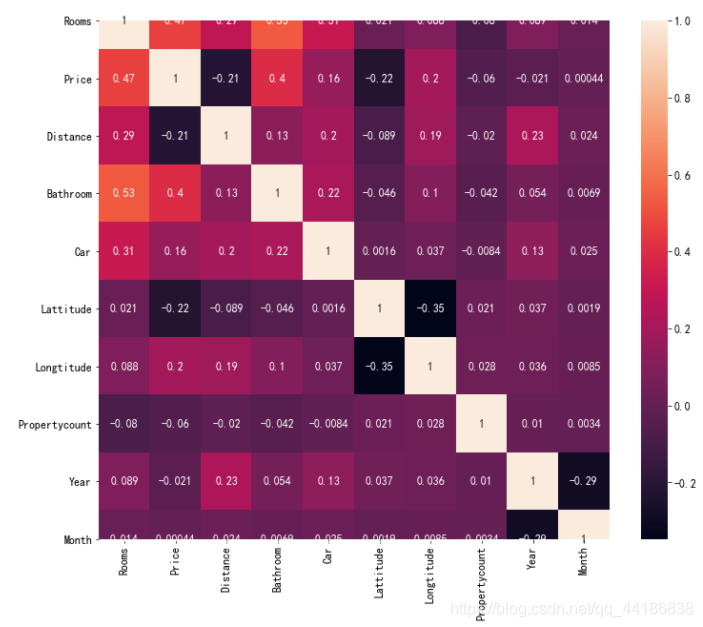
與其他因素相比,rooms和bathroom與price的相關性最高,
3 最終結論
- 從2.1.1可以得出:house一般會下降,condo價格會上升,這意味著投資公寓會更好,
- 從2.4得出:在hous方面,S Metro 2017年價格增長超過5%,三年銷售4718套,排名第二;在condo方面,S Metro 2017年銷售2782套,排名第四,價格增長8.7%,
- 從2.4得出:E Metro和SE Metro的condo和townhouse潛力很大,現在沒有S Metro那么吸引人,增長率超過100%,價格增長率超過8%,
- 從2.6得出,南方地鐵的condo排在第三位,雖然N Metro和W Metro的house數量最多,但它們的價格正在下降,如第2.4節sns.lmplot所示,從數量上看,S Metro的condo具有巨大的市場潛力,因為其數量排名第三,價格在第2.4節中呈現出逐年上升的趨勢,S Metro的house也有很大的市場,但增長率不如condo,
- 最后在結合理想戶型,2rooms1bathroom的S Metro的condo將被推薦給投資者或開發商,
另外為方便需要的朋友運行代碼,我也把完整的代碼和資料檔案放到了網盤上,需要的朋友自取,
鏈接:https://pan.baidu.com/s/1qw-fwmykg6-G3RmLBKUT7A
提取碼:1024
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290209.html
標籤:python
上一篇:【超詳細講解】基于pandas、matplotlib和seaborn進行資料分析實戰
下一篇:怎樣學好Java語言