前言
爬蟲,全稱網路爬蟲,就是通過技術手段從網路獲取資料的程式或者腳本
人生苦短,我選python,本次就用python來進行實作對一個壁紙網站的圖片下載
本篇文章就是直接爬蟲實戰,通過本文,帶你了解requests庫的基本使用,并且完成壁紙網站的圖片爬取
宣告:博主攻城獅白玉的本篇博文只用于對于爬蟲技術的學習交流,如果侵犯到相關網站利益,請聯系我洗掉博文,造成不便還請見諒,希望各位同學在學習的時候不要過于頻繁的去請求,
一、requests庫介紹
Requests庫是python一個很好用的http請求庫,封裝得很好~在我們爬蟲的時候常常也會用到,
Requests的官方介紹說到,讓HTTP服務人類,有一說一,這是個非常容易使用的庫,本次咱們的爬蟲也會用到這個庫,
關于requests庫的介紹,可以看一下官方檔案
Requests: 讓 HTTP 服務人類 - Requests 2.18.1 檔案
使用前記得安裝requests庫
pip install requests
二、網站分析
進入目標網站
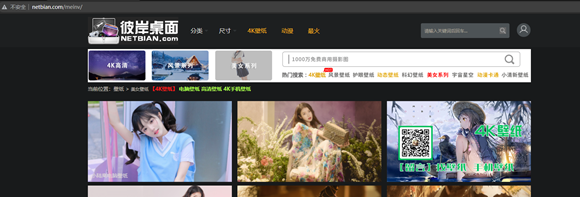
隨便點開一張圖,查看它的url,http://www.netbian.com/desk/23744.htm
先留意一下這個網址,后面會用到

回到瀏覽器,打開F12,通過目標元素檢查工具,點擊剛剛我們點過的圖片,通過它的元素我們可以知道a標簽里的屬性值href的鏈接就是上面我們訪問圖片的鏈接地址
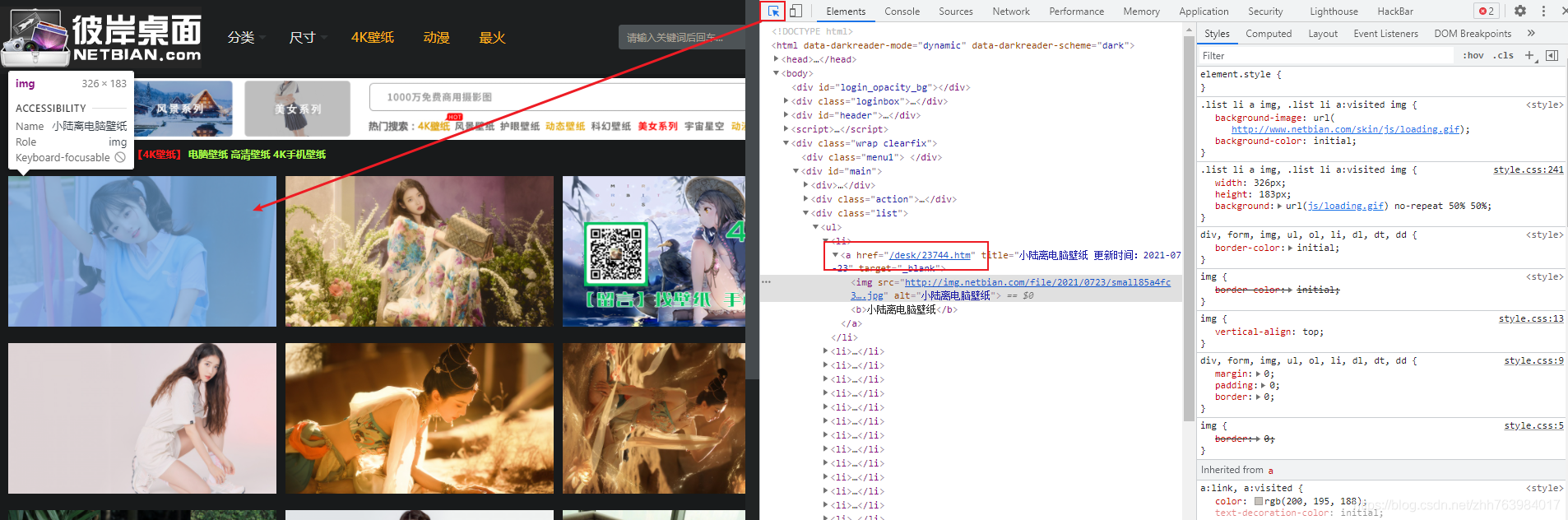
我們在大圖的頁面,同樣用f12點擊一下,找到圖片的鏈接地址
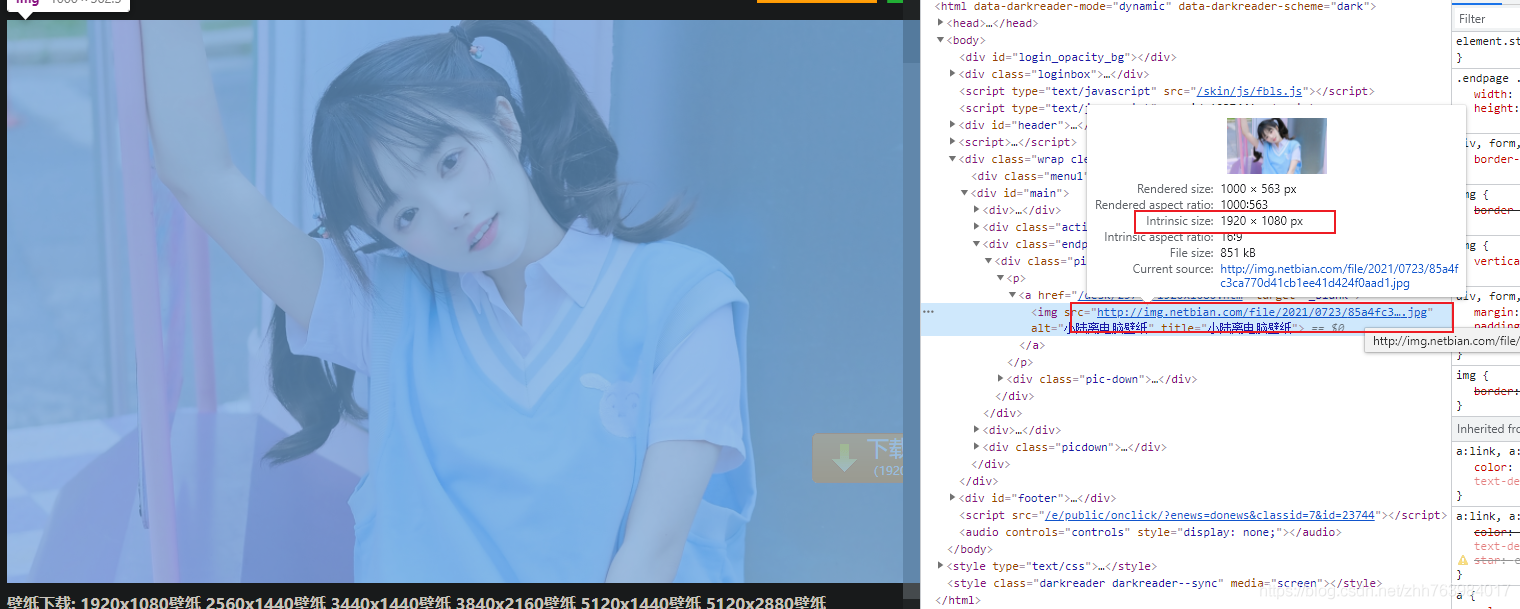
訪問圖片鏈接發現是咱們要的大圖,至此,對于網站的分析完畢,

三、任務分析
綜上所述,咱們目標網站是一個壁紙圖片網站,編程做到的步驟如下:
- 訪問首頁
- 定位到每個圖片的詳情鏈接
- 訪問詳情鏈接
- 定位到圖片對應的大圖鏈接,下載,保存圖片
看起來是不是很容易,開干
四、編程實作
4.1 訪問首頁
import requests
url = 'http://www.netbian.com/meinv/'
resp = requests.get(url)
resp.encoding = 'gbk'
#
with open('index.html', 'wb') as f:
f.write(resp.content)通過requests庫發起get請求,請求壁紙網站的首頁,并把結果保存在index.html檔案里面
打開保存的檔案一看,我們把首頁給下載下來了,
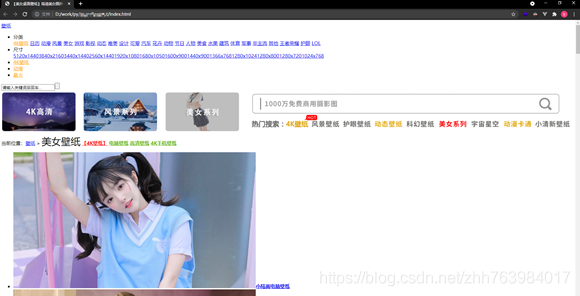
4.2 定位元素
這里我們通過xpath方式,這里用到的是lxml庫,不懂lxml庫的話,參考下文
【Python】爬蟲決議利器Xpath,由淺入深快速掌握(附原始碼例子)
PS:谷歌渲染的頁面的xpath和requests請求回來的xpath會有不一樣,有時需要保存下來進行xpath分析
對于元素進行定位,把a標簽的href值全部拿出來,而且也把對應的名稱取出來

tree = etree.HTML(resp.content)
node_list = tree.xpath('/html/body/div[2]/div[2]/div[3]/ul/li')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/@href')) > 0:
sub_url = node.xpath('./a/@href')[0]
if len(node.xpath('./a/@href')) > 0:
title = node.xpath('./a/b/text()')[0]
sub_url_list.append((sub_url, title))4.3 訪問詳情頁
base_url = 'http://www.netbian.com/'
for sub_url, title in sub_url_list:
s_page = base_url + sub_url
s_resp = requests.get(s_page)
with open('s.html', 'wb') as f:
f.write(s_resp.content)4.4 定位圖片鏈接并下載
img = s_tree.xpath('/html/body/div[2]/div[2]/div[3]/div/p/a/img/@src')[0]
suffix = img.split('.')[-1]
img_content = requests.get(img).content
with open(f'./image/{title}.{suffix}', 'wb') as f:
f.write(img_content)
f.close()下載完效果圖
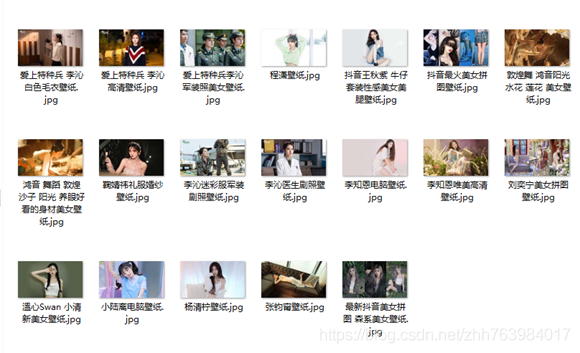
4.5 完整原始碼
import requests
from lxml import etree
import time
'''
目標網站是一個圖片網站
1.訪問首頁
2.定位到每個圖片的下載鏈接
3.定位到每個圖片對應的大圖鏈接
4.下載,保存圖片
'''
if __name__ == '__main__':
t1 = time.time()
url = 'http://www.netbian.com/meinv/'
resp = requests.get(url)
resp.encoding = 'gbk'
with open('index.html', 'wb') as f:
f.write(resp.content)
tree = etree.HTML(resp.content)
node_list = tree.xpath('/html/body/div[2]/div[2]/div[3]/ul/li')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/@href')) > 0:
sub_url = node.xpath('./a/@href')[0]
if len(node.xpath('./a/@href')) > 0:
title = node.xpath('./a/b/text()')[0]
sub_url_list.append((sub_url, title))
#
base_url = 'http://www.netbian.com/'
for sub_url, title in sub_url_list:
s_page = base_url + sub_url
s_resp = requests.get(s_page)
s_tree = etree.HTML(s_resp.content)
img = s_tree.xpath('/html/body/div[2]/div[2]/div[3]/div/p/a/img/@src')[0]
suffix = img.split('.')[-1]
img_content = requests.get(img).content
with open(f'./image/{title}.{suffix}', 'wb') as f:
f.write(img_content)
f.close()
t2 = time.time()
print(t2-t1)總結
媽媽再也不用擔心我的學習了,
寫在后面
如果覺得有用的話,麻煩一鍵三連支持一下攻城獅白玉,并把本文分享給更多的小伙伴,你的簡單支持,我的無限創作動力
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290283.html
標籤:python
上一篇:【python實戰】B站彈幕是如何看待“法外狂徒張三”的?詞云分析
下一篇:JAVA 四種參考型別