目錄
- 前言
- 一、Java面試之MyBatis
- 什么是MyBatis?
- 講下MyBatis的快取
- Mybatis是如何進行分頁的?分頁插件的原理是什么?
- 簡述Mybatis的插件運行原理,以及如何撰寫一個插件?
- Mybatis動態sql是做什么的?都有熟些動態sql?能簡述一下動態sql 的執行原理不?
- #{}和${}區別是?
- 為什么說Mybatis是半百動ORM映射工具?它與全自動的區別在熟里?
- Mybatis是否支持延遲加裁?如果支持,它的實作原理是什么?
- MyBatis的好處是什么?
- 簡述Mybatis的Xml映射檔案和Mybatis內部資料結構之間的映射關系?
- 什么是MyBatis的介面系結,有什么好處?
- 介面系結有幾種實作方式,分別是怎么實作的?
- 什么情況下用注解系結,什么情況下用xml系結?
- MyBatis實作一對'一有幾種方式?具體怎么操作的?
- MyBatis里面的動態Sql是怎么設定的?用什么語法?
- Mybatis是如何將SQI執行結果封裝為目標物件并回傳的?都有哪 些映射形式?
- Xml映射檔案中,除了常見的select insert updae delete標簽之 外,還有哪些標簽?
- Mybatis中如何指定使用型一種Executor執行器?
- Mybatis執行批量插入,能回傳資料庫土鍵串列嗎?
- Mybatis是否可以映射Enum列舉類?
- 如何獲家自動生成的(主)鍵值?
- 在mapper中如何傳遞多個引數?
- resultType resultMap的區別?
- 二、Java面試之Dubbo
- Dubbo是什么?
- Dubbo核心部分包含哪些東西?
- Dubbo能做什么?
- Dubbo框架設計分為哪十層?
- 和淘寶HSF相比,Dubbo的特點是什么?
- Dubbo使用哪些場景?
- 三、Java面試之微服務
- 微服務有哪些優勢?
- 微服務核心部件有哪些
- 微服務總體架構?
- Dubbo與SpringCloud性能對比?
- 四、Java面試之Linux
- 絕對路徑用什么符號表示?當前目錄、上層目錄用什么表示?主目錄用什么表示? 切換目錄用什么命令?
- 怎么查看當前行程?怎么執行退出?怎么查看當前路徑?
- 怎么清屏?怎么退出當前命令?怎么執行睡眠?怎么查看當前用戶 id?查看指定幫助用什么命令?
- Ls 命令執行什么功能?可以帶哪些引數,有什么區別?
- 建立軟鏈接(快捷方式),以及硬鏈接的命令?
- 目錄創建用什么命令?創建檔案用什么命令?復制檔案用什么命令?
- 查看檔案內容有哪些命令可以使用?
- 隨意寫檔案命令?怎么向螢屏輸出帶空格的字串,比如 ” hello world ” ?
- 終端是哪個檔案夾下的哪個檔案?黑洞檔案是哪個檔案夾下的哪個命令?
- 移動檔案用哪個命令?改名用哪個命令?
- 使用哪一個命令可以查看自己檔案系統的磁盤空間配額呢?
- 五、Java面試之Nginx
- 什么是Nginx快取?
- 如何啟動快取?
- Nginx是用來干嘛的?
- Nginx優勢?
- Nginx如何實作高并發?
- Nginx為何不使用多執行緒?
- Nginx如何處理請求?
- 為什么要做動靜分離?
- Nginx負載均衡的幾種常用方式?
- Nginx常用優化配置?
- Nginx中正向代理與反向代理的區別?
- 六、Java面試題之總結 ?
- jdk1.7到jdk1.8 Map發生了什么變化(底層)?
- ConcurrentHashMap
- 并行跟并發有什么區別?
- 什么是中間件?
- 如果叫你自己設計一個中間件,你會如何設計?
- ThreadLock用過沒有,說說它的作用?
- Hashcode()和equals()和==區別?
- mysql優化會不會,mycat分庫,垂直分庫,水平分庫?
- 分布式事務解決方案?
- sql陳述句優化會不會,說出你知道的?
- mysql的存盤引擎了解過沒有?
- 紅黑樹原理?
前言
學而不思則罔 思而不學則殆 大家好 眾所周知 IT行業發展史日新月異 我們程式員也是 不是在面試 就是在面試的路上 今天博主為大家爆肝總結了常見的一些面試題 希望對大家有所幫助
直接奉上博主十年珍藏的面試題庫 永久有效 免費下載
鏈接:面試題50套
提取碼:oy80
一、Java面試之MyBatis
什么是MyBatis?
MyBatis是一個可以自定義SQL存盤程序和高級映射的持
久層坷猬
講下MyBatis的快取
MyBatis的快取分為一級快取和二級快取,一級快取放在session里面, 默認就有,二級快取放在它的命名空間星,默認是不打開的,使用二級快取屬性 類需要實作Serializable序列化介面(可用來保存物件的狀態),可在它的映 射檔案中配置
Mybatis是如何進行分頁的?分頁插件的原理是什么?
1.Mybatis使用RowBounds物件進行分頁,也可以直接撰寫SQL實作分 頁,也可以使用Mybatis的分頁插件,
2.分頁插件的原理:實作Mybatis提供的介面,實作自定義插件,在插件的 攔截方法內攔截待執行的SQL,然后重寫SQL
舉例:select * from student,攔截.SQI 后重寫為:
select t. * from (select * from student) t limit 0, 10
簡述Mybatis的插件運行原理,以及如何撰寫一個插件?
1.Mybatis 僅可以撰寫針對ParameterHandler.ResultSetHandler. StatementHandler. Executor這4科介面的插件,Mybatis通過動態代理, 為需要攔截的介面生成代理物件以實作介面方法攔截功能,每當執行這4種接 口物件的方法時,就會進入攔截方法,具體就是InvocationHandler的 invoke,方法,當然,只會攔截那些你指定需要攔截的方法,
2.實作Mybatis的Interceptor介面并復寫intercept0方法,然后在給插 件撰寫注解,指定要攔截熟一個介面的哪些方法即可,記住,別忘了在組態檔中配置你撰寫的插件,
Mybatis動態sql是做什么的?都有熟些動態sql?能簡述一下動態sql 的執行原理不?
1)Mybatis動態SQL可以讓我們在Xml映射檔案內,以標簽的形式撰寫動態 SQL,完成邏輯判斷和動態拼接SQL的功能,
2) Mybatis提供了 9種動態SQI標簽:
trim | where | set | foreach | if | choose | when | other | wise |bind
#{}和${}區別是?
1.#{}是預編譯處理,而${}是字串替換
2.Mybatis在處理#{}時, 會將sql中#{}替換為?好,呼叫PrepareStatement的set方法來賦值
3.Mybatis在處理
時
,
就
是
把
{}時,就是把
時,就是把{}替換成變數的值,
4.使用#{}可以有效的防止SQL注入,提高系統安全性,
為什么說Mybatis是半百動ORM映射工具?它與全自動的區別在熟里?
Hibernate屬于全自動ORM映射工具,使用Hibernate查詢關聯物件或者 關聯集合物件對,可以根據物件關系模型直接獲家,所以它是全自動的,而 Mybatis在查詢關聯物件或關聯集合物件時,需要手動撰寫SQL來完成,所 以,稱之為半百動ORM映射工具,
Mybatis是否支持延遲加裁?如果支持,它的實作原理是什么?
1.Mybatis僅支持association關聯物件和collection關聯集合物件的延 遲加戴,association指的就是一對’ 一,collection指的就是一對多查詢,在 Mybatis組態檔中,可以配置是否啟用延遲加載lazjrLoadingEnabled=true |false,
2.它的原理是,使用CGLIB創建目標物件的代理物件,當呼叫目標方法時,進入攔截器方法,比如呼叫a. getB(). getNameO ,攔截器invoke,方法發現 a. getB()*null值,那么就會單獨發送事先保存好的查詢關聯B物件的 SQI,把B查詢上來,然后呼叫a.setB(b),于是a的物件b屬性就有值了, 接著完成a.getBO.getYameO方法的呼叫,這就是延遲加裁的基本原理,
MyBatis的好處是什么?
1)MyBatis把SQI陳述句從Java源程式中獨立出來,放在單獨的XML檔案中 撰寫,給程式的維護帶來了很大便利,
2) MyBatis封裝了底層JDBC API的呼叫細節,并能自動將結果集轉換成Java Bean物件,大大簡化了 Java資料庫編程的重復作業,
3)因為MyBatis需要程式員官己去撰寫sql陳述句,程式員可以結合資料庫自 身的特點靈活控制sql陳述句,因此能夠實作比Hibernate等全自動orm框架更高的查詢效率,能夠完成復雜查詢,
簡述Mybatis的Xml映射檔案和Mybatis內部資料結構之間的映射關系?
Mybatis將所有Xml配置資訊都封裝到All-In-One重量級對?象
Configuration內部,在Xml映射檔案中,標簽■會被決議為 ParameterMap物件,其每個子元素會被決議為ParameterMapping物件, 標簽會被決議為ResultMap物件,其每個子元素會被決議為 ResultMapping 物件,每一個> 標簽 均會被決議為MappedStatement物件,標簽內的sql會被決議為BoundSql物件,
什么是MyBatis的介面系結,有什么好處?
介面映射就是在MyBatis中任意定義介面,然后把介面里面的方法和SQL 陳述句系結,我們直接呼叫介面方法就可以,這樣比起原來了 SqlSession提供的 方法我們可以有更加靈活的選擇和設定.
介面系結有幾種實作方式,分別是怎么實作的?
介面系結有兩種實作方式,一種是通過注解系結,就是在介面的方法上面 加上@Select@Update等注解星面包含SQI陳述句來系結,另外一拜就是逋過 xml里面寫SQL來系結,在這拜情況下,要指定xml映射檔案里面的 namespace必須為介面的全路徑名.
什么情況下用注解系結,什么情況下用xml系結?
當Sql陳述句比較簡單時候,用注解系結;當SQL陳述句比較復雜時候,用xml 系結,一般用xml系結的比較多
MyBatis實作一對’一有幾種方式?具體怎么操作的?
有聯合查詢和嵌套查詢,聯合查詢是幾個表聯合查詢,只查詢一次,通過在 resultMap星面配置association節點配置一對一的類就可以完成;嵌套查詢 是先查一個表,根據這個表里面的結果的外鍵id,去再另外一個表里面查詢資料, 也是通過association配置,但另外一個表的查詢通過select屬性配置,
MyBatis里面的動態Sql是怎么設定的?用什么語法?
MyBatis里面的動態Sql 一般是逋過if節點來實作,通過OGNL語法來實 現,但是如果要寫的完整,必須配合where,trim節點,where節點是判斷包含節 點有內容就插入where,否則不插入,trim節點是用來判斷如果動態陳述句是以 and或or開始,那么會自動把這個and或者or型掉,
Mybatis是如何將SQI執行結果封裝為目標物件并回傳的?都有哪 些映射形式?
1.使用< resultMap>標簽,逐一定義列名和物件屬性名之間的映射關系,
2.使用SQI列的別名功能,將列別名書寫為物件屬性名,比如T_NAME AS NAME,物件屬性名一般是name,小寫,但是列名不區分大小寫,Mybatis 會忽略列名大小寫,智能找到與之對■應物件屬性名,你甚至可以寫成T_NAME AS NaMe, Mybatis 一樣可以正常作業,有了列名與屬性名的映射關系后,Mybatis逋過反射創建物件,同時使用反射 給物件的屬性逐一賦值并回傳,那些找不到映射關系的屬性,是無法完成賦值 的,
Xml映射檔案中,除了常見的select insert updae delete標簽之 外,還有哪些標簽?
還有很多其他的標簽,< resultMap><parameterMap>
<SQ1>< selectKey> ,加上動態SQI的9個標簽,
trim where set foreach if choose when otherwise bind 等,其中<SQL>為 sql片段標簽,通過< include>標筌引入sql片段,< selectKey>為不支持目 官的主鍵生成策略標簽,
Mybatis中如何指定使用型一種Executor執行器?
在Mybatis組態檔中,可以指定默認的ExecutorType執行器型別,也 可以手動給DefaultScjlSessionFactory的創建SqlSession的方法傳遞 ExecutorType 型別引數
Mybatis執行批量插入,能回傳資料庫土鍵串列嗎?
能,JDBC都能,Mybatis當然也能
Mybatis是否可以映射Enum列舉類?
Mybatis可以映射列舉類,不單可以映射列舉類,Mybatis可以映射任何 物件到表的一列上,映射方式為自定義一TypeHandler,實作TypeHandler 的 setParameter()和getResult()介面方法,TypeHandler 有兩個作用,一是 完成從javalype至jdbcType的轉換,二是完成jdbcType至javaType的 轉換,體現為setParameter()和getResult()兩個方法,分別代表設置SQL問
號占位將引數和獲取列查詢結果,
如何獲家自動生成的(主)鍵值?
組態檔設定usegeneratedkejrs為true
在mapper中如何傳遞多個引數?
1)直接在方法中傳遞引數,xml檔案用#{0} #{1}來獲取
2)使用@param注解:這樣可以直接在xml檔案中通過#{name}來獲取
resultType resultMap的區別?
1.類的名字和資料庫相同時,可以直接設定resultType引數
為Pojo類
2.若不同,需要設定resultMap將結果名字和Pojo名字進行轉換
二、Java面試之Dubbo
Dubbo是什么?
Dubbo是一個分布式服務框架,致力于提供高性能和透明化的RPC遠程服務調 用方案,以及SOA服務治理方案,
簡單的說,Dubbo就是個服務框架,如果沒有分布式的需求,其實是不需要用 的,只有在分布式的時候,才有Dubbo這樣的分布式服務框架的需求,并且本 質上是個服務呼叫的東東,說白了就是個遠程服務呼叫的分布式框架(告別W納 Service模式中的WSdl,以服務者與消費者的方式在Dubbo上注冊),
Dubbo核心部分包含哪些東西?
1.遠程通訊:
提供對多種基于長連接的NIO,框架抽象封裝,包括多種執行緒模型,序列化,以 及“請求-回應,模式的資訊交換方式,
2.集群容錯:
提供基于介面方法的透明遠程程序呼叫,包括多協議支持,以及軟負載均衡,失 敗容錯,地址路由,動態配置等集群支持,
3.自動發現
基于注冊中心目錄服務,使服務消費方能動態的查找服務提供方,使地址透明, 使服務提供方可以平滑增加或減少機器,
Dubbo能做什么?
1.透明化的遠程癱呼叫
就像呼叫本地方法一樣呼叫遠程方法,只需簡單配置,沒有任何API侵入,
2.軟負載均衡及容錯機制
可在內網替代F5等硬體負載均衡器,降低成本,減少單點,
3.服務自動注冊與發現
不再需要寫死服務提供方地址,注冊中心基于介面名查詢服務提供者的IP地址, 并且能夠平滑添加或洗掉服務提供者,
Dubbo采用全spring配置方式,透明化接入應用,對應用沒有任何API侵入, 只需用Spring加載Dubbo的配置即可,Dubbo基于Spring的Schema擴展 進行加載,
Dubbo框架設計分為哪十層?
1.服務介面層(Service):該層是與實際業務邏輯相關的,根據服務提供 方和服務消費方的業務設計對應的介面和實作,
2.配置層(Config):對外配置介面,以ServiceConfig和
RefererceConfig為中心,可以直接new配置類,也可以通過spring解 析配置生成配置類,
3.服務代理層(Proxy):服務介面透明代理,生成服務的客戶端Skeleton和服務器端Ske/eto八,以ServiceProxy為中心,擴展介面為 ProxyFactory
4.服務注冊層(Registry):封裝服務地址的注冊與發現,以服務URL 為中心,擴展介面為 RegistryFactory、Registry 和RegistryService, 可能沒有服務注冊中心,此時服務提供方直接暴露服務,
5.集群層(Cluster):封裝多個提供者的路由及負載均衡,并橋接注冊中 心,以Invoker 為中心,擴展介面為 Cluster、Directory、Router 、LoadBanlance,將多個服務提供方組合為一個服務提供方,實作對服務消 費方來透明,只需要與一個服務提供方進行互動,
6.監控層(Monitor):RPC呼叫次數和呼叫時間監控,以Statistics 為中心,擴展介面為 MoitorFactory、Monitor、MonitorService
7.遠程呼叫層(Protocol):封將RPC呼叫,以Invocation和Result 為中心,擴展介面為 Protocol、 Invoker和Exporter,Protocol是服務域,它是Invoker暴露和參考的主功能入口,它負責(Invoker的生命周期 管理,Invoker是物體域,它是Dubbo,的核心模型,其它模型都向它靠擾, 或轉換成它,它代表一個可執行體,可向它發起Meke呼叫,它有可能是 一個本地的實作,也可能是一個遠程的實作,也可能一個集群實作,
8.資訊交換層(Exchange):封裝請求回應模式,同步轉異步,以Request 和Response為中心,擴展介面為Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer
9.網路傳輸層(Transport):抽象mina和netty為統一介面,以Message 為中心,擴展介面為Channel、Transporter、Client、Server和Codec
10.資料序列化層(Serialize) :可復用的一些工具,擴展介面為Serialization 、ObjectInput、ObjectOutput和ThreadPool
和淘寶HSF相比,Dubbo的特點是什么?
1.Dubbo比HSF的部署方式更輕量
HSF要求使用指定的JBoss等容器,還需要在JBoss等容器中加入包擴展, 對用戶運行環境的侵入性大,如果你要運行在Weblogic或Websphere等其它 容器上,需要自行擴展容器以兼容HSF的ClassLoader加載,而Dubbo沒有任何要求,可運行在任何Java環境中,
2 .Dubbo比HSF的擴展性更好,很方便二次開發
一個框架不可能覆寫所有需求,Dubbo始終保持平等對待第三方理念,即所有 功能,都可以在不修改Dubbo原生代碼的情況下,在外圍擴展,包括Dubbo自己內置的功能,也和第三方一樣,是通過擴展的方式實作的,而HSF如果你 要加功能或替換某部分實作是很困難的,比如支付寶和淘寶用的就是不同的
HSF分支,因為加功能時改了核心代碼,不得不拷一個分支單獨發展,HSF現 階段就算開源出來,也很難復用,除非對架構重寫,
3.Dubbo比HSF功能更多
除了ClassLoader隔離 Dubbo基本上是HSF的超集 Dubbo也支持更多協議 更多注冊中心的集成 以適應更多的網站架構
Dubbo使用哪些場景?
1.RPC分布式服務
2.配置管理
3.服務依賴
4.服務擴容
三、Java面試之微服務
微服務有哪些優勢?
1.降低復雜度(將耦合在一起的復雜業務拆分為單個服務)
2.可獨立部署(降低測驗作業了以及服務發布的風險)
3.容錯(某一主鍵發生故障 故障會被隔離再單個服務中)
4.擴展
微服務核心部件有哪些
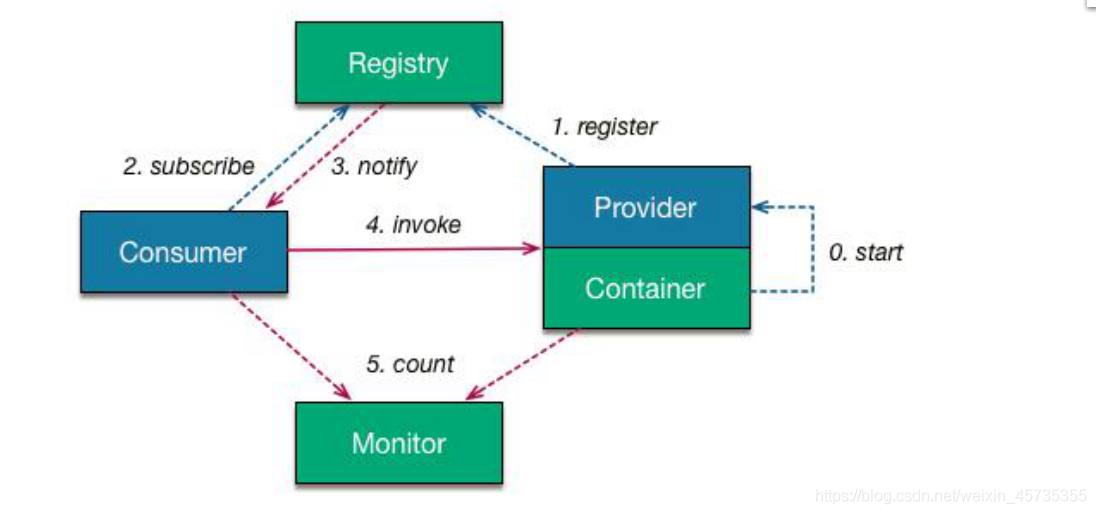

微服務總體架構?
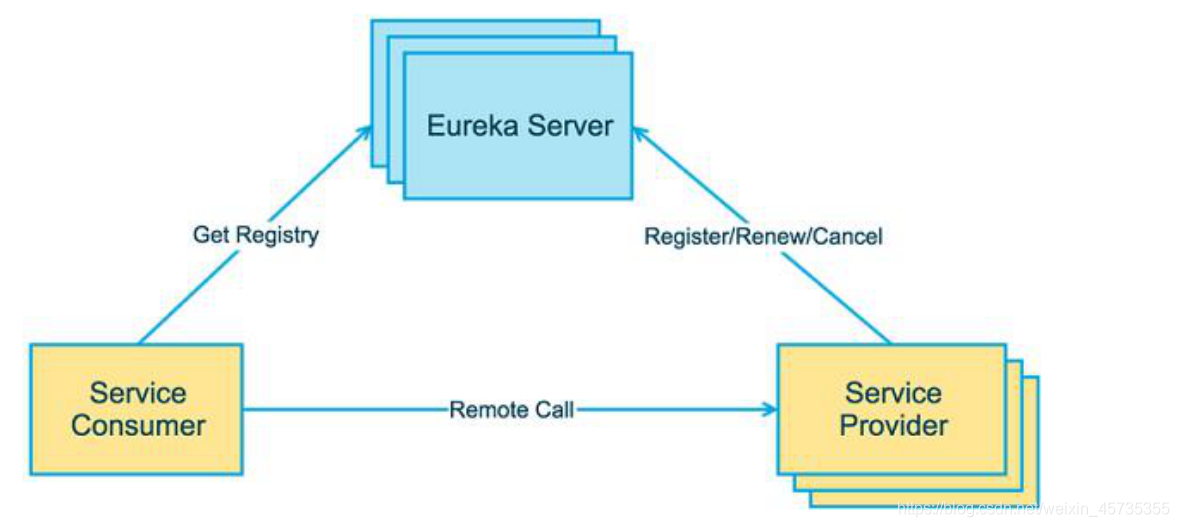
Service Provider:暴露服務提供方
Service Consumer:呼叫遠程服務的服務消費方
Eureka Server:服務注冊中心和服務發現中心
Dubbo與SpringCloud性能對比?
使用一個Pojo物件包含10個屬性 請求10萬次 Dubbo和SpringCloud在不同的執行緒數量下每次請求耗時(ms)如下:
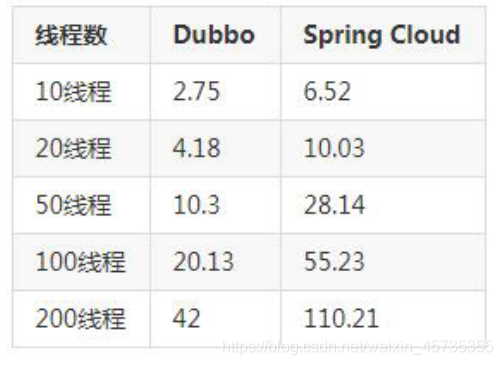
結論:客戶端和服務端配置均采用阿里云ECS服務器 4核8G配置 Dubbo采用默認dubbo協議 dubbo支持各種通信協議 而且消費方使用長鏈接方式互動 通訊速度略勝SpringCloud 如果對于系統的相應時間有嚴格要求 長鏈接更合適
四、Java面試之Linux
絕對路徑用什么符號表示?當前目錄、上層目錄用什么表示?主目錄用什么表示? 切換目錄用什么命令?
絕對路徑:如/etc/init.d
當前目錄和上層目錄:./ …/
主目錄:~/
切換目錄:cd
怎么查看當前行程?怎么執行退出?怎么查看當前路徑?
查看當前行程:ps
執行退出:exit
查看當前路徑:pwd
怎么清屏?怎么退出當前命令?怎么執行睡眠?怎么查看當前用戶 id?查看指定幫助用什么命令?
清屏:clear
退出當前命令:ctrl+c 徹底退出
執行睡眠 :ctrl+z 掛起當前行程fg 恢復后臺
查看當前用戶 id: ” id “ :查看顯示目前登陸賬戶的 uid 和 gid 及所屬分組及用戶名
查看指定幫助:如 man adduser 這個很全 而且有例子;adduser --help 這個告訴你一些常用引數;info adduesr;
Ls 命令執行什么功能?可以帶哪些引數,有什么區別?
ls 執行的功能:列出指定目錄中的目錄,以及檔案
哪些引數以及區別:a 所有檔案l 詳細資訊,包括大小位元組數,可讀可寫可執行的權限等
建立軟鏈接(快捷方式),以及硬鏈接的命令?
軟鏈接:ln -s slink source
硬鏈接:ln link source
目錄創建用什么命令?創建檔案用什么命令?復制檔案用什么命令?
創建目錄:mkdir
創建檔案:典型的如 touch,vi 也可以創建檔案,其實只要向一個不存在的檔案輸出,都會創建
檔案
復制檔案:cp 7. 檔案權限修改用什么命令?格式是怎么樣的?
檔案權限修改:chmod
格式如下:
$ chmod u+x file 給 file 的屬主增加執行權限
$ chmod 751 file 給 file 的屬主分配讀、寫、執行(7)的權限,給 file 的所在組分配讀、執行(5)
的權限,給其他用戶分配執行(1)的權限
$ chmod u=rwx,g=rx,o=x file 上例的另一種形式
$ chmod =r file 為所有用戶分配讀權限
$ chmod 444 file 同上例
$ chmod a-wx,a+r file 同上例
$ chmod -R u+r directory 遞回地給 directory 目錄下所有檔案和子目錄的屬主分配讀的權限
查看檔案內容有哪些命令可以使用?
vi 檔案名 #編輯方式查看,可修改
cat 檔案名 #顯示全部檔案內容
more 檔案名 #分頁顯示檔案內容
less 檔案名 #與 more 相似,更好的是可以往前翻頁
tail 檔案名 #僅查看尾部,還可以指定行數
head 檔案名 #僅查看頭部,還可以指定行數
隨意寫檔案命令?怎么向螢屏輸出帶空格的字串,比如 ” hello world ” ?
寫檔案命令:vi
向螢屏輸出帶空格的字串:echo hello world
終端是哪個檔案夾下的哪個檔案?黑洞檔案是哪個檔案夾下的哪個命令?
終 端 /dev/tty
黑洞檔案 /dev/null
移動檔案用哪個命令?改名用哪個命令?
mv mv
使用哪一個命令可以查看自己檔案系統的磁盤空間配額呢?
使用命令repquota 能夠顯示出一個檔案系統的配額資訊
五、Java面試之Nginx
什么是Nginx快取?
基于proxy store實作 當啟動快取時 nginx會將相應資料保存在磁盤快取中 只要快取尚未過期 就用快取中的資料回應客戶端的請求
如何啟動快取?
Nginx啟用快取需要在最頂層的http節點下配置proxy_cache_path命令,我們先看看proxy_cache_path命令的語法結構:
proxy_cache_path /data/cache keys_zone=niyueling:10m;
可以看到proxy_cache_path命令一共包含兩個引數,第一個引數指定快取保存的本地路徑,第二個引數定義快取資料的共享記憶體區域的名稱和記憶體區大小,Nginx啟動后,快取加載程式只進行加載一次,加載時會將快取的元資料加載到共享記憶體區域,但是如果一次加載整個快取全部內容可能會使Nginx剛啟動的前幾分鐘性能消耗嚴重,大幅度降低Nginx的性能,所以可以
proxy_cache_path命令中配置快取迭代加載,快取迭代加載一共可以設定三個引數:
1.loader_threshold - 迭代的持續時間,以毫秒為單位(默認為200)
2.loader_files - 在一次迭代期間加載的最大專案數(默認為100)
3.loader_sleeps - 迭代之間的延遲(以毫秒為單位)(默認為50)
Nginx是用來干嘛的?
Nginx是一個高性能的HTTP和反向代理服務器,這個基本是用來前端服務器集群后做負載均衡和動靜分離用的
Nginx優勢?
1.Nginx由于使用了epoll和kqueue網路I/O模型,在實際生產環境能夠支撐3萬左右并發連接,
2.Nginx記憶體消耗低,
3.Nginx跨平臺,而且配置相對來說難度較低,
4.Nginx內置健康檢查功能,如果負載均衡其中一個服務器宕機了,則接受到的請求會發送給其他服務器去處理,
5.支持Gzip壓縮,可以添加瀏覽器本地快取的Header頭,
6.Nginx支持熱部署,可以在不間斷服務的情況下平滑進行配置的更改,
7.Nginx異步接收用戶請求,減輕了Web服務器的壓力,
Nginx如何實作高并發?
異步非阻塞,實際上Nginx就是異步非阻塞,使用了epoll模型并對底層代碼進行大幅度優化,之前其實有講過Nginx是采用1個master行程,多個worker行程的模式,每次接收到一個請求,master會將請求按照一定策略分發給一個worker行程去進行處理請求,worker行程數一般設定為和CPU核心數一致,異步非阻塞模式就會使得worker執行緒在等待請求callback的空閑時間可以接收處理新的請求,當接收到舊請求的callback時再回去繼續處理該請求,這樣就完成了少數幾個worker行程卻實作了高并發的問題,
Nginx為何不使用多執行緒?
眾所周知,沒創建一個新的執行緒,都需要為其分配cpu和記憶體,當然,創建行程也是一樣,但是由于執行緒過多會導致記憶體消耗過多,所以Nginx采用單執行緒異步處理用戶請求,這樣不需要不斷地為新的執行緒分配cpu和記憶體,減輕服務器記憶體消耗,所以使得Nginx性能方面更為高效,
Nginx如何處理請求?
Nginx啟動后,首先進行組態檔的決議,決議成功會得到虛擬服務器的ip和埠號,在主行程master行程中創建socket,對addrreuse選項進行設定,并將socket系結到對應的ip地址和埠并進行監聽,然后創建子行程worker行程,當客戶端和Nginx進行三次握手,則可以創建成功與Nginx的連接,當有新的請求進入時,空閑的worker行程會競爭,當某一個worker行程競爭成功,則會得到這個已經成功建立連接的socket,然后創建ngx_connection_t結構體,接下來設定讀寫事件處理函式并添加讀寫事件用來與客戶端進行資料交換,當請求結束Nginx或者客戶端主動關閉連接,此時一個請求處理完畢,
為什么要做動靜分離?
在日常開發中,前端請求靜態檔案比如圖片資源是不需要經過后端服務器的,但是呼叫API這些型別的就需要后端進行處理請求,所以為了提高對資源檔案的回應速度,我們應該使用動靜分離的策略去做架構,我們可以將靜態檔案放到Nginx中,將動態資源的請求轉發到后端服務器去進行進一步的處理,
Nginx負載均衡的幾種常用方式?
1.輪詢方式:默認情況下Nginx使用輪詢的方式實作負載均衡,每個新的請求按照時間順序逐一分配到不同的后端服務器去進行處理,如果后端服務器宕機,則Nginx的健康檢查功能會將這個后端服務器剔除,但是輪詢方式是顯而易見的:可靠性低而且負載分配不平衡,所以輪詢方式更適用于圖片服務器或者靜態資源服務器,
2.weight:可以對不同的后端服務器設定不同的權重比例,這樣可以改變不同后端服務器處理請求的比例,可以給性能更優的后端服務器配置更高的權重,
3.ip_hash:這種方式會根據請求的ip地址的hash結果分配后端服務器來處理請求,這樣每個用戶發起的請求固定只會由同一個后端服務器處理,這樣可以解決session問題,
4.fail:這種方式有點類似于輪詢方式,主要是根據后端服務器的回應時間來分配請求,回應時間短的后端服務器優先分配請求,
5.url_hash:這種方式是按照請求url的hash結果來將不同請求分配到不同服務器,使用這種方式每個url的請求都會由同一個后端服務器進行處理,后端服務器為快取時效率會更高,
Nginx常用優化配置?
1.調整worker_processes指定Nginx需要創建的worker行程數量,剛才有提到worker行程數一般設定為和CPU核心數一致,
2.調整worker_connections設定Nginx最多可以同時服務的客戶端數,結合worker_processes配置可以獲得每秒可以服務的最大客戶端數,
3.啟動gzip壓縮,可以對檔案大小進行壓縮,減少了客戶端http的傳輸帶寬,可以大幅度提高頁面的加載速度,
4.啟用快取,如果請求靜態資源,啟用快取是可以大幅度提升性能的,
Nginx中正向代理與反向代理的區別?
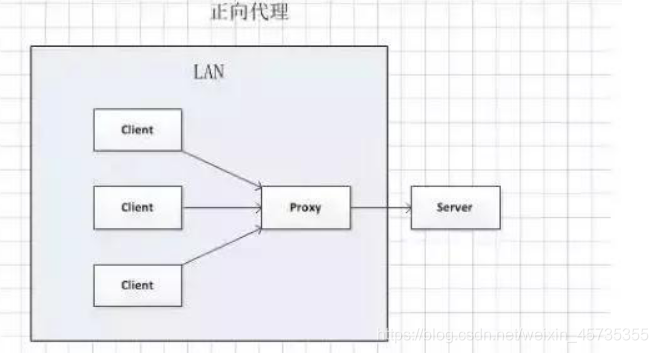
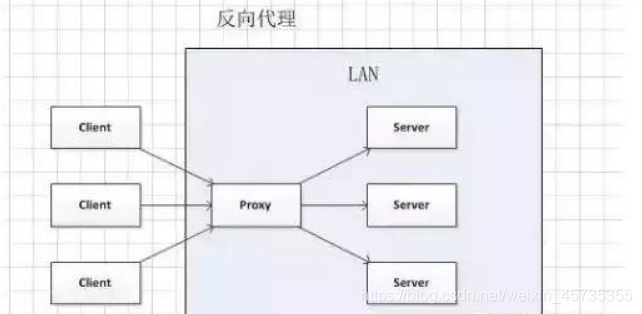
1.在正向代理中,隱藏了請求來源的客戶端資訊;
2.在反向代理中,隱藏了請求具體處理的服務端資訊;
六、Java面試題之總結 ?
jdk1.7到jdk1.8 Map發生了什么變化(底層)?
1.8之后hashMap的資料結構發生了變化,從之前的單純的陣列+鏈表結構變成陣列+鏈表+紅黑樹,也就是說在JVM存盤hashMap的K-V時僅僅通過key來決定每一個entry的存盤槽位(Node[]中的index),并且Value以鏈表的形式掛在到對應槽位上(1.8以后如果value長度大于8則轉為紅黑樹),
但是hashmap1.7跟1.8 中都沒有任何同步操作,容易出現并發問題,甚至出現死回圈導致系統不可用,解決方案是jdk的ConcurrentHashMap,位于java.util.concurrent下,專門解決并發問題,
ConcurrentHashMap
思路與hashMap差不多,但是支持并發操作,要復雜很多
并行跟并發有什么區別?
并發:指應用交替執行不同的任務,多執行緒原理
并行:指應用同時執行不用的任務
區別:一個是交替執行,一個是同時執行,
什么是中間件?
中間件是處于作業系統和應用程式之間軟體,使用時旺旺是一組中間件集成在一起,構成一個平臺(開發平臺+運行平臺),在這組中間件中必須要有一個通信中間件,即中間件=平臺+通信,該定義也限定了只有勇于分布式系統中才能稱為中間件
主要分類:遠程程序呼叫、面向訊息的中間件、物件請求代理、事物處理監控,
如果叫你自己設計一個中間件,你會如何設計?
我會從以下幾點方面考慮開發:
1)遠程程序呼叫
2)面向訊息:利用搞笑的訊息傳遞機制進行平臺無關的資料交流,并給予資料通信來進行分布式系統的集成,有一下三個特點:
i)通訊程式可以在不同的時間運行
ii)通訊晨旭之家可以一對一、一對多、多對一甚至是上述多種方式的混合
iii)程式將訊息放入訊息佇列會從小吸毒列中取出訊息來進行通訊
3)物件請求代理:提供不同形式的通訊服務包括同步、排隊、訂閱發布、廣播等,可構筑各種框架如:事物處理監控器、分布資料訪問、物件事務管理器OTM等,
4)事物處理監控有一下功能:
a)行程管理,包括啟動server行程、分配任務、監控其執行并對負載進行平衡
b)事務管理,保證在其監控下的事務處理的原子性、一致性、獨立性和持久性
c)通訊管理,為client和server之間提供多種通訊機制,包括請求回應、會話、排隊、訂閱發布和廣播等
ThreadLock用過沒有,說說它的作用?
ThreadLock為本地執行緒,為每一個執行緒提供一個區域變數,也就是說只有當前線層可以訪問,是執行緒安全的,原理:為每一個執行緒分配一個物件來作業,并不是由ThreadLock來完成的,而是需要在應用層面保證的,ThreadLock只是起到了一個容器的作用,原理為ThreadLock的set()跟get()方法,
實作原理:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
return (T)e.value;
}
return setInitialValue();
}
Hashcode()和equals()和==區別?
(1)hashcode()方法跟equals()在java中都是判斷兩個物件是否相等
(2)兩個物件相同,則hashcode至一定要相同,即物件相同 ---->成員變數相同 ---->hashcode值一定相同
(3)兩個物件的hashcode值相同,物件不一定相等,總結:equals相等則hashcode一定相等,hashcode相等,equals不一定相等,
==比較的是兩個參考在記憶體中指向的是不是同一物件(即同一記憶體空間)
mysql優化會不會,mycat分庫,垂直分庫,水平分庫?
(1)為查詢快取優化你的查詢
(2)EXPLAIN select查詢:explain 的查詢結果會告訴你索引主鍵是如何被利用的
(3)只需要一行資料時使用limit1
(4)為搜索欄位添加索引
(5)在關聯表的時候使用相當型別的例,并將其索引
(6)千萬不要ORDER BY RAND()
(7)避免select*
(8)永遠為每張表設定一個ID
(9)使用ENUM而不是VARCHAR
(10)從PROCEDURE ANALYS()提取建議
(11)盡可能的使用NOT NULL
(12)Java中使用Prepared Statements
(13)無緩沖的查詢
(14)把IP地址存成UNSIGNED INT
(15)固定表的長度
(16)垂直分庫:“垂直分割”是一種把資料庫中的表按列變成幾張表的方法,這樣可以降低表的復雜度和欄位的數目,從而達到優化的目的,
(17)水平分庫:“水平分割”是一種把資料庫中的表按行變成幾張表的方法,這樣可以降低表的復雜度和欄位的數目,從而達到優化的目的,
(18)越小的列會越快
(19)選擇正確的存盤引擎
(20)使用一個物件關系映射器
(21)小心永久鏈接
(22)拆分大的DELETE活INSERT陳述句
分布式事務解決方案?
(1)什么是分布式事務?
a.什么情況下需要用到分布式事務?
a)當本地資料庫斷電、機器宕機、網路例外、訊息丟失、訊息亂序、資料錯誤、不可靠TCP、存盤資料丟失、其他例外等需要用到分布式事務,
b)例如:當本地事務資料庫斷電的這種秦光,如何保證資料一致性?資料庫由連個檔案組成的,一個資料庫檔案和一個日志檔案,資料庫任何寫入操作都要先寫日志,在操作前會吧日志檔案寫入磁盤,那么斷電的時候及時才做沒有完成,在重啟資料庫的時候,資料庫會根據當前資料情況進行undo回滾活redo前滾,保證了資料的強一致性,
c)分布式理論:當單個資料庫性能產生瓶頸的時候,可能會對資料庫進行磁區(物理磁區),磁區之后不同的資料庫不同的服務器上 ,此時單個資料庫的ACID不適應這種清苦啊,在此集群環境下很難達到集群的ACID,甚至效率性能大幅度下降,重要的是再很難擴展新的磁區了,此時就需要參考一個新的理論來使用這種集群情況:CAP定理
d)CAP定理:由加州肚餓伯克利分銷Eric Brewer教授提出,指出WEB服務無法同時滿足3個屬性:
a.一致性:客戶端知道一系列的操作都會同時發生(生效)
b.可用性:每個操作都必須以可預期的回應結束
c.磁區容錯性:及時出現單組件無法可用,操作依然可以完成,
具體的將在分布式系統中,在任何資料庫設計中,一個WEB應
至多只能同時支持上面兩個屬性,設計人員必須在一致性和可用
性之間做出選擇,
e)BASE理論:分布式系統中追求的是可用性,比一致性更加重要,BASE理論來實作高可用性,核心思想是:我們無法做到羥乙酯,單每個應用都可以根據自身的業務特點,采用適當的方式使系統達到最終一致性,
f)資料庫事務特性:ACID
i.原子性
ii.一致性
iii.獨立性或隔離性
iv.持久性
(2)分布式系統中,實作分布式事務的解決方案:
a.兩階段提交2PC
b.補償事務TCC
c.本地訊息表(異步確保)
d.MQ事務訊息
e.Sagas事務模型
sql陳述句優化會不會,說出你知道的?
(1)避免在列上做運算,可能會導致索引失敗
(2)使用join時應該小結果集驅動大結果集,同時把復雜的join查詢拆分成多個query,不然join越多表,會導致越多的鎖定和堵塞,
(3)注意like模糊查詢的使用,避免使用%%
(4)不要使用select * 節省記憶體
(5)使用批量插入陳述句,節省互動
(6)Limit基數比較大時,使用between and
(7)不要使用rand函式隨機獲取記錄
(8)避免使用null,建表時,盡量設定not nul,提高查詢性能
(9)不要使用count(id),應該使用count(*)
(10)不要做無謂的排序,盡可能在索引中完成排序
(11)From陳述句中一定不要使用子查詢
(12)使用更多的where加以限制,縮小查找范圍
(13)合理運用索引
(14)使用explain查看sql性能
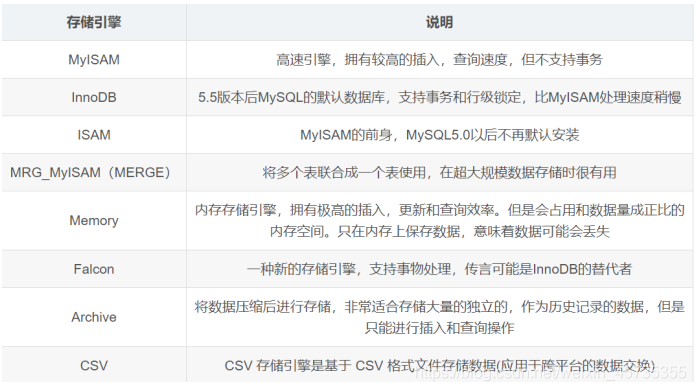
mysql的存盤引擎了解過沒有?
(1)MySQL存盤引擎種類:
(2)https://blog.csdn.net/m0_37888031/article/details/80704344
(3)https://blog.csdn.net/m0_37888031/article/details/80664138
(4)事務處理:在整個流程中出現任何問題,都能讓資料回滾到最開始的狀態,這種處理方式稱之為事務處理,也就是說事務處理要么都成功,要么的失敗,
紅黑樹原理?
紅黑樹的性質:紅黑樹是一個二叉搜索樹,在每個節點增加了一個存盤位記錄節點的顏色,可以是RED,也可以是BLACK,通過任意一條從根到葉子簡單路徑上顏色的約束,紅黑樹保證最長路徑不超過最短路徑的兩倍,加以平衡,性質如下:
i.每個節點顏色不是黑色就是紅色
ii.根節點的顏色是黑色的
iii.如果一個節點是紅色,那么他的兩個子節點就是黑色的,沒有持續的紅節點
iv.對于每個節點,從該節點到其后代葉節點的簡單路徑上,均包含相同數目的黑色節點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290418.html
標籤:java