爬蟲學習練練手:
剛好最近在學習爬蟲,了解了一些基本的知識,以任務為導向去學習一下,所以根據自己的愛好出發,先來爬取一個《青春有你2》的評論吧,(可能會有點繁雜,主要記錄自己在想什么,記錄自己的思路)
我認為我寫爬蟲的時候基本就是在處理兩方面:
第一:獲取請求url,是直接那個網址就是呢,還是存在于另外的地方,這里我們可以用抓包工具去看
第二: 處理資料,將服務器回傳的資料整理一下,
第一部分:獲取請求URL(這也是最重要的,但是因為愛奇藝的離奇網址也為這一步添加了難度,我也是差點被困在里面了)*
爬取網址:https://www.iqiyi.com/v_19ry9w7eh8.html
- 第一步,我們可以先看一看這種評論資料是直接全部給你呢,還是隨著你的重繪慢慢的給你呢
*使用request向服務器發個請求,得到html網頁,在搜索框隨便搜索一句評論,發現沒有,這時候就可以斷定是異步讀取評論資料,且這個網址也不是我們需要的request URL
import requests
url= 'https://www.iqiyi.com/v_19ry9w7eh8.html'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'
}
request = requests.get(url, headers=headers)
request.encoding='utf-8'
response =request.text
print(response)
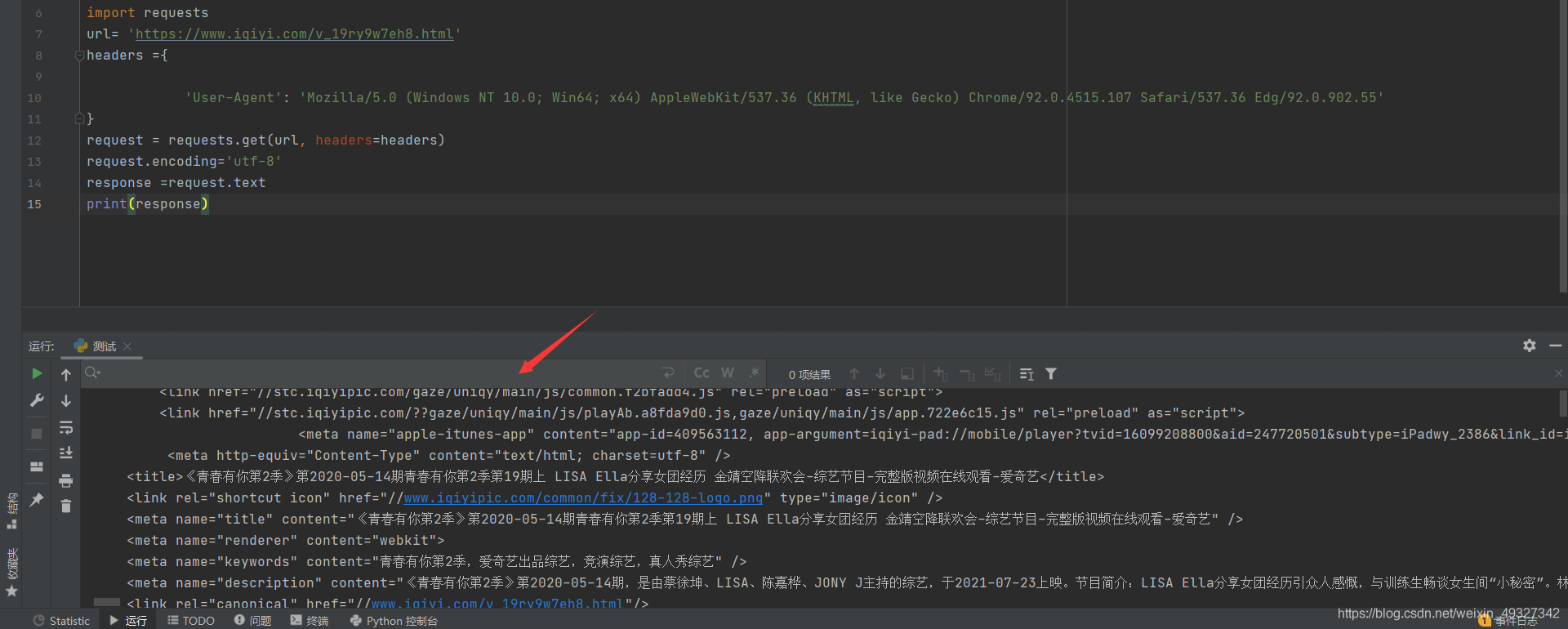
- 第二步,我們可以先打開之后直接F12,然后再次重繪頁面,讓抓包工具抓到所有的資料
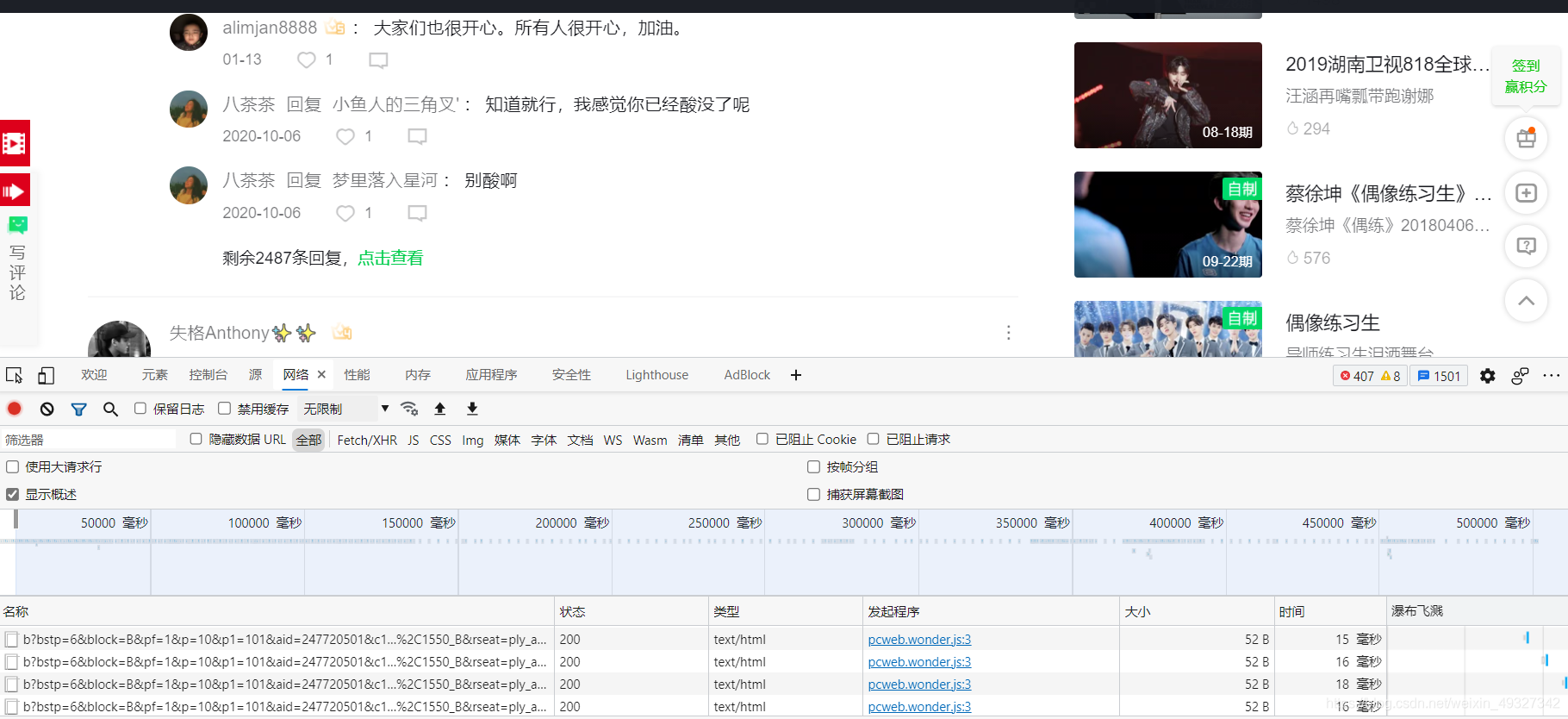
- 第三步,到了這個頁面之后呢,我們可以先去嘗試一下看看評論資料都存在哪里,隨便復制一小段評論,然后點擊抓包工具左上角的搜索
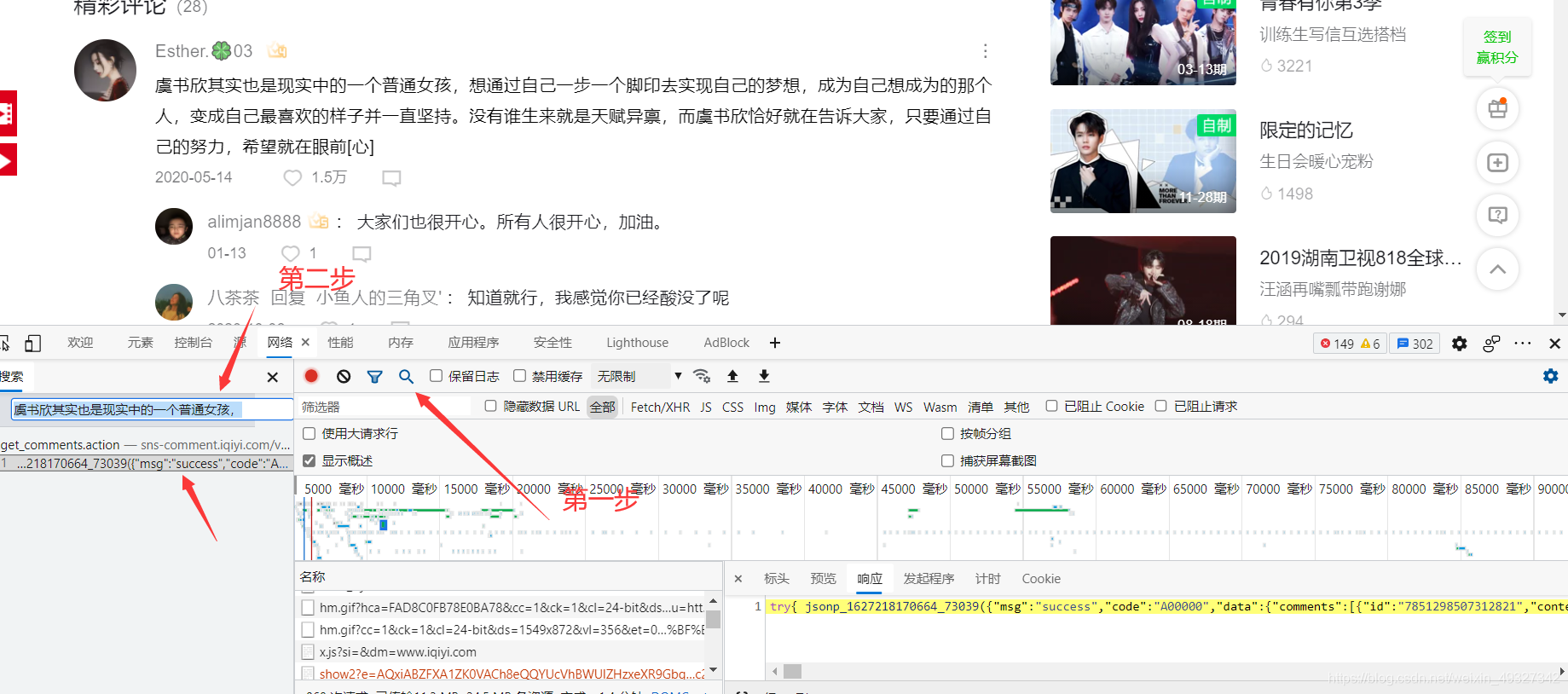
- 第四步,這時候我們就找到了我們的評論資料了,我們將指標放在這個評論資料上,并在旁邊的檔案框里面找到它,(這里建議點擊一下名稱,這樣可以讓這些得到的資料進行排序,更好得觀察有規律的資料)
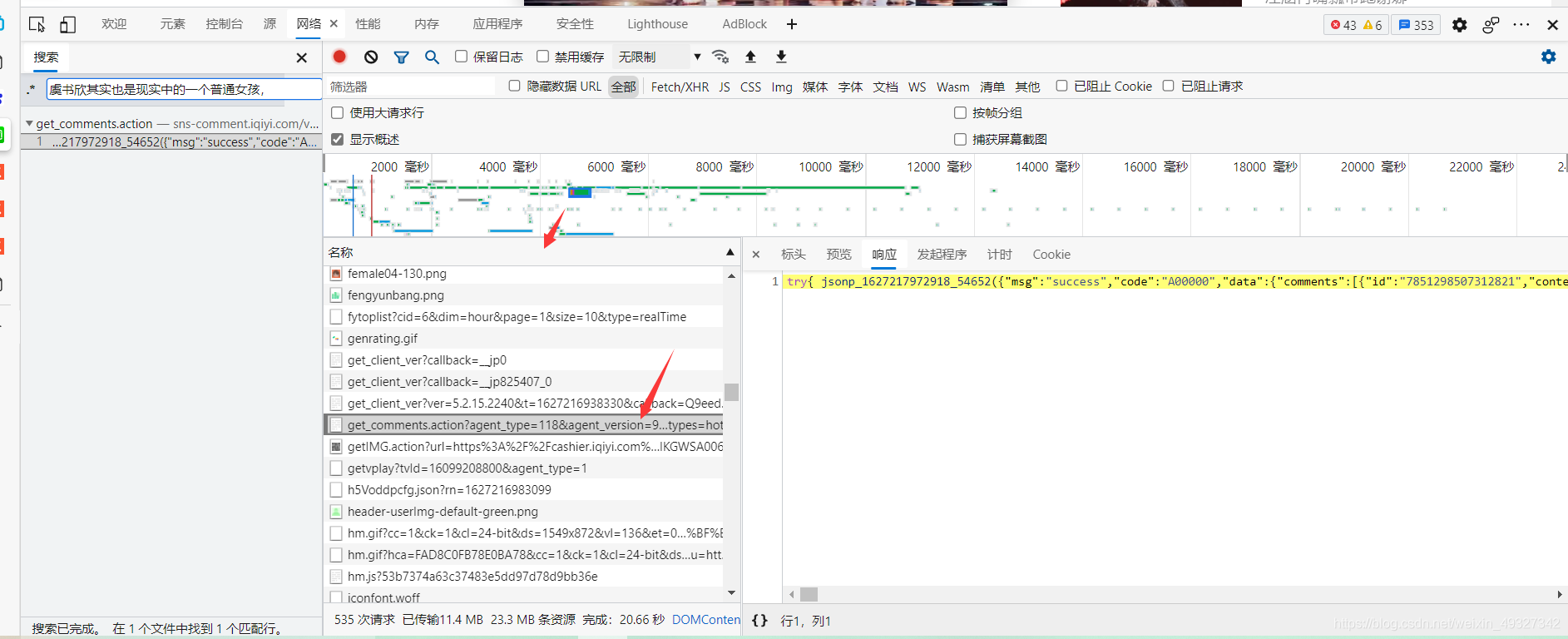
- 第五步,找到了它之后呢,我們可以先觀察一下它的回應,發現他的資料是json格式的(這個有點經驗吧,一般json格式的特點就是,串列和字典在一起),我們可以把這串資料到https://www.json.cn/去看一下這個回應的構成,
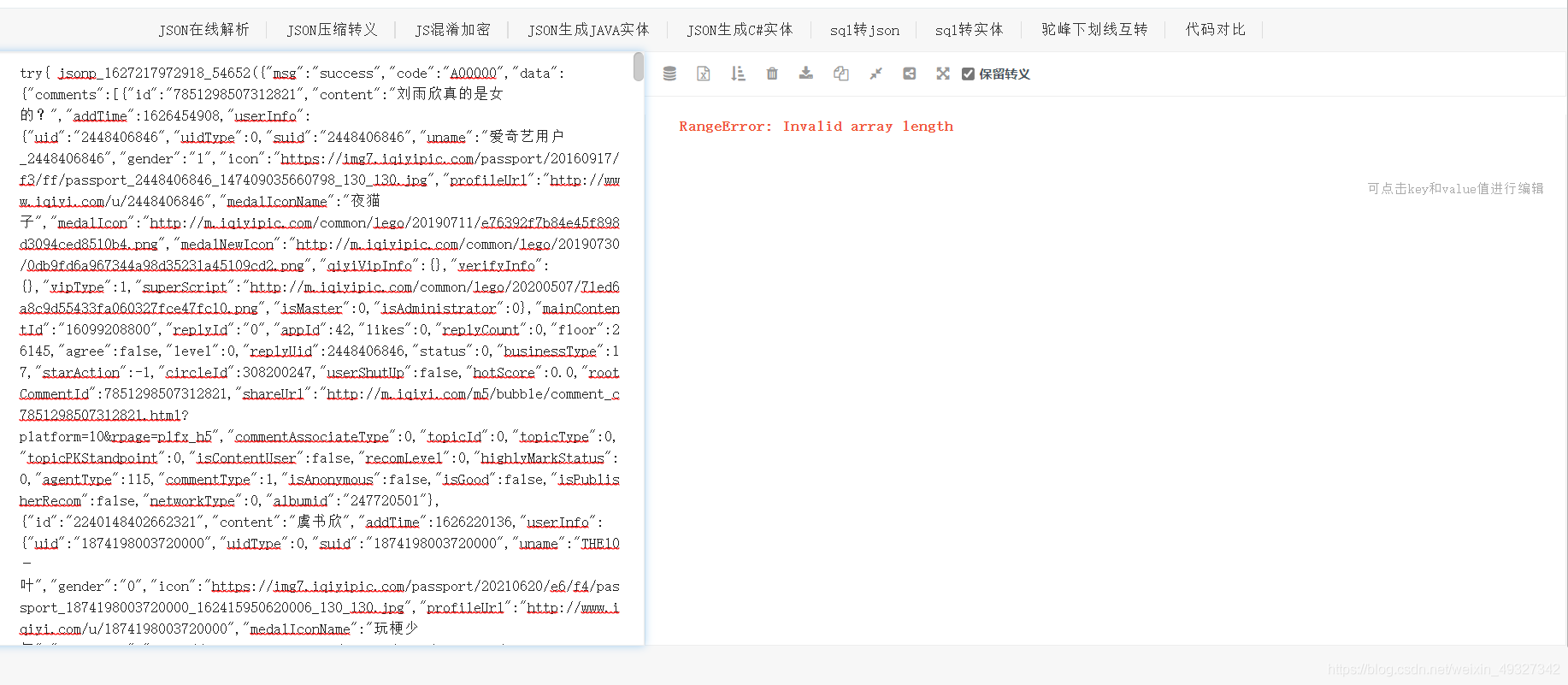
- 第六步看到報錯之后呢,我們就會發現,這不是一個很正常的json格式資料,我們自習的看下資料的前面就會發現,這個字典前面還多出了一部分東西,我們可以將它刪掉,然后我們就會得到一個正常的json資料了(這是一種經驗之談,其實在后面我們去分析請求網址的時候,想要等到一個規律的網址資料時,我們會有一種更方便的方法去獲得這個json資料)(假如我們將瀏覽器回傳給我們的資料整理成右圖這樣,那么我們獲取資料就會十分簡單了,下面也是為了這個目的)
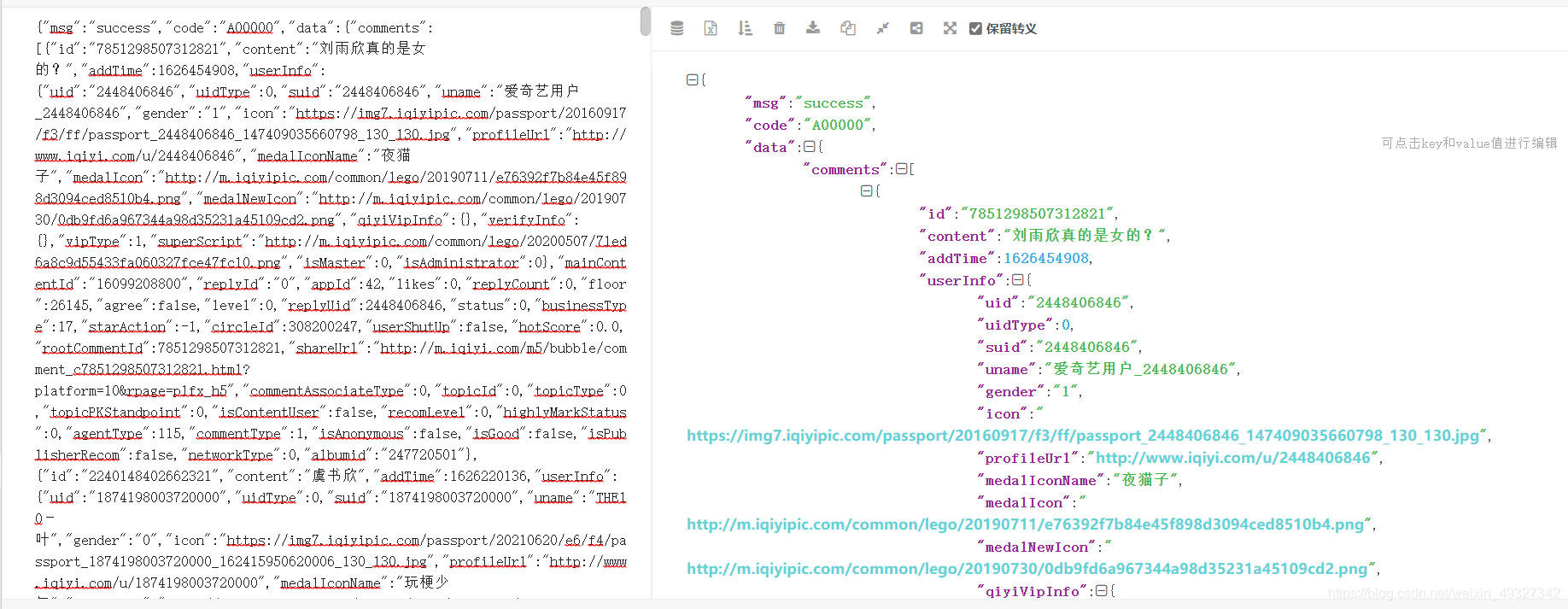
我們發現,這里的評論資料只有10條,明顯不是全部的評論資料,但這時候我們就可以確定,這個get_comments.action基本就是評論資料所在的地方了,然后我們可以先留著這個網頁,然后回去抓包工具的地方,繼續觀察,
- 第七步,當我們一步一步將評論往下面翻的時候,發現這個get_comments.action越來越多了,也證實了我們前面的想法
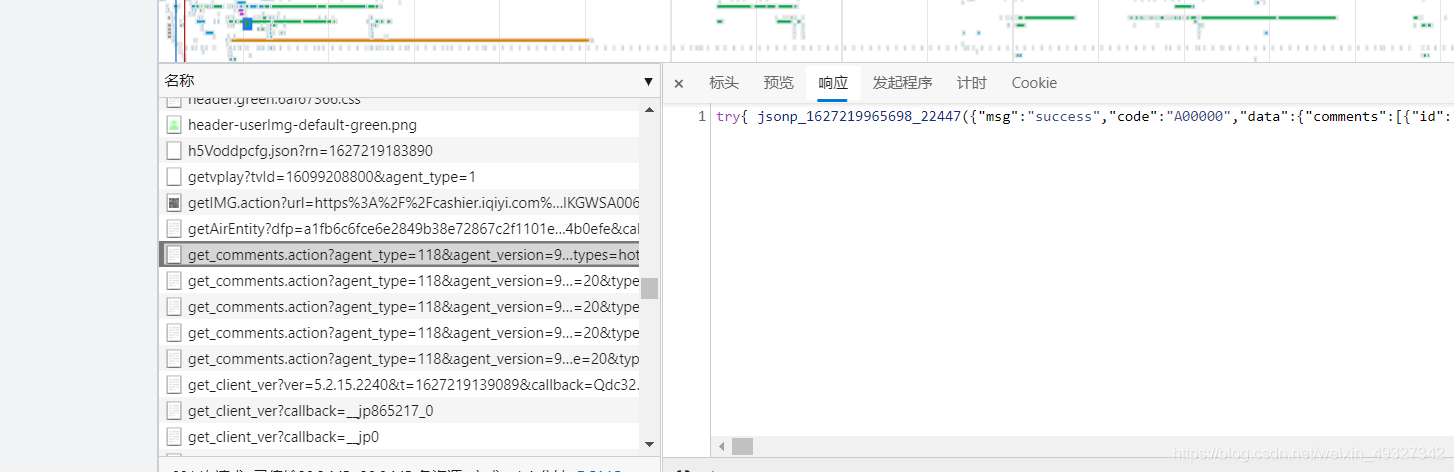
這時候我們可以點開標頭,復制一下他的請求url到記事本中,來分析一下他們的規律,并且可以將標頭翻到最下面,看著查詢字串引數一起看(其實這里的引數,就是網址里面的引數,只是我更喜歡放記事本中來看),
- 第八步,分析代碼,我們可以將它分成引數的形式(習慣),我做了以下一個嘗試
- 看到最下面一項callback,發現回傳的給我們的是jsonp格式的資料,
- 我們可以將它先改成json資料試試,直接將網址放到瀏覽器中,發現回傳的資料變成了json格式,(知道前面還是有多余的東西,說明這個回傳的會限制回傳的資料格式),
- 我們將這個引數洗掉掉,然后就會發現,這時候就是一個單純的json格式的資料了,我們可以將它直接放到json轉換器中,這樣也更方便我們后面的解碼

我們向服務器發起一個請求,使用這個網址
import requests
url= 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=b3YOhPajFgcajWm1pRZnX5IKGWSA006JVVqm1Y9DVNFvTM9zm17t9ee5a61JpgV2TYcsg59&business_type=17&channel_id=6&content_id=16099208800&hot_size=10&last_id=&page=&page_size=10&types=hot,time'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'
}
request = requests.get(url, headers=headers)
request.encoding='utf-8'
# 使用這一步,就是對于服務器回傳的資料,我們要解碼成json資料,輸出的結果就是我們想要的json資料(可以使用字串,字典的方法去呼叫里面的資料)
response =request.json()
print(response)
- 第九步,我們就可以開始嘗試找出代碼的規律了,這里就省略最折磨的吧(總結,看到page=,經歷使用page,不要去相信什么last_id之類的,我前面的誤區就是,看到page為空,然后我對比幾個評論的資料,發現只是last_id產生了變化,然后我就打算尋找出last_id的變化,但是我最后發現它是隨機的,然后就自閉了,到最后還是抱著試一試的態度,去試了下page,發現這才是真愛),然后我就將content_id洗掉了,轉而使用page為頁面引數
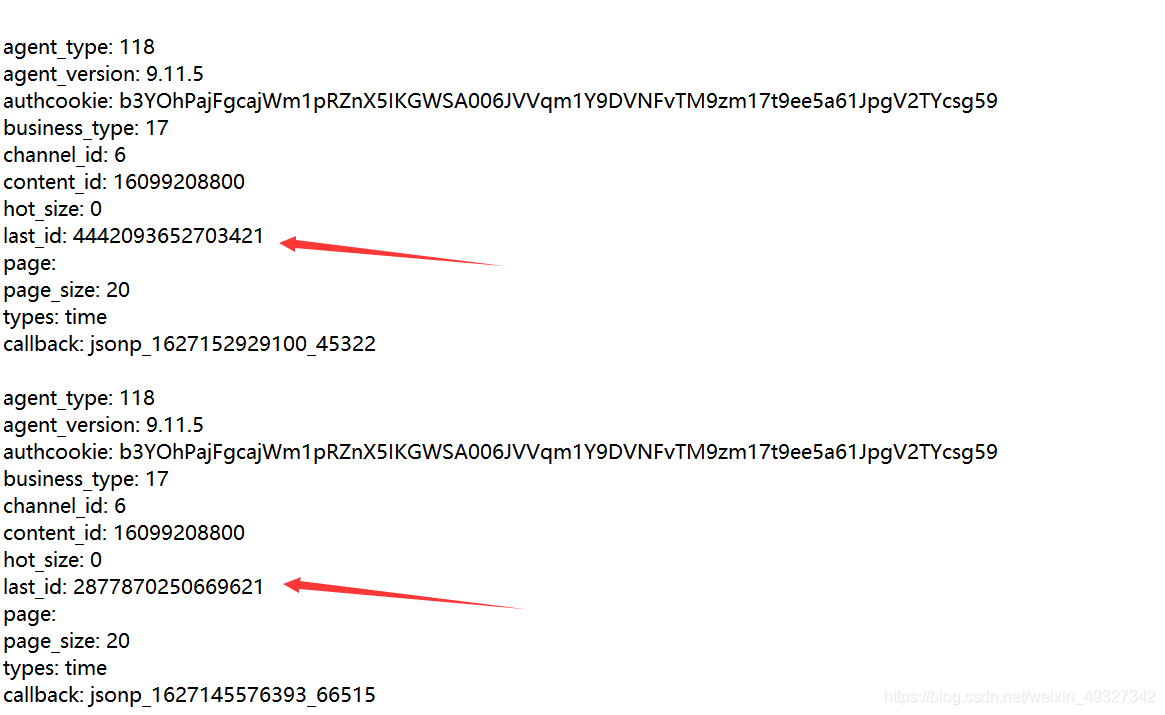
# 添加page引數,洗掉last_content
# 洗掉引數callback,回傳的資料直接為字典
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118
&agent_version=9.11.5
&authcookie=b3YOhPajFgcajWm1pRZnX5IKGWSA006JVVqm1Y9DVNFvTM9zm17t9ee5a61JpgV2TYcsg59
&business_type=17
&channel_id=6
&content_id=16099208800
# page_size中40條分為hot_size=0和普通comments=40條,只有第一頁為10條,其余都為40條
&hot_size=30
&page_size=40
&types=hot,time
&page=1
找到規律了,這樣我們就得到了請求url的格式了,只要去更改page就行了,然后就是開始處理一下它回傳的資料了
第二部分,發起請求,處理服務器回傳的資料
(中間也發現了一個很痛苦的問題,導致我一步一步除錯,才看出來的)
第一步,我們對比著https://www.json.cn/整理好的資料,去得到一個串列
all_comments_list = response['data']['comments']
如果我們只是單純的去按照常理去獲得他們的評論資料的話,從他的page_size來看,每一頁應該有40條資料,我去列印第一頁的時候,直接就是超出了list,然后我就發現了,它的只要第一頁是10條,其他的都是40條(無語~!),然后就讓第一頁單獨立出來,本以為獲取就結束了,沒想到,下面才是最痛苦的問題,

發現獲取鍵值錯誤,我當時就懵逼了,沒碰到過,然后一步一步去看資料才發現**(強烈安利在控制臺中運行代碼,類似于在jupyter中運行,可以一步一步來,還會給你顯示引數)**
然后就發現了最陰間的問題,有些地方是沒有content的,然后我就差點自閉了(這里找個好久好久)如下就解決了這個問題
if page == 1:
for i in range(10):
comments.append(all_comments_list[i]['content'])
# print(all_comments_list[i]['content'])
else:
for j in range(39):
# 因為存在有幾個是沒有content的情況,所以需要判斷一下
if 'content' in all_comments_list[j]:
comments.append(all_comments_list[j]['content'])
# print(all_comments_list[j]['content'])
else:
comments.append(' ')
然后就開始處理資料了,洗掉轉碼失敗的表情,和前面開頭就有的標點符號和一些空的資料,為了下面更好的去分詞,
'''
* name: not_empty:資料篩選
* para: NONE
* return:
* return_lx :
* writer: xihuanafeng
* function: 定義篩選規則,去除空, :和開頭的,
* time: 2021/7/25
'''
def not_empty(s):
return s and s.strip() and s.strip(':') and s.strip(',')
'''
* name: comment_clear:資料整理函式
* para: 評論資料
* return: 整理好的評論資料
* return_lx : str
* writer: xihuanafeng
* function: 去除評論中的字母表情之類的資料
* time: 2021/7/25
'''
def comment_clear(content):
comment_clear_list = re.sub(r"</?(.+?)>| |\t|\r", "", content)
comment_clear_list = re.sub(r"\n", " ", comment_clear_list)
clear_comment = re.sub('[^\u4e00-\u9fa5^a-z^A-Z^0-9]', '', comment_clear_list)
return clear_comment

接下來就是分詞了
- 我們分詞采用的是jieba(結巴),一個很好用的中文分詞軟體,大家可以去看下這位大佬的博客[https://blog.csdn.net/codejas/article/details/80356544],講解的還是很清楚的,(我這里使用的是自定義的分詞字典,在github里面有)
'''
* name: 分詞函式
* para: 需要分詞的句子或文本:str
* return: 分詞后的資料
* return_lx : list
* writer: xihuanafeng
* function: 分詞
* time: 2021/7/25
'''
def fenci(text):
jieba.load_userdict('add_words.txt') # 添加自定義字典
# seg = jieba.lcut(text, cut_all=False)
seg = jieba.lcut(text, cut_all=False) # 直接回傳list
return seg
- 在分詞的時候,會存在一些停用詞,這些詞不利于我們后面的分詞,我們這里也將它去掉
'''
* name: 去除停用詞
* para:
* return:
* return_lx :
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def movestopwords(sentence, stopwords, counts):
'''
去除停用詞,統計詞頻
引數 file_path:停用詞文本路徑 stopwords:停用詞list counts: 詞頻統計結果
return:None
'''
out = []
for word in sentence:
if word not in stopwords:
if len(word) != 1:
counts[word] = counts.get(word, 0) + 1
return None
分好詞之后呢,我們就進入到最后的階段了,統計好詞頻去繪制詞云圖
'''
* name: 繪制詞頻統計表
* para: counts: 詞頻統計結果 num:繪制topN
* return: None
* return_lx : None
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def drawcounts(counts, num):
'''
繪制詞頻統計表
引數 counts: 詞頻統計結果 num:繪制topN
return:none
'''
x_aixs = []
y_aixs = []
c_order = sorted(counts.items(), key=lambda x: x[1], reverse=True)
# print(c_order)
for c in c_order[:num]:
x_aixs.append(c[0])
y_aixs.append(c[1])
# 設定顯示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 指定默認字體
matplotlib.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
plt.bar(x_aixs, y_aixs)
plt.title('詞頻統計結果')
plt.show()
'''
* name: 根據詞頻繪制詞云圖
* para: 引數 word_f:統計出的詞頻結果
* return: None
* return_lx : None
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def drawcloud(word_f):
'''
根據詞頻繪制詞云圖
引數 word_f:統計出的詞頻結果
return:none
'''
# 加載背景圖片
cloud_mask = np.array(Image.open('cluod.png'))
# 忽略顯示的詞
st = set(["東西", "這是"])
# 生成wordcloud物件
wc = WordCloud(background_color='white',
mask=cloud_mask,
max_words=150,
font_path='simhei.ttf',
min_font_size=10,
max_font_size=100,
width=400,
relative_scaling=0.3,
stopwords=st)
wc.fit_words(word_f)
wc.to_file('pic.png')
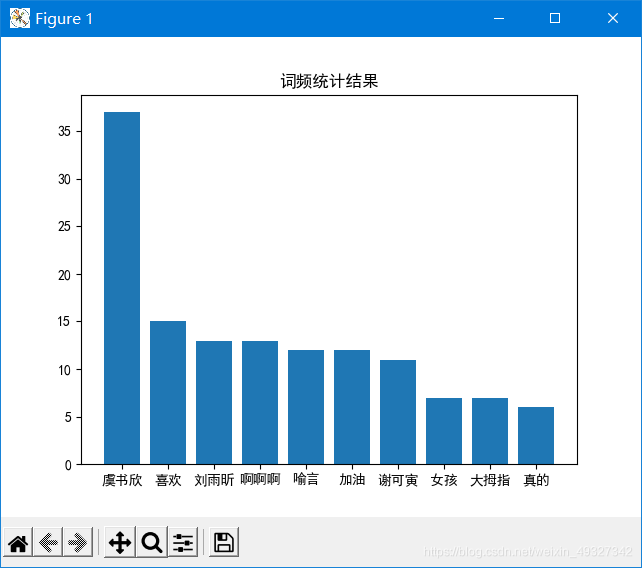
這是我們得到的詞頻統計表
這是我們得到的詞云圖
ps:效果還是挺不錯的,愛奇藝的評論絕絕子,還是很樂觀的,

總結:
- 第一點,爬蟲方面問題:前面寫的幾個爬蟲,像爬取京東的評論資料和爬取一個神奇網站的圖片都沒有碰到過這樣的問題,網址尋找規律基本就是去嘗試使用page引數,其他的變化基本可以后看,
- 第二點,資料處理方面:第一次碰見空值,導致無法很直接的去獲取到全部資料,對于繪制詞頻圖,和詞云基本都是有相同的模板,都是通過呼叫一個庫就可以輕松解決的,
希望各位大佬可以提提意見,可以說是第一次認真寫博客,語言之類的也有點語無倫次,愛奇藝的評論真的把我爬吐了,,
已經開源在GitHub了,大家覺得寫的可以的話可以點一點star的
我的github鏈接
或許大家進不去,大家可以上鏡像站,也可以下載的,好像只是不可以點star
這是鏡像站的鏈接,大家應該是可以進去的
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290437.html
標籤:python
上一篇:如何系統地自學 Python?