前段時間來到中關村重慶基地實訓,老師要求每人提交一張本人白底免冠照片用于錄入門禁監控系統,我當時想:好高級哇,一張照片就可以耶;神經網路訓練模型還得好多張圖片不斷輪次迭代才能產生好的效果呢,當時的我非常好奇,心生崇拜之意,一直夢想著自己也能開發出這樣一個系統,然而,不久之后的現在,成功了!回頭再看門口那個門禁監控系統:呵~不過如此!

目錄
1 人臉識別應用所涉及到的功能模塊
2 人臉識別的基本程序
2.1 dlib 庫的安裝與實體決議
2.2 face_recognition 庫的安裝與實體決議
2.2.1 load_image_file
2.2.2 face_locations
2.2.3 face_landmarks
2.2.4 face_encodings
2.2.5 compare_faces
2.2.6 獲取攝像頭的影像資訊
3 實作人臉識別的監控系統
3.1 人臉識別監控系統
3.2 眨眼活體檢測
1 人臉識別應用所涉及到的功能模塊
- 攝像頭呼叫
- 臉部影像識別和處理
- 活體檢測
- 多執行緒的應用
- 定時器的呼叫
2 人臉識別的基本程序
- 人臉的 68 個基本特征點位置以及順序,判斷 68 個特征點在影像上面是否存在、是否完整;
- 人臉 detect,這一步主要就是定位人臉在影像中的位置,利用目標檢測演算法輸出人臉位置矩形框;
- 人臉 shape predictor,這一步就是要找出眼睛眉毛鼻子嘴巴具體的點位;
- 人臉對齊 alignment,這一步主要是通過投影幾何變換出一張標準臉;
- 人臉識別,這一步就是在對擠的人臉影像上提取 128 維的特征向量,根據特征向量間的距離來進行判斷識別,
python 中最常用的人臉識別庫是基于 C++ 開發的 dlib 庫,
2.1 dlib 庫的安裝與實體決議
dlib 庫需要單獨安裝,dlib 庫目前已經編譯好的安裝版本只支持 python 3.6 的版本,
這里再提供一個 python 3.7 版本的 dlib 庫 whl 檔案:鏈接:https://pan.baidu.com/s/1Fch0AqhZTmql7MpFyEDtYA 提取碼:re7z
# -*-coding:GBK -*-
import dlib
from skimage import io
detector = dlib.get_frontal_face_detector() # 獲取一個臉部檢測器,這個監測器包含了臉部檢測演算法
win = dlib.image_window()
img = io.imread('E:/girl.png') # 讀取帶辨別的影像
# 利用臉部檢測器讀取待檢測的影像資料,第二個引數1代表讀取圖片像素并放大1倍以便能夠收集到更多的照片細節
# 回傳結果是一組人臉區域的資料
ders = detector(img, 1)
win.set_image(img)
win.add_overlay(ders)
dlib.hit_enter_to_continue()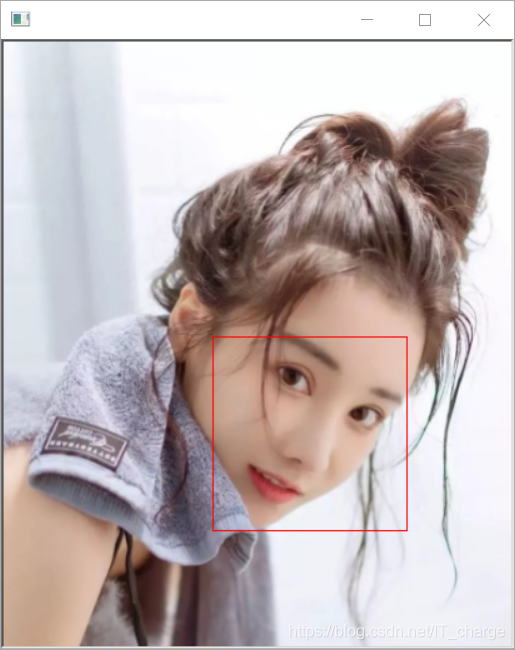
2.2 face_recognition 庫的安裝與實體決議
face_recognition 庫是基于 dlib 進行了二次封裝,號稱世界上最簡潔的人臉識別庫,
訓練資料集:Labeled Faces in the Wild,13000 多人臉作為訓練資料集,識別效果取決于樣本的數量以及質量,
windows 上安裝: pip install -i https://pypi.douban.com/simple face_recognition
2.2.1 load_image_file
load_image_file 這個方法主要用于加載要識別的人臉影像,加載回傳的資料是 Numpy 數組,記錄了圖片的所有像素的特征向量,
# -*-coding:GBK -*-
import face_recognition
image = face_recognition.load_image_file('E:/girl.jpg')
print(image)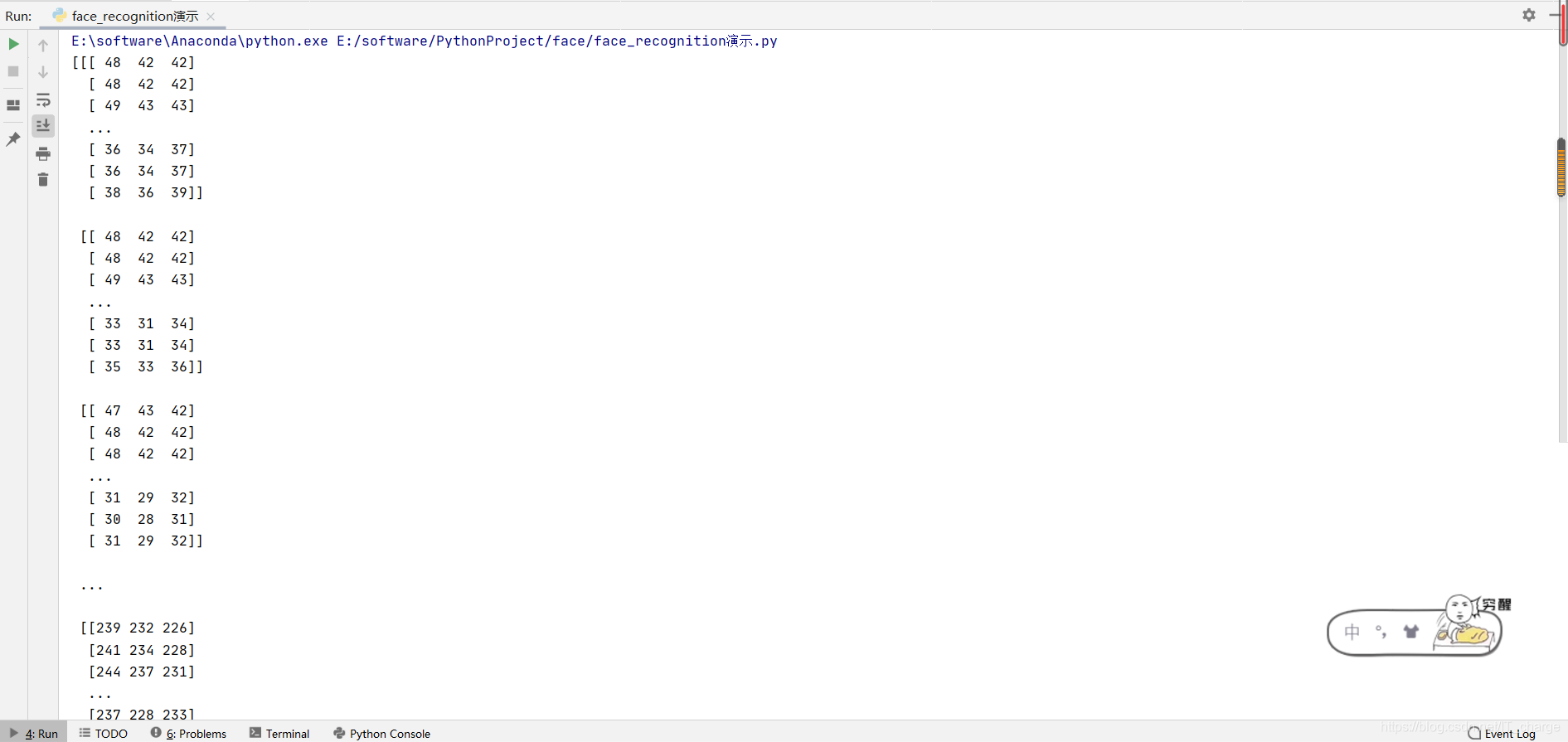
2.2.2 face_locations
face_locations 定位圖中所有的人臉的像素位置,
- 回傳值是一個串列形式,串列中每一行是一張人臉的位置資訊,包括[top, right, bottom, left],也可以認為每個人臉就是一組元組資訊,主要用于標識影像中所有的人臉資訊,
# -*-coding:GBK -*-
import face_recognition
from PIL import Image
import cv2
# 通過 load_image_file 方法加載待識別圖片
image = face_recognition.load_image_file('E:/girls.jpg')
# 通過 face_locations 得到影像中所有人臉位置
face_locations = face_recognition.face_locations(image)
for face_location in face_locations:
top, right, bottom, left = face_location # 結報操作,得到每張人臉的四個位置資訊
print("已識別到人臉部位,限速區域為:top{}, right{}, bottom{}, left{}".format(top, right, bottom, left))
# face_image = image[top:bottom, left:right]
# pil_image = Image.fromarray(face_image)
# pil_image.show()
start = (left, top)
end = (right, bottom)
# 在圖片上繪制矩形框
cv2.rectangle(image, start, end, (0,0,255), thickness=2)
cv2.imshow('window', image)
cv2.waitKey()

2.2.3 face_landmarks
face_landmarks 識別人臉關鍵特征點,
- 引數仍然是待檢測的影像物件,回傳值是包含面部特征點字典的串列,串列長度就是影像中的人臉數,
- 面部特征包括以下幾個部分:nose_bridge (鼻梁)、right _eyebrow (右眼眉)、left_eyebrow (左眼眉)、right_eye(右眼)、left_eye(左眼)、chin(下巴)、 nose_tip(下鼻部)、bottom_lip (下嘴唇)
- 勾勒臉部大體輪廓
# -*-coding:GBK -*-
import face_recognition
from PIL import Image, ImageDraw
image = face_recognition.load_image_file('E:/boys.jpg')
face_landmarks_list = face_recognition.face_landmarks(image)
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image) # 生成一張PIL影像
for face_landmarks in face_landmarks_list:
facial_features = [
'chin',
'left_eyebrow',
'right_eyebrow',
'nose_bridge',
'nose_tip',
'left_eye',
'right_eye',
'bottom_lip'
]
for facial_feature in facial_features:
# print("每個人的面部特征顯示在以下為位置:{}".format(facial_feature))
d.line(face_landmarks[facial_feature], width=5) # 直接呼叫PIL中的line方法在PIL影像中繪制線條,幫助我們觀察特征點
pil_image.show()
2.2.4 face_encodings
face_encodings 獲取影像檔案中所有面部編碼資訊,
- 回傳值是一個編碼串列,引數仍然是要識別的影像物件,如果后續訪問時,需要注意加上索引或遍歷來進行訪問,每張人臉的編碼資訊是一個 128 維向量,
- 面部編碼資訊是進行人像對比的重要引數,
# -*-coding:GBK -*-
import face_recognition
image = face_recognition.load_image_file('E:/boys.jpg')
# 不管影像中有多少個人臉資訊,回傳值都是一個串列
face_encodings = face_recognition.face_encodings(image)
for face_encoding in face_encodings:
print("資訊編碼長度為:{}\n編碼資訊為:{}".format(len(face_encoding), face_encoding))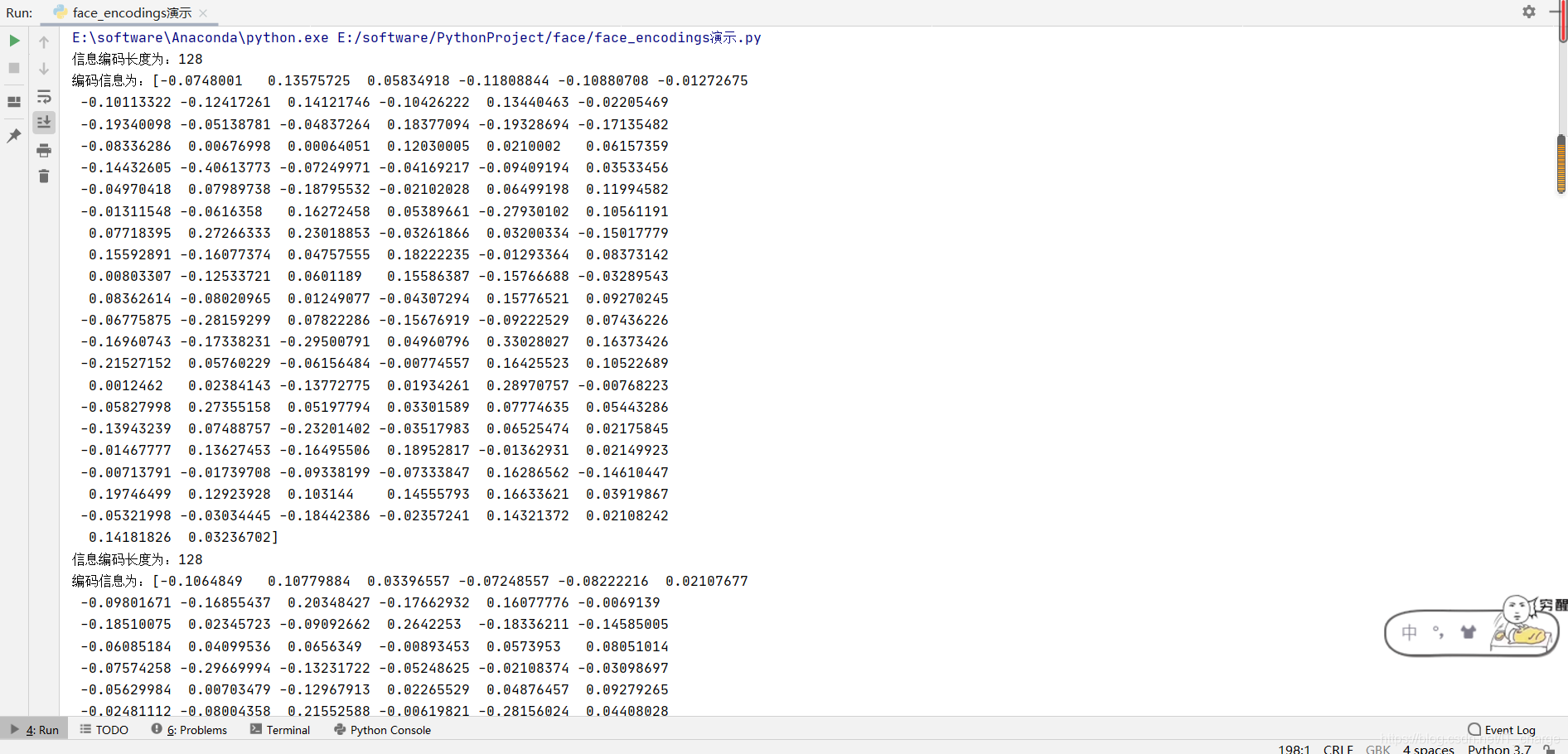
2.2.5 compare_faces
compare_faces 由面部編碼資訊進行面部識別匹配,
- 主要用于匹配兩個面部特征編碼,利用這兩個特征向量的內積來衡量相似度,根據閾值確認是否是同一個人,
- 第一個引數就是一個面部編碼串列(很多張臉), 第二個引數就是給出單個面部編碼(一張臉), compare_faces 會將第二個引數中的編碼資訊與第一個引數中的所有編碼資訊依次匹配,回傳值是一個布爾串列,匹配成功則回傳 True,匹配失敗則回傳 False,順序與第一個引數中臉部編碼順序一致,
- 引數里有一個 tolerance = 0.6,大家可以根據實際的效果進行調整,一般經驗值是 0.39,
tolerance 值越小,匹配越嚴格,
# -*-coding:GBK -*-
import face_recognition
# 加載一張合照
image1 = face_recognition.load_image_file('./facelib/yangmi+liukaiwei.jpeg')
# 加載一張單人照
image2 = face_recognition.load_image_file('./facelib/yangmi.jpg')
known_face_encodings = face_recognition.face_encodings(image1)
# face_encodings回傳的是串列型別,我們只需要拿到第一個人臉編碼即可
compare_face_encodings = face_recognition.face_encodings(image2)[0]
# 注意第二個引數,只能是答案個面部特征編碼,不能傳串列
matches = face_recognition.compare_faces(known_face_encodings, compare_face_encodings)
print(matches)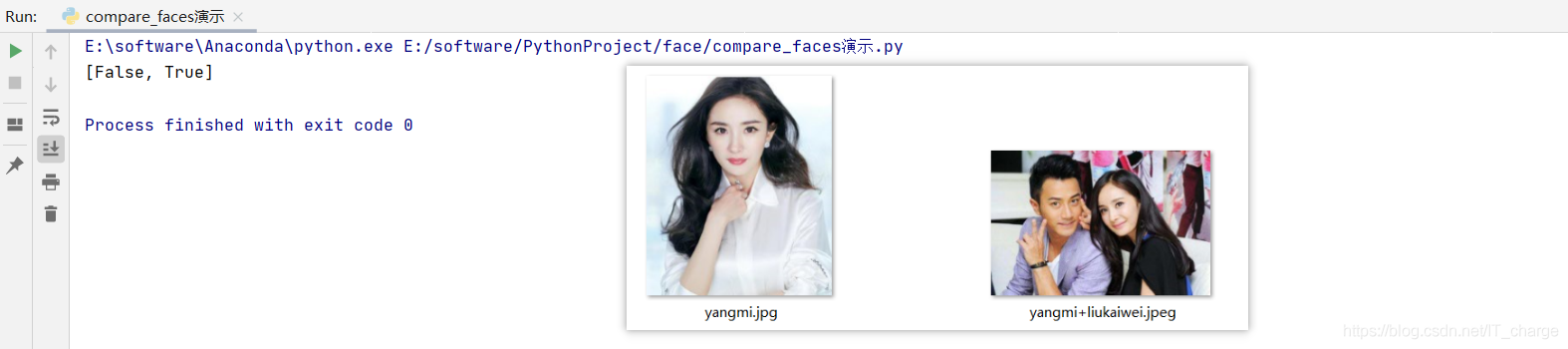
2.2.6 獲取攝像頭的影像資訊
我們可以利用 cv2 模塊中的 VideoCapture 方法,然后每次讀取其中的一幀影像進行處理即可,
# -*-coding:GBK -*-
import cv2
from PIL import Image, ImageDraw
import numpy as np
# 1.呼叫攝像頭
# 2.讀取攝像頭影像資訊
# 3.在影像上添加文字資訊
# 4.保存影像
cap = cv2.VideoCapture(0) # 呼叫第一個攝像頭資訊
while True:
ret, frame = cap.read()
# BGR是cv2 的影像保存格式,RGB是PIL的影像保存格式,在轉換時需要做格式上的轉換
img_PIL = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_PIL)
draw.text((100, 100), 'press q to exit', fill=(255, 255, 255))
# 將frame物件轉換成cv2的格式
frame = cv2.cvtColor(np.array(img_PIL), cv2.COLOR_RGB2BGR)
cv2.imshow('capture', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
cv2.imwrite('out.jpg', frame)
break
cap.release()
3 實作人臉識別的監控系統
整理人臉識別監控系統主要功能:
- 打開攝像頭讀取影像 ok
- 與已知人物頭像進行對比,識別哪些是已知人員,哪些是未知人員 ok
- 在攝像頭影像上直接標注對比結果 ok
- 記錄每次對比的結果,并將未知人員的影像進行保存
- 活體檢測
3.1 人臉識別監控系統
# -*-coding:GBK -*-
import face_recognition
import os
import cv2
from PIL import Image, ImageFont, ImageDraw
import numpy as np
import datetime
import threading
class Recorder:
pass
record_dic = {}
unknown_pic = []
flag_over = 0 # 定義一個是否進行來訪記錄的標記
# 定時去保存對比影像資訊,并且將位置人員的影像保存下來
def save_recorder(name, frame):
global record_dic
global flag_over
global unknown_pic
if flag_over == 1: return
try:
record = record_dic[name]
seconds_diff = (datetime.datetime.now() - record.times[-1]).total_seconds()
if seconds_diff < 60 * 10:
return
record.times.append(datetime.datetime.now())
print('更新記錄', record_dic, record.times)
except KeyError:
newRec = Recorder()
newRec.times = [datetime.datetime.now()]
record_dic[name] = newRec
print('添加記錄', record_dic, newRec.times)
if name == '未知頭像':
s = str(record_dic[name].times[-1])
# print(s)
# 未知人員的圖片名稱
filename = s[:10]+s[-6:] + '.jpg'
cv2.imwrite(filename, frame)
unknown_pic.append(filename)
# 決議已有人員的所有照片并得到照片名和人物面部編碼資訊
def load_img(path):
print('正在加載已知人員的圖片...')
for dirpath, dirnames, filenames in os.walk(path):
print(filenames)
facelib = []
for filename in filenames:
filepath = os.sep.join([dirpath, filename])
# 把對應每張圖片加載進來
face_image = face_recognition.load_image_file(filepath)
face_encoding = face_recognition.face_encodings(face_image)[0]
facelib.append(face_encoding)
return facelib,filenames
facelib, facenames = load_img('facelib')
# print(facenames)
video_capture = cv2.VideoCapture(0)
while True:
ret, frame = video_capture.read()
# 通過縮小圖片(縮小為1/4),提高對比效率
small_frame = cv2.resize(frame, (0,0), fx=0.25, fy=0.25)
rgb_small_frame = small_frame[:,:,::-1] # 將opencv的BGR格式轉換為RGB格式
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
# 回圈多張人臉
for face_encoding in face_encodings:
matches = face_recognition.compare_faces(facelib, face_encoding, tolerance=0.39)
name = '未知頭像'
if True in matches:
# 如果攝像頭里面的頭像匹配了已知人物頭像,則取出第一個True的位置
first_match_index = matches.index(True)
name = facenames[first_match_index][:-4] # 取出檔案上對應的人名
face_names.append(name)
for (top, right, bottom, left), name in zip(face_locations, face_names):
# 還原原圖片大小
top *= 4
right *= 4
bottom *= 4
left *= 4
cv2.rectangle(frame, (left, top), (right, bottom), (0,0,255), thickness=2) # 標注人臉資訊
img_PIL = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype('simhei.ttf', 40)
draw = ImageDraw.Draw(img_PIL)
draw.text((left+6, bottom-6), name, font=font, fill=(255,255,255))
frame = cv2.cvtColor(np.asarray(img_PIL),cv2.COLOR_RGB2BGR)
save_recorder(name, frame)
cv2.imshow('capture', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()

3.2 眨眼活體檢測
# -*-coding:GBK -*-
from scipy.spatial import distance
import dlib
import cv2
from imutils import face_utils
def eye_aspect_ratio(eye):
'''
計算EAR值
:param eye: 眼部特征點陣列
:return: EAR值
'''
A = distance.euclidean(eye[1], eye[5])
B = distance.euclidean(eye[2], eye[4])
C = distance.euclidean(eye[0], eye[3])
return (A+B) / (2.0*C)
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# 設定眼睛縱橫比的閾值
EAR_THRESH = 0.3
# 我們假定連續3幀以上的EAR的值都小于閾值,才確認是產生了眨眼操作
EAR_CONSEC_FRAMES = 3
# 人臉特征點中對應眼睛的那幾個特征點的序號
RIGHT_EYE_START = 37-1
RIGHT_EYE_END = 42-1
LEFT_EYE_START = 43-1
LEFT_EYE_END = 48-1
frame_counter = 0 # 連續幀的計數
blink_counter = 0 # 眨眼的計數
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 轉化為灰度影像
rects = detector(gray, 1) # 人臉檢測
if len(rects) > 0:
shape = predictor(gray, rects[0]) # 檢測特征點
points = face_utils.shape_to_np(shape)
leftEye = points[LEFT_EYE_START:LEFT_EYE_END + 1] # 取出左眼特征點
rightEye = points[RIGHT_EYE_START:RIGHT_EYE_END + 1] # 取出右眼特征點
# 計算左右眼的EAR值
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# 求左右眼EAR的平均值
ear = (leftEAR+rightEAR) / 2.0
# 實際判斷一下眼輪廓部分代碼并不是必須的
# 尋找左右眼的輪廓
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
# 繪制左右眼輪廓
cv2.drawContours(frame, [leftEyeHull], -1, (0,255,0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
# 如果EAR小于閾值,開始計算連續幀
if ear < EAR_THRESH:
frame_counter += 1
else:
if frame_counter >= EAR_CONSEC_FRAMES:
print('眨眼檢測成功,請進入')
frame_counter += 1
break
frame_counter = 0
cv2.putText(frame, "COUNTER: {}".format(frame_counter), (150, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "Blinks: {}".format(blink_counter), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# cv2.putText(frame, 'blink:{}'.format(blink_counter))
cv2.imshow('window', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
cv2.imwrite('out.jpg', frame)
break
cap.release()
cv2.destroyAllWindows()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290447.html
標籤:python