目錄
前言
專案介紹
多的我就不說了,源代碼附有詳細說明
前言
激動的心,顫抖的手,老婆你們誰沒有?

(圖片來源于米游社)
7月21號《原神》2.0發布,大家更新了嗎?
更新內容一覽:
1、稻妻城:稻妻城和六大島嶼相連,目前新的島嶼只是其中三個;
2、家園系統更新:會新增植物,種植系統;
3、新圣遺物:稻妻會上三種新圣遺物;
4、主要登場人物:八重神子、珊瑚宮星海,早柚、神里綾華、托馬、巴爾、宵宮、五郎,
激動的我,在逛米游社的時候,看著這些cos美女已經按捺不住了,連夜的給大家爬了cos同人圖,保存了!有福同享,下面我們一起來看看這些美女,不對是代碼操作,正好給大家一個練手的小專案!
首先,我們來看看效果圖:
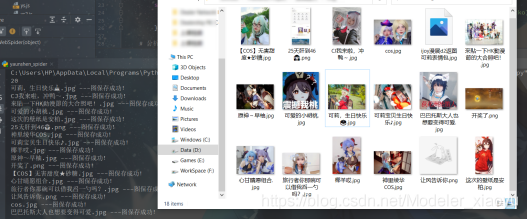
專案介紹
開發環境: Python3.6
模塊(庫): requests/ json /os/ threading
爬取目標:爬取的是原神官方網站,米游社,https://bbs.mihoyo.com/ys/home/49 (米游社.原神)
目的:爬取COS專區下的圖片,并保存
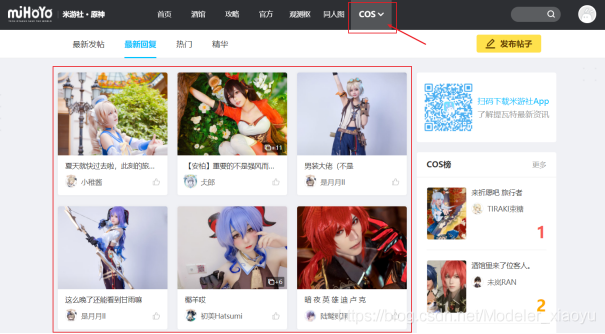
在COS專區下的圖片排序以最新回復欄目排序,因此所爬取的圖片會隨著最新的時間而更改,程式運行時自動爬取最新20條最新圖片,
1、匯入庫
import requests
import json
import os
import threading2、初始化URL地址、設定UA代理(注意:這里的url并不是首頁,而是一個二級頁面)
class WebSpider(object):
def __init__(self):
self.url = 'https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=49'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/92.0.4515.107 Safari/537.36'
}3、分析資料并儲存為字典回傳
def parse(self):
img_dict_data = {}
res = requests.get(self.url, headers=self.headers).content.decode('utf-8')
res = json.loads(res)
res = res['data']['list']
subject_name = [i['post']['subject'] for i in res]
cover_url = [i['post']['cover'] for i in res]
# print(cover_url, subject_name)
# 獲取對應的標題以及圖片地址
for name, url in zip(subject_name, cover_url):
# print(name, url)
img_dict_data[name] = url
return img_dict_data 4、 保存圖片
def save_img(self, data):
for k, v in data.items():
img_type = v.split('/')[-1].split('.')[-1]
save_path = os.path.dirname(os.path.join(__file__)) + '/img' # 當前目錄下的圖片保存路徑
if not os.path.exists(save_path):
os.mkdir('img')
with open(f'img/{k}.{img_type}', 'wb') as f:
img = requests.get(v, headers=self.headers).content f.write(img)
print(f'{k}.{img_type} ---圖保存成功!')運行示例圖:
多的我就不說了,源代碼附有詳細說明:
"""
爬取地址:https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=49
getForumPostList:api回傳當前最新回復的串列json資料
forum_id=49:COS欄目ID資料為 49
"""
import requests
import json
import os
import threading
class WebSpider(object):
def __init__(self):
self.url = 'https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=49'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/92.0.4515.107 Safari/537.36'
}
def parse(self):
img_dict_data = {}
res = requests.get(self.url, headers=self.headers).content.decode('utf-8')
res = json.loads(res)
res = res['data']['list']
subject_name = [i['post']['subject'] for i in res]
cover_url = [i['post']['cover'] for i in res] # 遍歷圖片的URL地址
# print(cover_url, subject_name)
# 獲取對應的標題以及圖片地址
for name, url in zip(subject_name, cover_url):
# print(name, url)
img_dict_data[name] = url # 字典增加資料
return img_dict_data # 回傳資料
# 保存圖片
def save_img(self, data):
for k, v in data.items():
img_type = v.split('/')[-1].split('.')[-1] # 獲取圖片型別
save_path = os.path.dirname(os.path.join(__file__)) + '/img' # 當前目錄下的圖片保存路徑
if not os.path.exists(save_path): # img檔案夾不存在時則創建新檔案夾
os.mkdir('img')
with open(f'img/{k}.{img_type}', 'wb') as f:
img = requests.get(v, headers=self.headers).content # 發送請求獲取圖片內容
f.write(img) # 寫入資料
print(f'{k}.{img_type} ---圖保存成功!')
def main(self):
data = self.parse()
self.save_img(data)
(圖片來源于米游社,左一神里同人圖,右一博主仧郎的cos圖)
有這技術 還要啥自行車?福利已經發布,大家可以留下你們的贊再走!!原始碼獲取看簡介!!關鍵詞回復“原神”
往期回顧:保姆級爬蟲教程:python爬取“實習網”資訊,找不到實習作業你打我!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291045.html
標籤:python