Python期末考試知識點(史上最全)






python簡介
Python是一種解釋型語言
Python使用縮進對齊組織代碼執行,所以沒有縮進的代碼,都會在載入時自動執行
資料型別:整形 int 無限大
浮點型 float 小數
復數 complex 由實數和虛陣列成
Python中有6個標準的資料型別:
Number(數字)
String(字串)
List(串列)
Tuple(元組)
Sets(集合)
Dictionart(字典)
其中不可變得資料:
Number(數字) String(字串) Tuple(元組) Sets(集合)
可變得:
List(串列) Dictionart(字典)
我們可以用type或者isinstance來判斷型別

type()不會認為子類是一種父型別別,
isinstance()會認為子類是一種父型別別
python中定義變數,不需要寫變數型別,但是必須初始化,會根據我們寫的資料型別,自動匹配
變數命名規則:由字母,數字,下劃線組成,第一個必須字母或者下劃線,對大小寫敏感,不能是關鍵字
輸入與輸出
在我們需要輸入中文的時候,需要包含頭檔案 # -*- coding: UTF-8 -*- 或者 #coding=utf-8
輸入 a=input("請輸入一個數字") 回傳值為str型別
輸出 print('hello world') 當然這里也可以嚴格按照格式控制符去輸出變數值
例如:print("now a=%d,b=%d"%(a,b)) 雙引號后面沒有逗號
print默認換行,我們可以print( end=''),修改默認引數讓他不換行,
也可以在print()后面加逗號 print(xxx) , 這樣也可以不換行 測驗發現:只適合在2.7版本
- 基礎語法
運算子:
算術運算子: 多了一個**,代表 冪方 5**5 就是5的5次方 還多了一個 // 整數除法
邏輯運算子: and,or,not 與,或,非
賦值運算子: 沒有++,–
身份運算子: is is not
成員關系運算子: in not in
總結:多出來了** 和 // //就是整除的意思 比如 5//3結果為 1 但是5/3結果為小數 1.6666666667
運算子優先級(下面由高到低):冪運算子最高
冪運算子 **
正負號 + -
算術運算子 *,/,//,+,-
比較運算子 <,<=,>,>=,==,!=
邏輯運算子 not,and,or (not>and>or)
選擇結構
if-else
if-elif-else(這里可以不寫else)
邏輯結果
python里面只要是"空”的東西都是false ""(中間有空格就為真,這里什么都不寫,為假) 空元組,空串列,空字典 0 都為false
字串
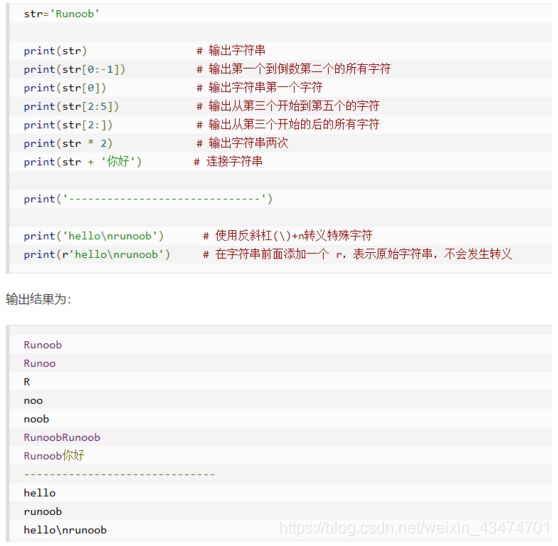
Pis:在字串前面添加一個 r,表示原始字串,不會發生轉義
串列
list是處理一組有序專案的資料結構,用方括號定義
串列的操作:
一,通過下標去訪問串列中的值 (可以用切片的方式去訪問)
輸出結果:這里就用了切片的方式去訪問1到5
重點:這里切片的使用方法要注意,我們寫的1:5實際訪問的是下標為1,2,3,4.沒有5!
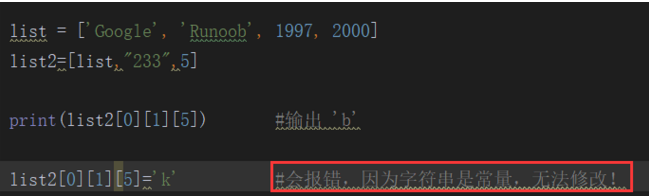
二,更新串列(串列是可以修改的)
通過下標去直接修改他的值
三,洗掉串列元素(del + 串列項) 洗掉項remove()后面說
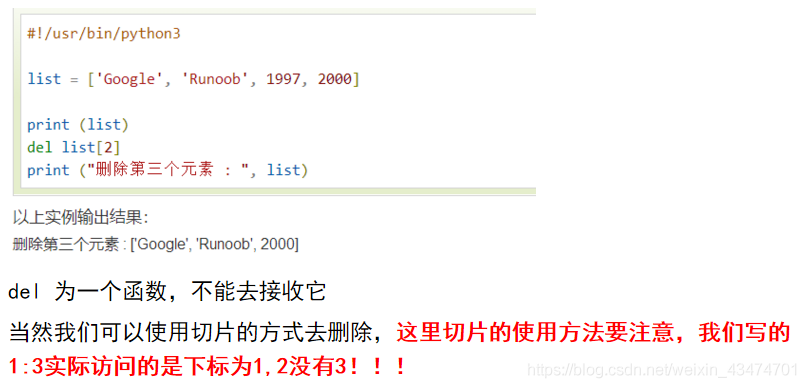
四,串列的腳本運算子
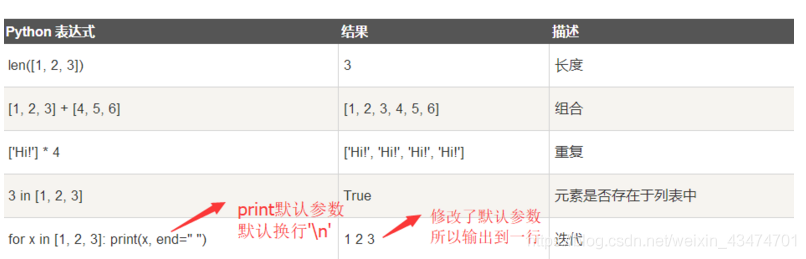
五,對于串列截取,拼接

六,list自帶函式 (其中有元組轉串列)
方法 功能
max(list) 回傳串列元素最大值
min(list) 回傳串列元素最小值
list(seq) 元組轉串列
list.append(obj) 在串列末尾添加新物件
list.count(obj) 統計某個元素在串列出現的次數
list.extend(seq) 在末尾添加新串列,擴展串列
list.index(obj) 在串列中找出某個值第一個匹配性的索引位置
list.insert(index,obj) 將物件插入串列,其中的index,為插入的位置,原來該位置后面的元素包含該位置元素,都統一后移
list.pop(obj=list[-1])
有默認引數,即最后一項 洗掉指定位置元素并回傳,他和del的區別在于del是一個關鍵字,而pop是內建函式,我們無法用變數去接收del洗掉的項 (引數可以不寫,默認洗掉最后一項)
list.remove(obj) 移出串列中某個值第一次匹配的項
list.reverse() 反向串列中的元素(收尾互換),不代表倒序排列!
list.sort() 對串列進行排序
list.copy() 復制串列
list.clear() 清空串列
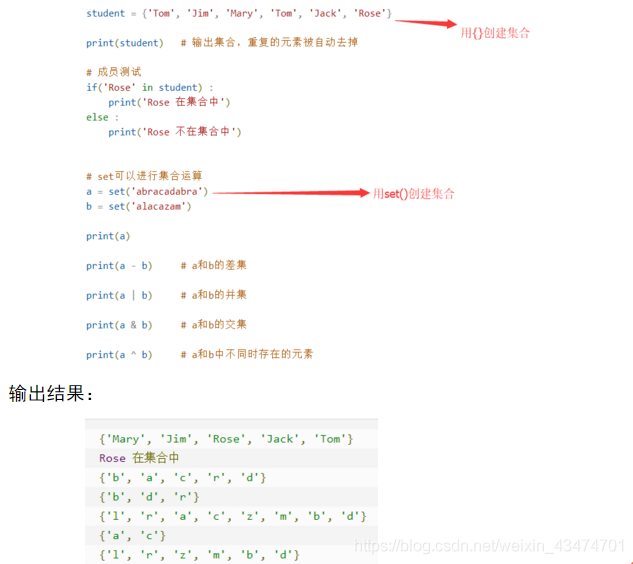
Set集合
集合是一個無序不重復元素的序列
基本功能就是進行成員關系測驗,和洗掉重復元素 (所謂成員關系測驗就是查看他們是否重復,兩個集合的交集…)
可以使用 { } 或者set()函式來創建集合 但是創建一個空集合必須適用set()
編程語言的進化:機器語言、匯編語言、高級語言
機器語言:由于計算機內部只能接受二進制代碼,因此,用二進制代碼0或1描述的指令稱為機器指令,全部機器指令的集合構成計算機的機器語言,
匯編語言:實質和機器語言是相同的,都是直接對硬體操作,只不過指令采用英文縮寫的識別符號,更容易識別和記憶,
高級語言:高級語言對開發人員更加友好,開發效率大大提高
高級語言所編制的程式不能直接被計算機識別,必須經過轉換才能被執行,
高級語言按轉換方式可分為:編譯型、解釋型
編譯型:指在應用源程式執行之前,將程式源代碼轉換成目標代碼,因此其目標代碼可以脫離其語言環境獨立執行,
編譯后程式運行時不需要重新翻譯,直接使用翻譯的結果就行,程式執行效率高,依懶性編譯器,跨平臺性差,如C、C++、GO、Delphi等
解釋型:應用程式源代碼一邊由相應語言的解釋器翻譯成目標代碼,一邊執行,因此效率比較低,不能生成可獨立執行的可執行檔案,應用程式不能脫離其解釋器,如Python、Java、PHP、Ruby等,跨平臺性好、開發效率不高,
編譯型語言執行速度快,不依賴語言環境運行,跨平臺差
解釋型跨平臺好,一份代碼,到處運行,缺點是執行速度慢,依賴解釋器運行,
Python創始人:Guido van Rossum(龜叔)
Python誕生在1989年
2008年12月出現Python3.0
2010年出現一個過渡版本Python2.7(最多只支持到2020年,之后不支持2.0版本)
Python解釋器是用C語言寫的
Python解釋器種類有:CPython、IPython、PyPy、Jython、IronPython
測驗安裝是否成功:
windows–>運行–>輸入cmd,回車,彈出cmd程式,輸入Python,如果進入互動環境,代表安裝成功,
print(‘hello world!’)
保存為helloworld.py,注意.py后綴名的作用:命名約束規范,方便程式員識別代碼,
進入cmd命令列,執行Python helloworld.py,看結果,
注意檔案名前面加python的原因是要把代碼交給python解釋器去解釋執行
記憶體和磁盤的關系:記憶體存取速度快,斷電就丟失;磁盤存取速度慢,永久保存,
Python互動器是主要用來對代碼進行除錯用的
變數:先定義后使用
變數作用:存資料,占記憶體,存盤程式運行的中間結果,可以被后面的代碼呼叫,
宣告變數:變數名=變數的值
變數的命名規則:
1.變數名只能是數字、字母或下劃線的任意組合
2.變數名的第一個字符不能是數字
3.以下關鍵字不能宣告為變數名[‘and’,‘as’,‘assert’,‘break’,‘class’,‘continue’,‘def’,‘elif’,‘else’,‘except’,‘exec’,‘finally’,‘for’,‘from’,‘global’,‘if’,‘import’,‘in’,‘is’,‘lambda’,‘not’,‘or’,‘pass’,‘print’,‘raise’,‘return’,‘try’,‘while’,‘with’,‘yield’]
常量:程式在執行程序中不能改變的量
在Python中沒有一個專門的語法代表常量,程式員約定俗成的變數名全部大寫代表常量,
讀取用戶輸入
name = input(“what’s your name:”)print(“hello”+name)
輸入用戶姓名和密碼
username= input(“username:”)
password= input(“password:”)print(username,password)
注釋:解釋說明,幫助閱讀代碼,
單行注釋:#
多行注釋:’’’…’’’
資料型別
資料型別-數字型別
int(整型):32位機器上:-231 —— 231-1 64位同樣的道理
long(長整型):Python的長整型沒有指定位寬,(Python3里不再有long型別)
float(浮點型):
資料型別-字串型別
字串:在Python中,加了引號的字符都被認為是字串!
注意:單雙引號是沒有任何區別的;多行字串必須用多引號,
布爾型別:
只有兩個值True、False ,主要用來做邏輯判斷
格式化輸出:(%s 以一個字符替換 %d以一個整數替換 %f以一個浮點數替換)都是一個占位符 %是一個連接符
運算子
算術運算子(+,-,*,/,%,**,//),
比較運算子(==,!=,<>,>,<,>=,<=),
邏輯運算子(and,or,not),
賦值運算子(=,+=,*=,/=,%=,**=,//=),
成員運算子(in,not in),
身份運算子(is , is not),
位運算(>>,<<)
流程控制
單分支:
if 條件:
滿足條件后要執行的代碼塊
多分支:
if 條件:
滿足條件后要執行的代碼塊
elif 條件:
上面的條件不滿足就走這個
elif 條件:
上面的條件不滿足就走這個
elif 條件:
上面的條件不滿足就走這個
else:
上面的條件不滿足就走這個
while回圈
while 條件:
執行代碼…
Dead Loop
count=0
while True:
print(“你個基佬!!!”,count)
count+=1
回圈終止陳述句:break陳述句或continue陳述句
break陳述句:用于完全結束一個回圈,跳出回圈體執行后面的陳述句
continue陳述句:只終止本次回圈,接著執行后面的回圈
while…else用法
當while回圈正常執行完,中間沒有被break終止的話,就會執行else后面的陳述句,
二進制運算、字符編碼、資料型別
二進制(0,1)、八進制(0-7)、十進制(0-9)、十六(0-9,A-F)進制的轉換
四位二進制表示一位十六進制
oct() 八進制 hex()十六進制
char(num)將ASCII值得數字轉換成ASCII字符,范圍只能是0-255
ord(char)接受一個ASCII值字符,回傳相應的ASCII值
每一位0或1所占的空間單位為bit(位元),這是計算機中最小的表示單位
8bits = 1Bytes位元組,最小的存盤單位,1bytes縮寫為1B
1024Bytes = 1KB = 1KB
1024KB = 1MB
1024MB =1GB
1024GB = 1TB
1024TB = 1PB
ASCII 256,每一個字符占8位
Unicode編碼(統一碼、萬國碼):規定了所有的字符和符號最少由16位表示
UTF-8:ascii碼中的內容用1個位元組保存,歐洲的字符用2個位元組保存,東亞的字符用3個位元組保存…
winsows系統中文版默認編碼是GBK
Mac OS\Linux系統默認編碼是UTF-8
UTF是為unicode編碼 設計的一種在存盤和傳輸時節省空間的編碼方案,
無論以什么編碼在記憶體里顯示字符,存到硬碟上都是二進制,不同編碼的二進制是不一樣的
存到硬碟上以何種編碼存的,那么讀的時候還得以同樣的編碼讀,否則就亂碼了,
python2.x默認編碼是ASCII;默認不支持中文,支持中文需要加:#* coding:utf-8 * 或者 #!encoding:utf-8
Python3.x默認編碼是UTF-8,默認支持中文
Python資料型別
字串 str
數字:整型(int)長整型(long) 浮點型(float) 布爾(bool) 復數(complex)
串列 list
元組 tuple
字典 dictionary
集合:可變集合(set) 不可變集合(frozenset)
不可變型別:數字,字串,元組
可變型別:串列,字典,集合
899590-20180512120213031-26929447.png
字串
特點:有序、不可變
字串的常用方法:isdigit,replace,find,count,index,strip,split,format,join,center
ContractedBlock.gif
ExpandedBlockStart.gif
1 s = “abcd”
2 print(s.swapcase()) #都變成大寫字母
3
4 print(s.capitalize()) #都變成首字母大寫
5
6 print(s.center(50,"")) #列印變數s的字串 指定長度為50,字串長度不夠的用號補齊
7
8 print(s.count(“a”,0,5)) #統計字串a在變數里有幾個;0,5代表統計范圍是下標從0-5的范圍
9
10 print(s.endswith("!")) #是否是以什么結尾的,
11
12 print(s.startswith(“a”)) #判斷以什么開始
13
14
15 s = “a b”
16 print(s.expandtabs(20)) #相當于在a和b中間的tab長度變成了20個字符,互動模式可看出效果
17
18 s.find(“a”,0,5) #查找字串,并回傳索引
19
20 s.format() #字串格式化
21 s1 = “my name is {0},i am {1} years old”
22 print(s1)23 print(s1.format(“aaa”,22)) #分別把{0}替換成aaa {1}替換成22
24 #也可以寫成如下
25 s1 = “my name is {name},i am {age} years old”
26 s1.format(name=“aaa”,age = 22) #字典形式賦值
27
28 #s.format_map() #后續補充
29
30
31 print(s.index(“a”)) #回傳索引值
32
33 print(s.isalnum()) #查看是否是一個阿拉伯字符 包含數字和字母
34
35 print(s.isalpha()) #查看是否是一個阿拉伯數字 不包含字母
36
37 print(s.isdecimal()) #判斷是否是一個整數
38
39 print(s.isdigit()) #判斷是否是一個整數
40
41 print(s.isidentifier()) #判斷字串是否是一個可用的合法的變數名
42
43 print(s.islower()) #判斷是否是小寫字母
44
45 print(s.isnumeric()) #判斷只有數字在里邊
46
47 print(s.isprintable()) #判斷是否可以被列印,linux的驅動不能被列印
48
49 print(s.isspace()) #判斷是否是一個空格
50
51 print(s.istitle()) #判斷是否是一個標題 每個字串的首字母大寫 Hello Worlld
52
53 print(s.isupper()) #判斷是否都是大寫
54
55 #s.join()
56 name = [“a”,“b”,“1”,“2”]57 name2 = “”.join(name) #串列轉成字串,把串列里邊的元素都join到字串中
58 print(name2) #得出ab12
59
60 #s.ljust
61 s = “Hello World”
62 print(s.ljust(50,"-")) #給字串從左往右設定長度為50,字串長度不夠用 - 補充
63
64 print(s.lower()) #字串都變成小寫
65
66 print(s.upper()) #變大寫
67
68 print(s.strip()) #脫掉括號里邊的,可以是空格 換行 tab …
69
70 s.lstrip() #只脫掉左邊的空格
71 s.rstrip() #只拖點右邊的空格
72
73 #s.maketrans() #
74 str_in = “abcdef” #必須是一一對應
75 str_out = “!@#$%^” #必須是一一對應
76 tt = str.maketrans(str_in,str_out) #生成對應表,就像密碼表一樣
77 print(tt)78 #結果:{97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94}
79
80 print(s.translate(tt)) #s.translate方法呼叫 加密方法tt 給 s的字串加密
81 #結果:H%llo Worl$
82
83 #s.partition()
84 s = “Hello World”
85 print(s.partition(“o”)) #把字串用 從左到右第一個o把 字串分成兩半
86 #結果:(‘Hell’, ‘o’, ’ World’)
87
88 s.replace(“原字符”,“新字符”,2) #字串替換,也可以寫換幾次 默認全換,可以設定count次數
89
90 s.rfind(“o”) #查找最右邊的字符,也有開始和結束
91
92 print(s.rindex(“o”) ) #查找最右邊的字符的索引值
93
94 s.rpartition(“o”) #從最右邊的字符開始 把字串分成兩半
95
96 s.split() #已括號里邊的把字串分成串列,括號里可以是空格、等字符來分成串列
97
98 s.rsplit() #從最右邊以 某字符 來分開字串
99
100 s.splitlines() #設定以換行的形式 把字串分成串列
101
102 print(s.swapcase()) #字母換成相反的大小寫,大的變成小,小的變成大
103 #結果“:hELLO wORLD
104 #原來的“hello World”
105
106 s.title() #把字串變成title格式 Hello World
107
108 s.zfill(40) #把字串變成40,字串不夠,從左往右用0 補齊
109
110
111 #“a\tb” 字串中間的\t 被認為是tab 是4個或者8個空格
112 #整體意思是:a 有一個tab 然后 又有一個b
View Code
串列
串列的常用方法:創建、查詢、切片、增加、修改、洗掉、回圈、排序、反轉、拼接、clear、copy
串列的特點:可以重復;串列是有序的
ContractedBlock.gif
ExpandedBlockStart.gif
1 1、創建2 ? 方法一:list1 = [“a”, “b”] #常用
3 ? 方法二:list2 = list () #一般不用這種方法
4
5 2、查詢6 ? 串列的索引 (也稱下標):7 串列從左到右下標是從0開始0、1、2、3…8 ?串列從右到左下標是從 - 1開始 -1 -2 -3…9
10 ?查詢索引值:11 ?list1.index (a) #index查詢找到第一個a程式就不走了,
12 list1[0] #通過a的索引 得出a
13 list1[-1] #通過b的下標 得出b
14
15 當list1 = [1, 2, 3, 4, 4, 4, 4, 4, 4]16 串列里出現元素相同時,統計相同次數17 list1.count (4) #統計得出:6 代表串列有6個4
18
19 3、切片20 切片:通過索引 (或下標)21 截取串列中一段資料出來,22 list1 = [1, 2, 3, 4, 4, 4, 4, 4, 4]23 list1[0:2] #得出 [1,2] ,串列切片顧頭不顧尾,也可成list1[:2]
24 list1[-5:] #得出[4,4,4,4,4],取最后5個元素,只能從左往右取
25 按步長取元素:26 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5]27 list1[:6:2] #得出:[1, 3, 5] :2 代表步長 ,每隔兩步取一個元素
28 list1[::2] #得出:[1, 3, 5, 1, 3, 5] 在串列所有元素中,每隔2步取一個數
29
30 4、增加31 list1 = [“a”, “b”, “c”]32 list1.append (“d”) #追加d到串列list1的最后 結果:[‘a’, ‘b’, ‘c’, ‘d’]
33 list1.insert (1, “aa”) #插入aa到串列下標為1的之前 得出結果:[‘a’, ‘aa’, ‘b’, ‘c’, ‘d’]
34
35 5、修改36 list1[1] = “bb” #直接給對應位置賦值,即是修改 結果:[‘a’, ‘bb’, ‘b’, ‘c’, ‘d’]
37 批量修改38 把[‘a’, ‘bb’, ‘b’, ‘c’, ‘d’]里的前兩個元素替換掉39 list1[0:2] = “boy” #結果:[‘b’, ‘o’, ‘y’, ‘b’, ‘c’, ‘d’]
40
41 6、洗掉42 list1 = [‘b’, ‘o’, ‘y’, ‘b’, ‘c’, ‘d’]43 list1.pop () #默認洗掉最后一個元素 d
44 list1.remove (“o”) #洗掉元素O remove只能一個一個洗掉
45 list1.remove (0) #洗掉下標為0的元素 b
46 del list1[0] #洗掉下標為0的元素 del是一個全域刪的方法
47 del list1[0:2] #del可以批量洗掉
48
49 7、for回圈串列50 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5]51 for i in list1: #使用for回圈回圈串列list1里邊的元素
52 range (10) #生成0到10 的數字
53
54 8、排序55 list1 = [“1”, “5”, “3”, “a”, “b”, “f”, “c”, “d”, “A”, “C”, “B”]56 list1.sort () #結果:[‘1’, ‘3’, ‘5’, ‘A’, ‘B’, ‘C’, ‘a’, ‘b’, ‘c’, ‘d’, ‘f’]
57
58 排序是按照ASCII碼對應排序,59 反轉60 list1.reverse () #結果:[‘f’, ‘d’, ‘c’, ‘b’, ‘a’, ‘C’, ‘B’, ‘A’, ‘5’, ‘3’, ‘1’]
61
62 9、兩個串列拼一塊63 #方法一
64 list1 = [1, 2, 3, 4, 5]65 list2 = [6, 7, 8, 9]66 list1 + list2 #結果:[1, 2, 3, 4, 5, 6, 7, 8, 9]
67 #?方法二
68 list1.extend (list2) #把串列2擴展到list1中
69 結果:[1, 2, 3, 4, 5, 6, 7, 8, 9]70
71 10、clear72 #清空串列
73 list2.clear () #清空list2
74
75 11、copy76 淺copy77 復制串列78 list2 =list1.copy ()79 當串列只有一層資料,沒有串列嵌套串列的情況下,復制后的串列和原來的串列是完全獨立的,80 當串列有多層嵌套的時候,串列嵌套里邊的串列的內容是和原有串列是共享的,81 list1.copy () #所以這個叫做:淺copy
82
83 ?深copy:需要借助python模塊84 importcopy85 list2 =copy.deepcopy (list1)86 深copy后,新的串列和舊的串列,不管有沒有串列嵌套串列,都是完全獨立的個體,87 可以通過查看串列名對應的記憶體地址分辨兩個串列是否獨立88 查看python解釋器里邊的記憶體地址:id (變數名)
View Code
元組
特點:有序的,不可變的串列
常用功能:index,count,切片
使用場景:顯示的告知別人,此處資料不可修改;資料庫連接配置資訊等
hash函式
hash,一般翻譯為“散列”,也有直接翻譯為“哈希”的,就是把任意長度的輸入,通過散列演算法,變成固定長度的輸出,該輸出就是散列值,這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小于輸入的空間,不通的輸入可能會散列成相同的輸出,所以不可能從散列值來確定唯一的輸入值,簡單的說就是一種將任意長度的訊息壓縮到某一固定長度的訊息摘要的函式,
特征:hash值的計算程序是依據這個值的一些特征計算的,這就要求被hash的值必須固定,因此被hash的值必須是不可變的,(不能保證輸出的資料唯一的,容易造成沖突)
用途:檔案簽名;md5加密;密碼驗證
ContractedBlock.gif
ExpandedBlockStart.gif
1 >>> hash(“abc”)2 -6784760005049606976
3 >>> hash((1,2,3))4 2528502973977326415
View Code
字典
語法:info={}
特點:1.key-value結構,key必須是可hash、必須是不可變資料型別、必須唯一
2.每一個key必須對應一個value值,value可以存放任意多個值,可修改,可以不唯一
3.字典是無序的
字典的查找速度快是因為字典可以把每個key通過hash變成一個數字(數字是按照ASCII碼表進行排序的)
字典的方法:增刪改查 多級嵌套 等
ContractedBlock.gif
ExpandedBlockStart.gif
1 #字典方法
2 info ={3 “student01”:“aaa”,4 “student02”:“bbb”,5 “student03”:“ccc”
6 }7
8 #增加
9 info[“student04”] = “ddd”
10 info[“student05”] = “eee”
11 info[“student06”] = “fff”
12
13 #查詢
14 #判斷student01在不在info字典里
15 print(“student01” in info ) #回傳True
16 print(info.get(“student01”)) #回傳aaa,沒有回傳None
17 info[“student01”] #獲取對應的value ,如果沒有這個key 就報錯,所以一般用get
18
19 #洗掉
20 print(info.pop(“student01”)) #洗掉key
21 print(info.popitem()) #隨機洗掉一個key
22 del info[“student02”] #洗掉的key ,如果沒有洗掉的key 就報錯 KeyError: ‘student01’
23
24 info.clear() #清空字典
25
26 #多級字典嵌套
27 dic1 = {“aaa”: {“aa”: 11}, “bbb”: {“bb”: 22}}28
29 #其他方法
30 info ={31 “name1”: [22, “it”],32 “name2”: [24, “hr”],33 “name3”: 33
34 }35
36 info2 ={37 “name1”: 44,38 “name4”: 33,39 1: 2
40 }41 info.keys() #列印所有的key
42 info.values() #列印所有的value
43 info.items() #把字典轉成一個串列
44 info.update(info2) #把兩個字典合成一個,如果有重復的key ,info2里邊的重復key會覆寫info里邊的key
45 info.setdefault(“student07”,“abcdef”) #設定一個默認的key:value ,
46 #如果info字典里沒有key student07 ,那么info字典里有添加 student07:abcdef
47 #如果info字典里已經手動添加了student07的key value,那么這里的student07:abcdef 就不起作用
48 print(info.fromkeys([“name1”,“name2”],“aaa”) ) #從一個可迭代的物件中批量生成key和相同的value
49
50 #字典的回圈:高效回圈
51 for k ininfo:52 print(k,info[k]) #列印key value
53
54 #另外一種方法 低效
55 for k,v in info.items(): #先把字典轉成串列,在回圈,所以低效
56 print(k,v)
View Code
集合
集合是一個無序的、不重復的資料組合
作用:1.去重
2.關系測驗,測驗兩組資料之間的交集、差集、并集等關系
語法:
s = {} #如果為空,就是字典
s = {1,2,3,4} #就成了集合 set
s = {1,2,3,4,1,2} #有重復資料,顯示結果就直接去重{1, 2, 3, 4}
串列轉成給一個字典
l = [1,2,3,4,1,2]
l2 = set(l)
集合的方法
ContractedBlock.gif
ExpandedBlockStart.gif
1 #集合方法
2 s = {1,2,3,4,5} #定義一個集合
3
4 #增加
5 s.add(6)6 print(s) #{1, 2, 3, 4, 5, 6}
7
8 #洗掉
9 #隨機洗掉
10 s.pop()11 print(s) #{2, 3, 4, 5, 6}
12 #指定洗掉,如果不存在,就報錯
13 s.remove(6)14 print(s) #{2, 3, 4, 5}
15 #指定洗掉,如果不存在,不報錯
16 s.discard(6)17 print(s)18
19 #聯合其他集合,可以添加多個值
20 s.update([7,8,9])21 print(s) #{2, 3, 4, 5, 7, 8, 9}
22
23 #清空集合
24 s.clear()25
26
27 #集合的關系測驗
28 iphone7 = {“alex”,“rain”,“jack”,“old_driver”}29 iphone8 = {“alex”,“shanshan”,“jack”,“old_boy”}30
31 #交集
32 print(iphone7.intersection(iphone8))33 print(iphone7 &iphone8)34 #輸出:
35 {‘jack’, ‘alex’}36 {‘jack’, ‘alex’}37
38 #差集
39 print(iphone7.difference(iphone8))40 print(iphone7 -iphone8)41 #輸出:
42 {‘rain’, ‘old_driver’}43 {‘rain’, ‘old_driver’}44
45 #并集 把兩個串列加起來
46 print(iphone7.union(iphone8))47 print(iphone7 |iphone8)48 #輸出:
49 {‘rain’, ‘jack’, ‘old_driver’, ‘alex’, ‘shanshan’, ‘old_boy’}50 {‘rain’, ‘jack’, ‘old_driver’, ‘alex’, ‘shanshan’, ‘old_boy’}51
52 #對稱差集 把不交集的取出來
53 print(iphone7.symmetric_difference(iphone8))54 #輸出:
55 {‘rain’, ‘old_driver’, ‘shanshan’, ‘old_boy’}56
57 s = {1,2,3,4}58 s2 = {1,2,3,4,5,6,}59 #超集 誰是誰的父集
60 print(s2.issuperset(s)) #s2是s的父集
61 print(s2 >=s)62 #輸出:
63 True64 True65
66 #子集
67 print(s.issubset(s2)) #s是s2的子集
68 print(s <=s2)69 #輸出:
70 True71 True72
73 #判斷兩個集合是否不相交
74 print(s.isdisjoint(s2))75 #輸出:
76 False #代表兩個集合是相交的
77
78 s = {1,2,3,-1,-2}79 s2 = {1,2,3,4,5,6}80 s.difference_update(s2) #求出s和s2 的差集,并把差集 覆寫給 s
81 print(s) #結果:{-2, -1}
82
83 s.intersection_update(s2) #求出s和s2的交集,并把交集 覆寫給 s
84 print(s)85 print(s2)86 #結果:
87 {1, 2, 3}88 {1, 2, 3, 4, 5, 6}
View Code
字符編碼
python3
檔案編碼默認 :utf-8
字串編碼:unicode
python2
檔案編碼默認:ascii
字串編碼默認:ascii
如果檔案頭宣告了utf-8,那字串的編碼是utf-8
unicode是一個單獨的型別
python3的記憶體里:全部是unicode
python3執行代碼的程序:
1、解釋器找到代碼檔案,把代碼字串按檔案頭定義的編碼加載到記憶體,轉成unicode
2、把代碼字串按照python語法規則進行解釋
3、所有的變數字符都會以unicode編碼宣告
在python2里邊,默認編碼是ASCII編碼,那么檔案頭宣告是utf-8的代碼,在windows中將顯示亂碼
如何在windows上顯示正常呢?(windows的默認編碼是gbk)
1、字串以gbk格式顯示
2、字串以unicode編碼
修改方法:
1.UTF-8 – >decode解碼 --> Unicode
2.Unicode – > encode編碼 – > GBK / UTF-8
ContractedBlock.gif
ExpandedBlockStart.gif
1 s=“路飛學城”
2 print(“decode before:”,s)3 s2=s.decode(“utf-8”)4 print(“decode after:”,s2)5 print(type(s2))6 s3=s2.encoded(“gbk”)7 print(s3)8 print(type(s3))
View Code
python中bytes型別
二進制的組合轉換成16進制來表示就稱之為bytes型別,即位元組型別,它把8個二進制組成一個bytes,用16進制來表示,
在python2里,bytes型別和字串是本質上時沒有區分的,
str = bytes
python2 以utf-8編碼的字串,在windows上不能顯示,亂碼,
如何在python2下實作一種,寫一個軟體,在全球各國電腦上 可以直接看?
以unicode編碼寫軟體,
s = you_str.decode(“utf-8”)
s2= u"路飛"
unicode型別 也算字串
檔案頭:
python2:以utf-8 or gbk 編碼的代碼,代碼內容加載到記憶體,并不會被轉成unicode,編碼依然是utf-8 或 gbk,
python3:以utf-8 or gbk編碼的代碼,代碼內容加到在記憶體,會被自動轉成unicode,
在python3里,bytes型別主要來存盤圖片、視頻等二進制格式的資料
str = unicode
默認就支持了全球的語言編碼
常見編碼錯誤的原因有:
1、python解釋器的默認編碼
2、python源檔案檔案編碼
3、終端使用的編碼(windows/linux/os)
4、作業系統的語言設定
一、模塊、包
1、什么是模塊?
1、把相同功的函式放在一個py檔案里,稱為模塊,
2、一個PY檔案就稱為一個模塊,
3、模塊有什么好處:
1、容易維護,
2、減少變數和函式名沖突,
4、模塊種類:
1、第三方模塊——別人寫的模塊
2、內置模塊——編譯器自帶模塊(如:os、sys、等)
3、自定義模塊——自己撰寫的模塊
5、模塊怎么匯入:
通過import命令匯入,eg:import os(模塊名)
2、什么是包?
1、把多個模塊放在同一個檔案夾內,這個檔案夾稱為包,
2、檔案夾稱為包還有一個條件——檔案夾里要有__init__.py模塊,
3、模塊與包有什么區別
1、模塊——一個py檔案就稱一個模塊
2、包——一個包含有__init__.py的檔案夾稱為一個包;一個包里可以有多個py模塊,
json、pickle
1、什么是序列化?
1、把記憶體資料轉換成字串,
1、把記憶體資料保存到硬碟,
2、把記憶體資料傳輸給他人(由于網路傳輸是通過二進制傳輸,所以需要進行轉換),
2、序列化的模塊有兩個,json和pickle
2、json、pickle有什么優點和缺點?
1、json——把json所支持的資料轉換成字串
優點:體積小、跨平臺,
缺點:只支持int、str、list、dict、tuple等型別,
2、pickle——把python所支持的所有型別轉換成字串
優點:支持python 全部資料型別
缺點:只能在python平臺使用,占用空間大,
3、json和pickle有4個方法
load 、loads 、dump 、dumps
load:通過open函式的read檔案方法,把記憶體資料轉成字串
loads:把記憶體資料轉成字串
dump:通過open函式的write檔案方法,把字串轉換成相應的資料型別,
dumps:把字串資料轉成相應的資料型別,
shelve
1、什么是shelve?
1、shelve是一種key,value 形式的檔案序列化模塊;序列化后的資料是串列形式,
2、底層封裝了pickle模塊,支持pickle模塊所支持的資料型別,
3、可以進行多次反序列化操作,
hashlib
1、什么是hashlib?
hashlib 模塊——也稱‘哈希’模塊,
通過哈希演算法,可以將一組不定長度的資料,生成一組固定長度的資料散列,
特點:
1、固定性——輸入一串不定長度的資料,生成固定長度的數字散列,
2、唯一性——不同的輸入所得出的資料不一樣,
2、md5
輸入一串不定長度的資料,生成128位固定長度的資料,
特點:
1、數字指紋——輸入一串不定長度的資料,生成128位固定長度的資料(數字指紋),
2、運算簡單——通過簡單的運算就可以得出,
3、放篡改——改動很少,得出的值都會不一樣,
4、強碰撞——已知MD5值,想找到相同的MD5值很難,
函式
1、什么是函式?
把代碼的集合通過函式名進行封裝,呼叫時只需要呼叫其函式名即可,
有什么好處:
1、可擴展
2、減少重復代碼
3、容易維護
2、函式的引數?
函式可以帶引數:
形參:
1、在函式定義是指定,
2、函式呼叫時分配記憶體空間,函式運行結束,釋放記憶體空間,
實參:
1、形式可以是常量、變數、運算式、函式等形式,
2、無論是何種形式,都必須要有明確的值,以便把資料傳遞給形參,
默認引數:
1、函式定義時可以指定默認引數(eg: def func(a,b=1))
2、傳參時指定了默認引數,就使用傳參時的值,沒有指定,則使用默認引數的值,
關鍵引數:
1、函式傳參時需按順序傳參,如果不按順序傳參可以使用關鍵引數傳參,
非固定引數:
1、當不確定引數的數量時可以使用非固定參數,
2、非固定引數有兩種:1.*args——(傳入的引數以元組表示),2.**kwargs——(傳入的闡述用字典表示)
3、函式的回傳值
1、函式可以把運算的結果回傳,
2、函式可以有回傳值,也可以沒有回傳值,
有回傳值——通過return回傳,
沒有回傳值——回傳值為None
3、函式遇到return,代表函式運行結束,
4、函式的種類
嵌套函式——一個函式包含了另一個函式,
高階函式——一個函式的引數參考了另一個函式,一個函式的回傳值是另一個函式,
匿名函式——不用顯式指定函式名的函式(lambrda),常和map和filter配合使用,
遞回函式
1、函式內部參考了函式自身
2、函式里有一個明確的結束條件,
遞回函式的特性:
1、有一個明確的結束條件
2、每次遞回的規模都應有所減少
3、遞回函式的效率不高,
作用域
1、名稱空間
名稱空間就是存放變數名和變數值(eg:x=1)系結關系的地方,
1、名稱空間種類:
local:函式內部,包括形參和區域變數,
global:函式所在模塊的名字空間,
buildin:內置函式的名字空間,
2、變數名的作用域范圍的不同,是由這個變數名所在的名稱空間所決定的,
全域范圍:全域存活,全域有效,
區域范圍:區域存活,區域有效,
2、作用域查找順序
作用域查找順序:
local——》enclosing function——》global——》builtin
local:函式內部,包括形參、區域引數,
enclosing function:內嵌函式,
global:函式所在模塊,
builtin:內置函式,
閉包
1、什么是閉包
1、一個嵌套函式,分別有內函式,外函式,
2、內函式使用了外函式的變數,
3、外函式回傳了內函式的應用地址,
4、那么這個嵌套函式就稱為閉包,
2、閉包有什么意義
1、閉包回傳的物件不僅僅是一個物件,而且還回傳了這個函式的外層包裹的作用域,
2、無論這個函式在何處被呼叫,都優先使用其外層作用域,
裝飾器
1、什么是裝飾器
1、裝飾器本質上就是一個閉包函式,
2、裝飾器的作用是,在不改變原有函式的呼叫方式下,增加代碼的功能,
不喜勿噴,喜歡的點個贊唄!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291051.html
標籤:python