
目錄
- Selenium庫
- 基本用法
- 查找節點
- 查找單個節點
- 查找多個節點
- 節點互動
- 動作鏈
- 執行Javascript代碼
- 獲取節點資訊
- 管理Cookie
- 改變節點的屬性
- 實戰:抓取京東最暢銷的編程書籍
Selenium庫
前面,我們分析的都是簡單的網頁直接加載所得的結果,也就是說,通過requests庫請求的網頁資料都是存在的,
但是,現實并不總是如此,有很多大型的網站其網頁的資料都是通過javascript執行后獲取的,如果需要常規處理爬蟲,我們需要分析JavaScript代碼,
但即使你分析出來了,也可能有大量的資料是經過加密處理的,有時候很難找到決議的規律,這個時候想要抓取資料,就必須等待瀏覽器加載完成之后獲取,
而要得到所見即所得的網頁資料,就必須等待瀏覽器加載完成,這個時候,只要加載完成,不管其使用了多么復雜的反爬蟲技術,都不會影響爬取的結果,
而這個庫就是:Selenium庫,它能模擬瀏覽器進行網頁的加載與生成,也就是所見即所得,老規矩,使用之前必須安裝該庫:
pip install selenium
不過,僅僅有selenium庫是不能運行程式的,因為selenium庫使用了WebDriver介面,比如我們后續都使用Chrome瀏覽器,那么你需要下載chromedriver,下載鏈接如下:
http://npm.taobao.org/mirrors/chromedriver/
在這個鏈接中,找到對應系統,對于Chrome瀏覽器版本的chromedriver進行下載,下載完成之后,建議開發中配置其到PATH開發環境之中,這樣不管專案在哪里都可以運行,
如果你沒有配置環境變數,那么將檔案放在專案目錄也就可以運行,后面會講解不配置環境也可以哪里都可以運行的方式,這里先略過,
基本用法
既然,我們Selenium庫的運行環境已經完全配置成功,下面,我們來實作一個最基本的用法,也就是打開淘寶,并自動搜索不二家棒棒糖,示例如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
try:
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
input = browser.find_element_by_id('key')
input.send_keys("不二家棒棒糖")
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 5)
wait.until(ec.presence_of_all_elements_located((By.ID, 'J_selector')))
print(browser.title)
print(browser.current_url)
print(browser.page_source)
browser.close()
except Exception as e:
print(e)
browser.close()
運行之后,效果如下:
這里,我們通過檔案位置指定,設定了chromedriver,這也就是不配置環境的辦法,不過,這是在專案目錄,你不寫默認也可以運行,而其他的,我們通過browser.get()加載網頁,通過find_element_by_id()發現標簽,通過send_keys()填入標簽內容,通過send_keys(Keys.ENTER)模擬按下回車鍵搜索,至于其他的后續有詳細的介紹,
查找節點
在基本用法中,我們通過find_element_by_id()方法進行查找節點,但是find具有很多的方法,我們先來看一張圖:
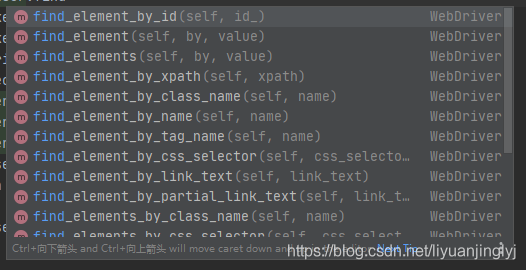
可以看到,我們可以通過class,id,xpath,tag_name等查找節點的內容,而且具有相同標簽或者class等節點的還提供了elements以及element的2種方式,
elements獲取所有集合串列,element獲取一個標簽,如果多個標簽相同,獲取第一個標簽,
查找單個節點
下面,我們來分別使用這些方法,查找節點,首先,我們使用element方法查找單個節點,示例代碼如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
try:
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
# 通過id查找單個元素
input = browser.find_element_by_id('key')
# 通過class查找單個元素
moblie = browser.find_element_by_class_name('mobile_txt')
print(moblie.text)
# 通過class查找單個元素
xpath = browser.find_element_by_xpath('//*[@id="shortcutServiceButton"]')
print(xpath.text)
# 通過name查找單個元素
meta = browser.find_element_by_name('Keywords')
print(meta.get_attribute('content'))
div = browser.find_element_by_tag_name('div')
print(div.text)
# 通過class查找單個元素通用方式
moblie = browser.find_element(By.CLASS_NAME, 'mobile_txt')
print(moblie.text)
browser.close()
except Exception as e:
print(e)
browser.close()
這里,我們使用京東網頁進行測驗獲取單個元素,運行之后,效果如下:
需要額外注意最后一個通用方法:find_element,它前面是指定你根據什么規則去找,后面是這個規則的字串,
查找多個節點
Selenium庫的element()的每個方法,都對應著一個elements()方法,而elements()方法就是用于查找多個節點的方式,示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
try:
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
divs = browser.find_elements_by_tag_name('div')
i = 0
for div in divs:
if i == 5:
break
print(div.text)
i += 1
moblies = browser.find_elements(By.CLASS_NAME, 'mobile_txt')
for moblie in moblies:
print(moblie.text)
browser.close()
except Exception as e:
print(e)
browser.close()
這里,我們只通過2個方法舉例,其他的方法都是直接在element后面加個s即可,因為elements()方法獲取的都是元素串列,所以可以進行一個個的遍歷處理,
運行之后,效果如下:
節點互動
在前面的基礎用法中,我們通過Selenium庫實作了自動搜索等功能,這也是Selenium庫最大的優點,它可以與節點互動,模擬人的操作,

比如,輸入文本框,點擊按鈕,點擊鏈接等等,都屬于互動范疇,Selenium庫都完全支持,這里,我們從京東主頁進入家用電器板塊,代碼如下:
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
a = browser.find_element_by_class_name('cate_menu_lk')
a.click()
其click()方法,就是模擬用戶進行點擊操作,因為這是個超鏈接點擊之后就會跳轉,這里不展示,感興趣的讀者可以自己測驗,
動作鏈
在實際的爬蟲程式中,我們往往并不是只用于跳轉鏈接,獲取搜索而已,更多的時候,我們的動作是連續的,
比如我要模擬一個手機下單,首先需要進入手機購買界面,選擇購買的型號,點擊購買的鏈接,然后付款,這是一個完整的動作鏈,
Selenium庫中,這些動作鏈的實作需要創建ActionChains物件,并通過ActionChains類的若干方法向瀏覽器發送一個或多個動作,
現在,我們來實作一個有趣的動作鏈,剛剛前面不是點擊手機鏈接嗎?現在,我們不點擊鏈接,只將這個二級導航一個一個的展開,示例代碼如下所示:
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
actions=ActionChains(browser)
lis=browser.find_elements_by_css_selector('.cate_menu_item')
for li in lis:
actions.move_to_element(li).perform()
time.sleep(2)
運行之后,效果如下:
其動作鏈還有很多其他的操作方式,比如拖動操作使用的是drag_and_drop(),雙擊double_click()等,這些一個一個講太多,使用方式與這個差不多,所以跳過,
執行Javascript代碼
說句不好的爬蟲使用方式,那就是重繪瀏覽量,而很多網頁并不將打開網站視作瀏覽量的增加,而是你瀏覽了或者停留了一段時間才增加瀏覽量,這個時候怎么辦?
我們可以自己定義一個Javascript代碼,將頁面緩慢滑動,或者說直接滑動到底部,示例代碼如下所示:
from selenium import webdriver
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
在Selenium庫中,我們使用execute_script執行Javascript代碼,這里的意思是滑動到網頁的底部,同樣的你可以通過execute_async_script()方法alert一個彈出框,
獲取節點資訊
節點資訊都是一些簡單的資料,這里小編用一個表格專門列出來這些資料如果獲取呼叫,如下表所示:
| 屬性/方法 | 意義 |
|---|---|
| text | 獲取標簽文本 |
| id | 獲取標簽id |
| tag_name | 獲取標簽名稱 |
| size | 獲取節點的尺寸 |
| location | 獲取節點相對于頁面的絕對坐標 |
| get_attribute(‘屬性名’) | 獲取節點屬性 |
這些都是一些簡單的方法,這里就不演示了,不過有一個節點需要注意,它就是location,在我們識別驗證碼的時候,往往用它進行定位然后截圖,當然,其也可以應用于移動元素鎖定位置,
管理Cookie
其實,我們使用Selenium庫用的最多的就是其輔助登錄,要知道現在驗證碼千奇百怪,有的需要手機驗證碼才能登錄,有的需要滑動模塊登錄,但博主相信,以后肯定是二維碼登錄為主,
比如,博主寫過一個搶購茅臺的腳本,就需要開始輔助驗證碼登錄之后,開始搶購,登錄之后,我們主要用于獲取Cookie,下面,我們來模擬京東登錄,并獲取Cookie,示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
login_button = browser.find_element_by_class_name('user_login')
login_button.click()
time.sleep(10)
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
運行之后,效果如下:

可以看到,我們通過get_cookies獲取登錄后的cookie,通過delete_all_cookies洗掉cookie值,如果你有現成的cookie,可以通過add_cookie方法進行設定,
改變節點的屬性
這里,我們來做一個有趣的實驗,比如百度中間有一個百度一下的按鈕,我們這里試著將其移動位置,示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.baidu.com/")
login_button = browser.find_element_by_id('su')
x = [50, 90, 150, 180]
y = [100, 200, 250, 60]
for i in range(len(x)):
js_code='''
arguments[0].style.position="absolute"
arguments[0].style.left="{}px"
arguments[0].style.top="{}px"
'''.format(x[i],y[i])
browser.execute_script(js_code,login_button)
time.sleep(2)
按鈕會在設定的x,y區間每2秒動一次,感興趣的讀者可以自己運行觀察一下,
實戰:抓取京東最暢銷的編程書籍
初始步驟很簡單,就與開頭基礎用法一樣,搜索編程書籍然后跳轉,不過,后面的內容才是真正的爬蟲問題,這里我們先來看看幫當書籍在哪里,如下圖所示:
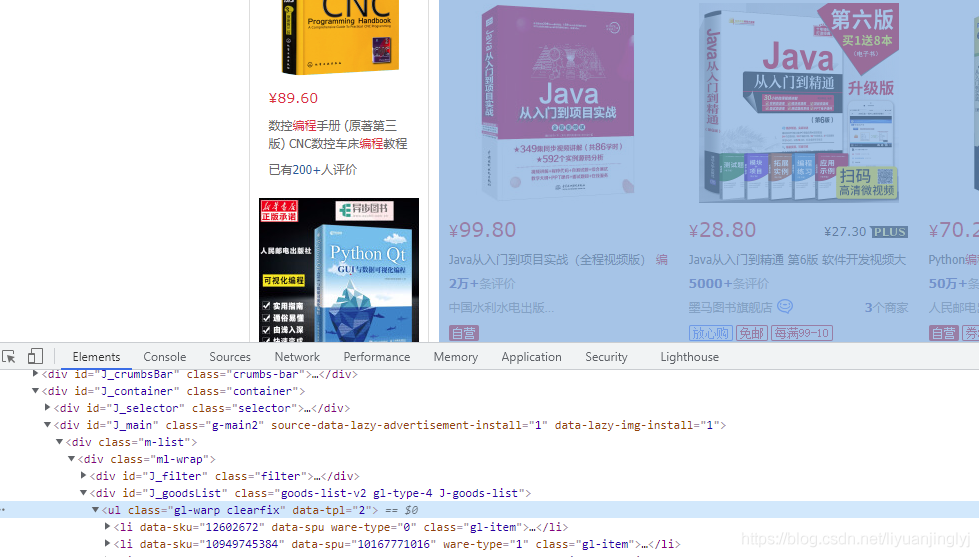
可以看到我們的每個書籍訂單都是在ul之中,不過,這里只是默認的搜索編程書籍出來的結果,我們需要的是銷量排行,所以這里需要再次點擊銷量后,在獲取,
完整的代碼如下所示:
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
try:
browser = webdriver.Chrome('./chromedriver')
browser.get("https://www.jd.com/")
search_edit = browser.find_element_by_id('key')
search_edit.send_keys("編程書籍")
search_edit.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 5)
wait.until(ec.presence_of_all_elements_located((By.ID, 'J_selector')))
time.sleep(5)
sales_volume = browser.find_element_by_css_selector('#J_filter > div.f-line.top > div.f-sort > a:nth-child(2)')
print(sales_volume.text)
sales_volume.click()
time.sleep(5)
wait.until(ec.presence_of_all_elements_located((By.CLASS_NAME, 'tab-content-item')))
div = browser.find_element_by_id('J_goodsList')
ul = div.find_element_by_tag_name('ul')
lis = ul.find_elements_by_tag_name('li')
for li in lis:
title = li.find_element_by_class_name('p-name').find_element_by_tag_name('a')
commit = li.find_element_by_class_name('p-commit').find_element_by_tag_name('a')
price = li.find_element_by_class_name('p-price').find_element_by_tag_name('i')
print("書籍名稱:", title.get_attribute('title'))
print("書籍銷量:", commit.text)
print("書籍購買:", "https://"+title.get_attribute('href'))
print("書籍價格:", price.text)
print()
browser.close()
except Exception as e:
print(e)
browser.close()
運行之后,效果如下:
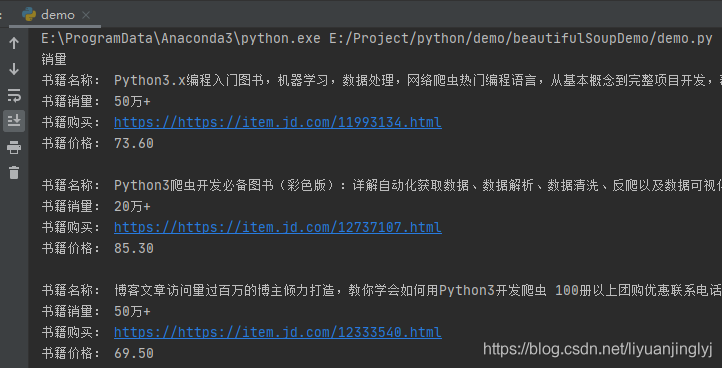
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291204.html
標籤:python