爬蟲基礎簡介
- What is Web Crawler?
- 爬蟲合法性探究
- 爬蟲究竟是合法還是違法的?
- 爬蟲所帶來風險主要體現在以下2個方面:
- 那么作為爬蟲開發者,如何在使用爬蟲時避免進局子的厄運呢?
- 哪些語言可以實作爬蟲
- 爬蟲的分類
- 反爬機制
- 反反爬策略
- robots協議
- http&https協議
- what is http協議 ?
- HTTP作業原理
- 常見的請求頭資訊
- 常見的回應頭資訊
- https協議
- https加密演算法
寫在前面:學習Python爬蟲一直都in the ToDoList,前面因為種種原因擱置,也有好一段時間沒有更新博客,停滯了很長一段時間,也很久可以接觸新事物,后面將會有一段很長的空閑時間,打算從小白開始學習Python爬蟲,重拾CSDN,
What is Web Crawler?
- 形象概念: 爬蟲,即網路爬蟲,大家可以理解為在網路上爬行的一直蜘蛛,互聯網就比作一張大網,而爬蟲便是在這張網上爬來爬去的蜘蛛咯,如果它遇到資源,那么它就會抓取下來,想抓取什么?這個由你來控制它,
- 學術概念:爬蟲就是通過撰寫程式模擬瀏覽器上網,讓其去互聯網上抓取資料的程序,
爬蟲合法性探究
爬蟲究竟是合法還是違法的?
爬蟲作為一種計算機技術就決定了它的中立性,因此爬蟲本身在法律上并不被禁止,但是利用爬蟲技識訓取資料這一行為是具有違法甚至是犯罪的風險的,所謂具體問題具體分析,正如水果刀本身在法律上并不被禁止使用,但是用來捅人,就不被法律所容忍了,
或者我們可以這么理解:爬蟲是用來批量獲得網頁上的公開資訊的,也就是前端顯示的資料資訊,因此,既然本身就是公開資訊,其實就像瀏覽器一樣,瀏覽器決議并顯示了頁面內容,爬蟲也是一樣,只不過爬蟲會批量下載而已,所以是合法的,不合法的情況就是配合爬蟲,利用黑客技術攻擊網站后臺,竊取后臺資料(比如用戶資料等),
舉個例子:像谷歌這樣的搜索引擎爬蟲,每隔幾天對全網的網頁掃一遍,供大家查閱,各個被掃的網站大都很開心,這種就被定義為“善意爬蟲”,但是像搶票軟體這樣的爬蟲,對著 12306 每秒鐘恨不得擼幾萬次,鐵總并不覺得很開心,這種就被定義為“惡意爬蟲”,
爬蟲所帶來風險主要體現在以下2個方面:
- 爬蟲干擾了被訪問網站的正常運營;
- 爬蟲抓取了受到法律保護的特定型別的資料或資訊,
那么作為爬蟲開發者,如何在使用爬蟲時避免進局子的厄運呢?
- 嚴格遵守網站設定的robots協議;
- 在規避反爬蟲措施的同時,需要優化自己的代碼,避免干擾被訪問網站的正常運行;
- 在使用、傳播抓取到的資訊時,應審查所抓取的內容,如發現屬于用戶的個人資訊、隱私或者他人的商業秘密的,應及時停止并洗掉,
哪些語言可以實作爬蟲
- php:可以實作爬蟲,php被號稱是全世界最優美的語言,但是php在實作爬蟲中支持多執行緒和多行程方面做的不好,
- c、c++:可以實作爬蟲,但是使用這種方式實作爬蟲純粹是是某些人(大佬們)能力的體現,卻不是明智和合理的選擇,
- java:可以實作爬蟲,java可以非常好的處理和實作爬蟲,是唯一可以與python并駕齊驅且是python的頭號勁敵,但是java實作爬蟲代碼較為臃腫,重構成本較大,
- python:可以實作爬蟲,python實作和處理爬蟲語法簡單,代碼優美,支持的模塊繁多,學習成本低,具有非常強大的框架且一語難以言表的好!沒有但是!
爬蟲的分類
-
通用爬蟲:通用爬蟲是搜索引擎(Baidu、Google、Yahoo等)“抓取系統”的重要組成部分,主要目的是將互聯網上的網頁下載到本地,形成一個互聯網內容的鏡像備份, 簡單來講就是盡可能的;把互聯網上的所有的網頁下載下來,放到本地服務器里形成備分,在對這些網頁做相關處理(提取關鍵字、去掉廣告),最后提供一個用戶檢索介面,
-
聚焦爬蟲:聚焦爬蟲是根據指定的需求抓取網路上指定的資料,例如:獲取豆瓣上電影的名稱和影評,而不是獲取整張頁面中所有的資料值,
-
增量式爬蟲:增量式是用來檢測網站資料更新的情況,且可以將網站更新的資料進行爬取(后期會有章節單獨對其展開詳細的講解),
反爬機制
- 門戶網站通過制定相應的策略和技術手段,防止爬蟲程式進行網站資料的爬取,
反反爬策略
- 爬蟲程式通過相應的策略和技術手段,破解門戶網站的反爬蟲手段,從而爬取到相應的資料,
robots協議
“君子協議”—— robots.txt,即網站有權規定網站中哪些內容可以被爬蟲抓取,哪些內容不可以被爬蟲抓取,這樣既可以保護隱私和敏感資訊,又可以被搜索引擎收錄、增加流量,
可以通過網站域名 + /robots.txt的形式訪問該網站的協議詳情,例如:www.taobao.com/robots.txt
http&https協議
what is http協議 ?
官方概念: HTTP協議是Hyper Text Transfer Protocol(超文本傳輸協議)的縮寫,是用于從萬維網(WWW:World Wide Web )服務器傳輸超文本到本地瀏覽器的傳送協議,
白話概念: HTTP協議就是服務器(Server)和客戶端(Client)之間進行資料互動(相互傳輸資料)的一種形式,
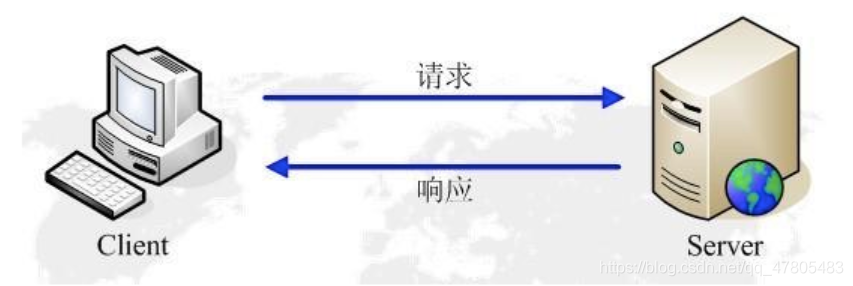
HTTP作業原理
HTTP協議作業于客戶端-服務端架構為上,瀏覽器作為HTTP客戶端通過URL向HTTP服務端即WEB服務器發送所有請求,Web服務器根據接收到的請求后,向客戶端發送回應資訊,
常見的請求頭資訊

常見的回應頭資訊

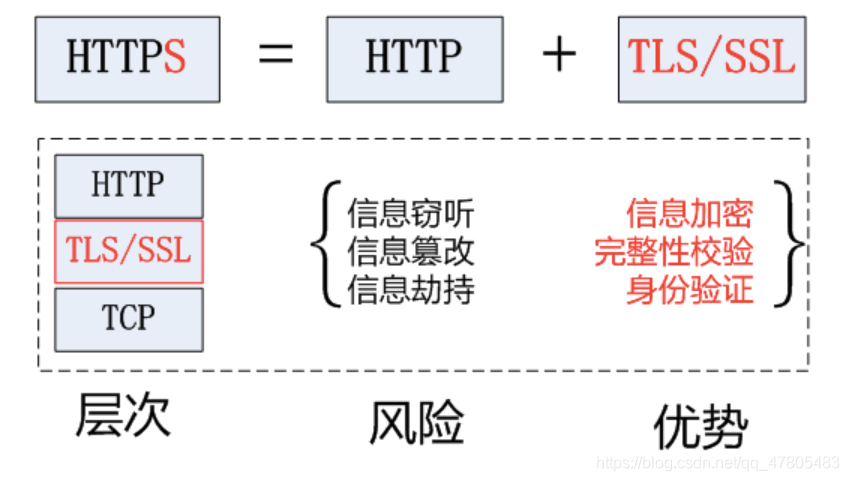
https協議
HTTPS (Secure Hypertext Transfer Protocol)安全超文本傳輸協議,HTTPS是在HTTP上建立SSL加密層,并對傳輸資料進行加密,是HTTP協議的安全版,
https加密演算法
- 對稱秘鑰加密
- 非對稱秘鑰加密
- 證書秘鑰加密
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291492.html
標籤:python