🇨🇳奧運會看著真熱血呀,但也不能忘記學習!在python的資料結構的章節中,我們上次學習到了python面向物件的思想,即我們想用程式來實作一個東西,我們需是用物件的特征來描述我們想構建的物件,感興趣的小伙伴可以查看下面內容👇:
- python資料型別: python資料結構之資料型別.
- python的輸入輸出: python資料結構之輸入輸出、控制和例外.
- python資料結構之面向物件: python資料結構之面向物件.
🍉今天我們來學習的內容是面試題中都避免不小了的問題,就是演算法分析了,什么是演算法分析,演算法分析是用來分析一個演算法的好壞的,大家完成一件事情寫不一樣的演算法,就需要演算法分析來評判演算法的好壞,最常見的就是程式的復雜的O(n),
1.演算法分析的定義
有這樣一個問題:當兩個看上去不同的程式 解決同一個問題時,會有優劣之分么?答案是肯定的,演算法分析關心的是基于所使用的計算資源比較演算法,我們說甲演算法比乙演算法好,依據是甲演算法有更高的資源利用率或使用更少的資源,從這個角度來看,上面兩個函式其實差不多,它們本質上都利用同一個演算法解決累加問題,
計算資源究竟指什么?思考這個問題很重要,有兩種思考方式,
- 一是考慮演算法在解決問題時 要占用的空間或記憶體,解決方案所需的空間總量一般由問題實體本身決定,但演算法往往也會有特定的空間需求,
- 二是根據演算法執行所需的時間進行分析和比較,這個指標有時稱作演算法的執行 時間或運行時間,要 衡 量 sumOfN 函式的執行時間,一個方法就是做基準分析,也就是說,我們會記錄程式計算出結果所消耗的實際時間,在 Python 中,我們記錄下函式就所處系統而言的開始時間和結束時間,time 模塊中有一個 time 函式,它會以秒為單位回傳自指定時間點起到當前的系統時鐘時間,在首尾各呼叫一次這個函式,計算差值,就可以得到以秒為單位的執行時間,
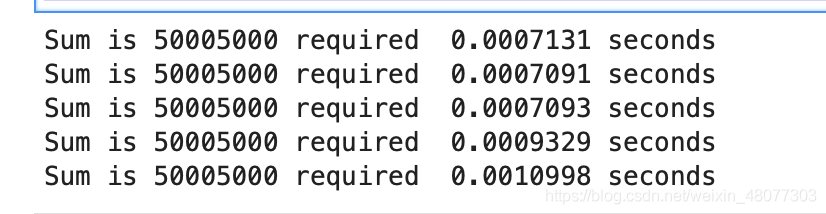
舉個例子:我們需要求解前n個數之和,通過計算所需時間來評判效率好壞,(這里使用time函式,并計算5次來看看大致需要多少時間)
- 第一種方法:回圈方案
import time
def sumOfN2(n):
start=time.time()
thesum=0
for i in range(1,n+1):
thesum=thesum+i
end=time.time()
return thesum,end-start
#回圈5次
for i in range(5):
print("Sum is %d required %10.7f seconds" % sumOfN2(10000))
結果如下:
- 第二種方法:公式方法
#直接利用求和公式
def sumOfN3(n):
start=time.time()
thesum=(1+n)*n/2
end=time.time()
return thesum,end-start
for i in range(5):
print("Sum is %d required %10.7f seconds" % sumOfN3(10000))
結果如下:
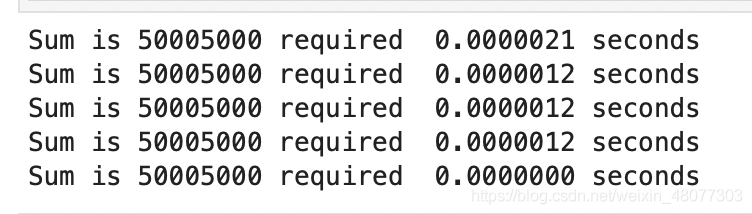
直覺上,回圈方案看上去作業量更大,因為有些步驟重復,這好像是耗時更久的原因,而且,回圈方案的耗時會隨著 n 一起增長,然而,這里有個問題,如果在另一臺計算機上運行這個函式,或用另一種編程語言來實作,很可能會得到不同的結果,如果計算機再舊些,sumOfN3 的執行時間甚至更長,
我們需要更好的方式來描述演算法的執行時間,基準測驗計算的是執行演算法的實際時間, 這不是一個有用的指標,因為它依賴于特定的計算機、程式、時間、編譯器與編程語言,我們希 望找到一個獨立于程式或計算機的指標,這樣的指標在評價演算法方面會更有用,可以用來比較不同實作下的演算法,
2. 大O記法
試圖擺脫程式或計算機的影響而描述演算法的效率時,量化演算法的操作或步驟很重要,如果將每一步看成基本計算單位,那么可以將演算法的執行時間描述成解決問題所需的步驟數,確定合適的基本計算單位很復雜,也依賴于演算法的實作,
對于累加演算法,計算總和所用的賦值陳述句的數目就是一個很好的基本計算單位,在 sumOfN 函式中,賦值陳述句數是1(thesum=0)加上n(thesum=thesum+i),可以將其定義為函式
T
T
T,令
T
(
n
)
=
1
+
n
T(n)=1+n
T(n)=1+n,引數n常被常稱為問題規模,,可以將函式解讀為“當問題規模為 n 時,解決問題所需的時間為
T
(
n
)
T(n)
T(n),即需要1+n步,
隨著計算機科學家的深入研究,他們發現,精確的步驟數中并沒有
T
(
n
)
T(n)
T(n)函式中起決定作用的部分重要,例如:
T
(
n
)
=
5
n
3
+
3
n
2
+
1
T(n)=5n^3+3n^2+1
T(n)=5n3+3n2+1,隨著問題規模的增長,
5
n
3
5n^3
5n3才是最重要的部分,于是就誕生了數量級也叫做大O記法,記作
O
(
f
(
x
)
)
O(f(x))
O(f(x)),他提供了步驟數的一個有用的近似方法,假設某演算法的步驟數是
T
(
n
)
=
5
n
3
+
3
n
2
+
1
T(n)=5n^3+3n^2+1
T(n)=5n3+3n2+1,則它的數量級是
O
(
n
3
)
O(n^3)
O(n3).
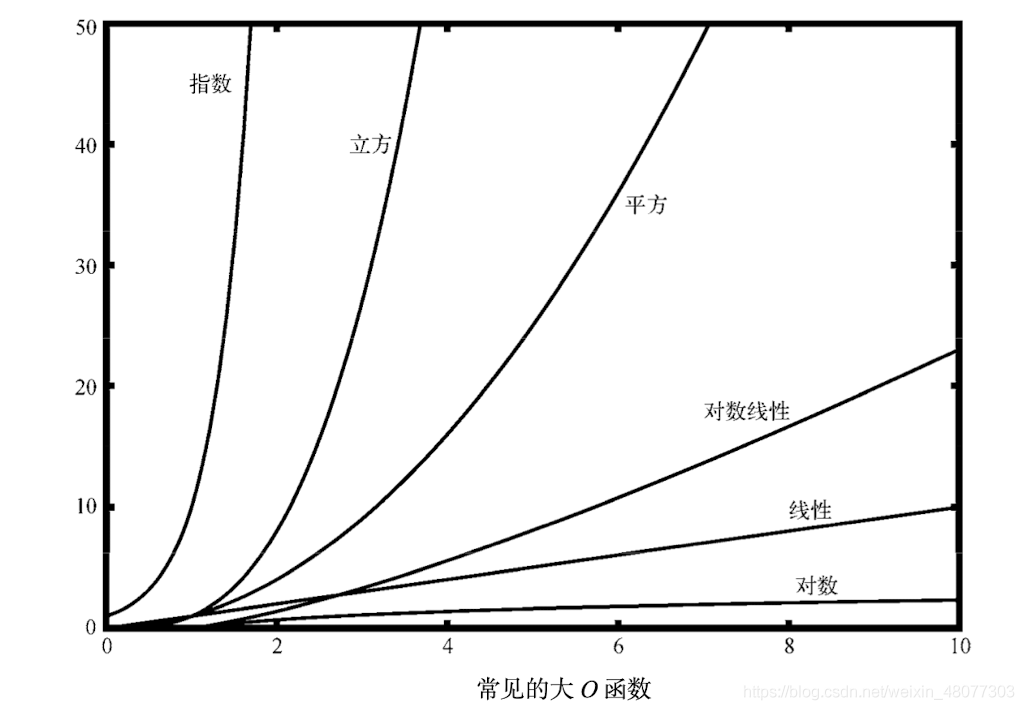
這里為了讓大家知道一些函式的增長速度,我決定將一些函式的列舉出來,

例:計算如下程式的步驟數,和數量級大O
a = 5
b = 6
c = 10
for i in range(n):
for j in range(n):
x = i * i
y = j * j
z = i * j
for k in range(n):
w = a * k + 45
v = b * b
d = 33
這段程式的賦值次數為 T ( n ) = 3 + 3 n 2 + 2 n + 1 T(n)=3+3n^2+2n+1 T(n)=3+3n2+2n+1,大O記法為 O ( n 2 ) O(n^2) O(n2),大家可以自己算一下,
3. 不同演算法的大O記法
這里我們采用不同的演算法實作一個經典的異序詞檢測問,所謂異序詞,就是組成單詞的字母一樣,只是順序不同,例如heart和earth,python和typhon,為了簡化問題,我們假設要檢驗的兩個單詞字串的長度已經一樣長,
3.1 清點法
該方法主要是清點第 1 個字串的每個字符,看看它們是否都出現在第 2 個字串中,如果是,那么兩個字串必然是異序詞,清點是通過用 Python 中的特殊值 None 取代字符來實作的,但是,因為 Python 中的字串是不可修改的,所以先要將第 2 個字串轉換成串列,在字串列中檢查第 1 個字串中的每個字符,如果找到了,就替換掉,
def anagramSolution1(s1, s2):
alist = list(s2)
pos1=0
stillOK = True
while pos1 < len(s1) and stillOK:
pos2 = 0
found = False
while pos2 < len(alist) and not found:
if s1[pos1] == alist[pos2]:
found = True
else:
pos2 = pos2 + 1
if found:
alist[pos2] = None
else:
stillOK = False
pos1 = pos1 + 1
return stillOK
來分析這個演算法,注意,對于 s1 中的 n 個字符,檢查每一個時都要遍歷 s2 中的 n 個字符, 要匹配 s1 中的一個字符,串列中的 n 個位置都要被訪問一次,因此,訪問次數就成了從 1 到 n 的整數之和,這可以用以下公式來表示,
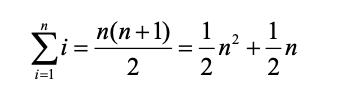
因此,該方法的時間復雜度是
O
(
n
2
)
O(n^2)
O(n2)
3.2 排序法
盡管 s1 與 s2 是不同的字串,但只要由相同的字符構成,它們就是異序詞,基于這一點, 可以采用另一個方案,如果按照字母表順序給字符排序,異序詞得到的結果將是同一個字串,
def anagramSolution2(s1, s2):
alist1 = list(s1)
alist2 = list(s2)
alist1.sort()
alist2.sort()
pos=0
matches = True
while pos < len(s1) and matches:
if alist1[pos] == alist2[pos]:
pos = pos + 1
else:
matches = False
return matches
乍看之下,你可能會認為這個演算法的時間復雜度是 O ( n ) O(n) O(n),因為在排序之后只需要遍歷一次就可以比較 n 個字符,但是,呼叫兩次 sort 方法不是沒有代價,我們在后面會看到,排序的時 間復雜度基本上是 O ( n 2 ) O(n2 ) O(n2)或 O ( n l o g n ) O(nlogn) O(nlogn) ,所以排序操作起主導作用,也就是說,該演算法和排序程序的數量級相同,
3.3 蠻力法
用蠻力解決問題的方法基本上就是窮盡所有的可能,就異序詞檢測問題而言,可以用 s1 中 的字符生成所有可能的字串,看看 s2 是否在其中,但這個方法有個難處,用 s1 中的字符生 成所有可能的字串時,第 1 個字符有 n 種可能,第 2 個字符有 n-1 種可能,第 3 個字符有 n-2 種可能,依此類推,字串的總數是
n
?
(
n
?
1
)
?
(
n
?
2
)
?
.
.
.
.
.
.
?
3
?
2
?
1
n*(n-1)*(n-2)*......*3*2*1
n?(n?1)?(n?2)?......?3?2?1,即為
n
!
n!
n!也許有些字串會重復,但程式無法預見,所以肯定會生成
n
!
n!
n!個字串,
當 n 較大時, n! 增長得比2n還要快,實際上,如果 s1 有20個字符,那么字串的個數就 是 20!= 2432902008176640000 ,假設每秒處理一個,處理完整個串列要花 77146816596 年, 這可不是個好方案,
3.4 計數法
最后一個方案基于這樣一個事實:兩個異序詞有同樣數目的 a、同樣數目的 b、同樣數目的 c,等等,要判斷兩個字串是否為異序詞,先數一下每個字符出現的次數,因為字符可能有 26 種,所以使用 26 個計數器,對應每個字符,每遇到一個字符,就將對應的計數器加 1,最后, 如果兩個計數器串列相同,那么兩個字串肯定是異序詞,
def anagramSolution4(s1, s2):
c1=[0]*26
c2=[0]*26
for i in range(len(s1)):
pos = ord(s1[i]) - ord('a')
c1[pos] = c1[pos] + 1
for i in range(len(s2)):
pos = ord(s2[i]) - ord('a')
c2[pos] = c2[pos] + 1
j=0
stillOK = True
while j < 26 and stillOK:
if c1[j] == c2[j]:
j=j+1
else:
stillOK = False
return stillOK
這個方案也有回圈,但不同于方案 1,這個方案的回圈沒有嵌套,前兩個計數回圈都是 n 階 的,第 3 個回圈比較兩個串列,由于可能有 26 種字符,因此會回圈 26 次,全部加起來,得到總步驟數 T (n) =2n - 26 ,即 O(n) ,我們找到了解決異序詞檢測問題的線性階演算法,
4. 串列和字典操作的復雜度
4.1 串列
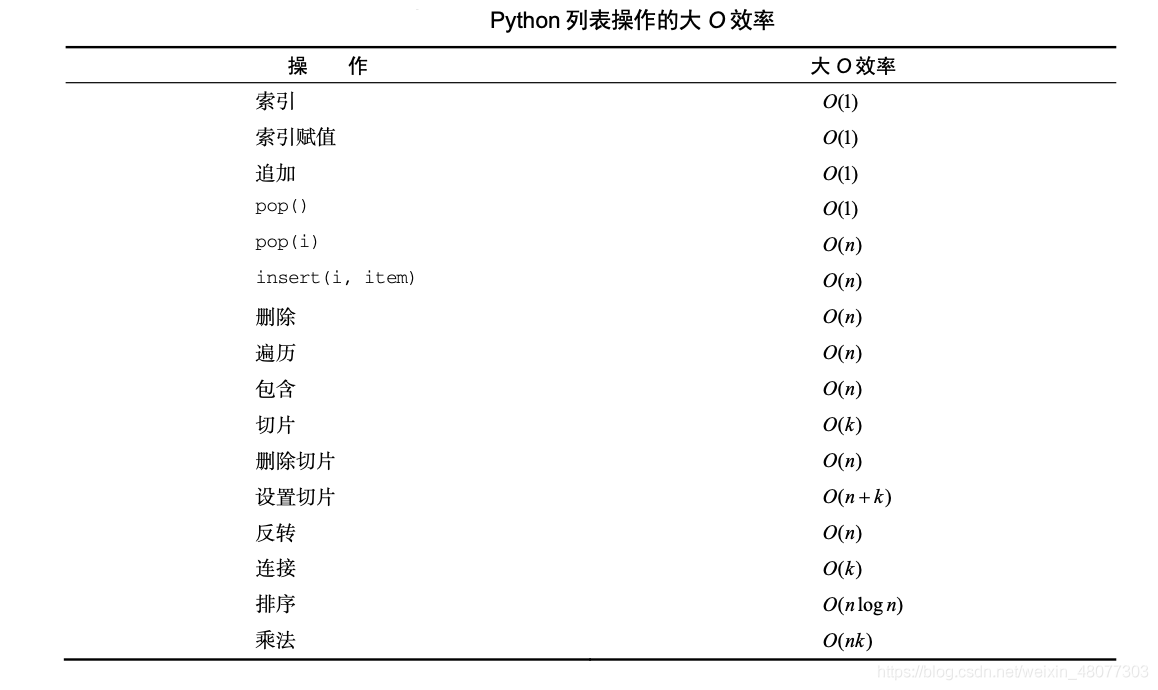
4.2 字典

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291865.html
標籤:python