前言:字體反爬,也是一種常見的反爬技術,例如58同城,貓眼電影票房,汽車之家,天眼查,實習僧等網站,這些網站采用了自定義的字體檔案,在瀏覽器上正常顯示,但是爬蟲抓取下來的資料要么就是亂碼,要么就是變成其他字符,是因為他們采用自定義字體檔案,通過在線加載來參考樣式,這是CSS3的新特性,通過 CSS3,web 設計師可以使用他們喜歡的任意字體 ,然后因為爬蟲不會主動加載在線的字體,

字體加密一般是網頁修改了默認的字符編碼集,在網頁上加載他們自己定義的字體檔案作為字體的樣式,可以正確地顯示數字,但是在原始碼上同樣的二進制數由于未加載自定義的字體檔案就由計算機默認編碼成了亂碼,
目標
目標:我們今天來學習爬取58同城的租房資訊,獲取房源資訊,
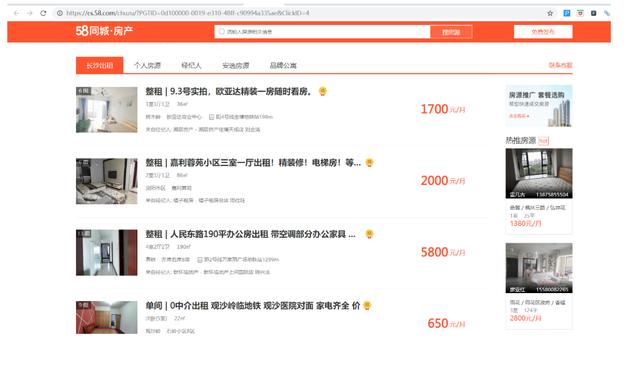
資料爬取
我們先按照前面學的爬蟲基本知識,拿起鍵盤直接開干(無經驗不知道字體反爬是啥玩意),一直在用xpath進行決議,都忘記了BeautifulSoup提取了,這里來用這個提取,回顧回顧,
import requestsfrom bs4 import BeautifulSoupurl = 'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'}
response = requests.get(url,headers=headers)html_text = response.textbs = BeautifulSoup(html_text, 'lxml')
# 獲取房源串列資訊,通過css選擇器來
lis = bs.select('li.house-cell')
# 獲取每個li下的資訊for li in lis:
title = li.select('h2 a')[0].stripped_strings
# stripped_strings獲取某個標簽下的子孫非標簽字串,會去掉空白字符,回傳來的是個生成器
room = li.select('div.des p')[0].stripped_strings
money = li.select('.money b')[0].string
# 獲取某個標簽下的非標簽字串,回傳來的是個字串,
print(list(title)[0], list(room)[0], money)
輸出的結果:

顯示亂碼,在頁面上看也是亂碼
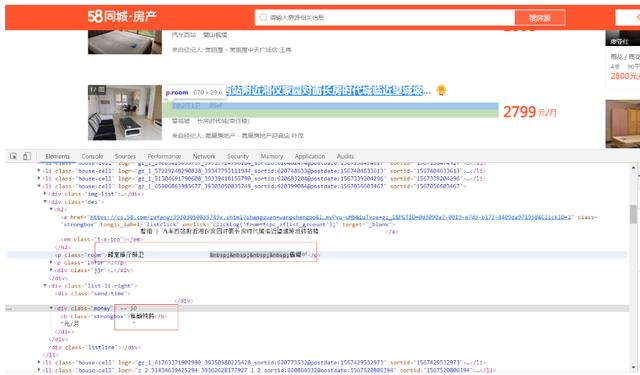
我們右擊選擇查看網頁源代碼
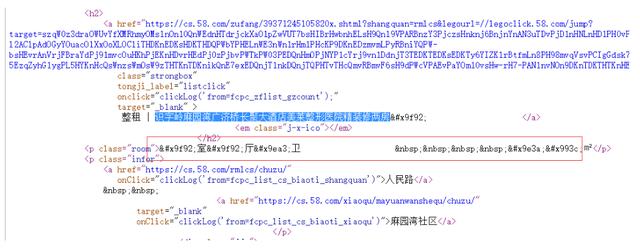
看起來是unicode 編碼導致的,這種就是對字體進行了加密了,通用解決辦法是找到字體檔案,分析檔案中的映射關系,一般來說,字體檔案都是作為樣式加在加密字體的部位,所以我們在html頭部里面找相關樣式,找了頭部資訊字體樣式font-face,CSS中的@font-face,它允許網頁開發者為其網頁指定在線字體,
我們ctrl+f搜索@font-face
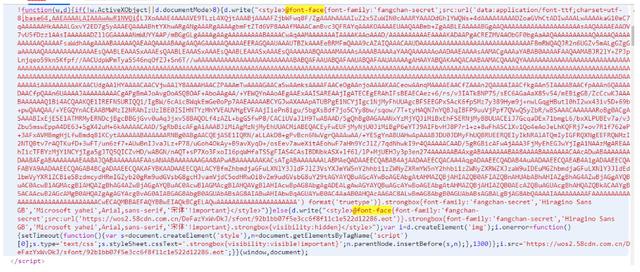
發現58同城的頁面中的字體檔案是經過base64加密之后放在js里面的,一大串字串,從base64后面開始一直到后面format前面的括號中的內容,應該是字體檔案的內容,是經過了base64編碼后的形式,我們把其中加密的部分取出,通過正則運算式將其中的內容取出來,然后用base64解碼后再保存成本地ttf檔案(ttf是字體的一種型別),
關于字體
fontTools操作相關
這里我們使用到一個模塊fontTools,它是用來操作字體的庫,用于將woff或ttf這種字體檔案轉化成XML檔案,
1.我們可以直接使用pip進行安裝:
pip install fontTools
2.加載字體檔案:
font = TTFont('58.woff')
3.轉為xml檔案:
font.saveXML('58.xml')
4.各節點名稱:
font.keys()
5.按序獲取GlyphOrder節點name值:
font.getGlyphOrder() 或 font['cmap'].tables[0].ttFont.getGlyphOrder()
6.獲取cmap節點code與name值映射:
font.getBestCmap()
7.獲取字體坐標資訊:
font['glyf'][i].coordinates
8.獲取坐標的0或1:
font['glyf'][i].flags **注:** 0表示弧形區域 1表示矩形
字體基礎與XML
一個字體由數個表(ta-ble)構成,字體的資訊儲存在表中,1、一個最基本的字體檔案一定會包含以下的表:
- cmap: Char-ac-ter to glyph map-ping unicode跟 Name的映射關系
- head: Font header 字體全域資訊
- hhea: Hor-i-zon-tal header 定義了水平header
- hmtx: Hor-i-zon-tal met-rics 定義了水平metric
- maxp: Max-i-mum pro-file 用于為字體分配記憶體
- name: Nam-ing ta-ble 定義字體名稱、風格名以及著作權說明等
- glyf: 字形資料即輪廓定義和調整指令
- OS2: OS2 and Win-dows spe-cific met-rics
- post: Post-Script in-for-ma-tion
我們將字體解密并保存到本地看看:
import requestsfrom fontTools.ttLib import TTFontimport reimport base64url =
'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'headers =
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/74.0.3729.108 Safari/537.36'}
response = requests.get(url,headers=headers)html_text = response.text
# print(html_text)pattern = r"base64,(.*?)'"
# 提取加密資訊result = re.findall(pattern, html_text)
# 回傳串列if result:
# 避免有的頁面沒有使用加密
print(type(result), len(result))
base64str = result[0]
fontfile_content = base64.b64decode(base64str)
# 通過base64編碼的資料進行解碼,輸出二進制
with open('58.ttf', 'wb') as f:
# 生成字體檔案
f.write(fontfile_content)
font = TTFont('58.ttf') # 加載字體檔案
font.saveXML('58.xml') # 轉換成xml檔案else:
print('沒有內容')
base64str = ""
生成的字體庫檔案58.ttf,

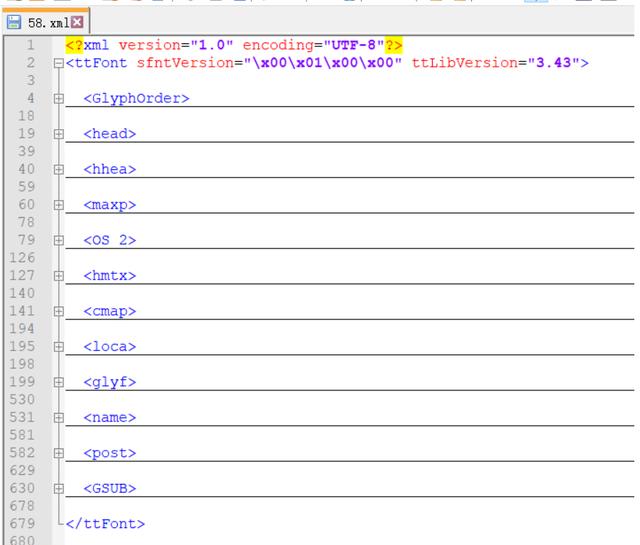
生成的xml檔案:
分析xml檔案
我們來分析xml檔案中映射關系,
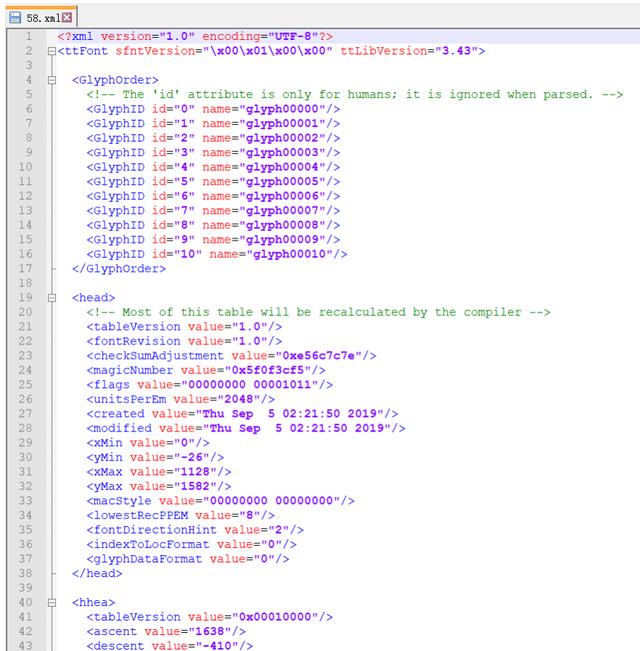
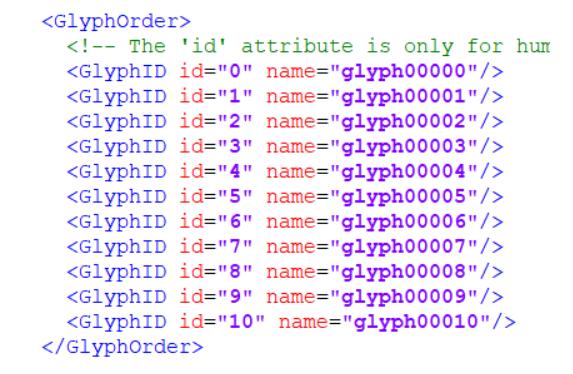
點開GlyphOrder標簽,可以看到Id和name,這里id僅表示序號而已,而不是對應具體的數字:
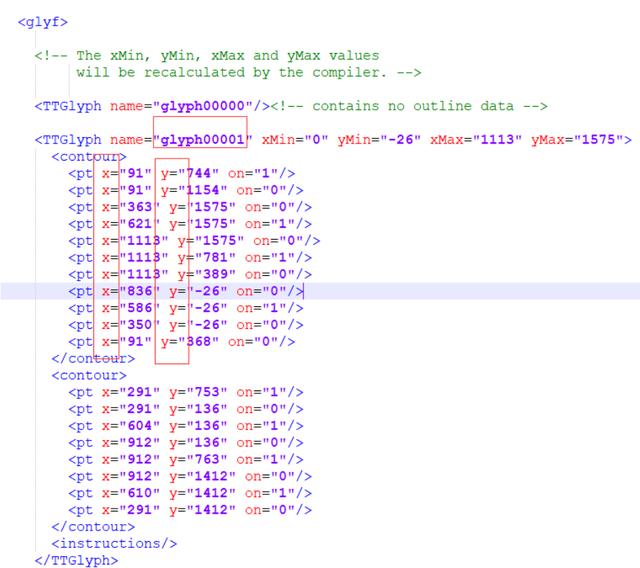
點開glyf標簽,看到的是name和一些坐標點,這些座標點就是描繪字體形狀的,這里不需要關注這些坐標點,
點開cmap標簽,是編碼和name的對應關系:
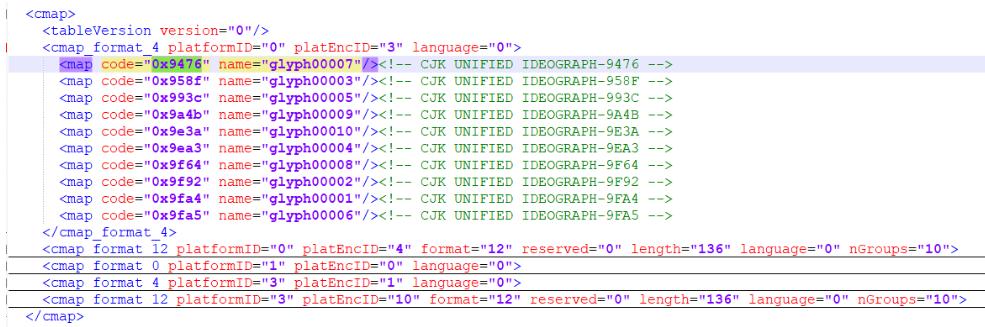
這里將字體檔案匯入到 http://fontstore.baidu.com/static/editor/index.html 網頁將其打開,顯示如下:

網頁原始碼中顯示的 鑶 跟這里顯示的是不是有點像?事實上確實如此,去掉開頭的 &#x 和結尾的 ; 后,剩余的4個16進制顯示的數字加上 uni 就是字體檔案中的編碼,所以鑶對應的就是數字“6”,按照此就對應到glyph00007從這2張圖我們可以發現,glyph00001對應的是數字0,glyph00002對應的是數字1,以此類推……glyph00010對應的是數字9,
用代碼來獲取編碼和name的對應關系:
from fontTools.ttLib import TTFontfont = TTFont('58.ttf')
# 打開本地的ttf檔案font.saveXML('58.xml')
# 轉換為xml檔案bestcmap = font['cmap'].getBestCmap()
# 獲取cmap節點code與name值映射print(bestcmap)
輸出:
{38006: 'glyph00010', 38287: 'glyph00006', 39228: 'glyph00007', 39499: 'glyph00005', 40506: 'glyph00009', 40611: 'glyph00002', 40804: 'glyph00008', 40850: 'glyph00003', 40868: 'glyph00001', 40869: 'glyph00004'}
輸出的是一個字典,key是編碼的int型,我們要將其轉換為我們在xml看到的16進制一樣以及與具體的數字映射關系:
for key,value in bestcmap.items(): key = hex(key) # 10進制轉16進制 value = int(re.search(r'(\d+)', value).group()) -1 # 通過上面分析得出glyph00001對應的是數字0依次類推, print(key,value)
輸出結果:
0x9476 60x958f 50x993c 40x9a4b 30x9e3a 70x9ea3 20x9f64 90x9f92 10x9fa4 00x9fa5 8
現在就可以把頁面上的自定義字體替換成正常字體,再決議了,全部代碼如下:
import requestsfrom bs4 import BeautifulSoupfrom fontTools.
ttLib import TTFontimport reimport base64import iodef base46_str(html_text):
pattern = r"base64,(.*?)'"
# 提取加密部分
result = re.findall(pattern, html_text)
# 回傳串列
if result:
# 避免有的頁面沒有使用加密
# print(type(result), len(result))
base64str = result[0]
bin_data = base64.b64decode(base64str)
# 通過base64編碼的資料進行解碼,輸出二進制
# # print(fontfile_content)
# with open('58.ttf', 'wb') as f:
# f.write(bin_data)
# font = TTFont('58.ttf')
# 打開本地的ttf檔案
# font.saveXML('58.xml')
# bestcmap = font['cmap'].getBestCmap()
# print(bestcmap)
fonts = TTFont(io.BytesIO(bin_data))
# BytesIO實作了在記憶體中讀寫bytes,提高性能
bestcmap = fonts['cmap'].getBestCmap()
# print(bestcmap) # 字典
# for key,value in bestcmap.items():
# key = hex(key) # 10進制轉16進制
# value = int(re.search(r'(\d+)', value).group()) -1
# print(key,value)
# 使用字典推導式
cmap = {hex(key).replace('0x', '&#x') + ';'
: int(re.search(r'(\d+)', value).group(1)) - 1 for key, value in bestcmap.items()}
# print(cmap)
for k,v in cmap.items():
html_text = html_text.replace(k, str(v))
return html_text
else:
print('沒有內容')
base64str = ""
return html_textdef parse_html(html_text):
bs = BeautifulSoup(html_text, 'lxml')
# 獲取房源串列資訊,通過css選擇器來
lis = bs.select('li.house-cell')
# 獲取每個li下的資訊
for li in lis:
href = li.select('h2 a')[0]['href']
title = li.select('h2 a')[0].stripped_strings
# stripped_strings獲取某個標簽下的子孫非標簽字串,會去掉空白字符,回傳來的是個生成器
room = li.select('div.des p')[0].stripped_strings
money = li.select('.money')[0].get_text().replace('\n','')
# 獲取某個標簽下的非標簽字串,回傳來的是個字串,
print(href, list(title)[0], list(room)[0], money)
if __name__ == '__main__': url = 'https://cs.58.com/chuzu/?PGTID=0d100000-0019-e310-48ff-c90994a335ae&ClickID=4'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36' }
response = requests.get(url, headers=headers)
html_text = response.text
html_text = base46_str(html_text)
parse_html(html_text)
輸出結果:
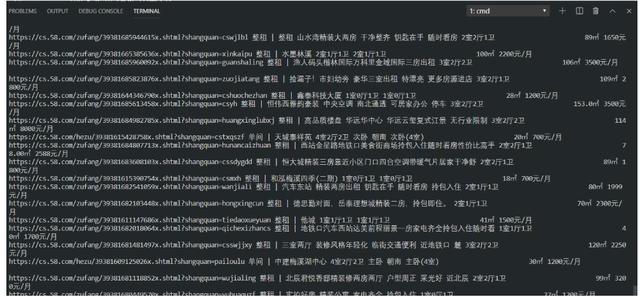
至此,58同城字體相關差不多了,
拓展
上面只是簡單的字體反爬,像汽車之家,貓眼電影,我們可以去挑戰一下,
最后,小編想說:我是一名python開發工程師,
整理了一套最新的python系統學習教程,
想要這些資料的可以關注私信小編“01”即可(免費分享哦)希望能對你有所幫助.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291867.html
標籤:python
上一篇:python實作子檔案夾中檔案數目批量識別并匯出條件子檔案夾名單為Excel
下一篇:anaconda里面的spyder打不開:qtpy.PythonQtError: No Qt bindings could be found[已解決]