該系列文章是講解Python OpenCV影像處理知識,前期主要講解影像入門、OpenCV基礎用法,中期講解影像處理的各種演算法,包括影像銳化算子、影像增強技術、影像分割等,后期結合深度學習研究影像識別、影像分類應用,希望文章對您有所幫助,如果有不足之處,還請海涵~
上一篇文章是影像處理的最后一篇文章,寫到這里,第一階段的44篇Python影像處理就介紹完畢,接下來我們進入Python影像識別第二階段,該部分主要以目標檢測、影像識別以及深度學習相關影像分類為主,將會分享近50篇文章,感謝您一如至往的支持,作者也會繼續加油的!
本文主要介紹目標檢測原理,通過七個問題來普及什么是目標檢測,然后利用ImageAI實作最簡單的目標檢測案例,加深讀者的印象,希望您喜歡,且看且珍惜,
文章目錄
- 一.目標檢測入門普及
- 1.什么是目標檢測?
- 2.目標檢測的核心問題是什么?
- 3.目標檢測演算法常用分類
- 4.目標檢測常見演算法
- 5.目標檢測應用
- 6.目標檢測未來挑戰
- 7.目標檢測原理簡述
- 二.ImageAI簡介
- 三.安裝流程
- 四.TinyYOLOv3模型物件檢測案例
- 1.案例實作
- 2.學習建議
- 五.總結
萬字長文整理,希望對您有所幫助,同時,該部分知識均為作者查閱資料撰寫總結,并且開設成了收費專欄,為小寶賺點奶粉錢,感謝您的抬愛,如果有問題隨時私聊我,只望您能從這個系列中學到知識,一起加油,代碼下載地址(如果喜歡記得star,一定喔):
- https://github.com/eastmountyxz/ImageProcessing-Python
影像識別:
- [Python影像識別] 四十五.物件檢測案例入門及ImageAI基礎用法 (1)
影像處理:
- [Python影像處理] 一.影像處理基礎知識及OpenCV入門函式
- [Python影像處理] 二.OpenCV+Numpy庫讀取與修改像素
- [Python影像處理] 三.獲取影像屬性、興趣ROI區域及通道處理
- [Python影像處理] 四.影像平滑之均值濾波、方框濾波、高斯濾波及中值濾波
- [Python影像處理] 五.影像融合、加法運算及影像型別轉換
- [Python影像處理] 六.影像縮放、影像旋轉、影像翻轉與影像平移
- [Python影像處理] 七.影像閾值化處理及演算法對比
- [Python影像處理] 八.影像腐蝕與影像膨脹
- [Python影像處理] 九.形態學之影像開運算、閉運算、梯度運算
- [Python影像處理] 十.形態學之影像頂帽運算和黑帽運算
- [Python影像處理] 十一.灰度直方圖概念及OpenCV繪制直方圖
- [Python影像處理] 十二.影像幾何變換之影像仿射變換、影像透視變換和影像校正
- [Python影像處理] 十三.基于灰度三維圖的影像頂帽運算和黑帽運算
- [Python影像處理] 十四.基于OpenCV和像素處理的影像灰度化處理
- [Python影像處理] 十五.影像的灰度線性變換
- [Python影像處理] 十六.影像的灰度非線性變換之對數變換、伽馬變換
- [Python影像處理] 十七.影像銳化與邊緣檢測之Roberts算子、Prewitt算子、Sobel算子和Laplacian算子
- [Python影像處理] 十八.影像銳化與邊緣檢測之Scharr算子、Canny算子和LOG算子
- [Python影像處理] 十九.影像分割之基于K-Means聚類的區域分割
- [Python影像處理] 二十.影像量化處理和采樣處理及區域馬賽克特效
- [Python影像處理] 二十一.影像金字塔之影像向下取樣和向上取樣
- [Python影像處理] 二十二.Python影像傅里葉變換原理及實作
- [Python影像處理] 二十三.傅里葉變換之高通濾波和低通濾波
- [Python影像處理] 二十四.影像特效處理之毛玻璃、浮雕和油漆特效
- [Python影像處理] 二十五.影像特效處理之素描、懷舊、光照、流年以及濾鏡特效
- [Python影像處理] 二十六.影像分類原理及基于KNN、樸素貝葉斯演算法的影像分類案例
- [Python影像處理] 二十七.OpenGL入門及繪制基本圖形(一)
- [Python影像處理] 二十八.OpenCV快速實作人臉檢測及視頻中的人臉
- [Python影像處理] 二十九.MoviePy視頻編輯庫實作抖音短視頻剪切合并操作
- [Python影像處理] 三十.影像量化及采樣處理萬字詳細總結(推薦)
- [Python影像處理] 三十一.影像點運算處理兩萬字詳細總結(灰度化處理、閾值化處理)
- [Python影像處理] 三十二.傅里葉變換(影像去噪)與霍夫變換(特征識別)萬字詳細總結
- [Python影像處理] 三十三.影像各種特效處理及原理萬字詳解(毛玻璃、浮雕、素描、懷舊、流年、濾鏡等)
- [Python影像處理] 三十四.數字影像處理基礎與幾何圖形繪制萬字詳解(推薦)
- [Python影像處理] 三十五.OpenCV影像處理入門、算數邏輯運算與影像融合(推薦)
- [Python影像處理] 三十六.OpenCV影像幾何變換萬字詳解(平移縮放旋轉、鏡像仿射透視)
- [Python影像處理] 三十七.OpenCV和Matplotlib繪制直方圖萬字詳解(掩膜直方圖、H-S直方圖、黑夜白天判斷)
- [Python影像處理] 三十八.OpenCV影像增強萬字詳解(直方圖均衡化、區域直方圖均衡化、自動色彩均衡化)
- [Python影像處理] 三十九.Python影像分類萬字詳解(貝葉斯影像分類、KNN影像分類、DNN影像分類)
- [Python影像處理] 四十.全網首發Python影像分割萬字詳解(閾值分割、邊緣分割、紋理分割、分水嶺演算法、K-Means分割、漫水填充分割、區域定位)
- [Python影像處理] 四十一.Python影像平滑萬字詳解(均值濾波、方框濾波、高斯濾波、中值濾波、雙邊濾波)
- [Python影像處理] 四十二.Python影像銳化及邊緣檢測萬字詳解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG)
- [Python影像處理] 四十三.Python影像形態學處理萬字詳解(腐蝕膨脹、開閉運算、梯度頂帽黑帽運算)
- 萬字長文告訴新手如何學習Python影像處理(上篇完結 四十四)
一.目標檢測入門普及
該部分結合自己多年影像識別的經驗,并參考影像演算法AI(yegeli)、Zhengxia Zou、牛戈和SIGAI老師們的文章進行總結,主要通過七個核心問題帶領初學者了解什么是目標檢測,
1.什么是目標檢測?
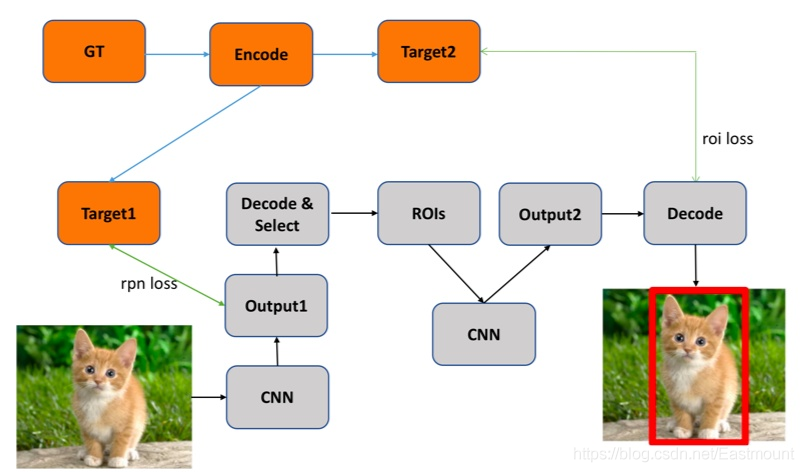
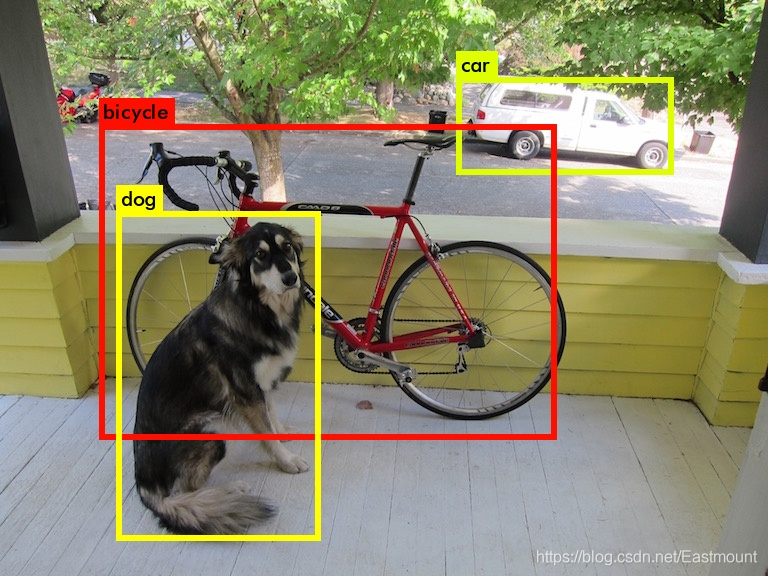
目標檢測(Object Detection)旨在尋找出影像中所有感興趣的目標物體或物件,包含物體定位和物體分類兩個子任務,同時確定它們的類別和位置,如下圖所示,通過卷積神經網路有效定位貓的輪廓及類別,
目標檢測是計算機視覺領域中最基本、最具挑戰性的問題之一,近年來受到了廣泛的關注,它在過去二十年的發展可以說是計算機視覺歷史的縮影,由于各類物體有不同的外觀、形狀和姿態,加上成像時光照、遮擋、天氣、解析度、景深等因素的干擾,目標檢測一直是計算機視覺領域最具有挑戰性的問題,并且目標檢測的結果將直接影響后續的跟蹤、動作識別和行為描述的效果,因此,目標檢測發展到今天仍然是非常具有挑戰且存在很大提升空間的問題,
2.目標檢測的核心問題是什么?
在計算機視覺領域,影像識別主要包括四大類任務:
- 分類(Classification)
解決“是什么?”問題,即給定一張圖片或一段視頻判斷里面包含什么類別的目標, - 定位(Location)
解決“在哪里?”問題,即定位出這個目標的的位置, - 檢測(Detection)
解決“在哪里?是什么?”問題,即定位出這個目標的位置并且知道目標物是什么, - 分割(Segmentation)
包括實體分割(Instance-level)和場景分割(Scene-level),解決“每一個像素屬于哪個目標物或場景”的問題,
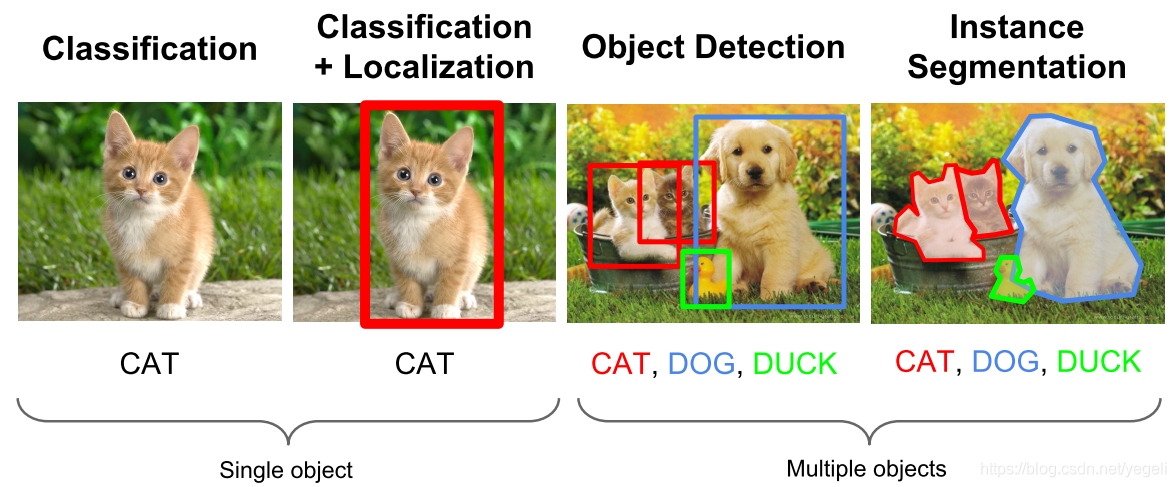
如上圖所示(參考yegeli老師,推薦大家關注),目標檢測主要是實作分類問題和定位問題的疊加,其核心問題即:
- 分類問題:確定圖片(或某個區域)中的影像屬于哪個類別,
- 定位問題:目標可能出現在影像的任何位置,
同時,需要解決大小問題(目標存在各種不同的大小)和形狀問題(目標可能有各種不同的形狀),
3.目標檢測演算法常用分類
每個領域的分類方法通常各式各樣,這里主要介紹兩種分類方法,
(1) 基于應用程式的角度分類
目標檢測作為計算機視覺的基本問題之一,是許多其他計算機視覺任務的基礎,如實體分割、影像字幕、物件跟蹤等,從應用程式的角度來看,目標檢測可以被分為兩個研究主題:
-
general object detection
旨在探索統一框架下檢測不同型別物體的方法,以模擬人類的視覺和認知, -
detection applications
指特定應用場景下的檢測,如行人檢測、人臉檢測、文本檢測等,
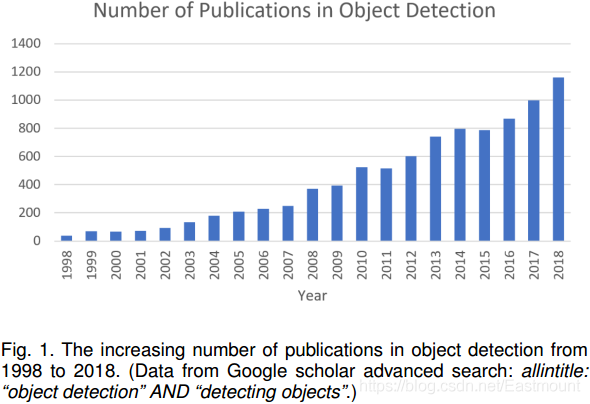
近年來,隨著深度學習技術的快速發展,為目標檢測注入了新的血液,取得了顯著的突破,將其推向了一個前所未有的研究熱點,目前,目標檢測已廣泛應用于自主駕駛、機器人視覺、視頻監控等領域,下圖顯示了過去二十年中與“目標檢測”相關的出版物數量的增長,
(2) 基于深度學習的目標檢測分類
基于深度學習的目標檢測演算法主要分為兩類:Two stage和One stage,
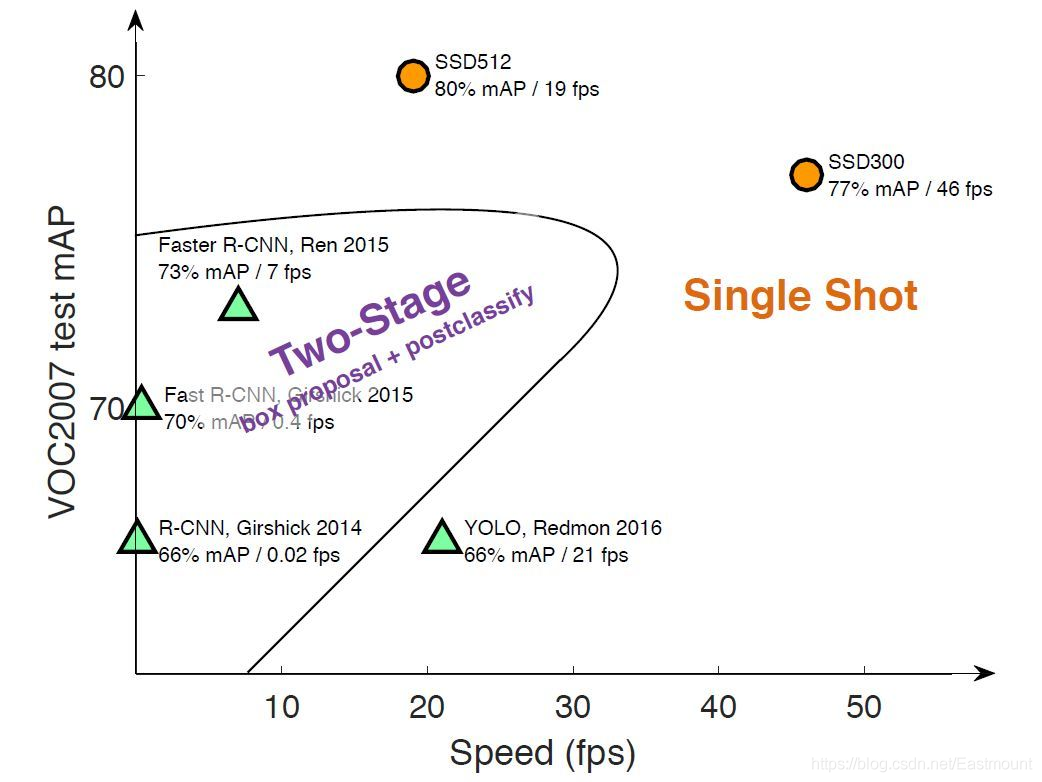
- Two stage
Two-stage Detection將檢測框定為一個“從粗到細”的程序,先進行區域生成,該區域稱之為Region Proposal(簡稱RP,一個有可能包含待檢物體的預選框),再通過卷積神經網路進行樣本分類,
任務流程:特征提取 => 生成RP => 分類/定位回歸,常見tow stage目標檢測演算法有:
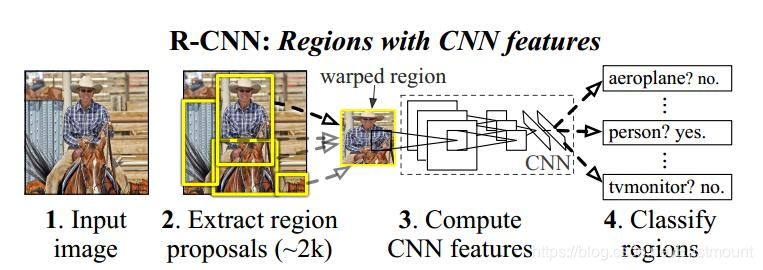
– R-CNN
– SPP-Net
– Fast R-CNN
– Faster R-CNN
– R-FCN
– …
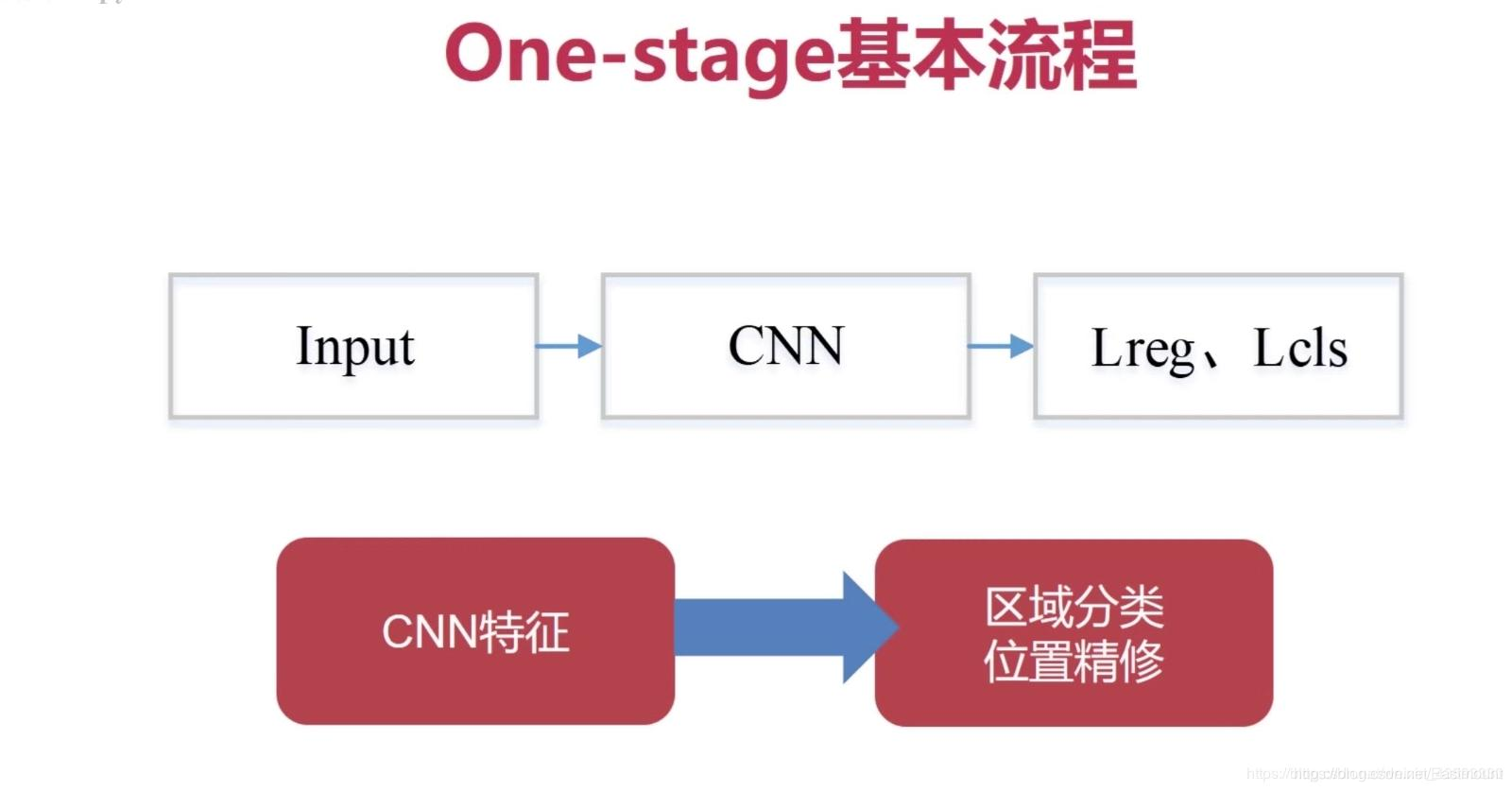
- One stage
One-stage Detection定義為 “ 一步完成 ”程序,不用RP,直接在網路中提取特征來預測物體分類和位置,
任務流程:特征提取 => 分類/定位回歸,常見one stage目標檢測演算法有:
– OverFeat
– YOLOv1
– YOLOv2
– YOLOv3
– SSD
– RetinaNet
– …
4.目標檢測常見演算法
在過去的二十年中,人們普遍認為,目標檢測的發展大致經歷了兩個歷史時期:“ 傳統的目標檢測時期 ” ( 2014年以前 ) 和 “ 基于深度學習的檢測時期 ” ( 2014年以后 ),其發展歷程如下圖所示,
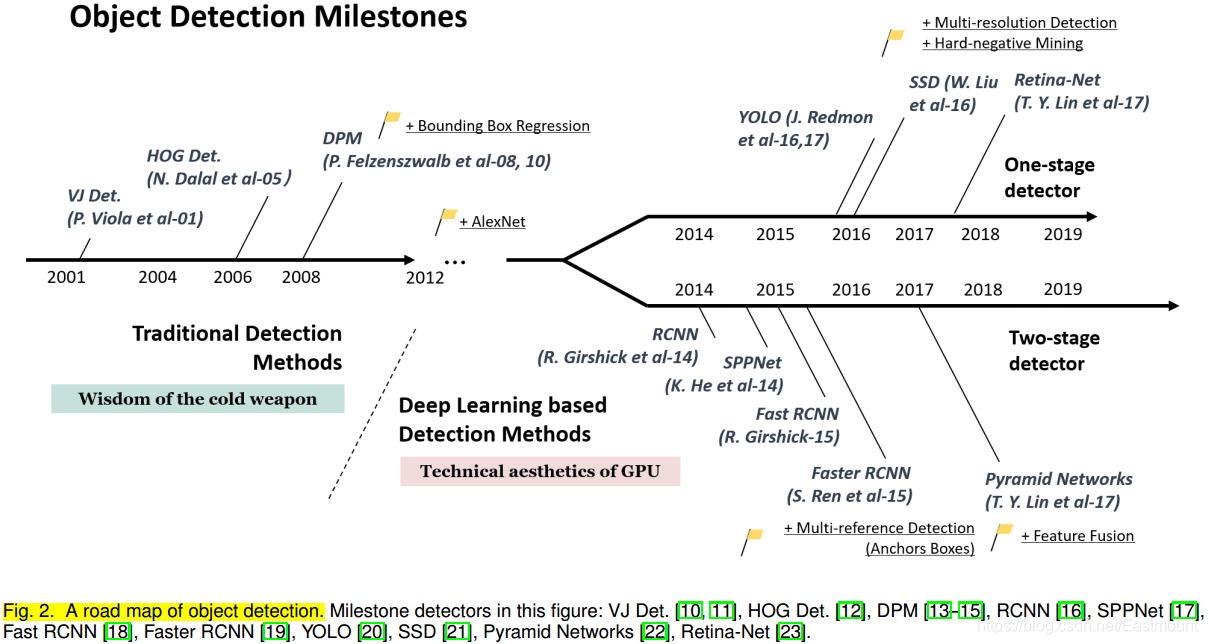
下面分別列舉了各里程碑式的目標檢測演算法,后續博客會分別進行詳細介紹及編程案例實作,
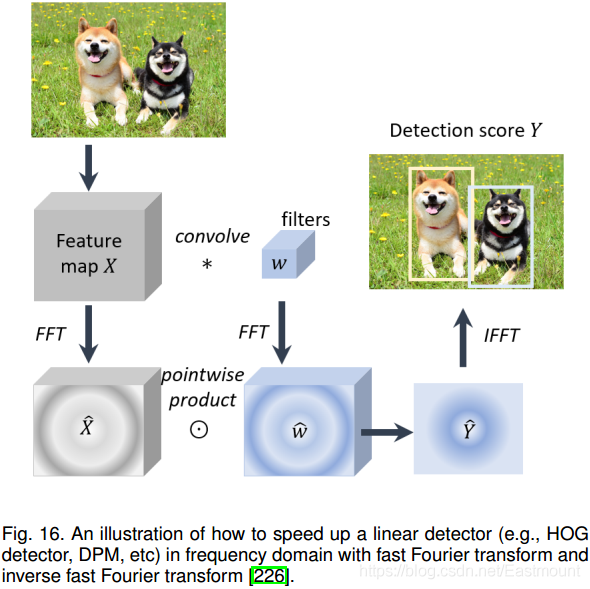
(1) 傳統檢測器(Traditional Detectors)
早期的目標檢測演算法大多是基于手工特征構建的,由于當時缺乏有效的影像表示,人們只能設計復雜的特征表示,以及各種加速技術來用盡有限的計算資源,
-
Viola Jones Detectors
2001年,P. Viola和M. Jones在沒有任何約束條件(如膚色分割)的情況下首次實作了人臉的實時檢測,VJ檢測器采用滑動視窗最直接的檢測方法,查看影像中所有可能的位置和比例,看看是否有視窗包含人臉,其檢測器結合了 “積分影像”、“特征選擇” 和 “檢測級聯” 三種重要技術,大大提高了檢測速度, -
HOG Detector
方向梯度直方圖(HOG)特征描述符最初是由N. Dalal和B.Triggs在2005年提出的,HOG可以被認為是對當時的尺度不變特征變換和形狀背景關系的重要改進,多年來,HOG檢測器一直是許多目標檢測器和各種計算機視覺應用的重要基礎, -
Deformable Part-based Model (基于可變形部件的模型,DPM)
DPM最初是由P. Felzenszwalb提出的,于2008年作為HOG檢測器的擴展,DPM遵循“分而治之”的檢測思想,訓練可以簡單地看作是學習一種正確的分解物件的方法,推理可以看作是對不同物件部件的檢測的集合,例如,檢測“汽車”的問題可以看作是檢測它的視窗、車身和車輪,
(2) CNN based Two-stage Detectors
隨著手工特征的性能趨于飽和,目標檢測在2010年之后達到了一個穩定的水平,2012年卷積神經網路在世界范圍內重生,由于深度卷積網路能夠學習影像的魯棒性和高層次特征表示,一個自然的問題是我們能否將其應用到目標檢測中?
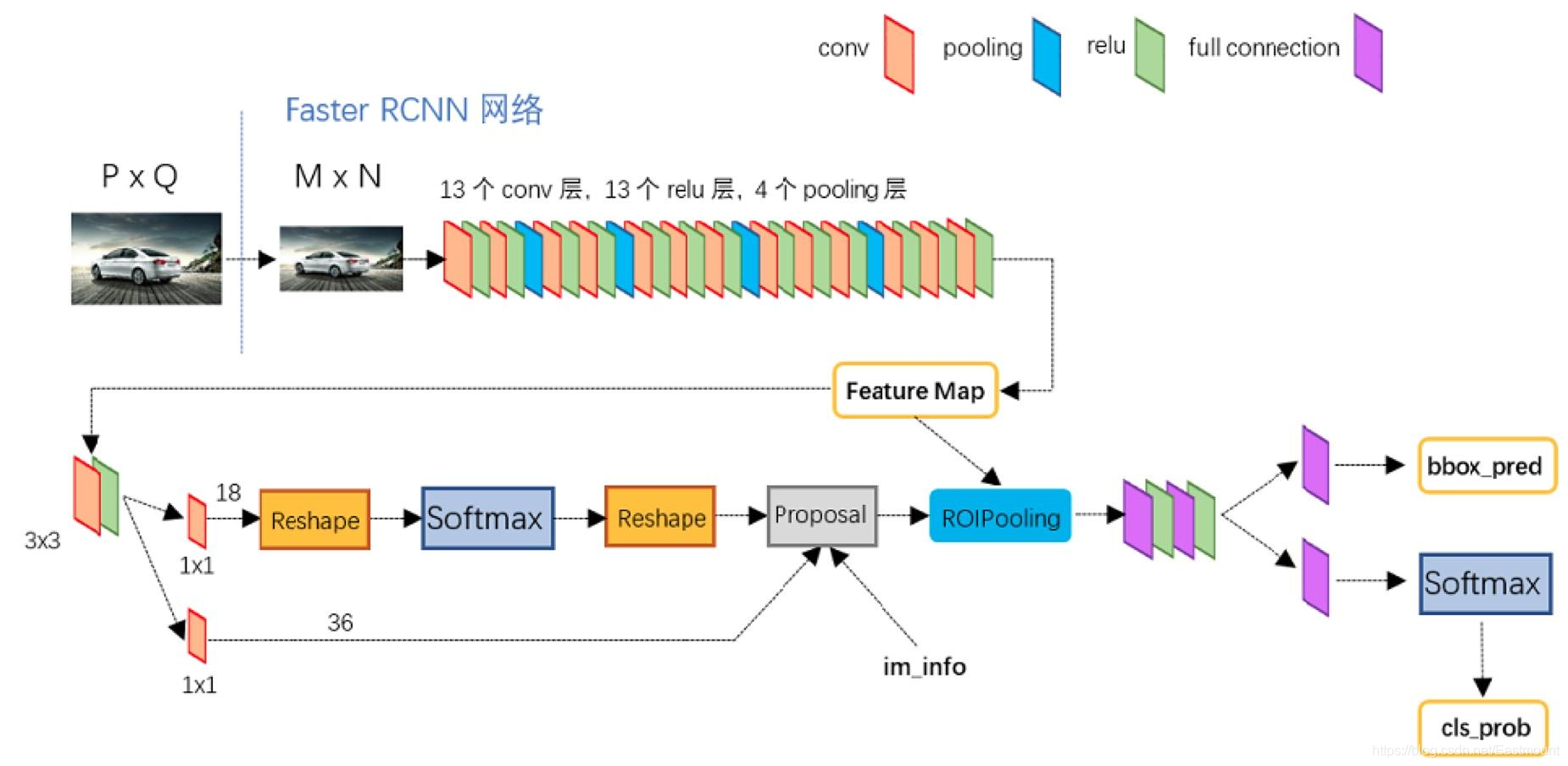
在2014年,R. Girshick等人率先打破僵局,提出了具有CNN特征的區域(RCNN)用于目標檢測,從那時起,目標檢測開始以前所未有的速度發展,在深度學習時代,目標檢測可以分為兩類,即 two-stage detection 和 one-stage detection,分別對應“從粗到細”的檢測程序和“一步完成”的檢測程序,
-
RCNN
RCNN首先通過選擇性搜索提取一組物件候選框,然后,每個提案都被重新調整成一個固定大小的影像,并輸入到一個在 ImageNet 上訓練得到的CNN模型 ( 如AlexNet) 來提取特征,最后,利用線性SVM分類器對每個區域內的目標進行預測,識別目標類別, -
SPPNet
2014年,K. He等人提出了空間金字塔池化網路 ( Spatial Pyramid Pooling Networks,SPPNet ) ,以前的CNN模型需要固定大小的輸入,例如,AlexNet需要224x224影像,SPPNet主要貢獻是引入了空間金字塔池化(SPP)層,它使CNN能夠生成固定長度的表示,而不需要重新縮放影像/感興趣區域的大小,利用SPPNet進行目標檢測時,只對整個影像進行一次特征映射計算,然后生成任意區域的定長表示,訓練檢測器,避免了卷積特征的重復計算, -
Fast RCNN
2015年,R. Girshick提出了 Fast RCNN 檢測器,這是對 R-CNN和SPPNet的進一步改進,Fast-RCNN融合了R-CNN和SPPNet的優點,使我們能夠在相同的網路配置下同時訓練檢測器和邊界框回歸器, -
Faster RCNN
2015年,S. Ren等人提出了 Faster RCNN 檢測器,在 Fast RCNN 之后不久,Faster RCNN是第一個端到端的,也是第一個接近實時的深度學習檢測器,Faster RCNN 主要貢獻是引入了區域建議網路 ( RPN ),使幾乎cost-free的區域建議成為可能,從RCNN到Faster RCNN,一個目標檢測系統中的大部分獨立塊,如提案檢測、特征提取、邊界框回歸等,都已經逐漸集成到一個統一的端到端學習框架中, -
Feature Pyramid Networks(FPN)
2017年,T.-Y.Lin等人基于 Faster RCNN 提出了特征金字塔網路 ( FPN ),在FPN之前,大多數基于深度學習的檢測器只在網路的頂層進行檢測,雖然CNN較深層的特征有利于分類識別,但不利于物件的定位,為此,開發了具有橫向連接的自頂向下體系結構,用于在所有級別構建高級語意,由于CNN通過它的正向傳播,自然形成了一個特征金字塔,FPN在檢測各種尺度的目標方面顯示出了巨大的進步,FPN現在已經成為許多最新探測器的基本組成部分,
(3) CNN based One-stage Detectors
-
You Only Look Once (YOLO)
YOLO由R. Joseph等人于2015年提出,它是深度學習時代的第一個單級檢測器,YOLO是“You Only Look Once”的縮寫,其速度較快,從它的名字可以看出,作者完全拋棄了之前的“提案檢測+驗證”的檢測范式,相反,它遵循一個完全不同的哲學:將單個神經網路應用于整個影像,該網路將影像分割成多個區域,同時預測每個區域的邊界框和概率,后來R. Joseph在 YOLO 的基礎上進行了一系列改進,提出了其 v2 和 v3 版本,在保持很高檢測速度的同時進一步提高了檢測精度,盡管與兩級探測器相比,它的探測速度有了很大的提高,但是YOLO的定位精度有所下降,特別是對于一些小目標, -
Single Shot MultiBox Detector (SSD)
SSD由W. Liu等人于2015年提出,這是深度學習時代的第二款單級探測器,SSD的主要貢獻是引入了多參考和多解析度檢測技術,這大大提高了單級檢測器的檢測精度,特別是對于一些小目標,SSD與以往任何檢測器的主要區別在于,前者在網路的不同層檢測不同尺度的物件,而后者僅在其頂層運行檢測, -
RetinaNet
單級檢測器速度快、結構簡單,但多年來一直落后于兩級檢測器的精度,T.-Y.Lin等人發現了背后的原因,并在2017年提出了RetinaNet,他們聲稱,在密集探測器訓練程序中所遇到的極端的前景-背景階層不平衡(the extreme foreground-background class imbalance)是主要原因,為此,在 RetinaNet 中引入了一個新的損失函式“焦損失(focal loss)”,通過對標準交叉熵損失的重構,使檢測器在訓練程序中更加關注難分類的樣本,焦損耗使得單級檢測器在保持很高的檢測速度的同時,可以達到與兩級檢測器相當的精度,

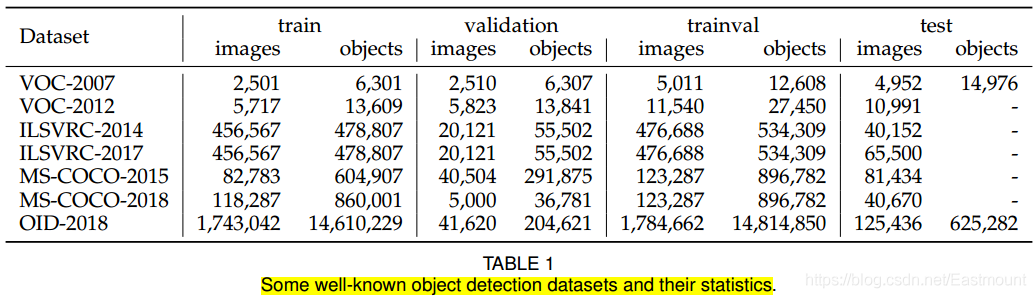
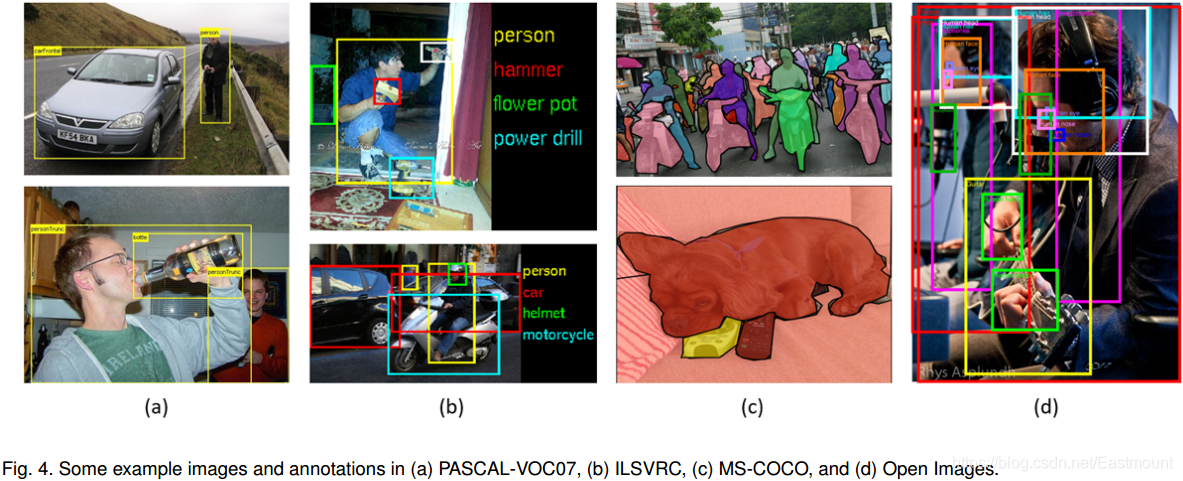
建立具有更少偏置的大資料集,是開發先進的計算機視覺演算法的關鍵,在目標檢測方面,在過去10年中,已經發布了許多著名的資料集和基準測驗,包括 PASCAL VOC 挑戰的資料集(如VOC2007、VOC2012)、ImageNet大尺度視覺識別挑戰(如ILSVRC2014)、MS-COCO檢測挑戰等,表1給出了這些資料集的統計資料,下圖顯示了這些資料集的一些影像示例,
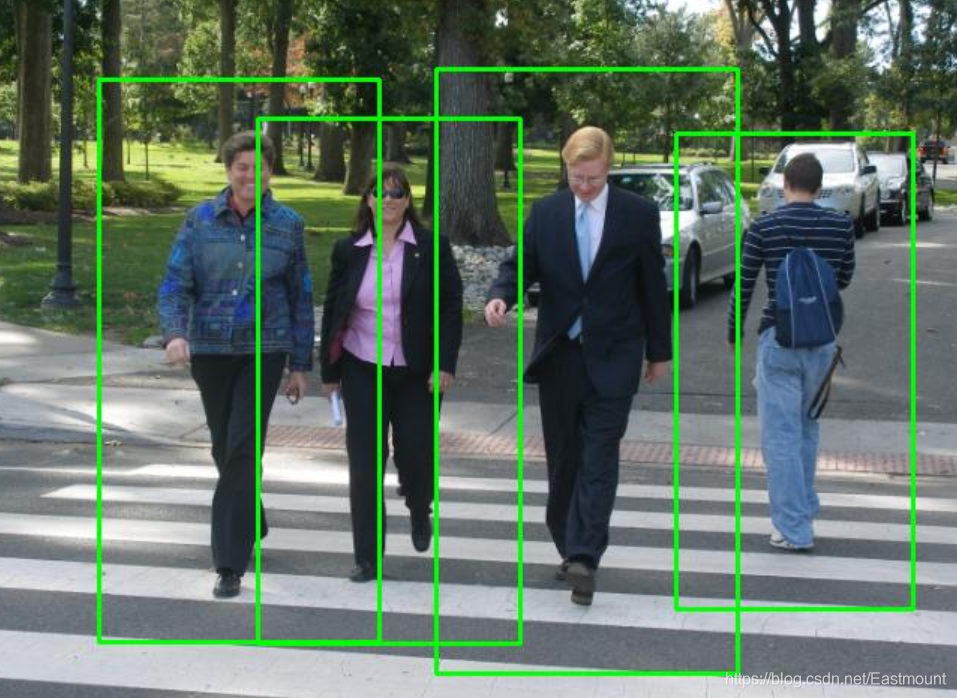
5.目標檢測應用
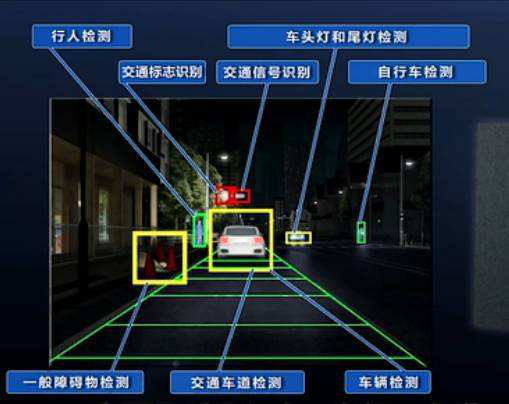
- 車輛檢測
自動駕駛、違章查詢、關鍵通道檢測、廣告檢測(檢測廣告中的車輛型別,彈出鏈接)等,
- 人臉檢測
人臉支付、智能門控、考勤簽到、智慧超市、車站機場實名認證、公共安全(逃犯抓捕、走失人員檢測)等,

- 行人檢測
步態識別、智能輔助駕駛、智能監控、暴恐檢測(根據面相識別暴恐傾向)、移動偵測、區域入侵檢測、安全帽/安全帶檢測等,

- 遙感檢測
大地遙感(如土地使用、公路、水渠、河流監控)、農作物監控、工業檢測、JS檢測等,

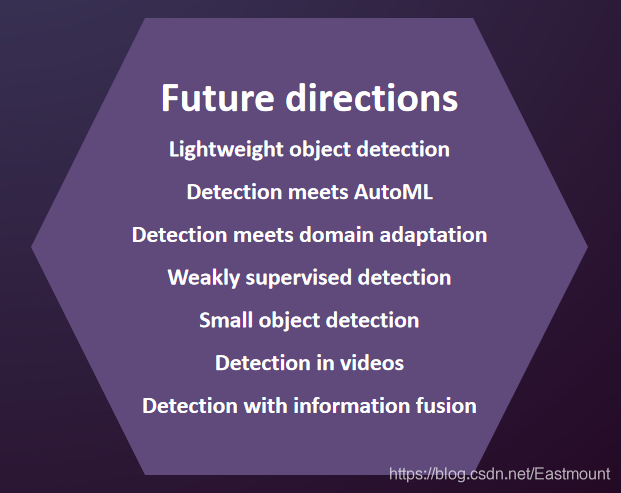
6.目標檢測未來挑戰
近20年來,目標檢測取得了顯著的成就,包括里程碑檢測器、關鍵技術、加速方法、檢測應用、資料集和指標,,如VJ、HOG、DPM、Faster-RCNN、YOLO、SSD等,未來的目標檢測研究可能會集中在以下幾個方面:
-
加快檢測演算法的速度(Lightweight object detection)
使其能夠在移動設備上平穩運行,一些重要的應用包括移動增強現實、智能攝像頭、人臉驗證等,雖然近年來已經做了很大的努力,但機器和人眼之間的速度差距仍然很大,特別是在檢測一些小物體時, -
自動機器學習目標檢測(Detection meets AutoML)
近年來,基于深度學習的檢測器變得越來越復雜,嚴重依賴于經驗,未來的方向是在使用神經結構搜索設計檢測模型時減少人為干預 ,譬如如何設計引擎和如何設定錨框 ) ,AutoML可能是未來的目標檢測, -
領域自適應檢測(Detection meets domain adaptation)
任何目標檢測器的訓練程序本質上都可以看作是一個假設資料獨立且同分布(i.i.d)時的似然估計程序,使用非 i.i.d 資料的目標檢測,特別是對一些實際應用程式來說,仍然是一個挑戰,GAN在領域自適應方面顯示出良好的應用前景,對未來的目標檢測具有重要的指導意義, -
弱監督檢測(Weakly supervised detection)
基于深度學習的檢測器的訓練通常依賴于大量注釋良好的影像,注釋程序耗時、開銷大且效率低,開發弱監督檢測技術,只使用影像級標注或部分使用邊界框標注對檢測器進行訓練,對于降低人工成本和提高檢測靈活性具有重要意義, -
小目標檢測(Small object detection)
在大場景中檢測小物體一直是一個挑戰,該研究方向的一些潛在應用包括利用遙感影像計算野生動物的數量和檢測一些重要JS目標的狀態,進一步的方向可能包括視覺注意機制的集成和高解析度輕量級網路的設計, -
視頻目標檢測(Detection in videos)
高清視頻中的實時目標檢測/跟蹤對于視頻監控和自主駕駛具有重要意義,傳統的目標檢測器通常設計為基于影像的檢測,而忽略了視頻幀之間的相關性,通過探索時空相關性來改進檢測是一個重要的研究方向, -
含資訊融合的目標檢測(Detection with information fusion)
RGB-D影像、三維點云、激光雷達等多資料源/多模式的目標檢測對自主駕駛和無人機應用具有重要意義,目前存在的問題包括:如何將訓練有素的檢測器移植到不同的資料模式,如何進行資訊融合以提高檢測能力等,
7.目標檢測原理簡述
目標檢測分為兩大系列——RCNN系列和YOLO系列,RCNN系列是基于區域檢測的代表性演算法,YOLO是基于區域提取的代表性演算法,另外還有著名的SSD是基于前兩個系列的改進,基本原理包括:
(1) 候選區域產生
目標檢測技術大都會涉及候選框(bounding boxes)的生成,物體候選框獲取當前主要使用影像分割與區域生長技術,區域生長(合并)主要由于檢測影像中存在的物體具有區域區域相似性(顏色、紋理等),目標識別與影像分割技術的發展進一步推動有效提取影像中資訊,
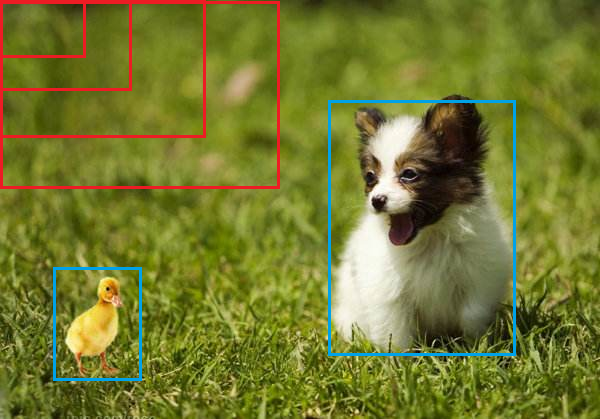
- 滑動視窗
① 首先對輸入影像進行不同視窗大小的滑窗進行從左往右、從上到下的滑動,每次滑動時候對當前視窗執行分類器(分類器是事先訓練好的),如果當前視窗得到較高的分類概率,則認為檢測到了物體,② 對每個不同視窗大小的滑窗都進行檢測后,會得到不同視窗檢測到的物體標記,這些視窗大小會存在重復較高的部分,接著采用非極大值抑制(Non-Maximum Suppression, NMS)的方法進行篩選,③ 最終經過NMS篩選后獲得檢測到的物體,
- 選擇性搜索
影像中物體可能存在的區域應該是有某些相似性或者連續性區域的,因此,選擇搜索基于上面這一想法采用子區域合并的方法進行提取bounding boxes,① 首先對輸入影像進行分割演算法產生許多小的子區域,② 根據這些子區域之間相似性(相似性標準主要有顏色、紋理、大小等)進行區域合并,不斷的進行區域迭代合并,每次迭代程序中對這些合并的子區域做bounding boxes(外切矩形),這些子區域外切矩形就是通常所說的候選框,最終提高檢測物體的概率,

(2) 資料表示
經過標記后的樣本資料如下所示:

預測輸出可以表示如下,其中pc為預測結果的置信概率,(bx,by,bw,bh)是邊框坐標,Ci為屬于某個類別的概率,通過預測結果、實際結果,構建損失函式,

(3) 效果評估
使用IoU(Intersection over Union,交并比)來判斷模型的好壞,交并比是指預測邊框、實際邊框交集和并集的比率,一般約定0.5為一個可以接收的值,
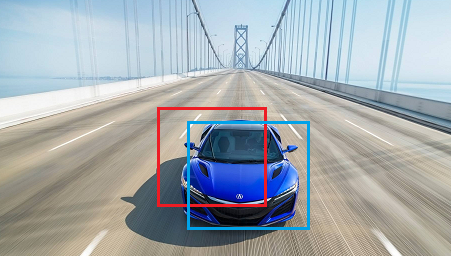
(4) 非極大值抑制
預測結果中,可能多個預測結果間存在重疊部分,需要保留交并比最大的、去掉非最大的預測結果,這就是非極大值抑制(Non-Maximum Suppression,簡寫作NMS),如下圖所示,對同一個物體預測結果包含三個概率0.8、0.9、0.95,經過非極大值抑制后,僅保留概率最大的預測結果,
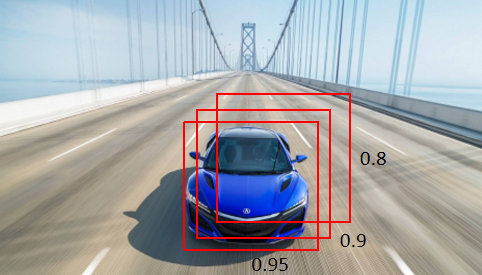
寫到這里,一個簡單的目標檢測程序介紹完畢,接下來我們重點使用ImageAI庫實作最簡單的目標檢測或物件檢測案例,這部分原理應用了yegeli老師的博客,
參加及推薦文章,大家可以關注并前往學習,
- 目標檢測(Object Detection) - 影像演算法AI yegeli老師
- https://arxiv.org/abs/1905.05055v2
- Object Detection in 20 Years: A Survey 綜述:目標檢測的二十年 - 牛戈老師
- 目標檢測最新進展總結與展望 - SIGAI老師
- 論文筆記-2019-Object Detection in 20 Years: A Survey
二.ImageAI簡介
ImageAI是一個開源Python庫,旨在使開發人員能夠使用簡單的幾行代碼構建具有包含深度學習和計算機視覺功能的應用程式和系統, 這個AI Commons專案由Moses Olafenwa和John Olafenwa開發和維護,官方原始碼及檔案如下:
- https://github.com/OlafenwaMoses/ImageAI
- https://imageai-cn.readthedocs.io/zh_CN/latest/

ImageAI本著簡潔的原則,支持最先進的機器學習演算法,用于 影像預測、自定義影像預測、物體檢測、視頻檢測、視頻物件跟蹤 和 影像預測訓練,ImageAI目前支持使用在ImageNet-1000資料集上訓練的4種不同機器學習演算法進行影像預測和訓練,ImageAI還支持使用在COCO資料集上訓練的RetinaNet、YOLOv3 和 TinyYOLOv3 進行物件檢測、視頻檢測和物件跟蹤, 最終,ImageAI將為計算機視覺提供更廣泛和更專業化的支持,包括但不限于特殊環境和特殊領域的影像識別,
- 新版本:ImageAI 2.1.6
新添加功能:
- 添加了SqueezeNet、ResNet50、InceptionV3 和 DenseNet121 模型進行自定義影像預測訓練
- 添加了自定義訓練模型和json檔案進行匯入和匯出自定義影像
- 預覽版:添加視頻物件檢測和視頻自定義物件檢測(物件跟蹤)
- 為所有影像預測和物件檢測任務添加檔案,numpy陣列和流輸入型別
- 添加檔案和numpy陣列輸出型別,用于影像中的物件檢測和自定義物件檢測
- 引入4種速度模式(normal, fast, faster 和 fastest)進行影像預測,在fastest速度模式下預測時間將縮短50%,同時保持預測精準度
- 為影像所有物體檢測和視頻物體檢測任務引入5種速度模式(normal, fast, faster, fastest 和 flash)
- 引入幀檢測率,允許開發人員調整視頻中的檢測間隔frame_detection_interval,有利于達到特定效果
ImageAI核心功能如下:
1.影像檢測
ImageAI提供 4 種不同的演算法和模型型別來執行影像預測,并在ImageNet-1000資料集上進行訓練,為影像預測提供的4 種演算法包括:
- MobileNetV2
- ResNet50
- InceptionV3
- DenseNet121

2.物件檢測
ImageAI提供了非常方便和強大的方法來對影像進行物件檢測并從影像中提取每個物件,物件檢測類提供對三種模型的支持,并提供針對最先進性能或實時處理進行調整的選項,
- RetinaNet
- YOLOv3
- TinyYOLOv3

person : 91.946941614151
--------------------------------
person : 73.61021637916565
--------------------------------
laptop : 90.24320840835571
--------------------------------
laptop : 73.6881673336029
--------------------------------
laptop : 95.16398310661316
--------------------------------
person : 87.10319399833679
--------------------------------
3.視頻物件檢測和跟蹤
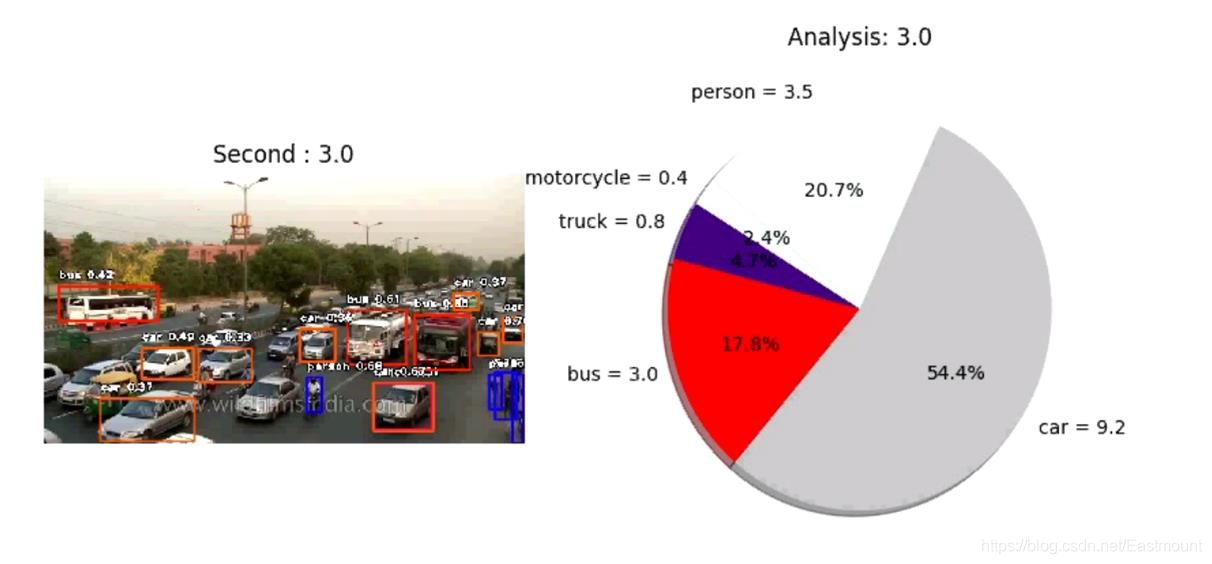
ImageAI提供了非常方便和強大的方法來執行視頻中的物件檢測和跟蹤特定物件,提供的視頻物件檢測類僅支持當前最先進的RetinaNet,但可以選擇調整最先進的性能或實時處理,下圖展示了對人、自行車和摩托車的視頻快照檢測效果,

下面是ImageAI回傳到“per_second”函式中的視頻分析的可視化,
4.自定義模型訓練
ImageAI為您提供了用于訓練新模型的類和方法,該模型可用于對您自己的自定義物件進行預測,您可以在5行代碼中使用演算法訓練您的自定義模型 ,
- SqueezeNet
- ResNet50
- InceptionV3
- DenseNet
下圖展示了來自IdenProf資料集的樣本,用于訓練預測專業人士的模型,

自定義影像預測:來自在 IdenProf 上訓練的樣本模型的預測,用于預測專業人士,

mechanic : 76.82620286941528
chef : 10.106072574853897
waiter : 4.036874696612358
police : 2.6663416996598244
pilot : 2.239348366856575
ImageAI提供了一些類和方法,供您使用通過ImageAI模型訓練類訓練的自己的模型來運行影像預測您自己的自定義物件,您可以使用SqueezeNet、ResNet50、InceptionV3和DenseNet訓練的自定義模型以及包含自定義物件名稱映射的JSON檔案,
5.自定義檢測模型訓練
ImageAI提供類和方法供您在自定義資料集上訓練新的YOLOv3物件檢測模型,這意味著您可以通過提供影像、注釋和使用 ImageAI 進行訓練來訓練模型以檢測任何感興趣的物件,

下圖展示了自定義YOLOv3模型的檢測結果,該模型經過訓練以檢測 Hololens 耳機,

hololens : 39.69653248786926 : [611, 74, 751, 154]
hololens : 87.6643180847168 : [23, 46, 90, 79]
hololens : 89.25175070762634 : [191, 66, 243, 95]
hololens : 64.49641585350037 : [437, 81, 514, 133]
hololens : 91.78624749183655 : [380, 113, 423, 138]
ImageAI現在提供類和方法,供您使用通過DetectionModelTraining類訓練的自己的模型檢測和識別影像中的自定義物件,您可以使用自定義訓練的YOLOv3模式和訓練期間生成的detection_config.json檔案,
6.自定義視頻物件檢測和分析
來自自定義 YOLOv3 模型的視頻檢測結果,訓練用于檢測視頻中的 Hololens 耳機,

三.安裝流程
安裝程序比較簡單,直接呼叫pip工具即可,
- pip install imageai --upgrade
- pip install imageai-2.0.2-py3-none-any.whl
Processing c:\users\xxx\downloads\imageai-2.0.2-py3-none-any.whl
(base) C:\Users\xiuzhang>activate tensorflow
(tensorflow) C:\Users\xiuzhang>cd Downloads
(tensorflow) C:\Users\xiuzhang\Downloads>pip install imageai-2.0.2-py3-none-any.whl
Processing c:\users\xiuzhang\downloads\imageai-2.0.2-py3-none-any.whl
Installing collected packages: imageai
Successfully installed imageai-2.0.2
本地安裝下載鏈接如下:
- https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.2/imageai-2.0.2-py3-none-any.whl
依賴擴展包:
- Python 3.5.1
- Tensorflow 1.4.0
- Numpy 1.13.1
- SciPy 0.19.1
- OpenCV
- pillow
- Matplotlib
- h5py
- Keras 2.x
四.TinyYOLOv3模型物件檢測案例
1.案例實作
物件檢測是計算機視覺領域中的一種技術,它處理識別和跟蹤影像和視頻中存在的物件,目標檢測有多種應用,如人臉檢測、車輛檢測、行人計數、自動駕駛汽車、安全系統等,ImageAI提供了非常方便和強大的方法來對影像進行物件檢測并從影像中提取每個物件,ImageAI 包含幾乎所有最先進的深度學習演算法的Python 實作,如RetinaNet、YOLOv3和 TinyYOLOv3,
ImageAI使用物件檢測、視頻檢測和物件跟蹤 API,無需訪問網路即可呼叫,ImageAI使用預先訓練的模型并且可以輕松定制,ImageAI中的 ObjectDetectionImageAI 庫的類包含使用預訓練模型對任何影像或影像集執行物件檢測的函式,借助 ImageAI,可以檢測和識別 80 種不同的常見日常物品,
下面開始實作一個簡單的物件檢測案例,
第一步,成功安裝ImageAI后,下載包含將用于物件檢測的分類模型的TinyYOLOv3模型檔案,
- https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/yolo-tiny.h5
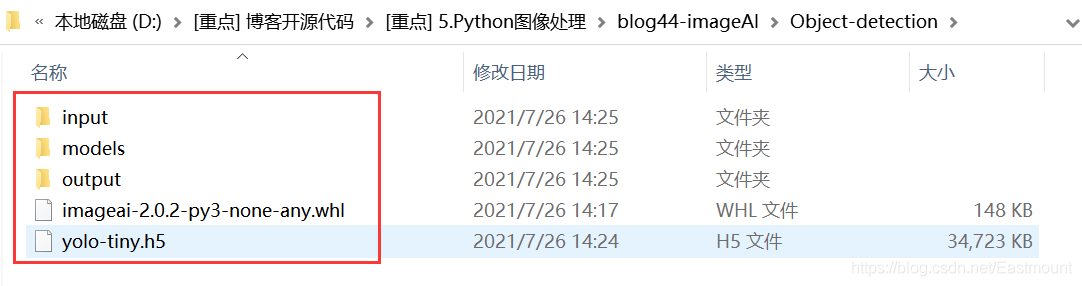
第二步,創建如下圖所示的檔案夾,
- Object-detection:根檔案夾
- models:存盤預先訓練的模型
- input : 存盤要執行物件檢測的影像檔案
- output:存盤檢測到物件的影像檔案
│ test_detector.py
│
├─input
│ test_car.png
│
├─models
│ yolo-tiny.h5
│
└─output
第三步,創建test_detector.py檔案,從ImageAI庫匯入ObjectDetection類,
from imageai.Detection import ObjectDetection
第四步,實體化ObjectDetection并指定相關的路徑檔案,
model_path = "./models/yolo-tiny.h5"
input_path = "./input/test_car-02.png"
output_path = "./output/pre_car-02.png"
detector = ObjectDetection()
第五步,利用實體化ObjectDetection類,呼叫其中的函式實作不同的功能,該類包含以下功能呼叫預先訓練模式:
- setModelTypeAsRetinaNet()
- setModelTypeAsYOLOv3()
- setModelTypeAsTinyYOLOv3()
第六步,使用預訓練TinyYOLOv3模型,利用setModelTypeAsTinyYOLOv3()函式加載模型,
detector.setModelTypeAsTinyYOLOv3()
第七步,設定模型路徑并實作影像物件檢測,這里需要detectObjectsFromImage使用detector創建的物件,并輸出結果,
detector.setModelPath(model_path)
detector.loadModel()
detection = detector.detectObjectsFromImage(input_image=input_path,
output_image_path=output_path)
完整代碼如下圖所示:
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 26 14:26:27 2021
@author: xiuzhang
"""
from imageai.Detection import ObjectDetection
#實體化
detector = ObjectDetection()
#路徑定義
model_path = "./models/yolo-tiny.h5"
input_path = "./input/test_car.png"
output_path = "./output/pre_car.png"
#預訓練模式
detector.setModelTypeAsTinyYOLOv3()
#設定預訓練模型路徑
detector.setModelPath(model_path)
#加載模型
detector.loadModel()
#創建物件
detection = detector.detectObjectsFromImage(input_image=input_path, output_image_path=output_path)
#檢測結果
for eachItem in detection:
print(eachItem["name"] , " : ", eachItem["percentage_probability"])
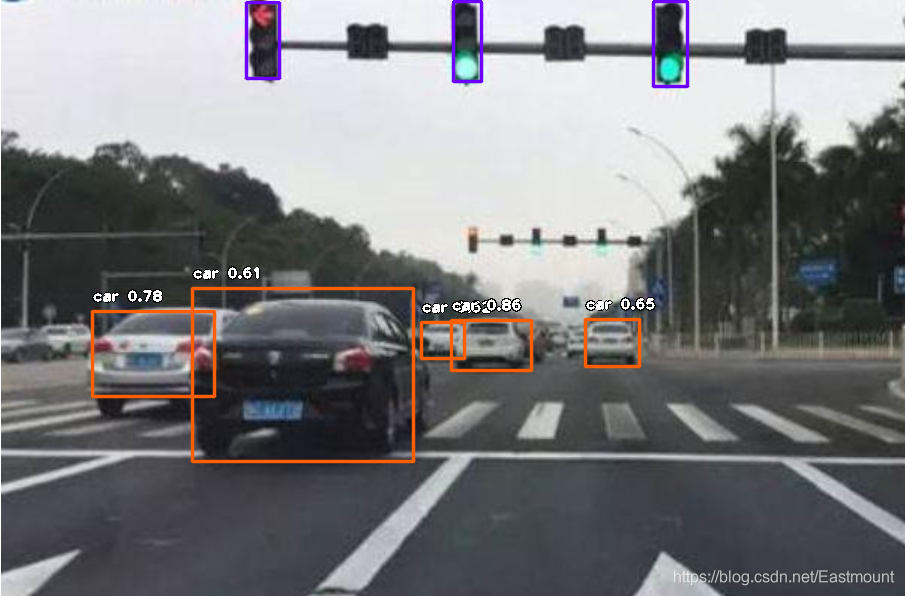
輸入影像如下圖所示,位于input檔案夾中,

輸出結果如下圖所示,可以看到不同列類別的預測概率及對應輪廓,

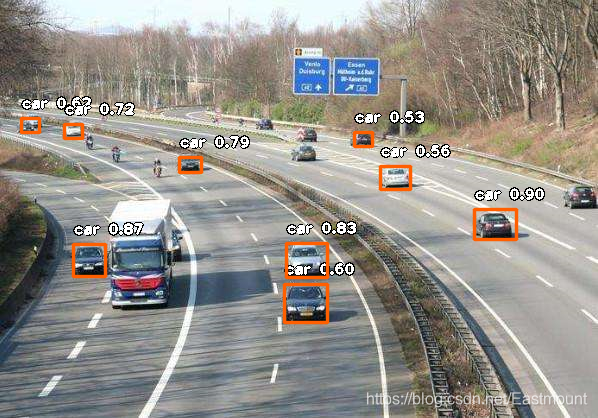
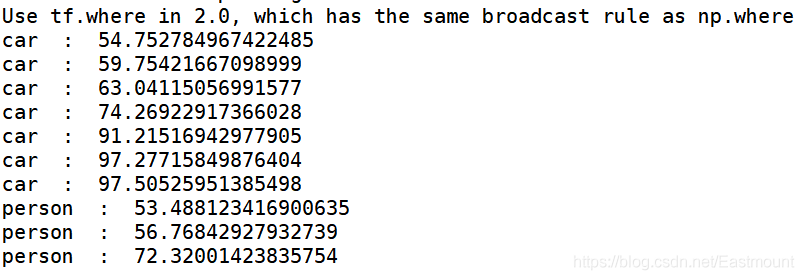
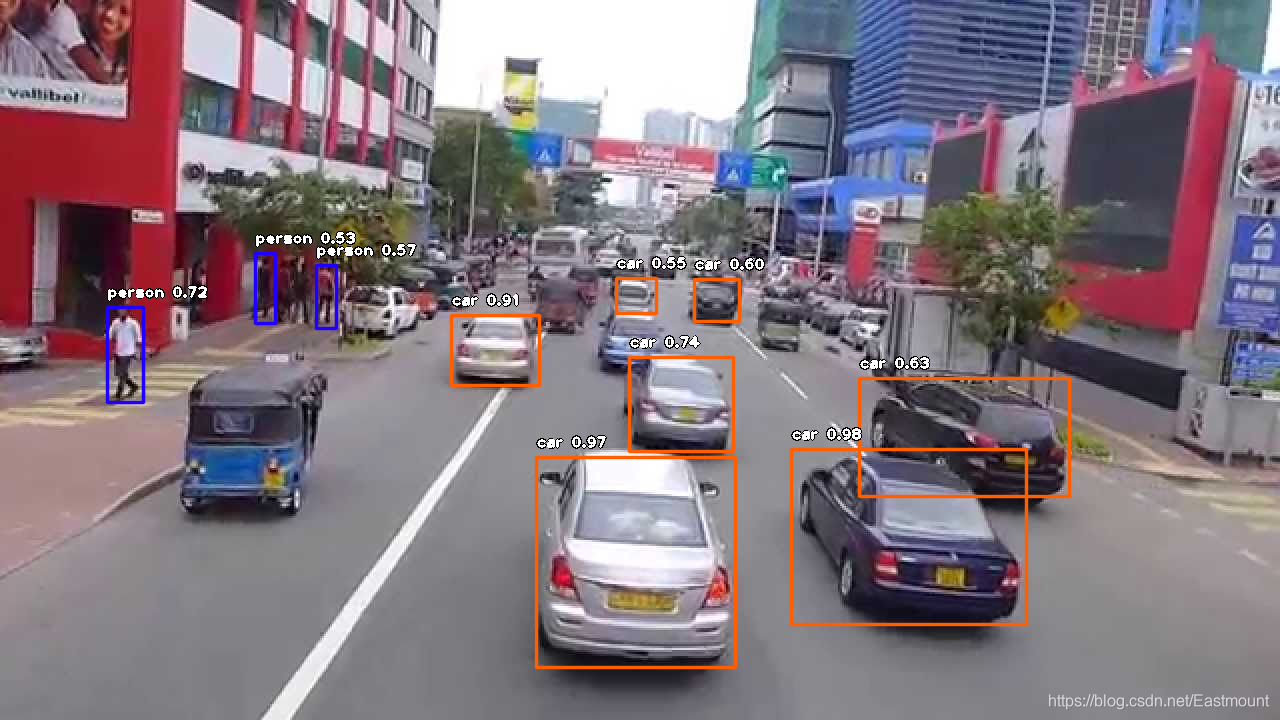
同時,還可以預測其他的車輛及行人等,
2.學習建議
個人認為Python提供了良好的擴展包供大家學習,如果您對CV感興趣,可以先閱讀作者前面的影像處理系列文章,后面再進行目標檢測的實驗,而目標檢測可以嘗試先了解最簡單調包的實作,后面再一步步告訴大家如果構建YOLO或SSD模型,
此外,Python開源庫提供了強大的源代碼,大家可以去學習及修改對應的功能,比如:
- setModelTypeAsTinyYOLOv3函式原型
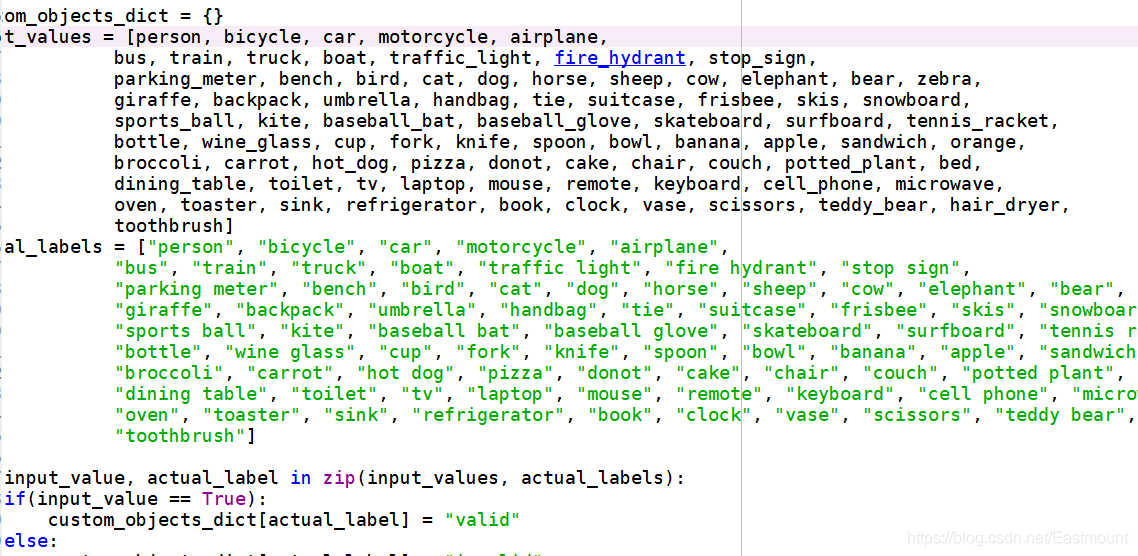
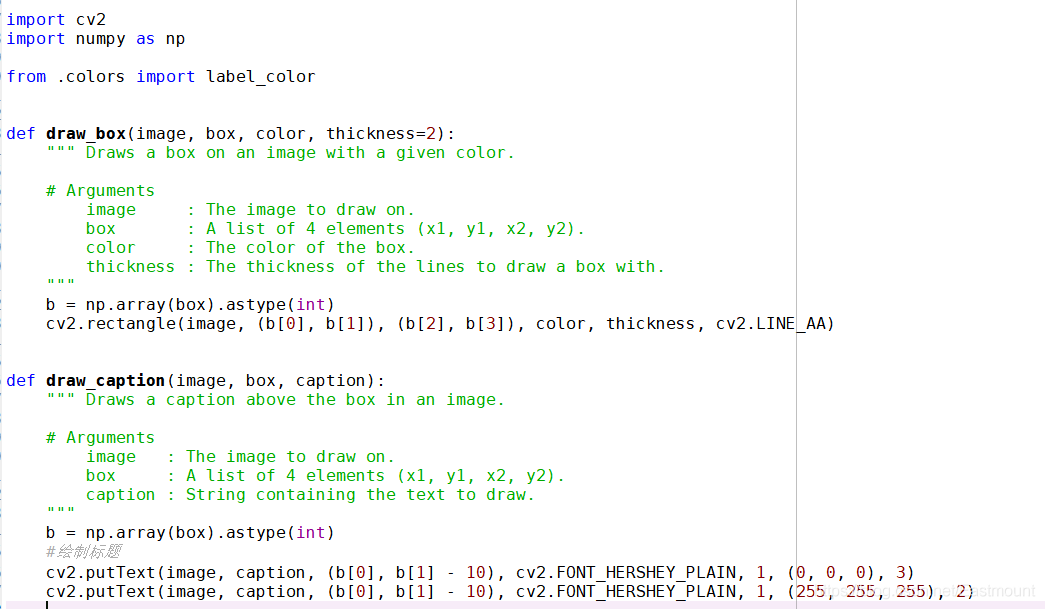
同時,該擴展包可以檢測多種型別的物件,從上圖源代碼中可以看到,也可以看到繪制方塊及Text的程序,
后續作者會想辦法嘗試自定義資料集進行目標識別,比如農產品、飛行器、自然災害等,
- https://github.com/OlafenwaMoses/ImageAI/blob/master/imageai/Classification/CUSTOMCLASSIFICATION.md
from imageai.Classification.Custom import CustomImageClassification
import os
execution_path = os.getcwd()
prediction = CustomImageClassification()
prediction.setModelTypeAsResNet50()
prediction.setModelPath(os.path.join(execution_path, "idenprof_resnet_ex-056_acc-0.993062.h5"))
prediction.setJsonPath(os.path.join(execution_path, "idenprof.json"))
prediction.loadModel(num_objects=10)
predictions, probabilities = prediction.classifyImage(os.path.join(execution_path, "4.jpg"), result_count=5)
for eachPrediction, eachProbability in zip(predictions, probabilities):
print(eachPrediction + " : " + eachProbability)
最后推薦劉兄的系列文章,也真心不錯,
- 深度學習和目標檢測系列教程 2-300:小試牛刀,使用 ImageAI 進行物件檢測
五.總結
寫到這里,第一篇目標檢測入門文章就介紹完畢,希望您喜歡,
- 一.目標檢測入門普及
1.什么是目標檢測?
2.目標檢測的核心問題是什么?
3.目標檢測演算法常用分類
4.目標檢測常見演算法
5.目標檢測應用
6.目標檢測未來挑戰
7.目標檢測原理簡述 - 二.ImageAI簡介
- 三.安裝流程
- 四.TinyYOLOv3模型物件檢測案例
1.案例實作
2.學習建議
源代碼下載地址,記得幫忙點star和關注喔,
- https://github.com/eastmountyxz/ImageProcessing-Python
大學之道在明明德,
在親民,在止于至善,
這周又回答了很多博友的問題,有大一學生的困惑,有論文的咨詢,也有老鄉和考博的疑問,還有無數博友奮斗路上的相互勉勵,雖然自己早已忙成狗,但總忍不住去解答別人的問題,最后那一句感謝和祝福,永遠是我最大的滿足,雖然會花費我一些時間,但也挺好的,無所謂了,跟著心走,不負遇見,感恩同行,莫愁前路無知己,繼續加油,晚安娜和珞,

(By:Eastmount 2021-08-03 晚上10點 http://blog.csdn.net/eastmount/ )
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291872.html
標籤:python
上一篇:【python實戰】不玩微博,一封郵件就能知道實時熱榜,天秀吃瓜
下一篇:全網首發,一篇文章帶你走進pycharm的世界----別再問我pycharm的安裝和環境配置了!!!萬字只為君一笑,趕緊收藏起來吧