第一步:導庫
import requests
from lxml import etree第二步:請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'Referer': 'http://www.xbiquge.la/7/7931/',
'Cookie': '_abcde_qweasd=0; BAIDU_SSP_lcr=https://www.baidu.com/link?url=jUBgtRGIR19uAr-RE9YV9eHokjmGaII9Ivfp8FJIwV7&wd=&eqid=9ecb04b9000cdd69000000035dc3f80e; Hm_lvt_169609146ffe5972484b0957bd1b46d6=1573124137; _abcde_qweasd=0; bdshare_firstime=1573124137783; Hm_lpvt_169609146ffe5972484b0957bd1b46d6=1573125463',
'Accept-Encoding': 'gzip, deflate'
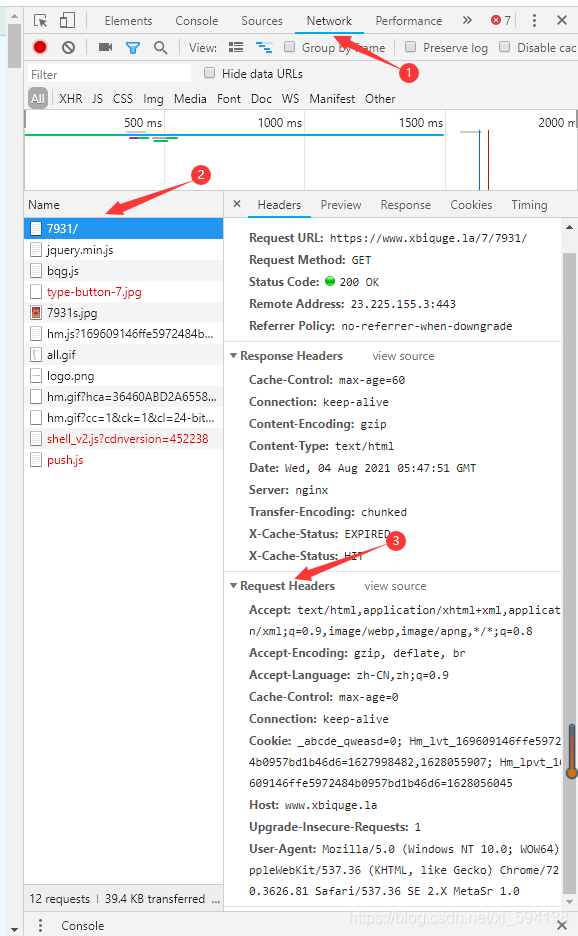
}請求頭的內容獲取:F12鍵進入開發者模式,步驟如下圖所示(未出現網站資訊重繪一下頁面就可以了)
第三步:獲取網站原始碼
def get_text(url, headers):
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
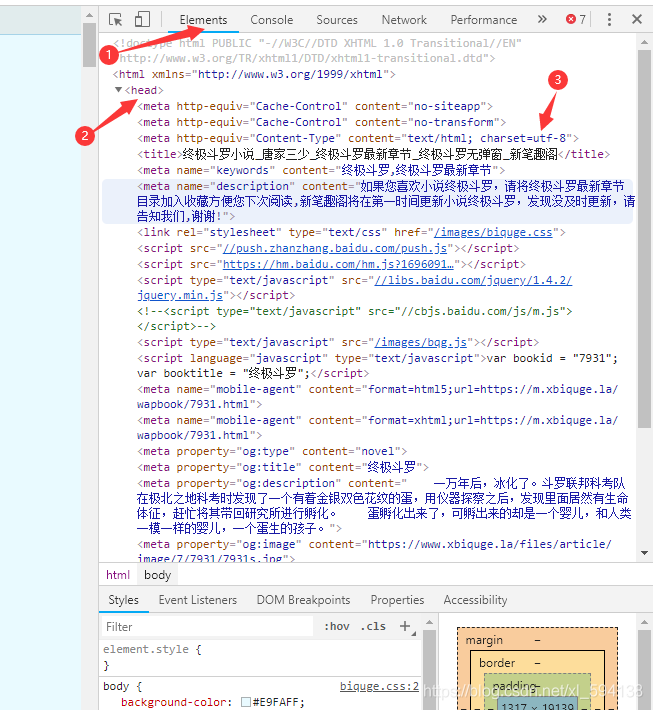
return response.text部分網站編碼是gbk,gb2312等,可以這樣查看網頁編碼,按F12鍵
第四步:獲取小說資訊
def get_novelinfo(list1, name_list):
for i, url in enumerate(list1):
html = etree.HTML(get_text(url, headers))
name = name_list[i] # 書名
title_url = html.xpath('//div[@id="list"]/dl/dd/a/@href')
title_url = ['http://www.xbiquge.la' + i for i in title_url] # 章節地址
titlename_list = html.xpath('//div[@id="list"]/dl/dd/a/text()') # 章節名字串列
get_content(title_url, titlename_list, name)
第五步:獲取小說每章節內容
def get_content(url_list, title_list, name):
for i, url in enumerate(url_list):
item = {}
html = etree.HTML(get_text(url, headers))
content_list = html.xpath('//div[@id="content"]/text()')
content = ''.join(content_list)
content=content+'\n'
item['title'] = title_list[i]
item['content'] = content.replace('\r\r', '\n').replace('\xa0', ' ')
print(item)
with open(name + '.txt', 'a+',encoding='utf-8') as file:
file.write(item['title']+'\n')
file.write(item['content'])第六步:獲取小說主頁資訊
def main():
base_url = 'http://www.xbiquge.la/xiaoshuodaquan/'
html = etree.HTML(get_text(base_url, headers))
novelurl_list = html.xpath('//div[@class="novellist"]/ul/li/a/@href')
name_list = html.xpath('//div[@class="novellist"]/ul/li/a/text()')
get_novelinfo(novelurl_list, name_list)
if __name__ == '__main__':
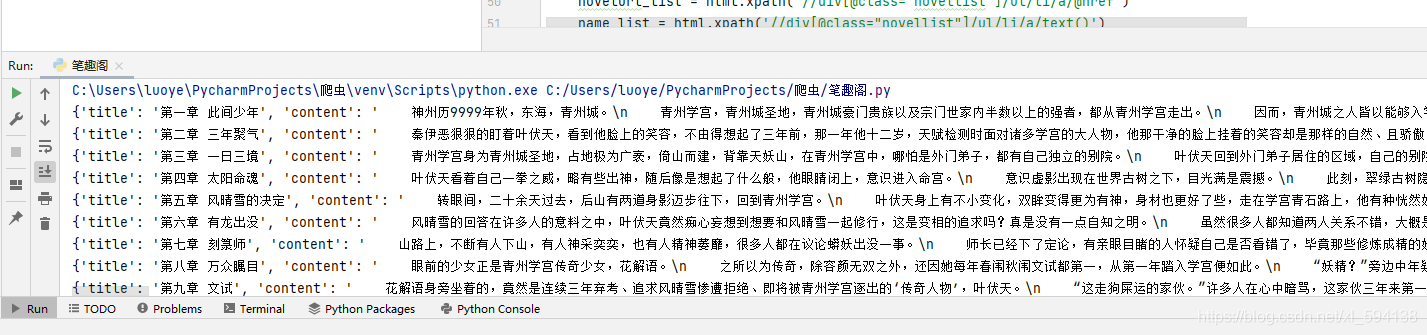
main()下面是爬取的結果:
運行后會在左側生成一個文本檔案:
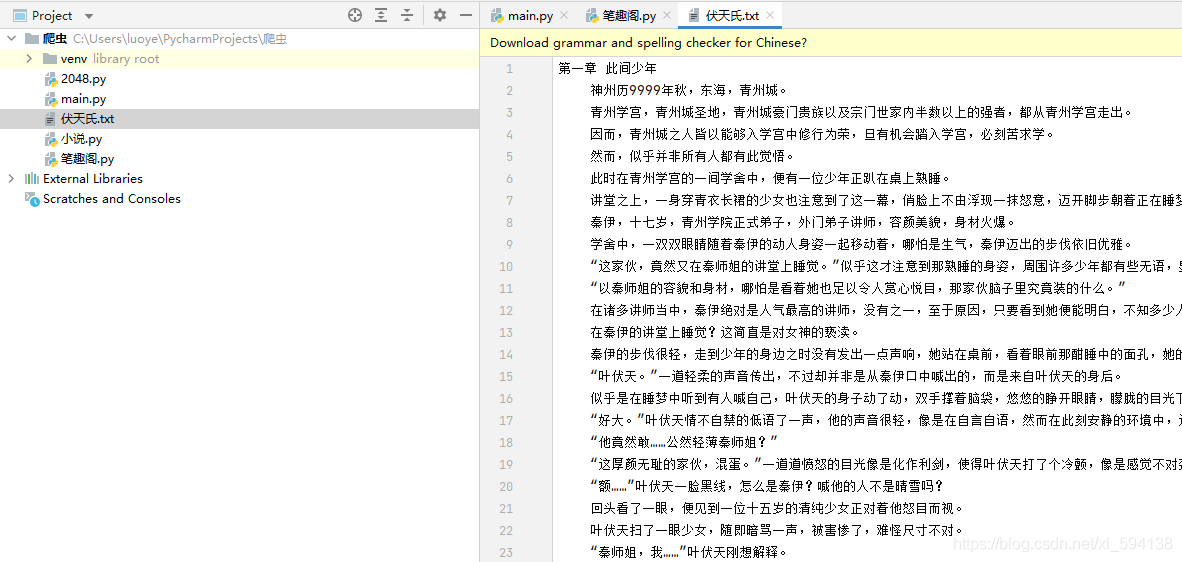
同時可以在本地查看生成的文本:
一個完整的爬蟲就到此結束了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292044.html
標籤:python
上一篇:模擬登陸python程式