Python圖片文字識別——Windows下Tesseract-OCR的安裝與使用
- 前言
- Windows下Tesseract-OCR的安裝與配置
- Tesseract-OCR簡介與版本選擇
- tesseract-OCR安裝
- Tesseract-OCR配置
- 安裝Python呼叫Tesseract API所需依賴項
- Tesseract-OCR測驗與使用
- 命令列模式
- 使用 Python 呼叫 Tesseract API
- 溫馨提示
前言
最近想做一篇爬蟲分析給男朋友/女朋友送禮物的博文,但是在某寶上使用“七夕禮物送女友”關鍵字進行搜索得到的商品的標題很多都是類似這樣的《生日禮物女生七夕情人節給閨蜜送女友朋友送給女孩的實用小高級感》,讓人僅看標題根本不知道賣的是什么,但是看到很多封面圖片上包含的有商品名或者商品說明,于是想到可以識別封面圖中的文字進行分析,
雖然可以通過自己訓練模型來實作此效果,但暫時又實在是比較懶惰,就使用了現有工具 Tesseract,將安裝和使用進行分享,
Windows下Tesseract-OCR的安裝與配置
提取、識別圖片中的文字也稱為光學字符識別 (Optical Character Recognition, OCR),其是指將手寫或印刷文本的影像轉換為文本,包括來自掃描檔案、檔案照片、場景照片(例如風景照片中標志和廣告牌上的文字)或疊加在影像上的字幕等文字,
Tesseract-OCR簡介與版本選擇
Tesseract 是一個開源 OCR 引擎,Tesseract 可以直接通過命令列使用,或者通過使用 API 從影像中提取文本,它為多種語言提供了API,其中顯然包括 Python,除了可以使用二進制安裝包進行安裝外,也可以針對各種設備使用源代碼進行編譯,包括 Android 和 iPhone,Tesseract 支持 unicode (UTF-8),可以識別 100 多種語言,Tesseract 支持各種輸出格式,包括純文本、HTML、PDF、TSV等,5.0.0 alpha 還增加了對 XML 輸出的支持,
目前,Tesseract 主要包含三個版本:3.x、4.x和 5.0.0 alpha,最新的 3.x 版本(可用于某些具有特殊需求的專案,如特征回歸)為 3.05.02,于 2018 年 6 月 19 日發布;最新的穩定版本(基于 LSTM)是 4.1.1,發布于 2019 年 12 月 26 日;5.0.0 alpha 對代碼進行了重構,增加了一些實驗性的功能,參考官方意見,由于需要使用 Tesseract API,因此選擇使用 4.1.0,
有關 Tesseract 的更多介紹,可以參考官方檔案.
tesseract-OCR安裝
安裝程序主要參考官方檔案,
-
首先,下載根據需要下載安裝包,這里選擇 tesseract-ocr-w64-setup-v4.1.0.20190314.exe,
-
雙擊下載完成的安裝包進行安裝,
-
點擊
Next后,經典同意 (I Agree) 服務條款,
-
單擊
I Agree后,選擇為所有用戶或僅當前用戶安裝,這里選擇默認的為所有用戶,
-
單擊
Next后,選擇附加腳本和語言資料,
根據需要,選擇附加腳本資料:
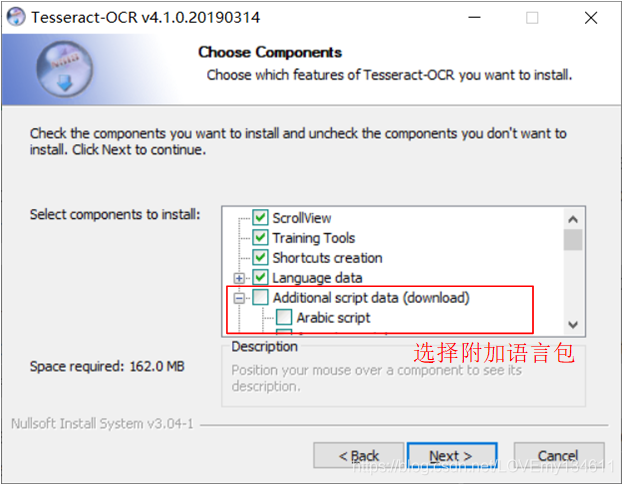
根據需要,選擇附加語言資料:
這里選擇了中文相關的附加語言包:
-
點擊
Next后,選擇軟體安裝位置,這里使用默認位置,
Warning: Tesseract 應該安裝默認目錄或新目錄中,否則由于卸載程式會洗掉整個安裝目錄,會導致該目錄及其所有子目錄和檔案被洗掉, -
點擊
Next后,選擇是否創建快捷方式,及快捷方式位置,
由于我只想使用 Tesseract API,因此此處選擇不創建快捷方式,勾選Do not create shortcuts前復選框,如果需要快捷方式,取消勾選此復選框即可,
-
點擊
Install開始安裝,
-
安裝完成后,點擊
Next,
-
最后點擊
Finish完成安裝,
Tesseract-OCR配置
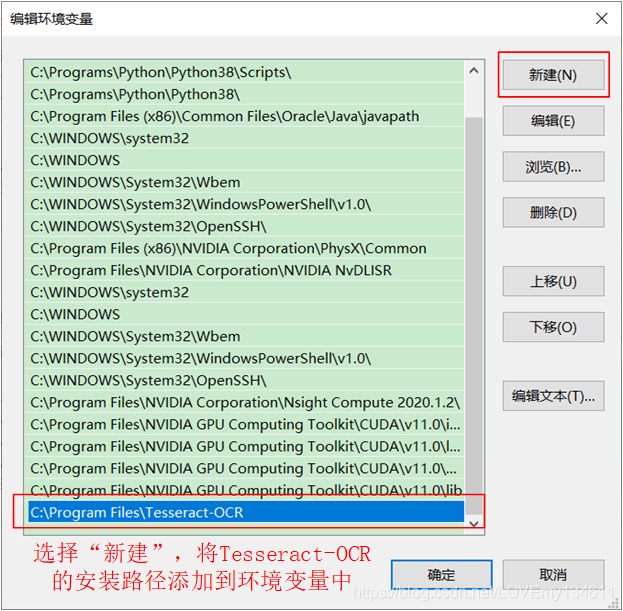
將 Tesseract 添加進環境變數中,右鍵單擊“此電腦”,選擇“屬性”,單擊“高級系統設定”,然后單擊“環境變數”,“編輯”系統環境變數“Path”,選擇“新建”將 Tesseract-OCR 的安裝目錄(此處展示的安裝目錄為默認位置,如果修改了安裝目錄需要根據自己的安裝位置進行修改)添加到環境變數中,
“確定”生效后,可以在 shell 中運行以下命令進行驗證:
tesseract -v
若成功配置,則會列印版本資訊:
tesseract v4.0.0.20190314
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
Found AVX2
Found AVX
Found SSE
安裝Python呼叫Tesseract API所需依賴項
- 安裝 pillow,在命令列 shell 中使用以下命令
pip install pillow - 安裝 pytesser3,在命令列 shell 中使用以下命令
pip install pytesser3 - 安裝 pytesseract,在命令列 shell 中使用以下命令
pip install pytesseract
Tesseract-OCR測驗與使用
如果需要提取的文字并非英文,則還需要下載其他語言的資料包,但是,如果在安裝程序已經選擇了所需的附加語言資料則不需要再次下載;否則需要在下載所需語言包后,將其置于 C:\Program Files\Tesseract-OCR\tessdata 目錄下(如果修改了默認安裝目錄,需要根據自己的安裝位置進行修改),
除了直接使用程式外,還可以使用以下兩種方式呼叫 Tesseract,
命令列模式
命令格式如下:
tesseract 輸入圖片的檔案名 輸出檔案名 [-l lang][-psm pagesegmode][configfile...]
例如識別 “test.png” 圖片中文字,保存至 “result.txt” 檔案中,
tesseract test.png result
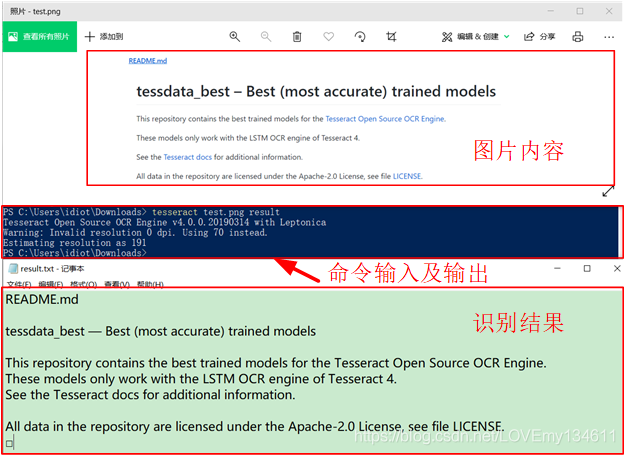
可以看到識別的準確率非常優秀,
使用 Python 呼叫 Tesseract API
測驗使用 Tesseract 識別中文的準確率,
import pytesseract
from PIL import Image
img = Image.open("test_1.png")
print(pytesseract.image_to_string(img,lang='chi_sim'))
識別圖片:

識別結果:
通過反射填充(reflection padding)減少塊偽影
當我們在卷積層中將填充( padding )應上
的影像q
導致塊偽影,減少這些高頻分量的一種方法是在網路訓練
于輸入張量時,在張量周圍填充常數
網
1. 首先,通過將|
2. 然后減去原始|
像移動一個像素來計算高頻分量,
像以創建一個矩陣,
加添加總變分損失( total variation loss )作為正則化器:
,但是,邊界處的值突然下降會產生高頻分量,
看到識別的問題問題并不大,但是格式很奇怪,接下來試一下識別商品圖片上的文字:
img = Image.open("test_2.webp")
print(pytesseract.image_to_string(img,lang='chi_sim'))
識別圖片與識別結果如下所示:

識別效果,呃,能用只能說,
溫馨提示
- 為了獲得更好的 OCR 結果,需要提高提供給 Tesseract 的影像質量,
- 除了官方預先訓練好的語言包外,也可以訓練 Tesseract 識別其他語言,有關更多資訊,請參閱 Tesseract 訓練,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292049.html
標籤:python