技術上碾壓對手
顏值上驚艷對手
中國奧運健兒們真是又美又能打!
帶你一看
中國運動員顏值有多高
需求分析
網友們都在微博上說了啥?
看這里
▼

之氣那我們也有分析過B站的彈幕,有興趣的小伙伴可以看看這里
爬蟲B站彈幕| 考完試,這輩子,這個班,基本是聚不齊了......
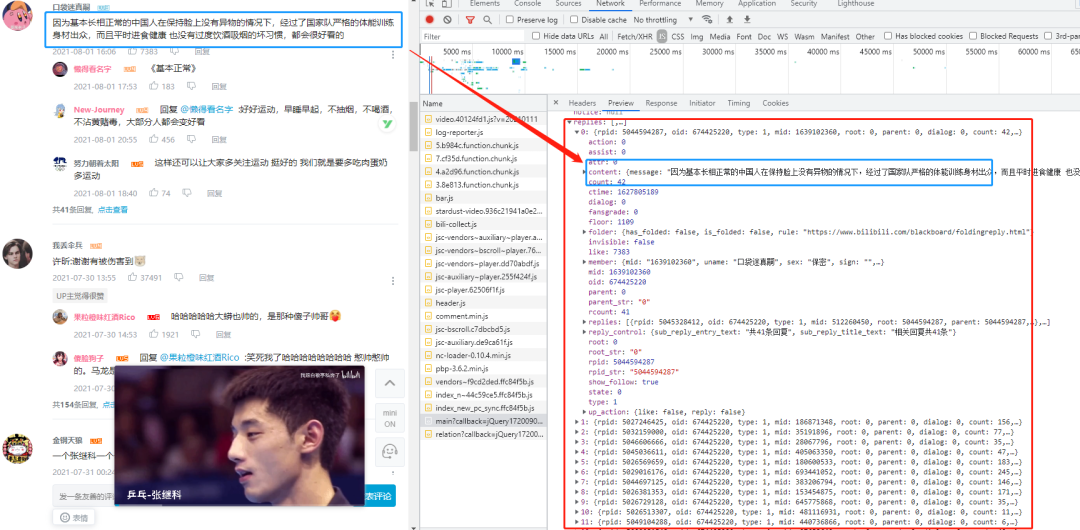
首先我們打開B站找到我們要找的視頻,

F12打開瀏覽器開發者模式,找到如下鏈接,
經過測驗發現,目前它是通過Js經行渲染的,想通了這一點,那就可以馬上去找介面了,
可以看到我們所有爬取的評論資訊全在在一個不規則的json檔案當中
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172011288135593018156_1627894496820&jsonp=jsonp&next=2&type=1&oid=674425220&mode=3&plat=1&_=1627894506606
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172011288135593018156_1627894496821&jsonp=jsonp&next=3&type=1&oid=674425220&mode=3&plat=1&_=1627894508981
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172011288135593018156_1627894496822&jsonp=jsonp&next=4&type=1&oid=674425220&mode=3&plat=1&_=1627894510667
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172011288135593018156_1627894496823&jsonp=jsonp&next=5&type=1&oid=674425220&mode=3&plat=1&_=1627894567580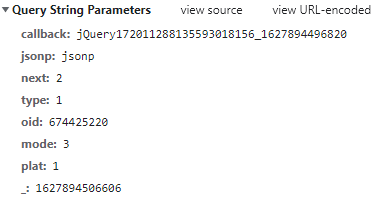
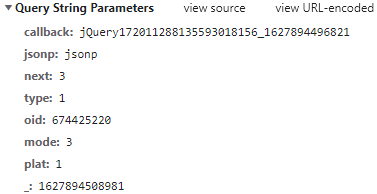
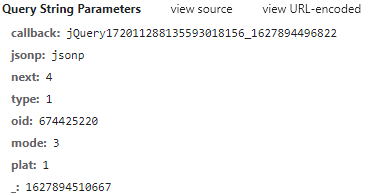
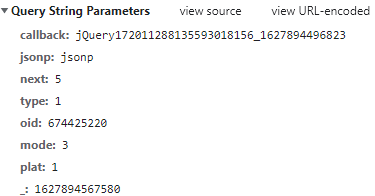
從上面的URL地址以及圖片,可以看出一共有8個查詢引數,
callback:每加載出一次便加1操作,
next:每加載一次便加1操作,next是從0開始加載的,
_:13位的時間戳,????????????
![]()
![]()
發送請求
我們首先模擬瀏覽器來發送請求獲取到這個json資料集,然后獲取具體的
評論者、行唄、評論時間、點贊人數和具體的評論內容
url = f'https://api.bilibili.com/x/v2/reply/main?callback=jQuery172009047692616139114_{1627891325400 + page}&jsonp=jsonp&next={page}&type=1&oid=674425220&mode=3&plat=1&_={time_thick}'
headers = {
"cookie": "_uuid=BA408FD2-1B4E-DCB0-1CBE-71233AE9FB2918358infoc; buvid3=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; sid=ld1hsb9h; fingerprint=84acc3579a53d0eba78d769e71574df6; buvid_fp=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; buvid_fp_plain=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; DedeUserID=434541726; DedeUserID__ckMd5=448fda6ab5098e5e; SESSDATA=40011147%2C1643348516%2Ce493c*81; bili_jct=1d136ab44a600313299942bf8f6b8f95; CURRENT_FNVAL=80; blackside_state=1; rpdid=|(u)YJR~R~)m0J'uYk~~mY~Y); bsource=search_baidu; PVID=1; bfe_id=393becc67cde8e85697ff111d724b3c8",
'referer': 'https://www.bilibili.com/video/BV1uU4y1H7wL',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.8 Safari/537.36'
}
resp = requests.get(url, headers=headers)
ic(resp.text)前面說到我們獲取的這個json格式的資料集不是一個標準的json
就是因為前面多了一串
‘jQuery172009047692616139114_1627891325400’

所以我們先將獲取到的資料集轉為標準的json格式,
如下:
# 獲取resp回應
text = resp.text[42:-1]
# 轉換json格式
json_data = json.loads(text)
# 獲取所有評論
datas = json_data['data']['replies']
ic(datas)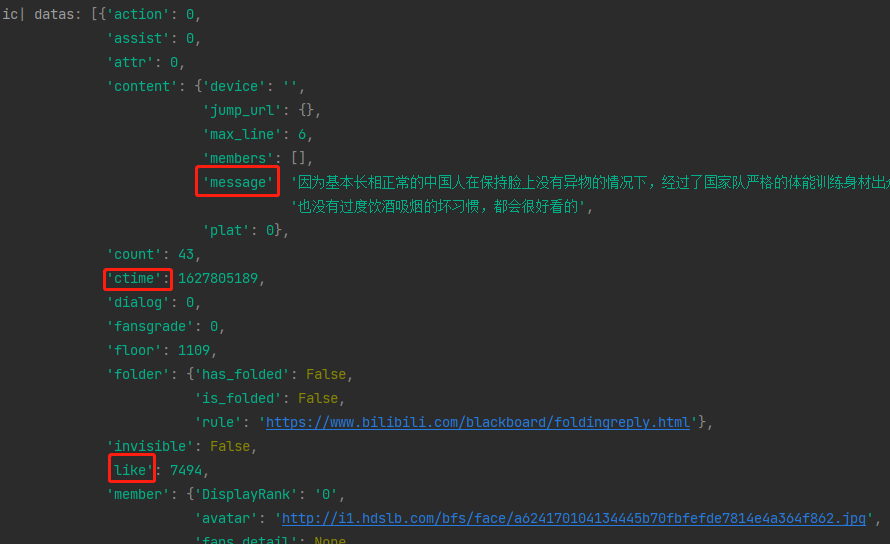
接下來我們要獲取的就是那些評論資訊等
for item in datas:
# 評論者
name = item['member']['uname']
# 性別
sex = item['member']['sex']
# 評論時間
ctime = item.get('ctime')
content_time = time.strftime('%Y-%m-%d %H:%M', time.localtime(ctime))
# 點贊人數
star = item['like']
# 評論內容
cmts = item['content']['message']
ic(name, sex, content_time, star, cmts)
實作翻頁爬取
在前面所描述的內容,都只是爬取一頁的資料,因此,接下來我要實作類于翻頁爬取的效果,
其實只要修改我上面所描述的3個查詢引數即可,
測驗資料我們就先取200頁,
for page in range(1, 200 + 1):
time_thick = int(time.time() * 1000)
url = f'https://api.bilibili.com/x/v2/reply/main?callback=jQuery172009047692616139114_{1627891325400 + page}&jsonp=jsonp&next={page}&type=1&oid=674425220&mode=3&plat=1&_={time_thick}'
保存資料
最后將爬取下來的資料,使用openpyxl保存至Excel檔案中,總共得到4000條測驗資料,

資料處理
這里我們使用熊貓來讀取資料,并去除空行
使用jieba制作分詞
rcv_data = pd.read_excel('嗶哩嗶哩.xlsx')
exist_col = rcv_data.dropna() # 洗掉空行
c_title = exist_col['評論內容'].tolist()
# 觀影評論詞云圖
wordlist = jieba.cut(''.join(c_title))
result = ' '.join(wordlist)可視化
最后我們使用stylecloud來生成多樣形式的詞云
gen_stylecloud(text=result,
icon_name='fas fa-table-tennis',
font_path='msyh.ttc',
background_color='white',
output_name=pic,
custom_stopwords=['啊', '的', '也', '了', '我', '是', '嗎', '都', '就', '你', '不', '真的', '有', '這', '沒有', '他們', '還有', '說', '封面']
)
print('繪圖成功!')



轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292051.html
標籤:python