目錄
- 🎅第一部分——初識Selenium!
- 🍏1.Selenium是什么?
- 🍒2.運行環境
- 🍓3.安裝
- 1??安裝selenium庫:
- 2??安裝ChromeDriver驅動:
- 🍌4.selenium的作用和作業原理
- 1??作用:
- 2??作業原理:
- 🍠5. 實戰例子 之 簡單使用:
- ??①上代碼:
- ??②代碼決議:
- ??③效果展示:
- 🎍第二部分——Selenium進階操作!
- 🐱1.操作瀏覽器的常用騷操作:
- 🚩(1)騷操作及代碼實作:
- 🚩(2)實戰使用:
- ??①上代碼:
- ??②實作效果:
- 🐹2.元素選取/查找節點:
- 第一種方法——find_element(s)by_...方法:
- ??(1)單個節點:
- ??(2)多個節點:
- 第二種方法——By物件查找:
- 🐸3.節點互動:
- 🚀(1)常見用法:
- 🚀(2)示例之騷操作:
- 🐻4.動作鏈:
- 👑(1)講解:
- 👑(2)方法:
- 👑(3)示例:
- 🐮5.提取節點文本內容和屬性值:
- ??(1)獲取文本內容:
- ??(2)獲取屬性值:
- 🐒6.執行JavaScript代碼:
- ??實戰演示:
- 📌①上代碼:
- 📌②效果展示:
- 🐫7.標簽頁/視窗的切換:
- 💊(1)方法:
- 💊(2)實戰演示:
- 🔆①思路決議:
- 🔆②上代碼:
- 🔆③效果展示:
- 🏃8.實戰——Selenium過滑塊驗證碼:
- 🔮第三部分——In The End!
- 👻👻相信不少小伙伴們在經歷過我的上幾篇關于爬蟲技術的萬字博文的輪番轟炸后,已經可以獨立開發出屬于自己的爬蟲專案!!!——爬蟲之路,已然開啟!👻👻
?
?💦第一篇之爬蟲入坑文;一篇萬字博文帶你入坑爬蟲這條不歸路(你還在猶豫什么&抓緊上車) 【??熬夜整理&建議收藏??】
?💦第二篇之爬蟲庫requests庫詳解,兩萬字博文教你python爬蟲requests庫,看完還不會我把我女朋友都給你【??熬夜整理&建議收藏??】
?💦第三篇之決議庫Xpath庫詳解,萬字博文教你python爬蟲必備XPath庫,看完還不會我把我女朋友都給你【??建議收藏系列??】
?💦第四篇之決議庫Beautiful Soup庫詳解,Python萬字博文教你玩透Beautiful Soup庫,不信你學不會【??建議收藏系列??】
- 😬😬但是前幾天有粉絲VX問了我這樣一個問題:“我在瀏覽器中通過開發者工具看到的網頁原始碼與我通過requests庫爬取下來的網頁原始碼完全不一樣!這是怎么一回事啊?通過博主你教的方法都解決不了哎!”😬😬
? 其實這就涉及到了前端方面的知識,但是本人精力時間有限,所以目前暫只更新了一篇HTML的必備知識文,關注本博主——后面會加把勁繼續更新CSS及JavaScript相關知識的文哦!
?
? 💦身為爬蟲人也必須要會的前端知識第一篇之HTML講解,前端HTML兩萬字圖文大總結,快來看看你會多少!【??熬夜整理&建議收藏??】
- ??關于這個問題,我們先要知道為啥子會出現這種情況然后才能對癥下藥,首先要知道的是requests獲取的都是原始的HTML檔案,而瀏覽器中的頁面都是經過JavaScript處理資料后生成的結果,這些資料的來源多種多樣,可能是通過Ajax加載的,可能是包含在HTML檔案里的,也可能是經過JavaScript和特定演算法計算后生成的, ??
?對于第一種情況:資料加載是一種異步加載方式,原始的頁面最初不會包含某些資料,原始頁面加載完后,會再向服務器請求某個介面獲取資料,然后資料才被處理從而呈現在網頁上,這其實就是發送了一個Ajax請求(這就是JavaScript動態渲染頁面的一種情形!);
?
?對于第三種情況:資料加載是通過JavaScript和特定演算法計算后生成的,并非原始HTML代碼,這其中也并不包含Ajax請求,
- 📻📻原理知道了,下面的問題就是我們到底該如何解決呢?📻📻
|
?
| 分欄名稱 | 傳送門 |
|---|---|
| 🎐爬蟲難,跟我一起入爬蟲坑,爬蟲一條龍服務!🎐 | 《入坑Python爬蟲》 |
| 🐲Django框架難,跟我一起一條龍教學(附帶多個小型專案實戰!)🐲 | 《Django框架一條龍》 |
| 🐋Scrapy框架難,跟我一起一條龍教學(附帶多個小型專案實戰!)🐋 | 《Scrapy框架一條龍》 |
| 🐠Tornado框架難,跟我一起一條龍教學(附帶一個完整專案!)🐠 | 《Tornado框架一條龍》 |
| 🐝爬蟲——JS滲透;三大驗證碼(滑塊,點觸,圖形);字體反爬;移動端!🐝 | 《爬蟲高級一條龍》 |
- 🔩🔩本篇博文就會帶領小伙伴們全面而又細致的學習上述第二種方法——直接使用模擬瀏覽器運行的方式來解決上面所說的問題!我會盡量把技術文寫的通俗易懂/生動有趣,保證每一個想要學習知識&&認認真真讀完本文的讀者們能夠有所獲,有所得,當然,如果你讀完感覺本文寫的還可以,真正學習到了東西,希望給我個「 贊 」 和 「 收藏 」,這個對我很重要,謝謝了!🔩🔩
?
??我們偉大的Python為我們提供了許多模擬瀏覽器運行的庫,其中比較強大&&用的較多的就是Selenium,本篇博文帶領小伙伴們走入Selenium的世界!
?
🎅第一部分——初識Selenium!
?
🍏1.Selenium是什么?
| ??Selenium是一個自動化測驗工具,利用它可以驅動瀏覽器執行特定的動作,如點擊,下拉等操作,同時還可以獲取瀏覽器當前程式的頁面的源代碼,做到可見即可爬,對于一些JS動態渲染的界面來說,此種抓取方式非常有效! |
🍒2.運行環境
Selenium測驗直接運行在瀏覽器中,就好像一個真正的用戶在操作一樣, 支持大部分主流的瀏覽器,包括IE(7,8,9,10,11),Firefox,Safari,Chrome,Opera等, 我們可以利用它來模擬用戶點擊訪問網站,繞過一些復雜的認證場景 通過selenium+驅動瀏覽器這種組合可以直接渲染決議js,繞過大部分的引數構造和反爬,
🍓3.安裝
本人使用的瀏覽器是Chrome,沒有谷歌瀏覽器的小伙伴們先自行去應用市場或者官網下載哦!
1??安裝selenium庫:
直接pip安裝(一句命令&&一步到位):
pip install selenium
2??安裝ChromeDriver驅動:
(根據瀏覽器版本安裝對應的瀏覽器驅動)
步驟:
-
獲取當前瀏覽器版本(谷歌為例:幫助里面)
-
訪問下載地址 下載對應的driver版本(注意你的瀏覽器版本和driver驅動版本沒有一一對應的版本號,請前往ChromeDriver官網查看確認自己瀏覽器對應的驅動版本哦!)
-
解壓,獲取可執行檔案:
??windows為chromedriver.exe
??linux/mac為chromedriver -
chromedriver環境變數配置:
①Windows環境下,需要將chromedriver.exe所在的目錄設定為path環境變數中的路徑/直接將chromedriver.exe檔案拖到Python的Scripts目錄下(建議這樣做!);
②linux/mac環境下,將chromedriver所在的目錄設定到系統的PATH環境值中, -
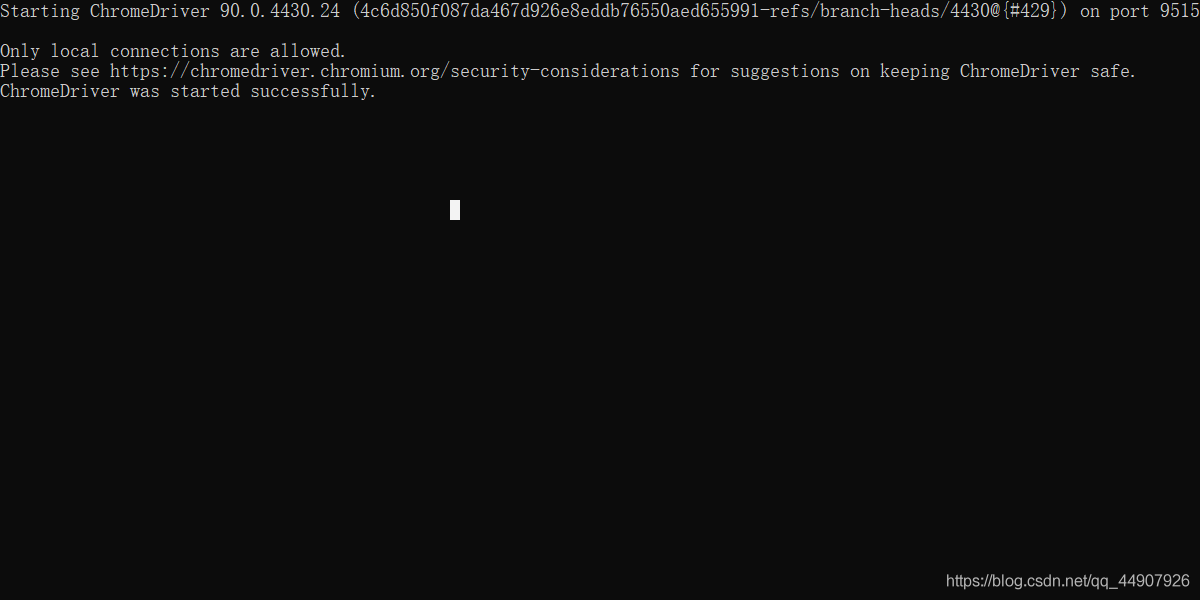
驗證安裝——CMD視窗中輸入chromedriver出現如下圖所示界面:
?
🍌4.selenium的作用和作業原理
1??作用:
- 自動化測驗,通過它我們可以寫出自動化程式,模擬瀏覽器里操作web界面, 比如點擊界面按鈕,在文本框中輸入文字 等操作,
- 獲取資訊——從web界面獲取資訊, 比如招聘網站職位資訊,財經網站股票價格資訊 等等,然后用程式進行分析處理,
- 官網地址,
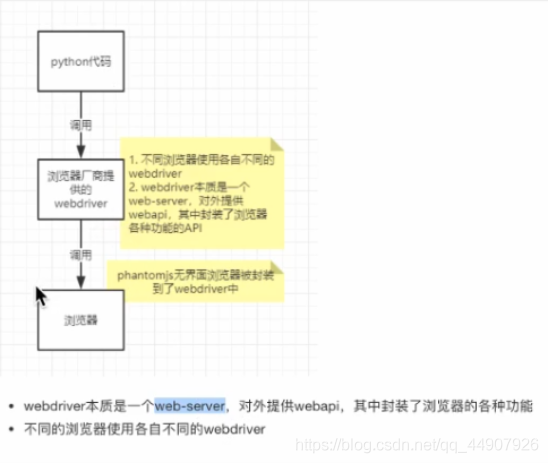
2??作業原理:
(開發使用有頭瀏覽器,部署使用無界面瀏覽器無界面瀏覽器phantomjs官方下載地址),
注意事項:
| ??新版本的Selenium已經不再支持phantomjs,原作者也已經放棄維護該專案了,還有在做爬蟲的時候盡量不要用這種方法,Selenium+瀏覽器的組合速度慢,應付不了資料量比較大的爬取以及并發爬取,并且很吃電腦資源, |
🍠5. 實戰例子 之 簡單使用:
??①上代碼:
from selenium import webdriver # 控制瀏覽器的模塊
import time # 加入睡眠,不然運行的太快了錄屏效果不行!
# 宣告瀏覽器物件——如果是火狐瀏覽器的話:driver = webdriver.Firefos()
driver = webdriver.Chrome() # 獲取chrome控制物件——webdriver物件
# 1.向一個url發起請求
driver.get('http://www.baidu.com')
time.sleep(1)
# 2.定位到搜索框標簽
input_tag = driver.find_element_by_id('kw')
# 3.往搜索框中輸入搜索內容
input_tag.send_keys('貓咪圖片')
# 4.定位到百度一下的搜索圖示
submit_tag = driver.find_element_by_id('su')
time.sleep(1)
# 5.單擊搜索圖示
submit_tag.click()
time.sleep(5)
# 6.一定要退出!不退出會有殘留行程!!!
driver.quit()
??②代碼決議:
- webdriver.Chrome() 如果沒有將驅動加入環境變數,則需要在Chrome中加入executable引數,值為下載好的chromedriver檔案路徑;
- driver.find_element_by_id(‘kw’).send_keys(‘貓咪圖片’) 定位id屬性值是‘kw’的標簽,并向其中輸入字串‘貓咪圖片’;
- driver.find_element_by_id(‘su’).click()定位id屬性值是su的標簽;
- click函式的作用是:觸發標簽的js的click事件,
??③效果展示:
[video(video-0waMWAQN-1627551355187)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=589471881)(image-https://ss.csdn.net/p?http://i1.hdslb.com/bfs/archive/711b5cd83dafb8420406009b4326213278271f9b.jpg)(title-selenium簡單使用!)]
?
🎍第二部分——Selenium進階操作!
?
🐱1.操作瀏覽器的常用騷操作:
🚩(1)騷操作及代碼實作:
| 瀏覽器操作 | 代碼 |
|---|---|
| 最大化瀏覽器 | driver.maximize_window() |
| 重繪 | driver.refresh() |
| 后退 | driver.back() |
| 前進 | driver.forward() |
| 設定瀏覽器大小 | driver.set_window_size(300,300) |
| 設定瀏覽器位置 | driver.set_window_position(300,200) |
| 關閉瀏覽器單個視窗,如果只有一個標簽頁則關閉整個瀏覽器 | driver.close() |
| 關閉瀏覽器所有視窗 | driver.quit() |
🚩(2)實戰使用:
??連續訪問三個頁面——天貓,淘寶,京東,然后呼叫back()方法回到第二個頁面——淘寶,接下來再呼叫forward()方法又可以前進到第三個頁面——京東!
??①上代碼:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.tmall.com/')
time.sleep(1)
browser.get('https://taobao.com/')
time.sleep(1)
browser.get('https://www.jd.com/')
time.sleep(1)
browser.back()
time.sleep(1)
browser.forward()
time.sleep(1)
browser.close()
??②實作效果:
[video(video-i52xcAPo-1627553947871)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=889491980)(image-https://ss.csdn.net/p?http://i0.hdslb.com/bfs/archive/1c57c21ed122a821f94a06e3b3003a7e7b9be3c4.jpg)(title-selenium操作實戰)]
?
🐹2.元素選取/查找節點:
第一種方法——find_element(s)by_…方法:
??(1)單個節點:
??在一個頁面中有很多不同的策略可以定位一個元素,我們可以選擇最合適的方法去查找元素,Selenium提供了下列的方法:
| 單個元素查找方法 | 作用 |
|---|---|
| find_element_by_xpath() | 通過Xpath查找 |
| find_element_by_class_name() | 通過class屬性查找 |
| find_element_by_id() | 通過id屬性查找 |
| find_element_by_name() | 通過name屬性進行查找 |
| find_element_by_css_selector() | 通過css選擇器查找 語法規則 |
| find_element_by_link_text() | 通過鏈接文本查找 |
| find_element_by_partial_link_text() | 通過鏈接文本的部分匹配查找 |
| find_element_by_tag_name() | 通過標簽名查找 (只有目標元素在當前html中是唯一標簽或者是眾多定位出來的標簽中的第一個的時候才使用!) |
注意:通過上述不管是哪一種方法,其回傳的節點型別都是WebElement型別!
??(2)多個節點:
| 上面方法的element加上一個s,則是對應的多個元素的查找方法, |
??如下可知其回傳內容是串列型別,串列中每個節點仍然是WebElement型別:
[<selenium.webdriver.remote.webelement.WebElement (session="73974727c0ec09e0b7d57639c3", element="1b33ea80-ba15-91ac-635903f79df2")>,
<selenium.webdriver.remote.webelement.WebElement (session="739747be09cb27c0ecd57639c3", element="1ac2f257-4364-be00-84de883b265d")>]
注意:find_element匹配不到就拋出例外,但是find_elements匹配不到回傳空串列!
第二種方法——By物件查找:
| 除了以上的多種查找方式,還有兩種私有方法集成了上面的所有的查找方法,讓我們更方便的使用! |
| 方法 | 作用 |
|---|---|
| find_element(By.XPATH, ‘//button/span’) | 通過Xpath查找一個 |
| find_elements(By.XPATH, ‘//button/span’) | 通過Xpath查找多個 |
??其中的第一個引數可以選擇使用查找的方法,By.xxx 使用xxx方式決議,決議方法如下(注意——By物件匯入: from selenium.webdriver.common.by import By):
- ID = “id” ?
- XPATH = “xpath” ?
- LINK_TEXT = “link text” ?
- PARTIAL_LINK_TEXT = “partial link text”
- ? NAME = “name” ?
- TAG_NAME = “tag name” ?
- CLASS_NAME = “class name”
- ? CSS_SELECTOR = “css selector”
?
🐸3.節點互動:
??Selenium可以驅動瀏覽器來執行一些操作,也就是說可以讓瀏覽器模擬執行一些動作,
🚀(1)常見用法:
| 方法 | 作用 |
|---|---|
| send_keys() | 輸入文字 |
| clear() | 清空文字 |
| click() | 點擊按鈕 |
| submit() | 提交表單 |
🚀(2)示例之騷操作:
# 定位用戶名
element=driver.find_element_by_id("userA")
# 輸入用戶名
element.send_keys("admin1")
# 洗掉輸入的用戶名
element.send_keys(Keys.BACK_SPACE)
# 重新輸入用戶名
element.send_keys("admin_new")
# 全選
element.send_keys(Keys.CONTROL,'a')
# 復制
element.send_keys(Keys.CONTROL,'c')
# 粘貼
driver.find_element_by_id('passwordA').send_keys(Keys.CONTROL,'v')
?
🐻4.動作鏈:
👑(1)講解:
-
在selenium當中除了簡單的點擊動作外,還有一些稍微復雜的動作,就需要用到ActionChains(動作鏈)這個子模塊來滿足我們的需求,
-
ActionChains可以完成復雜一點的頁面互動行為,例如元素的拖拽,滑鼠移動,懸停行為,內容選單互動, 它的執行原理就是當呼叫ActionChains方法的時候不會立即執行,而是將所有的操作暫時儲存在一個佇列中,當呼叫perform()方法的時候,會按照佇列中放入的先后順序執行前面的操作,
-
匯入ActionChains包:
from selenium.webdriver.common.action_chains import ActionChains
👑(2)方法:
| ActionChains提供的方法 | 作用 |
|---|---|
| click(on_element=None) | 滑鼠左鍵單擊傳入的元素 |
| double_click(on_element=None) | 雙擊滑鼠左鍵 |
| context_click(on_element=None) | 點擊滑鼠右鍵 |
| click_and_hold(on_element=None) | 點擊滑鼠左鍵,按住不放 |
| release(on_element=None) | 在某個元素位置松開滑鼠左鍵 |
| drag_and_drop(source, target) | 拖拽到某個元素然后松開 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽到某個坐標然后松開 |
| move_to_element(to_element) | 滑鼠移動到某個元素 |
| move_by_offset(xoffset, yoffset) | 移動滑鼠到指定的x,y位置 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 將滑鼠移動到距某個元素多少距離的位置 |
| perform() | 執行鏈中的所有動作 |
👑(3)示例:
示例:
1. 導包:from selenium.webdriver.common.action_chains import ActionChains
2. 實體化ActionChains物件:Action=ActionChains(driver)
3. 呼叫右鍵方法:element=Action.context_click(username)
4. 執行:element.perform()
?
🐮5.提取節點文本內容和屬性值:
??(1)獲取文本內容:
- element.text
??通過定位獲取的標簽物件的 text 屬性,獲取文本內容,
??(2)獲取屬性值:
- element.get_attribute(‘屬性名’)
??通過定位獲取的標簽物件的 get_attribute()函式,傳入屬性名,來獲取屬性的值,
🐒6.執行JavaScript代碼:
| ??對于某些操作:Selenium是沒有提供相關的API的,比如:往下滑動頁面,但是Selenium偉大的創造者給了我們另一個更為方便的方法——它可以直接模擬運行JavaScript,使用execute_script()方法即可! |
??實戰演示:
📌①上代碼:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E6%96%87%E5%BA%93/4928294?fr=aladdin')
# 執行JS代碼,滑動網頁至最底部!
js = 'window.scrollTo(0, document.body.scrollHeight)'
browser.execute_script(js)
# 執行JS代碼,彈窗提示文字!
browser.execute_script('alert("到達最底部啦!")')
time.sleep(3)
📌②效果展示:
[video(video-XVDEByxw-1627557637531)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=546960307)(image-https://ss.csdn.net/p?http://i0.hdslb.com/bfs/archive/f2d201f5b3794f04d997681e882a444abb96a5f9.jpg)(title-滑動)]
?
🐫7.標簽頁/視窗的切換:
💊(1)方法:
??用selenium操作瀏覽器如果需要再打開新的頁面,這個時候會有問題,因為我們用selenium操作的是第一個打開的視窗,所以新打開的頁面我們是無法去操作的,所以我們要用到切換視窗——即handle切換的方法!
| 方法 | 作用 |
|---|---|
| js = 'window.open(“https://www.baidu.com”);'chrome.execute_script(js) | 打開新標簽 |
| window_handles | 獲取所有頁面視窗的句柄 |
| current_window_handle | 獲取當前頁面視窗的句柄 |
| switch_to.window(window_name) | 定位頁面轉到指定的window_name頁面 |
注意:Window_handles的順序并不是瀏覽器上標簽的順序,盡量避免多標簽操作!
💊(2)實戰演示:
🔆①思路決議:
視窗切換:
首先要獲取所有標簽頁的視窗句柄;
然后利用視窗句柄切換到句柄指向的標簽頁,
視窗句柄:指的是指向標簽頁物件的標識!
決議:
#1.獲取當前所有的標簽頁的句柄構成的串列
current_windows = driver.window_handles
#2.根據標簽頁句柄串列索引下標進行切換
driver.switch_to.window(windows[0])
🔆②上代碼:
import time
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
time.sleep(1)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)
# 通過執行js來新開一個標簽頁
js = "window.open('https://www.sougou.com');"
driver.execute_script(js)
time.sleep(1)
# 1.獲取當前所有的視窗
windows = driver.window_handles
time.sleep(2)
# 2.根據視窗索引進行切換
driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])
time.sleep(6)
driver.quit()
🔆③效果展示:
[video(video-f7hFykeq-1627557936718)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=334461229)(image-https://ss.csdn.net/p?http://i0.hdslb.com/bfs/archive/01e4dd81c451599fdfd654d8785bd81072eb06ff.jpg)(title-視窗切換)]
?
🏃8.實戰——Selenium過滑塊驗證碼:
點擊我觀看博文詳解!
🔮第三部分——In The End!

| 從現在做起,堅持下去,一天進步一小點,不久的將來,你會感謝曾經努力的你! |
?本博主會持續更新爬蟲基礎分欄及爬蟲實戰分欄,認真仔細看完本文的小伙伴們,可以點贊收藏并評論出你們的讀后感,并可關注本博主,在今后的日子里閱讀更多爬蟲文!
如有錯誤或者言語不恰當的地方可在評論區指出,謝謝!
如轉載此文請聯系我征得本人同意,并標注出處及本博主名,謝謝 !
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292184.html
標籤:python
下一篇:Python 的內建函式