七夕將至,Python爬蟲分析告訴你到底要送女朋友/男朋友什么禮物
- 前言
- 程式說明
- 資料爬取
- 🕸? 網址構成分析
- 🕸? 網頁結構分析
- 🕸? 將資料寫入csv檔案中
- 🕸? 通過觀察頁面鏈接,爬取更多頁面
- 🕸? 爬蟲程式完整代碼
- 🕸? 爬取資料結果
- 資料分析及可視化
- 🎁 七夕禮物清單
- 👧 送女朋友禮物清單
- 👦 送男朋友禮物清單
- 下一步計劃
- 寫在最后
前言
“牛郎織女”的在七夕相會的美麗愛情傳說,使七夕成為了象征愛情的節日,同時也被認為是中國最具浪漫色彩的傳統節日,在當代更是成為了“中國情人節”的文化符號,
隨著七夕的臨近,很多小伙伴都開始籌備送女朋友/男朋友的禮物了,禮物作為一種傳達情感的媒介,表達了對于女朋友/男朋友的祝福和心意,但同時對于要送什么禮物,對于很多小伙伴來講倒是選擇困難,本文利用 Python 爬取某寶商品頁面,為小伙伴們分析銷量較高的禮物清單,以供大家參考,
(本文無任何廣告行為,僅作為學習分析使用,如侵刪,)
程式說明
根據不同關鍵字,爬取“某寶”獲取商品資訊(以“七夕禮物”、“七夕禮物送男友”、“七夕禮物送女友”等為例),根據所獲取資料分析得到七夕禮物清單,并通過詞云可視化的方式展示不同禮物的頻率比重對比,
資料爬取
🕸? 網址構成分析
爬蟲少不了網址,因此首先觀察網址的構成,在輸入關鍵字“七夕禮物”進行搜索時,發現網址中 q 的引數值即為所鍵入的關鍵字“七夕禮物”,如下圖所示:
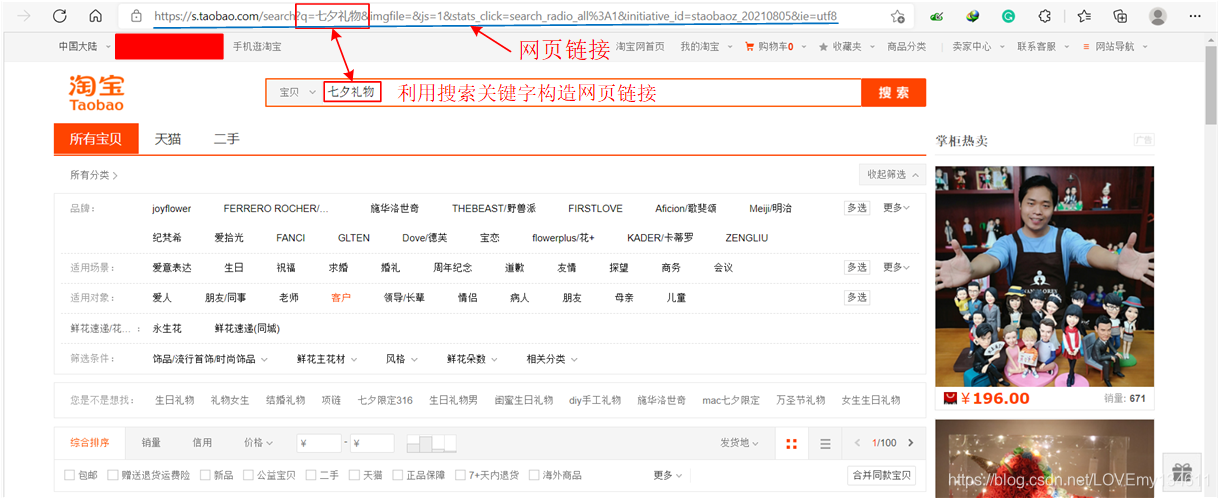
因此可以使用以下方式構造網址:
q_value = "七夕禮物"
url = "https://s.taobao.com/search?q={}imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210802&ie=utf8&bcoffset=5&p4ppushleft=2%2C48&ntoffset=5&s=44".format(q_value)
雖然也可以直接復制網址,但是這種方法的弊端在于,每次想要爬取其他類別的商品時,都需要重新打開網頁復制網址;而利用 q_value 變數構造網址,當需要獲取其他品類商品時僅需要修改 q_value 變數,例如要爬取關鍵字“七夕禮物送男友”,只需要做如下修改:
q_value = "七夕禮物送男友"
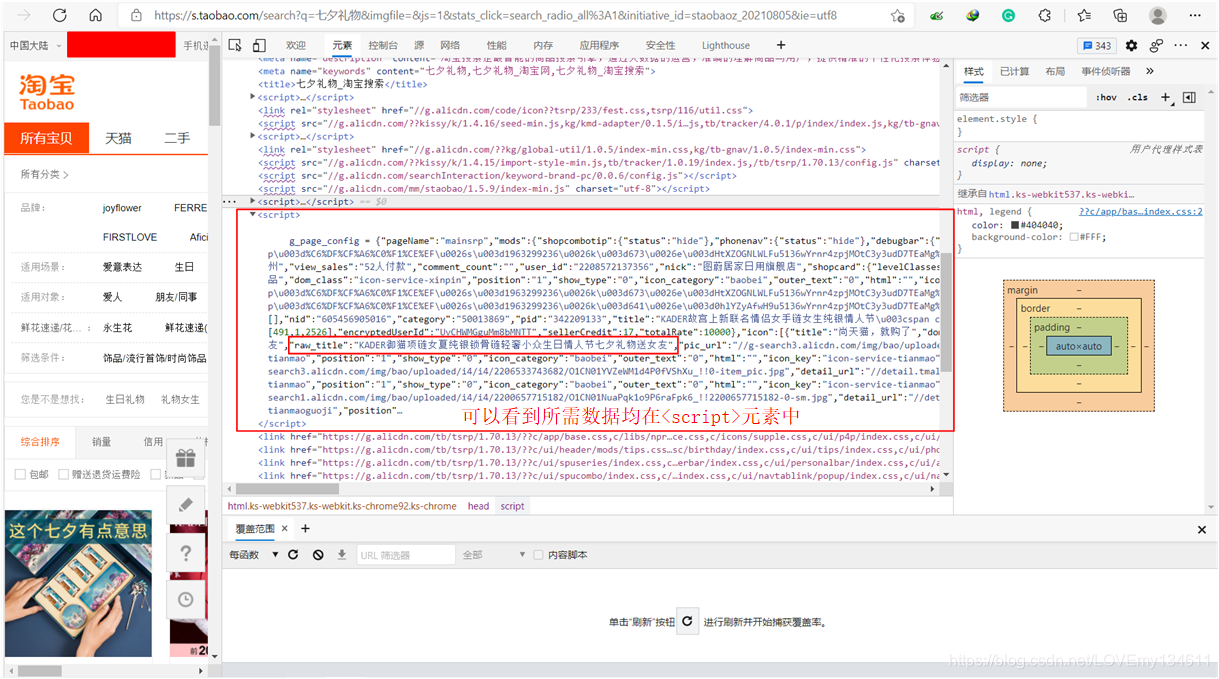
🕸? 網頁結構分析
使用瀏覽器“開發者工具”,觀察網頁結構,可以看出商品的資訊都是在 <script> 中,
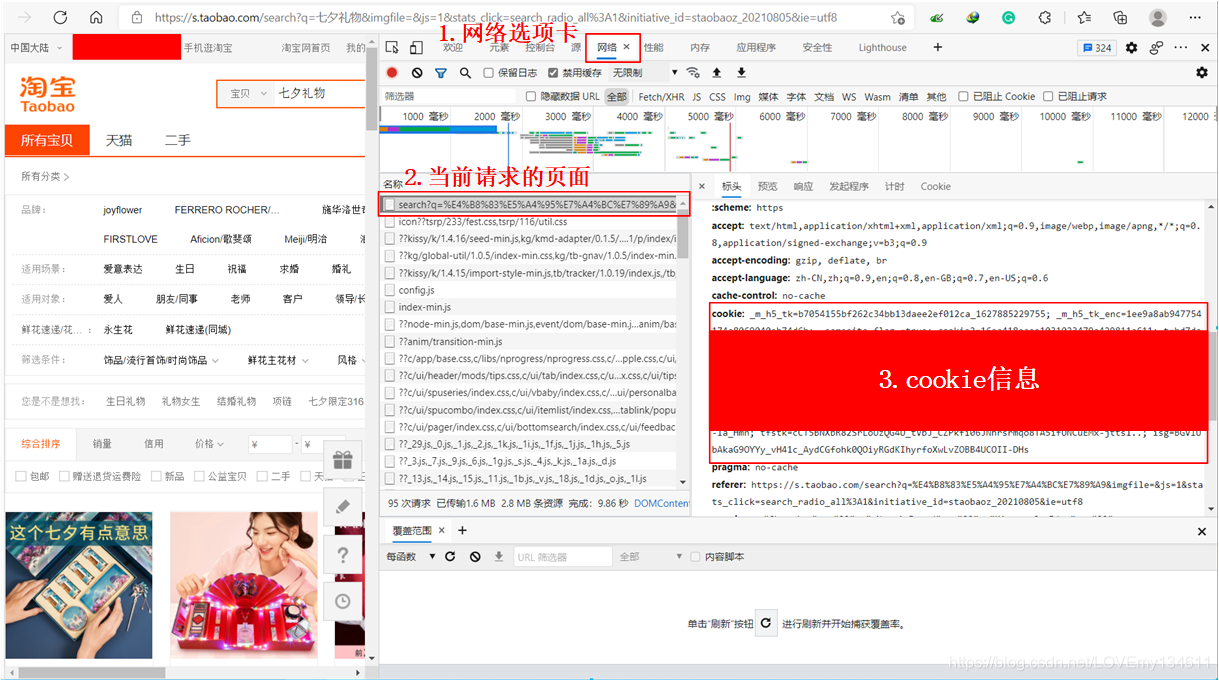
因此,首先使用 requests 庫請求網頁內容,需要注意的是,在請求頁面資訊時,需要構造請求頭中的 cookie 和 user-agent 資訊,否則并不會得到有效回應,獲取 cookie 和 user-agent 資訊需要在瀏覽器“開發者工具”中的網路標簽下單擊當前請求頁面(如果網路標簽下沒有當前請求的頁面,需要重繪后才可以顯示),在標頭選項卡中找到請求標頭的 cookie 和 user-agent 值并復制,按照以下方式構造請求頭:
headers = {
# 將user-agent值,替換為剛剛復制的user-agent值
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62",
# 將cookie值,替換為剛剛復制的cookie值
"cookie":"...JSESSIONID=4990DB1E8783DF90266F5159209F8E3A"
}
下圖顯示了獲取 cookie 值的示例(獲取 user-agent 值的方式類似,只需在標頭選項卡中找到請求標頭的 user-agent 值):
得到回應網頁后,需要使用 BeautifulSoup4 與正則表達庫 re 決議網頁,獲取商品資訊:
import re
import requests
from bs4 import BeautifulSoup
# 請求網頁
response = requests.get(url,headers =headers)
response.raise_for_status()
response.encoding = 'utf-8'
# 決議網頁
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('script')
information = str(results[7])
# 獲取商品標題
raw_title = re.findall(r'"raw_title":"(.*?)"', information)
# 獲取商品價格
view_price = re.findall(r'"view_price":"(.*?)"', information)
# 獲取購買人數
view_sales = re.findall(r'"view_sales":"(.*?)"', information)
# 獲取發貨地址
item_loc = re.findall(r'"item_loc":"(.*?)"', information)
# 獲取店鋪名
nick = re.findall(r'"nick":"(.*?)"', information)
# 獲取詳情頁地址
detail_url = re.findall(r'"detail_url":"(.*?)"', information)
# 獲取封面圖片地址
pic_url = re.findall(r'"pic_url":"(.*?)"', information)
需要注意的是,由于一開始使用 utf-8 方式解碼網頁,并不能解碼 Unicode,因此列印詳情頁地址和封面圖片地址會看到解碼不正確的情況:
print(detail_url[4])
# //detail.tmall.com/item.htm?id\u003d628777347316\u0026ns\u003d1\u0026abbucket\u003d17
因此需要使用以下方式進行正確解碼:
decodeunichars = detail_url[4].encode('utf-8').decode('unicode-escape')
print(decodeunichars)
# //detail.tmall.com/item.htm?id=628777347316&ns=1&abbucket=17
🕸? 將資料寫入csv檔案中
為了將資料寫入 csv 檔案中,首先創建 csv 檔案并寫入標頭:
#創建存盤csv檔案存盤資料
file = open('gift.csv', "w", encoding="utf-8-sig",newline='')
csv_head = csv.writer(file)
#表頭
header = ['raw_title','view_price','view_sales','salary','item_loc','nick','detail_url','pic_url']
csv_head.writerow(header)
file.close()
然后,由于英文逗號(",")表示單元格的切換,因此需要將獲取的資料經過預處理:
def precess(item):
return item.replace(',', ' ')
最后將預處理資料后,將資料寫入 csv 檔案中:
for i in range(len(raw_title)):
with open('gift.csv', 'a+', encoding='utf-8-sig') as f:
f.write(precess(raw_title[i]) + ','
+ precess(view_price[i]) + ','
+ precess(view_sales[i]) + ','
+ precess(item_loc[i]) +','
+ precess(nick[i]) + ','
+ precess(detail_url[i]) + ','
+ precess(pic_url[i]) + '\n')
🕸? 通過觀察頁面鏈接,爬取更多頁面
通過查看第2頁以及第3頁,網址:
https://s.taobao.com/search?q=七夕禮物imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210805&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s=44
https://s.taobao.com/search?q=七夕禮物&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210805&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s=88
可以看到,網址的不同僅在于第二頁的 s 的引數值為 44,而第三頁 s 的引數值為 88,結合可以每頁有 44 個商品,因此可以使用以下方式構造爬取20頁商品:
url_pattern = "https://s.taobao.com/search?q={}&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210805&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s={}"
for i in range(20):
url = url_pattern.format(q, i*44)
🕸? 爬蟲程式完整代碼
import re
import requests
import time
from bs4 import BeautifulSoup
import csv
import os
q = "七夕禮物"
url_pattern = "https://s.taobao.com/search?q={}&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210805&ie=utf8&bcoffset=2&ntoffset=2&p4ppushleft=2%2C48&s={}"
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62",
# cookie值替換為使用上述方式獲取的cookie值
"cookie":"..."
}
def analysis(item,results):
pattern = re.compile(item, re.I|re.M)
result_list = pattern.findall(results)
return result_list
def analysis_url(item, results):
pattern = re.compile(item, re.I|re.M)
result_list = pattern.findall(results)
for i in range(len(result_list)):
result_list[i] = result_list[i].encode('utf-8').decode('unicode-escape')
return result_list
def precess(item):
return item.replace(',', ' ')
# 創建csv檔案
if not os.path.exists("gift.csv"):
file = open('gift.csv', "w", encoding="utf-8-sig",newline='')
csv_head = csv.writer(file)
#表頭
header = ['raw_title','view_price','view_sales','salary','item_loc','nick','detail_url','pic_url']
csv_head.writerow(header)
file.close()
for i in range(100):
#增加時延防止反爬蟲
time.sleep(25)
url = url_pattern.format(q, i*44)
response = requests.get(url=url, headers=headers)
#宣告網頁編碼方式,需要根據具體網頁回應情況
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('script')
information = str(results[7])
# 獲取所有的商品資訊,由于有些購買人數為空白,導致回傳空值,因此添加例外處理
all_goods = analysis(r'"raw_title":"(.*?)"shopLink"', information)
for good in all_goods:
# 獲取商品標題
raw_title = analysis(r'(.*?)","pic_url"', good)
if not raw_title:
raw_title.append('未命名')
# 獲取商品價格
view_price = analysis(r'"view_price":"(.*?)"', good)
if not view_price:
view_price.append('0.00')
# 獲取購買人數,由于有些購買人數為空白,導致回傳空值,因此添加例外處理
view_sales = analysis(r'"view_sales":"(.*?)"', good)
#print(view_sales)
if not view_sales:
view_sales.append('0人付款')
# 獲取發貨地址
item_loc = analysis(r'"item_loc":"(.*?)"', good)
if not item_loc:
item_loc.append('未知地址')
# 獲取店鋪名
nick = analysis(r'"nick":"(.*?)"', good)
if not nick:
nick.append('未知店鋪')
# 獲取詳情頁地址
detail_url = analysis_url(r'"detail_url":"(.*?)"', good)
if not detail_url:
detail_url.append('無詳情頁')
# 獲取封面圖片地址
pic_url = analysis_url(r'"pic_url":"(.*?)"', good)
if not pic_url:
pic_url.append('無封面')
with open('gift.csv', 'a+', encoding='utf-8-sig') as f:
f.write(precess(raw_title[0]) + ','
+ precess(view_price[0]) + ','
+ precess(view_sales[0]) + ','
+ precess(item_loc[0]) +','
+ precess(nick[0]) + ','
+ precess(detail_url[0]) + ','
+ precess(pic_url[0]) + '\n')
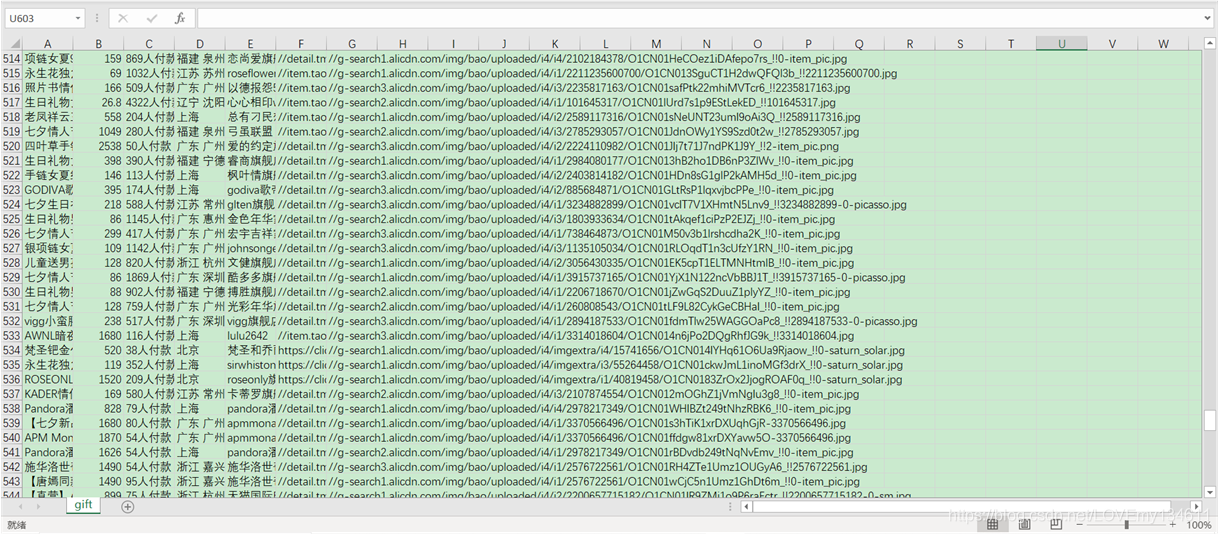
🕸? 爬取資料結果
資料分析及可視化
可能很多朋友(并非)是為了學習技術才點擊進來的,完(shun)全(bian)是求知若渴的想知道要送男朋友/女朋友什么禮物,別著急,大家最關注的部分來了,
接下來使用詞云可視化分析,分別考慮包含銷量與不包含銷量兩種情況,
🎁 七夕禮物清單
不考慮銷量時:
from os import path
from PIL import Image
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, STOPWORDS
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
import math
import re
df = pd.read_csv('gift.csv', encoding='utf-8-sig',usecols=['raw_title','view_price','view_sales','salary','item_loc','nick','detail_url','pic_url'])
raw_title_list = df['raw_title'].values
raw_title = ','.join(raw_title_list)
with open('text.txt','a+') as f:
f.writelines(raw_title)
###當前檔案路徑
d = path.dirname(__file__)
# Read the whole text.
file = open(path.join(d, 'text.txt')).read()
##進行分詞
#停用詞,去除修飾性的詞
stopwords = ["七夕","七夕情人節","情人節","男友","女友","男生","女生","女朋友","男朋友","禮物","生日禮物","創意","實用","朋友","男士","老婆","老公","直營","閨蜜","結婚","送給"]
text_split = jieba.cut(file) # 未去掉停用詞的分詞結果 list型別
#去掉停用詞的分詞結果 list型別
text_split_no = []
for word in text_split:
if word not in stopwords:
text_split_no.append(word)
#print(text_split_no)
text =' '.join(text_split_no)
#背景圖片
picture_mask = np.array(Image.open(path.join(d, "beijing.jpg")))
stopwords = set(STOPWORDS)
stopwords.add("said")
wc = WordCloud(
#設定字體,指定字體路徑
font_path=r'C:\Windows\Fonts\simsun.ttc',
background_color="white",
max_words=4000,
mask=picture_mask,
stopwords=stopwords)
# 生成詞云
wc.generate(text)
# 存盤圖片
wc.to_file(path.join(d, "result.jpg"))

接下來考慮銷量:
def get_sales(item):
tmp = item[:-3]
if '萬' in tmp:
tmp = tmp.replace('萬','0000').replace('.','')
if '+' in tmp:
tmp = tmp.replace('+','')
tmp = int(tmp)
tmp = tmp / 100.0
if tmp <= 0:
tmp = 0
tmp = round(tmp)
return tmp
raw_title_list = df['raw_title'].values
view_sales_list = df['view_sales'].values
for i in range(len(raw_title_list)):
for j in range(get_sales(view_sales_list[i])):
with open('text.txt','a+') as f:
f.writelines(raw_title_list[i]+',')
# 其余代碼不再贅述
"""
...
"""

可以看到差別還是較為明顯的,最后將分詞結果,進行排序,手動去除無效詞后,歸類整理出排名前15的禮物清單:
gift = {}
for i in text_split_no:
if gift.get(i,0):
gift[i] += 1
else:
gift[i] = 1
sorted_gift = sorted(gift.items(), key=lambda x:x[1],reverse=True)
??禮物清單??
玩偶/公仔/毛絨玩具/抱抱熊
糖果
項鏈
巧克力
相冊/紀念冊
零食/小吃
手鏈/手鐲/鐲子
玫瑰
吊墜
小夜燈
音樂盒/八音盒
戒指/對戒
口紅
手繩/紅繩
耳釘
👧 送女朋友禮物清單
以同樣的方法,將關鍵字改為“女友+禮物”,可以得到??送女朋友禮物清單??:
小夜燈
相冊/紀念冊/相框
刻字類禮物
八音盒
項鏈/手鏈/手鐲/鐲子
口紅
手表
包
水晶鞋
玩偶
👦 送男朋友禮物清單
最后,將關鍵字改為“男友+禮物”,可以得到??送男朋友禮物清單??:
可樂刻字
相冊/紀念冊/相框
花束
手辦
擺件
鑰匙扣
木刻畫
情書
刺繡
籃球
可以看出,送女朋友和男朋友的禮物還是有一些差別的,
當然,和主管感覺上有很些差異的原因可能在于,很多商品的標題太過創意,完全不包含商品,
下一步計劃
下一步的作業包括:
- 獲取商品的評價資訊,將購買者的評論資訊也融合到計算權重中去,根據購買者的評價對商品排序進行修正,例如可能去除一些華而不實的“智商稅”產品,同時可能得到一些小眾好評的商品,
- 利用深度學習相關技術,識別圖片中商品,用以解決一些商品標題及商品圖片文字中完全不包含商品名的情況,讓我們明白標題為《生日禮物女生七夕情人節給閨蜜送女友朋友送給女孩的實用小高級感》的商品到底賣的是什么?
寫在最后
當然,本文僅做分析之用,結果也僅供參考,如果清單里沒有令你心儀的禮物,也可以選擇紅包或者清空購物車的方式,無論送女朋友/男朋友什么禮物,傳達自己的??心意??最重要了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292356.html
標籤:python