1.一個簡單的Java程式
public class Test {
public static void main(String[] args) {
System.out.println("==============args start============");
for (int i = 0; i < args.length; i++) {
System.out.println(args[i]);
}
System.out.println("==============args end============");
System.out.println("args: " + args);
}
}
在Java語言中,規定了入口函式是一個main()方法,該方法有一個String[]型別的引數,但是在很多時候,很多人都使用不上這個引數,也不關心為什么要寫這個引數,
那么這個字串陣列型別的引數究竟是什么東西呢?
其實很簡單,main()方法中的字串陣列型別的引數就是java命令的引數,使用java命令的方式運行main()方法,會將java命令的引數入參到Java main()方法的字串陣列引數中,
我們通過以下方式來驗證:
- 先撰寫一個Hello.java檔案,檔案內容如下:
public class Test {
public static void main(String[] args) {
System.out.println("==============args start============");
for (int i = 0; i < args.length; i++) {
System.out.println(args[i]);
}
System.out.println("==============args end============");
System.out.println("args: " + args);
}
}
- 在
Test.java檔案的路徑下打開cmd命令提示符,運行javac -encoding utf-8 Test.java命令編譯該檔案,這將會在對應的檔案路徑下,得到一
個Test.class位元組碼檔案,
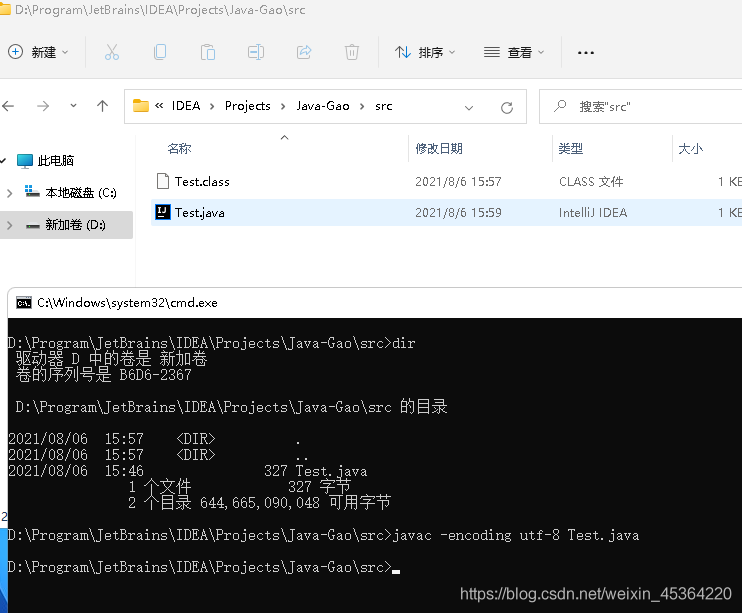
當檔案中出現中文的時候,比如輸出的內容有漢字的時候需要使用utf-8編碼,加上了編碼格式,保證后續命令列編譯輸出沒有亂碼情況
- 使用
java Test命令運行Test.class檔案,我們將會得到如下的運行結果:

- 我們這次在java命令后面添加一些引數,這些引數我們可以自己定義,
例如:java Test a b c d我們將會得到如下的運行結果:
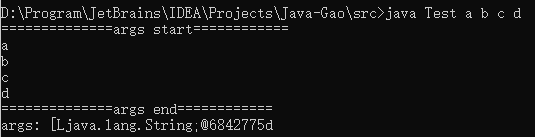
正是因為Java main()方法的這個擴展性,使得每一個開發者,可以通過自己定義一些Java命令的引數,實作一些不同的功能,
2.注釋
2.1 普通注釋
這些注釋用一個 “/*” 起頭,隨后是注釋內容,并可跨越多行,最后用一個“/”結束
/* 這是
*一段注釋,
* 它跨越了多個行
*/
進行編譯時,/ 和 / 之間的所有東西都會被忽略,所以上述注釋與下面這段注釋并沒
有什么不同
/* 這是一段注釋,
它跨越了多個行 */
// 這是一條單行注釋
2.2 嵌入檔案
用于提取注釋的工具叫作 javadoc,它采用了部分來自Java編譯器的技術,查找我們置入程式
的特殊注釋標記,它不僅提取由這些標記指示的資訊,也將毗鄰注釋的類名或方法名提取出
來,這樣一來,我們就可用最輕的作業量,生成十分專業的程式檔案,
所有javadoc命令都只能出現于 /** 注釋中,但和平常一樣,注釋結束于一個 */ ,主
要通過兩種方式來使用javadoc:嵌入的HTML,或使用“檔案標記”,其中,“檔案標記”(Doc
tags)是一些以“@”開頭的命令,置于注釋行的起始處(但前導的*會被忽略)
/** 一個類注釋 /
public class docTest {
/* 一個變數注釋 /
public int i;
/* 一個方法注釋 */
public void f() {}
}
嵌入HTML
/**
* <pre>
* System.out.println(new Date());
* </pre>
*/
/**
* 您甚至可以插入一個串列:
*\
* <li> 專案一
* <li> 專案二
* <li> 專案三
* </ol>
*/
參考其它類
@see 類名
@see 完整類名
@see 完整類名#方法名
類檔案標記
@version 版本資訊
@author 作者資訊
變數檔案標記
變數檔案只能包括嵌入的HTML以及@see參考
方法檔案標記
. @param 格式如下: @param 引數名 說明 其中,“引數名”是指引數串列內的識別符號,
而“說明”代表一些可延續到后續行內的說明文字,一旦遇到一個新檔案標記,就認為前一個說
明結束,可使用任意數量的說明,每個引數一個,
@return 說明
@exception 完整類名 說明【它們是一些特殊的對
象,若某個方法失敗,就可將它們“扔出”物件】
注意javadoc只能為 public(公共)和 protected(受保護)成員處理注釋檔案,“private”(私
有)和“友好”成員的注釋會被忽略,我們看不到任何輸出(也可以用-private標記
包括private成員),因為只有public和protected成員才可在檔案之外使
用,
3. 編碼樣式
- 一個非正式的Java編程標準是大寫一個類名的首字母,若類名由幾個單詞構成,那么把它們
緊靠到一起(也就是說,不要用下劃線來分隔名字),此外,每個嵌入單詞的首字母都采用
大寫形式 - 對于其他幾乎所有內容:方法、欄位(成員變數)以及物件句柄名稱,可接受的樣式與類樣
式差不多,只是識別符號的第一個字母采用小寫,
舉例:
class AllTheColorsOfTheRainbow {
int anIntegerRepresentingColors;
void changeTheHueOfTheColor(int newHue) {
// ...
}
// ...
}
4.基礎資料型別【口訣:4類8種】
4.1 整型

在 C 和 C++ 中, int 和 long 等型別的大小與目標平臺相關,在 8086 這樣的16 位處理器上整型數值占 2 位元組;不過, 在 32 位處理器上,整型數值則為 4 位元組, 類似地, 在 32 位處理器上 long 值為 4 位元組, 在 64 位處理器上則為 8 位元組,由于存在這些差別, 這對撰寫跨平臺程式帶來了很大難度, 在 Java 中, 所有的數值型別所占據的位元組數量與平臺無關,
注意, Java 沒有任何無符號(unsigned) 形式的 int、 long、short 或 byte 型別,
在通常情況下,int 型別最常用,但如果表示星球上的居住人數, 就需要使用 long 型別 了,byte 和 short
型別主要用于特定的應用場合,例如,底層的檔案處理或者需要控制占用 存盤空間量的大陣列,
長整型數值有一個后綴 L 或 1 ( 如 4000000000L,) 十六進制數值有一個前綴 Ox 或 0X (如 OxCAFEL
八進制有一個前綴 0 , 例如, 010 對應八進制中的 8,很顯然, 八進制表示法比較容易混淆, 所以建議最好不要使用八進制常數
從 Java 7 開始, 加上前綴 0b 或 0B 就可以寫二進制數,例如,OblOO丨就是 9, 另外,同樣是從 Java 7
開始,還可以為數字字面量加下劃線,如用 1_000_000(或0b1111 0100 0010 0010 0000)表示一百萬,這些下劃線只是為了讓人更易讀,Java 編譯器會去除這些下劃線
4.2 浮點型

double 表示這種型別的數值精度是 float 型別的兩倍(有人稱之為雙精度數值),絕大部 分應用程式都采用 double型別,在很多情況下,float 型別的精度很難滿足需求,實際上,只 有很少的情況適合使用 float 型別,例如,需要單精度資料的庫,或者需要存盤大量資料, float 型別的數值有一個后綴 F 或 f (例如,3.14F,) 沒有后綴 F 的浮點數值(如 3.14 ) 默認為 double 型別,當然,也可以在浮點數值后面添加后綴 D 或 d (例如,3.14D) ,
浮點數值不適用于無法接受舍入誤差的金融計算中, 例如,命令 System.out.println( 2.0-1.1 ) 將列印出 0.8999999999999999, 而不是人們想象的 0.9,這種舍入誤差的主要原因是浮點數值采用二進制系統表示, 而在二進制系統中無法精確地表示分數 1/10,這就好像十進制無法精確地表示分數 1/3—樣,如果在數值計算中不允許有任何舍入誤差,就應該使用 BigDecimal類
4.3 char 型別
char 型別原本要用單引號括起來于表示單個字符,不過,現在情況已經有所變化, 如今,有些 Unicode 字符可以用一個 char 值描述,另外一些 Unicode 字符則需要兩個 char 值,char 型別的值可以表示為十六進制值,其范圍從 \u0000 到 \Uffff,例如:W2122 表示注冊符號 (? ), \u03C0 表示希臘字母 Π
Unicode 轉義序列會在決議代碼之前得到處理, 例如,"\u0022+\u0022”并不是一個由引號(U+0022)包圍加號構成的字串, 實際上, \u0022 會在決議之前轉換為 ", 這會 得 到 也 就 是 一 個 空 串,更隱秘地,一定要當心注釋中的 \u, 注釋
// \u00A0 is a newline會產生一個語法錯誤, 因為讀程式時\u00A0會替換為一個換行符類似地,下面這個注釋// Look inside c:\users也會產生一個語法錯誤, 因為 \u> 后面并未跟著 4 個十六進制數

要想弄清 char 型別, 就必須了解 Unicode 編碼機制,Unicode 打破了傳統字符編碼機制
的限制,
歷史原因:在 Unicode 出現之前, 已經有許多種不同的標準:美國的 ASCII、 西歐語言中的ISO 8859-1 俄羅斯的 KOI-8、 中國的 GB 18030 和 BIG-5 等,這樣就產生了下面兩個問題:一個是對于任意給定的代碼值,在不同的編碼方案下有可能對應不同的字母;二是采用大字符集的語言其編碼長度有可能同,例如,有些常用的字符采用單位元組編碼, 而另一些字符則需要兩個或更多個位元組,
改進:在設計 Java 時決定采用 16 位的 Unicode 字符集,這樣會比使用 8 位字符集的程式設計語言有很大的改進,十分遺憾, 經過一段時間, 不可避免的事情發生了,Unicode 字符超過了 65 536 個,其主要原因是增加了大量的漢語、 日語和韓語中的表意文字,現在,16 位的 char 型別已經不能滿足描述所有 Unicode 字符的需要了,
以下是維基百科內容:
16位的 cha r如何描述所有 Unicode 字符
從 Java SE 5.0 開始,碼點( code point) 是指與一個編碼表中的某個字符對應的代碼值,在 Unicode標準中,碼點采用十六進制書寫,并加上前綴 U+, 例如 U+0041 就是拉丁字母 A 的碼點,Unicode 的碼點可以分成 17個代碼級別( codeplane),第一個代碼級別稱為基本的多語言級別( basicmultilingual plane ), 碼點從U+0000 到U+FFFF, 其中包括經典的 Unicode 代碼;其余的 16個級另丨〗碼點從 U+10000 到 U+10FFFF ,其中包括一些輔助字符(supplementary character),UTF-16 編碼采用不同長度的編碼表示所有 Unicode碼點,在基本的多語言級別中,每個字符用 16 位表示,通常被稱為代碼單元( code unit); 而輔助字符采用一對連續的代碼單元進行編碼,這樣構成的編碼值落人基本的多語言級別中空閑的 2048 位元組內,通常被稱為替代區域(surrogate area) [ U+D800 ~ U+DBFF 用于第一個代碼單兀,U+DC00 ~ U+DFFF用于第二個代碼單元,這樣設計十分巧妙,我們可以從中迅速地知道一個代碼單元是一個字符的編碼,還是一個輔助字符的第一或第二部分,例如,?是八元數(http://math.ucr.edu/home/baez/octonions) 的一個數學符號,碼點為 U+1D546, 編碼為兩個代碼單兀 U+D835 和U+DD46,(關于編碼演算法的具體描述見http://en.wikipedia.org/wiki/UTF-l6 )
強烈建議不要在程式中使用 char 型別,除非確實需要處理 UTF-16 代碼單元,最好 將字串作為抽象資料型別處理
4.4 boolean 型別
boolean (布爾)型別有兩個值:false 和 true, 用來判定邏輯條件 整型值和布林值之間
不能進行相互轉換,
在 C++ 中, 數值甚至指標可以代替 boolean 值,值 0 相當于布林值 false, 非 0 值相當于布林值 true, 在
Java 中則不是這樣,, 因此, Java 程式員不會遇到下述麻煩:
if (x = 0) // oops… meant x = 0
在 C++ 中這個測驗可以編譯運行, 其結果總是 false: 而在 Java 中, 這個測驗將不 能通過編譯, 其原因是整數運算式 x = 0 不能轉換為布林值,
5.變數
5.1 可以在一行中宣告多個變數:
不能使用 Java 保留字作為變數名
int i , j; // both are integers
5.2 變數初始化
宣告一個變數之后,必須用賦值陳述句對變數進行顯式初始化, 千萬不要使用未初始化的
變數,例如, Java 編譯器認為下面的陳述句序列是錯誤的
int vacationDays;
System.out.println(vacationDays): // ERROR variable not initialized
C 和 C++ 區分變數的宣告與定義,例如:
int i = 10; 是一個定義
而 extern int i; 是一個宣告,
在 Java中, 不區分變數的宣告與定義,
5.3 常量
在 Java 中, 利用關鍵字 final 指示常量,例如:
public class Test {
public static void main(String[] args) {
final double CM_PER_INCH = 2.54;
double paperWidth = 8.5;
double paperHeight = 11;
System.out.println("Paper size in centimeters: "
+ paperWidth * CM_PER_INCH + "by" + paperHeight * CM_PER_INCH);
}
}
//Paper size in centimeters: 21.59by27.94
在 Java 中,經常希望某個常量可以在一個類中的多個方法中使用,通常將這些常量稱為
類常量,可以使用關鍵字 static fina丨設定一個類常量, 下面是使用類常量的示例:
public class Test {
public static final double CM_PER_INCH2 = 2.54;
public static void main(String[] args) {
double paperWidth = 8.5;
double paperHeight = 11;
System.out.println("Paper size in centimeters: "
+ paperWidth * CM_PER_INCH2 + "by" + paperHeight * CM_PER_INCH2);
}
}
//Paper size in centimeters: 21.59by27.94
需要注意, 類常量的定義位于 maiii 方法的外部,因此,在同一個類的其他方法中也可
以使用這個常量,而且,如果一個常量被宣告為 public,那么其他類的方法也可以使用這個
常量, 在這個示例中,Constants2.CM_PER-INCH 就是這樣一個常童,
6.運算子
6.1 可移植性和性能間的平衡
需要嚴格計算【了解】 很多 Intel 處理器計算 x * y,并且將結果存盤在 80 位的暫存器中, 再除以 z 并將結果截斷為 64 位? 這樣可以得到一個更加精確的計算結果,并且還能夠避免產生指數溢位,但是, 這個結果可能與始終在 64 位機器上計算的結果不一樣, 因此,Java 虛擬機的最初規范規定所有的中間計算都必須進行截斷這種行為遭到了數值計算團體的反對,截斷計算不僅可能導致溢位, 而且由于截斷操作需要消耗時間, 所以在計算速度上實際上要比精確計算慢, 為此,Java程式設計語言承認了最優性能與理想結果之間存在的沖突,并給予了改進,在默認情況下, 虛擬機設計者允許對中間計算結果采用擴展的精度,但是,對于使用 strictfj) 關鍵字標記的方法必須使用嚴格的浮點計算來生成可再生的結果,例如,可以把 main 方法標記為:
publicstatic strictfp void main(String[] args)
于是,在 main 方法中的所有指令都將使用嚴格的浮點計算,如果將一個類標記為strictfp,這個類中的所有方法都要使用嚴格的浮點計算,實際的計算方式將取決于 Intel 處理器的行為,在默認情況下,中間結果允許使用擴展的指數,但不允許使用擴展的尾數(Intel 芯片在截斷尾數時并不損失性能),因此,這兩種方式的區別僅僅在于采用默認的方式不會產生溢位,而采用嚴格的計算有可能產生溢位對大多數程式來說, 浮點溢位不屬于大向題,
6.2常用數學函式
double y = Math.sqrt(3.14);//開平方,形參是double型別,回傳值也是double型別
double y = Math.pow(x, a);//冪運算將,形參是double型別,回傳值也是double型別
Math 類提供了一些常用的三角函式:
Math.sin
Math.cos
Math.tan
Math.atan
Math.atan2
有指數函式以及它的反函式—自然對數以及以 10 為底的對數:
Math.exp
Math.log
Math.loglO
最后,Java 還提供了兩個用于表示 TC 和 e 常量的近似值:
Math.PI
Math.E
小技巧:不必在數學方法名和常量名前添加前綴“ Math”, 只要在源檔案的頂部加上下面
這行代碼就可以了,
import static java.lang.Math.*;
System.out.println("The square root of \u03C0 is " + sqrt(PI));
精度和性能:在 Math 類中, 為了達到最快的性能, 所有的方法都使用計算機浮點單元中的例
程… 如果得到一個完全可預測的結果比運行速度更重要的話, 那么就應該使用 StrictMath
類
6.3 數值型別之間的轉換
某些整型數值轉換為 float 型別時, 將會得到同樣大小的結果,但卻失去了一定
的精度
int n = 123456789;
float f = n; // f is 1.23456792E
System.out.println("n: " + n);
System.out.println("f: " + f);
System.out.printf("格式化輸出f: %f\n", f);
//n: 123456789
//f: 1.23456792E8
//格式化輸出f: 123456792.000000
//float ff = 3.14;//編譯報錯原因:因為小數會自動隱式提升到 double, 因此需要在小數后加上F或者f
float ff = 3.14f;
轉換規則:當使用上面兩個數值進行二元操作時(例如 n + f,n 是整數, f 是浮點數,) 先要將兩個運算元轉換為同一種型別,然后再進行計算,
- 如果兩個運算元中有一個是 double 型別, 另一個運算元就會轉換為 double 型別,
- 否則,如果其中一個運算元是 float 型別,另一個運算元將會轉換為 float 型別,
- 否則, 如果其中一個運算元是 long 型別, 另一個運算元將會轉換為 long 型別,
- 否則, 兩個運算元都將被轉換為 int 型別
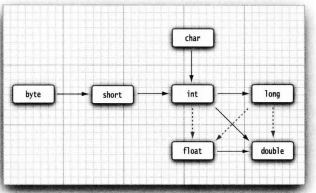
6.4 強制型別轉換
byte b1 = 1;
byte b2 = 2;
byte b3 = (byte) (b1+b2);//編譯報錯原因:byte型別會隱式提升為 int,因此需要型別強轉
int i1= (int) Math.round(3.14);//其原因是 round 方法回傳的結果為 long 型別,由于存在資訊丟失的可能性,所以只有使用顯式的強制型別轉換才能夠將 long 型別轉換成 int 型別,
如果試圖將一個數值從一種型別強制轉換為另一種型別, 而又超出了目標型別的表示范圍,結果就會截斷成一個完全不同的值,例如,(byte )> 300 的實際值為 44
System.out.println("byte取值范圍: [" + Byte.MAX_VALUE + ", " + Byte.MIN_VALUE + "]");
System.out.println("(byte)128: " + (byte) 128);
System.out.println("(byte)(-129): " + (byte) (-129));
//byte取值范圍: [127, -128]
//(byte)128: -128
//(byte)(-129): 127
System.out.println(Integer.MAX_VALUE);//System.out.println()默認內部資料型別是 int,超出范圍即溢位
System.out.println(Integer.MAX_VALUE+1);
System.out.println(Integer.MIN_VALUE);
System.out.println(Integer.MIN_VALUE-1);
//2147483647
//-2147483648
//-2147483648
//2147483647
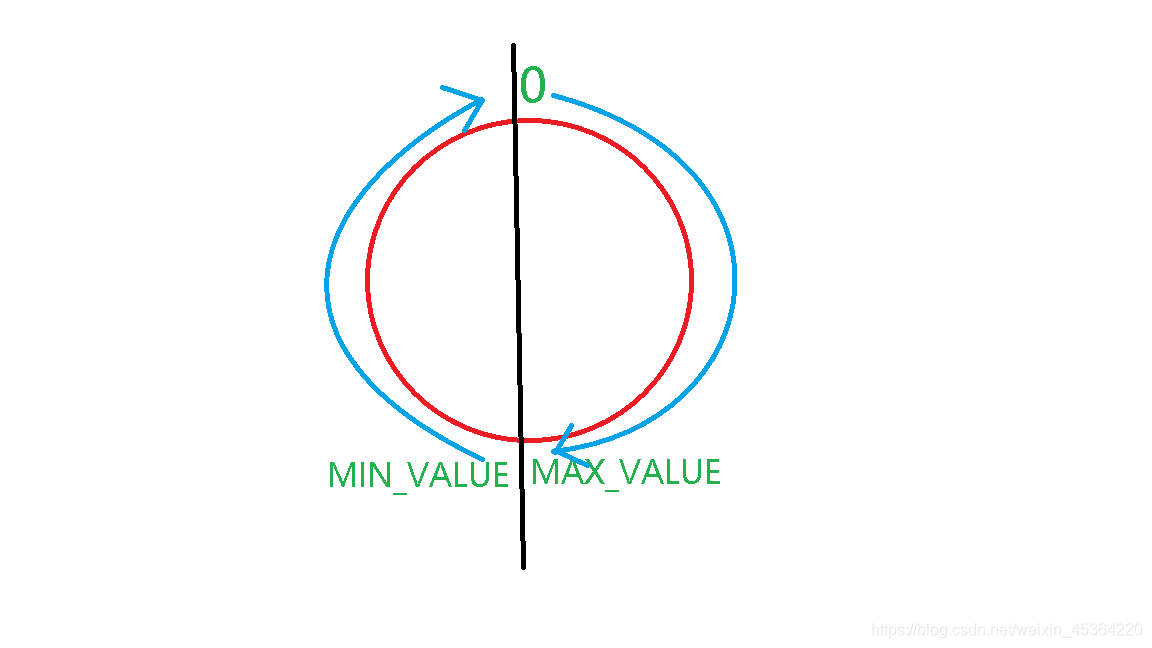
附加
不要在 boolean 型別與任何數值型別之間進行強制型別轉換, 這樣可以防止
發生錯誤,只有極少數的情況才需要將布爾型別轉換為數值型別,這時可以使用條件表 達式 b ? 1:0
6.5 優先級
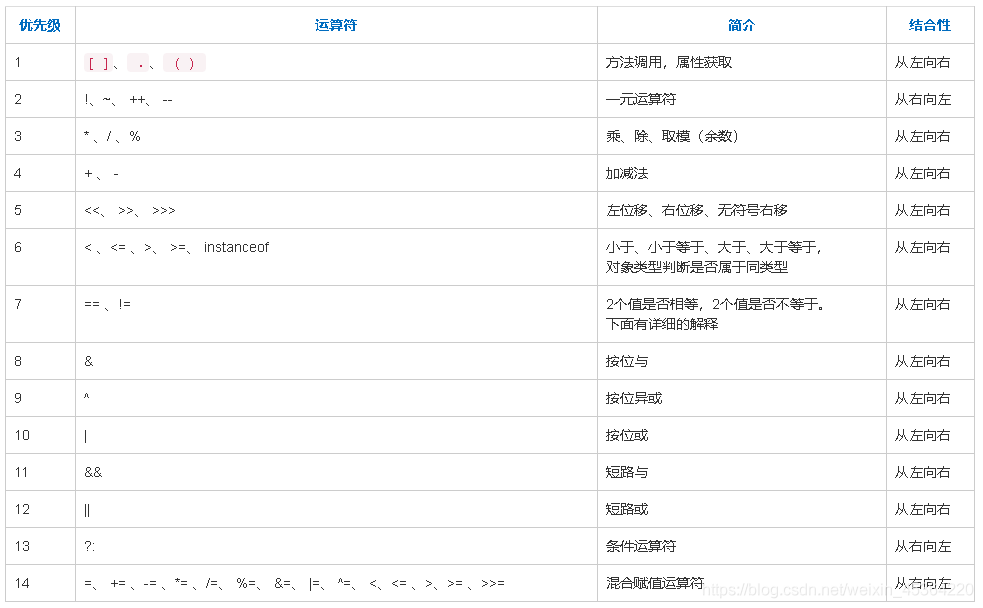
- % 表示取余, 不僅僅可以對 int 求模, 也能對 double 來求模
- &&,||會出現短路運算
- 左移 <<: 最左側位不要了, 最右側補 0【 左移 1 位, 相當于原數字 * 2. 左移 N 位, 相當于原數字 * 2 的N次方.】
- 右移 >>: 最右側位不要了, 最左側補符號位(正數補0, 負數補1)【右移 1 位, 相當于原數字 / 2. 右移 N 位, 相當于原數字 / 2 的N次方.】
- 無符號右移 >>>: 最右側位不要了, 最左側補 0.
- 沒有無符號左移<<<
- 由于計算機計算移位效率高于計算乘除, 當某個代碼正好乘除 2 的N次方的時候可以用移位運算代替.移動負數位或者移位位數過大都沒有意義
System.out.println(10 < 20 && 20 < 30); 雖然關系運算子優先級高于邏輯運算子但此時明顯是先計算的 10< 20 和 20 < 30, 再計算 &&. 否則 20 && 20 這樣的操作是語法上有誤的(&& 的運算元只能是 boolean).
6.6 結合賦值和運算子
可以在賦值中使用二元運算子,這是一種很方便的簡寫形式,例如:
X += 4;
等價于:
x = x + 4;
(一般地, 要把運算子放在 = 號左邊,如 *=,%=,/=,-=,<<=,>>=,>>>=,&=, |=,,^=)
6.7 自增與自減運算
int n = 12;
n++;
將 n 的值改為 13,由于這些運算子會改變變數的值,所以它們的運算元不能是數值,例如,
4++ 就不是一個合法的陳述句,實際上, 這些運算子有兩種形式;上面介紹的是運算子放在運算元后面的“ 后綴” 形式,還有一種“ 前綴” 形式:++n,后綴和前綴形式都會使變數值加 1 或減 1,但用在運算式中時,二者就有區別了,前綴形式會先完成加 1; 而后綴形式會使用變數原來的值,
int m = 7;
int n = 7;
int a = 2 * ++m; // now a is 16, m is 8
int b = 2 * n++; // now b is 14, n is 8
建議不要在運算式中使用 ++, 因為這樣的代碼很容易讓人閑惑,而且會帶來煩人的 bug,
6.8 列舉型別
public class Test {
enum Size {SMALL, MEDIUM, LARGE, EXTRA};
public static void main(String[] args) {
Size s = Size.MEDIUM;
System.out.println(s);
}
}
//MEDIUM
7.字串
從概念上講, Java 字串就是 Unicode 字符序列, 例如, 串“ Java\u2122” 由 5 個Unicode 字符 J、a、 v、a 和?,Java 沒有內置的字串型別, 而是在標準 Java 類別庫中提供了一個預定義類,很自然地叫做 String,每個用雙引號括起來的字串都是 String類的一個實
例:
public class Test {
public static void main(String[] args) {
String str = "";
String str1 = null;
String str2 = "Hello World";
System.out.println(str);
System.out.println(str1);
System.out.println(str2);
}
}
//
//null
//Hello World
7.1 子串
public class Test {
public static void main(String[] args) {
String greeting = "Hello";
String s = greeting.substring(0, 3);
System.out.println(s);
}
}
//Hel
substring 方法的第二個引數是不想復制的第一個位置,這里要復制位置為 0、 1 和 2 (從 0 到 2, 包括 0 和 2 )
的字符,在 substring 中從 0 開始計數,直到 3 為止, 但不包含 3
7.2 拼接
public class Test {
public static void main(String[] args) {
String expletive = "Expletive";
String PC13 = "deleted";
String message = expletive + PC13;
System.out.println(message);
}
}
//Expletivedeleted
+ 號連接(拼接)兩個字串,“ Expletivedeleted” 賦給變數 message
當將一個字串與一個非字串的值進行拼接時,后者被轉換成字串
public class Test {
public static void main(String[] args) {
int age = 13;
String rating = "PC" + age;
System.out.println(rating);
}
}
//PC13
這種特性通常用在輸出陳述句中,例如:System.out.println("The answer is " + answer);
如果需要把多個字串放在一起, 用一個定界符分隔,可以使用靜態 join 方法
public class Test {
public static void main(String[] args) {
String all = String.join(" / ", "S", "M", "L", "XL");
System.out.println(all);
}
}
//S / M / L / XL
7.3 不可變字串
String 類沒有提供用于修改字串的方法, 如果希望將 src的內容修改為“ Hello Java!”,不能直接地將 greeting 的最后位置的字符修改為‘Java ’ 和 ‘!’ 這對于 C 語言來說,將會感到無從下手,如何修改這個字串呢? 在 Java中實作這項操作非常容易,首先提取需要的字符, 然后再拼接上替換的字串
public class Test {
public static void main(String[] args) {
String src = "Hello World";
src = src.substring(0, 5) + " Java!";
System.out.println(src);
}
}
//Hello Java!
理解 String 類不可變:
由于不能修改 Java 字串中的字符, 所以在 Java 檔案中將 String 類物件稱為不可變字 符串, 如同數字 3 永遠是數字 3—樣,字串“ Hello” 永遠包含字符 H、 e、1、 1 和 o 的代 碼單元序列, 而不能修改其中的任何一個字符,當然, 可以修改字串變數 src, 讓它 參考另外一個字串, 這就如同可以將存放 3 的數值變數改成存放 4 一樣
思考
這樣做是否會降低運行效率呢? 看起來好像修改一個代碼單元要比創建一個新字串更 加簡潔,答案是:也對,也不對,的確, 通過拼接“ Hello” 和“ Java! ” 來創建一個新字串的 效率確實不高,但是,不可變字串卻有一個優點:編譯器可以讓字串共享,為了弄清具體的作業方式,可以想象將各種字串存放在公共的存盤池中,字串變數 指向存盤池中相應的位置,如果復制一個字串變數,原始字串與復制的字串共享相同 的字符, 總而言之,Java 的設計者認為共享帶來的高效率遠遠勝過于提取、 拼接字串所帶來的 低效率
學 C 的同學第一次接觸 Java 字串的時候, 常常會感到迷惑, 因為他們總將字串認為是字符型陣列:
char greeting[ ] = "Hello";
//這種認識是錯誤的, Java 字串大致類似于 char* 指標,
char* src= "Hello World";
//當采用另一個字串替換 src 的時候, Java 代碼大致進行下列操作:
char* temp = mal1oc(11);
strncpy(temp, src, 5);
strncpy(temp + 1, "Java!, 3);
src= temp;
以 Java 角度考慮這樣做會不會產生記憶體遺漏呢? 畢競, 原始字串放置在堆中,十分幸運,強大的 JVM 將自動地進行垃圾回收, 如果一塊記憶體不再使用了, 系統最侄訓將其回收,
有了前邊的理論知識下面一幅圖解釋清楚不可變
字串是一種不可變物件. 它的內容不可改變.String 類的內部實作也是基于 char[] 來實作的, 但是 String 類并沒有提供 set 方法之類的來修改內部的字符陣列.
public class Test {
public static void main(String[] args) {
String str = "hello" ;
str = str + " world" ;
str += "!!!" ;
System.out.println(str);
}
}
//hello world!!!
形如 += 這樣的操作, 表面上好像是修改了字串, 其實不是. 記憶體變化如下:
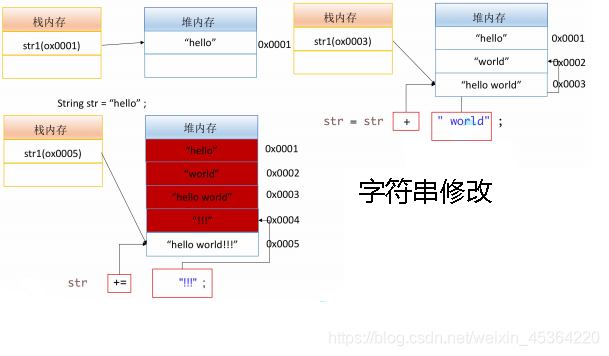
+= 之后 str 列印的結果卻是變了, 但是不是 String 物件本身發生改變, 而是 str 參考到了其他的物件
回顧參考
參考相當于一個指標, 里面存的內容是一個地址. 我們要區分清楚當前修改到底是修改了地址對應 記憶體的內容發生改變了, 還是參考中存的地址改變了
那么如果實在需要修改字串, 例如, 現有字串 str = “Hello” , 想改成 str = “hello” , 該怎么辦?
7.3.1 substring原地修改
a) 常見辦法: 借助原字串, 創建新的字串
public class Test {
public static void main(String[] args) {
String str = "Hello";
str = "h" + str.substring(1);
System.out.println(str);
}
}
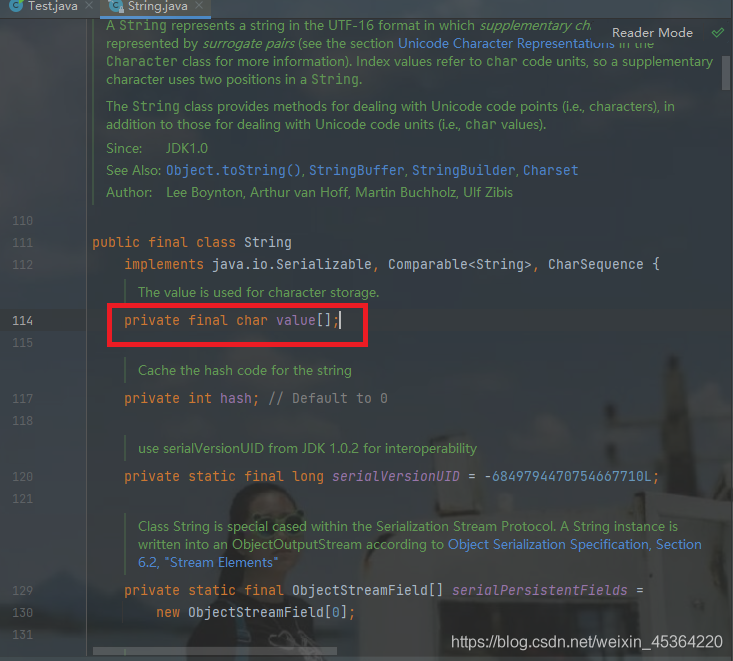
7.3.2 反射修改
b) 特殊辦法(了解): 使用 “反射” 這樣的操作可以破壞封裝, 訪問一個類內部的 private 成員.
IDEA 中 ctrl + 左鍵 跳轉到 String 類的定義, 可以看到內部包含了一個 char[] , 保存了字串的內容.
public class Test {
public static void main(String[] args) {
String str = "Hello";
// 獲取 String 類中的 value 欄位. 這個 value 和 String 原始碼中的 value 是匹配的
Field valueField = null;
try {
valueField = String.class.getDeclaredField("value");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
// 將這個欄位的訪問屬性設為 true
valueField.setAccessible(true);
// 把 str 中的 value 屬性獲取到
char[] value = new char[0];
try {
value = (char[]) valueField.get(str);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
// 修改 value 的值
value[0] = 'G';
System.out.println(str);
}
}
//Gello
為什么 String 要不可變?(不可變物件的好處是什么?) (了解)
- 方便實作字串物件池. 如果 String 可變, 那么物件池就需要考慮何時深拷貝字串的問題了.
- 不可變物件是執行緒安全的.
- 不可變物件更方便快取 hash code, 作為 key 時可以更高效的保存到 HashMap 中.
注意事項: 如下代碼不應該在你的開發中出, 會產生大量的臨時物件, 效率比較低
public class Test {
public static void main(String[] args) {
String str = "hello";
for (int x = 0; x < 1000; x++) {
str += x;
}
System.out.println(str);
}
}
輸出結果:

7.4 檢測字串是否相等
可以使用 equals 方法檢測兩個字串是否相等,對于運算式:s.equals(t)
如果字串 s 與字串 t 相等, 則回傳 true ; 否則, 回傳 false,需要注意,s與 t 可以是字串變數, 也可以是字串字面量, 例如, 下列運算式是合法的:
public class Test {
public static void main(String[] args) {
System.out.println("Hello World".equals("Hello Java"));
}
}
//false
要想檢測兩個字串是否相等,而不區分大小寫, 可以使用 equalsIgnoreCase 方法,
public class Test {
public static void main(String[] args) {
System.out.println("HELLO".equalsIgnoreCase("hello"));
}
}
//true
一定不要使用==運算子檢測兩個字串是否相等! 這個運算子只能夠確定兩個字串 是否放置在同一個位置上,當然, 如果字串放置在同一個位置上,它們必然相等,但是, 完全有可能將內容相同的多個字串的拷貝放置在不同的位置上,
public class Test {
public static void main(String[] args) {
String greeting = "Hello";
System.out.println(greeting == "Hello");// probably true
System.out.println(greeting.substring(0, 3).intern() == "Hel");// probably true
System.out.println(greeting.substring(0, 3) == "Hel");// probably false
}
}
//true
//true
//false
由于 String 是參考型別, 因此對于以下代碼
String greeting = “Hello”;
greeting.substring(0, 3).intern();
greeting.substring(0, 3);
記憶體布局如圖
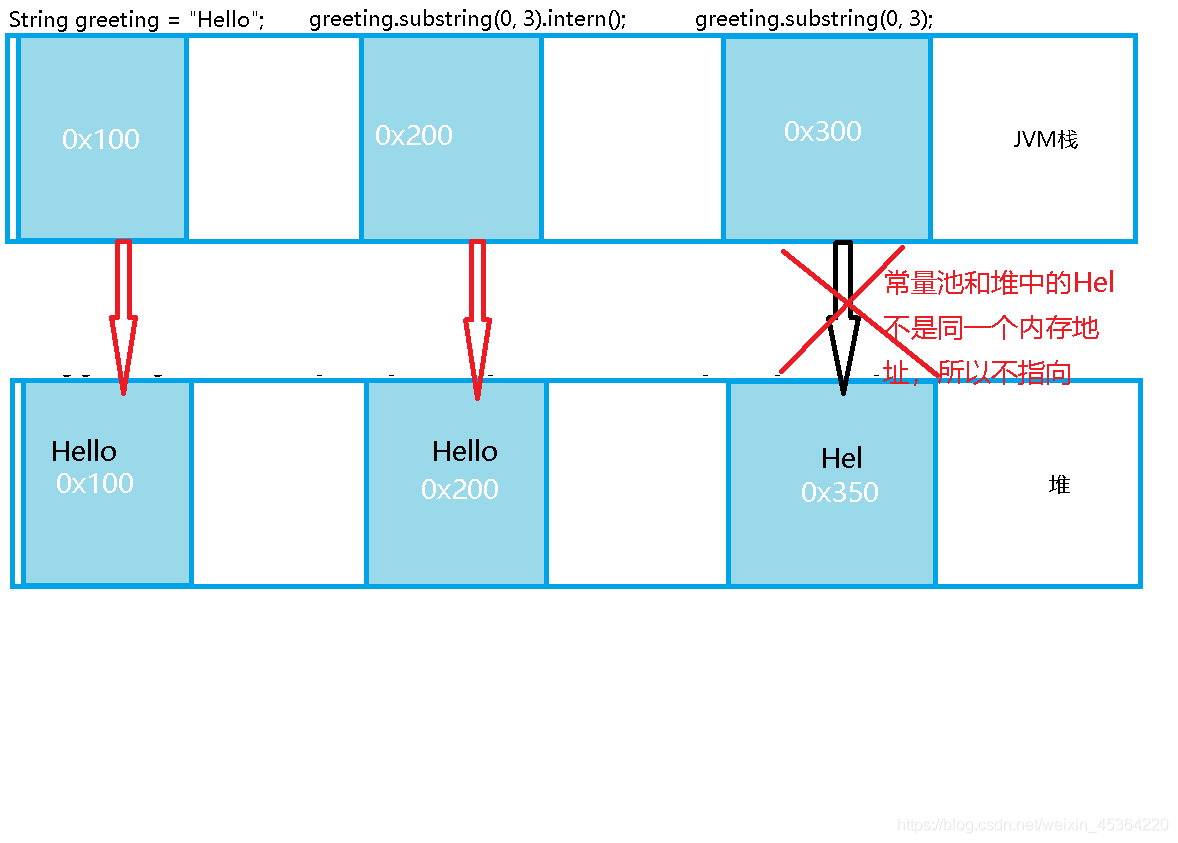
如果沒理解==比較的是兩個元素的位置的話,再舉個例子,
我們都知道 Java 字串初始化的方式有如下幾種:
// 方式一
String str = “Hello Bit”;
// 方式二
String str2 = new String(“Hello Bit”);
// 方式三
char[] array = {‘a’, ‘b’, ‘c’};
String str3 = new String(array);
在 官方檔案 上我們可以看到
String 還支持很多其.他的構造方式, 我們用到的時候去查就可以了,
“hello” 這樣的字串也是字面值常量, 型別也是 String. String 也是參考型別. String str = “Hello”; 這樣的代碼記憶體布局如下:
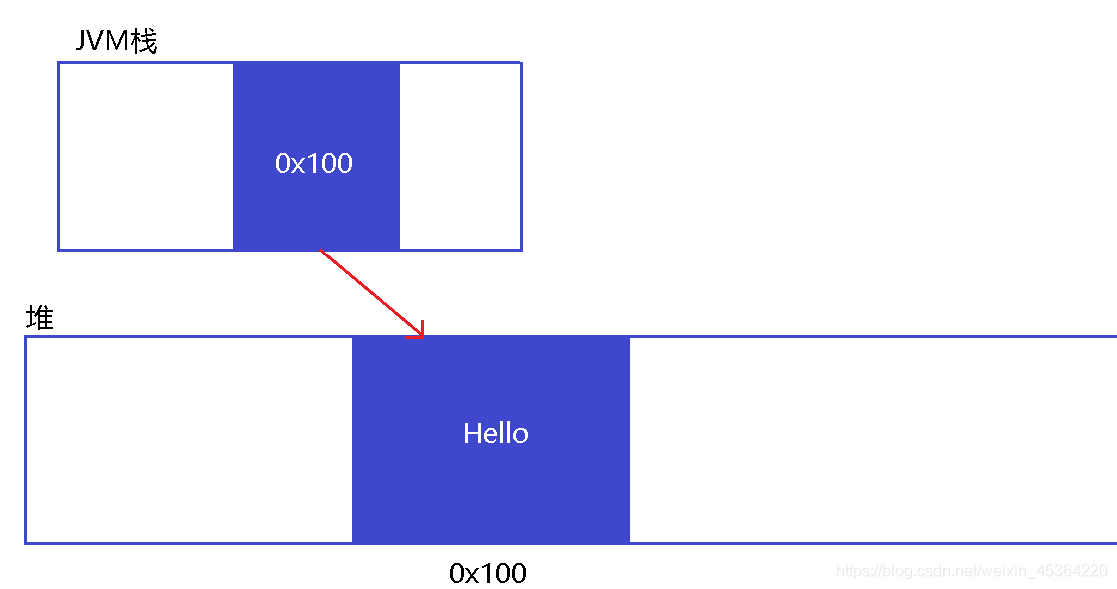
回憶 "參考"
參考類似于 C 語言中的指標, 只是在堆疊上開辟了一小塊記憶體空間保存一個地址. 但是參考和指標又 不太相同,指標能進行各種數字運算(指標+1)之類的, 但是參考不能, 這是一種 “沒那么靈活” 的指標. 另外, 也可以把參考想象成一個標簽, “貼” 到一個物件上. 一個物件可以貼一個標簽, 也可以貼多個. 如果一個物件上面一個標簽都沒有, 那么這個物件就會被 JVM 當做垃圾物件回收掉.Java 中陣列, String, 以及自定義的類都是參考型別
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = str1;
System.out.println(str1 == str2);
}
}
//true
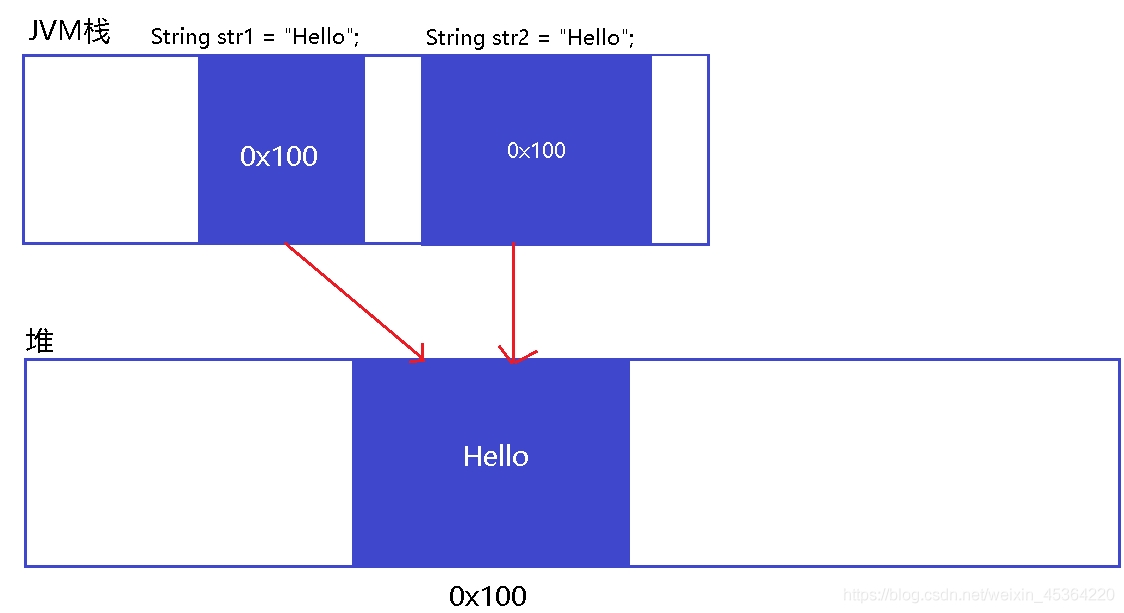
那么有同學可能會說, 是不是修改 str1 , str2 也會隨之變化呢?
public class Test {
public static void main(String[] args) {
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1 == str2);
str1 = "World";
System.out.println(str2);
}
}
//false
//Hello
我們發現, “修改” str1 之后, str2 也沒發生變化, 還是 hello? 事實上, str1 = "world"這樣的代碼并不算 “修改” 字串, 而是讓 str1 這個參考指向了一個新的 String 物件.
通過 String str1 = new String(“Hello”); 這樣的方式創建的 String 物件相當于再堆上另外開辟了空間來存盤 “Hello” 的內容, 也就是記憶體中存在兩份 “Hello”.
String 使用 == 比較并不是在比較字串內容, 而是比較兩個參考是否是指向同一個物件
關于物件的比較
面向物件編程語言中, 涉及到物件的比較, 有三種不同的方式, 比較身份, 比較值, 比較型別. 在大部分編程語言中 ==是用來比較比較值的. 但是 Java 中的 == 是用來比較身份的. 如何理解比較值和比較身份呢? 經過兩張圖,應該清楚所謂的身份了吧,也就是 JVM堆疊 存盤的參考指向了 堆,因此 == 比較的也就是參考相不相同,也就是身份相同與否了,
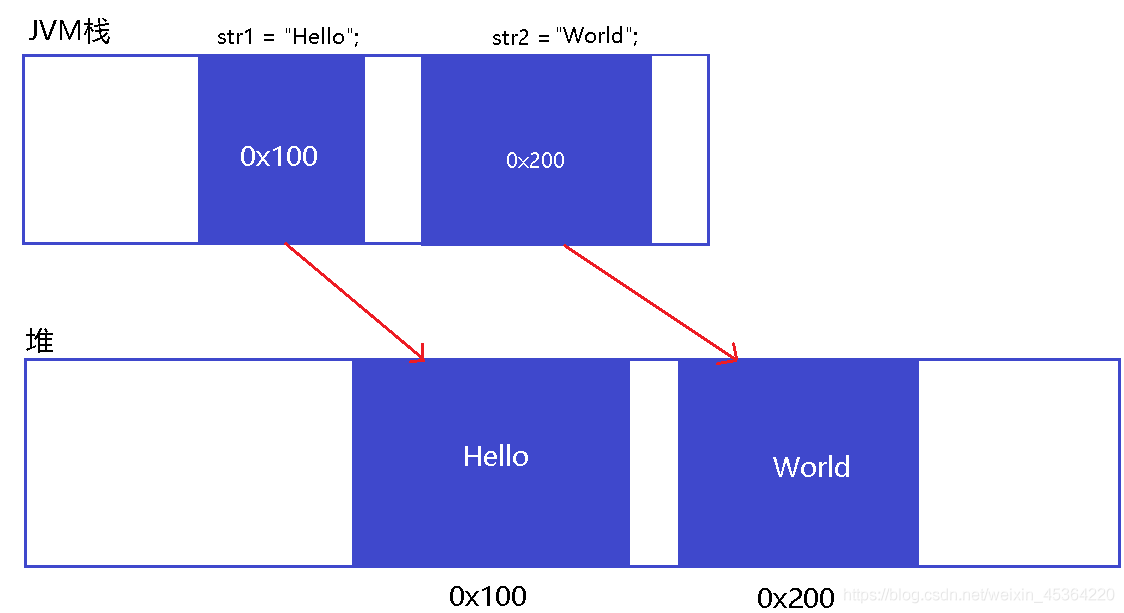
equals方法比較字符堆上的串是否相等
public class Test {
public static void main(String[] args) {
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1 == str2);
System.out.println(str1.equals(str2));
}
}
//false
//true
好奇的小伙伴可能想知道為什么上文中System.out.println(greeting.substring(0, 3).intern() == "Hel");// probably true為何輸出的是true,這就涉及到了 字串常量池 這一概念
7.5 字串常量池
在上面的例子中, String類的兩種實體化操作, 直接賦值和 new 一個新的 String
7.5.1 直接賦值
String str1 = “hello” ;
String str2 = “hello” ;
String str3 = “hello”;
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // true
System.out.println(str2 == str3); // true
為什么現在并沒有開辟新的堆記憶體空間呢?
前文提到了String類的設計使用了共享設計模式,因為設計者認為共享資源帶來的效益高于性能
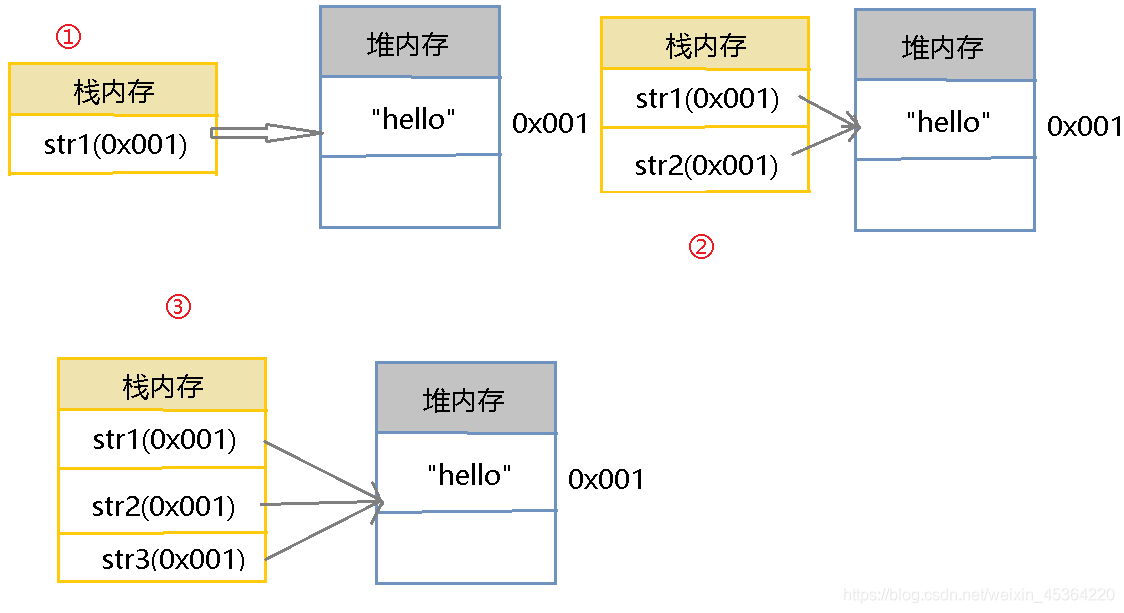
在JVM底層實際上會自動維護一個物件池(字串常量池)
- 如果現在采用了直接賦值的模式進行String類的物件實體化操作,那么該實體化物件(字串內
容)將自動保存到這個物件池之中. - 如果下次繼續使用直接賦值的模式宣告String類物件,此時物件池之中如若有指定內容,將直接進
行參考 - 如若沒有,則開辟新的字串物件而后將其保存在物件池之中以供下次使用
7.5.2 理解 “池” (pool)
“池” 是編程中的一種常見的, 重要的提升效率的方式, 我們會在未來的學習中遇到各種 “記憶體池”, “執行緒池”, “資料庫連接池” …
然而池這樣的概念不是計算機獨有, 也是來自于生活中. 舉個栗子:
現實生活中有一種女神, 稱為 “綠茶”, 在和高富帥談著物件的同時,還可能和別的屌絲搞曖昧. 這時 候這個屌絲被稱為 “備胎”. 那么為啥要有備胎? 因為一旦和高富帥分手了, 就可以立刻找備胎接盤, 這樣效率比較高. 如果這個女神, 同時在和很多個屌絲搞曖昧, 那么這些備胎就稱為 備胎池.
7.5.3 采用構造方法
類物件使用構造方法實體化是標準做法,分析如下程式:
String str = new String("hello") ;
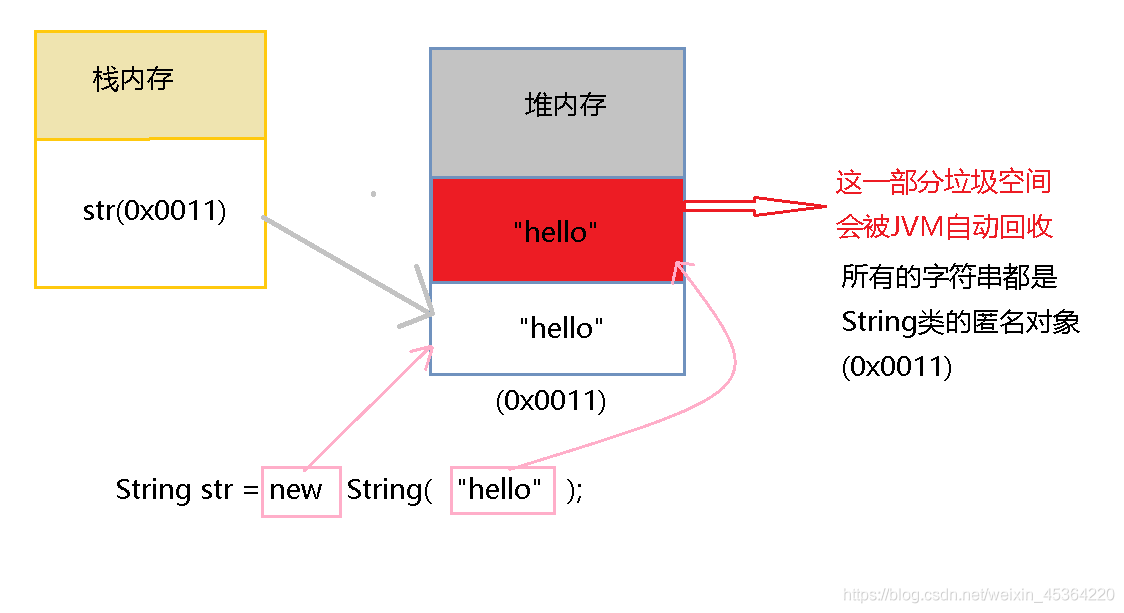
這樣的做法有兩個缺點:
- 如果使用String構造方法就會開辟兩塊堆記憶體空間,并且其中一塊堆記憶體將成為垃圾空間(字串常
量 “hello” 也是一個匿名物件, 用了一次之后就不再使用了, 就成為垃圾空間, 會被 JVM 自動回收掉). - 字串共享問題. 同一個字串可能會被存盤多次, 比較浪費空間
我們可以使用 String 的 intern 方法來手動把 String 物件加入到字串常量池中
public class Test {
public static void main(String[] args) {
// 該字串常量并沒有保存在物件池之中
String str1 = new String("hello") ;
String str2 = "hello" ;
System.out.println(str1 == str2);//false
String str11 = new String("hello").intern() ;
String str22 = "hello" ;
System.out.println(str11 == str22);//true
}
}
//false
//true
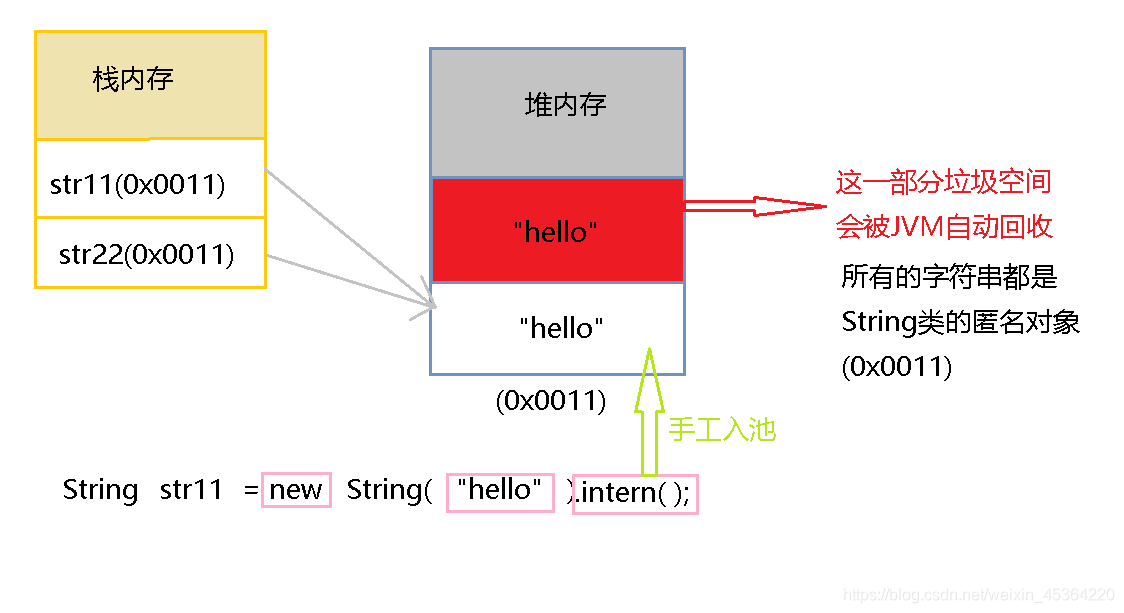
面試題:請解釋String類中兩種物件實體化的區別
- 直接賦值:只會開辟一塊堆記憶體空間,并且該字串物件可以自動保存在物件池中以供下次 使用,
- 構造方法:會開辟兩塊堆記憶體空間,不會自動保存在物件池中,可以使用intern()方法手工入 池,
綜上, 我們一般采取直接賦值的方式創建 String 物件.
7.6 String 常用 API
| 函式原型 | 簡介 |
|---|---|
| char charAt (int index) | 回傳給定位置的代碼單元,除非對底層的代碼單元感興趣, 否則不需要呼叫這個方法 |
| int compareTo(String other) | 按照字典順序,如果字串位于 other 之前, 回傳一個負數;如果字串位于 other 之后,回傳一個正數;如果兩個字串相等,回傳 0 |
| boolean equals(0bject other) | 如果字串與 other 相等, 回傳 true |
| boolean equalsIgnoreCase(String other ) | 如果字串與 other 相等 ( 忽略大小寫,) 回傳 true |
| boolean startsWith(String prefix ) | 如果字串以 prefix 開頭, 則回傳 true |
| boolean endsWith(String suffix ) | 如果字串以 suffix結尾, 則回傳 true |
| int indexOf(String str) | |
| int indexOf(String str, int fromlndex ) | |
| int indexOf(int cp) | |
| int indexOf(int cp, int fromlndex ) | 回傳與字串 str 或代碼點 cp 匹配的第一個子串的開始位置,這個位置從索引 0 或fromlndex 開始計算, 如果在原始串中不存在 str,回傳 -1 |
| int lastIndexOf(String str) | |
| int lastIndexOf(String str, int fromlndex ) | |
| int lastindexOf(int cp) | |
| int lastindexOf(int cp, int fromlndex ) | 回傳與字串 str 或代碼點 cp 匹配的最后一個子串的開始位置, 這個位置從原始串尾端或 fromlndex 開始計算 |
| int length( ) | 回傳字串的長度 |
| String substring(int beginlndex ) | |
| String substring(int beginlndex, int endlndex ) | 回傳一個新字串,這個字串包含原始字串中從 beginlndex 到串尾或 endlndex-l的所有代碼單元 |
| String toLowerCase( ) | 回傳一個新字串,這個字串將原始字串中的大寫字母改為小寫 |
| String toUpperCase( ) | 回傳一個新字串, 這個字串將原始字串中的所有小寫字母改成了大寫字母 |
| String trim( ) | 回傳一個新字串,這個字串將洗掉了原始字串頭部和尾部的空格 |
| String join(CharSequence delimiter, CharSequence … elements ) | 回傳一個新字串, 用給定的定界符連接所有元素 |
7.7 構建字串
使用場景分析:有些時候, 需要由較短的字串構建字串, 例如, 按鍵或來自檔案中的單詞,采用字串連接的方式達到此目的效率比較低,每次連接字串, 都會構建一個新的 String 物件,既耗時, 又浪費空間,使用 StringBuildei?類就可以避免這個問題的發生
如果需要用許多小段的字串構建一個字串, 那么應該按照下列步驟進行, 首先, 構建一個空的字串構建器:
public class Test {
public static void main(String[] args) {
//效率低下:一般不這么構建字串
String str = "hello";
for (int x = 0; x < 1000; x++) {
str += x;
}
System.out.println(str);
//快捷
StringBuilder builder = new StringBuilder("hello");
for (int i = 0; i < 1000; i++) {
builder.append(i);
}
String completedString = builder.toString();//在需要構建字串時就凋用 toString 方法, 將可以得到一個 String 物件, 其中包含了構建器中的字符序列
System.out.println(completedString);
}
}
附加
在 JDK5.0 中引入 StringBuilder 類, 這個類的前身是 StringBuffer, 其效率稍有些 低, 但允許采用多執行緒的方式執行添加或洗掉字符的操作,如果所有字串在一個單線 程中編輯 (通常都是這樣,) , 則應該用StringBuilder 替代它, 這兩個類的 AP丨是相同的
String Builder 常用 API
| 函式原型 | 簡介 |
|---|---|
| StringBuilder() | 構造一個空的字串構建器 |
| int length() | 回傳構建器或緩沖器中的代碼單元數量 |
| Stri ngBuilder append(String str) | 追加一個字串并回傳 this |
| StringBuilder append(char c) | 追加一個代碼單元并回傳 this |
| void setCharAt(int i ,char c) | 將第 i 個代碼單元設定為 c |
| StringBuilder insert(int offset,String str) | 在 offset 位置插入一個字串并回傳 this |
| StringBuilder insert(int offset,char c) | 在 offset 位置插入一個代碼單元并回傳 this |
| StringBuilder delete(int startindex,int endlndex) | 洗掉偏移量從 startindex 到 -endlndex-1 的代碼單元并回傳 this |
| String toString() | 回傳一個與構建器或緩沖器內容相同的字串 |
8.輸入輸出
8.1 讀取輸入
列印輸出到“ 標準輸出流”(即控制臺視窗)是一件非常容易的事情,只要呼叫System.out.println 即可,然而,讀取“ 標準輸人流” System.in 就沒有那么簡單了,要想通過控制臺進行輸人,首先需要構造一個 Scanner 物件,并與“ 標準輸人流” System.in 關聯
Scanner in = new Scanner(System.in);
8.2 Scanner 常用 API
| 函式原型 | 簡介 |
|---|---|
| Scanner (InputStream in) | 用給定的輸人流創建一個 Scanner 物件 |
| String nextLine( ) | 讀取輸入的下一行內容,如果前邊有其其它輸入,那么它會讀取到回車換行符"\n",因此需要使用nextLine()的時候需要把它放在所有輸入中第一個 |
| String next( ) | 讀取輸入的下一個單詞(以空格作為分隔符,) |
| int nextlnt( ) | |
| double nextDouble( ) | 讀取并轉換下一個表示整數或浮點數的字符序列 |
| boolean hasNext( ) | 檢測輸人中是否還有其他單詞 |
| boolean hasNextInt( ) | |
| boolean hasNextDouble( ) | 檢測是否還有表示整數或浮點數的下一個字符序列 |
8.3 格式化輸出
如下:
%8.2f:可以用 8 個字符的寬度和小數點后兩個字符的精度列印 x,也就是說,列印輸出一個空格和
7 個字符
%,.2f:另外,還可以給出控制格式化輸出的各種標志,表 3-6 列出了所有的標志,例如,逗號
標志增加了分組的分隔符
public class Test {
public static void main(String[] args) {
double x = 10000.0 / 3.0;
System.out.println(x);
System.out.printf("%,.2f\n", x);
System.out.printf("%8.2f\n", x);
}
}
//3333.3333333333335
//3,333.33
// 3333.33
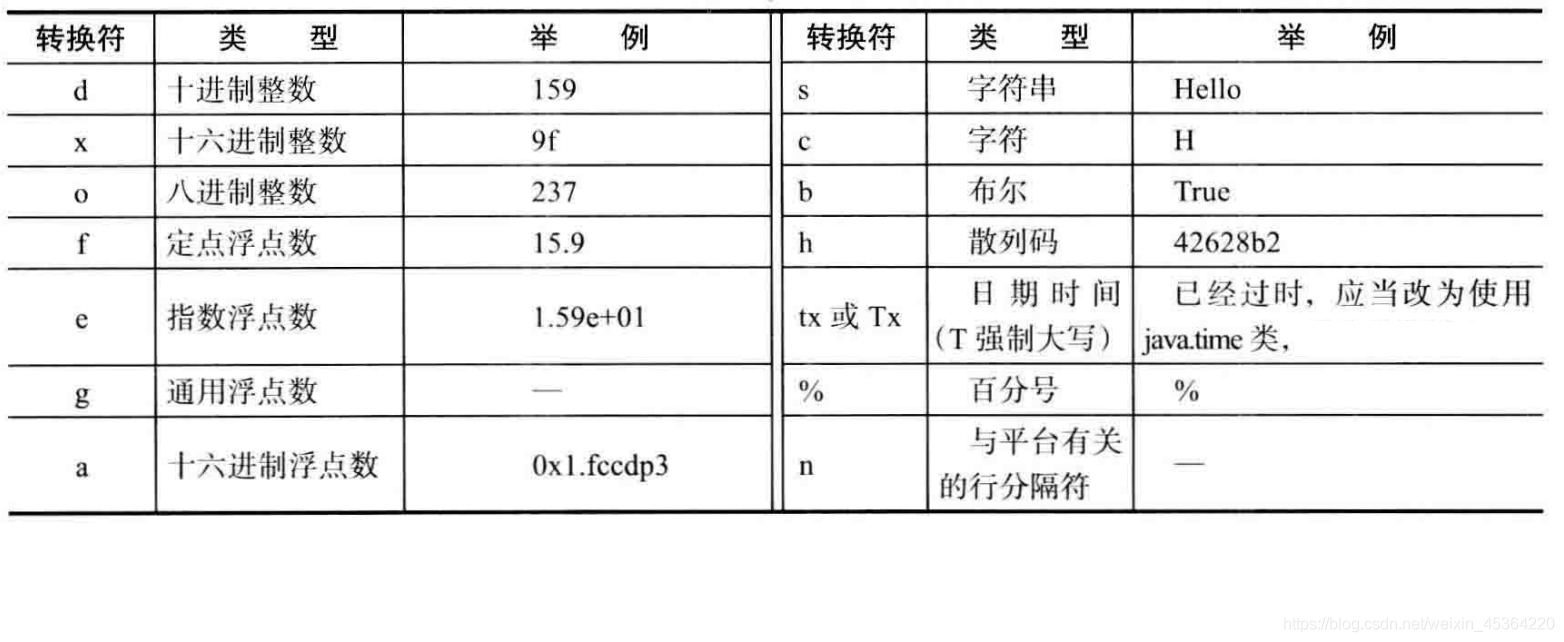
printf轉換符
8.4 時間和日期
格式包括兩個字母, 以 t 開始,以圖中任意一個字母結束
經常用tc即可,其他可以忽略
public class Test {
public static void main(String[] args) {
System.out.printf("%tc", new Date());
System.out.println();
System.out.printf("%tT", new Date());
}
}
//星期六 八月 07 15:27:03 CST 2021
//15:27:03
8.5 檔案輸入與輸出
public class Test {
public static void main(String[] args) {
try {
Scanner scanner = new Scanner(Paths.get("D:\\Program\\JetBrains\\IDEA\\Projects\\Java-Gao\\src\\讀取三行情書.txt"), "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果檔案名中包含反斜杠符號,就要記住在每個反斜杠之前再加一個額外的反斜杠“:\D:\Program\JetBrains\IDEA\Projects\Java-Gao\src\讀取三行情書.txt ”
在這里指定了 UTF-8 字符編碼, 這對于互聯網上的檔案很常見(不過并不是普遍適用),讀取一個文本檔案時,要知道它的字符編碼—更多資訊參見卷 n 第 2 章,如果 省略字符編碼, 則會使用運行這個 Java程式的機器的“ 默認編碼”, 這不是一個好主意, 如果在不同的機器上運行這個程式, 可能會有不同的表現
要想寫入檔案, 就需要構造一個 PrintWriter 物件,在構造器中,只需要提供檔案名:
public class Test {
public static void main(String[] args) {
try {
PrintWriter out = new PrintWriter("D:\\Program\\JetBrains\\IDEA\\Projects\\Java-Gao\\src\\寫入三行情書.txt", "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 如果檔案不存在,創建該檔案, 可以像輸出到 System.out—樣使用 print、 println 以及 printf 命令
- 可以構造一個帶有字串引數的 Scanner, 但這個 Scanner 將字串解釋為資料,而不是檔案名,
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner("myfile.txt"); // ERROR?:這個 scanner 會將引數作為包含 10 個字符的資料:‘ m ’,‘y ’,‘ f’ 等,在這個示例中所顯示的并不是所期望的效果
}
}
8.6 路徑問題
當指定一個相對檔案名時, 例如,“ myfile.txt”,“ mydirectory/myfile.txt” 或“ …/myfiletxt”,檔案位于 Java 虛擬機啟動路徑的相對位置 , 如果在命令列方式下用下列命令啟動程式:
java MyProg
啟動路徑就是命令解釋器的當前路徑, 然而,如果使用集成開發環境, 那么啟動路徑將由 IDE 控制, 可以使用下面的呼叫方式找到路徑的位置:
public class Test {
public static void main(String[] args) {
String dir = System.getProperty("user.dir");
System.out.println(dir);
}
}
//D:\Program\JetBrains\IDEA\Projects\Java-Gao
如果覺得定位檔案比較煩惱, 則可以考慮使用絕對路徑, 例如:“ c:\mydirectory\myfile.txt ” 或者“ /home/me/mydirectory/myfile.txt”
當采用命令列方式啟動一個程式時, 可以利用 Shell 的重定向語法將任意檔案關聯 到 System.in 和 System.out: java MyProg < rayfile.txt > output.txt 這樣,就不必擔心處理 IOException 例外了,
8.7 常用 API
| 函式原型 | 簡介 |
|---|---|
| Scanner(File f) | 構造一個從給定檔案讀取資料的 Scanner |
| Scanner(String data) | 構造一個從給定字串讀取資料的 Scanner |
| PrintWriter(String fileName) | 構造一個將資料寫入檔案的 PrintWriter,檔案名由引數指定 |
| static Path get(String pathname) | 根據給定的路徑名構造一個 Path |
9.控制流程
9.1 if
-
if(布爾運算式){
//條件滿足時執行代碼 } -
if(布爾運算式){
//條件滿足時執行代碼
}else{
//條件不滿足時執行代碼
} -
if(布爾運算式){
//條件滿足時執行代碼
}else if(布爾運算式){
//條件滿足時執行代碼
}else{
//條件都不滿足時執行代碼
}
懸垂 else 問題:if / else 陳述句中可以不加 大括號 . 但是也可以寫陳述句(只能寫一條陳述句). 此時 else 是和最接近的 if 匹配.但是實際開發中我們 不建議 這么寫. 最好加上大括號
public class Test {
public static void main(String[] args) {
int x = 10;
int y = 10;
if (x == 10)
if (y == 10)
System.out.println("aaa");
else
System.out.println("bbb");
}
}
//aaa
9.2 switch 陳述句
case 標簽可以是:
- 型別為 char、byte、 short 或 int 的整形常量運算式,
- 列舉常量,
- 從 Java SE 7開始,case 標簽還可以是字串字面量,
public class Test {
public static void main(String[] args) {
switch (整數 | 列舉 | 字符 | 字串) {
case 內容1: {
內容滿足時執行陳述句;
break;
}
case 內容2: {
內容滿足時執行陳述句;
break;
}
default: {
內容都不滿足時執行陳述句;
break;
}
}
}
}
- 根據 switch 中值的不同, 會執行對應的 case 陳述句. 遇到 break 就會結束該 case 陳述句. 如果 switch> 中的值沒有匹配的 case, 就會執行 default 中的陳述句. 我們建議一個 switch 陳述句最好都要帶上 default
- break 不要遺漏, 否則會失去 “多分支選擇” 的效果
- switch 中的值只能是 整數|列舉|字符|字串
- switch 不能表達復雜的條件
例如: 如果 num 的值在 10 到 20 之間, 就列印 hehe 這樣的代碼使用 if 很容易表達, 但是使用 switch 就無法表示.
if (num > 10 && num < 20) {
System.out.println(“hehe”);
}
9.3 回圈結構
9.3.1while 回圈
9.3.2 for 回圈
for(初始化; 判斷; 更新)
如下代碼可能永遠不會結束, 由于舍入的誤差, 最終可能得不到精確值,下面回圈中, 因為 0.1 無法精確地用二進制表示,所以,x 將從 9.999 999 999 999 98 跳到10.099 999 999 999 98
public class Test {
public static void main(String[] args) {
for (double x = 0; x != 10; x += 0.1) {
System.out.print(x + " ");
}
}
}
//死回圈
特別指出,如果在 for 陳述句內部定義一個變數, 這個變數就不能在回圈體之外使用,因 此, 如果希望在 for回圈體之外使用回圈計數器的最終值,就要確保這個變數在回圈陳述句的 前面且在外部宣告!
public class Test {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
;
}
System.out.println(i);
}
}
//java: 找不到符號
// 符號: 變數 i
// 位置: 類 Test
9.3.3 do while 回圈(了解)
9.3.4 塊作用域
塊(即復合陳述句)是指由一對大括號括起來的若干條簡單的 Java 陳述句,塊確定了變數的作用域,一個塊可以嵌套在另一個塊中,下面就是在 main方法塊中嵌套另一個陳述句塊示例
public class Test {
public static void main(String[] args) {
int n;
{
int k;
}
}
}
但是,不能在嵌套的兩個塊中宣告同名的變數,例如,下面的代碼就有錯誤,而無法通過編譯:
public class Test {
public static void main(String[] args) {
int n;
{
int k;
int n;//java: 已在方法 main(java.lang.String[])中定義了變數 n
}
}
}
9.3.5 中斷流程
- break:用于 switch,for,while, do while流程
- continue:用于除 switch 之外的所有流程;while或者do while中continue陳述句將控制轉移到最內層回圈的首部;for中跳到回圈的“ 更新” 部分
10.大數值
10.1 使用場景
如果基本的整數和浮點數精度不能夠滿足需求, 那么可以使用jaVa.math 包中的兩個很有用的類:Biglnteger 和BigDecimaL 這兩個類可以處理包含任意長度數字序列的數值,Biglnteger 類實作了任意精度的整數運算, BigDecimal實作了任意精度的浮點數運算
10.2 注意
遺憾的是,不能使用人們熟悉的算術運算子(如:+ 和 *) 處理大數值,應該使用給定的方法
下邊是一個抽獎概率計算的程式,因為是需要數值精準所以使用了 大數值 來進行計算程式結果
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
System.out.print("How many numbers do you need to draw? ");
int k = in.nextInt();
System.out.print("What is the highest number you can draw? ");
int n = in.nextInt();
BigInteger lotteryOdds = BigInteger.valueOf(1);
for (int i = 1; i <= k; i++) {
//otteryOdds = lotteryOdds *(n - i + 1) / i;
lotteryOdds = lotteryOdds.multiply(BigInteger.valueOf(n - i + 1)).divide(BigInteger.valueOf(i));
}
System.out.println("Your odds are 1 /" + lotteryOdds + ".Good luck !");
}
}
//How many numbers do you need to draw? 1
//What is the highest number you can draw? 2
//Your odds are 1 in 2.Good luck !
10.3 常用 API
| 函式原型 | 簡介 |
|---|---|
| Biglnteger add(Biglnteger other) | |
| Biglnteger subtract(Biglnteger other) | |
| Biglnteger multipiy(Biginteger other) | |
| Biglnteger divide(Biglnteger other) | |
| Biglnteger mod(Biglnteger other) | 返冋這個大整數和另一個大整數 other的和、 差、 積、 商以及余數, |
| int compareTo(Biglnteger other) | 如果這個大整數與另一個大整數 other 相等, 回傳 0; 如果這個大整數小于另一個大整 |
| 數 other, 回傳負數; 否則, 回傳正數 | |
| static Biglnteger valueOf(1 ong x) | 回傳值等于 x 的大整數, |
| BigDecimal add(BigDecimal other) | |
| BigDecimal subtract(BigDecimal other) | |
| BigDecimal multipiy(BigDecimal other) | |
| BigDecimal divide(BigDecimal other RoundingMode mode) | 回傳這個大實數與另一個大實數 other 的和、 差、 積、 商,要想計算商, 必須給出舍入方式 ( rounding mode,) RoundingMode.HALF UP 是在學校中學習的四舍五入方式( BP , 數值 0 到 4 舍去, 數值 5 到 9 進位),它適用于常規的計算,有關其他的舍入方 |
| int compareTo(BigDecimal other) | 如果這個大實數與另一個大實數相等, 回傳 0 ; 如果這個大實數小于另一個大實數,回傳負數;否則,回傳正數 |
| static BigDecimal valueOf(1 ong x) | |
| static BigDecimal valueOf(1 ong x ,int scale) | 回傳值為 X 或 x / 10scale 的一個大實數 |
11.陣列
11.1 一維陣列創建&賦值
public class Test {
public static void main(String[] args) {
int len = 4;
int[] arr1 = new int[len];//陣列長度不要求是常量: newint[n] 會創建一個長度為 n 的陣列
int[] arr2 = new int[]{1, 2, 3, 4};
int[] arr3 = {1, 2, 3, 4};
for (int i = 0; i < arr1.length; i++) {
arr1[i] = i;
}
System.out.println(Arrays.toString(arr1));
}
}
//[0, 1, 2, 3]
- 陣列長度為 0 與 null 不同
- 要想獲得陣列中的元素個數,可以使用 array.length
- 陣列訪問不可越界
- 一旦創建了陣列, 就不能再改變它的大小(盡管可以改變每一個陣列元素)0 如果經常需要在運行程序中擴展陣列的大小, 就應該使用另一種資料結構—陣列串列
11.2 一維陣列列印輸出
- 利用 Arrays 類的 toString 方法, 呼叫 Arrays.toString(a), 回傳一個包含陣列元素的字串,這些元素被放置在括號內, 并用逗號分隔
- for回圈遍歷:可以輸出全部也可以輸出指定部分
- foreach遍歷:不關心下標越界,輸出所有元素
- 利用 Arrays 類的 toString 方法
11.3 陣列拷貝
在 Java 中,允許將一個陣列變數拷貝給另一個陣列變數,這時, 兩個變數將參考同一個陣列
arr.clone():陣列本身的一個拷貝可以復制給其它同型別的陣列
int[] arr = {1, 2, 3, 4, 5, 6};
int[] newArr = arr.clone();
去和區分深淺拷貝:如果拷貝的是簡單型別的資料則是深拷貝【記憶體中重新拷貝了一份資料】;如果是拷貝的參考型別就是淺拷貝【拷貝的參考,副本的修改也會改變元資料】
public class Test {
public static void main(String[] args) {
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 };
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
System.out.println(Arrays.toString(smallPrimes));
System.out.println(Arrays.toString(luckyNumbers));
}
}
//[2, 3, 5, 7, 11, 12]
//[2, 3, 5, 7, 11, 12]
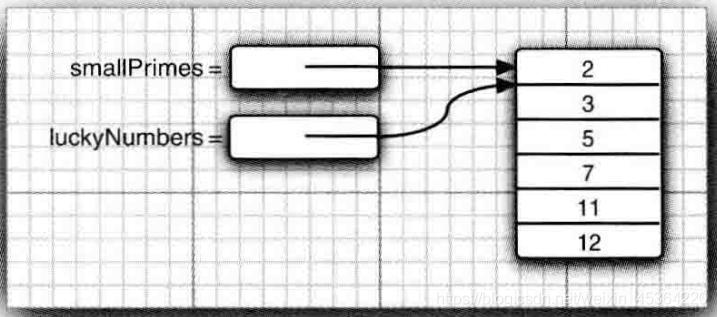
如果希望將一個陣列的所有值拷貝到一個新的陣列中去,就要使用 Arrays 類的 copyOf方法
public class Test {
public static void main(String[] args) {
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 };
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers , luckyNumbers .length);
System.out.println(Arrays.toString(copiedLuckyNumbers));
}
}
//[2, 3, 5, 7, 11, 12]
第 2 個引數是新陣列的長度,這個方法通常用來增加陣列的大小
public class Test {
public static void main(String[] args) {
int[] smallPrimes = {2, 3, 5, 7, 11, 13};
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers, luckyNumbers.length);
System.out.println(luckyNumbers.length);
luckyNumbers = Arrays.copyOf(luckyNumbers, 2 * luckyNumbers.length);
System.out.println(luckyNumbers.length);
}
}
//6
//12
如果陣列元素是數值型,那么多余的元素將被賦值為 0 ; 如果陣列元素是布爾型,則將賦值 為false,相反,如果長度小于原始陣列的長度,則只拷貝最前面的資料元素
Java 陣列與 C++ 陣列在堆疊上有很大不同, 但基本上與分配在堆(heap) 上 的陣列指標一樣,也就是說
int[] a = new int[100];//Java
不同于
int a[100]; // C++
而等同于
int* a = new int[100];//C++
Java 中的 [ ] 運算子被預定義為檢查陣列邊界,而且沒有指標運算, 即不能通過 a 加 1 得到陣列的下一個元素,
11.4 命令列引數
前面已經看到多個使用 Java 陣列的示例, 每一個 Java 應用程式都有一個帶 String arg[ ]引數的 main 方法,這個引數表明 main 方法將接收一個字串陣列, 也就是命令列引數
public class Test {
public static void main(String[] args) {
if (args.length == 0 || args[0].equals("-h"))
System.out.print("Hello, ");
else if (args[0].equals("-g"))
System.out.print("Goodbye, ");
// print the other command-line arguments
for (int i = 1; i < args.length; i++)
System.out.print(args[i]+" ");
System.out.println("!");
}
}
args[0] 是“ -h/-g”, 而不是“ Miss
java Test.java -g Miss Zhu is a charmous Girl
java Test.java -h Miss Zhu is a charmous Girl

11.5 陣列排序
要想對數值型陣列進行排序, 可以使用 Arrays 類中的 sort 方法
public class Test {
public static void main(String[] args) {
int[] arr = {1,3,5,7,9,2,4,6,8,10};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
產生一個抽彩游戲中的亂數值組合
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
//填充資料個數
System.out.print("How many numbers do you need to draw? ");
int k = in.nextInt();
//所能填充的最大資料
System.out.print("What is the highest number you can draw? ");
int n = in.nextInt();
int[] numbers = new int[n];
//填充資料
for (int i = 0; i < numbers.length; i++) {
numbers[i] = i + 1;
}
//k 個資料放入第二個陣列
int[] result = new int[k];
for (int i = 0; i < result.length; i++) {
//隨機生成 0~n-1
int r = (int) (Math.random() * n);
//選取任意位置的元素
result[i] = numbers[r];
//移動最后一個元素到隨機位置
numbers[r] = numbers[n - 1];
--n;
}
Arrays.sort(result);
System.out.println("Bet the following combination. It'll make you rich!");
for (int r : result) {
System.out.println(r);
}
}
}
11.6 常用 API
| 函式原型 | 簡介 |
|---|---|
| static String toString(type[]a) | 回傳包含 a 中資料元素的字串, 這些資料元素被放在括號內, 并用逗號分隔,引數: a 型別為 int、long、short、 char、 byte、boolean、float 或 double 的陣列 |
| static type copyOf(type[]a, int length) | |
| static type copyOfRange(type[]a , int start, int end) | 回傳與 a 型別相同的一個陣列, 其長度為 length 或者 end-start, 陣列元素為 a 的值,引數:a 型別為 int、 long、 short、 char、 byte、boolean、 float 或 double 的陣列,start 起始下標(包含這個值)end 終止下標(不包含這個值),這個值可能大于 a.length, 在這種情況下,結果為 0 或 false,length 拷貝的資料元素長度,如果 length 值大于 a.length, 結果為 0 或 false ;否則, 陣列中只有前面 length 個資料元素的拷 W 值,參 static void sort(t y p e [ 2 a)采用優化的快速排序演算法對陣列進行排序,引數:a 型別為 int、long、short、char、byte、boolean、float 或 double 的陣列 |
| static int binarySearch(type[] a , type v) | |
| static int binarySearch(type[]a, int start, int end, type v) | 采用二分搜索演算法查找值 v,如果查找成功, 則回傳相應的下標值; 否則, 回傳一個負數值 ,r -r-1 是為保持 a 有序 v 應插入的位置,引數:a 型別為 int、 long、 short、 char、 byte、 boolean 、 float 或 double 的有序陣列,start 起始下標(包含這個值),end 終止下標(不包含這個值,)v: 同 a 的資料元素型別相同的值, |
| static void sort(type[] a) | 采用優化的快速排序演算法對陣列進行排序,引數:a 型別為 int、long、short、char、byte、boolean、float 或 double 的陣列 |
| static void fill(type[]a , type v) | 將陣列的所有資料元素值設定為 V,引數:a 型別為 int、 long、short、 char、byte、boolean、float 或 double 的陣列,v 與 a 資料元素型別相同的一個值, |
| static boolean equals(type[]a, type[] b) | 如果兩個陣列大小相同, 并且下標相同的元素都對應相等, 回傳 true,引數:a、 b 型別為 int、long、short、char、byte、boolean、float 或 double 的兩個陣列, |
11.7 多維陣列
11.7.1 初始化和創建
public class Test {
public static void main(String[] args) {
double[][] balances;
balances = new double[4][4];
double[][] arr = new double[4][4];
//如果知道陣列元素, 就可以不呼叫 new, 而直接使用簡化的書寫形式對多維陣列進行初始化
int[][] magicSquare =
{
{16, 3, 2, 13},
{5, 10, 11, 8},
{9, 6, 7, 12},
{4, 15, 14, 1}
};
for (int[] row : magicSquare) {
for (int x : row) {
System.out.print(x + " ");
}
System.out.println();
}
System.out.println("======================");
System.out.println(Arrays.deepToString(magicSquare));
}
}
//16 3 2 13
//5 10 11 8
//9 6 7 12
//4 15 14 1
//======================
//[[16, 3, 2, 13], [5, 10, 11, 8], [9, 6, 7, 12], [4, 15, 14, 1]]
for each 回圈陳述句不能自動處理二維陣列的每一個元素,它是按照行, 也就是一維陣列處理的要想訪問二維教組 a 的所有元素,> 需要使用兩個嵌套的回圈
要想快速地列印一個二維陣列的資料元素串列, 可以呼叫:System.out.println(Arrays.deepToString(magicSquare))
11.7 不規則陣列
Java 實際上沒有多維陣列,只有一維陣列,多維陣列被解釋為“ 陣列的陣列,”例如, 在前面的示例中, balances 陣列實際上是一個包含 10 個元素的陣列,而每個元素又是一個由 6 個浮點陣列成的陣列
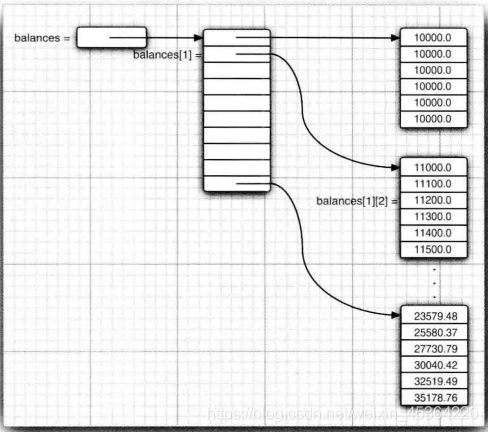
與C++區分:
doublet][] balances = new double[10][6]; // Java
不同于
double balances [10] [6]; // C++
也不同于
double (balances)[6] = new double[10] [6]; // C++
而是分配了一個包含 10 個指標的陣列:
double* balances = new double*[10]; // C++
然后, 指標陣列的每一個元素被填充了一個包含 6 個數字的陣列:
for (i = 0; i < 10; i++)
balances[i] = new double [6] ;
慶幸的是, 當創建 new double[10][6] 時, 這個回圈將自動地執行,當需要不規則的陣列時, 只能單獨地創建行陣列
構造一個“ 不規則” 陣列, 即陣列的每一行有不同的長度,下面是一個典型的示例,在這個示例中,創建一個陣列, 第 i 行第 j 列將存放“ 從 i 個數值中抽取 j 個數值”產生的結果
public class Test {
public static void main(String[] args) {
final int MAX = 10;
int[][] odds = new int[MAX + 1][];
//創建不規則陣列
for (int i = 0; i <= MAX; i++) {
odds[i] = new int[i + 1];
}
//填充資料
for (int i = 0; i < odds.length; i++) {
for (int j = 0; j < odds[i].length; j++) {
int lotteryOdds = 1;
for (int k = 1; k <= j; k++) {
lotteryOdds = lotteryOdds * (i - k + 1) / k;
}
odds[i][j] = lotteryOdds;
}
}
//列印
for (int[] row : odds) {
for (int odd : row) {
System.out.printf("%-4d", odd);
}
System.out.println();
}
}
}
//1
//1 1
//1 2 1
//1 3 3 1
//1 4 6 4 1
//1 5 10 10 5 1
//1 6 15 20 15 6 1
//1 7 21 35 35 21 7 1
//1 8 28 56 70 56 28 8 1
//1 9 36 84 126 126 84 36 9 1
//1 10 45 120 210 252 210 120 45 10 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292476.html
標籤:java