歡迎大家來到“Python從零到壹”,在這里我將分享約200篇Python系列文章,帶大家一起去學習和玩耍,看看Python這個有趣的世界,所有文章都將結合案例、代碼和作者的經驗講解,真心想把自己近十年的編程經驗分享給大家,希望對您有所幫助,文章中不足之處也請海涵,Python系列整體框架包括基礎語法10篇、網路爬蟲30篇、可視化分析10篇、機器學習20篇、大資料分析20篇、影像識別30篇、人工智能40篇、Python安全20篇、其他技巧10篇,您的關注、點贊和轉發就是對秀璋最大的支持,知識無價人有情,希望我們都能在人生路上開心快樂、共同成長,
前一篇文章講述了分類演算法的原理知識級案例,包括決策樹、KNN、SVM,并通過詳細的分類對比實驗和可視化邊界分析與大家總結,本文將詳細講解資料預處理、Jieba分詞和文本聚類知識,這篇文章可以說是文本挖掘和自然語言處理的入門文章,兩萬字基礎文章,希望對您有所幫助,
文章目錄
- 一.資料預處理概述
- 二.中文分詞
- 1.中文分詞技術
- 2.Jieba中文分詞用法
- 三.資料清洗
- 1.資料清洗概述
- 2.中文語料清洗
- 四.特征提取及向量空間模型
- 1.特征規約
- 2.向量空間模型
- 3.余弦相似度計算
- 五.權重計算
- 1.常用權重計算方法
- 2.TF-IDF
- 3.Sklearn計算TF-IDF
- 六.文本聚類
- 七.總結
下載地址:
- https://github.com/eastmountyxz/Python-zero2one
前文賞析:
第一部分 基礎語法
- [Python從零到壹] 一.為什么我們要學Python及基礎語法詳解
- [Python從零到壹] 二.語法基礎之條件陳述句、回圈陳述句和函式
- [Python從零到壹] 三.語法基礎之檔案操作、CSV檔案讀寫及面向物件
第二部分 網路爬蟲
- [Python從零到壹] 四.網路爬蟲之入門基礎及正則運算式抓取博客案例
- [Python從零到壹] 五.網路爬蟲之BeautifulSoup基礎語法萬字詳解
- [Python從零到壹] 六.網路爬蟲之BeautifulSoup爬取豆瓣TOP250電影詳解
- [Python從零到壹] 七.網路爬蟲之Requests爬取豆瓣電影TOP250及CSV存盤
- [Python從零到壹] 八.資料庫之MySQL基礎知識及操作萬字詳解
- [Python從零到壹] 九.網路爬蟲之Selenium基礎技術萬字詳解(定位元素、常用方法、鍵盤滑鼠操作)
- [Python從零到壹] 十.網路爬蟲之Selenium爬取在線百科知識萬字詳解(NLP語料構造必備技能)
第三部分 資料分析和機器學習
- [Python從零到壹] 十一.資料分析之Numpy、Pandas、Matplotlib和Sklearn入門知識萬字詳解(1)
- [Python從零到壹] 十二.機器學習之回歸分析萬字總結全網首發(線性回歸、多項式回歸、邏輯回歸)
- [Python從零到壹] 十三.機器學習之聚類分析萬字總結全網首發(K-Means、BIRCH、層次聚類、樹狀聚類)
- [Python從零到壹] 十四.機器學習之分類演算法三萬字總結全網首發(決策樹、KNN、SVM、分類演算法對比)
- [Python從零到壹] 十五.文本挖掘之資料預處理、Jieba工具和文本聚類萬字詳解
作者新開的“娜璋AI安全之家”將專注于Python和安全技術,主要分享Web滲透、系統安全、人工智能、大資料分析、影像識別、惡意代碼檢測、CVE復現、威脅情報分析等文章,雖然作者是一名技術小白,但會保證每一篇文章都會很用心地撰寫,希望這些基礎性文章對你有所幫助,在Python和安全路上與大家一起進步,
前文第一部分詳細介紹了各種Python網路資料爬取方法,但所爬取的語料都是中文知識,在第二部分前面的章節也講述了常用的資料分析模型及實體,這些實體都是針對陣列或矩陣語料進行分析的,那么如何對中文文本語料進行資料分析呢?在本章作者將帶領大家走進文本聚類分析領域,講解文本預處理和文本聚類等實體內容,
一.資料預處理概述
在資料分析和資料挖掘中,通常需要經歷前期準備、資料爬取、資料預處理、資料分析、資料可視化、評估分析等步驟,而資料分析之前的作業幾乎要花費資料工程師近一半的作業時間,其中的資料預處理也將直接影響后續模型分析的好壞,
資料預處理(Data Preprocessing)是指在進行資料分析之前,對資料進行的一些初步處理,包括缺失值填寫、噪聲處理、不一致資料修正、中文分詞等,其目標是得到更標準、高質量的資料,糾正錯誤例外資料,從而提升分析的結果,
圖1是資料預處理的基本步驟,包括中文分詞、詞性標注、資料清洗、特征提取(向量空間模型存盤)、權重計算(TF-IDF)等,
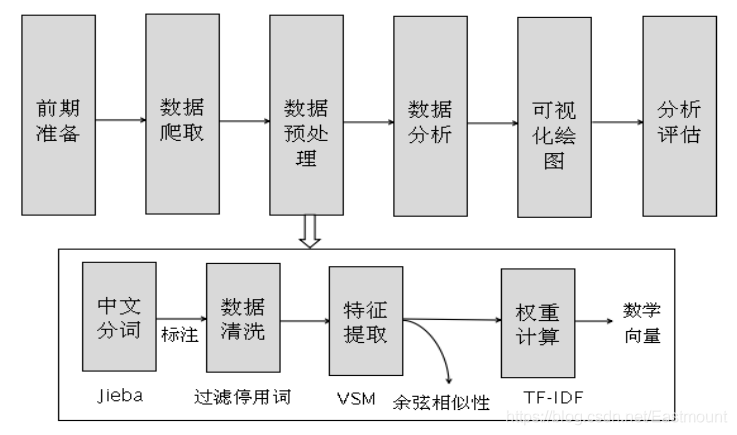
1.中文分詞技術及Jieba工具
在得到語料之后,首先需要做的就是對中文語料進行分詞,由于中文詞語之間是緊密聯系的,一個漢陳述句子是由一串前后連續的漢字組成,詞與詞之間沒有明顯的分界標志,所以需要通過一定的分詞技術把句子分割成空格連接的詞序列,本章介紹了中文常用的分詞技術,同時著重講解了Python常用分詞工具Jieba進行分詞的實體,
2.資料清洗及停用詞過濾
在使用Jieba中文分詞技術得到分完詞的語料后,可能會存在臟資料和停用詞等現象,為了得到更好的資料分析結果,需要對這些資料集進行資料清洗和停用詞過濾等操作,這里利用Jieba庫進行清洗資料,
3.詞性標注
詞性標注是指為分詞結果中的每個單詞或詞組標注一個正確的詞性,即確定每個詞是名詞、動詞、形容詞或其他詞性的程序,通過詞性標注可以確定詞在背景關系中的作用,通常詞性標注是自然語言處理和資料預處理的基礎步驟,Python也提供了相關庫進行詞性標注,

4.特征提取
特征提取是指將原始特征轉換為一組具有明顯物理意義或者統計意義的核心特征,所提取的這組特征可以盡可能地表示這個原始語料,提取的特征通常會存盤至向量空間模型中,向量空間模型是用向量來表征一個文本,它將中文文本轉化為數值特征,本章介紹了特征提取、向量空間模型和余弦相似性的基本知識,同時結合實體進行深入講解,
5.權重計算及TFIDF
在建立向量空間模型程序中,權重的表示尤為重要,常用方法包括布爾權重、詞頻權重、TF-IDF權重、熵權重方法等,本章講述了常用的權重計算方法,并詳細講解了TF-IDF的計算方法和實體,
現在假設存在表1所示的資料集,并存盤至本地test.txt檔案中,整章內容都將圍繞該資料集進行講解,資料集共分為9行資料,包括3個主題,即:貴州旅游、大資料和愛情,接下來依次對數據預處理的各個步驟進行分析講解,
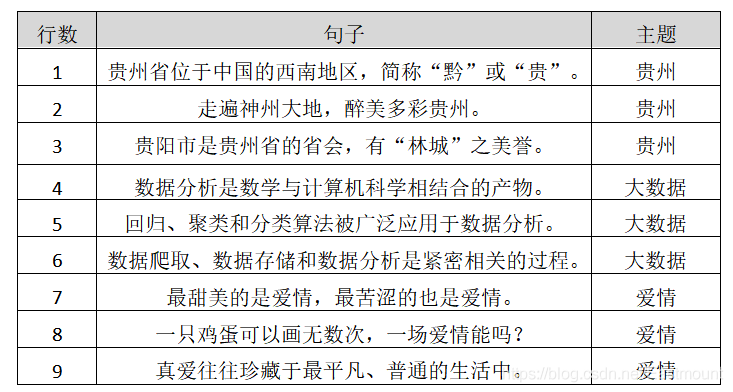
貴州省位于中國的西南地區,簡稱“黔”或“貴”,
走遍神州大地,醉美多彩貴州,
貴陽市是貴州省的省會,有“林城”之美譽,
資料分析是數學與計算機科學相結合的產物,
回歸、聚類和分類演算法被廣泛應用于資料分析,
資料爬取、資料存盤和資料分析是緊密相關的程序,
最甜美的是愛情,最苦澀的也是愛情,
一只雞蛋可以畫無數次,一場愛情能嗎?
真愛往往珍藏于最平凡、普通的生活中,
二.中文分詞
當讀者使用Python爬取了中文資料集之后,首先需要對資料集進行中文分詞處理,由于英文中的詞與詞之間是采用空格關聯的,按照空格可以直接劃分詞組,所以不需要進行分詞處理,而中文漢字之間是緊密相連的,并且存在語意,詞與詞之間沒有明顯的分隔點,所以需要借助中文分詞技術將語料中的句子按空格分割,變成一段段詞序列,下面開始詳細介紹中文分詞技術及Jiaba中文分詞工具,
1.中文分詞技術
中文分詞(Chinese Word Segmentation)指將漢字序列切分成一個個單獨的詞或詞串序列,它能夠在沒有詞邊界的中文字串中建立分隔標志,通常采用空格分隔,中文分詞是資料分析預處理、資料挖掘、文本挖掘、搜索引擎、知識圖譜、自然語言處理等領域中非常基礎的知識點,只有經過中文分詞后的語料才能轉換為數學向量的形式,繼續進行后面的分析,同時,由于中文資料集涉及到語意、歧義等知識,劃分難度較大,比英文復雜很多,下面舉個簡單示例,對句子“我是程式員”進行分詞操作,
輸入:我是程式員
輸出1:我\是\程\序\員
輸出2:我是\是程\程式\序員
輸出3:我\是\程式員
這里分別采用了三種方法介紹中文分詞,
- “我\是\程\序\員”采用的是一元分詞法,將中文字串分隔為單個漢字;
- “我是\是程\程式\序員”采用二元分詞法,將中文漢字兩兩分隔;
- “我\是\程式員”是比較復雜但更實用的分詞方法,它根據中文語意來進行分詞的,其分詞結果更準確,
中文分詞方法有很多,常見的包括:
- 基于字串匹配的分詞方法
- 基于統計的分詞方法
- 基于語意的分詞方法
這里介紹比較經典的基于字串匹配的分詞方法,
基于字串匹配的分詞方法又稱為基于字典的分詞方法,它按照一定策略將待分析的中文字串與機器詞典中的詞條進行匹配,若在詞典中找到某個字串,則匹配成功,并識別出對應的詞語,該方法的匹配原則包括最大匹配法(MM)、逆向最大匹配法(RMM)、逐詞遍歷法、最佳匹配法(OM)、并行分詞法等,
正向最大匹配法的步驟如下,假設自動分詞詞典中的最長詞條所含漢字的個數為n,
- ① 從被處理文本中選取當前中文字串中的前n個中文漢字作為匹配欄位,查找分詞詞典,若詞典中存在這樣一個n字詞,則匹配成功,匹配欄位作為一個詞被切分出來,
- ② 若分詞詞典中找不到這樣的一個n字詞,則匹配失敗,匹配欄位去掉最后一個漢字,剩下的中文字符作為新的匹配欄位,繼續進行匹配,
- ③ 回圈步驟進行匹配,直到匹配成功為止,
例如,現在存在一個句子“北京理工大學生前來應聘”,使用正向最大匹配方法進行中文分詞的程序如下所示,
分詞演算法:正向最大匹配法
輸入字符:北京理工大學生前來應聘
分詞詞典:北京、北京理工、理工、大學、大學生、生前、前來、應聘
最大長度:6
匹配程序:
-
(1)選取最大長度為6的欄位匹配,即“北京理工大學”匹配詞典“北京理工大學”在詞典中沒有匹配欄位,則去除一個漢字,剩余“北京理工大”繼續匹配,該詞也沒有匹配欄位,繼續去除一個漢字,即“北京理工”,分詞詞典中存在該詞,則匹配成功,結果:匹配“北京理工”
-
(2)接著選取長度為6的字串進行匹配,即“大學生前來應” “大學生前來應”在詞典中沒有匹配欄位,繼續從后去除漢字,“大學生” 三個漢字在詞典中匹配成功,結果:匹配“大學生”
-
(3)剩余字串“前來應聘”繼續匹配“前來應聘”在詞典中沒有匹配欄位,繼續從后去除漢字,直到“前來”,結果:匹配“前來”
-
(4)最后的字串“應聘”進行匹配,結果:匹配“應聘”
-
分詞結果:北京理工 \ 大學生 \ 前來 \ 應聘
隨著中文資料分析越來越流行、應用越來越廣,針對其語意特點也開發出了各種各樣的中文分詞工具,常見的分詞工具包括:
- Stanford漢語分詞工具
- 哈工大語言云(LTP -cloud)
- 中國科學院漢語詞法分析系統(ICTCLAS)
- IKAnalyzer分詞
- 盤古分詞
- 庖丁解牛分詞
- …
同時針對Python語言的常見中文分詞工具包括:盤古分詞、Yaha分詞、Jieba分詞等,它們的用法都相差不大,由于結巴分詞速度較快,可以匯入詞典如“頤和園”、“黃果樹瀑布”等專有名詞再進行中文分詞等特點,本文主要介紹結巴(Jieba)分詞工具講解中文分詞,
2.Jieba中文分詞用法
(1) 安裝程序
作者推薦大家使用PIP工具來安裝Jieba中文分詞包,安裝陳述句如下:
pip install jieba
呼叫命令“pip install jieba”安裝jieba中文分詞包如圖所示,
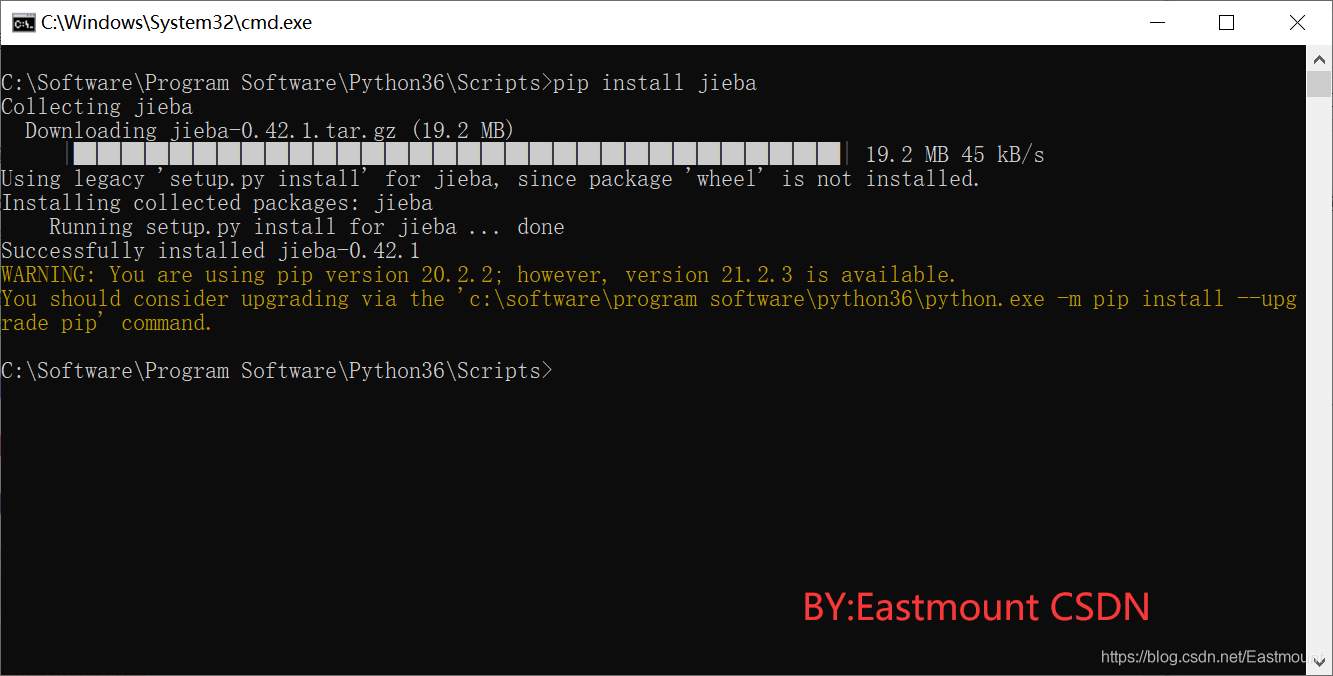
安裝程序中的會顯示安裝配置相關包和檔案的百分比,直到出現“Successfully installed jieba”命令,表示安裝成功,注意,在安裝程序中會遇到各種問題,大家一定要學會獨立搜索答案解決這些問題,才能提升您獨立解決問題的能力,
同時,如果您使用Anaconda Spyder集成環境,則呼叫“Anaconda Prompt”命令列模式輸入“pip install jieba”命令進行安裝,如果您的Python開發環境已經安裝了該擴展包,則會提示已經存在Jieba中文分詞包,如圖所示,

(2) 基礎用法
首先讀者看一段簡單的結巴分詞代碼,
- jieba.cut(text,cut_all=True)
分詞函式,第一個引數是需要分詞的字串,第二個引數表示是否為全模式,分詞回傳的結果是一個可迭代的生成器(generator),可使用for回圈來獲取分詞后的每個詞語,更推薦讀者轉換為list串列再使用, - jieba.cut_for_search(text)
搜索引擎模式分詞,引數為分詞的字串,該方法適合用于搜索引擎構造倒排索引的分詞,粒度比較細,
#coding=utf-8
#By:Eastmount CSDN
import jieba
text = "小楊畢業于北京理工大學,從事Python人工智能相關作業,"
#全模式
data = jieba.cut(text,cut_all=True)
print(type(data))
print(u"[全模式]: ", "/".join(data))
#精確模式
data = jieba.cut(text,cut_all=False)
print(u"[精確模式]: ", "/".join(data))
#默認是精確模式
data = jieba.cut(text)
print(u"[默認模式]: ", "/".join(data))
#搜索引擎模式
data = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/".join(data))
#回傳串列
seg_list = jieba.lcut(text, cut_all=False)
print("[回傳串列]: {0}".format(seg_list))
輸出結果如下所示,

最終的分詞結果比較理想,其中精確模式輸出的“小/楊/畢業/于/北京理工大學/,/從事/Python/人工智能/相關/作業/,”比較精準,下面簡單敘述結巴中文分詞的三種分詞模式,
全模式
該模式將語料中所有可以組合成詞的詞語都構建出來,其優點是速度非常快,缺點是不能解決歧義問題,并且分詞結果不太準確,其分詞結果為“小/楊/畢業/于/北京/北京理工/北京理工大學/理工/理工大/理工大學/工大/大學///從事/Python/人工/人工智能/智能/相關/作業//”,
精確模式
該模式利用其演算法將句子最精確地分隔開,適合文本分析,通常采用這種模式進行中文分詞,其分詞結果為“小/楊/畢業/于/北京理工大學/,/從事/Python/人工智能/相關/作業/,”,其中“北京理工大學”、“人工智能”這些完整的名詞被精準識別,但也有部分詞未被識別,后續匯入詞典可以實作專有詞匯識別,
搜索引擎模式
該模式是在精確模式基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞,其結果為“小/楊/畢業/于/北京/理工/工大/大學/理工大/北京理工大學/,/從事/Python/人工/智能/人工智能/相關/作業/,”,
Python提供的結巴(Jieba)中文分詞包主要利用基于Trie樹結構實作高效的詞圖掃描(構建有向無環圖DAG)、動態規劃查找最大概率路徑(找出基于詞頻的最大切分組合)、基于漢字成詞能力的HMM模型等演算法,這里不進行詳細敘述,本書更側重于應用案例,同時結巴分詞支持繁體分詞和自定義字典方法,
- ==load_userdict(f) ==
(3) 中文分詞實體
下面對表1中的語料進行中文分詞,代碼為依次讀取檔案中的內容,并呼叫結巴分詞包進行中文分詞,然后存盤至本地檔案中,
#coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
source = open("test.txt", 'r')
line = source.readline().rstrip('\n')
content = []
while line!="":
seglist = jieba.cut(line,cut_all=False) #精確模式
output = ' '.join(list(seglist)) #空格拼接
print(output)
content.append(output)
line = source.readline().rstrip('\n')
else:
source.close()
輸出如圖所示,可以看到分詞后的語料,

三.資料清洗
在分析語料的程序中,通常會存在一些臟資料或噪聲詞組干擾我們的實驗結果,這就需要對分詞后的語料進行資料清洗(Data Cleaning),比如前面使用Jieba工具進行中文分詞,它可能存在一些臟資料或停用詞,如“我們”、“的”、“嗎”等,這些詞降低了資料質量,為了得到更好的分析結果,需要對資料集進行資料清洗或停用詞過濾等操作,本節主要介紹資料清洗概念、中文資料清洗技術及停用詞過濾,并利用Jieba分詞工具進行停用詞和標點符號的清洗,
1.資料清洗概述
臟資料通常是指資料質量不高、不一致或不準確的資料,以及人為造成的錯誤資料等,作者將常見的臟資料分為四類:
- 殘缺資料
該類資料是指資訊存在缺失的資料,通常需要補齊資料集再寫入資料庫或檔案中,比如統計9月份30天的銷售資料,但期間某幾天資料出現丟失,此時需要對資料進行補全操作, - 重復資料
資料集中可能存在重復資料,此時需要將重復資料匯出讓客戶確認并修正資料,從而保證資料的準確性,在清洗轉換階段,對于重復資料項盡量不要輕易做出洗掉決策,尤其不能將重要的或有業務意義的資料過濾掉,校驗和重復確認的作業是必不可少的, - 錯誤資料
該類臟資料常常出現在網站資料庫中,是指由于業務系統不夠健全,在接收輸入后沒有進行判斷或錯誤操作直接寫入后臺資料庫造成的,比如字串資料后緊跟一個回車符、不正確的日期格式等,這類錯誤可以通過去業務系統資料庫用SQL陳述句進行挑選,再交給業務部門修正, - 停用詞
分詞后的語料并不是所有的詞都與檔案內容相關,往往存在一些表意能力很差的輔助性詞語,比如中文詞組“我們”、“的”、“可以”等,英文詞匯“a”、“the”等,這類詞在自然語言處理或資料挖掘中被稱為停用詞(Stop Words),它們是需要進行過濾的,通常借用停用詞表或停用詞字典進行過濾,
資料清洗主要解決臟資料,從而提升資料質量,它主要應用于資料倉庫、資料挖掘、資料質量管理等領域,讀者可以簡單將資料清洗定位為:只要是有助于解決資料質量問題的處理程序就被認為是資料清洗,不同領域的資料清洗定義有所不同,總之,資料清洗的目的是保證資料質量,提供準確資料,其任務是通過過濾或者修改那些不符合要求的資料,從而更好地為后面的資料分析作鋪墊,
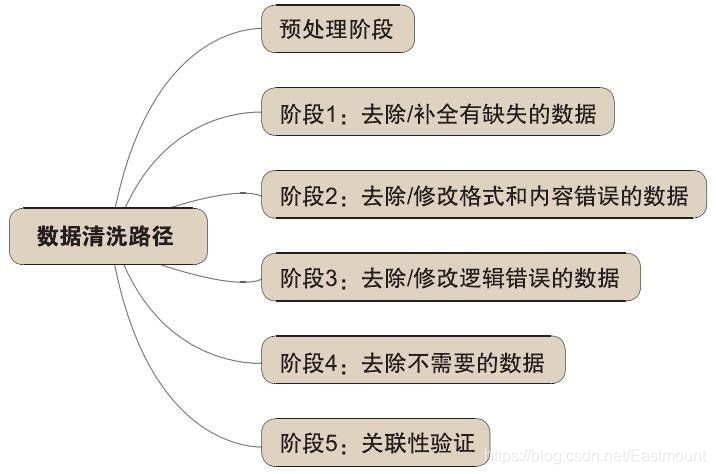
為了解決上述問題,將資料清洗方法劃分為:
- 解決殘缺資料
對于空值或缺失資料,需要采用估算填充方法解決,常見的估算方法包括樣本均值、中位數、眾數、最大值、最小值等填充,比如選取所有資料的平均值來填充缺失資料,這些方法會存在一定的誤差,如果空值資料較多,則會對結果造成影響,偏離實際情況, - 解決重復資料
簡單的重復資料需要人為識別,而計算機解決重復資料的方法較為復雜,其方法通常會涉及到物體識別技術,采用有效的技術識別處相似的資料,這些相似資料指向同一物體,再對這些重復資料進行修正, - 解決錯誤資料
對于錯誤資料,通常采用統計方法進行識別,如偏差分析、回歸方程、正態分布等,也可以用簡單的規則庫檢測數值范圍,使用屬性間的約束關系來校對這些資料, - 解決停用詞
停用詞概念由Hans Peter Luhn提出,并為資訊處理做出了巨大的貢獻,通常存在一個存放停用詞的集合,叫做停用詞表,停用詞往往由人工根據經驗知識加入,具有通用性,解決停用詞的方法即利用停用詞詞典或停用詞表進行過濾,比如“并”、“當”、“地”、“啊”等字都沒有具體的含義,需要過濾,還存在一些如“我們”、“但是”、“別說”、“而且”等詞組也需要過濾,
2.中文語料清洗
前面已將Python爬取的中文文本語料進行了分詞處理,接下來 需要對其進行資料清洗操作,通常包括停用詞過濾和特殊標點符號去除等,而對于空值資料、重復資料,作者更建議大家在資料爬取程序中就進行簡單的判斷或補充缺失值,下面對表1所提供的中文語料(包括貴州、大資料和愛情三個主題)進行資料清洗實體操作,
(1) 停用詞過濾
上圖是使用結巴工具中文分詞后的結果,但它存在一些出現頻率高卻不影響文本主題的停用詞,比如“資料分析是數學與計算機科學相結合的產物”句子中的“是”、“與”、“的”等詞,這些詞在預處理時是需要進行過濾的,
這里作者定義一個符合該資料集的常用停用詞表的陣列,然后將分詞后的序列,每一個字或詞組與停用詞表進行比對,如果重復則洗掉該詞語,最后保留的文本能盡可能地反應每行語料的主題,代碼如下:
#coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
#停用詞表
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '與',
'和', '也', '被', '嗎', '于', '中', '最'])
source = open("test.txt", 'r')
line = source.readline().rstrip('\n')
content = [] #完整文本
while line!="":
seglist = jieba.cut(line,cut_all=False) #精確模式
final = [] #存盤去除停用詞內容
for seg in seglist:
if seg not in stopwords:
final.append(seg)
output = ' '.join(list(final)) #空格拼接
print(output)
content.append(output)
line = source.readline().rstrip('\n')
else:
source.close()
其中stopwords變數定義了停用詞表,這里只列舉了與我們test.txt語料相關的常用停用詞,而在真實的預處理中,通常會從檔案中匯入常見的停用詞表,包含了各式各樣的停用詞,讀者可以去網上搜索查看,
核心代碼是for回圈判斷分詞后的語料是否在停用詞表中,如果不在則添加到新的陣列final中,最后保留的就是過濾后文本,如圖所示,

(2) 去除標點符號
在做文本分析時,標點符號通常也會被算成一個特征,從而影響分析的結果,所以我們需要把標點符號也進行過濾,其過濾方法和前面過濾停用詞的方法一致,建立一個標點符號的陣列或放到停用詞stopwords中,停用詞陣列如下:
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '與',
'和', '也', '被', '嗎', '于', '中', '最',
'“', '”', ',', ',', '?', '、', ';'])
同時將文本內容存盤至本地result.txt檔案中,完整代碼如下:
# coding=utf-8
#By:Eastmount CSDN
import os
import codecs
import jieba
import jieba.analyse
#停用詞表
stopwords = {}.fromkeys(['的', '或', '等', '是', '有', '之', '與',
'和', '也', '被', '嗎', '于', '中', '最',
'“', '”', ',', ',', '?', '、', ';'])
source = open("test.txt", 'r')
result = codecs.open("result.txt", 'w', 'utf-8')
line = source.readline().rstrip('\n')
content = [] #完整文本
while line!="":
seglist = jieba.cut(line,cut_all=False) #精確模式
final = [] #存盤去除停用詞內容
for seg in seglist:
if seg not in stopwords:
final.append(seg)
output = ' '.join(list(final)) #空格拼接
print(output)
content.append(output)
result.write(output + '\r\n')
line = source.readline().rstrip('\n')
else:
source.close()
result.close()
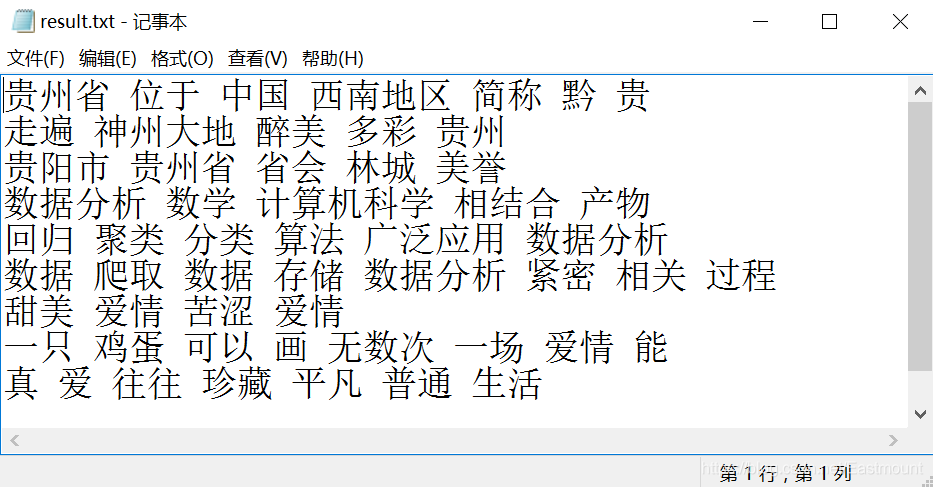
輸出結果如圖7所示,得到的語料非常精煉,盡可能的反應了文本主題,其中1-3行為貴州旅游主題、4-6為大資料主題、7-9位愛情主題,
四.特征提取及向量空間模型
本小節主要介紹特征提取、向量空間模型和余弦相似性的基礎知識,并用表21.1所提供的語料進行基于向量空間模型的余弦相似度計算,
1.特征規約
經過網路爬取、中文分詞、資料清洗后的語料通常稱為初始特征集,而初始特征集通常都是由高維資料組成,并且不是所有的特征都很重要,高維資料中可能包含不相關的資訊,這會降低演算法的性能,甚至高維資料會造成維數災難,影響資料分析的結果,
研究發現,減少資料的冗余維度(弱相關維度)或提取更有價值的特征能夠有效地加快計算速度,提高效率,也能夠確保實驗結果的準確性,學術上稱為特征規約,
特征規約是指選擇與資料分析應用相關的特征,以獲取最佳性能,并且處理的作業量更小,特征規約包含兩個任務:特征選擇和特征提取,它們都是從原始特征中找出最有效的特征,并且這些特征能盡可能地表征原始資料集,
(1) 特征提取
特征提取是將原始特征轉換為一組具有明顯物理意義或者統計意義的核心特征,所提取的這組特征可以盡可能地表示這個原始語料,特征提取分為線性特征提取和非線性特征提取,其中線性特征提取常見的方法包括:
- PCA主成分分析方法,該方法尋找表示資料分布的最優子空間,將原始資料降維并提取不相關的部分,常用于降維,參考前面聚類那篇文章,
- LDA線性判別分析方法,該方法尋找可分性判據最大的子空間,
- ICA獨立成分分析方法,該方法將原始資料降維并提取出相互獨立的屬性,尋找一個線性變換,
非線性特征提取常見方法包括Kernel PCA、Kernel FDA等,
(2) 特征選擇
特征選擇是從特征集合中挑選一組最具統計意義的特征,從而實作降維,通常包括產生程序、評價函式、停止準則、驗證程序四個部分,傳統方法包括資訊增益(Information Gain,簡稱IG)法、隨機產生序列選擇演算法、遺傳演算法( Genetic Algorithms,簡稱GA )等,
下圖是影像處理應用中提取Lena圖的邊緣線條特征的實體,可以利用一定量的特征盡可能的描述整個人的輪廓,它和資料分析中的應用也是相同的原理,

2.向量空間模型
向量空間模型(Vector Space Model,簡稱VSM)是通過向量的形式來表征一個檔案,它能夠將中文文本轉化為數值特征,從而進行資料分析,作為目前最為成熟和應用最廣的文本表示模型之一,向量空間模型已經廣泛應用于資料分析、自然語言處理、中文資訊檢索、資料挖掘、文本聚類等領域,并取得了一定成果,
采用向量空間模型來表示一篇文本語料,它將一個檔案(Document)或一篇網頁語料(Web Dataset)轉換為一系列的關鍵詞(Key)或特征項(Term)的向量,
- 特征項(Trem)
特征項是指檔案所表達的內容由它所含的基本語言單位(字、詞、詞組或短語)組成,在文本表示模型中,基本語言單位即稱為文本的特征項,例如文本Doc中包含n個特征項,表示為:
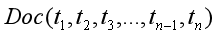
- 特征權重(Trem Weight)
特征權重是指為檔案中的某個特征項ti(1≤ i ≤n)賦予權重wi,以表示該特征項對于檔案內容的重要程度,權重越高的特征項越能反應其在檔案中的重要性,文本Doc中存在n個特征項,即:{t1, t2, t3, … , tn-1, tn},它是一個n維坐標,接著需要計算出各特征項ti在文本中的權重wi,為對應特征的坐標值,按特征權重文本表示如下,其中,WDoc稱為文本Doc的特征向量,
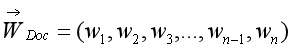
- 檔案表示
得到了特征項和特征權重后,需要表示一篇檔案,則利用下面這個公式,其中,檔案Doc共包含n個特征詞和n個權重,ti是一系列相互之間不同的特征詞,i=1,2,…,n,wi(d)是特征詞ti在檔案d中的權重,它通常可以被表達為ti在d中呈現的頻率,
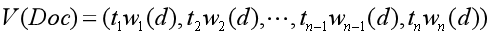
特征項權重W有很多種不同的計算方法,最簡單的方法是以特征項在文本中的出現次數作為該特征項的權重,第五部分將詳細敘述,
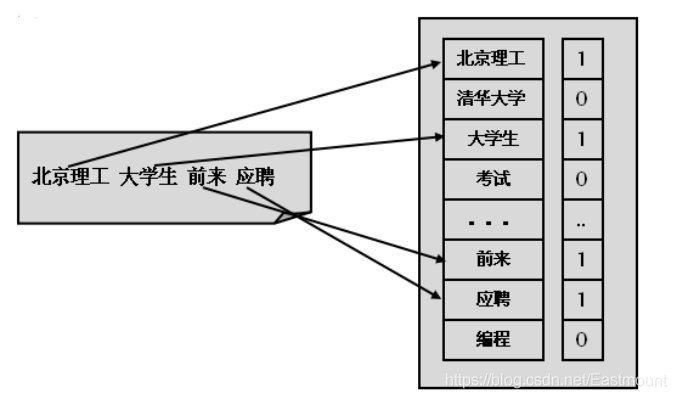
從上圖可以看到,將檔案存盤為詞頻向量的程序,轉換為{1,0,1,0,…,1,1,0}形式,特征項的選取和特征項權重的計算是向量空間模型的兩個核心問題,為了使特征向量更能體現文本內容的含義,要為文本選擇合理的特征項,并且在給特征項賦權重時遵循對文本內容特征影響越大的特征項的權值越大的原則,
3.余弦相似度計算
當使用上面的向量空間模型計算得到兩篇文章的向量后,則可以計算兩篇文章的相似程度,兩篇文章間的相似度通過兩個向量的余弦夾角Cos來描述,文本D1和D2的相似度計算公式如下:
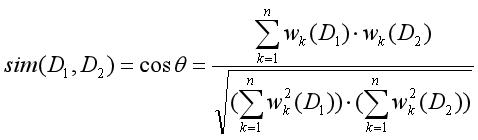
其中,分子表示兩個向量的點乘積,分母表示兩個向量的模的乘積,通過余弦相似性計算后,得到了任意兩篇文章的相似程度,可以將相似程度越高的檔案歸類到同一主題,也可以設定閾值進行聚類分析,該方法的原理是將語言問題轉換為數學問題來解決實際問題,
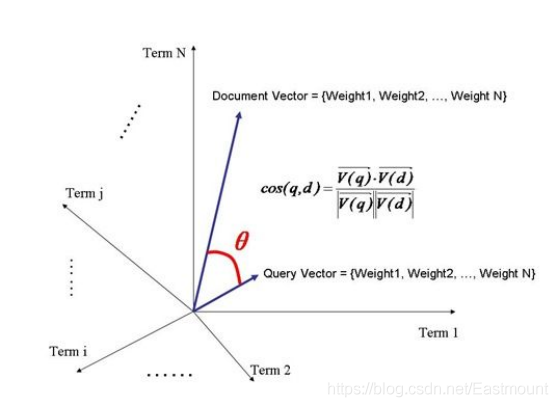
下圖是向量空間模型圖,它展示了檔案Term1、Term2、…、TermN之間的余弦相似度計算方法,如果兩篇檔案越相似,則其夾角θ越小,Cos值越接近于1,當兩篇檔案完全相似時,此時的夾角為0°,Cos值為1,這也展示了余弦相似性的原理知識,
下面我們借用兩個句子來計算其與“北京理工大學生前來應聘”的余弦相似程度,假設存在三個句子,需要看哪一個句子和“北京理工大學生前來應聘”相似程度更高,則認為主題更為類似,那么,如何計算句子A和句子B的相似性呢?
句子1:北京理工大學生前來應聘
句子2:清華大學大學生也前來應聘
句子3: 我喜歡寫代碼
下面采用向量空間模型、詞頻及余弦相似性計算句子2和句子3分別與句子1的相似性,
第一步:中文分詞,
句子1:北京理工 / 大學生 / 前來 / 應聘
句子2:清華大學 / 大學生 / 也 / 前來 / 應聘
句子3: 我 / 喜歡 / 寫 / 代碼
第二步:列出所有詞語,按照詞出現的先后順序,
北京理工 / 大學生 / 前來 / 應聘 / 清華大學 / 也 / 我 / 喜歡 / 寫 / 代碼
第三步:計算詞頻,如表所示,
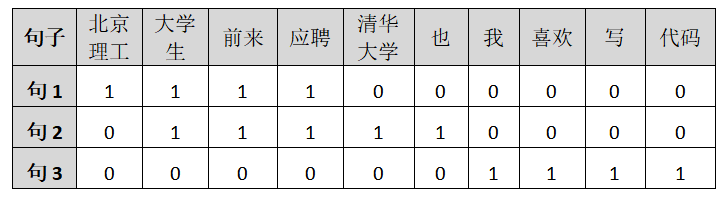
第四步:寫出詞頻向量,
句子1:[1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
句子2:[0, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子3:[0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
第五步:計算余弦相似度,
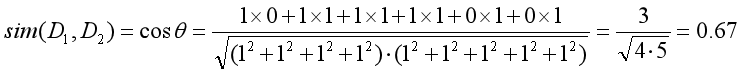
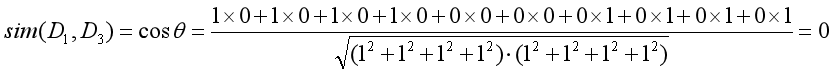
其結果顯示句子1和句子2的相似度為0.67,存在一定的相似主題;而句子1和句子3的相似度為0,完全不相似,
總之,余弦相似度是一種非常有用的演算法,只要是計算兩個向量的相似程度,都可用它,當余弦值越接近1時,表明兩個向量的夾角越接近0度,兩個向量越相似,但余弦相似性作為最簡單的相似度計算方法,也存在一些缺點,如計算量太大、詞之間的關聯性沒考慮等,
五.權重計算
前面講述的詞頻權重計算的方法過于簡單,下面就給大家介紹下其他權重計算方法,
權重計算是指通過特征權重來衡量特征項在檔案表示中的重要程度,給特征詞賦予一定的權重來衡量統計文本特征詞,常用的權重計算方法包括:布爾權重、絕對詞頻、倒檔案詞頻、TF-IDF、TFC、熵權重等,
1.常用權重計算方法
(1) 布爾權重
布爾權重是比較簡單的權重計算方法,設定的權重要么是1,要么是0,如果在文本中出現了該特征詞,則文本向量對應該特征詞的分量賦值為1;如果該特征詞沒有在文本中出現,則分量為0,公式如下所示,其中wij表示特征詞ti在文本Dj中的權重,
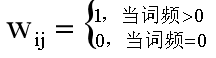
假設特征向量為:
- {北京理工,大學生,前來,應聘,清華大學,也,我,喜歡,寫,代碼}
現在需要計算句子“北京理工大學生前來應聘”的權重,則特征詞在特征向量中存在的,對應分量為1,不存在的對應分量為0,最終特征向量結果為:
- {1,1,1,1,0,0,0,0,0,0}
但是實際應用中,布爾權重0-1值是無法體現特征詞在文本中的重要程度,那就衍生出了詞頻這種方法,
(2) 絕對詞頻
詞頻方法又稱為絕對詞頻(Term Frequency,簡稱TF),它首先計算特征詞在檔案中出現的頻率,再來表征文本,通常使用tfij表示,即特征詞ti在訓練文本Dj中出現的頻率,
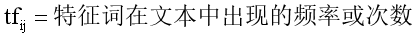
假設句子為“北京理工大學的大學生和清華大學的大學生前來應聘”,而對應的特征詞為:{北京理工,大學生,前來,應聘,清華大學,也,我,喜歡,寫,代碼,的,和},對應詞頻向量為:
- {1,2,1,1,1,0,0,0,0,0,2,1}
前面所采用的向量空間模型計算文本余弦相似性的例子也使用的是詞頻,這是權重計算方法中最簡單、有效的方法之一,
(3) 倒檔案頻率
由于詞頻方法無法體現低頻特征項的區分能力,往往存在某些特征項頻率很高,卻在文本中起到很低影響程度的現象,如“我們”、“但是”、“的”等詞語;同時,有的特征項雖然出現的頻率很低,但表達著整個文本的核心思想,起著至關重要的作用,
倒檔案頻率(Inverse Document Frequency,簡稱IDF)方法是Spark Jones在1972年提出的,用于計算詞與文獻相關權重的經典方法,公式如下:
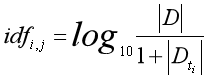
其中,引數|D|表示語料的文本總數,表示文本所包含特征詞ti的數量,
在倒檔案頻率方法中,權重是隨著特征詞的檔案數量的變化呈反向變化,如某些常用詞“我們”、“但是”、“的”等,在所有檔案中出現頻率很高,但它的IDF值卻非常低,甚至如果它每篇檔案都出現,則log1的計算結果為0,從而降低了這些常用詞的作用;相反,如果某篇介紹“Python”的詞,僅僅在該篇檔案中出現,它的作用就非常高,
同樣還有很多權重計算方法,包括TF-IDF、熵權重、TF-IWF、基于錯誤驅動的特征權重演算法等,讀者可以自行研究,這里僅僅簡單引入了最基礎的幾種方法,
2.TF-IDF
TF-IDF(Term Frequency-Invers Document Frequency)是近年來用于資料分析和資訊處理經典的權重計算技術,該技術根據特征詞在文本中出現的次數和在整個語料中出現的檔案頻率來計算該特征詞在整個語料中的重要程度,其優點是能過濾掉一些常見卻無關緊要的詞語,盡可能多的保留影響程度高的特征詞,
其中,TF(Term Frequency)表示某個關鍵詞在整篇文章中出現的頻率或次數,IDF(Invers Document Frequency)表示倒文本頻率,又稱為逆檔案頻率,它是檔案頻率的倒數,主要用于降低所有檔案中一些常見卻對檔案影響不大的詞語的作用,TF-IDF的完整公式如下:
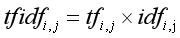
式中tfidfi,j表示詞頻tfi,j和倒文本詞頻idfi的乘積,TF-IDF中權重與特征項在檔案中出現的頻率成正比,與在整個語料中出現該特征項的檔案數成反比,tfidfi,j值越大則該特征詞對這個文本的重要程度越高,
TF詞頻的計算公式如下:
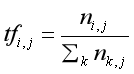
其中,ni,j為特征詞ti在訓練文本Dj中出現的次數,是文本Dj中所有特征詞的個數,計算的結果即為某個特征詞的詞頻,
TF-IDF公式推導如下所示:
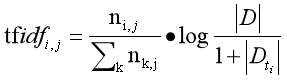
TF-IDF技術的核心思想是如果某個特征詞在一篇文章中出現的頻率TF高,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來做權重計算,TF-IDF演算法簡單快速,結果也符合實際情況,其缺點是單純以詞頻衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數并不多,并且該演算法無法體現詞的位置資訊,
3.Sklearn計算TF-IDF
Scikit-Learn是基于Python的機器學習模塊,基本功能主要分為六個部分:分類、回歸、聚類、資料降維、模型選擇和資料預處理,具體可以參考官方網站上的檔案,本書前面詳細介紹了Scikit-Learn的安裝及使用方法,這里主要使用Scikit-Learn中的兩個類CountVectorizer和TfidfTransformer,用來計算詞頻和TF-IDF值,
- CountVectorizer
該類是將文本詞轉換為詞頻矩陣的形式,比如“I am a teacher”文本共包含四個單詞,它們對應單詞的詞頻均為1,“I”、“am”、“a”、“teacher”分別出現一次,CountVectorizer將生成一個矩陣a[M][N],共M個文本語料,N個單詞,比如a[i][j]表示單詞j在i類文本下的詞頻,再呼叫fit_transform()函式計算各個詞語出現的次數,get_feature_names()函式獲取詞庫中的所有文本關鍵詞,
計算result.txt文本的詞頻代碼如下,下表是表1資料集被中文分詞、資料清洗后的結果,如下所示,
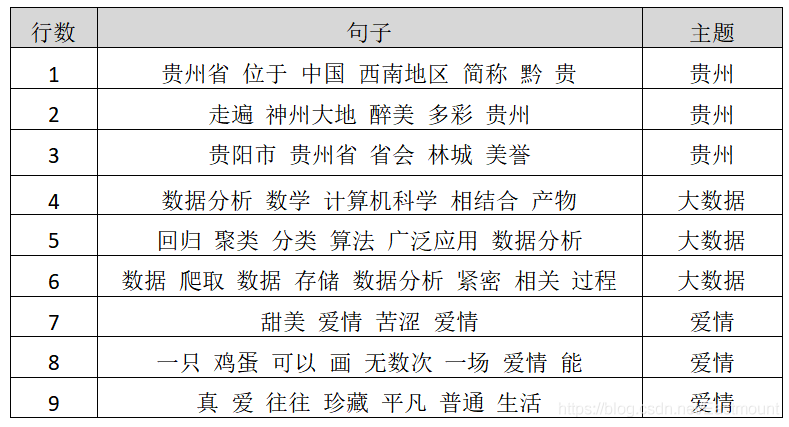
貴州省 位于 中國 西南地區 簡稱 黔 貴
走遍 神州大地 醉美 多彩 貴州
貴陽市 是 貴州省 省會 有 林城 美譽
資料分析 是 數學 計算機科學 相結合 產物
回歸 聚類 分類 演算法 廣泛應用 資料分析
資料 爬取 資料 存盤 資料分析 緊密 相關 程序
最 甜美 愛情 最 苦澀 愛情
一只 雞蛋 可以 畫 無數次 一場 愛情
真愛 往往 珍藏 最 平凡 普通 生活
代碼如下:
#coding:utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
#存盤讀取語料 一行預料為一個檔案
corpus = []
for line in open('result.txt', 'r', encoding="utf-8").readlines():
corpus.append(line.strip())
#將文本中的詞語轉換為詞頻矩陣
vectorizer = CountVectorizer()
#計算個詞語出現的次數
X = vectorizer.fit_transform(corpus)
#獲取詞袋中所有文本關鍵詞
word = vectorizer.get_feature_names()
for n in range(len(word)):
print(word[n],end=" ")
print('')
#查看詞頻結果
print(X.toarray())
輸出如下圖所示,

- TfidTransformer
當使用CountVectorizer類計算得到詞頻矩陣后,接下來通過TfidfTransformer類實作統計vectorizer變數中每個詞語的TF-IDF值,代碼補充如下,
#coding:utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#存盤讀取語料
corpus = []
for line in open('result.txt', 'r', encoding="utf-8").readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer() #將文本中的詞語轉換為詞頻矩陣
X = vectorizer.fit_transform(corpus) #計算個詞語出現的次數
word = vectorizer.get_feature_names() #獲取詞袋中所有文本關鍵詞
for n in range(len(word)):
print(word[n],end=" ")
print('')
print(X.toarray()) #查看詞頻結果
#計算TF-IDF值
transformer = TfidfTransformer()
print(transformer)
tfidf = transformer.fit_transform(X) #將詞頻矩陣X統計成TF-IDF值
#查看資料結構
print(tfidf.toarray()) #tfidf[i][j]表示i類文本中的tf-idf權重
運行部分結果如下圖所示,

TF-IDF值采用矩陣陣列的形式存盤,每一行資料代表一個文本語料,每一行的每一列都代表其中一個特征對應的權重,得到TF-IDF后就可以運用各種資料分析演算法進行分析,比如聚類分析、LDA主題分布、輿情分析等等,
六.文本聚類
獲取文本TF-IDF值之后,本小節簡單講解使用TF-IDF值進行文本聚類的程序,主要包括如下五個步驟:
- 第一步,對中文分詞和資料清洗后的語料進行詞頻矩陣生成操作,主要呼叫CountVectorizer類計算詞頻矩陣,生成的矩陣為X,
- 第二步,呼叫TfidfTransformer類計算詞頻矩陣X的TF-IDF值,得到Weight權重矩陣,
- 第三步,呼叫Sklearn機器學習包的KMeans類執行聚類操作,設定的類簇數n_clusters為3,對應語料貴州、資料分析和愛情的三個主題,然后呼叫fit()函式訓練,并將預測的類標賦值給y_pred陣列,
- 第四步,呼叫Sklearn庫PCA()函式進行降維操作,由于TF-IDF是多維陣列,是9行文本所有特征對應的權重,而在繪圖之前需要將這些特征降低為二維,對應X和Y軸,
- 第五步,呼叫Matplotlib函式進行可視化操作,繪制聚類圖形,并設定圖形引數、標題、坐標軸內容等,
代碼如下,
# coding:utf-8
#By:Eastmount CSDN
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
#第一步 生成詞頻矩陣
corpus = []
for line in open('result.txt', 'r', encoding="utf-8").readlines():
corpus.append(line.strip())
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
for n in range(len(word)):
print(word[n],end=" ")
print('')
print(X.toarray())
#第二步 計算TF-IDF值
transformer = TfidfTransformer()
print(transformer)
tfidf = transformer.fit_transform(X)
print(tfidf.toarray())
weight = tfidf.toarray()
#第三步 KMeans聚類
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3)
s = clf.fit(weight)
y_pred = clf.fit_predict(weight)
print(clf)
print(clf.cluster_centers_) #類簇中心
print(clf.inertia_) #距離:用來評估簇的個數是否合適 越小說明簇分的越好
print(y_pred) #預測類標
#第四步 降維處理
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #降低成兩維繪圖
newData = pca.fit_transform(weight)
print(newData)
x = [n[0] for n in newData]
y = [n[1] for n in newData]
#第五步 可視化
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(x, y, c=y_pred, s=100, marker='s')
plt.title("Kmeans")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
聚類輸出如圖所示,
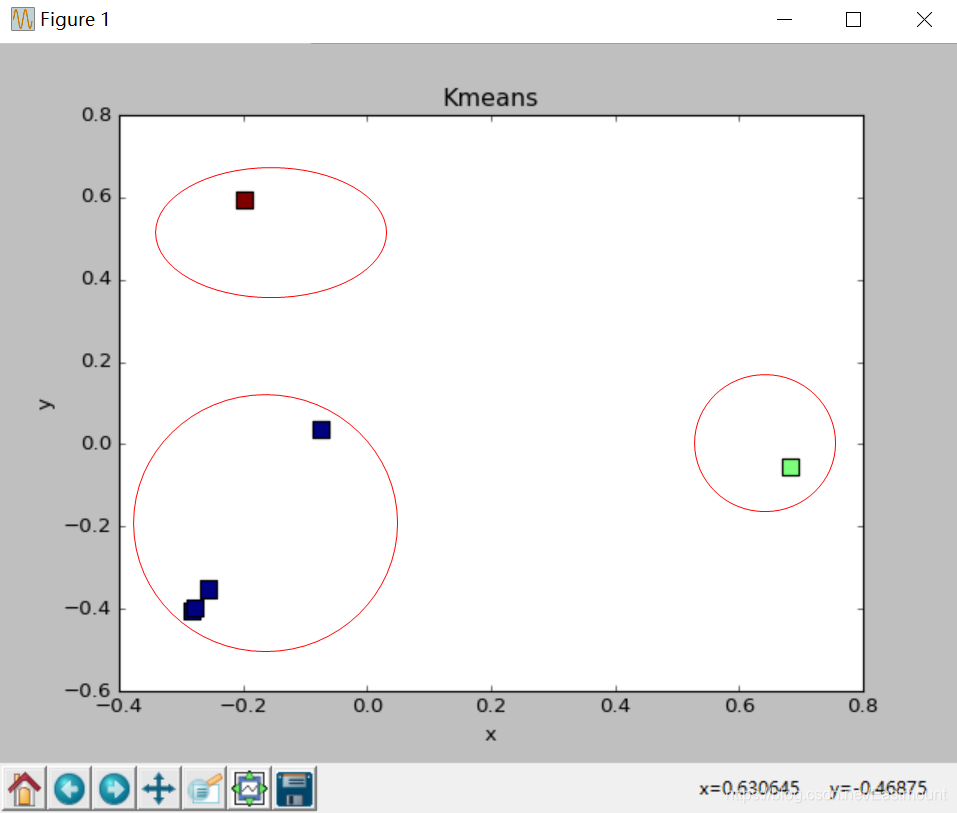
圖中共繪制了6個點,將資料聚集為三類,對應不同的顏色,其中對應的類標為:
- [2 0 2 0 0 0 1 1 0]
它將第1、3行語料聚集在一起,類標為2;第2、4、5、6、9行聚集為一組,類標為0;第7、8行語料聚集為最后一組,類標為1,而真實資料集中,第1、2、3行表示貴州主題,第4、5、6行表示資料分析主題,第7、8、9行表示愛情主題,所以資料分析預測結果會存在一定誤差,我們需要將誤差盡可能的降低,類似于深度學習,也是在不斷學習中進步,
您可能會疑惑為什么9行資料,卻只繪制了6個點呢?下面是9行資料進行降維處理生成的X和Y坐標,可以看到部分資料是一樣的,這是因為這9行語料所包含的詞較少,出現的頻率基本都是1次,在生成詞頻矩陣和TF-IDF后再經降維處理可能出現相同的現象,而真實分析中語料所包含詞語較多,聚類分析更多的散點更能直觀地反應分析的結果,
[[-0.19851936 0.594503 ]
[-0.07537261 0.03666604]
[-0.19851936 0.594503 ]
[-0.2836149 -0.40631642]
[-0.27797826 -0.39614944]
[-0.25516435 -0.35198914]
[ 0.68227073 -0.05394154]
[ 0.68227073 -0.05394154]
[-0.07537261 0.03666604]]
研究生期間,作者在研究知識圖譜、物體對齊知識時,曾采用過KMeans聚類演算法對所爬取的四個主題百科資料集進行文本聚類分析,其聚類結果如圖所示,
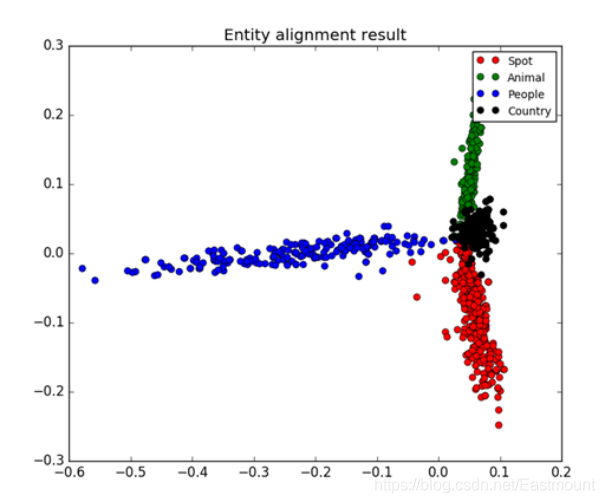
圖中紅色表示旅游景點主題文本、綠色表示保護動物主題文本、藍色表示人物明星主題文本、黑色表示國家地理主題文本,從圖中可以發現四類主題分別聚集成四個類簇,這是文本分析的一個簡單示例,希望讀者能根據本章的知識點,分析自己所研究的文本知識,
七.總結
前面講述的資料分析內容幾乎都是基于數字、矩陣的,而也有一部分資料分析會涉及文本處理分析,尤其是中文文本資料,它們究竟怎么處理呢?當我們通過網路爬蟲得到中文語料之后,我們究竟能不能進行資料分析呢?答案肯定是能的,
但是不同于之前的資料分析,它還需要經歷中文分詞、資料清洗、特征提取、向量空間模型、權重計算等步驟,將中文資料轉換為數學向量的形式,這些向量就是對應的數值特征,然后才能進行相應的資料分析,本章講解貫穿著自定義的資料集,它包含了貴州、資料分析、愛情三個主題的語料,采用KMeans聚類演算法進行實體講解,希望讀者認真學習,掌握中文語料分析的方法,如何將自己的中文資料集轉換成向量矩陣,再進行相關的分析,
最后希望讀者能復現每一行代碼,只有實踐才能進步,同時更多聚類演算法和原理知識,希望讀者下來自行深入學習研究,也推薦大家結合Sklearn官網和開源網站學習更多的機器學習知識,
該系列所有代碼下載地址:
- https://github.com/eastmountyxz/Python-zero2one
感謝在求學路上的同行者,不負遇見,勿忘初心,這周的留言感慨~
(By:娜璋之家 Eastmount 2021-08-06 夜于武漢 https://blog.csdn.net/Eastmount )
參考文獻:
- [1] 楊秀璋. 專欄:知識圖譜、web資料挖掘及NLP - CSDN博客[EB/OL]. (2016-09-19)[2017-11-07]. http://blog.csdn.net/column/details/eastmount-kgdmnlp.html.
- [2] 楊秀璋. [python] LDA處理檔案主題分布及分詞、詞頻、tfidf計算[EB/OL]. (2016-03-15)[2017-12-01]. http://blog.csdn.net/eastmount/article/details/50891162.
- [3] 楊秀璋. [python] 使用scikit-learn工具計算文本TF-IDF值[EB/OL]. (2016-08-08)[2017-12-01]. http://blog.csdn.net/eastmount/article/details/50323063.
- [4] 楊秀璋. [python] 基于k-means和tfidf的文本聚類代碼簡單實作[EB\OL]. (2016-01-16)[2017-12-01]. http://blog.csdn.net/eastmount/article/details/50473675.
- [5] 楊秀璋. [python] Kmeans文本聚類演算法+PAC降維+Matplotlib顯示聚類影像[EB/OL]. (2016-01-20)[2017-12-01]. http://blog.csdn.net/eastmount/article/details/50545937.
- [6] 張良均,王路,譚立云,蘇劍林. Python資料分析與挖掘實戰[M]. 北京:機械工業出版社,2016.
- [7] (美)Wes McKinney著. 唐學韜等譯. 利用Python進行資料分析[M]. 北京:機械工業出版社,2013.
- [8] Jiawei Han,Micheline Kamber著. 范明,孟小峰譯. 資料挖掘概念與技術. 北京:機械工業出版社,2007.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292505.html
標籤:python