目錄
- Pandas介紹
- Pandas資料結構
- Series
- Series的創建
- Series的屬性
- DataFrame
- DataFrame的創建
- DataFrame的屬性
- DatatFrame索引的設定
- 基本資料操作
- 索引操作
- 賦值操作
- 排序
- DataFrame排序
- Series排序
- DataFrame運算
- 算術運算
- 邏輯運算
- 邏輯運算子號
- 邏輯運算函式
- 統計運算
- describe
- 統計函式
- 累計統計函式
- 自定義運算
- 檔案讀取與存盤
- CSV
- HDF5
- JSON
- 高級處理-缺失值處理
- 判斷缺失值是否存在
- 存在缺失值nan,并且是np.nan
- 高級處理-資料離散化
- 為什么要離散化
- 什么是資料的離散化
- 股票的漲跌幅離散化
- 股票漲跌幅分組資料變成one-hot編碼
- 高級處理-合并
- pd.concat實作資料合并
- pd.merge
- 高級處理-交叉表與透視表
- 高級處理-分組與聚合
- 什么分組與聚合
- 分組API
(所需要的資料均已上傳)
Pandas介紹
Pandas簡介
2008年WesMcKinney開發出的庫
專門用于資料挖掘的開源python庫
以Numpy為基礎,借力Numpy模塊在計算方面性能高的優勢
基于matplotlib,能夠簡便的畫圖
獨特的資料結構
Pandas資料結構
Pandas中一共有三種資料結構,分別為:Series、DataFrame和MultiIndex(老版本中叫Panel ),
其中Series是一維資料結構,DataFrame是二維的表格型資料結構,MultiIndex是三維的資料結構,
Series
Series是一個類似于一維陣列的資料結構,它能夠保存任何型別的資料,比如整數、字串、浮點數等,主要由一組資料和與之相關的索引兩部分構成,

Series的創建
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
引數:
data:傳入的資料,可以是ndarray、list等
index:索引,必須是唯一的,且與資料的長度相等,如果沒有傳入索引引數,則默認會自動創建一個從0-N的整數索引,
dtype:資料的型別
1、指定內容,默認索引
import pandas as pd
pd.Series(np.arange(10))
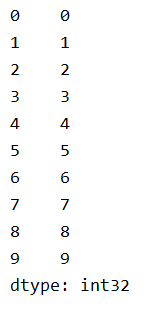
2、指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])

3、通過字典資料創建
pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})

Series的屬性
為了更方便地操作Series物件中的索引和資料,Series中提供了兩個屬性index和values
index:
import pandas as pd
series= pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
print(series.index)
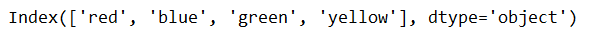
values:
import pandas as pd
series= pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
print(series.values)
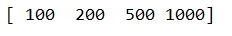
DataFrame
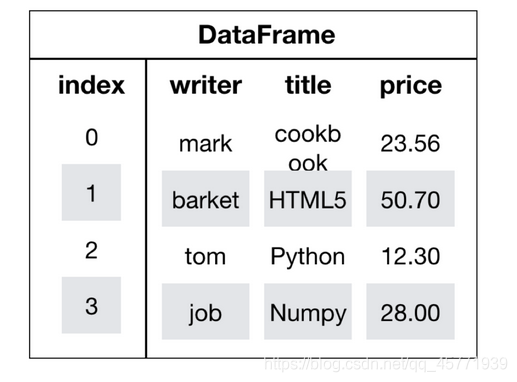
DataFrame是一個類似于二維陣列或表格(如excel)的物件,既有行索引,又有列索引
行索引,表明不同行,橫向索引,叫index,0軸,axis=0
列索引,表名不同列,縱向索引,叫columns,1軸,axis=1
DataFrame的創建
pd.DataFrame(data=None, index=None, columns=None)
引數:
index:行標簽,如果沒有傳入索引引數,則默認會自動創建一個從0-N的整數索引,
columns:列標簽,如果沒有傳入索引引數,則默認會自動創建一個從0-N的整數索引,
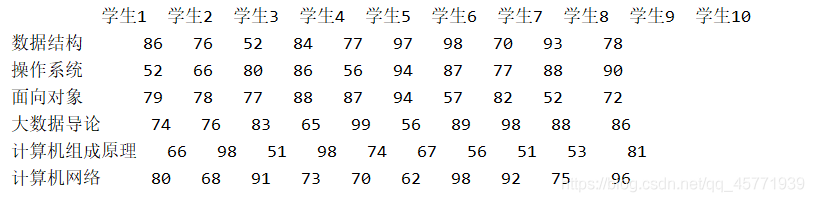
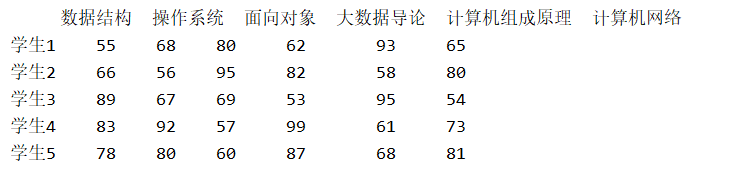
創建學生成績案例:
import pandas as pd
import numpy as np
subjects = ["資料結構", "作業系統", "面向物件", "大資料導論", "計算機組成原理","計算機網路"]
students=["學生{}".format(i) for i in range(1,11)]
data=pd.DataFrame(np.random.randint(50,100,(10,6)),index=students,columns=subjects)
print(data)

運行結果:
2、index
DataFrame的行索引串列
print(data.index)
運行結果:
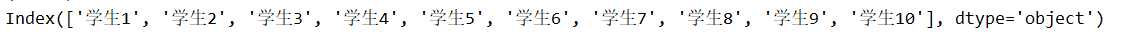
3、columns
DataFrame的列索引串列:
print(data.columns)
運行結果;
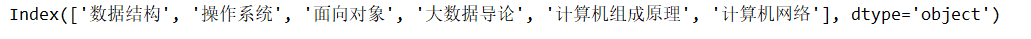
4、values
直接獲取其中array的值
print(data.values)

5、.T
轉置
print(data.T)
6、head(n):顯示前n行內容
如果不補充引數,默認5行,填入引數N則顯示前N行
print(data.head())
7、tail(n):顯示后n行內容
如果不補充引數,默認5行,填入引數N則顯示后N行
data.tail()
DatatFrame索引的設定
以下所有案例多數是參考上面的學生課表案例
1、修改行列索引值
data.index=["教師{}".format(i) for i in range(1,11)]
# 錯誤方法
data.index[3] = '教師3'
2、 重設索引
reset_index(drop=False)
drop:默認為False,不洗掉原來索引,如果為True,洗掉原來的索引值
3、以某列值設定為新的索引
set_index(keys, drop=True)
keys : 列索引名成或者列索引名稱的串列
drop : boolean, default True.當做新的索引,洗掉原來的列
設定新索引案例:
1、創建
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
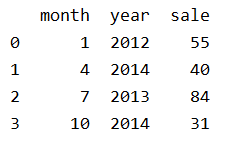
2、以月份設定新的索引
df=df.set_index('month')
print(df)
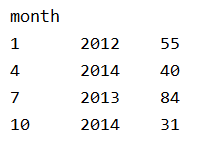
3、設定多個索引,以年和月份
df = df.set_index(['year', 'month'])
print(df)
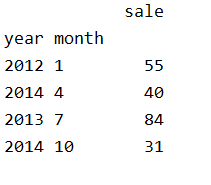
基本資料操作
為了更好的理解這些基本操作,我們將讀取一個真實的股票資料,
import pandas as pd
# 將資料全部顯示,沒有省略號
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
pd.set_option('display.width',10000)
data=pd.read_csv(r'C:\Users\Administrator\Desktop\stock_day.csv')
data=data.set_index(["date"])
索引操作
Numpy當中我們已經講過使用索引選取序列和切片選擇,pandas也支持類似的操作,也可以直接使用列名、行名稱,甚至組合使用,
1、直接使用行列索引(先列后行)
獲取’2018-02-27’這天的’open’的結果
print(data['open']['2018/2/27'])
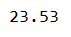
2、結合loc或者iloc使用索引
獲取從’2018-02-27’:‘2018-02-22’,'open’的結果
print(data.loc['2018/2/27':'2018/2/22', 'open'])
print("--------------------------")
data.iloc[:3, :5]
3、使用ix組合索引
獲取行第1天到第4天,[‘open’, ‘close’, ‘high’, ‘low’]這個四個指標的結果
# 使用ix進行下表和名稱組合做引
data.ix[0:4, ['open', 'close', 'high', 'low']]
# 推薦使用loc和iloc來獲取的方式
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
賦值操作
對DataFrame當中的close列進行重新賦值為1
# 直接修改原來的值
data['close'] = 1
# 或者
data.close = 1
排序
排序有兩種形式,一種對于索引進行排序,一種對于內容進行排序,
DataFrame排序
df.sort_values(by= , ascending= )
單個鍵或者多個鍵進行排序,
引數:
by:指定排序參考的鍵
ascending:默認升序
ascending=False:降序
ascending=True:升序
# 按照開盤價大小進行排序 , 使用ascending指定按照大小排序
data.sort_values(by="open", ascending=True).head()
# 按照多個鍵進行排序
data.sort_values(by=['open', 'high'])
使用df.sort_index給索引進行排序
# 對索引進行排序
data.sort_index()
Series排序
使用series.sort_values(ascending=True)進行排序
data['p_change'].sort_values(ascending=True).head()
使用series.sort_index()進行排序
data['p_change'].sort_index().head()
DataFrame運算
算術運算
add(other)
比如進行數學運算加上具體的一個數字
print(data['open'].add(1).head())

sub(other) :減去一個數
邏輯運算
邏輯運算子號
例如篩選data[“open”] > 23的日期資料
print(data['open']>23)
完成多個邏輯判斷:
data[(data["open"] > 23) & (data["open"] < 24)].head()
邏輯運算函式
1、query(expr)
通過query使得剛才的程序更加方便簡單
data.query("open<24 & open>23").head()
2、isin(values)
例如判斷’open’是否為23.53和23.85
# 可以指定值進行一個判斷,從而進行篩選操作
data[data["open"].isin([23.53, 23.85])]
統計運算
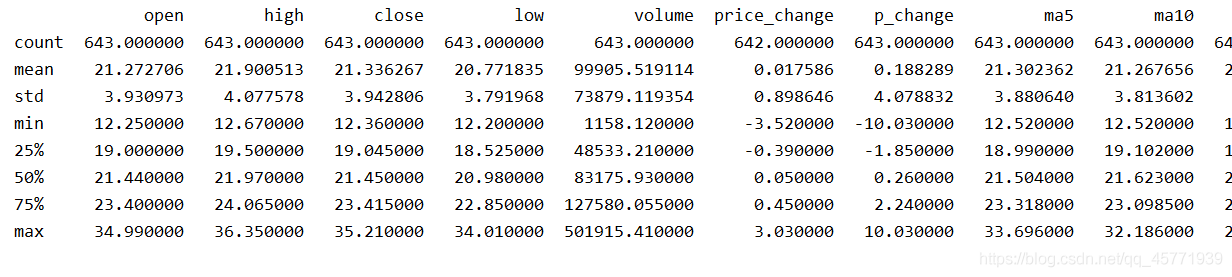
describe
綜合分析: 能夠直接得出很多統計結果,count, mean, std, min, max 等
print(data.describe())
統計函式
| count | Number of non-NA observations |
|---|---|
| sum | 求和 |
| mean | 平均值 |
| median | 中位數 |
| min | 最小值 |
| max | 最大值 |
| mode | 眾數 |
| abs | 絕對值 |
| prod | 乘積 |
| std | 標準差 |
| var | 方差 |
| idmax | 最大值索引 |
| idmin | 最小值索引 |
累計統計函式
| 函式 | 作用 |
|---|---|
| cumsum | 計算前1/2/3/…/n個數的和 |
| cummax | 計算前1/2/3/…/n個數的最大值 |
| cummin | 計算前1/2/3/…/n個數的最小值 |
| cumprod | 計算前1/2/3/…/n個數的積 |
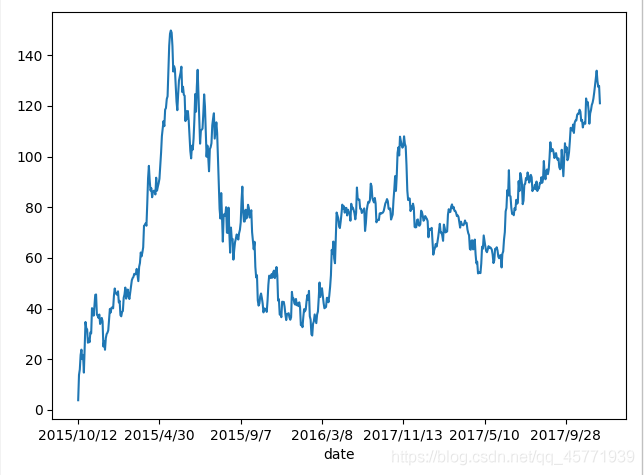
例:對p_change進行求和,計算股票的漲跌
import matplotlib.pyplot as plt
import pandas as pd
data=pd.read_csv(r'C:\Users\Administrator\Desktop\stock_day.csv')
data=data.set_index(["date"])
data=data.sort_index()
stock_rise=data['p_change']
stock_rise.cumsum().plot()
plt.show()
自定義運算
apply(func, axis=0)
func:自定義函式
axis=0:默認是列,axis=1為行進行運算
檔案讀取與存盤
CSV
pandas.read_csv(filepath_or_buffer, sep =’,’, usecols )
filepath_or_buffer:檔案路徑
sep :分隔符,默認用","隔開
usecols:指定讀取的列名,串列形式
# 讀取檔案,并且指定只獲取'open', 'close'指標
data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close'])
DataFrame.to_csv(path_or_buf=None,sep=’,’,columns=None,header=True,index=True, mode=‘w’, encoding=None)
path_or_buf :檔案路徑
sep :分隔符,默認用","隔開
columns :選擇需要的列索引
header :boolean or list of string, default True,是否寫進列索引值
index:是否寫進行索引
mode:‘w’:重寫, ‘a’ 追加
# 選取10行資料保存,便于觀察資料
data[:10].to_csv("./data/test.csv", columns=['open'])
HDF5
從h5檔案當中讀取資料
pandas.read_hdf(path_or_buf,key =None, kwargs)**
path_or_buffer:檔案路徑
key:讀取的鍵
return:Theselected object
DataFrame.to_hdf(path_or_buf, key, \kwargs)
JSON
pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
將JSON格式準換成默認的Pandas DataFrame格式
例:
json_read = pd.read_json(r'C:\Users\Administrator\Desktop\Sarcasm_Headlines_Dataset.json', orient="records", lines=True)
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
將Pandas 物件存盤為json格式
高級處理-缺失值處理
判斷缺失值是否存在
如果缺失值的標記方式是NaN,判斷資料中是否包含NaN:
pd.isnull(df),
pd.notnull(df)
案例:
import pandas as pd
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
pd.set_option('display.width',10000)
# 讀取電影資料
movie = pd.read_csv(r'C:\Users\Administrator\Desktop\IMDB-Movie-Data.csv')
print(pd.notnull(movie))
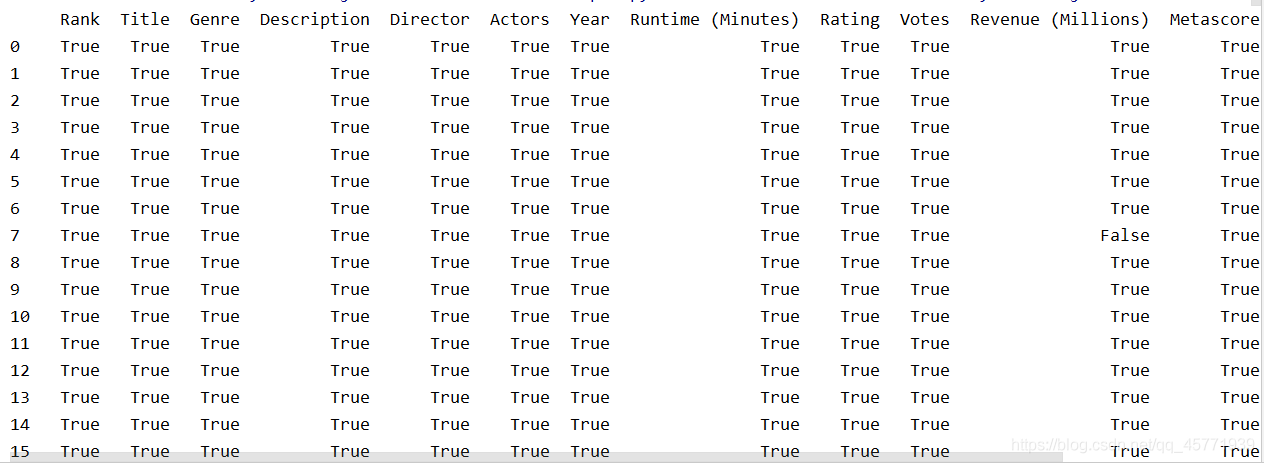
存在缺失值nan,并且是np.nan
存在缺失值nan:
1、洗掉存在缺失值的:dropna(axis='rows')
注:不會修改原資料,需要接受回傳值
2、替換缺失值:fillna(value, inplace=True)
value:替換成的值
inplace:True:會修改原資料,False:不替換修改原資料,生成新的物件
1、洗掉
pandas洗掉缺失值,使用dropna的前提是,缺失值的型別必須是np.nan
# 不修改原資料
movie.dropna()
# 可以定義新的變數接受或者用原來的變數名
data = movie.dropna()
2、替換缺失值
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)
高級處理-資料離散化
為什么要離散化
連續屬性離散化的目的是為了簡化資料結構,資料離散化技術可以用來減少給定連續屬性值的個數,離散化方法經常作為資料挖掘的工具,
什么是資料的離散化
連續屬性的離散化就是在連續屬性的值域上,將值域劃分為若干個離散的區間,最后用不同的符號或整數 值代表落在每個子區間中的屬性值,
離散化有很多種方法,這使用一種最簡單的方式去操作
原始人的身高資料:165,174,160,180,159,163,192,184
假設按照身高分幾個區間段:150~165, 165~180,180~195
這樣我們將資料分到了三個區間段,我可以對應的標記為矮、中、高三個類別,最終要處理成一個"啞變數"矩陣,
股票的漲跌幅離散化
1、讀取股票的資料
# 讀取電影資料
data = pd.read_csv(r'C:\Users\Administrator\Desktop\IMDB-Movie-Data.csv')
p_change= data['p_change']
2、將股票漲跌幅資料進行分組
pd.qcut(data, q):
對資料進行分組將資料分組,一般會與value_counts搭配使用,統計每組的個數
series.value_counts():統計分組次數
# 自行分組
qcut = pd.qcut(p_change, 10)
# 計算分到每個組資料個數
print(qcut.value_counts())

自定義區間分組:
pd.cut(data, bins)
# 自己指定分組區間
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
# 自己指定分組區間
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
print(p_counts)

股票漲跌幅分組資料變成one-hot編碼
什么是one-hot編碼?
把每個類別生成一個布爾列,這些列中只有一列可以為這個樣本取值為1.其又被稱為熱編碼,
pandas.get_dummies(data, prefix=None)
# 得出one-hot編碼矩陣
dummies = pd.get_dummies(p_counts, prefix="rise")
print(dummies)

高級處理-合并
pd.concat實作資料合并
pd.concat([data1, data2], axis=1)
按照行或列進行合并,axis=0為列索引,axis=1為行索引
# 按照行索引進行
pd.concat([data, dummies], axis=1)
pd.merge
pd.merge(left, right, how=‘inner’, on=None)
可以指定按照兩組資料的共同鍵值對合并或者左右各自
left: DataFrame
right: 另一個DataFrame
on: 指定的共同鍵
how:按照什么方式連接
高級處理-交叉表與透視表
交叉表:交叉表用于計算一列資料對于另外一列資料的分組個數(用于統計分組頻率的特殊透視表)
pd.crosstab(value1, value2)
透視表:透視表是將原有的DataFrame的列分別作為行索引和列索引,然后對指定的列應用聚集函式
data.pivot_table()
DataFrame.pivot_table([], index=[])
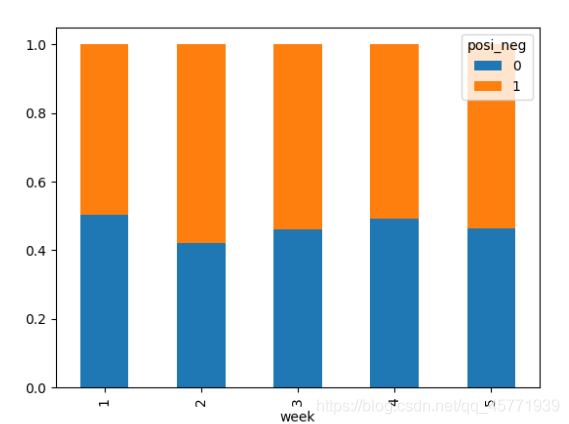
案例:探究股票的漲跌與星期幾有關?
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
pd.set_option('display.width',10000)
data=pd.read_csv(r'C:\Users\Administrator\Desktop\stock_day.csv')
time=data.set_index(keys=["date"])
week=pd.to_datetime(time.index).weekday+1
data['week']=week
data['posi_neg'] = np.where(data["p_change"]>0,1,0)
count=pd.crosstab(data['week'],data['posi_neg'])
sum=count.sum(axis=1).astype(np.float32)
pro=count.div(sum,axis=0)
pro.plot(kind='bar',stacked=True)
plt.savefig('2')
plt.show()
print(data.pivot_table(['posi_neg'], index='week'))

高級處理-分組與聚合
什么分組與聚合
分組與聚合通常是分析資料的一種方式,通常與一些統計函式一起使用,查看資料的分組情況
分組API
DataFrame.groupby(key, as_index=False)
key:分組的列資料,可以多個
案例:不同顏色的不同筆的價格數據
import pandas as pd
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
print(col.groupby(['color'],as_index=False)['price1'].mean())
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292959.html
標籤:python