目錄
- 🎅第一部分:走近scrapy!
- 🍏0.簡介及安裝
- 1??簡介:
- 2??安裝:
- 🍒1.scrapy專案開發流程:
- 🍓2.scrapy框架運行流程:
- 🍌拓展——scrapy中三個內置物件:
- 🎍第二部分:創建&&運行你的第一個scrapy專案!
- 🐱1.創建專案:
- 🐹2.爬蟲檔案的創建:
- 🐸3.運行scrapy爬蟲:
- 🐻4.明確了爬蟲所爬取資料之后,使用管道進行資料持久化操作:
- 🐮5.管道保存資料
- ??初級篇:
- ??進階篇:
- 🐒6.settings.py配置啟用管道:
- 🐫7.scrapy資料建模與請求:
- 💊(1)為什么建模?
- 💊(2)本專案中實操:
- 🏃8.設定user-agent:
- 🔮9.到目前為止,一個入門級別的scrapy爬蟲已經OK了,基操都使用了!
- 如何run呢?
- 🐱10.開發流程總結:
- 結語:
- 🔆第三部分——In The End!
- 👻👻相信不少小伙伴們在經歷過我的上幾篇關于爬蟲技術的萬字博文的輪番轟炸后,已經可以獨立開發出屬于自己的爬蟲專案!!!——爬蟲之路,已然開啟!👻👻
?
?💦第一篇之爬蟲入坑文;一篇萬字博文帶你入坑爬蟲這條不歸路(你還在猶豫什么&抓緊上車) 【??熬夜整理&建議收藏??】
?💦第二篇之爬蟲庫requests庫詳解,兩萬字博文教你python爬蟲requests庫,看完還不會我把我女朋友都給你【??熬夜整理&建議收藏??】
?💦第三篇之決議庫Xpath庫詳解,萬字博文教你python爬蟲必備XPath庫,看完還不會我把我女朋友都給你【??建議收藏系列??】
?💦第四篇之決議庫Beautiful Soup庫詳解,Python萬字博文教你玩透Beautiful Soup庫,不信你學不會【??建議收藏系列??】
?💦第五篇之Selenium詳解,【??爬蟲必備->Selenium從黑鐵到王者??】初篇——萬字博文詳解(建議收藏)
- 😬😬但是 前幾日有很多粉絲私聊我反饋說:"自己爬蟲基礎庫已經學差不多了,實戰也做了不少,但是好多自己接的爬蟲單或者老板都要求使用scrapy框架來爬取資料,自己沒有接觸過scrapy框架不知道如何下手!"😬😬
? 其實我已經有一個scrapy一條龍教學的分欄,也有不少人訂閱并且反響不錯,【Scrapy框架詳解】,但是呢?我又想了想,確實少了篇總結性的文章——來從總體上介紹Scrapy框架,
- ??所以應粉絲們要求,本博主花了假期周六周日兩天時間,肝出本文(共分上中下三篇),目的在于帶領想要學習scrapy的同學走近scrapy的世界!并在文末附帶一整套scrapy框架學習路線,如果你能認認真真看完這三篇文章,在心里對scrapy有個印象,然后潛心研究文末整套學習路線,那么,scrapy框架對你來說——手到擒來!!!??
| 分欄名稱 | 傳送門 |
|---|---|
| 🎐爬蟲難,跟我一起入爬蟲坑,爬蟲一條龍服務!🎐 | 《入坑Python爬蟲》 |
| 🐲Django框架難,跟我一起一條龍教學(附帶多個小型專案實戰!)🐲 | 《Django框架一條龍》 |
| 🐋Scrapy框架難,跟我一起一條龍教學(附帶多個小型專案實戰!)🐋 | 《Scrapy框架一條龍》 |
| 🐠Tornado框架難,跟我一起一條龍教學(附帶一個完整專案!)🐠 | 《Tornado框架一條龍》 |
| 🐝爬蟲——JS滲透;三大驗證碼(滑塊,點觸,圖形);字體反爬;移動端!🐝 | 《爬蟲高級一條龍》 |
- 🔩🔩我會盡量把技術文寫的通俗易懂/生動有趣,保證每一個想要學習知識&&認認真真讀完本文的讀者們能夠有所獲,有所得,當然,如果你讀完感覺本文寫的還可以,真正學習到了東西,希望給我個「 贊 」 和 「 收藏 」,這個對我很重要,謝謝了!🔩🔩
?
?
🎅第一部分:走近scrapy!
?
🍏0.簡介及安裝
1??簡介:
scrapy設計目的:用于爬取網路資料,提取結構性資料的框架,其中,scrapy使用了Twisted異步網路框架,大大加快了下載速度!
官方檔案地址!!!

2??安裝:
直接pip安裝(一句命令&&一步到位):
pip install scrapy
?
🍒1.scrapy專案開發流程:
- 創建專案:scrapy startproject mySpider
- 生成一個爬蟲:scrapy genspider baidu baidu.com
- 提取資料:根據網站結構在spider中實作資料采集相關內容
- 保存資料:使用pipeline進行資料后續處理和保存
?
🍓2.scrapy框架運行流程:
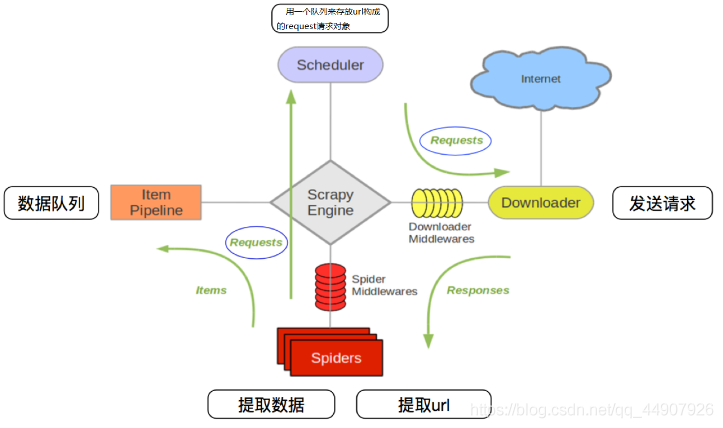
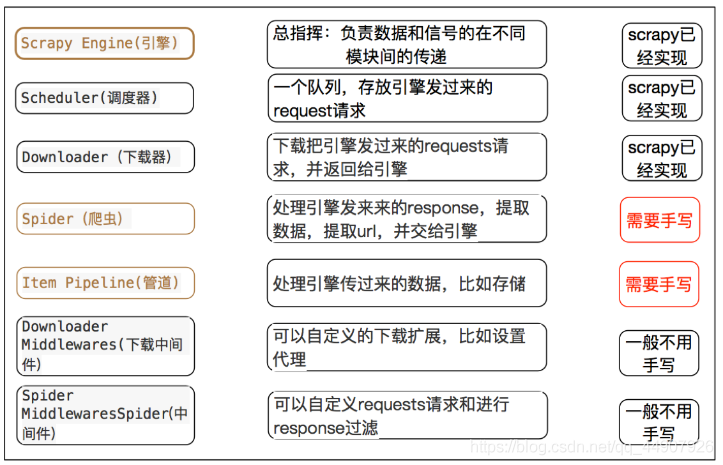
原理描述:
- 爬蟲中起始的url構造的url物件–>爬蟲中間件–>引擎–>調度器
- 調度器把request–>引擎–>下載中間件–>下載器
- 下載器發送請求,獲取response回應—>下載中間件—>引擎–>爬蟲中間件—>爬蟲
- 爬蟲提取url地址,組裝成request物件—>爬蟲中間件—>引擎—>調度器,重復步驟2
- 爬蟲提取資料—>引擎—>管道處理和保存資料
| 注意:爬蟲中間件和下載中間件只是運行的邏輯的位置不同,作用是重復的:如替換UA等! |
?
🍌拓展——scrapy中三個內置物件:
三個內置物件:(scrapy框架中只有三種資料型別)
request請求物件:由url,method,post_data,headers等構成;
response回應物件:由url,body,status,headers等構成;
item資料物件:本質是一個字典,
?
🎍第二部分:創建&&運行你的第一個scrapy專案!
?
🐱1.創建專案:
創建scrapy專案的命令:scrapy startproject <專案名字>
示例:
scrapy startproject myspider
生成的目錄和檔案結果如下:

?
🐹2.爬蟲檔案的創建:
在專案根路徑下執行:
scrapy genspider <爬蟲名字> <允許爬取的域名>
示例:
cd myspider
scrapy genspider itcast itcast.cn
講解:
- 爬蟲名字:作為爬蟲運行時的引數;
- 允許爬的域名:為對于爬蟲設定的爬取范圍,設定之后用于過濾要爬取的url,如果爬取的url與允許的域名不同,則被過濾掉,
?
🐸3.運行scrapy爬蟲:
命令:在專案目錄下執行:
scrapy crawl <爬蟲名字>
示例:
scrapy crawl itcast
不過,在運行之前,我們先要撰寫itcast.py爬蟲檔案:
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
# 爬蟲運行時的引數
name = 'itcast'
# 檢查允許爬的域名
allowed_domains = ['itcast.cn']
# 1.修改設定起始的url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajacaee']
# 資料提取的方法:接收下載中間件傳過來的response,定義對于網站相關的操作
def parse(self, response):
# 獲取所有的教師節點
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍歷教師節點串列
tea_dist = {}
for teacher in t_list:
# xpath方法回傳的是選擇器物件串列 extract()方法可以提取到selector物件中data對應的資料,
tea_dist['name'] = teacher.xpath('./h3/text()').extract_first()
tea_dist['title'] = teacher.xpath('./h4/text()').extract_first()
tea_dist['desc'] = teacher.xpath('./p/text()').extract_first()
yield teacher
然后再運行,會發現已經可以正常運行!
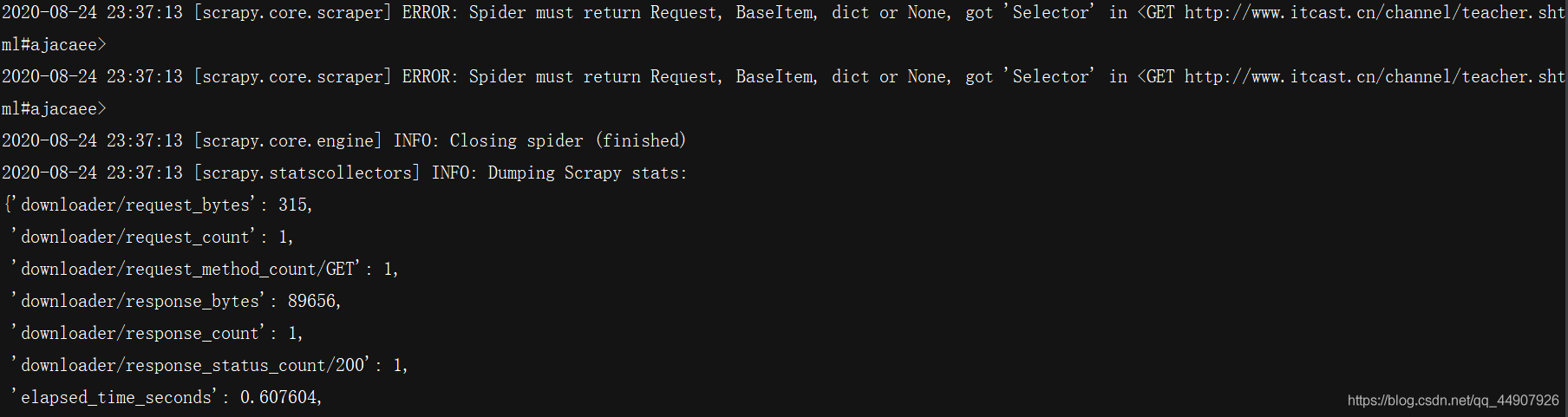 ?
?
🐻4.明確了爬蟲所爬取資料之后,使用管道進行資料持久化操作:
修改itcast.py爬蟲檔案:
# -*- coding: utf-8 -*-
import scrapy
from ..items import UbuntuItem
class ItcastSpider(scrapy.Spider):
# 爬蟲運行時的引數
name = 'itcast'
# 檢查允許爬的域名
allowed_domains = ['itcast.cn']
# 1.修改設定起始的url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajacaee']
# 資料提取的方法:接收下載中間件傳過來的response,定義對于網站相關的操作
def parse(self, response):
# 獲取所有的教師節點
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍歷教師節點串列
item = UbuntuItem()
for teacher in t_list:
# xpath方法回傳的是選擇器物件串列 extract()方法可以提取到selector物件中data對應的資料,
item['name'] = teacher.xpath('./h3/text()').extract_first()
item['title'] = teacher.xpath('./h4/text()').extract_first()
item['desc'] = teacher.xpath('./p/text()').extract_first()
yield item
注意:
- scrapy.Spider爬蟲類中必須有名為parse的決議;
- 如果網站結構層次比較復雜,也可以自定義其他決議函式;
- 在決議函式中提取的url地址如果要發送請求,則必須屬于allowed_domains范圍內,但是start_urls中的url地址不受這個限制;
- 啟動爬蟲的時候注意啟動的位置,是在專案路徑下啟動;
- parse()函式中使用yield回傳資料,注意:決議函式中的yield能夠傳遞的物件只能是:BaseItem, Request, dict, None,
小知識點1——定位元素以及提取資料、屬性值的方法:
(決議并獲取scrapy爬蟲中的資料: 利用xpath規則字串進行定位和提取)
- response.xpath方法的回傳結果是一個類似list的型別,其中包含的是selector物件,操作和串列一樣,但是有一些額外的方法;
- 額外方法extract():回傳一個包含有字串的串列;
- 額外方法extract_first():回傳串列中的第一個字串,串列為空沒有回傳None,
小知識點2——response回應物件的常用屬性:
- response.url:當前回應的url地址
- response.request.url:當前回應對應的請求的url地址
- response.headers:回應頭
- response.requests.headers:當前回應的請求頭
- response.body:回應體,也就是html代碼,byte型別
- response.status:回應狀態碼
?
🐮5.管道保存資料
在pipelines.py檔案中定義對資料的操作!
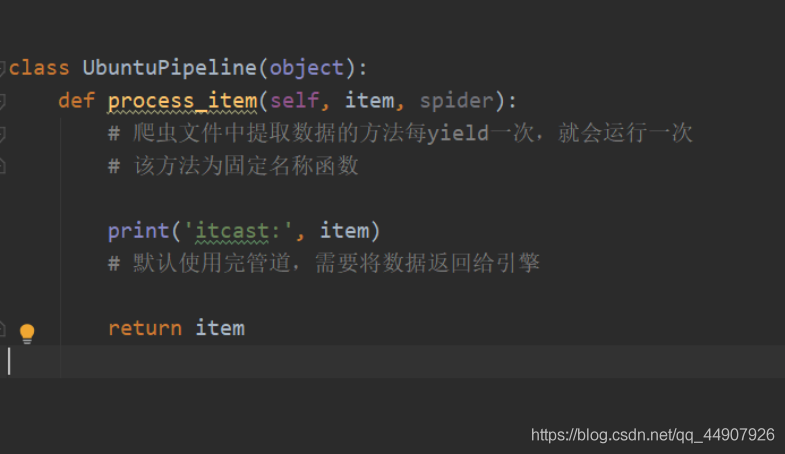
- 定義一個管道類;
- 重寫管道類的process_item方法;
- process-item方法處理完item之后必須回傳給引擎,
??初級篇:
??進階篇:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class UbuntuPipeline(object):
def __init__(self):
self.file = open('itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 將item物件強制轉為字典,該操作只能在scrapy中使用
item = dict(item)
# 爬蟲檔案中提取資料的方法每yield一次,就會運行一次
# 該方法為固定名稱函式
# 默認使用完管道,需要將資料回傳給引擎
# 1.將字典資料序列化
'''ensure_ascii=False 將unicode型別轉化為str型別,默認為True'''
json_data = json.dumps(item, ensure_ascii=False, indent=2) + ',\n'
# 2.將資料寫入檔案
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
?
🐒6.settings.py配置啟用管道:
在settings檔案中,解封代碼,說明如下:
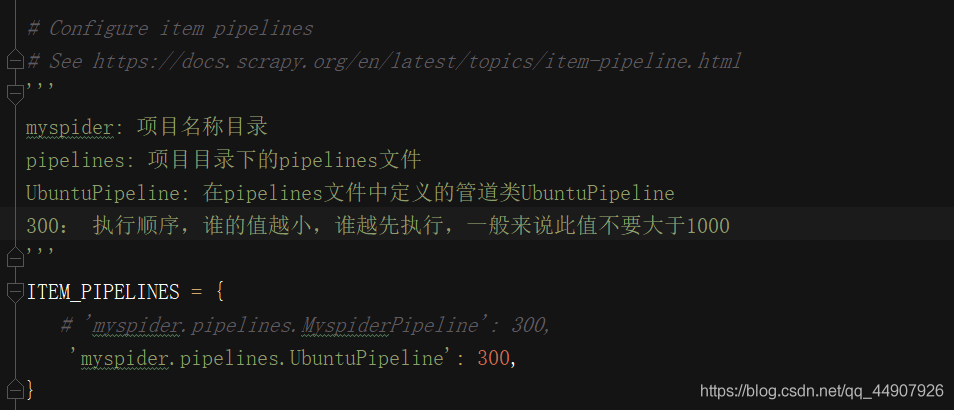
?
🐫7.scrapy資料建模與請求:
(通常在做專案的程序中,在items.py中進行資料建模!)
💊(1)為什么建模?
- 定義item即提前規劃好哪些欄位需要抓,防止手誤,因為定義好之后,在運行程序中,系統會自動檢查,值不相同會報錯;
- 配合注釋一起可以清晰的知道要抓取哪些欄位,沒有定義的欄位不能抓取,在目標欄位少的時候可以使用字典代替;
- 使用scrapy的一些特定組件需要Item做支持,如scrapy的ImagesPipeline管道類,
💊(2)本專案中實操:
在items.py檔案中操作:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class UbuntuItem(scrapy.Item):
# 講師名字
name = scrapy.Field()
# 講師職稱
title = scrapy.Field()
# 講師座右銘
desc = scrapy.Field()
注意:
- from …items import UbuntuItem這一行代碼中 注意item的正確匯入路徑,忽略pycharm標記的錯誤;
- python中的匯入路徑要訣:從哪里開始運行,就從哪里開始匯入,
?
🏃8.設定user-agent:
# settings.py檔案中找到如下代碼解封,并加入UA:
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36',
}
?
🔮9.到目前為止,一個入門級別的scrapy爬蟲已經OK了,基操都使用了!
如何run呢?
現在cd到專案目錄下,輸入
scrapy crawl itcast
即可運行scrapy!
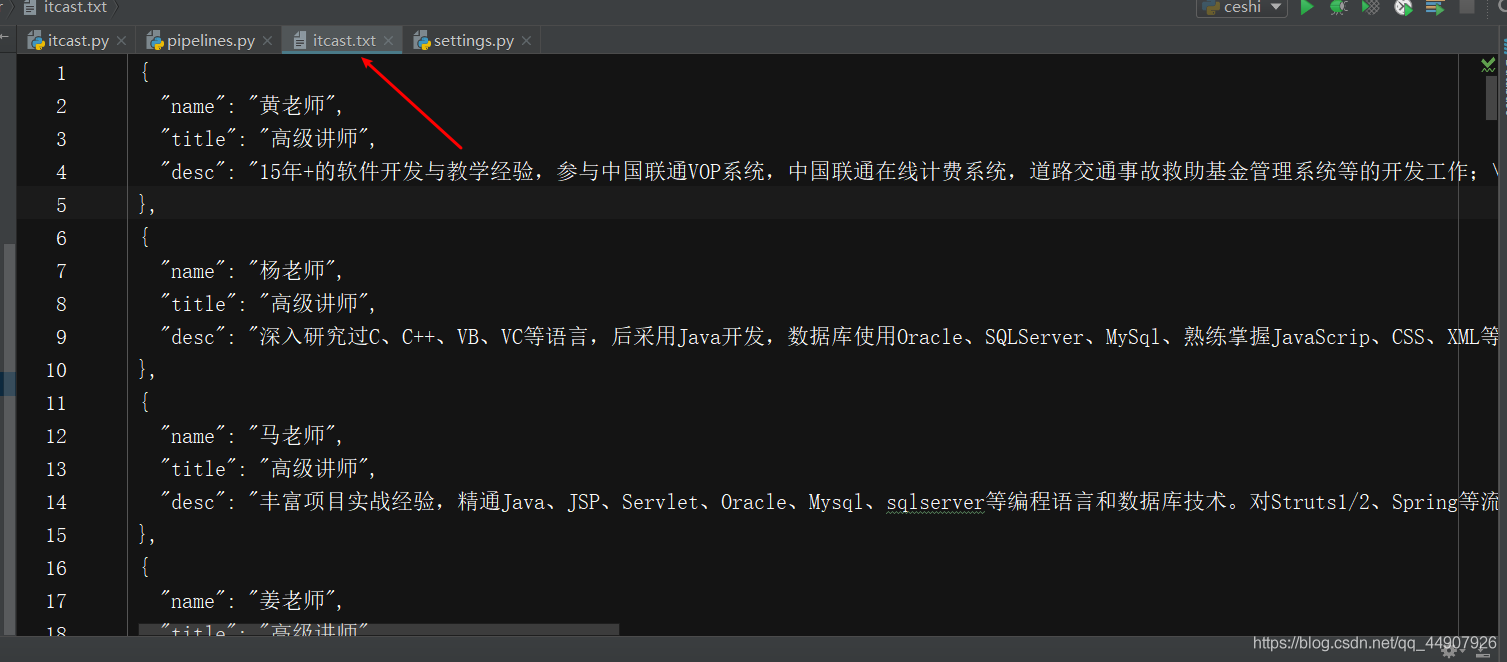 ?
?
🐱10.開發流程總結:
-
創建專案:
scrapy startproject 專案名 -
明確目標:
在items.py檔案中進行建模! -
創建爬蟲:
創建爬蟲:
??scrapy genspider 爬蟲名 允許的域名
完成爬蟲:
??修改start_urls; 檢查修改allowed_domains; 撰寫決議方法! -
保存資料:
在pipelines.py檔案中定義對資料處理的管道
在settings.py檔案中注冊啟用管道
結語:
??通過上面的學習,你已經可以獨立創建一個scrapy專案并使用此框架進行簡單的爬蟲專案撰寫,但是!任何一種功夫都不是一下就能學好學會學精的!所以下面分享一波scrapy學習路線,只要你跟著潛心學完,那么!恭喜你!你已經是名優秀的scrapy框架使用者了!!!
下面是整套scrapy學習路線,其實就是我開篇說到的那個專欄,想要好好學習的可以去好好看看哦!
- 學習爬蟲之Scrapy框架學習(1)—Scrapy框架初學習及豆瓣top250電影資訊獲取的實戰!
- 學習爬蟲之Scrapy框架學習(2)—豆瓣top250電影更加詳細的資訊獲取及txt文本存盤外加settings.py組態檔的學習!
- 學習爬蟲之Scrapy框架學習(3)—豆瓣top250電影完整版資訊獲取及如何存盤到mysql資料庫;Scrapy shell和Scrapy選擇器;使用到日志的學習!
- 學習爬蟲之Scrapy框架學習(4)–CrawlSpider的學習及實戰縱橫小說資訊獲取并儲存mysql;LinkExtractor類和Rule類;Response和Request
- 學習爬蟲之Scrapy框架學習(五)–中間件的學習及使用
- 學習爬蟲之Scrapy框架學習(六)–1.直接使用scrapy;使用scrapy管道;使用scrapy的媒體管道類進行貓咪圖片存盤,媒體管道類學習,自建媒體管道類存盤圖片
- 學習爬蟲之Scrapy框架學習(七)—Scrapy框架里使用分布式爬蟲(Scrapy_redis),分布式實戰豆瓣電影資訊爬取;使用scrapyd實作專案部署
- 學習爬蟲之Scrapy框架學習(八)—Scrapy框架里使用分布式爬蟲;分布式實戰縱橫小說爬取+專案完整原始碼!
- scrapy-redis分布式總結及升華(基礎知識;原理分析;第三方組件講解;實戰[普通爬蟲改造為分布式爬蟲為例];scrapy_splash組件的使用;日志資訊與配置;scrapyd部署專案)
- Scrapy中selenium的應用-----并通過京東圖書書籍資訊爬取專案進行實操!
🔆第三部分——In The End!

| 從現在做起,堅持下去,一天進步一小點,不久的將來,你會感謝曾經努力的你! |
?本博主會持續更新爬蟲基礎分欄及爬蟲實戰分欄,認真仔細看完本文的小伙伴們,可以點贊收藏并評論出你們的讀后感,并可關注本博主,在今后的日子里閱讀更多爬蟲文!
如有錯誤或者言語不恰當的地方可在評論區指出,謝謝!
如轉載此文請聯系我征得本人同意,并標注出處及本博主名,謝謝 !
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292966.html
標籤:python