Stream流
- What is Stream ?
- 注意:
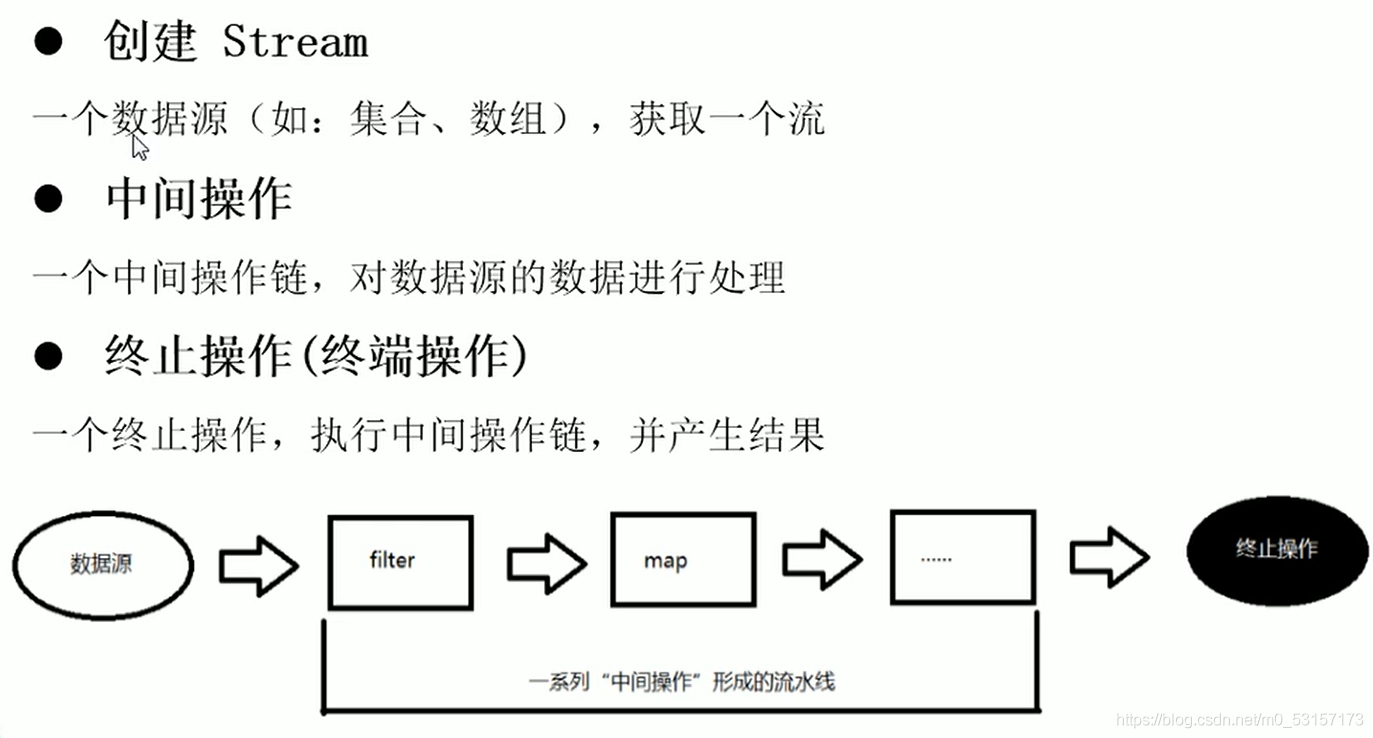
- Stream操作三部曲
- 使用演示:
- 中間操作
- 篩選與切片
- 內部迭代: 迭代操作由Stream API完成
- 終止操作:一次性執行全部內容,即惰性求值
- 外部迭代
- limit ===> 短路
- skip ===>跳過前n個元素
- distinct進行元素去重(自定義類需要重寫對應的hashcode和equals方法)
- 映射
- map的使用演示:
- flatMap使用演示:
- map與flatmap的區別
- 排序
- Stream的終止操作如下
- 查找與匹配
- 歸約--reduce
- 收集
- collect里面的分組
- collect里面的磁區
- collect里面獲取某個屬性相關的詳細資訊(平均值,最大值....)
- collect里面的join,完成字串連接作業
- 并行流與串行流
- 一、什么是并行流
- 二、了解 Fork/Join框架
- 三、Fork/Join 框架與傳統執行緒池的區別
- 四、 案例
- java8中 Fork/Join計算
- Optional類
What is Stream ?

注意:

Stream操作三部曲
使用演示:
/*
* Stream的三個操作步驟
*
* 1.創建stream
* 2.中間操作
* 3.終止操作(終端操作)
*
* */
@Test
void test()
{
//1.創建stream
//(1):可以通過collection系列集合提供的stream()或者parallelStream()
List<String> list=new ArrayList<>();
Stream<String> stream = list.stream();
//(2): 通過Arrays里面的靜態方法stream()獲取資料流
People[] peoples=new People[10];
Stream<People> stream1 = Arrays.stream(peoples);
//(3):通過stream里面的靜態方法of()
Stream<String> aa = Stream.of("aa", "bb", "cc");
//(4):創建無限流
//迭代
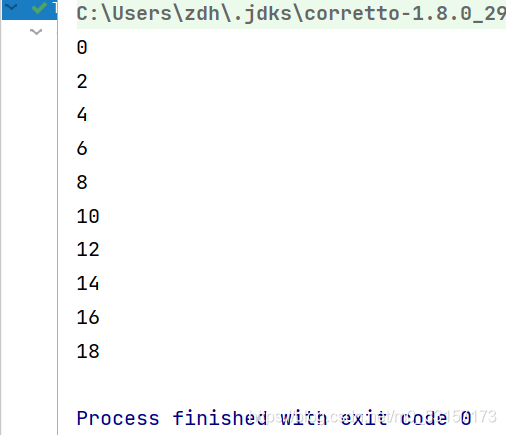
Stream.iterate(0, (x) -> x + 2)
.limit(10)//中間操作
.forEach(System.out::println);
}
}
中間操作

篩選與切片
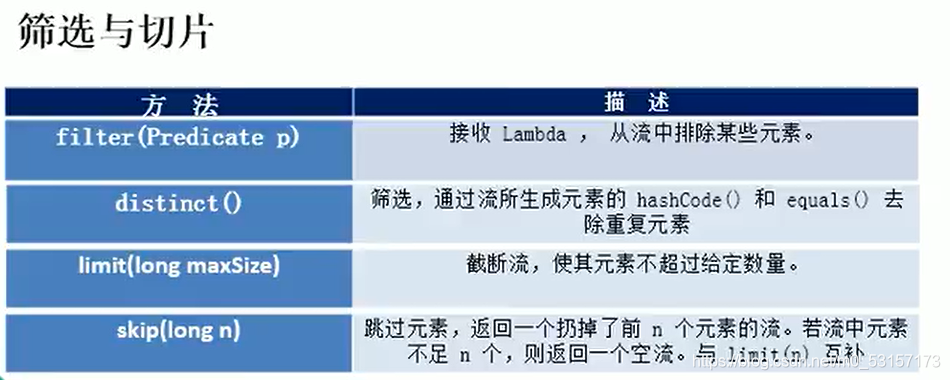
filter---接收Lambda,從流中排除某些元素
limit(max)---截斷流,使其元素不超過給定數量
skip(n)---跳過元素,回傳一個扔掉了前n個的元素的流,若流張元素不足n個,則回傳一個空流,與limit(n)互補
distinct---篩選,通過流所生成的元素的hashcode()和equals()去重復元素
內部迭代: 迭代操作由Stream API完成
終止操作:一次性執行全部內容,即惰性求值
使用演示:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("3號",19,5000),
new People("4號",20,3500)
);
@Test
void test()
{
//中間操作不會執行任何操作
Stream<People> s=peopleList.stream().filter(people ->people.getAge()>19);
//終止操作:一次性執行全部內容,即惰性求值
s.forEach(System.out::println);
}
}

外部迭代
//外部迭代
Iterator<People> iterator = peopleList.iterator();
while(iterator.hasNext())
System.out.println(iterator.next());
limit ===> 短路
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("3號",19,5000),
new People("4號",20,3500)
);
@Test
void test()
{
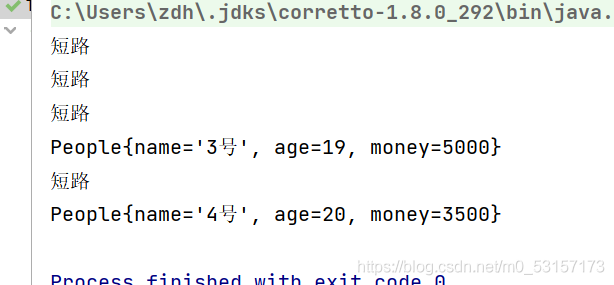
//當查詢到滿足條件的兩條資料后,就停止迭代,此行為稱為短路
peopleList.stream().
filter(people ->{
System.out.println("短路");
return people.getAge()>15;}).
limit(2).//短路
forEach(System.out::println);
}
}
skip ===>跳過前n個元素
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("3號",19,5000),
new People("4號",20,3500)
);
@Test
void test()
{
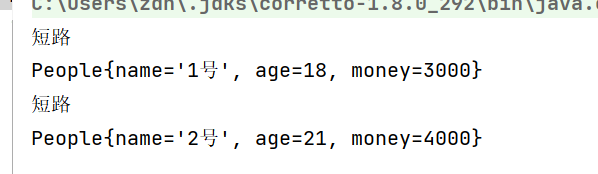
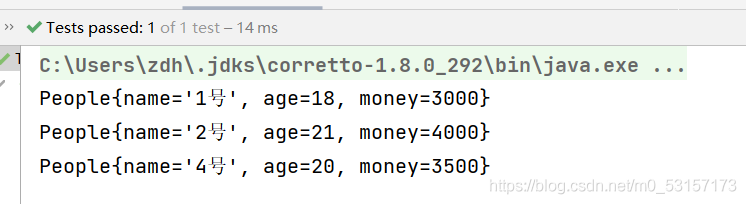
peopleList.stream().
filter(people ->{
System.out.println("短路");
return people.getAge()>15;}).
skip(2).
forEach(System.out::println);
}
}
distinct進行元素去重(自定義類需要重寫對應的hashcode和equals方法)
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("2號",21,4000),
new People("4號",20,3500)
);
@Test
void test()
{
peopleList.stream().
distinct().
forEach(System.out::println);
}
}
映射
map–接收Lambda,將元素轉換為其他形式或提取資訊,接收一個函式作為引數,該函式會被應用到每個元素上,并將其映射成一個新的元素
flatMap—接收一個函式作為引數,將流中的每個值都換成另一個流,然后把所有流連接成一個流
map的使用演示:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("2號",21,4000),
new People("4號",20,3500)
);
@Test
void test()
{
List<String> list=Arrays.asList("a","b","c");
//將原先集合里面的小寫,全部轉換為大寫,并輸出
list.stream().map((x)->x.toUpperCase()).forEach(System.out::println);
//對原先的流是沒有影響的
System.out.println(list);
System.out.println("------------------------------------------------");
// peopleList.stream().map(p->p.getName());
//將原先集合里面的People元素全部轉換為String元素
peopleList.stream().map(People::getName).forEach(System.out::println);
}
}

flatMap使用演示:
使用前,先看一下下面這個案例:
void test()
{
List<String> list=Arrays.asList("aaa","bbb","ccc");
Stream<Stream<Character>> sm = list.stream().map(TestMain::getAll);
//相當于當前sm大流里面存放了三個小流
sm.forEach(System.out::println);
}
public static Stream<Character> getAll(String str)
{
List<Character> list=new ArrayList<>();
for(Character ch:str.toCharArray())
{
list.add(ch);
}
return list.stream();
}

顯然這里我們將list集合對應的新流中每一個元素,都映射為了一個流,并回傳,相當于現在的大流中有三個小流
下面我們需要遍歷這些小流,取出里面的值
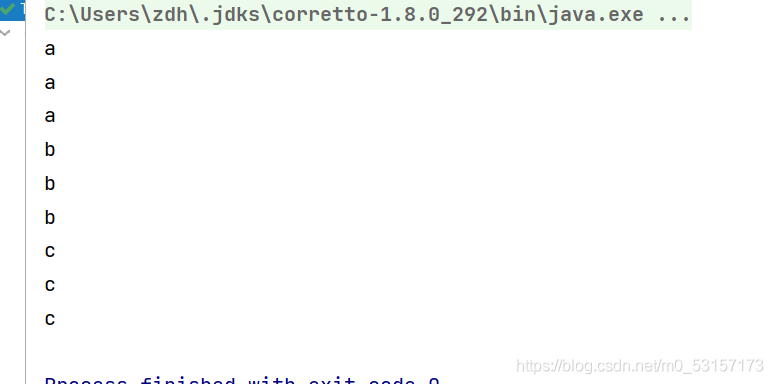
void test()
{
List<String> list=Arrays.asList("aaa","bbb","ccc");
Stream<Stream<Character>> sm = list.stream().map(TestMain::getAll);
//遍歷大流的同時,遍歷小流,取出小流中的值
sm.forEach(x-> x.forEach(System.out::println));//效果{{a,a,a},{b,b,b},{c,c,c}}
}
public static Stream<Character> getAll(String str)
{
List<Character> list=new ArrayList<>();
for(Character ch:str.toCharArray())
{
list.add(ch);
}
return list.stream();
}
顯然上面寫法比較復雜,下面給出簡化寫法
@Test
void test()
{
List<String> list=Arrays.asList("aaa","bbb","ccc");
//回傳值不在是大流嵌套小流,而是一個流
Stream<Character> characterStream = list.stream()
.flatMap(TestMain::getAll);// 效果{a,a,a,b,b,b,c,c,c}
characterStream.forEach(System.out::println);
}
public static Stream<Character> getAll(String str)
{
List<Character> list=new ArrayList<>();
for(Character ch:str.toCharArray())
{
list.add(ch);
}
return list.stream();
}

map與flatmap的區別
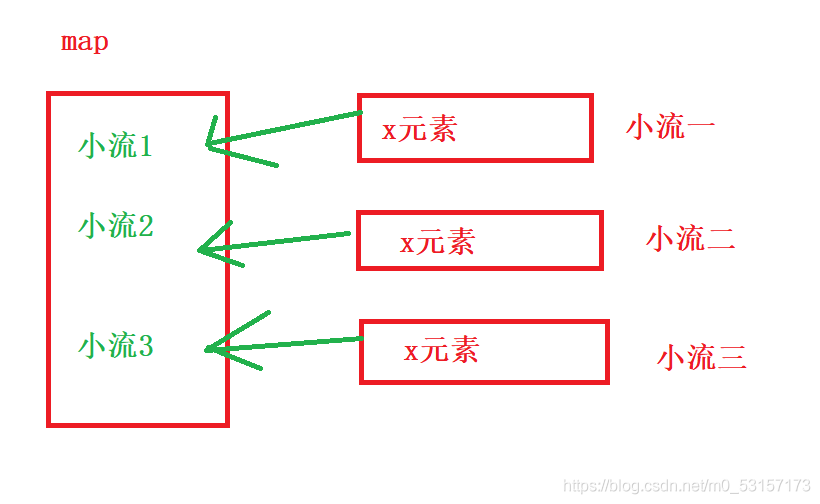
map是將對應的每個小流放入當前大流中構成一個流
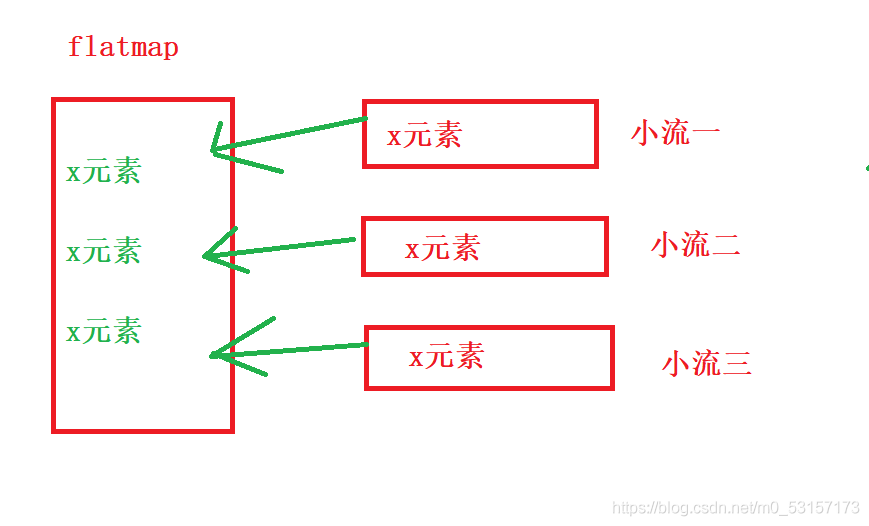
flatmap取出集合中的每個元素放入當前的流中,相當于將每個小流里面的元素拿出來組合為一個大流
這里還可以參考add()和addAll()的關系:
List<String> list=Arrays.asList("aaa","bbb","ccc");
List list1=new ArrayList();
list1.add(list);
list1.addAll(list);
System.out.println(list1);

排序
sorted()—自然排序(Comparable)
sorted(Comparator com)—定制排序(Comparator)
List<People> peopleList= Arrays.asList(
new People("1號",18,3000),
new People("2號",21,4000),
new People("2號",21,4000),
new People("4號",18,3500)
);
@Test
void test()
{
//這里people沒有實作Comparable介面,因此沒有自然排序的功能
//我們需要定制排序
peopleList.stream().sorted((x,y)->{
if(x.getAge()==y.getAge())
//money按照降序排列
return -x.money.compareTo(y.getMoney());
else
return x.getAge().compareTo(y.getAge());
}).forEach(System.out::println);
}
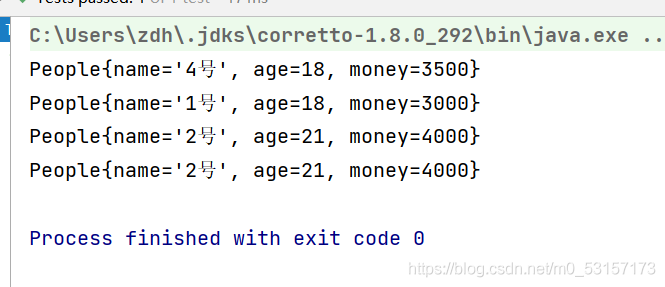
Stream的終止操作如下

查找與匹配
查找與匹配
allMatch--檢查是否匹配所有元素
anyMatch---檢查是否至少匹配一個元素
noneMatch---檢查是否沒有匹配所有元素
findFirst---回傳第一個元素
findAny---回傳當前流中任意元素
count---回傳流中元素的總個數
max----回傳流中最大值
min---回傳流中最小值
演示:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000, People.STATUS.BUSY),
new People("2號",21,4000, People.STATUS.FREE),
new People("2號",21,4000, People.STATUS.BUSY),
new People("4號",18,3500, People.STATUS.BUSY)
);
/*
allMatch--檢查是否匹配所有元素
anyMatch---檢查是否至少匹配一個元素
noneMatch---檢查是否沒有匹配所有元素
findFirst---回傳第一個元素
findAny---回傳當前流中任意元素
count---回傳流中元素的總個數
max----回傳流中最大值
min---回傳流中最小值*/
@Test
void test()
{
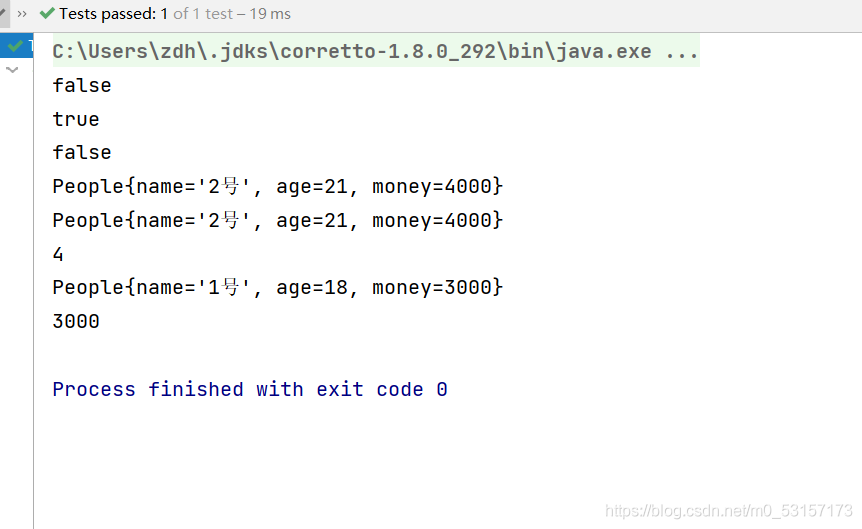
boolean ret = peopleList.stream().allMatch(x -> x.getStatus().equals(People.STATUS.BUSY));
System.out.println(ret);
boolean ret1 = peopleList.stream().anyMatch(x -> x.getStatus().equals(People.STATUS.FREE));
System.out.println(ret1);
boolean ret2 = peopleList.stream().noneMatch(x -> x.getStatus().equals(People.STATUS.BUSY));
System.out.println(ret2);
//得到第一個元素
Optional<People> first = peopleList.stream().sorted((x, y) -> -x.getMoney().compareTo(y.getMoney())).findFirst();
System.out.println(first.get());
//得到當前流中的任意一個元素
//parallelStream:多執行緒并行查找
Optional<People> any = peopleList.parallelStream().filter(x -> x.getStatus().equals(People.STATUS.FREE)).findAny();
System.out.println(any.get());
//元素總個數
long count = peopleList.stream().count();
System.out.println(count);
//回傳流中最大值和最小值
Optional<People> max = peopleList.stream().max((x, y) -> -x.getMoney().compareTo(y.getMoney()));
System.out.println(max.get());
//獲取當前最小的金錢數
Optional<Integer> min = peopleList.stream().map(People::getMoney).min(Integer::compareTo);
System.out.println(min.get());
}
}
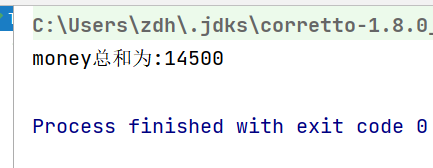
歸約–reduce
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000, People.STATUS.BUSY),
new People("2號",21,4000, People.STATUS.FREE),
new People("2號",21,4000, People.STATUS.BUSY),
new People("4號",18,3500, People.STATUS.BUSY)
);
@Test
void test()
{
// T reduce(T identity, BinaryOperator<T> accumulator);
//這里可以使用ClassName::MethodName的原因是 Function<T, R>,比getMoeny多一個引數,且第一個引數型別為People
Integer sum = peopleList.stream().map(People::getMoney).reduce(0, (x, y) -> x + y);//0是起始累加值
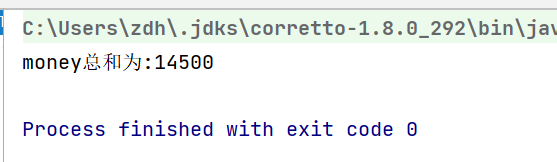
System.out.println("money總和為:"+sum);
}
}

也可以不指定起始值,但是這樣可能資料為空,因此會被封裝為一個Optional物件
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("1號",18,3000, People.STATUS.BUSY),
new People("2號",21,4000, People.STATUS.FREE),
new People("2號",21,4000, People.STATUS.BUSY),
new People("4號",18,3500, People.STATUS.BUSY)
);
@Test
void test()
{
// T reduce(T identity, BinaryOperator<T> accumulator);
Optional<Integer> reduce = peopleList.stream().map(People::getMoney).reduce((x, y) -> x + y);
System.out.println("money總和為:"+reduce.get());
}
}
這里不一定非要是數的累加,也可以是字串的反復拼接
.reduce("",String::contact);
收集
collect----將流轉換為其他形式,接收一個Collector介面的實作,用于給Stream中元素做匯總的方法

演示:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,4000, People.STATUS.BUSY),
new People("ddd",18,3500, People.STATUS.BUSY)
);
@Test
void test()
{
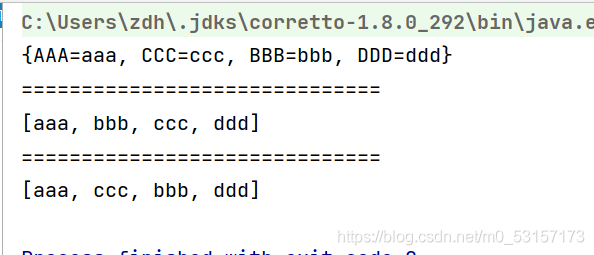
//結果收集到map中
Map<String, String> collect = peopleList.stream().map(People::getName)
//指定key和value,這里的key是name字串轉大寫,value就是name字串本身不變
.collect(Collectors.toMap(x -> x.toUpperCase(), y -> y));
System.out.println(collect);
System.out.println("==============================");
//結果收集到List中
List<String> stringList = peopleList.stream().map(People::getName).collect(Collectors.toList());
System.out.println(stringList);
System.out.println("==============================");
//結果收集到HashSet中
HashSet<String> collect1 = peopleList.stream().
map(People::getName).collect(Collectors.toCollection(HashSet::new));
System.out.println(collect1);
}
}
collect的其他一些用法
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,4000, People.STATUS.BUSY),
new People("ddd",18,3500, People.STATUS.BUSY)
);
@Test
void test()
{
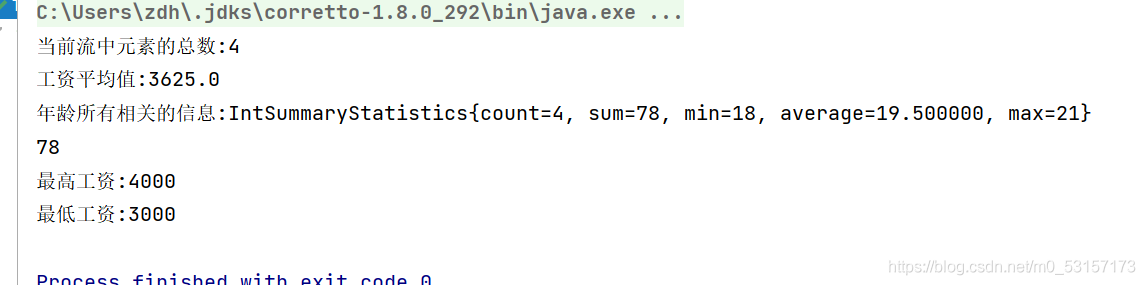
//計算當前流中元素的總數
Long sum = peopleList.stream().collect(Collectors.counting());
System.out.println("當前流中元素的總數:"+sum);
//計算工資平均值
Double MoneyAvg = peopleList.stream().collect(Collectors.averagingInt(People::getMoney));
System.out.println("工資平均值:"+MoneyAvg);
//計算年齡的所有資訊
IntSummaryStatistics age = peopleList.stream().collect(Collectors.summarizingInt(People::getAge));
System.out.println("年齡所有相關的資訊:"+age);
//計算年齡的總和
Integer ageSUm = peopleList.stream().collect(Collectors.summingInt(People::getAge));
System.out.println(ageSUm);
//計算工資最大值
Optional<Integer> moneyMax = peopleList.stream().map(People::getMoney).collect(Collectors.maxBy((x,y)->Integer.compare(x,y)));
System.out.println("最高工資:"+moneyMax.get());
//計算最低工資
Optional<Integer> moneyMin = peopleList.stream().map(People::getMoney).collect(Collectors.minBy(Integer::compare));
System.out.println("最低工資:"+moneyMin.get());
}
}
collect里面的分組
單級分組:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,4000, People.STATUS.FREE),
new People("ddd",18,3500, People.STATUS.BUSY)
);
@Test
void test()
{
//單級分組
Map<People.STATUS, List<People>> collect = peopleList.stream().collect(Collectors.groupingBy(People::getStatus));
System.out.println(collect);
}
}

多級分組:
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,10000, People.STATUS.FREE),
new People("ddd",18,12000, People.STATUS.BUSY)
);
@Test
void test()
{
//先按照狀態分組,再按照money分組
Map<People.STATUS, Map<String, List<People>>> collect = peopleList.stream().collect(Collectors.groupingBy(People::getStatus, Collectors.groupingBy(
x -> {
if (x.getMoney() >= 10000)
return "有錢人";
else
return "窮人";
}
)));
System.out.println(collect);
}
}

collect里面的磁區
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,10000, People.STATUS.FREE),
new People("ddd",18,12000, People.STATUS.BUSY)
);
@Test
void test()
{
//按照true or false進行磁區
Map<Boolean, List<People>> ret = peopleList.stream().collect(Collectors.partitioningBy(x -> x.getMoney() >= 10000));
System.out.println(ret);
}
}
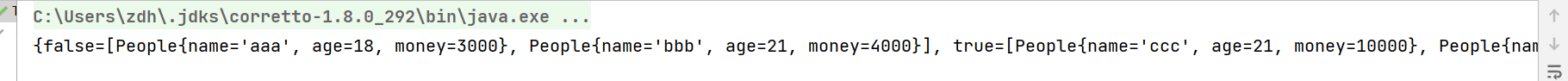
collect里面獲取某個屬性相關的詳細資訊(平均值,最大值…)
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,10000, People.STATUS.FREE),
new People("ddd",18,12000, People.STATUS.BUSY)
);
@Test
void test()
{
IntSummaryStatistics collect = peopleList.stream().collect(Collectors.summarizingInt(People::getMoney));
System.out.println(collect);
System.out.println(collect.getMax());
System.out.println(collect.getCount());
}
}

collect里面的join,完成字串連接作業
public class TestMain
{
List<People> peopleList= Arrays.asList(
new People("aaa",18,3000, People.STATUS.BUSY),
new People("bbb",21,4000, People.STATUS.FREE),
new People("ccc",21,10000, People.STATUS.FREE),
new People("ddd",18,12000, People.STATUS.BUSY)
);
@Test
void test()
{
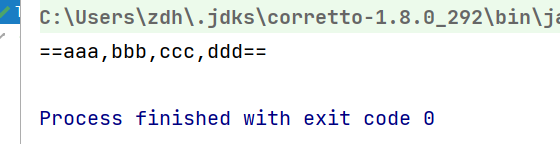
//第一個引數是連接字串時分割的符合,后面兩個引數依次是前綴和后綴
String ret = peopleList.stream().map(People::getName).collect(Collectors.joining(",", "==", "=="));
System.out.println(ret);
}
}
并行流與串行流
一、什么是并行流
并行流 : 就是把一個內容分成多個資料塊,并用不同的執行緒分 別處理每個資料塊的流,
Java 8 中將并行進行了優化,我們可以很容易的對資料進行并 行操作,Stream API 可以宣告性地通過 parallel() 與 sequential() 在并行流與順序流之間進行切換,
二、了解 Fork/Join框架
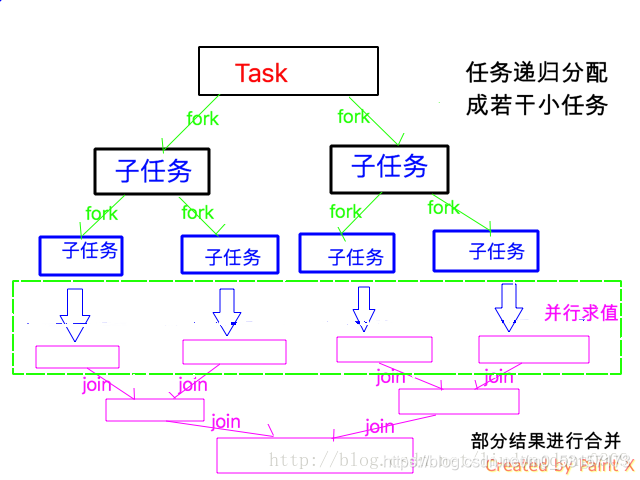
Fork/Join 框架 : 就是在必要的情況下,將一個大任務,進行拆分(fork)成若干個 小任務(拆到不可再拆時),再將一個個的小任務運算的結果進行 join 匯總.
三、Fork/Join 框架與傳統執行緒池的區別
采用 “作業竊取”模式(work-stealing): 當執行新的任務時它可以將其拆分分成更小的任務執行,并將小任務加到線 程佇列中,然后再從一個隨機執行緒的佇列中偷一個并把它放在自己的佇列中,
相對于一般的執行緒池實作,fork/join框架的優勢體現在對其中包含的任務的 處理方式上.在一般的執行緒池中,如果一個執行緒正在執行的任務由于某些原因 無法繼續運行,那么該執行緒會處于等待狀態,而在fork/join框架實作中,如果 某個子問題由于等待另外一個子問題的完成而無法繼續運行.那么處理該子 問題的執行緒會主動尋找其他尚未運行的子問題來執行,這種方式減少了執行緒 的等待時間, 高了性能,
四、 案例
創建一個ForkJoinCalculate計算類:
public class ForkJoinCalculate extends RecursiveTask<Long> {
private long start;
private long end;
private static final long THRESHOLD = 1000000;
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if (length <= THRESHOLD) {
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else {
long middle = (start + end) / 2;
ForkJoinCalculate left = new ForkJoinCalculate(start, middle);
left.fork();
ForkJoinCalculate right = new ForkJoinCalculate(middle + 1, end);
right.fork();
return left.join() + right.join();
}
}
}
測驗方法:
private static final long END_VALUE = 10000000000L;
// fork join
@Test
public void test1(){
Instant start = Instant.now();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinCalculate(0, END_VALUE);
Long sum = pool.invoke(task);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗時:" + Duration.between(start, end).toMillis());
}
執行結果:
-5340232216128654848
耗時:2325
使用普通for 回圈:
@Test
public void test2(){
Instant start = Instant.now();
long sum = 0L;
for (long i = 0; i <= END_VALUE; i ++){
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("耗時:" + Duration.between(start, end).toMillis());
}
執行結果:
-5340232216128654848
耗時:3571
java8中 Fork/Join計算
//java8 的并行流測驗
@Test
public void test3(){
Instant start = Instant.now();
LongStream.rangeClosed(0, END_VALUE)
.parallel()
.reduce(0, Long::sum);
Instant end = Instant.now();
System.out.println("耗時為:" + Duration.between(start, end).toMillis());
}
執行結果:
耗時為:1690
檢查本機的可用處理器數:
// 可用處理器
@Test
public void test4(){
int num = Runtime.getRuntime().availableProcessors();
System.out.println(num);
}
執行結果:
8
Optional類

Java 8 Optional的正確姿勢
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/293597.html
標籤:java
上一篇:Java之面向物件