網上PaddleClass2.2文章很少,都是2.1,但是2.2和2.1的配置還是有些區別的,而且看了網上很多關于paddle lite樹莓派相關教程都是修改cc檔案,然后./run.sh,但是沒有直接呼叫python api的教程,更有甚至利用python使用os.system('./run.sh')進行呼叫,實在難受,因此有了這篇文章來記錄一下,
本專案主要是基于PaddleClas2.2的奧特曼識別,從資料訓練到利用PaddleLite2.9框架將模型部署到樹莓派4b 64位,然后在樹莓派上利用paddlelite框架的python api進行模型轉換和圖片&視頻流對奧特曼的識別,
目錄
1.資料處理
2.模型訓練
3.模型評估
4.模型轉換
5.樹莓派部署
1.資料處理
我們利用百度的aistudio白嫖算力進行資料訓練,
首先是資料解壓處理
# 資料解壓
!unzip -oq /home/aistudio/data/data104203/aoteman.zipaoteman檔案夾結構如下
aoteman
├── dijia
│ ├── 001.jpg
│ ├── 002.jpg
│ ├── 003.jpg
│ ├── ······
├── jieke
│ ├── 001.jpg
│ ├── 002.jpg
│ ├── 003.jpg
│ ├── ······
├── saiwen
│ ├── 001.jpg
│ ├── 002.jpg
│ ├── 003.jpg
│ ├── ······
├── tailuo
│ ├── 001.jpg
│ ├── 002.jpg
│ ├── 003.jpg
│ ├── ······
├──predict_demo.jpg
由于代碼執行警告太多很煩,我也先去掉
import warnings
warnings.filterwarnings("ignore")資料集劃分是個很煩的事,之前我也是自己def了n個函式劃分然后寫入txt,很麻煩,小白甚至覺得訓練都沒資料處理煩,這里我推薦jikuai庫,可以一鍵劃分生成txt,我們先安裝一下,
!pip install jikuai -q那么接下來我們就開始git paddleclas了 ,并選擇2.2分支
!git clone https://gitee.com/paddlepaddle/PaddleClas.git -b release/2.2然后利用jiekuai進行資料劃分
%cd ~/
from jikuai.dataset import Dataset
dataset = Dataset("aoteman") # 引數為資料集所在的位置,是分類目錄的上一級目錄
dataset.paddleclastxt(0.8) # 生成訓練集和測驗集串列,引數為兩者劃分的比例值,
!ls
# 2280348.ipynb aoteman data eval.txt PaddleClas train.txt work
我們把資料移到PaddleClas/dataset里,方便打包
!mv eval.txt aoteman/
!mv train.txt aoteman/
!mv aoteman PaddleClas/dataset/2.模型訓練
接下來是最重要的tran前配置了,不得不說PaddleClas比PaddleDetection配置要方便多了,全在一個yaml里
我們對 PaddleClas/ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml 進行修改設定
主要是以下幾點:分類數、訓練和驗證的路徑、影像尺寸、資料預處理、訓練和預測的num_workers: 0才可以在aistudio跑通,
# global configs
Global:
checkpoints: null
# 預訓練模型加載,這里不用了
pretrained_model: null
# 模型保存地址
output_dir: ./output/
# 沒有gpu就用cpu
device: gpu
# 每幾個輪次保存一次
save_interval: 1
eval_during_train: True
# 每幾個輪次驗證一次
eval_interval: 1
# 訓練600輪次
epochs: 600
# 每10步列印
print_batch_step: 10
# 可視化,這里不開啟
use_visualdl: False
# 預測模型匯出地址
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# 模型結構
Arch:
name: ShuffleNetV2_x0_25
# 類別
class_num: 4
# 訓練/評估程序的損失函式配置
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Cosine
learning_rate: 0.0125
warmup_epoch: 5
regularizer:
name: 'L2'
coeff: 0.00001
# 用于訓練和評估的資料加載配置
DataLoader:
Train:
dataset:
name: ImageNetDataset
# 檔案根目錄 因為train.txt格式是“aoteman/tailuo/072.jpg 3” 以便匯入
image_root: ./dataset
# train劃分地址
cls_label_path: ./dataset/aoteman/train.txt
# 資料預處理
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
# 每一步16個資料加載
batch_size: 16
drop_last: False
shuffle: True
loader:
num_workers: 0 # 這里一定要0才可以跑通aistudio
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset
cls_label_path: ./dataset/aoteman/eval.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 0
use_shared_memory: True
Infer:
infer_imgs: ./dataset/aoteman/predict_demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
# 輸出的可能性最高的前topk個
topk: 4
# 標簽檔案 需要自己新建檔案
class_id_map_file: ./dataset/aoteman/labels.txt
Metric:
Train:
- TopkAcc:
topk: [1, 4]
Eval:
- TopkAcc:
topk: [1, 4]自己建個標簽檔案 ./dataset/label_list.txt
0 迪迦奧特曼
1 杰克奧特曼
2 賽文奧特曼
3 泰羅奧特曼配置搞定,那么接下來開始訓練吧~
# 采用GPU訓練
!export CUDA_VISIBLE_DEVICES=0
%cd ~/PaddleClas/
!python tools/train.py \
-c ./ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml訓練結果一窺究竟
[2021/08/13 18:01:49] root INFO: [Train][Epoch 596/600][Iter: 0/28]lr: 0.00001, CELoss: 0.03720, loss: 0.03720, top1: 1.00000, top4: 1.00000, batch_cost: 0.30420s, reader_cost: 0.25090, ips: 52.59725 images/sec, eta: 0:00:42
[2021/08/13 18:01:51] root INFO: [Train][Epoch 596/600][Iter: 10/28]lr: 0.00001, CELoss: 0.13251, loss: 0.13251, top1: 0.96023, top4: 1.00000, batch_cost: 0.22338s, reader_cost: 0.17151, ips: 71.62723 images/sec, eta: 0:00:29
[2021/08/13 18:01:53] root INFO: [Train][Epoch 596/600][Iter: 20/28]lr: 0.00001, CELoss: 0.12071, loss: 0.12071, top1: 0.96131, top4: 1.00000, batch_cost: 0.21830s, reader_cost: 0.16640, ips: 73.29514 images/sec, eta: 0:00:26
[2021/08/13 18:01:55] root INFO: [Train][Epoch 596/600][Avg]CELoss: 0.11507, loss: 0.11507, top1: 0.96591, top4: 1.00000
[2021/08/13 18:01:56] root INFO: [Eval][Epoch 596][Iter: 0/2]CELoss: 0.30446, loss: 0.30446, top1: 0.92188, top4: 1.00000, batch_cost: 1.02158s, reader_cost: 0.99066, ips: 62.64828 images/sec
[2021/08/13 18:01:56] root INFO: [Eval][Epoch 596][Avg]CELoss: 0.31860, loss: 0.31860, top1: 0.90909, top4: 1.00000
[2021/08/13 18:01:56] root INFO: [Eval][Epoch 596][best metric: 0.9454545497894287]
[2021/08/13 18:01:56] root INFO: Already save model in ./output/ShuffleNetV2_x0_25/epoch_596
[2021/08/13 18:01:56] root INFO: Already save model in ./output/ShuffleNetV2_x0_25/latest訓練600epoch,基本上top1能穩定90-96%以上了,大家可以試下加載預訓練模型,舉個例子,
python3 tools/train.py \
-c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml \
-o Arch.pretrained=True \
-o Global.device=gpu其中
Arch.pretrained設定為True表示加載ImageNet的預訓練模型,此外,Arch.pretrained也可以指定具體的模型權重檔案的地址,使用時需要換成自己的預訓練模型權重檔案的路徑,
3.模型評估
對我們模型評估一下 ,有90以上了,可以用了,
%cd ~/PaddleClas
!python3 tools/eval.py \
-c ./ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml \
-o Global.pretrained_model=output/ShuffleNetV2_x0_25/latest[2021/08/14 10:30:57] root INFO: [Eval][Epoch 0][Iter: 0/2]CELoss: 0.31628, loss: 0.31628, top1: 0.92188, top4: 1.00000, batch_cost: 1.16294s, reader_cost: 1.12821, ips: 55.03274 images/sec
[2021/08/14 10:30:57] root INFO: [Eval][Epoch 0][Avg]CELoss: 0.33670, loss: 0.33670, top1: 0.90909, top4: 1.00000我們用我們的模型來驗證一下
!python3 tools/infer.py \
-c ./ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml \
-o Infer.infer_imgs=dataset/aoteman/predict_demo.jpg \
-o Global.pretrained_model=output/ShuffleNetV2_x0_25/latest[{'class_ids': [0, 1, 3, 2], 'scores': [1.0, 0.0, 0.0, 0.0], 'file_name': 'dataset/aoteman/predict_demo.jpg', 'label_names': ['迪迦奧特曼 ', '杰克奧特曼 ', '泰羅奧特曼', '賽文奧特曼 ']}]驗證推定100%是迪迦奧特曼,我們看下是不是迪迦奧特曼, 果然是哈~

4.模型轉換
最后要把模型匯出inference模型,為什么又要匯出新格式模型呢,原來模型不是可以用了嗎?因為原來模型是包含正向和反向傳播的,而我們部署上線是不需要反向傳播的,因此我們匯出預測專用的inference模型,
# 匯出inference模型
!python3 tools/export_model.py \
-c ./ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml \
-o Global.pretrained_model=./output/ShuffleNetV2_x0_25/latest模型匯出到了我們.yaml里寫的 PaddleClas/inference檔案夾里里,我們將他下載上傳到樹莓派里,我們開始下一階段,
5.樹莓派部署
首先進行樹莓派PaddleLite2.9原始碼編譯,這大家也可以參考官方檔案,
https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_linux.html
我們先寫個inference模型轉nb模型的python代碼
# https://paddlelite.paddlepaddle.org.cn/api_reference/python_api/opt.html
# 參考Paddlelite預測庫
from paddlelite.lite import *
# 1. 創建opt實體
opt=Opt()
# 2. 指定輸入模型地址
# 非combined形式
#opt.set_model_dir("./mobilenet_v1")
# conmbined形式,具體模型和引數名稱,請根據實際修改
opt.set_model_file("./aoteman_inference/inference.pdmodel")
opt.set_param_file("./aoteman_inference/inference.pdiparams")
# 3. 指定轉化型別: arm、x86、opencl、npu
opt.set_valid_places("arm")
# 4. 指定模型轉化型別: naive_buffer、protobuf
opt.set_model_type("naive_buffer")
# 5. 動態離線量化
opt.set_quant_model(True)
opt.set_quant_type("QUANT_INT8")
# 6. 輸出模型地址
opt.set_optimize_out("aoteman_model")
# 7. 執行模型優化
opt.run()
生成aoteman_model.nb模型,這樣才可以被paddlelite呼叫,
然后我們建個predict.py利用python api進行模型呼叫和推斷
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加載模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#影像歸一化處理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 預測
def predict(image, predictor, input_image_size):
#輸入資料處理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#執行預測
predictor.run()
#獲取輸出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示結果
def post_res(label_dict, res):
print(max(res))
target_index = res.index(max(res))
print("結果是:" + " " + label_dict[target_index])
if __name__ == '__main__':
# 初始定義
label_dict = {0:"dijia", 1:"jieke", 2:"saiwen", 3:"tailuo"}
image = "./saiwen2.jpg"
model_dir = "./trans/aoteman_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
# 讀入圖片
image = cv2.imread(image)
# 預測
res = predict(image, predictor, image_size)
# 顯示結果
post_res(label_dict, res)
cv2.imshow("image", image)
cv2.waitKey() 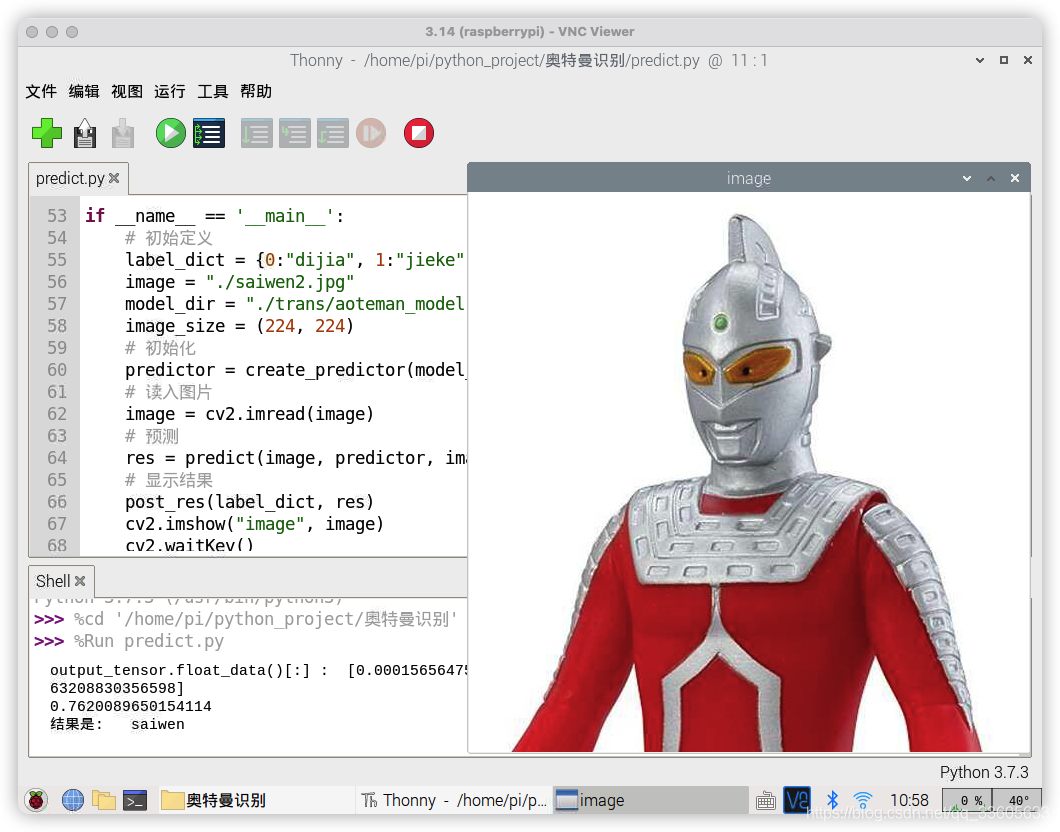
網上隨便找的賽文奧特曼被推斷出來了~
除了照片識別還不滿足,我們利用攝像頭視頻流進行識別,建了個predict_camera.py如下
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加載模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#影像歸一化處理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 預測
def predict(image, predictor, input_image_size):
#輸入資料處理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#執行預測
predictor.run()
#獲取輸出
output_tensor = predictor.get_output(0)
# print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示結果
def post_res(label_dict, res):
# print(max(res))
target_index = res.index(max(res))
# print("結果是:" + " " + label_dict[target_index], "準確率為:", max(res))
print(max(res))
return max(res), label_dict[target_index]
if __name__ == '__main__':
# 初始定義
label_dict = {0:"dijia", 1:"jieke", 2:"saiwen", 3:"tailuo"}
model_dir = "./trans/aoteman_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 預測
print('Predict Start')
time_start=time.time()
res = predict(frame, predictor, image_size)
confidence, label_result = post_res(label_dict, res)
fps = 1/(time.time()-time_start)
# 顯示結果
post_res(label_dict, res)
if confidence > 0.5:
cv2.putText(frame, '{}'.format(label_result), (20, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
cv2.putText(frame, '{:.2f}'.format(confidence), (20, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
cv2.putText(frame, 'fps:{:.2f}'.format(fps), (20, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
cv2.imwrite('out.png', frame)
print("save one image done!")
break
print('Predict End')
cap.release()
cv2.destroyAllWindows()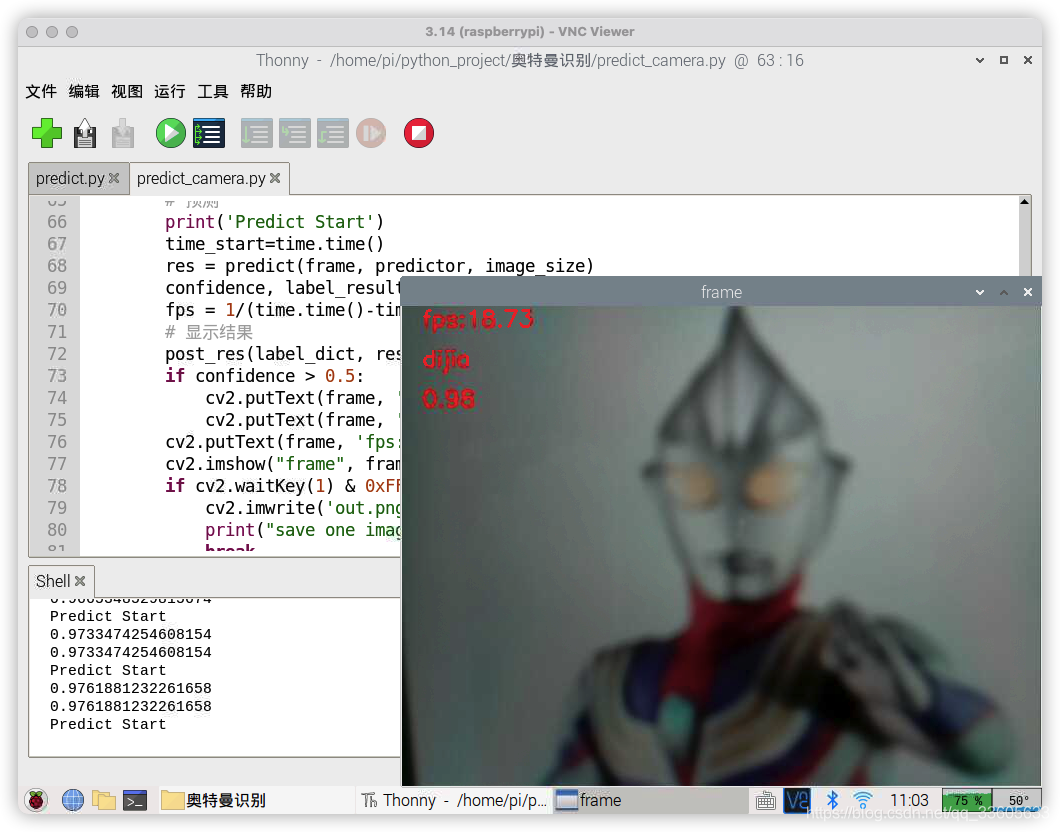
迪迦奧特曼被識別出來了!
需要影像資料或者opencv paddlelite編譯需求,甚至鏡像需要請私聊,
如下配置鏡像,并開啟jupyter開機自啟,插件已經裝全,
OpenCV 4.5.1
ncnn 20210124
MNN 1.1.0
Paddle-Lite 2.9
TensorFlow-Lite 2.4.1
TensorFLow 2.4.1
TensorFlow Addons 0.13.0-dev
Pytorch 1.8.0
TorchVision 0.9.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/293977.html
標籤:python