K-Means 是一種非常簡單的聚類演算法(聚類演算法都屬于無監督學習),給定固定數量的聚類和輸入資料集,該演算法試圖將資料劃分為聚類,使得聚類內部具有較高的相似性,聚類與聚類之間具有較低的相似性,
演算法原理
1. 初始化聚類中心,或者在輸入資料范圍內隨機選擇,或者使用一些現有的訓練樣本(推薦)
2. 直到收斂
- 將每個資料點分配到最近的聚類,點與聚類中心之間的距離是通過歐幾里德距離測量得到的,
- 通過將聚類中心的當前估計值設定為屬于該聚類的所有實體的平均值,來更新它們的當前估計值,
目標函式
聚類演算法的目標函式試圖找到聚類中心,以便資料將劃分到相應的聚類中,并使得資料與其最接近的聚類中心之間的距離盡可能小,
給定一組資料X1,...,Xn和一個正數k,找到k個聚類中心C1,...,Ck并最小化目標函式:
其中
是質心,計算運算式為
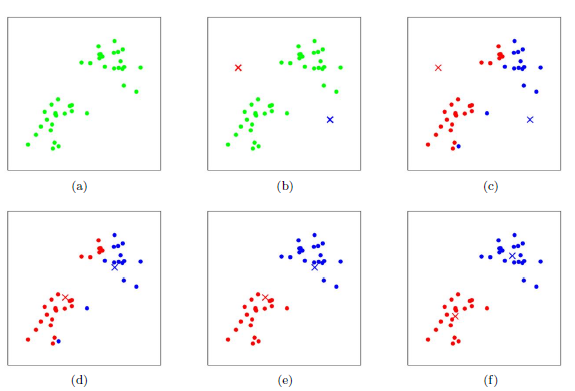
上圖a表達了初始的資料集,假設k=2,在圖b中,我們隨機選擇了兩個k類所對應的類別質心,即圖中的紅色質心和藍色質心,然后分別求樣本中所有點到這兩個質心的距離,并標記每個樣本的類別為和該樣本距離最小的質心的類別,如圖c所示,經過計算樣本和紅色質心和藍色質心的距離,我們得到了所有樣本點的第一輪迭代后的類別,此時我們對我們當前標記為紅色和藍色的點分別求其新的質心,如圖4所示,新的紅色質心和藍色質心的位置已經發生了變動,圖e和圖f重復了我們在圖c和圖d的程序,即將所有點的類別標記為距離最近的質心的類別并求新的質心,最終我們得到的兩個類別如圖f,當然在實際K-Mean演算法中,我們一般會多次運行圖c和圖d,才能達到最終的比較優的類別,
演算法流程
注意點:
- 對于K-Means演算法,首先要注意的是k值的選擇,一般來說,我們會根據對資料的先驗經驗選擇一個合適的k值,如果沒有什么先驗知識,則可以通過交叉驗證選擇一個合適的k值
- 在確定了k的個數后,我們需要選擇k個初始化的質心,就像上圖b中的隨機質心,由于我們是啟發式方法,k個初始化的質心的位置選擇對最后的聚類結果和運行時間都有很大的影響,因此需要選擇合適的k個質心,最好這些質心不能太近,
流程:
輸入是樣本集D={x1,x2,...xm},聚類的簇樹k,最大迭代次數N
輸出是簇劃分C={C1,C2,...Ck}
1) 從資料集D中隨機選擇k個樣本作為初始的k個質心向量: {μ1,μ2,...,μk}
2)對于n=1,2,...,N
a) 將簇劃分C初始化為Ct=? t=1,2...k
b) 對于i=1,2...m,計算樣本xi和各個質心向量μj(j=1,2,...k)的距離:,將xixi標記最小的為
所對應的類別
,此時更新
c) 對于j=1,2,...,k,對Cj中所有的樣本點重新計算新的質心
e) 如果所有的k個質心向量都沒有發生變化,則轉到步驟3)
3) 輸出簇劃分C={C1,C2,...Ck}
Python實作
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.datasets import make_blobs
np.random.seed(123)
from sklearn.cluster import KMeans
class Kmeans:
def __init__(self,data,k):
self.data=data
self.k = k
def cluster_data_Bysklearn(self):
kmeans_model = KMeans(self.k,random_state=1)
labels = kmeans_model.fit(self.data).labels_
print(labels)
return labels
def kmeans(self):
# 獲取4個亂數
rarray = np.random.random(size=self.k)
# 乘以資料集大小——>資料集中隨機的4個點
rarray = np.floor(rarray * len(self.data))
# 轉為int
rarray = rarray.astype(int)
print('資料集中隨機索引', rarray)
# 隨機取資料集中的4個點作為初始中心點
center = data[rarray]
# 測驗比較偏、比較集中的點,效果依然完美,測驗需要洗掉以上代碼
# center = np.array([[4.6,-2.5],[4.4,-1.7],[4.3,-0.7],[4.8,-1.1]])
# 1行80列的0陣列,標記每個樣本所屬的類(k[i])
cls = np.zeros([len(self.data)], np.int)
print('初始center=\n', center)
run = True
time = 0
n = len(self.data)
while run:
time = time + 1
for i in range(n):
# 求差
tmp = data[i] - center
# 求平方
tmp = np.square(tmp)
# axis=1表示按行求和
tmp = np.sum(tmp, axis=1)
# 取最小(最近)的給該點“染色”(標記每個樣本所屬的類(k[i]))
cls[i] = np.argmin(tmp)
# 如果沒有修改各分類中心點,就結束回圈
run = False
# 計算更新每個類的中心點
for i in range(self.k):
# 找到屬于該類的所有樣本
club = data[cls == i]
# axis=0表示按列求平均值,計算出新的中心點
newcenter = np.mean(club, axis=0)
# 如果新舊center的差距很小,看做他們相等,否則更新之,run置true,再來一次回圈
ss = np.abs(center[i] - newcenter)
if np.sum(ss, axis=0) > 1e-4:
center[i] = newcenter
run = True
print('new center=\n', center)
print('程式結束,迭代次數:', time)
# 按類列印圖表,因為每列印一次,顏色都不一樣,所以可區分出來
# for i in range(self.k):
# club = data[cls == i]
# self.showtable(club)
# 列印最后的中心點
self.showtable(center)
#列印聚類標簽
print(cls)
def showtable(self,data):
x = data.T[0]
y = data.T[1]
plt.scatter(x, y)
plt.show()
if __name__ == '__main__':
data = np.random.rand(10,2)
K = 4
model = Kmeans(data,K)
model.kmeans()
model.cluster_data_Bysklearn()結果:
自寫得出的 [0 2 0 0 0 2 3 2 1 2]
呼叫模型的出的[0 2 0 1 0 2 3 2 3 0]jupyter notebook實作
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.datasets import make_blobs
%matplotlib inlineX, y = make_blobs(centers=6, n_samples=1000)
print(f'Shape of dataset: {X.shape}')
fig = plt.figure(figsize=(8,6))
plt.scatter(X[:,0], X[:,1], c=y)
plt.title("Dataset with 6 clusters")
plt.xlabel("First feature")
plt.ylabel("Second feature")
plt.show()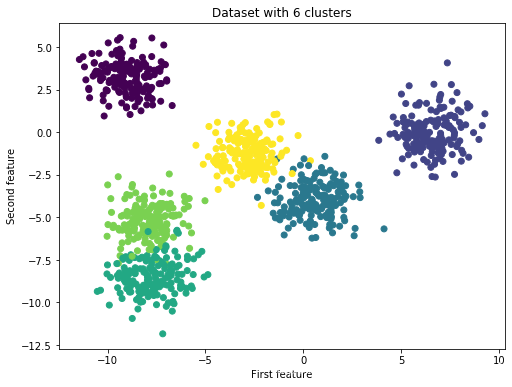
class KMeans():
def __init__(self, n_clusters=6):
self.k = n_clusters
def fit(self, data):
"""
Fits the k-means model to the given dataset
"""
n_samples, _ = data.shape
# initialize cluster centers
self.centers = np.array(random.sample(list(data), self.k))
self.initial_centers = np.copy(self.centers)
# We will keep track of whether the assignment of data points
# to the clusters has changed. If it stops changing, we are
# done fitting the model
old_assigns = None
n_iters = 0
while True:
new_assigns = [self.classify(datapoint) for datapoint in data]
if new_assigns == old_assigns:
print(f"Training finished after {n_iters} iterations!")
return
old_assigns = new_assigns
n_iters += 1
# recalculate centers
for id_ in range(self.k):
points_idx = np.where(np.array(new_assigns) == id_)
datapoints = data[points_idx]
self.centers[id_] = datapoints.mean(axis=0)
def l2_distance(self, datapoint):
dists = np.sqrt(np.sum((self.centers - datapoint)**2, axis=1))
return dists
def classify(self, datapoint):
"""
Given a datapoint, compute the cluster closest to the
datapoint. Return the cluster ID of that cluster.
"""
dists = self.l2_distance(datapoint)
return np.argmin(dists)
def plot_clusters(self, data):
plt.figure(figsize=(12,10))
plt.title("Initial centers in black, final centers in red")
plt.scatter(data[:, 0], data[:, 1], marker='.', c='y')
plt.scatter(self.centers[:, 0], self.centers[:,1], c='r')
plt.scatter(self.initial_centers[:, 0], self.initial_centers[:,1], c='k')
plt.show()X = np.random.randn(10,100)
kmeans = KMeans(n_clusters=6)
kmeans.fit(X)
for data in X:
print(kmeans.classify(data))總結
K-Means的主要優點:
1)原理簡單,容易實作
2)可解釋度較強
K-Means的主要缺點:
1)K值很難確定
2)區域最優
3)對噪音和例外點敏感
4)需樣本存在均值(限定資料種類)
5)聚類效果依賴于聚類中心的初始化
6)對于非凸資料集或類別規模差異太大的資料效果不好
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/294216.html
標籤:python