1、背景
為什么需要降維呢?
因為資料個數 N 和每個資料的維度 p 不滿足 N >> p,造成了模型結果的“過擬合”,有兩種方法解決上述問題:
- 增加N;
- 減小p,
這里我們講解的 PCA 屬于方法2,
2、樣本均值和樣本方差矩陣


3、PCA
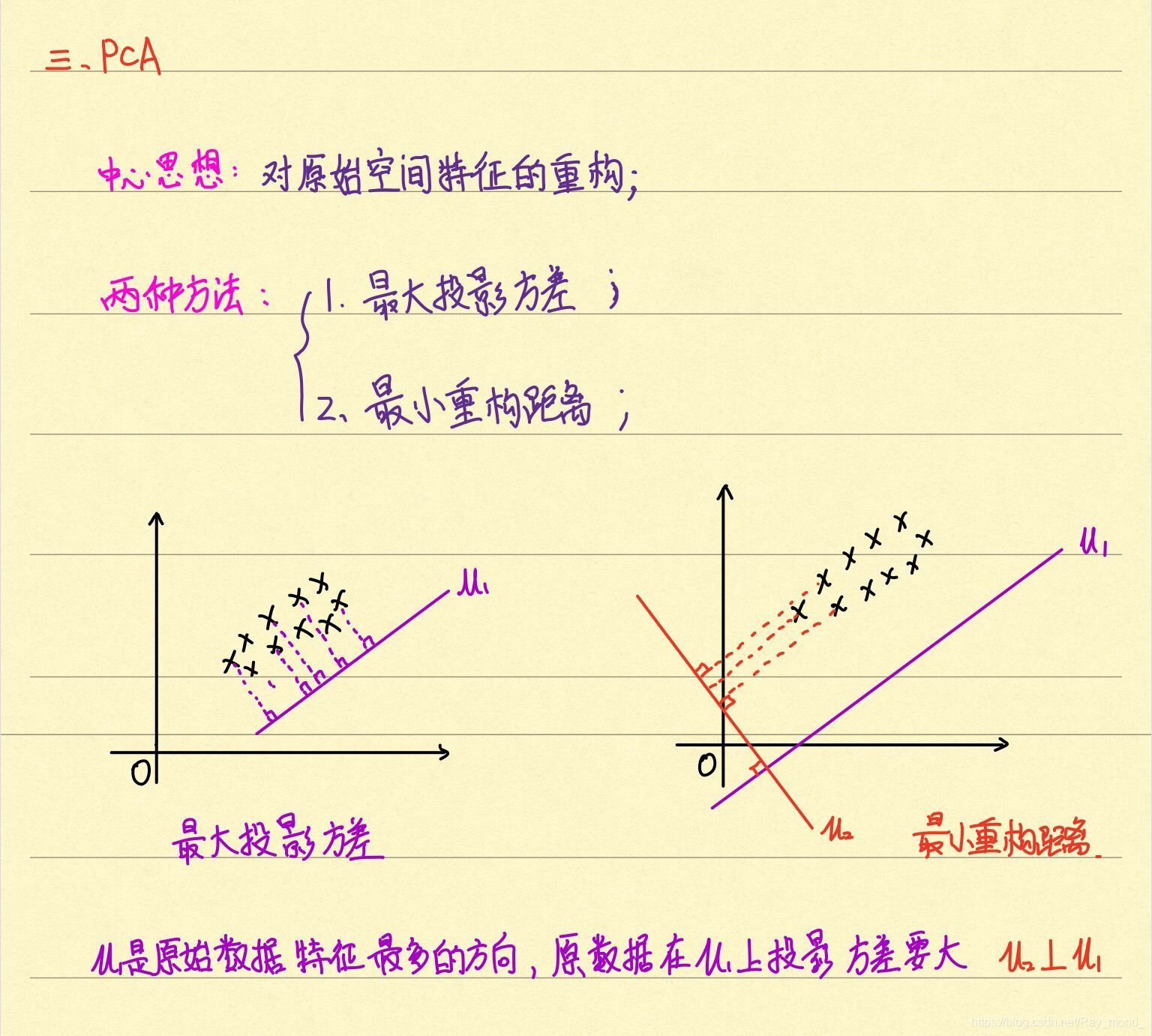

3.1 最大投影方差

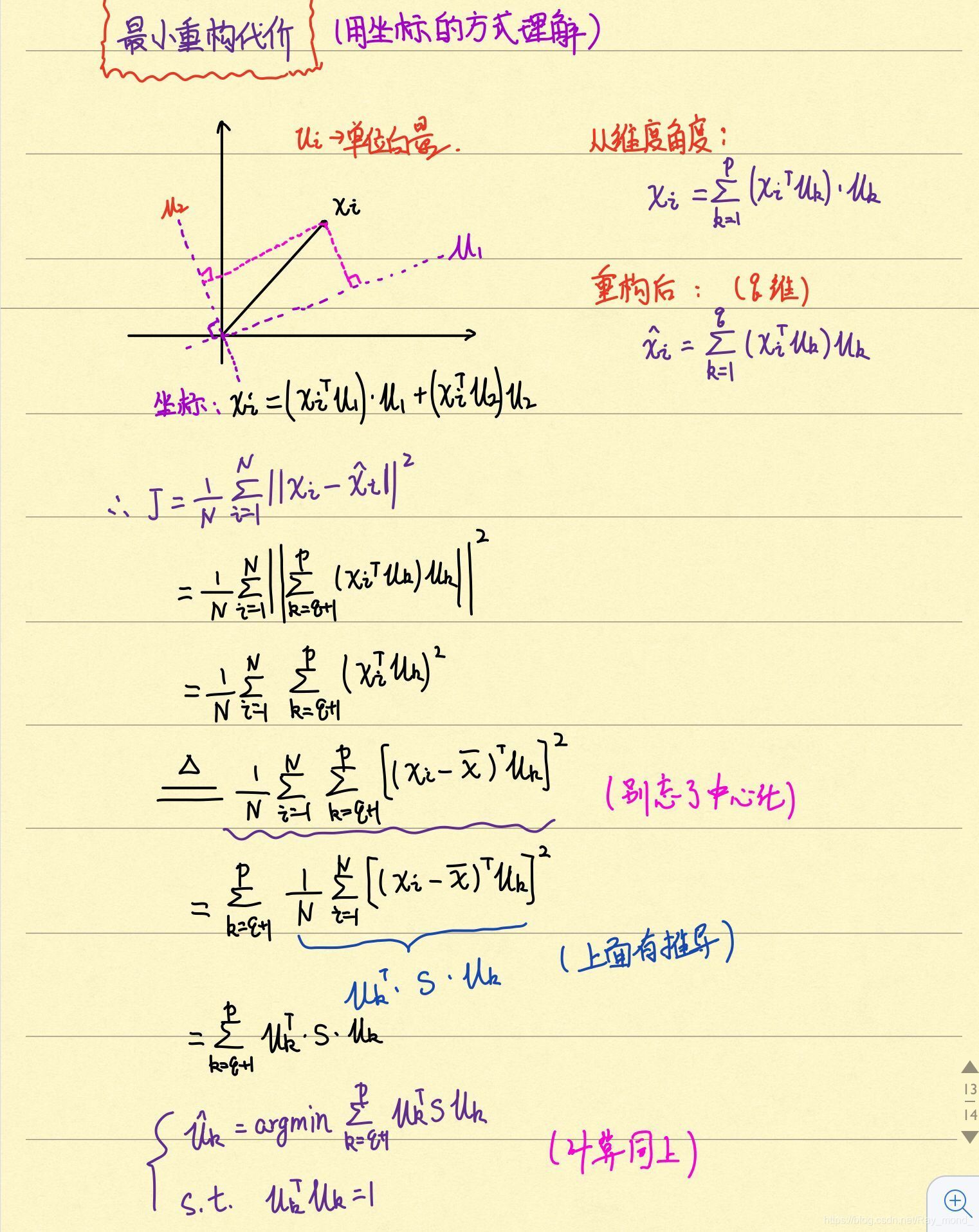
3.2 最小重構距離
4、Python實作
"""
-*- coding: utf-8 -*-
@ Time : 2021/8/15 22:19
@ Author : Raymond
@ Email : wanght2316@163.com
@ Editor : Pycharm
"""
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
digits = load_digits()
print(digits.keys())
print("資料的形狀為: {}".format(digits['data'].shape))
# 構建模型 - 降到10 d
pca = PCA(n_components=10)
pca.fit(digits.data)
projected=pca.fit_transform(digits.data)
print('降維后主成分的方差值為:',pca.explained_variance_)
print('降維后主成分的方差值占總方差的比例為:',pca.explained_variance_ratio_)
print('降維后最大方差的成分為:',pca.components_)
print('降維后主成分的個數為:',pca.n_components_)
print('original shape:',digits.data.shape)
print('transformed shape:',projected.shape)
s = pca.explained_variance_
c_s = pd.DataFrame({'b': s,'b_sum': s.cumsum() / s.sum()})
c_s['b_sum'].plot(style= '--ko',figsize= (10, 4))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默認字體
plt.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
plt.axhline(0.85, color= 'r',linestyle= '--')
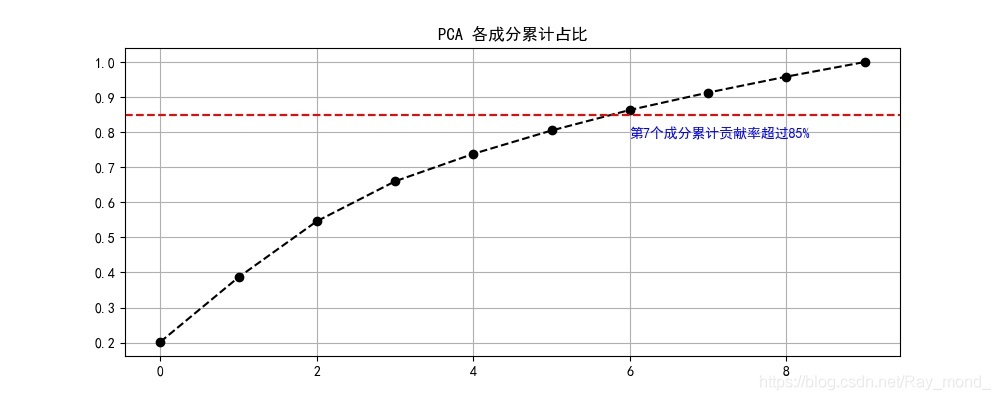
plt.text(6, c_s['b_sum'].iloc[6]-0.08, '第7個成分累計貢獻率超過85%', color='b')
plt.title('PCA 各成分累計占比')
plt.grid()
plt.savefig('./PCA.jpg')
plt.show()
結果展示:
若有理解偏差的地方,請您諒解,也歡迎各位討論,您的支持,就是我前進的動力,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/294222.html
標籤:python