前言
Stream是一個來自資料源的元素佇列并支持聚合操作,其中具有以下特性:
- Stream只負責計算,不存盤任何元素,元素是特定型別的物件,形成一個佇列
- 資料源可以實集合、陣列、I/O channel、generator等
- 聚合操作有類似SQL的:filter、map、match、sorted等操作
- Stream流的執行類似于懶加載,用戶使用時才執行相應操作
- 可消費性;Stream只能被消費一次,被消費后需要重新生成
本文總結了部分在日常開發中經常接觸到的一些Stream流相關的方法,不足之處或有錯誤歡迎留評,總結的幾個方法如下:
- void forEach() : 迭代流中的資料
- Stream map() : 用于映射每個元素到對應的結果
- Stream filter() : 條件過濾器
- Stream sorted() : 排序
- R collect() : 流資料 -> 集合/陣列
- 待補充…
forEach()
forEach()原始碼:
void forEach(Consumer<!--? super T--> action);
Stream().forEach() : 迭代流中的資料
forEach() 的回傳型別為void,不會產生新的流
舉個栗子:
public void testForEach() {
/**
* 使用forEach()內部迭代
* ints()表示整數型別
* limit()表示限制流個數(次數)
*/
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);
}
運行結果:
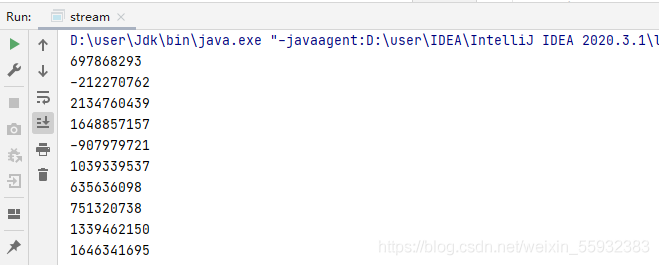
再舉個靈活一點的栗子:
public void testForEach() {
/**
* 使用forEach()轉換集合型別,如List->Map
*/
AtomicInteger i = new AtomicInteger();//原子型別
Map<Integer,String> map = new HashMap<>();
List<String> list = new ArrayList<>(Arrays.asList("Hello",",","world"));
list.stream().forEach(s->{
map.put(i.getAndIncrement(),s);
});
}
對于forEach()方法在本人日常開發中常用于:
- 使用內回圈對集合進行遍歷
- 使用foreach方法將List轉為Map形式
map()
map()原始碼:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
Stream().map() 用于映射每個元素到對應的結果
回傳型別為Stream,map()會產生新的流并回傳
舉個栗子:
public void testMap(){
/**
* map()獲取list每個元素的平方值
* distinct()去重操作
* collect()將map()產生的新的流轉為List型別
*/
List<Integer> list = Arrays.asList(1,2,3);
list.stream().map(num -> num * num)
.distinct()
.collect(Collectors.toList())
.forEach(System.out::println);
}
filter()
filter()原始碼:
Stream<T> filter(Predicate<? super T> predicate);
Stream().filter()為條件過濾器
舉個栗子:
public void testFilter(){
/**
* filter()過濾空字串
* count()統計符合條件的個數,回傳型別long
*/
List<String> list = new ArrayList<>(Arrays.asList("ab","","abc","","acd"));
long count = list.stream()
.filter(str -> str.isEmpty())
.count();
}
sorted()
sorted()原始碼:
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
Stream支持兩種方式的排序:
- 無參方法默認為自然排序
- sorted(Comparator comp) 按自定義比較器進行排序
仍然是舉個栗子:
1)無參方法
public void testSorted(){
/**
* sort()無參默認為自然排序
* 回傳型別Stream 會產生新的流
*/
List<String> list = new ArrayList<>(Arrays.asList("aaa","ccc","bbb"));
list.stream().sorted().forEach(System.out::println);
}
執行結果:
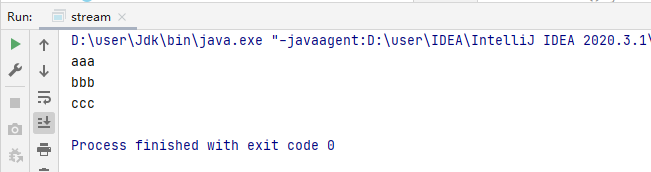
2)帶參方法(User類由name和age組成)
- 先比較年齡,按從小到大排序
- 若年齡相等,則按性名自然排序
public void testSorted(){
/**
* sort(Comparator comp)按自定義比較器進行排序
* 回傳型別同樣是Stream 會產生新的流
*/
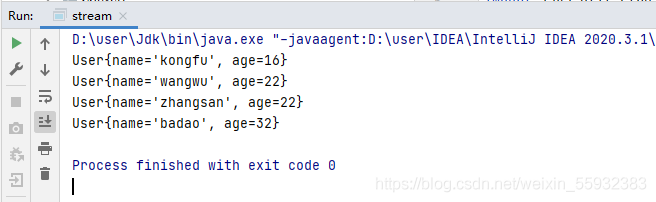
List<User> userList = new ArrayList<>(Arrays.asList(
new User("zhangsan",22),
new User("wangwu",22),
new User("badao",32),
new User("kongfu",16)
));
Stream<User> sorted = userList.stream().sorted((x, y) -> {
if (x.getAge() == y.getAge()) { // 使用流中的序列兩兩進行比較
return x.getName().compareTo(y.getName());
} else {
return x.getAge() - y.getAge();//順序
// y.getAge() - x.getAge() 為逆序
}
});
sorted.forEach(System.out::println);
}
執行結果:
collect()
collect()原始碼:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
stream().collect() 由三個引數構成 :
- Supplier 生產者,回傳最終結果
- BiConsumer<R, ? super T> accumulator,累加器 :
其中 R 為要回傳的集合, ? super T 為遍歷程序中的每個引數,相當于add操作
- BiConsumer<R,R> combiner,合并器 :
有并行流時才會使用,相當于將第二部操作形成的list添加到最終的list,addAll操作
舉個栗子:
1)new()
public void testCollect(){
Stream<String> stream = Stream.of("hello","world","hello,world");
// new()
List<String> list = stream.collect(Collectors.toList());//List
// 指定集合型別,如ArrayList
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
//Set
stream.collect(Collectors.toSet());
// 指定HashSet
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
// 拼接字串
String str = stream.collect(Collectors.joining());
2)new() -> add() -> addAll()
public void testCollect(){
/**
* 引數傳遞行為相當于: new() -> add() -> addAll()
*/
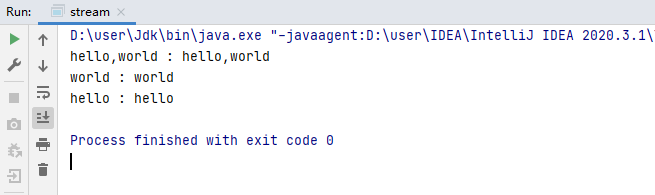
Stream<String> stream = Stream.of("hello","world","hello,world");
// new() -> add() -> addAll()完整演示
HashMap<String,String> map = stream.collect(HashMap::new,(x,y)->{
x.put(y,y); // x 為集合,y 為當前遍歷元素,以當前遍歷元素作為kv
},HashMap::putAll);
map.forEach((x,y)->{
System.out.println(x+" : "+y);
});
執行結果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/294704.html
標籤:java