最近冒出做人臉識別的想法,在github上正巧看到這個專案,在了解了大概思路之后打算自己獨立復刻出這個人臉識別專案,由于筆者自身代碼水平并不高,若有地方錯誤或者不合適的,還希望大神能夠指出,感謝交流!寫完這篇文章后感覺又識訓不少東西,
專案特點
- 可自行建立人臉特征庫
- 可實時對單張或多張人臉進行識別
dlib庫簡介
Dlib 是一個現代C++工具包,包含機器學習演算法和工具,用于在C++中創建復雜的軟體,以解決現實世界中的問題,按照dlib官網的敘述,其特點主要有:
- 豐富的幫助檔案:dlib官網為每個類與功能都提供了完整的幫助檔案,且官網提供有非常多的例程,作者在官網有說如果有東西檔案沒記錄或者不清楚的可以聯系他更改,
- 高質量的可移植代碼:dlib庫不需要第三方庫且符合ISO C++標準,支持Windows, Linux, Mac OS X系統,
- 豐富的機器學習演算法:dlib庫中包括深度學習演算法、SVM以及一些常用的聚類演算法等,
- 影像處理:支持讀寫windows BMP檔案、可實作各種色彩空間的影像變換、包括物體檢測的一些工具以及高質量的人臉識別功能,
- 執行緒:提供了簡單可移植的執行緒API,
環境建立
筆者實驗時的主要環境如下:
python = 3.6.4
dlib = 19.8.1
opencv = 3.4.1.15
tqdm = 4.62.1
- 首先是建立環境,打開Anaconda Prompt,輸入如下命令新建名為dlibTest(可更改,后續激活注意對應)、python版本為3.6.4的環境,這個環境專門用來存放該實驗所用到的庫,建立完成后輸入第二行命令激活環境,
conda create -n dlibTest python=3.6.4conda activate dlibTest - 繼續輸入如下命令安裝與實驗對應版本的庫,安裝opencv時會自動幫我們安裝numpy庫,
pip install dlib==19.8.1pip install opencv-python==3.4.1.15pip install tqdm
使用dlib庫進行人臉識別
一、采集人臉資料
先在代碼中定義dlib用于人臉識別的檢測器和特征提取器
detector = dlib.get_frontal_face_detector() # 人臉檢測器
# detector = dlib.cnn_face_detection_model_v1(model_path)
predictor = dlib.shape_predictor(shape_predictor_path) # 人臉68點提取器
# shape_predictor_path = 'data_dlib/shape_predictor_68_face_landmarks.dat'
recognition_model = dlib.face_recognition_model_v1(recognition_model_path) # 基于resnet的128維特征向量提取器
# recognition_model_path = 'data_dlib/dlib_face_recognition_resnet_model_v1.dat'其中,人臉檢測器detector也可用cnn進行檢測,
人臉資料可以用網上的照片,也可以自己通過攝像頭采集,
通過攝像頭獲取影像進行人臉識別的代碼如下,運行程序中可收集人臉資料,檢測到人臉后按下“n”可新建人臉檔案夾,之后再按下“s”可對人臉影像進行保存,因為一次采集的資料均放在一個檔案夾下,故一次采集應只對一人進行,
import cv2 as cv
import time
import os
import config
class face_detect():
def __init__(self):
self.start_time = 0 # 用于計算幀率
self.fps = 0 # 幀率
self.image = None
self.face_img = None
self.face_num = 0 # 這一幀的人臉個數
self.last_face_num = 0 # 上一幀的人臉個數
self.face_num_change_flag = False # 當前幀人臉數量變化的標志位,用于后續人臉識別提高幀率
self.quit_flag = False # 退出程式標志位
self.buildNewFolder = False # 按下"n"新建檔案夾標志位
self.save_flag = False # 按下“s”保存人臉資料標志位
self.face_flag = False # 人臉檢測標志位
self.img_num = 0 # 人臉資料檔案夾內的影像個數
self.collect_face_data = True # 是否進行人臉資料的采集,只有為真時才會進行采集
def get_fps(self):
now = time.time()
time_period = now - self.start_time
self.fps = 1.0 / time_period
self.start_time = now
color = (0,255,0)
if self.fps < 15:
color = (0,0,255)
cv.putText(self.image, str(self.fps.__round__(2)), (20, 50), cv.FONT_HERSHEY_DUPLEX, 1, color)
def key_scan(self, key):
if self.collect_face_data == True:
if self.save_flag == True and self.buildNewFolder == True:
if self.face_img.size > 0:
cv.imwrite(
config.faceData_path + 'person_{}/{}.png'.format(config.num_of_person_in_lib - 1, self.img_num),
self.face_img)
self.img_num += 1
if key == ord('s'):
self.save_flag = not self.save_flag
if key == ord('n'):
os.makedirs(config.faceData_path + 'person_{}'.format(config.num_of_person_in_lib))
config.num_of_person_in_lib += 1
print("新檔案夾建立成功!!")
self.buildNewFolder = True
if key == ord('q'): self.quit_flag = True
def face_detecting(self):
face_location = []
all_face_location = []
faces = config.detector(self.image, 0)
self.face_num = len(faces)
if self.face_num != self.last_face_num:
self.face_num_change_flag = True
print("臉數改變,由{}張變為{}張".format(self.last_face_num, self.face_num))
self.check_times = 0
self.last_face_num = self.face_num
else:
self.face_num_change_flag = False
if len(faces) != 0:
self.face_flag = True
for i, face in enumerate(faces):
face_location.append(face)
w, h = (face.right() - face.left()), (face.bottom() - face.top())
left, right, top, bottom = face.left() - w//4, face.right() + w//4, face.top() - h//2, face.bottom() + h//4
all_face_location.append([left, right, top, bottom])
return face_location, all_face_location
else:
self.face_flag = False
return None
def show(self, camera):
while camera.isOpened() and not self.quit_flag:
val, self.image = camera.read()
if val == False: continue
key = cv.waitKey(1)
res = self.face_detecting()
if res is not None:
_, all_face_location = res
for i in range(self.face_num):
[left, right, top, bottom] = all_face_location[i]
self.face_img = self.image[top:bottom, left:right]
cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))
if self.collect_face_data == True:
cv.putText(self.image, "Face", (int((left + right) / 2) - 50, bottom + 20), cv.FONT_HERSHEY_COMPLEX, 1,
(255, 255, 255))
self.key_scan(key)
self.get_fps()
cv.namedWindow('camera', 0)
cv.imshow('camera', self.image)
camera.release()
cv.destroyAllWindows()
def main():
try:
cam = cv.VideoCapture(0)
face_detect().show(cam)
finally:
cam.release()
cv.destroyAllWindows()
print("程式退出!!")
if __name__ == '__main__':
main()具體檢測效果如下圖所示,馬賽克為后期增加

采集的人臉資料在工程檔案夾faceData下,這里三個檔案夾分別存放劉德華、王冰冰、西野七瀨的圖片:

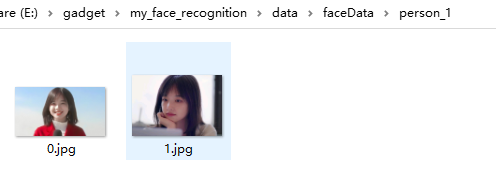

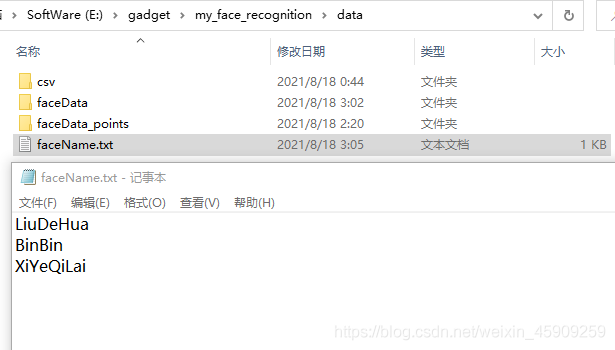
下一步再對記錄人臉名字的txt檔案進行修改,注意順序與faceData記憶體放人臉影像的檔案夾順序對應,
二、獲取128維特征向量
首先是對前一步采集到的人臉影像進行人臉檢測(避免有時候cv展示的影像上檢測到人臉,但保存下來的影像卻檢測不到而報錯),再對檢測到人臉的影像進行68個人臉關鍵點的提取,提取效果如下圖所示:

之后再將這68個點的值輸入到resnet模型中抽象出128維的人臉特征向量,進而保存在csv檔案夾中從而建立了一個人臉資料庫,
獲取特征向量的函式如下:
def get_128_features(person): # person代表第幾個人臉資料檔案夾
num = 0
features = []
imgs_folder = config.imgs_folder_path[person]
points_faceImage_path = config.points_faceData_path + imgs_folder
imgs_path = config.faceData_path + imgs_folder + '/'
list_imgs = os.listdir(imgs_path)
imgs_num = len(list_imgs)
if os.path.exists(config.points_faceData_path + imgs_folder):
shutil.rmtree(points_faceImage_path)
os.makedirs(points_faceImage_path)
print("人臉點圖檔案夾建立成功!!")
with tqdm(total=imgs_num) as pbar:
pbar.set_description(str(imgs_folder))
for j in range(imgs_num):
image = cv.imread(os.path.join(imgs_path, list_imgs[j]))
faces = config.detector(image, 1) # 經查閱資料,這里的1代表采樣次數
if len(faces) != 0:
for z, face in enumerate(faces):
shape = config.predictor(image, face) # 獲取68點的坐標
w, h = (face.right() - face.left()), (face.bottom() - face.top())
left, right, top, bottom = face.left() - w // 4, face.right() + w // 4, face.top() - h // 2, face.bottom() + h // 4
im = image
cv.rectangle(im, (left, top), (right, bottom), (0, 0, 255))
cv.imwrite(points_faceImage_path + '/{}.png'.format(j), im)
if config.get_points_faceData_flag == True:
for p in range(0, 68):
cv.circle(image, (shape.part(p).x, shape.part(p).y), 2, (0,0,255))
cv.imwrite(points_faceImage_path + '/{}.png'.format(j), image)
the_features = list(config.recognition_model.compute_face_descriptor(image, shape)) # 獲取128維特征向量
features.append(the_features)
#print("第{}張圖片,第{}張臉,特征向量為:{}".format(j+1, z+1, the_features))
num += 1
pbar.update(1)
np_f = np.array(features)
#res = np.mean(np_f, axis=0)
res = np.median(np_f, axis=0)
return res三、人臉識別
建立好人臉資料庫后就可開始進行人臉識別了,其程序也是和之前類似,先獲取影像、對影像進行人臉檢測、檢測到人臉后進行特征抽象、將庫內的特征向量逐個與當前的特征向量進行歐氏距離的計算、根據閾值判斷是否屬于庫內人臉,
其中,n維空間計算歐氏距離的公式如下:
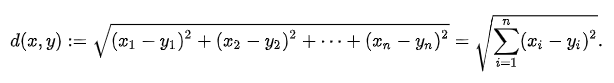
運用numpy庫計算向量間歐式距離的代碼如下:
def calculate_EuclideanDistance(self, feature1, feature2): # 計算歐氏距離
np_feature1 = np.array(feature1)
np_feature2 = np.array(feature2)
EuclideanDistance = np.sqrt(np.sum(np.square(np_feature1 - np_feature2)))
return EuclideanDistance人臉識別代碼中進行了5次的人臉識別,之后取每個特征分量的中值得到最終預測的特征向量,盡量減少干擾,self.init_process()是進行加載庫以及名字的操作:
def recognition_from_cam(self):
self.init_process()
while self.camera.isOpened() and not self.quit_flag:
val, self.image = self.camera.read()
if val == False: continue
#self.image = cv.imread('./data/test/test_bb.jpg')
key = cv.waitKey(1)
res = self.face_detecting() # 0.038s
if res is not None:
face, self.all_face_location = res
for i in range(self.face_num):
[left, right, top, bottom] = self.all_face_location[i]
self.middle_point = [(left + right) /2, (top + bottom) / 2]
self.face_img = self.image[top:bottom, left:right]
cv.rectangle(self.image, (left, top), (right, bottom), (0, 0, 255))
shape = config.predictor(self.image, face[i]) # 0.002s
if self.face_num_change_flag == True or self.check_times <= 5:
if self.face_num_change_flag == True: # 人臉數量有變化,重新進行五次檢測
self.check_times = 0
self.last_now_middlePoint_eDistance = [99999 for _ in range(self.available_max_face_num)]
for z in range(self.available_max_face_num): self.check_features_from_cam[z] = []
if self.check_times < 5:
the_features_from_cam = list(config.recognition_model.compute_face_descriptor(self.image, shape)) # 耗時主要在這步 0.32s
if self.check_times == 0: # 初始幀
self.check_features_from_cam[i].append(the_features_from_cam)
self.last_frame_middle_point[i] = self.middle_point
else:
this_face_index = self.track_link() # 后續幀需要與初始幀的人臉序號對應
self.check_features_from_cam[this_face_index].append(the_features_from_cam)
elif self.check_times == 5:
features_after_filter = self.middle_filter(self.check_features_from_cam[i])
self.check_features_from_cam[i] = []
for person in range(config.num_of_person_in_lib):
e_distance = self.calculate_EuclideanDistance(self.all_features[person],
features_after_filter) # 幾乎不耗時
self.all_e_distance[i].append(e_distance)
if min(self.all_e_distance[i]) < config.recognition_threshold:
self.person_name[i] = self.all_name[self.all_e_distance[i].index(min(self.all_e_distance[i]))]
cv.putText(self.image, self.person_name[i],
(int((left + right) / 2) - 50, bottom + 20),
cv.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255))
else:
self.person_name[i] = "Unknown"
print("預測結果為:{}, 與庫中各人臉的歐氏距離為:{}".format(self.person_name[i], self.all_e_distance[i]))
else:
this_face_index = self.track_link()
#print(this_face_index, self.person_name)
cv.putText(self.image, self.person_name[this_face_index], (int((left + right) / 2) - 50, bottom + 20),
cv.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255))
self.check_times += 1
for j in range(self.available_max_face_num):
self.all_e_distance[j] = []
self.key_scan(key)
self.get_fps()
cv.namedWindow('camera', 0)
cv.imshow('camera', self.image)
self.camera.release()
cv.destroyAllWindows()具體識別效果如下圖所示
單張人臉

多張人臉

由于庫中沒有薛之謙的人臉資料,故識別出來為Unknown,
實體給的是直接讀取圖片,觀賞效果會比較好,也可以攝像頭讀取影像進行識別,但若每次都進行特征向量提取,則會浪費大量時間從而導致幀率過低,原專案作者是根據前后幀的人臉數量是否發生變化來判斷是否進行特征提取的,若人臉數量發生變化,則對每張人臉進行特征提取;否則就只進行人臉檢測+人臉跟蹤,這樣就省掉了后續幀不必要的特征提取,提高了幀率,
實際效果如下圖所示(13幀左右)
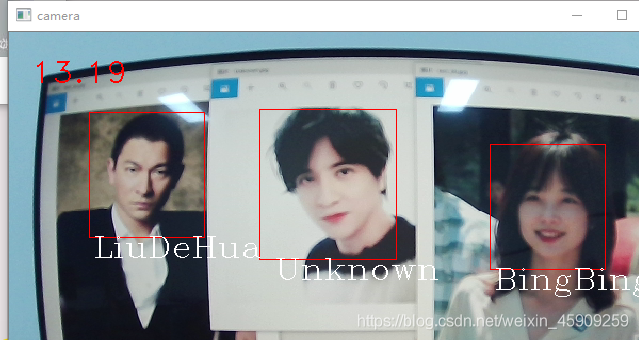
一般情況下的幀率(15幀左右)

我的代碼放在consolas-K/dlib_faceRecognition: 使用dlib進行人臉識別 (github.com),原專案作者的代碼在參考資料中,
參考資料
- coneypo/Dlib_face_recognition_from_camera: Detect and recognize the faces from camera / 呼叫攝像頭進行人臉識別,支持多張人臉同時識別 (github.com)
- 歐幾里得度量_百度百科 (baidu.com)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/294955.html
標籤:python