文章目錄
- 🍑源生動力😍
- 🍉網頁獲取
- 🍇完整代碼
- 🍋運行結果:美女姐姐,拿來把你🤣
- 🍊圖片無損放大
- 🍍參考文章
🍑源生動力😍
對于文章,標題是其濃縮的精華;那么對于視頻,其封面就可能是最亮眼的那一幀,B站,作為最近比較火熱的短視頻平臺,其舞蹈區各種各樣的舞蹈,尤其是宅舞,深受“宅男”的喜愛,(別和我說什么黑絲、jk,我真的不喜歡😆 )

于是乎,我就嘗試使用爬蟲獲取B站的封面,
🍉網頁獲取
B站是有防爬措施的,我一開始根據網頁進行分析,無果,
轉念一想,這么火熱的B站,想爬取的人肯定不止我一個,于是乎,我就開始搜索相關的文章和視頻,
啪的一下,很快啊,我就找到一篇,根據B站AV號爬取封面圖片的文章,我試了一下,咦,還真能用🤩(心中狂喜)
# 根據aid,獲取封面
https://api.bilibili.com/x/web-interface/view?aid=(aid)
可轉念一想,從去年開始,B站就開始用BV號了,哪來的AV號給我呀,文章里的AV號是哪來的呀?害,我轉念又看了文章的日期,2019年,哦,那沒事了,人家寫那會,B站還沒改呢😂
方法總比困難多,現在起碼知道了怎么利用AV號,那我利用BV號找到AV號不就可以了嗎?我真是個大聰明,
找尋一番,有個大佬分享了BV號的api,點擊傳送至大佬頁面
我一看,哦,還是B站的大佬,你這不講武德,居然教別人搞B站(不過我喜歡🤪 )
# 根據BV號獲取cid
https://api.bilibili.com/x/player/pagelist?bvid=(bvid,要帶上開頭的BV!)
# 根據BV號和cid獲取視頻播放串列
https://api.bilibili.com/x/player/playurl?cid=(cid)&qn=(qn)&bvid=(bvid,要帶上開頭的BV!)
# 根據BV號和cid獲取aid
https://api.bilibili.com/x/web-interface/view?cid=(cid)&bvid=(bvid,要帶上開頭的BV!)
總結上述內容的api,那么思路就有了,簡直是有手就行呀,跟著大佬混,就是行!😏
先根據BV號找到cid,再根據BV號和cid獲取aid,再根據aid獲取封面,
而且爬取程序中的資料基本上都是json資料,其中:
cid的資料在json的['data'][0]['cid']中
aid的資料在json的['data']['aid']中
封面圖片的資料在json的['data']['pic']中
更詳細的程序,我寫在了代碼的注釋中👇
🍇完整代碼
# -*- coding: UTF-8 -*-
# @Time: 2021/8/17 20:12
# @Author: 遠方的星
# @CSDN: https://blog.csdn.net/qq_44921056
import os
import json
import requests
import chardet
from fake_useragent import UserAgent
# 隨機產生請求頭
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 隨機切換請求頭
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip壓縮編碼 能提高傳輸檔案速率
"user-agent": ua.random
}
return headers
# 創建檔案夾
def path_creat():
_path = "D:/B站封面/"
if not os.path.exists(_path):
os.mkdir(_path)
return _path
# 對爬取的頁面內容進行json格式處理
def get_text(url):
res = requests.get(url=url, headers=random_ua())
res.encoding = chardet.detect(res.content)['encoding'] # 統一字符編碼
res = res.text
data = json.loads(res) # json格式化
return data
# 根據bv號獲取av號
def get_aid(bv):
url_1 = 'https://api.bilibili.com/x/player/pagelist?bvid={}'.format(bv)
response = get_text(url_1)
cid = response['data'][0]['cid'] # 獲取cid
url_2 = 'https://api.bilibili.com/x/web-interface/view?cid={}&bvid={}'.format(cid, bv)
response_2 = get_text(url_2)
aid = response_2['data']['aid'] # 獲取aid
return aid
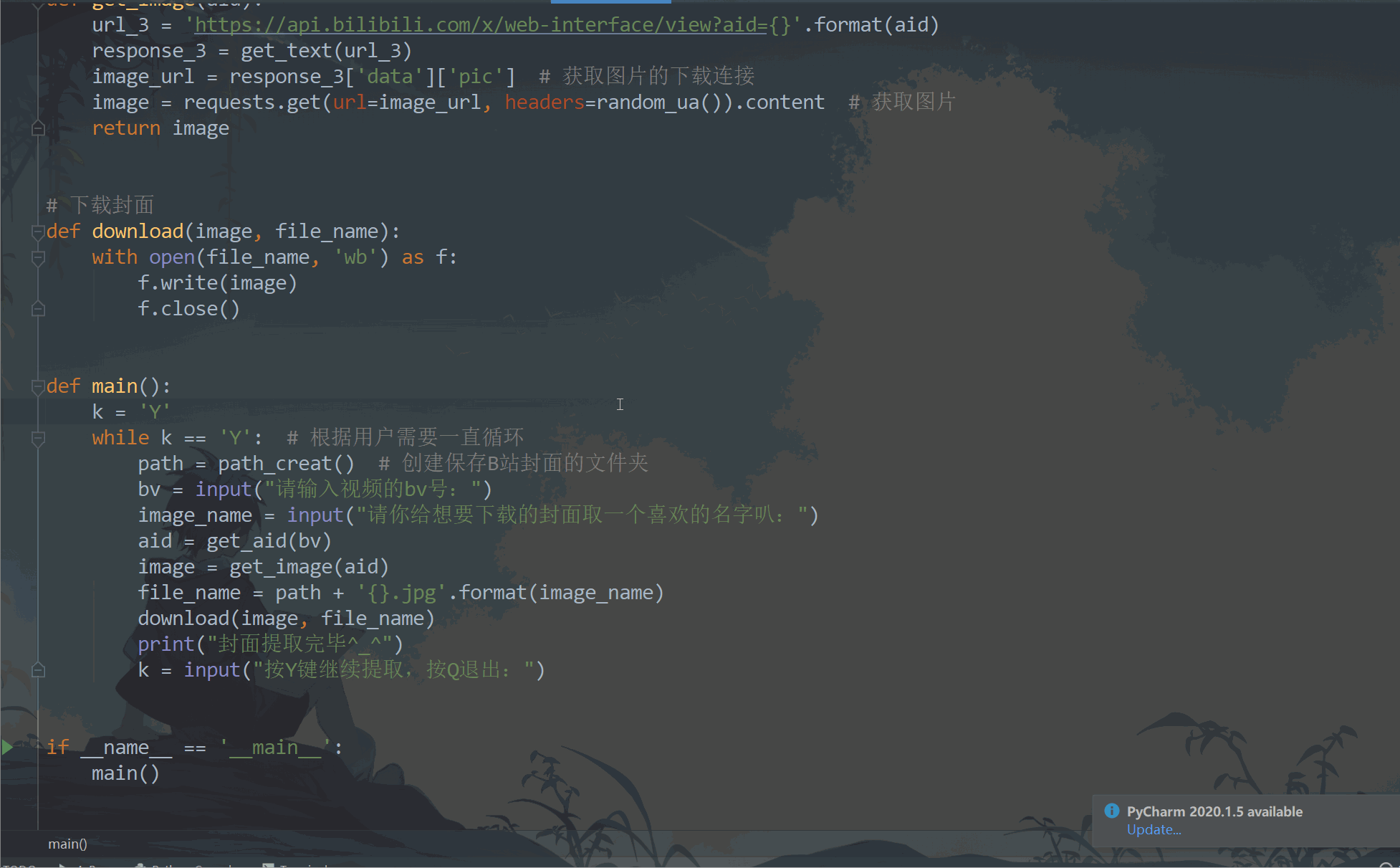
# 根據av號獲取封面圖片
def get_image(aid):
url_3 = 'https://api.bilibili.com/x/web-interface/view?aid={}'.format(aid)
response_3 = get_text(url_3)
image_url = response_3['data']['pic'] # 獲取圖片的下載連接
image = requests.get(url=image_url, headers=random_ua()).content # 獲取圖片
return image
# 下載封面
def download(image, file_name):
with open(file_name, 'wb') as f:
f.write(image)
f.close()
def main():
k = 'Y'
while k == 'Y': # 根據用戶需要一直回圈
path = path_creat() # 創建保存B站封面的檔案夾
bv = input("請輸入視頻的bv號:")
image_name = input("請你給想要下載的封面取一個喜歡的名字叭:")
aid = get_aid(bv)
image = get_image(aid)
file_name = path + '{}.jpg'.format(image_name)
download(image, file_name)
print("封面提取完畢^_^")
k = input("按Y鍵繼續提取,按Q退出:")
if __name__ == '__main__':
main()
代碼可直接復制運行,如果對你有幫助,記得點贊哦,也是對作者最大的鼓勵,不足之處可以在評論區多多指正、交流,
🍋運行結果:美女姐姐,拿來把你🤣
- 以BV號為
BV1C5411P7qM的視頻為例:

🍊圖片無損放大
在線網址:https://bigjpg.com/zh
這個是可以在線使用的,可以將你的圖片在線放大并且做降噪處理,有興趣的小伙伴可以自己嘗試一下,我感覺效果還可以,
🍍參考文章
參考文章1:python 爬取B站封面
參考文章2:bilibili新出的BV號api
作者:遠方的星
CSDN:https://blog.csdn.net/qq_44921056
本文僅用于交流學習,未經作者允許,禁止轉載,更勿做其他用途,違者必究,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/295189.html
標籤:python