該系列文章是講解Python OpenCV影像處理知識,前期主要講解影像入門、OpenCV基礎用法,中期講解影像處理的各種演算法,包括影像銳化算子、影像增強技術、影像分割等,后期結合深度學習研究影像識別、影像分類應用,希望文章對您有所幫助,如果有不足之處,還請海涵~
這篇文章是影像處理的最后一篇文章,后面我們將進入新的章節,影像處理文章主要講解的影像處理方法包括影像幾何運算、影像量化采樣、影像點運算、影像形態學處理、影像增強、影像平滑、影像銳化、影像特效、影像分割、傅里葉變換與霍夫變換、影像分類等,個人感覺如果你是編程初學者、Python初學者或影像處理愛好者,這個系列真心適合你學習,并且這篇文章算是Python影像處理的學習路線,希望您喜歡,
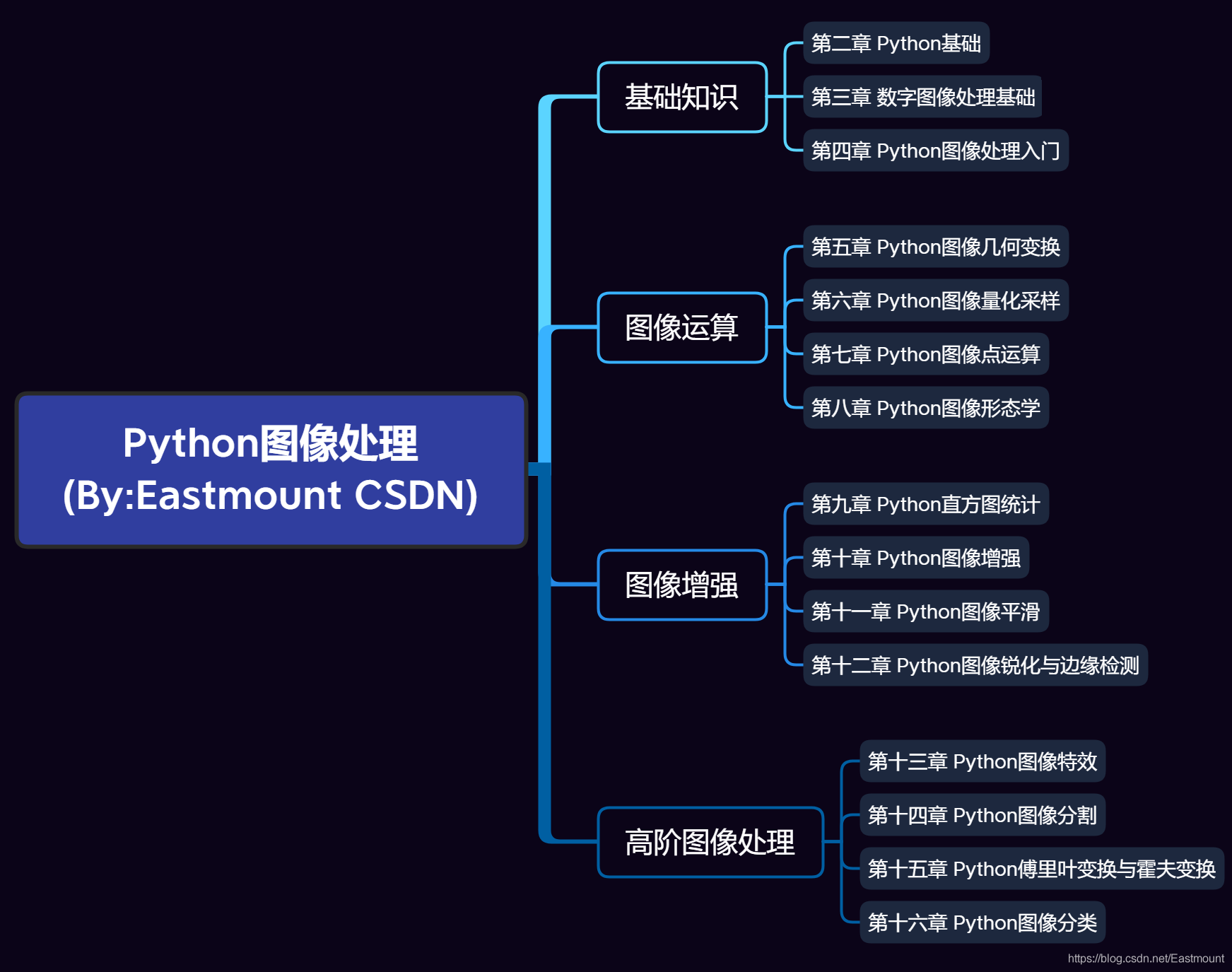
文章目錄
- 一.Python影像處理緒論
- 1.數字影像處理
- 2.Python
- 3.OpenCV
- 4.內容分布
- 二.基礎知識
- 1.Python基礎
- 2.數字影像處理基礎
- 3.Python影像處理入門
- 三.影像運算
- 1.Python影像幾何變換
- 2.Python影像量化采樣
- 3.Python影像點運算
- 4.Python影像形態學
- 四.影像增強
- 1.Python直方圖統計
- 2.Python影像增強
- 3.Python影像平滑
- 4.Python影像銳化
- 五.高階影像處理
- 1.Python影像特效
- 2.Python影像分割
- 3.Python傅里葉變換與霍夫變化
- 4.Python影像分類
- 六.總結
萬字長文整理,希望對您有所幫助,同時,該部分知識均為作者查閱資料撰寫總結,并且開設成了收費專欄,為小寶賺點奶粉錢,感謝您的抬愛,如果有問題隨時私聊我,只望您能從這個系列中學到知識,一起加油,代碼下載地址(如果喜歡記得star,一定喔):
- https://github.com/eastmountyxz/ImageProcessing-Python
一.Python影像處理緒論
影像處理是通過計算機對影像進行分析以達到所需結果的技術,常見的方法包括影像變換、影像運算、影像增強、影像分割、影像復原、影像分類等,廣泛應用于制造業、生物醫學、商品防偽、文物修復、影像校驗、模式識別、計算機視覺、人工智能、多媒體通信等領域,
隨著大資料和人工智能風暴的來臨,Python語言也變得越來越火熱,其清晰的語法、豐富和強大的功能,讓Python迅速運用于各個領域,該系列博客主要通過Python語言來實作各式各樣的影像處理演算法及案例,有效地輔助讀者學習影像處理知識,并運用于自己的科研、作業或學習中,
1.數字影像處理
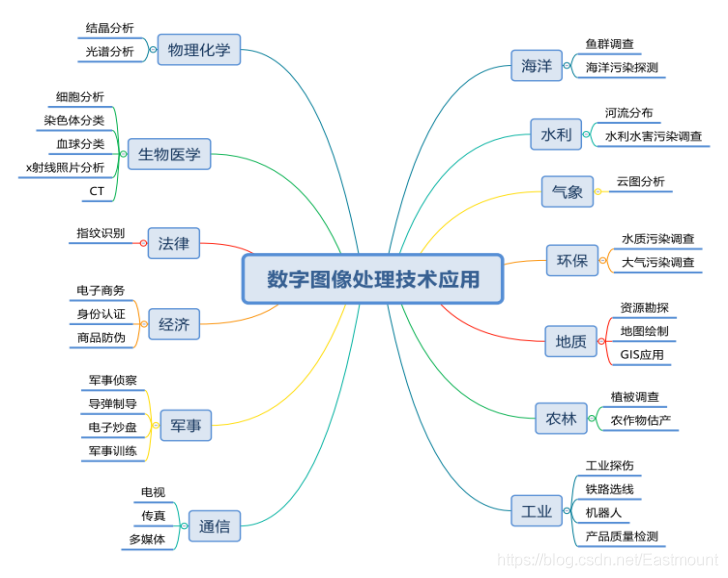
數字影像處理(Digital Image Processing)又稱為計算機影像處理(Computer Image Processing),旨在將影像信號轉換成數字信號并利用計算機對其進行處理的程序,其運用領域如圖所示,涉及通信、生物醫學、物理化學、經濟等,
數字影像處理最早出現于20世紀50年代,當時的電子計算機已經發展到一定水平,人們開始利用計算機來處理圖形和影像資訊,數字影像處理作為一門學科大約形成于20世紀60年代初期,早期的影像處理的目的是改善影像的質量,常用的處理方法包括影像增強、復原、編碼、壓縮等,1979年,無損傷診斷技識訓得了諾貝爾獎,說明它對人類作出了劃時代的貢獻,與此同時,影像處理技術在許多應用領域受到廣泛重視并取得重大開拓性成就,包括航空航天、生物醫學工程、工業檢測、機器人視覺、公安司法、軍事制導、文化藝術等領域,使影像處理成為一門引人注目、前景遠大的新型學科,

隨著影像處理技術的深入發展,從70年代中期開始,計算機技術和人工智能、思維科學研究迅速發展,數字影像處理向更高、更深層次發展,人們已開始研究如何用計算機系統解釋影像,實作類似人類視覺系統理解外部世界,這被稱為影像理解或計算機視覺,現如今,這項研究取得了不少重要的研究成果,數字影像處理在國民經濟的許多領域已經得到廣泛的應用,
2.Python
隨著大資料、深度學習、人工智能、影像識別的迅速發展,影像處理和計算機視覺也變得越來越熱門,由于Python具有語法清晰、代碼友好、易讀性好等特點,同時擁有強大的第三方庫支持,包括網路爬取、資訊傳輸、資料分析、影像處理、繪圖可視化等庫函式,該系列文章選擇了Python作為影像處理的編程語言,
Python是Guido van Rossum在1989年開發的一門語言,它既是解釋性編程語言,又是面向物件的語言,其操作性和可移植性高,被廣泛應用于資料挖掘、影像處理、人工智能領域,Python具有語言清晰、容易學習、高效率的資料結構、豐富且功能強大的第三方包等優勢,使其成為一種能在多種功能、多種平臺上撰寫腳本及快速開發的理想語言,

該系列文章主要通過Python呼叫OpenCV、Matplotlib、Numpy、Sklearn等第三方包實作影像處理,其優雅清晰的語法結構減少了讀者的負擔,從而大大增強程式的質量,
3.OpenCV
OpenCV(Open Source Computer Vision)直譯為“開源計算機視覺庫”,它是一個開放源代碼的影像及視頻分析庫,是進行影像處理的一款必備工具,自1999年問世以來,它已經被影像處理和計算機視覺領域的學者和開發人員視為首選工具,OpenCV可以運行在Linux、Windows、Android和Mac 作業系統上,它是一個由C/C++語言撰寫而成的輕量級并且高效的庫,同時提供了Python、Ruby、MATLAB等語言的介面,實作了影像處理和計算機視覺方面的很多通用演算法,其官方地址為:
- https://opencv.org/
下圖是OpenCV的Logo圖,其設計目標是執行速度更快,更加關注實時應用,采用優化的C/C++代碼撰寫而成,能夠充分利用多核處理器的優勢,構建一個簡單易用的計算機視覺框架,OpenCV被廣泛應用于產品檢測、醫學成像、立體視覺、影像識別、影像增強、影像恢復等領域,本書主要通過Python語言結合OpenCV庫實作影像處理相關的演算法及案例,并強化讀者的印象,

4.內容分布
本系列為滿足廣泛的讀者需求,結合Python語言實作各種影像處理,主要包括四部分內容,如圖所示,
-
第一部分 基礎知識
該部分主要講解基礎知識,包括第二章Python基礎、第三章數字影像處理基礎和第四章Python影像處理入門,第一部分重點介紹了Python基礎語法、資料型別、基本陳述句和操作、數字影像處理概念、OpenCV初識、Numpy和Matplotlib、幾何影像繪制、OpenCV讀取顯示影像、OpenCV讀取修改像素、影像算數與邏輯運算、影像融合、影像型別轉換等, -
第二部分 影像運算
該部分為核心知識,主要講述Python影像運算,包括第五章Python影像幾何變換、第六章Python影像量化采樣處理、第七章Python影像點運算處理、第八章Python影像形態學處理,影像幾何變換涉及影像平移變換、縮放變換、旋轉變換、鏡像變換、仿射變換、透視變換,影像量化及采樣處理涉及量化處理、K-Means聚類量化處理、采樣處理、區域馬賽克處理、影像向下取樣、影像向上取樣,影像點運算涉及影像灰度化處理(灰度線性變換、灰度非線性變換)、影像閾值化處理(固定閾值化處理、自適應閾值化處理),影像形態學處理涉及影像腐蝕、膨脹、開運算、閉運算、梯度運算、頂帽運算和底帽運算, -
第三部分 影像增強
影像增強是指按照某種特定的需求,突出影像中有用的資訊,去除或者削弱無用的資訊,該部分包括第九章Python直方圖統計、第十章Python影像增強、第十一章Python影像平滑、第十二章Python影像銳化,其中,影像直方圖涉及Matplotlib繪制直方圖、OpenCV繪制直方圖、掩膜直方圖、影像灰度變換直方圖對比、影像H-S直方圖、直方圖判斷黑夜白天等,影像增強涉及直方圖均衡化、區域直方圖均衡化、自動色彩均衡化,影像平滑涉及均值濾波、方框濾波、高斯濾波、中值濾波、雙邊濾波,影像銳化涉及Roberts算子、Prewitt算子、Sobel算子、Laplacian算子、Scharr算子、Canny算子、LOG算子, -
第四部分 高階影像處理
高階影像處理部分主要包括第十三章Python影像特效、第十四章Python影像分割、第十五章Python傅里葉變換與霍夫變換、第十六章Python影像分類,其中,影像特效涉及影像毛玻璃特效、浮雕特效、油漆特效、素描特效、懷舊特效、光照特效、流年特效、水波特效、卡通特效、濾鏡特效、直方圖均衡化特效、模糊特效,影像分割涉及基于閾值的影像分割、基于邊緣檢測的影像分割、基于紋理背景的影像分割、基于K-Means聚類的區域分割、基于均值漂移演算法的影像分割、基于分水嶺演算法的影像分割、影像漫水填充分割、文字區域定位及提取,傅里葉變換與霍夫變換涉及影像傅里葉變換操作、高通濾波和低通濾波、影像霍夫線變換操作、影像霍夫圓變換操作,影像分類涉及基于樸素貝葉斯演算法的影像分類、基于KNN演算法的影像分類、基于神經網路演算法的影像分類,
博客劃分:
-
基礎知識
[Python從零到壹] 一.為什么我們要學Python及基礎語法詳解
[Python從零到壹] 二.語法基礎之條件陳述句、回圈陳述句和函式
[Python從零到壹] 三.語法基礎之檔案操作、CSV檔案讀寫及面向物件
[Python影像處理] 一.影像處理基礎知識及OpenCV入門函式
[Python影像處理] 二.OpenCV+Numpy庫讀取與修改像素
[Python影像處理] 三.獲取影像屬性、興趣ROI區域及通道處理
[Python影像處理] 五.影像融合、加法運算及影像型別轉換
[Python影像處理] 三十四.數字影像處理基礎與幾何圖形繪制萬字詳解(推薦)
[Python影像處理] 三十五.OpenCV影像處理入門、算數邏輯運算與影像融合(推薦) -
影像運算
[Python影像處理] 六.影像縮放、影像旋轉、影像翻轉與影像平移
[Python影像處理] 七.影像閾值化處理及演算法對比
[Python影像處理] 八.影像腐蝕與影像膨脹
[Python影像處理] 九.形態學之影像開運算、閉運算、梯度運算
[Python影像處理] 十.形態學之影像頂帽運算和黑帽運算
[Python影像處理] 十二.影像幾何變換之影像仿射變換、影像透視變換和影像校正
[Python影像處理] 十三.基于灰度三維圖的影像頂帽運算和黑帽運算
[Python影像處理] 十四.基于OpenCV和像素處理的影像灰度化處理
[Python影像處理] 十五.影像的灰度線性變換
[Python影像處理] 十六.影像的灰度非線性變換之對數變換、伽馬變換
[Python影像處理] 二十.影像量化處理和采樣處理及區域馬賽克特效
[Python影像處理] 二十一.影像金字塔之影像向下取樣和向上取樣
[Python影像處理] 三十.影像量化及采樣處理萬字詳細總結(推薦)
[Python影像處理] 三十一.影像點運算處理兩萬字詳細總結(灰度化處理、閾值化處理)
[Python影像處理] 三十六.OpenCV影像幾何變換萬字詳解(平移縮放旋轉、鏡像仿射透視)
[Python影像處理] 四十三.Python影像形態學處理萬字詳解(腐蝕膨脹、開閉運算、梯度頂帽黑帽運算) -
影像增強
[Python影像處理] 四.影像平滑之均值濾波、方框濾波、高斯濾波及中值濾波
[Python影像處理] 十一.灰度直方圖概念及OpenCV繪制直方圖
[Python影像處理] 十七.影像銳化與邊緣檢測之Roberts算子、Prewitt算子、Sobel算子和Laplacian算子
[Python影像處理] 十八.影像銳化與邊緣檢測之Scharr算子、Canny算子和LOG算子
[Python影像處理] 三十七.OpenCV和Matplotlib繪制直方圖萬字詳解(掩膜直方圖、H-S直方圖、黑夜白天判斷)
[Python影像處理] 三十八.OpenCV影像增強萬字詳解(直方圖均衡化、區域直方圖均衡化、自動色彩均衡化)
[Python影像處理] 四十一.Python影像平滑萬字詳解(均值濾波、方框濾波、高斯濾波、中值濾波、雙邊濾波)
[Python影像處理] 四十二.Python影像銳化及邊緣檢測萬字詳解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG) -
高階影像處理
[Python影像處理] 十九.影像分割之基于K-Means聚類的區域分割
[Python影像處理] 二十二.Python影像傅里葉變換原理及實作
[Python影像處理] 二十三.傅里葉變換之高通濾波和低通濾波
[Python影像處理] 二十四.影像特效處理之毛玻璃、浮雕和油漆特效
[Python影像處理] 二十五.影像特效處理之素描、懷舊、光照、流年以及濾鏡特效
[Python影像處理] 二十六.影像分類原理及基于KNN、樸素貝葉斯演算法的影像分類案例
[Python影像處理] 三十二.傅里葉變換(影像去噪)與霍夫變換(特征識別)萬字詳細總結
[Python影像處理] 三十三.影像各種特效處理及原理萬字詳解(毛玻璃、浮雕、素描、懷舊、流年、濾鏡等)
[Python影像處理] 三十九.Python影像分類萬字詳解(貝葉斯影像分類、KNN影像分類、DNN影像分類)
[Python影像處理] 四十.全網首發Python影像分割萬字詳解(閾值分割、邊緣分割、紋理分割、分水嶺演算法、K-Means分割、漫水填充分割、區域定位) -
其他影像知識
[Python影像處理] 二十七.OpenGL入門及繪制基本圖形(一)
[Python影像處理] 二十八.OpenCV快速實作人臉檢測及視頻中的人臉
[Python影像處理] 二十九.MoviePy視頻編輯庫實作抖音短視頻剪切合并操作
[Python影像識別] 四十五.目標檢測入門普及和ImageAI“傻瓜式”物件檢測案例詳解 (1)
二.基礎知識
Python影像處理第一部分為“基礎知識”,主要包括Python基礎知識、數字影像處理、Python影像處理入門,
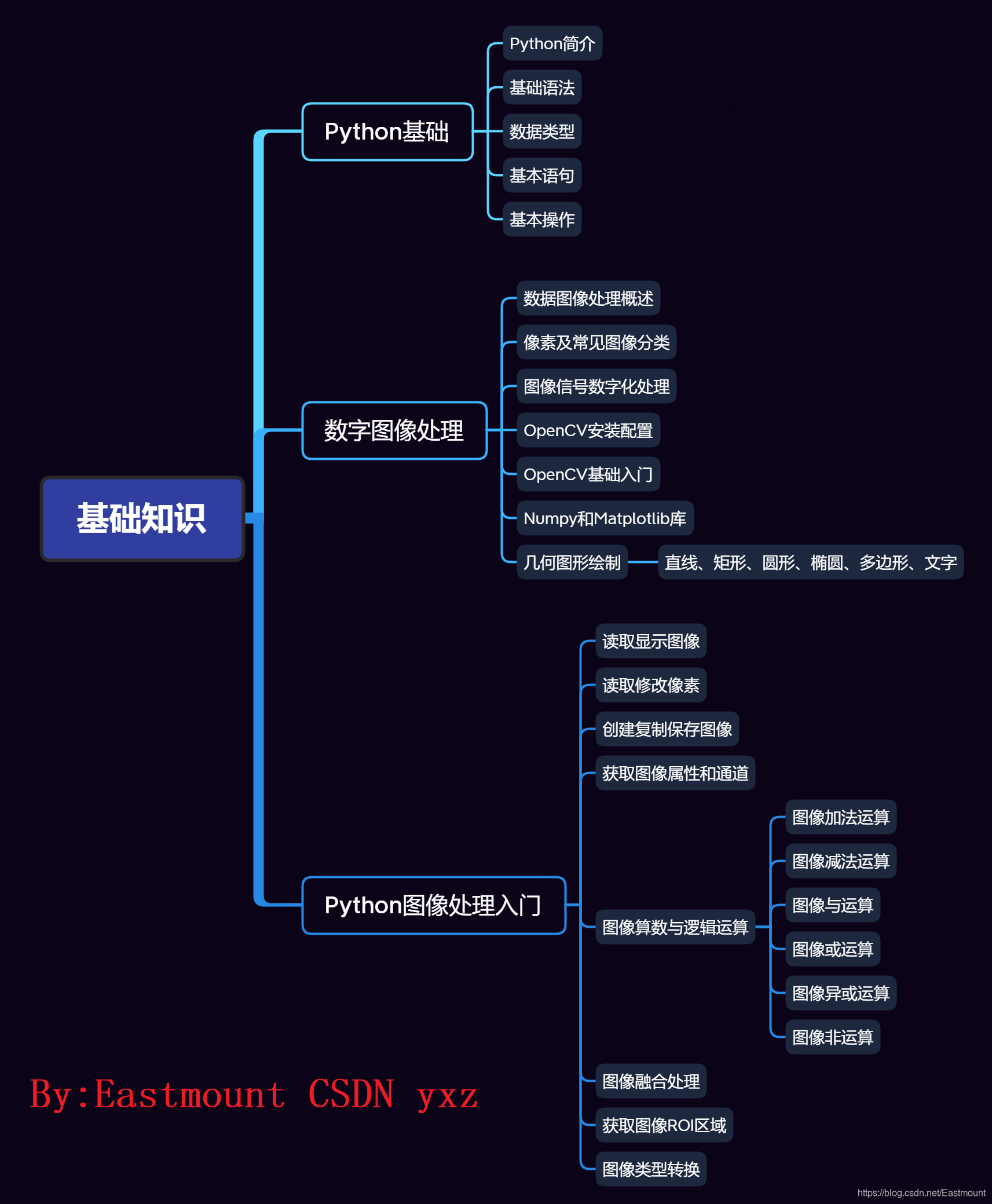
1.Python基礎
核心內容:
- Python簡介
- 基礎語法
– 輸出陳述句
– 注釋
– 變數及賦值
– 輸入陳述句 - 資料型別
– 數字型別
– 字串型別
– 串列型別
– 字典型別
– 元組型別 - 基本陳述句
– 條件陳述句
– 回圈陳述句 - 基本操作
– 自定義函式
– 第三方包
– 面向物件
2.數字影像處理基礎
推薦文章:
- [Python影像處理] 三十四.數字影像處理基礎與幾何圖形繪制萬字詳解(推薦)
核心內容:
- 數字影像處理概述
- 像素及常見影像分類
- 影像信號數字化處理
- OpenCV安裝配置
- OpenCV初識及常見資料型別
– OpenCV顯示影像:imshow(winname, mat)
– 常見資料型別 - Numpy和Matplotlib庫介紹
– Numpy庫
– Matplotlib庫 - 幾何圖形繪制
– 繪制直線
img = line(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
– 繪制矩形
img = rectangle(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
– 繪制圓形
img = circle(img, center, radius, color[, thickness[, lineType[, shift]]])
– 繪制橢圓
img = ellipse(img, center, axes, angle, startAngle, endAngle, color[, thickness[, lineType[, shift]]])
– 繪制多邊形
img = polylines(img, pts, isClosed, color[, thickness[, lineType[, shift]]])
– 繪制文字
img = putText(img, text, org, fontFace, fontScale, color[, thickness[, lineType[, bottomLeftOrigin]]])
經典知識:
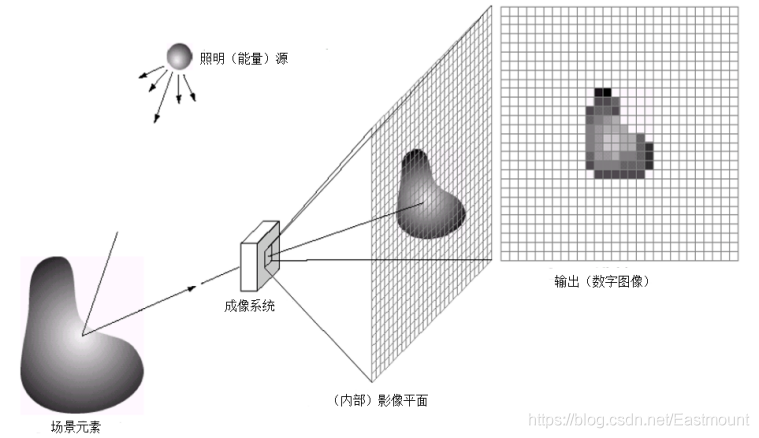
數字影像處理技術廣泛應用于各行各業,它主要是將現實物體離散化處理后轉換為信號數字影像,從而更好地進行后續的影像處理和影像識別等操作,下圖展示了影像信號數字化處理的程序,
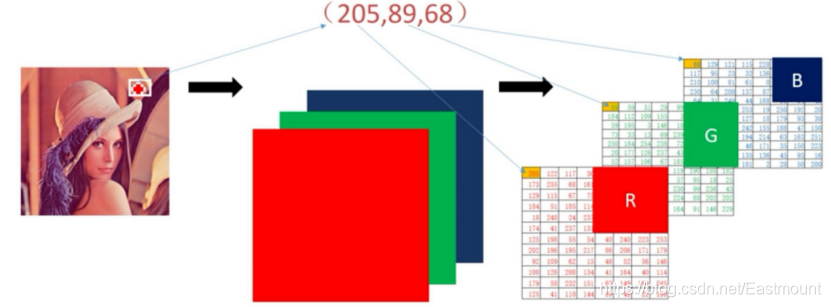
下圖展示了影像中某一點像素(205,89,68)所對應三原色像的素值,其中R表示紅色分量、G表示綠色分量、B表示藍色分量,
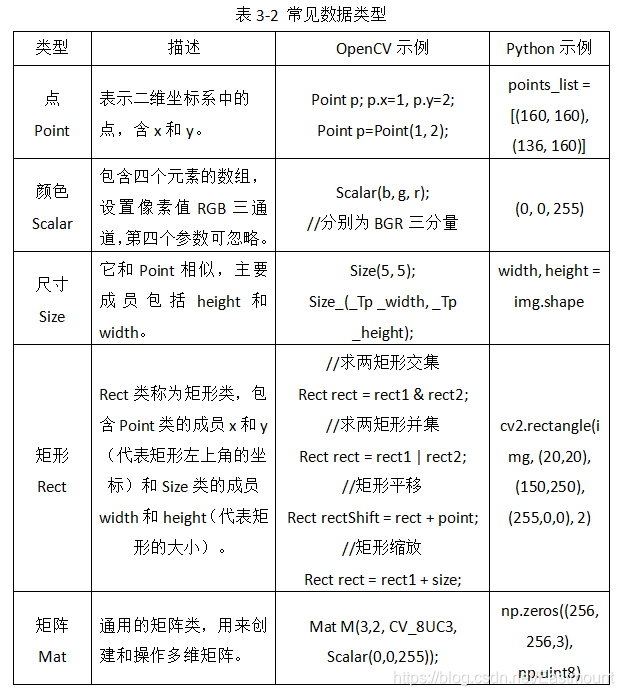
下面介紹OpenCV中常見的資料型別,包括點Point類、顏色Scalar類、尺寸Size類、矩形Rect類、矩陣Mat類,如下表所示,
經典示例:
(1) 顯示多張影像
在OpenCV中,主要呼叫Matplotlib繪制顯示多張圖形,從而方便實驗對比,如下代碼所示,它呼叫cv2.imread()函式分別讀取四張圖片,并轉換為RGB顏色空間,接著通過for回圈分別設定各子圖對應的影像、標題及坐標軸名稱,其中plt.subplot(2,2)表示生成2×2張子圖,
# -*- coding: utf-8 -*-
# By:Eastmount CSDN
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取影像
img1 = cv2.imread('lena.png')
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.imread('people.png')
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
img3 = cv2.imread('flower.png')
img3 = cv2.cvtColor(img3, cv2.COLOR_BGR2RGB)
img4 = cv2.imread('scenery.png')
img4 = cv2.cvtColor(img4, cv2.COLOR_BGR2RGB)
#顯示四張影像
titles = ['lena', 'people', 'flower', 'scenery']
images = [img1, img2, img3, img4]
for i in range(4):
plt.subplot(2, 2, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
顯示效果如下圖所示:

(2) 幾何圖形繪制
# -*- coding: utf-8 -*-
# By:Eastmount CSDN
import cv2
import numpy as np
#創建黑色影像
img = np.zeros((512,512,3), np.uint8)
#(1)繪制直線:影像、起點坐標、終點坐標、顏色、粗細
cv2.line(img, (0,0), (512,512), (55,255,155), 5)
#(2)繪制矩形:影像、左上角坐標、右下角坐標、顏色、粗細
cv2.rectangle(img, (20,300), (350,450), (255,0,0), 2)
#(3)繪制圓形:影像、圓心坐標、半徑、顏色、粗細\填充
cv2.circle(img, (400,400), 50, (255,255,0), -1)
#(4)繪制橢圓:影像、圓心坐標、長軸和短軸、偏轉角度20
# 圓弧起始角的角度、圓弧終結角的角度、顏色、線條粗細
cv2.ellipse(img, (320, 100), (100, 50), 20, 0, 360, (255, 0, 255), 2)
#(5)繪制多邊形:影像、多邊形曲線陣列、是否閉合、顏色、粗細
pts = np.array([[10,80], [120,80], [120,200], [30,250]])
cv2.polylines(img, [pts], True, (255, 255, 255), 5)
#(6)繪制多邊形
pts = np.array([[50, 190], [380, 420], [255, 50], [120, 420], [450, 190]])
cv2.polylines(img, [pts], True, (0, 255, 255), 1)
#(7)繪制文字
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'I love Python!!! By:Eatmount CSDN',
(10, 500), font, 0.6, (255, 255, 0), 2)
#顯示影像
cv2.imshow("img", img)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
運行結果如下圖所示:

3.Python影像處理入門
推薦文章:
- [Python影像處理] 三十五.OpenCV影像處理入門、算數邏輯運算與影像融合(推薦)
核心內容:
- OpenCV讀取顯示影像
–cv2.imshow("Demo", img) - OpenCV讀取修改像素
–blue=img[88,142,0] green=img[88,142,1] red=img[88,142,2]
–blue = img.item(78, 100, 0)
–img.itemset((88,99), 255) - OpenCV創建復制保存影像
–emptyImage2 = img.copy()
–retval = imwrite(filename, img[, params]) - 獲取影像屬性及通道
– 影像屬性:shape、size、dtype
– 影像通道處理:split、merge - 影像算數與邏輯運算
– 影像加法運算
dst = add(src1, src2[, dst[, mask[, dtype]]])
– 影像減法運算
dst = subtract(src1, src2[, dst[, mask[, dtype]]])
– 影像與運算
dst = bitwise_and(src1, src2[, dst[, mask]])
– 影像或運算
dst = bitwise_or(src1, src2[, dst[, mask]])
– 影像異或運算
dst = bitwise_xor(src1, src2[, dst[, mask]])
– 影像非運算
dst = bitwise_not(src1, src2[, dst[, mask]]) - 影像融合處理
- 獲取影像ROI區域
- 影像型別轉換
經典知識:
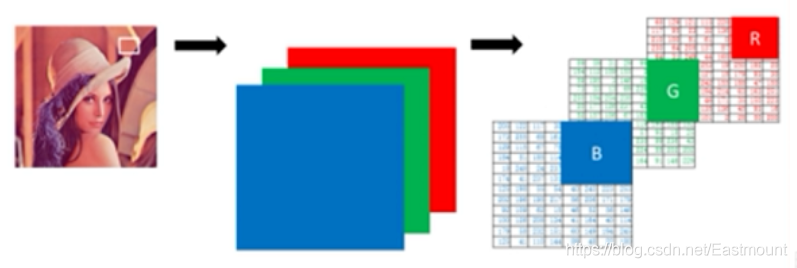
OpenCV讀取的彩色影像由藍色(B)、綠色(G)、紅色(R)三原色組成,每一種顏色可以認為是一個通道分量,如圖所示,
影像的演算法運算與邏輯運算,主要包括影像加法、影像減法、影像與運算、影像或運算、影像異或運算與影像非運算,
經典示例:
(1) 圖片拆分與合并
# -*- coding:utf-8 -*-
# By: Eastmount CSDN 2021-08-19
import cv2
import numpy as np
#讀取圖片
img = cv2.imread("Lena.png")
rows, cols, chn = img.shape
print(rows, cols, chn)
cv2.imshow("img", img)
#(1)拆分通道
b, g, r = cv2.split(img)
cv2.imshow("B", b)
cv2.imshow("G", g)
cv2.imshow("R", r)
#(2)合并通道
m = cv2.merge([b, g, r])
cv2.imshow("Merge", m)
#(3)顯示藍色通道
b_ = cv2.split(img)[0]
g_ = np.zeros((rows,cols), dtype=img.dtype) #設定g、r通道為0
r_ = np.zeros((rows,cols), dtype=img.dtype)
m = cv2.merge([b_, g_, r_])
cv2.imshow("MergeBlue", m)
cv2.imwrite("MergeBlue.png", m)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出結果如下圖所示:

(2) 影像算數與邏輯運算
# -*- coding:utf-8 -*-
# By: Eastmount CSDN 2021-08-19
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
src = cv2.imread("Lena.png")
#獲取影像寬和高
rows, cols = src.shape[:2]
#BGR轉換為RGB
img = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
#(1)OpenCV加法運算
m = np.ones(img.shape, dtype="uint8")*100 #影像各像素加100
result1 = cv2.add(img, m)
#(2)OpenCV減法運算
m = np.ones(img.shape, dtype="uint8")*50 #影像各像素減50
result2 = cv2.subtract(img, m)
#(3)畫圓形
circle = np.zeros((rows, cols, 3), dtype="uint8")
cv2.circle(circle, (int(rows/2.0), int(cols/2)), 100, (255,0,0), -1)
print(circle.shape,img.size, circle.size)
#(4)OpenCV影像與運算
result4 = cv2.bitwise_and(img, circle)
#(5)OpenCV影像或運算
result5 = cv2.bitwise_or(img, circle)
#(6)OpenCV影像異或運算
result6 = cv2.bitwise_xor(img, circle)
#(7)OpenCV影像非運算
result7 = cv2.bitwise_not(img)
#解決中文顯示問題
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默認字體
plt.rcParams['axes.unicode_minus'] = False #解決保存影像是負號
#顯示九張影像
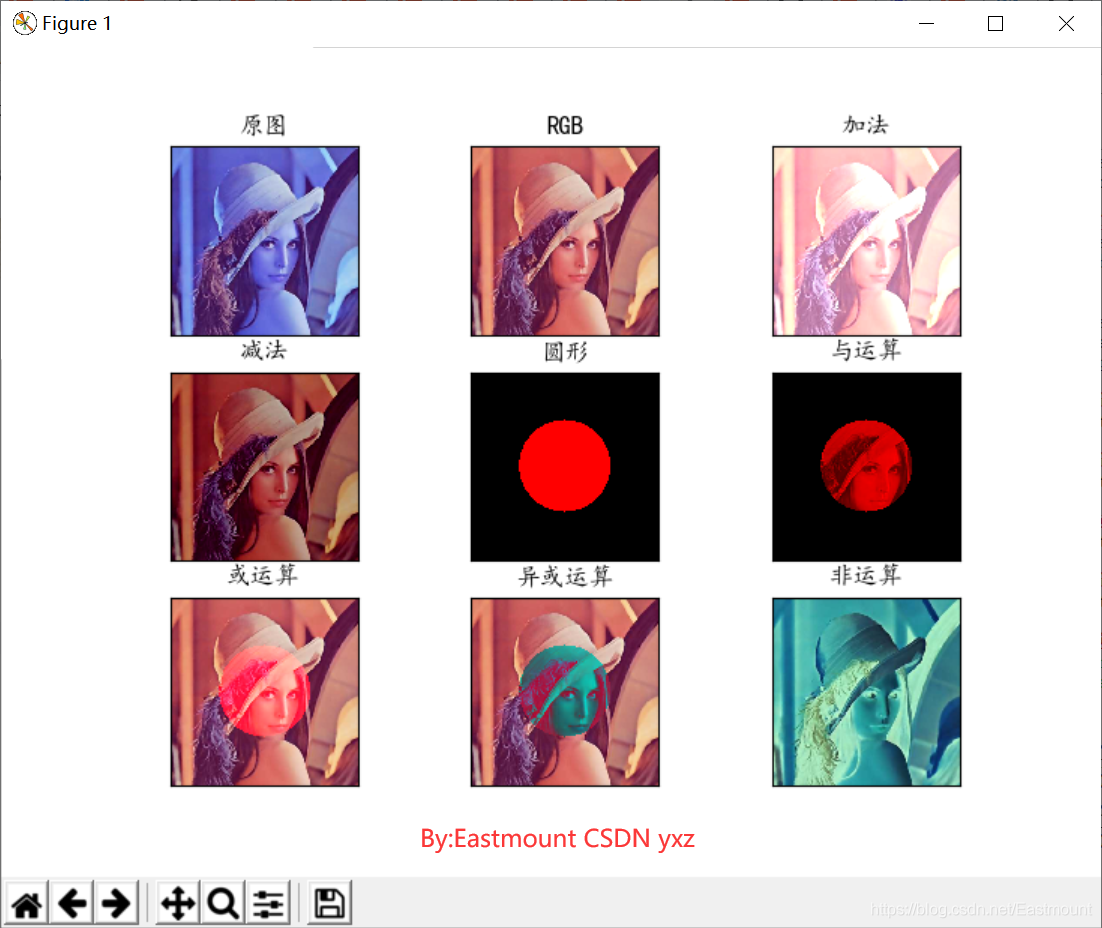
titles = ['原圖', 'RGB', '加法', '減法', '圓形', '與運算', '或運算', '異或運算', '非運算']
images = [src, img, result1, result2, circle, result4, result5, result6, result7]
for i in range(9):
plt.subplot(3, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:
(3) 影像融合處理與獲取影像ROI區域
#encoding:utf-8
# By: Eastmount CSDN 2021-08-19
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
src1 = cv2.imread('lena-hd.png')
src2 = cv2.imread('na.png')
src3 = cv2.imread("Lena.png")
print(src3.shape)
#影像融合
res1 = cv2.addWeighted(src1, 0.6, src2, 0.8, 10)
#顯示ROI區域
face = np.ones((100, 100, 3)) #定義150×150矩陣 3對應BGR
face = src3[200:300, 180:280]
#顯示ROI區域
res3 = src2.copy()
res3[150:250, 150:250] = face
#顯示影像
cv2.imshow("src1", src1)
cv2.imshow("src2", src2)
cv2.imshow("src3", src3)
cv2.imshow("res1", res1)
cv2.imshow("res2", face)
cv2.imshow("res3", res3)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出結果如下圖所示:

(4) 影像型別轉換
# -*- coding: utf-8 -*-
# By: Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取原始影像
img_BGR = cv2.imread('na.png')
#BGR轉換為RGB
img_RGB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)
#灰度化處理
img_GRAY = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2GRAY)
#BGR轉HSV
img_HSV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HSV)
#BGR轉YCrCb
img_YCrCb = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YCrCb)
#BGR轉HLS
img_HLS = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HLS)
#BGR轉XYZ
img_XYZ = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2XYZ)
#BGR轉LAB
img_LAB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2LAB)
#BGR轉YUV
img_YUV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YUV)
#呼叫matplotlib顯示處理結果
titles = ['BGR', 'RGB', 'GRAY', 'HSV', 'YCrCb', 'HLS', 'XYZ', 'LAB', 'YUV']
images = [img_BGR, img_RGB, img_GRAY, img_HSV, img_YCrCb,
img_HLS, img_XYZ, img_LAB, img_YUV]
for i in range(9):
plt.subplot(3, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
顯示結果如下圖所示:

三.影像運算
Python影像處理第二部分為“影像運算”,主要包括Python影像幾何變換、Python影像量化采樣、Python影像點運算和Python影像形態學,
1.Python影像幾何變換
推薦文章:
- [Python影像處理] 三十六.OpenCV影像幾何變換萬字詳解(平移縮放旋轉、鏡像仿射透視)
核心內容:
- 影像幾何變換概述
- 影像平移變換
–M = np.float32([[1, 0, x], [0, 1, y]])
–shifted = cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) - 影像縮放變換
–result = cv2.resize(src, dsize[, result[. fx[, fy[, interpolation]]]]) - 影像旋轉變換
–M = cv2.getRotationMatrix2D(center, angle, scale)
–rotated = cv2.warpAffine(src, M, (cols, rows)) - 影像鏡像變換
–dst = cv2.flip(src, flipCode) - 影像仿射變換
–M = cv2.getAffineTransform(pos1,pos2)
–cv2.warpAffine(src, M, (cols, rows)) - 影像透視變換
–M = cv2.getPerspectiveTransform(pos1, pos2)
–cv2.warpPerspective(src,M,(cols,rows))
經典知識:
一個幾何變換需要兩部分運算:首先是空間變換所需的運算,如平移、縮放、旋轉和正平行投影等, 需要用它來表示輸出影像與輸入影像之間的像素映射關系;此外,還需要使用灰度插值演算法, 因為按照這種變換關系進行計算, 輸出影像的像素可能被映射到輸入影像的非整數坐標上,
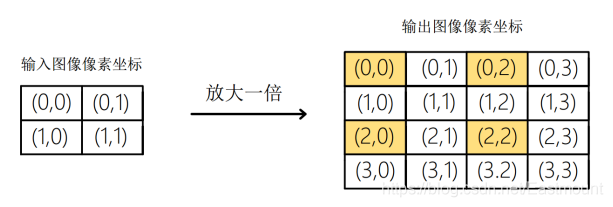
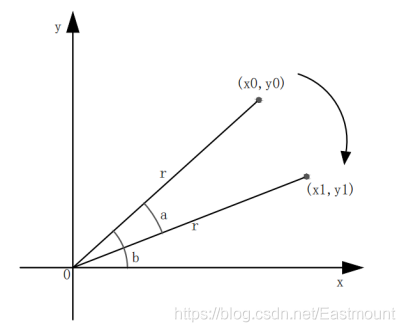
影像平移是將影像中的所有像素點按照給定的平移量進行水平或垂直方向上的移動,假設原始像素的位置坐標為(x0,y0),經過平移量(△x,△y)后,坐標變為(x1, y1),如圖所示,
影像旋轉是指影像以某一點為中心旋轉一定的角度,形成一幅新的影像的程序,影像旋轉變換會有一個旋轉中心,這個旋轉中心一般為影像的中心,旋轉之后影像的大小一般會發生改變,圖8表示原始影像的坐標(x0, y0)旋轉至(x1, y1)的程序,
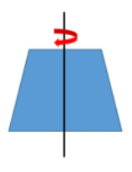
影像鏡像變換是影像旋轉變換的一種特殊情況,通常包括垂直方向和水平方向的鏡像,水平鏡像通常是以原影像的垂直中軸為中心,將影像分為左右兩部分進行堆成變換,如圖所示:
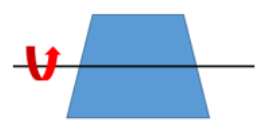
垂直鏡像通常是以原影像的水平中軸線為中心,將影像劃分為上下兩部分進行堆成變換的程序,示意圖如圖所示,
經典示例:
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
img = cv2.imread('test.bmp')
image = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#影像平移矩陣
M = np.float32([[1, 0, 100], [0, 1, 80]])
rows, cols = image.shape[:2]
img1 = cv2.warpAffine(image, M, (cols, rows))
#影像縮小
img2 = cv2.resize(image, (200,100))
#影像放大
img3 = cv2.resize(image, None, fx=1.1, fy=1.1)
#繞影像的中心旋轉
#源影像的高、寬 以及通道數
rows, cols, channel = image.shape
#函式引數:旋轉中心 旋轉度數 scale
M = cv2.getRotationMatrix2D((cols/2, rows/2), 30, 1)
#函式引數:原始影像 旋轉引數 元素影像寬高
img4 = cv2.warpAffine(image, M, (cols, rows))
#影像翻轉
img5 = cv2.flip(image, 0) #引數=0以X軸為對稱軸翻轉
img6 = cv2.flip(image, 1) #引數>0以Y軸為對稱軸翻轉
#影像的仿射
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1,pts2)
img7 = cv2.warpAffine(image, M, (rows,cols))
#影像的透射
pts1 = np.float32([[56,65],[238,52],[28,237],[239,240]])
pts2 = np.float32([[0,0],[200,0],[0,200],[200,200]])
M = cv2.getPerspectiveTransform(pts1,pts2)
img8 = cv2.warpPerspective(image,M,(200,200))
#回圈顯示圖形
titles = [ 'source', 'shift', 'reduction', 'enlarge', 'rotation', 'flipX', 'flipY', 'affine', 'transmission']
images = [image, img1, img2, img3, img4, img5, img6, img7, img8]
for i in range(9):
plt.subplot(3, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:
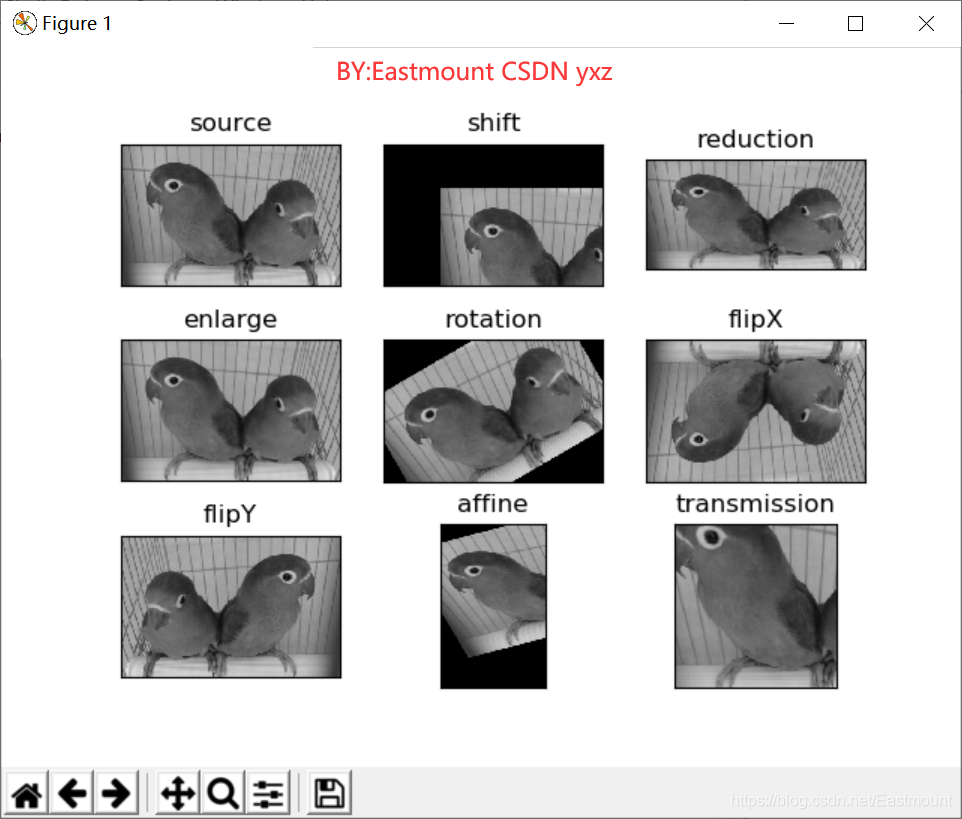
2.Python影像量化采樣
推薦文章:
- [Python影像處理] 三十.影像量化及采樣處理萬字詳細總結(推薦)
核心內容:
- 影像量化處理
– 概述
– 操作
– K-Means聚類量化處理 - 影像采樣處理
– 概述
– 操作
– 區域馬賽克處理 - 影像金字塔
– 影像向下取樣
dst = pyrDown(src[, dst[, dstsize[, borderType]]])
– 影像向上取樣
dst = pyrUp(src[, dst[, dstsize[, borderType]]])
經典知識:
所謂量化(Quantization),就是將影像像素點對應亮度的連續變化區間轉換為單個特定值的程序,即將原始灰度影像的空間坐標幅度值離散化,量化等級越多,影像層次越豐富,灰度解析度越高,影像的質量也越好;量化等級越少,影像層次欠豐富,灰度解析度越低,會出現影像輪廓分層的現象,降低了影像的質量,下圖是將影像的連續灰度值轉換為0至255的灰度級的程序,
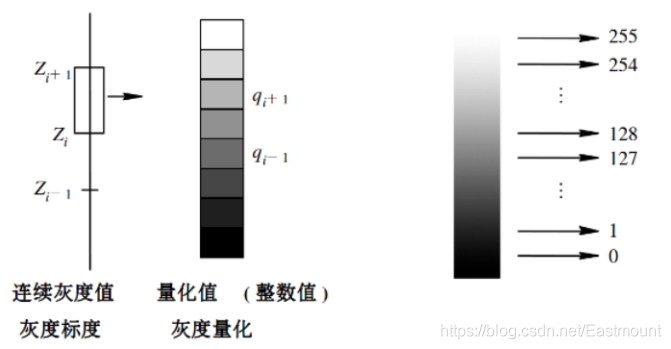
如果量化等級為2,則將使用兩種灰度級表示原始圖片的像素(0-255),灰度值小于128的取0,大于等于128的取128;如果量化等級為4,則將使用四種灰度級表示原始圖片的像素,新影像將分層為四種顏色,0-64區間取0,64-128區間取64,128-192區間取128,192-255區間取192,依次類推,
下圖是對比不同量化等級的“Lena”圖,其中(a)的量化等級為256,(b)的量化等級為64,(c)的量化等級為16,(d)的量化等級為8,(e)的量化等級為4,(f)的量化等級為2,

影像采樣(Image Sampling) 處理是將一幅連續影像在空間上分割成M×N個網格,每個網格用一個亮度值或灰度值來表示,其示意圖如圖所示,
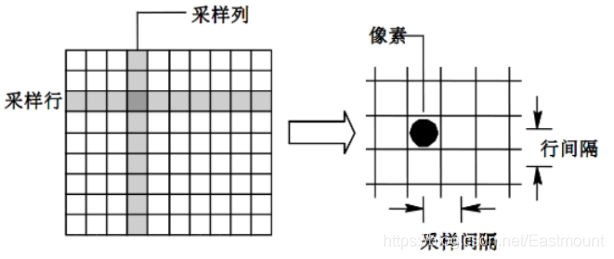
影像采樣的間隔越大,所得影像像素數越少,空間解析度越低,影像質量越差,甚至出現馬賽克效應;相反,影像采樣的間隔越小,所得影像像素數越多,空間解析度越高,影像質量越好,但資料量會相應的增大,下圖展示了不同采樣間隔的“Lena”圖,其中圖(a)為原始影像,圖(b)為128×128的影像采樣效果,圖?為64×64的影像采樣效果,圖(d)為32×32的影像采樣效果,圖(e)為16×16的影像采樣效果,圖(f)為8×8的影像采樣效果,

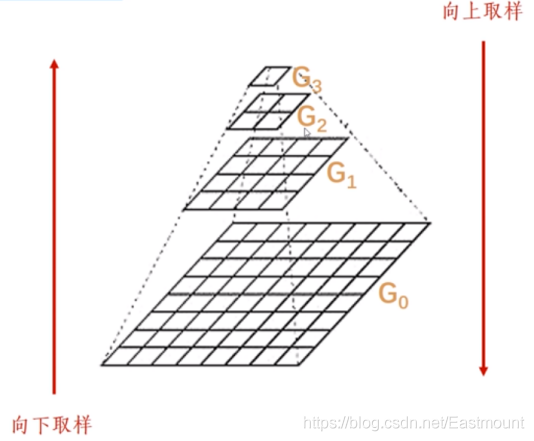
影像金字塔是指由一組影像且不同分別率的子圖集合,它是影像多尺度表達的一種,以多解析度來解釋影像的結構,主要用于影像的分割或壓縮,一幅影像的金字塔是一系列以金字塔形狀排列的解析度逐步降低,且來源于同一張原始圖的影像集合,如圖所示,它包括了四層影像,將這一層一層的影像比喻成金字塔,影像金字塔可以通過梯次向下采樣獲得,直到達到某個終止條件才停止采樣,在向下采樣中,層級越高,則影像越小,解析度越低,
經典示例:
(1)量化對比
下面的代碼分別比較了量化等級為2、4、8的量化處理效果,
# -*- coding: utf-8 -*-
# BY:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取原始影像
img = cv2.imread('lena-hd.png')
#獲取影像高度和寬度
height = img.shape[0]
width = img.shape[1]
#創建一幅影像
new_img1 = np.zeros((height, width, 3), np.uint8)
new_img2 = np.zeros((height, width, 3), np.uint8)
new_img3 = np.zeros((height, width, 3), np.uint8)
#影像量化等級為2的量化處理
for i in range(height):
for j in range(width):
for k in range(3): #對應BGR三分量
if img[i, j][k] < 128:
gray = 0
else:
gray = 128
new_img1[i, j][k] = np.uint8(gray)
#影像量化等級為4的量化處理
for i in range(height):
for j in range(width):
for k in range(3): #對應BGR三分量
if img[i, j][k] < 64:
gray = 0
elif img[i, j][k] < 128:
gray = 64
elif img[i, j][k] < 192:
gray = 128
else:
gray = 192
new_img2[i, j][k] = np.uint8(gray)
#影像量化等級為8的量化處理
for i in range(height):
for j in range(width):
for k in range(3): #對應BGR三分量
if img[i, j][k] < 32:
gray = 0
elif img[i, j][k] < 64:
gray = 32
elif img[i, j][k] < 96:
gray = 64
elif img[i, j][k] < 128:
gray = 96
elif img[i, j][k] < 160:
gray = 128
elif img[i, j][k] < 192:
gray = 160
elif img[i, j][k] < 224:
gray = 192
else:
gray = 224
new_img3[i, j][k] = np.uint8(gray)
#用來正常顯示中文標簽
plt.rcParams['font.sans-serif']=['SimHei']
#顯示影像
titles = ['(a) 原始影像', '(b) 量化-L2', '(c) 量化-L4', '(d) 量化-L8']
images = [img, new_img1, new_img2, new_img3]
for i in range(4):
plt.subplot(2,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:

(2)KMeans量化
# coding: utf-8
# BY:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取原始影像
img = cv2.imread('nv.png')
#影像二維像素轉換為一維
data = img.reshape((-1,3))
data = np.float32(data)
#定義中心 (type,max_iter,epsilon)
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
#設定標簽
flags = cv2.KMEANS_RANDOM_CENTERS
#K-Means聚類 聚集成4類
compactness, labels, centers = cv2.kmeans(data, 4, None, criteria, 10, flags)
#影像轉換回uint8二維型別
centers = np.uint8(centers)
res = centers[labels.flatten()]
dst = res.reshape((img.shape))
#影像轉換為RGB顯示
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dst = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB)
#用來正常顯示中文標簽
plt.rcParams['font.sans-serif']=['SimHei']
#顯示影像
titles = ['原始影像', '聚類量化 K=4']
images = [img, dst]
for i in range(2):
plt.subplot(1,2,i+1), plt.imshow(images[i], 'gray'),
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:

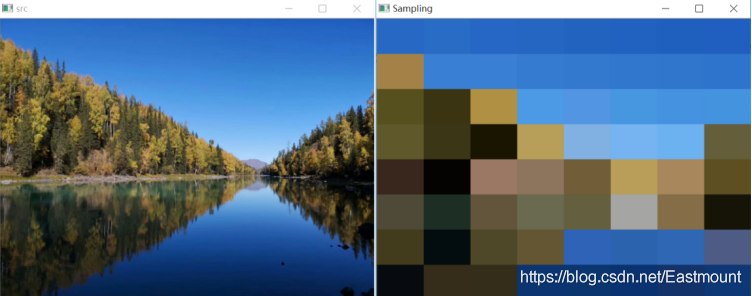
(3)彩色影像采樣
# -*- coding: utf-8 -*-
# BY:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取原始影像
img = cv2.imread('scenery.png')
#獲取影像高度和寬度
height = img.shape[0]
width = img.shape[1]
#采樣轉換成8*8區域
numHeight = int(height/8)
numwidth = int(width/8)
#創建一幅影像
new_img = np.zeros((height, width, 3), np.uint8)
#影像回圈采樣8*8區域
for i in range(8):
#獲取Y坐標
y = i*numHeight
for j in range(8):
#獲取X坐標
x = j*numwidth
#獲取填充顏色 左上角像素點
b = img[y, x][0]
g = img[y, x][1]
r = img[y, x][2]
#回圈設定小區域采樣
for n in range(numHeight):
for m in range(numwidth):
new_img[y+n, x+m][0] = np.uint8(b)
new_img[y+n, x+m][1] = np.uint8(g)
new_img[y+n, x+m][2] = np.uint8(r)
#顯示影像
cv2.imshow("src", img)
cv2.imshow("Sampling", new_img)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出結果如下圖所示:
3.Python影像點運算
推薦文章:
- [Python影像處理] 三十一.影像點運算處理兩萬字詳細總結(灰度化處理、閾值化處理)
核心內容:
- 影像點運算的概述
- 影像灰度化處理
– 基于OpenCV的影像灰度化處理
dst = cv2.cvtColor(src, code[, dst[, dstCn]])
– 基于像素操作的影像灰度化處理 - 影像的灰度線性變換
– 影像灰度上移變換
– 影像對比度增強變換
– 影像對比度減弱變換
– 影像灰度反色變換 - 影像的灰度非線性變換
– 影像灰度非線性變換
– 影像灰度對數變換
– 影像灰度伽瑪變換 - 影像閾值化處理
– 固定閾值化處理
dst = cv2.threshold(src, thresh, maxval, type[, dst])
– 自適應閾值化處理
dst = adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C[, dst])
經典知識:
影像點運算(Point Operation)指對于一幅輸入影像,將產生一幅輸出影像,輸出影像的每個像素點的灰度值由輸入像素點決定,點運算實際上是灰度到灰度的映射程序,通過映射變換來達到增強或者減弱影像的灰度,還可以對影像進行求灰度直方圖、線性變換、非線性變換以及影像骨架的提取,它與相鄰的像素之間沒有運算關系,是一種簡單和有效的影像處理方法,
影像灰度化是將一幅彩色影像轉換為灰度化影像的程序,彩色影像通常包括R、G、B三個分量,分別顯示出紅綠藍等各種顏色,灰度化就是使彩色影像的R、G、B三個分量相等的程序,灰度影像中每個像素僅具有一種樣本顏色,其灰度是位于黑色與白色之間的多級色彩深度,灰度值大的像素點比較亮,反之比較暗,像素值最大為255(表示白色),像素值最小為0(表示黑色),
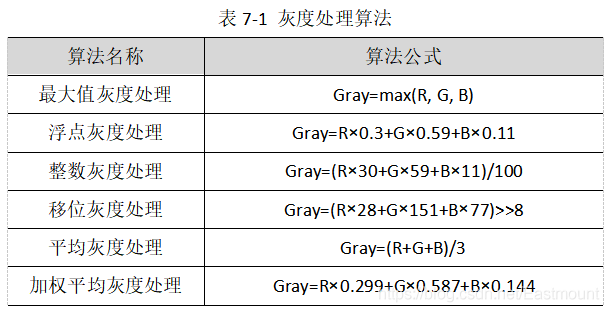
假設某點的顏色由RGB(R,G,B)組成,常見灰度處理演算法如表所示:
影像閾值化(Binarization) 旨在剔除掉影像中一些低于或高于一定值的像素,從而提取影像中的物體,將影像的背景和噪聲區分開來,影像閾值化可以理解為一個簡單的影像分割操作,閾值又稱為臨界值,它的目的是確定出一個范圍,然后這個范圍內的像素點使用同一種方法處理,而閾值之外的部分則使用另一種處理方法或保持原樣,
灰度化處理后的影像中,每個像素都只有一個灰度值,其大小表示明暗程度,閾值化處理可以將影像中的像素劃分為兩類顏色,常見的閾值化演算法如公式所示:
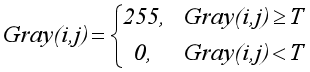
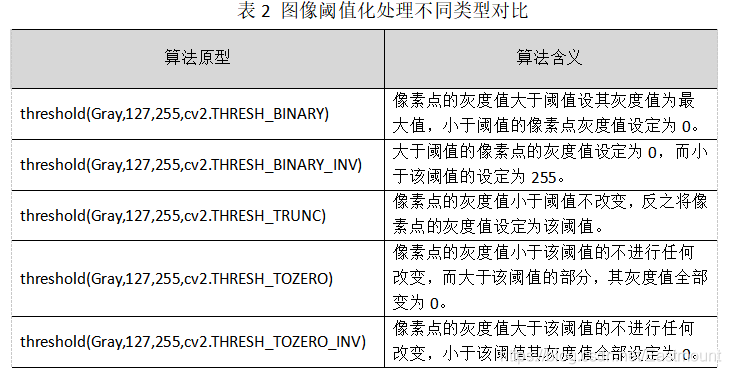
像閾值化處理threshold()函式不同型別的處理演算法如表所示,
經典示例:
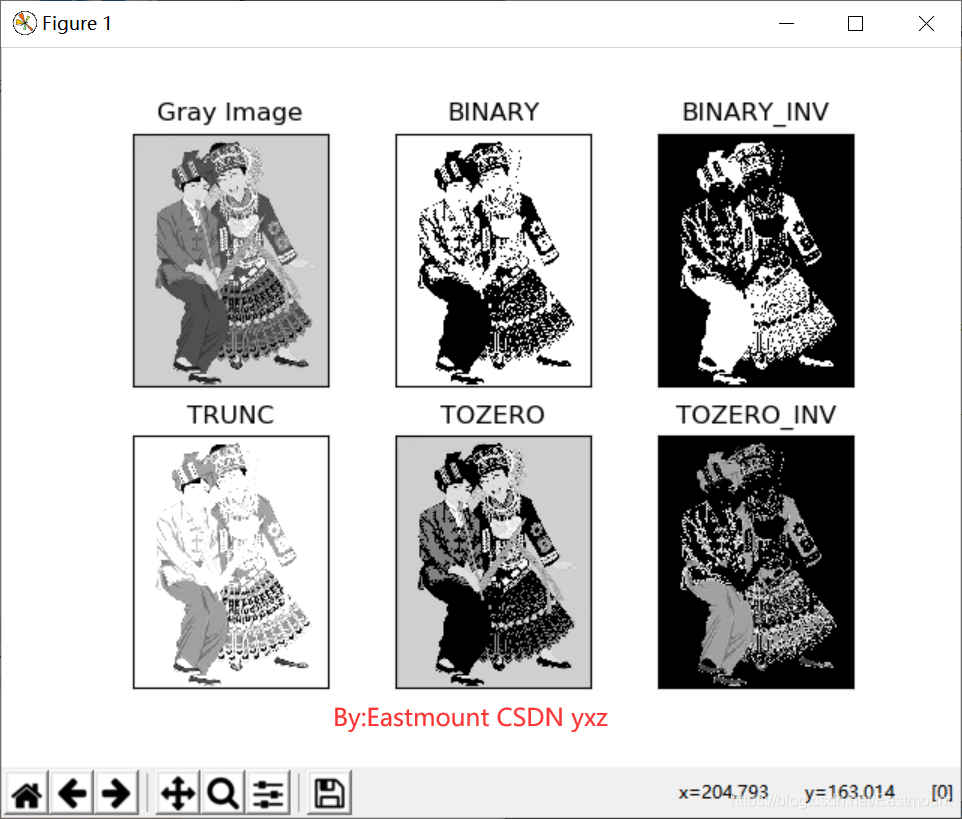
(1)固定閾值變化對比
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取影像
img=cv2.imread('miao.png')
grayImage=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#閾值化處理
ret,thresh1=cv2.threshold(grayImage,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(grayImage,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(grayImage,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(grayImage,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(grayImage,127,255,cv2.THRESH_TOZERO_INV)
#顯示結果
titles = ['Gray Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [grayImage, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:
(2)灰度變化對比
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import math
import numpy as np
import matplotlib.pyplot as plt
#讀取影像
img = cv2.imread('miao.png')
#影像灰度轉換
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#獲取影像高度和寬度
height = grayImage.shape[0]
width = grayImage.shape[1]
#影像灰度上移變換 DB=DA+50
result1 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
if (int(grayImage[i,j]+50) > 255):
gray = 255
else:
gray = int(grayImage[i,j]+50)
result1[i,j] = np.uint8(gray)
#影像對比度增強變換 DB=DA*1.5
result2 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
if (int(grayImage[i,j]*1.5) > 255):
gray = 255
else:
gray = int(grayImage[i,j]*1.5)
result2[i,j] = np.uint8(gray)
#影像對比度增強變換 DB=DA*0.8
result3 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
if (int(grayImage[i,j]*0.8) > 255):
gray = 255
else:
gray = int(grayImage[i,j]*0.8)
result3[i,j] = np.uint8(gray)
#影像灰度反色變換 DB=255-DA
result4 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
gray = 255 - grayImage[i,j]
result4[i,j] = np.uint8(gray)
#影像灰度非線性變換:DB=DA×DA/255
result5 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
gray = int(grayImage[i,j])*int(grayImage[i,j]) / 255
result5[i,j] = np.uint8(gray)
#影像灰度對數變換
result6 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
gray = 10* math.log(1 + grayImage[i, j])
result6[i,j] = np.uint8(gray)
#影像灰度伽瑪變換
result7 = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
gray = 3*pow(grayImage[i, j], 0.8)
if gray>255:
gray = 255
result7[i,j] = np.uint8(gray)
#用來正常顯示中文標簽
plt.rcParams['font.sans-serif']=['SimHei']
#顯示結果
titles = [u'原始影像', u'灰度影像', u'影像拉伸', u'對比度增強', u'對比度減弱',
u'影像反色', u'非線性變換', u'對數變換', u'伽馬變換']
images = [img, grayImage, result1, result2, result3, result4, result5, result6, result7]
for i in range(9):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:

(3)影像灰度伽瑪變換去霧
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import numpy as np
import matplotlib.pyplot as plt
import cv2
#繪制曲線
def gamma_plot(c, v):
x = np.arange(0, 256, 0.01)
y = c*x**v
plt.plot(x, y, 'r', linewidth=1)
plt.rcParams['font.sans-serif']=['SimHei'] #正常顯示中文標簽
plt.title('伽馬變換函式')
plt.xlim([0, 255]), plt.ylim([0, 255])
plt.show()
#伽瑪變換
def gamma(img, c, v):
lut = np.zeros(256, dtype=np.float32)
for i in range(256):
lut[i] = c * i ** v
output_img = cv2.LUT(img, lut) #像素灰度值的映射
output_img = np.uint8(output_img+0.5)
return output_img
#讀取原始影像
img = cv2.imread('2019.png')
#繪制伽瑪變換曲線
gamma_plot(0.00000005, 4.0)
#影像灰度伽瑪變換
output = gamma(img, 0.00000005, 4.0)
#顯示影像
cv2.imshow('Imput', img)
cv2.imshow('Output', output)
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出結果如下圖所示:

4.Python影像形態學
推薦文章:
- [Python影像處理] 四十三.Python影像形態學處理萬字詳解(腐蝕膨脹、開閉運算、梯度頂帽黑帽運算)
核心內容:
- 數學形態學概述
–dst = cv2.morphologyEx(src, model, kernel) - 影像腐蝕
–dst = cv2.erode(src, kernel, iterations) - 影像膨脹
–dst = cv2.dilate(src, kernel, iterations) - 影像開運算
–dst = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel) - 影像閉運算
–dst = cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel) - 影像梯度運算
–dst = cv2.morphologyEx(src, cv2.MORPH_GRADIENT, kernel) - 影像頂帽運算
–dst = cv2.morphologyEx(src, cv2.MORPH_TOPHAT, kernel) - 影像底帽運算
–dst = cv2.morphologyEx(src, cv2.MORPH_BLACKHAT, kernel)
經典知識:
數學形態學是一門建立在格論和拓撲學基礎之上的影像分析學科,是數學形態學影像處理的基本理論,其基本的運算包括:
- 腐蝕和膨脹
- 開運算和閉運算
- 影像頂帽運算和影像底帽運算
- 骨架抽取
- 形態學梯度
- Top-hat變換
常見的影像形態學運算包括腐蝕、膨脹、開運算、閉運算、梯度運算、頂帽運算和底帽運算等,主要通過MorphologyEx()函式實作,它能利用基本的膨脹和腐蝕技術,來執行更加高級形態學變換,如開閉運算、形態學梯度、頂帽、黑帽等,也可以實作最基本的影像膨脹和腐蝕,其函式原型如下:
- dst = cv2.morphologyEx(src, model, kernel)
– src表示原始影像
– model表示影像進行形態學處理,包括:
(1) cv2.MORPH_OPEN:開運算(Opening Operation)
(2) cv2.MORPH_CLOSE:閉運算(Closing Operation)
(3) cv2.MORPH_GRADIENT:形態學梯度(Morphological Gradient)
(4) cv2.MORPH_TOPHAT:頂帽運算(Top Hat)
(5) cv2.MORPH_BLACKHAT:黑帽運算(Black Hat)
– kernel表示卷積核,可以用numpy.ones()函式構建
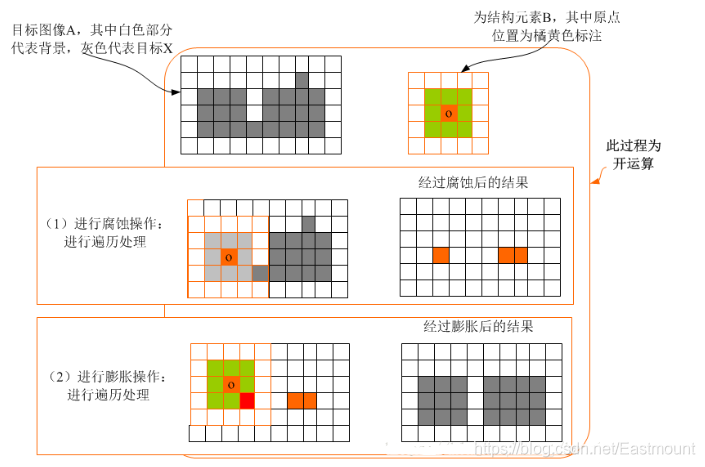
影像的腐蝕(Erosion)和膨脹(Dilation)是兩種基本的形態學運算,主要用來尋找影像中的極小區域和極大區域,影像腐蝕類似于“領域被蠶食”,它將影像中的高亮區域或白色部分進行縮減細化,其運行結果比原圖的高亮區域更小,
設A,B為集合,A被B的腐蝕,記為A-B,其定義為:
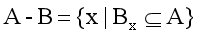
該公式表示影像A用卷積模板B來進行腐蝕處理,通過模板B與影像A進行卷積計算,得出B覆寫區域的像素點最小值,并用這個最小值來替代參考點的像素值,如圖1所示,將左邊的原始影像A腐蝕處理為右邊的效果圖A-B,
影像膨脹處理效果如下圖所示:
影像開運算是影像依次經過腐蝕、膨脹處理的程序,影像被腐蝕后將去除噪聲,但同時也壓縮了影像,接著對腐蝕過的影像進行膨脹處理,可以在保留原有影像的基礎上去除噪聲,其原理如圖所示,
經典案例:
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
src = cv2.imread('na.png', cv2.IMREAD_UNCHANGED)
img = cv2.cvtColor(src,cv2.COLOR_BGR2RGB)
# 轉化為灰度圖
Grayimg = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 1、消除椒鹽噪聲:
# 中值濾波器
median = cv2.medianBlur(Grayimg, 5)
# 消除噪聲圖
cv2.imshow("median-image", median)
# 2、直方圖均衡化:
equalize = cv2.equalizeHist(median)
cv2.imshow('hist', equalize)
# 3、二值化處理:
# 閾值為140
ret, binary = cv2.threshold(equalize, 127, 255,cv2.THRESH_BINARY)
cv2.imshow("binary-image",binary)
cv2.waitKey(0)
#設定卷積核
kernel = np.ones((10,10), np.uint8)
close = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)
#影像開運算
kernel = np.ones((10,10), np.uint8)
open1 = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
#顯示影像
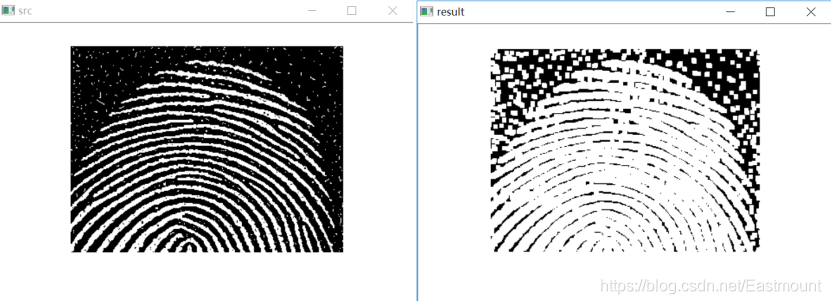
cv2.imshow("src", src)
cv2.imshow("result", close)
#等待顯示
cv2.waitKey(0)
cv2.destroyAllWindows()
#影像開運算
kernel = np.ones((10,10), np.uint8)
gradient = cv2.morphologyEx(binary, cv2.MORPH_GRADIENT, kernel)
# Sobel算子 XY方向求梯度 cv2.CV_8U
x = cv2.Sobel(close, cv2.CV_32F, 1, 0, ksize = 3) #X方向
y = cv2.Sobel(close, cv2.CV_32F, 0, 1, ksize = 3) #Y方向
#absX = cv2.convertScaleAbs(x) # 轉回uint8
#absY = cv2.convertScaleAbs(y)
#Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
gradient = cv2.subtract(x, y)
sobel = cv2.convertScaleAbs(gradient)
cv2.imshow('Sobel', sobel)
cv2.waitKey(0)
#回圈顯示圖形
titles = [ 'source', 'gray', 'median', 'equalize', 'binary', 'close', 'open', 'gradient', 'sobel']
images = [img, Grayimg, median, equalize, binary, close, open1, gradient, sobel]
for i in range(9):
plt.subplot(3, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:
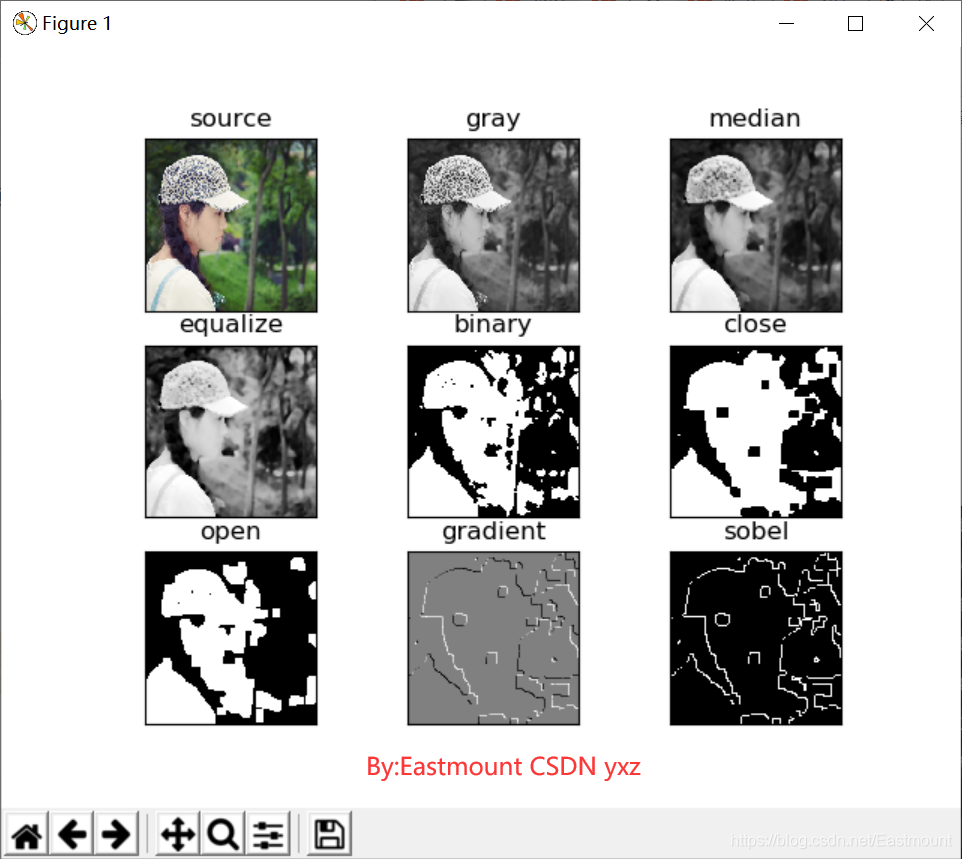
四.影像增強
Python影像處理第三部分為“影像增強”,主要包括Python直方圖統計、Python影像增強、Python影像平滑和Python影像銳化及邊緣檢測,
1.Python直方圖統計
推薦文章:
- [Python影像處理] 三十七.OpenCV直方圖統計兩萬字詳解(掩膜直方圖、灰度直方圖對比、黑夜白天預測)
核心內容:
- 影像直方圖概述
- Matplotlib繪制直方圖
–n, bins, patches = plt.hist(arr, bins=50, normed=1, facecolor=‘green’, alpha=0.75) - OpenCV繪制直方圖
–hist = cv2.calcHist(images, channels, mask, histSize, ranges, accumulate) - 掩膜直方圖
- 影像灰度變換直方圖對比
– 灰度上移變換影像直方圖對比
– 灰度減弱影像直方圖對比
– 影像反色變換直方圖對比
– 影像對數變換直方圖對比
– 影像閾值化處理直方圖對比 - 影像H-S直方圖
- 直方圖判斷黑夜白天
經典知識:
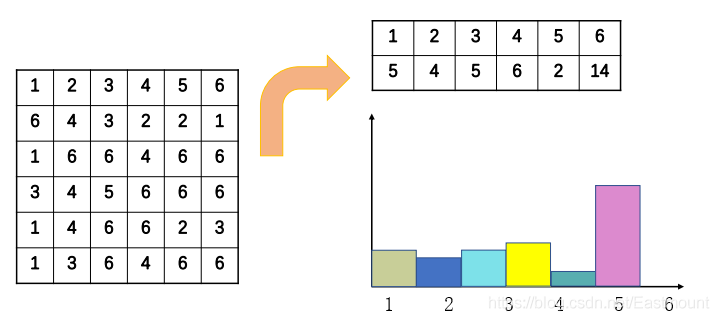
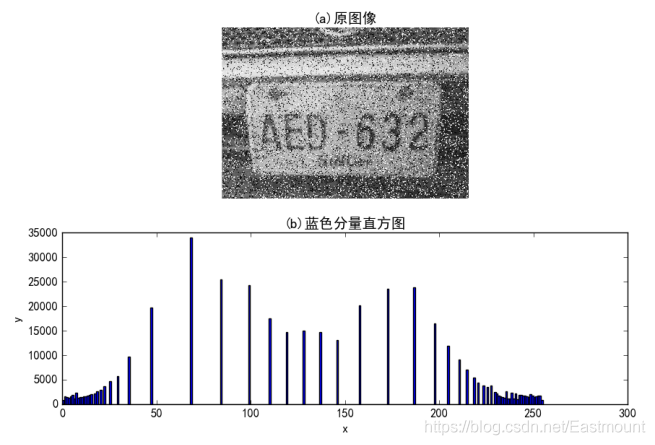
影像灰度直方圖(Histogram)是灰度級分布的函式,是對影像中灰度級分布的統計,灰度直方圖是將數字影像中的所有像素,按斬訓度值的大小,統計其出現的頻率并繪制相關圖形,
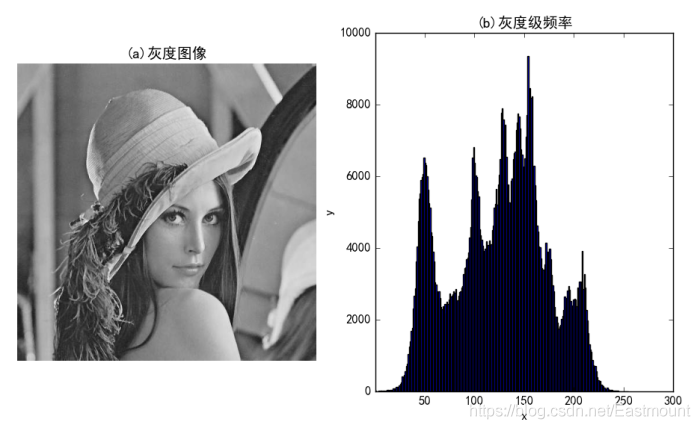
如果灰度級為0-255(最小值0為黑色,最大值255為白色),同樣可以繪制對應的直方圖,如圖2所示,左邊是一幅灰度影像(Lena灰度圖),右邊是對應各像素點的灰度級頻率,
經典示例:
(1)Matplotlib繪制直方圖
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
#讀取影像
src = cv2.imread('Lena.png')
#轉換為RGB影像
img_rgb = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
#獲取BGR三個通道的像素值
b, g, r = cv2.split(src)
print(r,g,b)
plt.figure(figsize=(8, 6))
#設定字體
matplotlib.rcParams['font.sans-serif']=['SimHei']
#原始影像
plt.subplot(221)
plt.imshow(img_rgb)
plt.axis('off')
plt.title("(a)原影像")
#繪制藍色分量直方圖
plt.subplot(222)
plt.hist(b.ravel(), bins=256, density=1, facecolor='b', edgecolor='b', alpha=0.75)
plt.xlabel("x")
plt.ylabel("y")
plt.title("(b)藍色分量直方圖")
#繪制綠色分量直方圖
plt.subplot(223)
plt.hist(g.ravel(), bins=256, density=1, facecolor='g', edgecolor='g', alpha=0.75)
plt.xlabel("x")
plt.ylabel("y")
plt.title("(c)綠色分量直方圖")
#繪制紅色分量直方圖
plt.subplot(224)
plt.hist(r.ravel(), bins=256, density=1, facecolor='r', edgecolor='r', alpha=0.75)
plt.xlabel("x")
plt.ylabel("y")
plt.title("(d)紅色分量直方圖")
plt.show()
輸出結果如下圖所示:
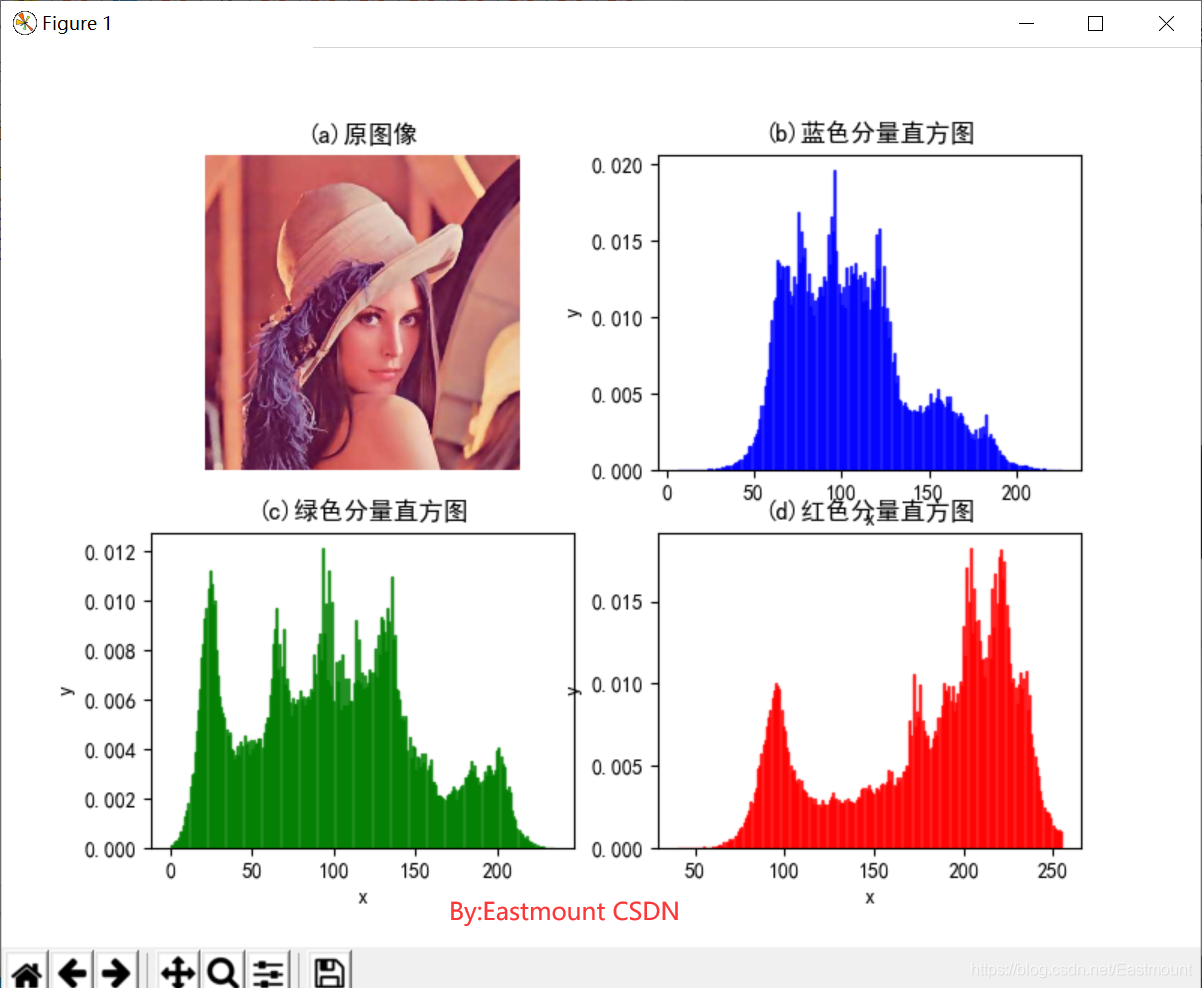
(2)OpenCV繪制直方圖
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
#讀取影像
src = cv2.imread('Lena.png')
#轉換為RGB影像
img_rgb = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
#計算直方圖
histb = cv2.calcHist([src], [0], None, [256], [0,255])
histg = cv2.calcHist([src], [1], None, [256], [0,255])
histr = cv2.calcHist([src], [2], None, [256], [0,255])
#設定字體
matplotlib.rcParams['font.sans-serif']=['SimHei']
#顯示原始影像和繪制的直方圖
plt.subplot(121)
plt.imshow(img_rgb, 'gray')
plt.axis('off')
plt.title("(a)Lena原始影像")
plt.subplot(122)
plt.plot(histb, color='b')
plt.plot(histg, color='g')
plt.plot(histr, color='r')
plt.xlabel("x")
plt.ylabel("y")
plt.title("(b)直方圖曲線")
plt.show()
輸出結果如下圖所示:
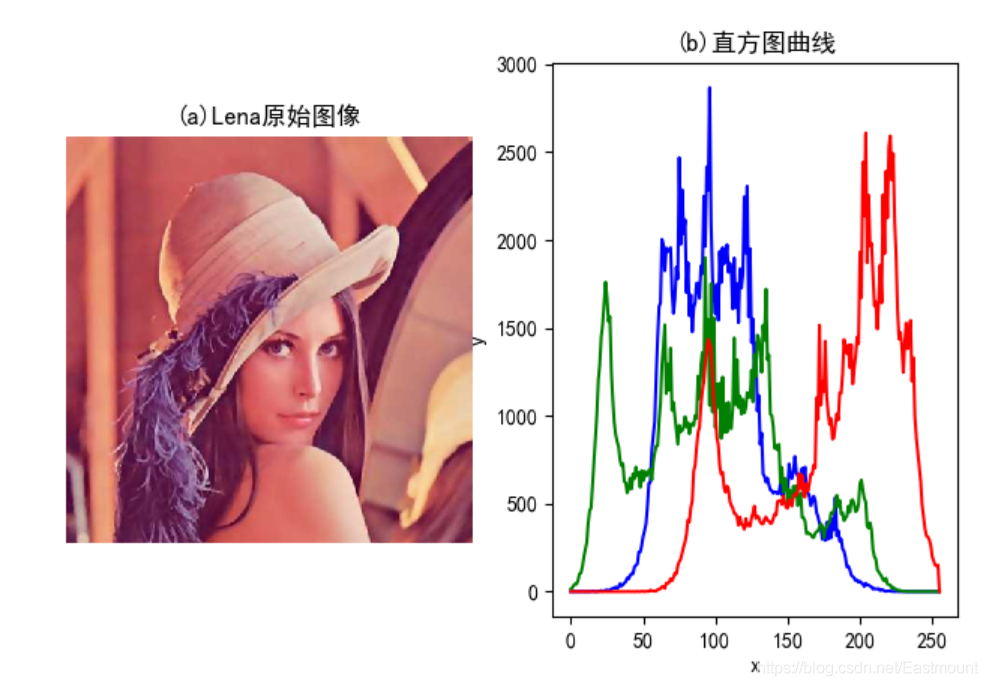
(3)灰度變換直方圖對比
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取影像
img = cv2.imread('lena-hd.png')
#影像灰度轉換
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#獲取影像高度和寬度
height = grayImage.shape[0]
width = grayImage.shape[1]
result = np.zeros((height, width), np.uint8)
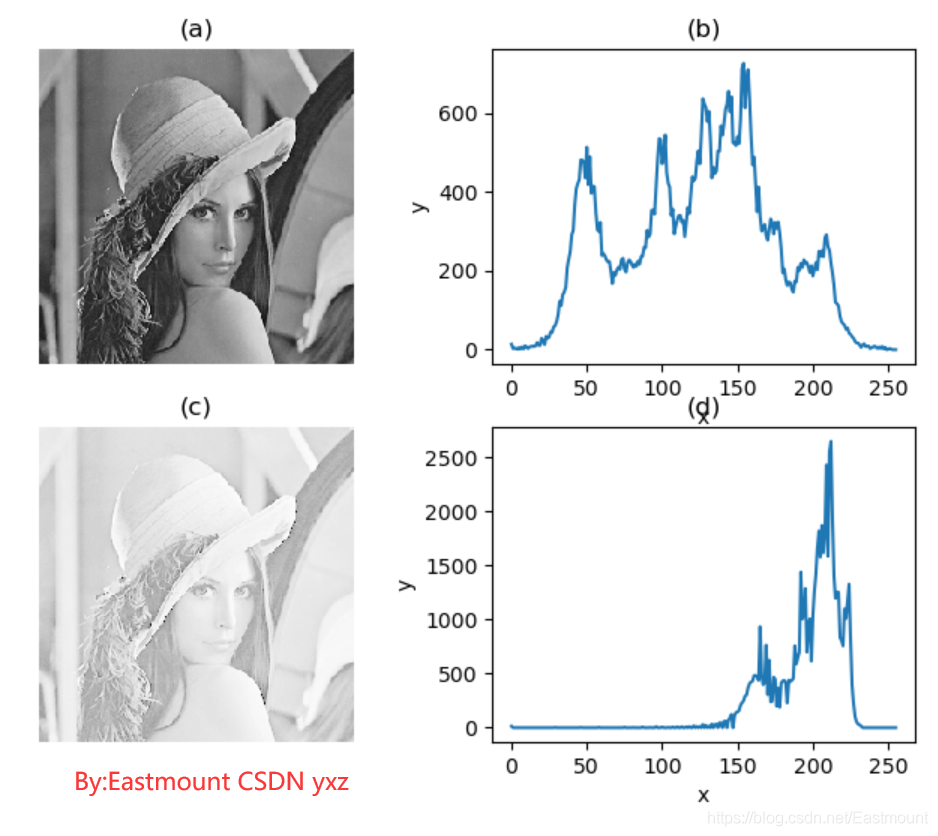
#影像灰度對數變換
for i in range(height):
for j in range(width):
gray = 42 * np.log(1.0 + grayImage[i,j])
result[i,j] = np.uint8(gray)
#計算原圖的直方圖
hist = cv2.calcHist([img], [0], None, [256], [0,255])
#計算灰度變換的直方圖
hist_res = cv2.calcHist([result], [0], None, [256], [0,255])
#原始影像
plt.figure(figsize=(8, 6))
plt.subplot(221), plt.imshow(img, 'gray'), plt.title("(a)"), plt.axis('off')
#繪制原始影像直方圖
plt.subplot(222), plt.plot(hist), plt.title("(b)"), plt.xlabel("x"), plt.ylabel("y")
#灰度變換后的影像
plt.subplot(223), plt.imshow(result, 'gray'), plt.title("(c)"), plt.axis('off')
#灰度變換影像的直方圖
plt.subplot(224), plt.plot(hist_res), plt.title("(d)"), plt.xlabel("x"), plt.ylabel("y")
plt.show()
輸出結果如下圖所示:
2.Python影像增強
推薦文章:
- [Python影像處理] 三十八.OpenCV影像增強和影像去霧萬字詳解(直方圖均衡化、區域直方圖均衡化、自動色彩均衡化)
核心內容:
- 影像增強概述
– 空間域
– 頻率域 - 直方圖均衡化
– 原理知識
– 代碼實作
dst = cv2.equalizeHist(src) - 區域直方圖均衡化
–retval = createCLAHE([, clipLimit[, tileGridSize]]) - 自動色彩均衡化
– ACE演算法
經典知識:
影像增強(Image Enhancement)是指按照某種特定的需求,突出影像中有用的資訊,去除或者削弱無用的資訊,影像增強的目的是使處理后的影像更適合人眼的視覺特性或易于機器識別,影像增強通常劃分為如圖2所示的分類,其中最重要的是影像平滑和影像銳化處理,
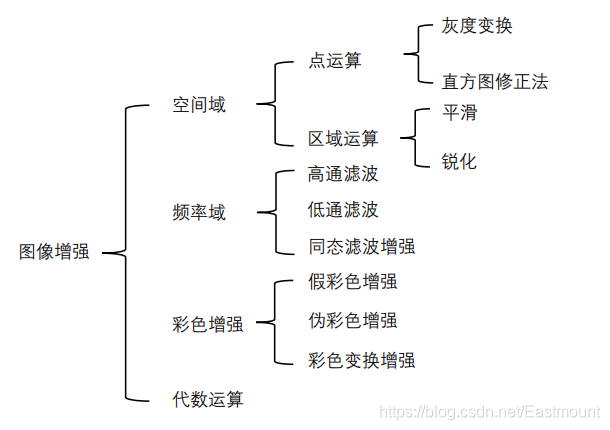
直方圖均衡是影像增強處理中對比度變換調整中最典型的方法,該方法是空域增強中最常用、最簡單有效的方法之一,其采用灰度統計特征,將原始影像中的灰度直方圖從較為集中的某個灰度區間轉變為均勻分布于整個灰度區域范圍的變換方法,通常又劃分為:
- 全域直方圖均衡
該方法的主要優點是演算法簡單、速度快,可自動增強影像;全域直方圖均衡方法的缺點是對噪聲敏感、細節資訊易失,在某些結果區域產生過增強問題,且對對比度增強的力度相對較低, - 區域直方圖均衡
該方法的主要優點是區域自適應,可最大限度的增強影像細節;其缺點是增強影像質量操控困難,并會隨之引入噪聲,
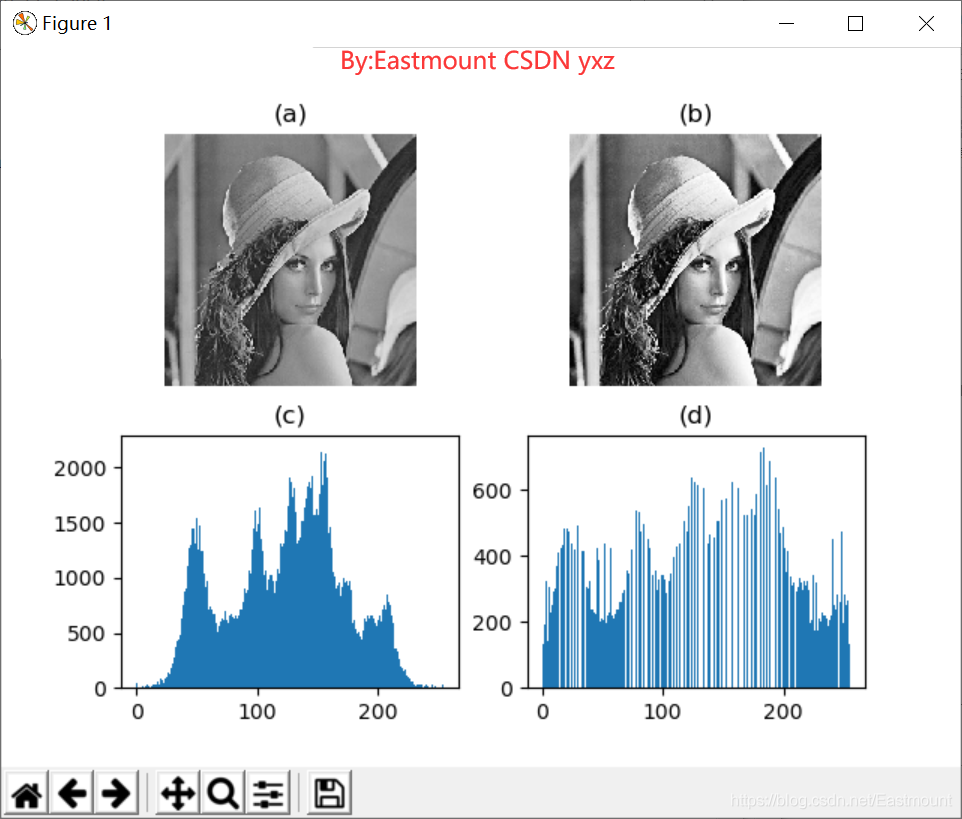
下圖(a)表示直方圖均衡化處理后的影像,圖(b)表示其對應的直方圖,從效果圖可以看出,經過直方圖均衡化處理,影像變得更加清晰,影像的灰度級分布也更加均勻,
自動色彩均衡(Automatic Color Enhancement,ACE) 演算法是在Retinex演算法的理論上提出的,它通過計算影像目標像素點和周圍像素點的明暗程度及其關系來對最終的像素值進行校正,實作影像的對比度調整,產生類似人體視網膜的色彩恒常性和亮度恒常性的均衡,具有很好的影像增強效果,
ACE演算法能有效進行影像去霧處理,實作影像的細節增強,

經典案例:
(1)直方圖均衡化對比
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
img = cv2.imread('lena-hd.png')
#灰度轉換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#直方圖均衡化處理
result = cv2.equalizeHist(gray)
#顯示影像
plt.subplot(221)
plt.imshow(gray, cmap=plt.cm.gray), plt.axis("off"), plt.title('(a)')
plt.subplot(222)
plt.imshow(result, cmap=plt.cm.gray), plt.axis("off"), plt.title('(b)')
plt.subplot(223)
plt.hist(img.ravel(), 256), plt.title('(c)')
plt.subplot(224)
plt.hist(result.ravel(), 256), plt.title('(d)')
plt.show()
輸出結果如圖所示,圖(a)為原始影像,對應的直方圖為圖?,圖(b)和圖(d)為直方圖處理后的影像及對應直方圖,它讓影像的灰度值分布更加均衡,
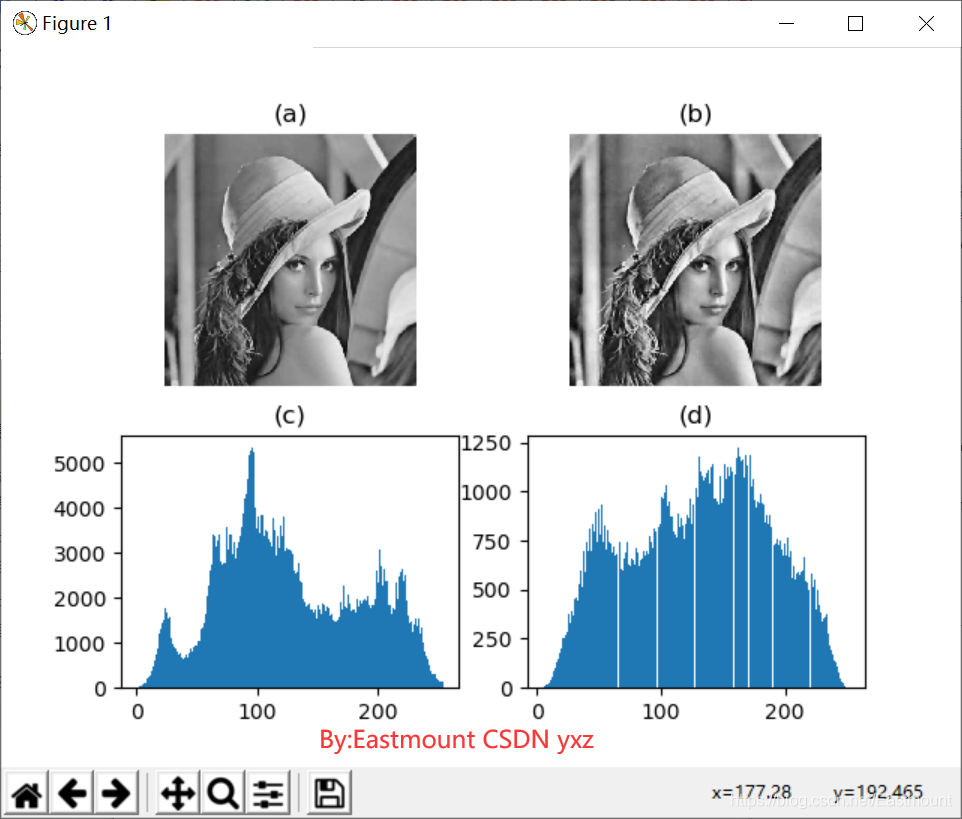
(2)區域直方圖均衡化
#encoding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
img = cv2.imread('lena.png')
#灰度轉換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#區域直方圖均衡化處理
clahe = cv2.createCLAHE(clipLimit=2, tileGridSize=(10,10))
#將灰度影像和區域直方圖相關聯, 把直方圖均衡化應用到灰度圖
result = clahe.apply(gray)
#顯示影像
plt.subplot(221)
plt.imshow(gray, cmap=plt.cm.gray), plt.axis("off"), plt.title('(a)')
plt.subplot(222)
plt.imshow(result, cmap=plt.cm.gray), plt.axis("off"), plt.title('(b)')
plt.subplot(223)
plt.hist(img.ravel(), 256), plt.title('(c)')
plt.subplot(224)
plt.hist(result.ravel(), 256), plt.title('(d)')
plt.show()
輸出結果如下圖所示:
3.Python影像平滑
推薦文章:
- [Python影像處理] 四十一.Python影像平滑萬字詳解(均值濾波、方框濾波、高斯濾波、中值濾波、雙邊濾波)
核心內容:
- 影像平滑概述
– 影像平滑
– 線性濾波和非線性濾波
– 常見濾波器 - 均值濾波
– 演算法原理
– 代碼實作
dst = blur(src, ksize[, dst[, anchor[, borderType]]]) - 方框濾波
–dst = boxFilter(src, depth, ksize[, dst[, anchor[, normalize[, borderType]]]]) - 高斯濾波
–dst = GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]]]) - 中值濾波
–dst = medianBlur(src, ksize[, dst]) - 雙邊濾波
–dst = bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])
經典知識:
影像平滑(smoothing)是一項簡單且使用頻率很高的影像處理方法,可以用來壓制、榷訓或消除影像中的細節、突變、邊緣和噪聲,最常見的是用來減少影像上的噪聲,
何為影像噪聲?噪聲是妨礙人的感覺器官所接受信源資訊理解的因素,是不可預測只能用概率統計方法認識的隨機誤差,從圖1中,可以觀察到噪聲的特點:位置隨機、大小不規則,將這種噪聲稱為隨機噪聲,這是一種常見的噪聲型別,

一幅影像不可避免地要受到各種噪聲源的干擾,所以噪聲濾除往往是影像處理中的第一步,濾波效果好壞將直接影響后續處理結果,噪聲濾除在影像處理中占有相當重要的地位,噪聲濾除演算法多種多樣,可以從設計方法上分為兩大類:
- 線性濾波演算法
- 非線性濾波演算法
后文將詳細介紹以下常用的一些濾波器,包括均值濾波、方框濾波、高斯呂波、中值濾波等,如表所示,
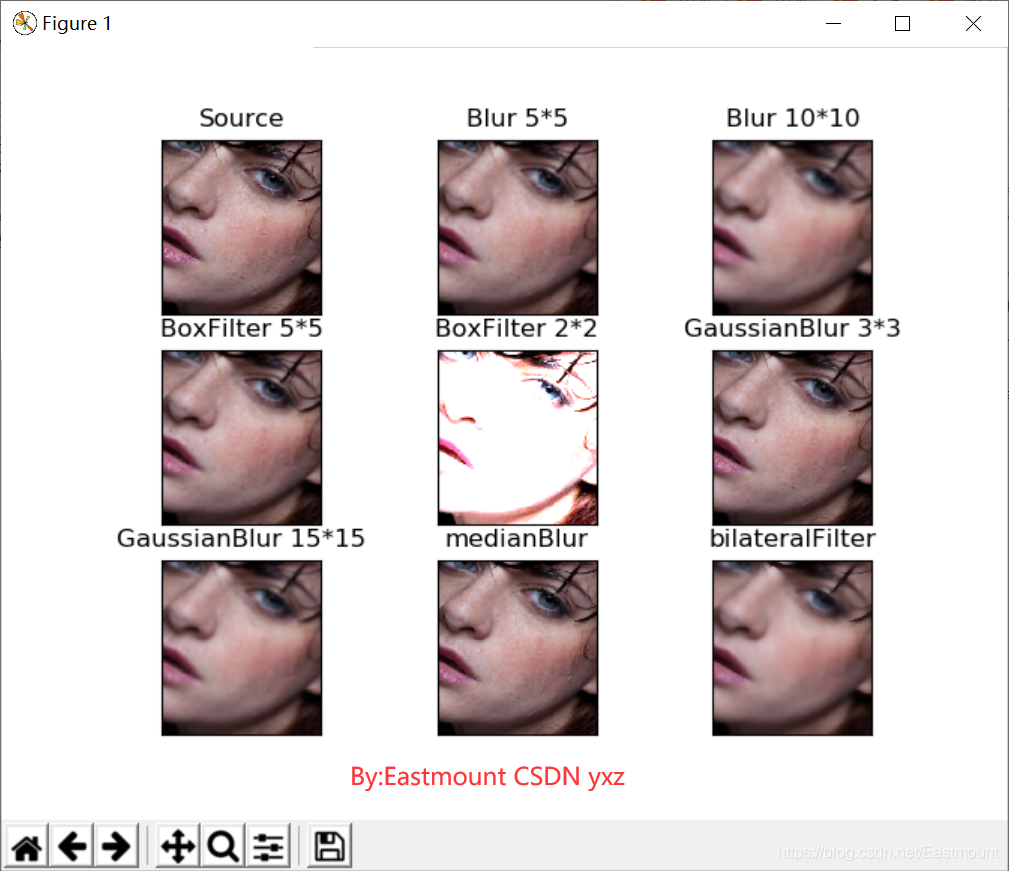
下圖為這五種濾波的效果對比,從濾波的結果可以看出各種濾波演算法對影像的作用非常不同,有些變化非常大,有些甚至跟原圖一樣,在實際應用時,應根據噪聲的特點、期望的影像和邊緣特征等來選擇合適的濾波器,這樣才能發揮影像濾波的最大優點,

經典示例:
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取圖片
img = cv2.imread('te.png')
source = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#均值濾波
result1 = cv2.blur(source, (5,5))
result2 = cv2.blur(source, (10,10))
#方框濾波
result3 = cv2.boxFilter(source, -1, (5,5), normalize=1)
result4 = cv2.boxFilter(source, -1, (2,2), normalize=0)
#高斯濾波
result5 = cv2.GaussianBlur(source, (3,3), 0)
result6 = cv2.GaussianBlur(source, (15,15), 0)
#中值濾波
result7 = cv2.medianBlur(source, 3)
#高斯雙邊濾波
result8 =cv2.bilateralFilter(source, 15, 150, 150)
#顯示圖形
titles = ['Source', 'Blur 5*5', 'Blur 10*10', 'BoxFilter 5*5',
'BoxFilter 2*2', 'GaussianBlur 3*3', 'GaussianBlur 15*15',
'medianBlur', 'bilateralFilter']
images = [source, result1, result2, result3,
result4, result5, result6, result7, result8]
for i in range(9):
plt.subplot(3,3,i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
輸出結果如下圖所示:
4.Python影像銳化
推薦文章:
- [Python影像處理] 四十二.Python影像銳化及邊緣檢測萬字詳解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG)
核心內容:
- 原理概述
– 一階微分算子
– 二階微分算子 - Roberts算子
–dst = filter2D(src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]])
–dst = convertScaleAbs(src[, dst[, alpha[, beta]]]) - Prewitt算子
–absX = cv2.convertScaleAbs(x)
–absY = cv2.convertScaleAbs(y)
–Prewitt = cv2.addWeighted(absX,0.5,absY,0.5,0) - Sobel算子
–dst = Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]])
–dst = convertScaleAbs(src[, dst[, alpha[, beta]]]) - Laplacian算子
–dst = Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]])
–dst = convertScaleAbs(src[, dst[, alpha[, beta]]]) - Scharr算子
–dst = Scharr(src, ddepth, dx, dy[, dst[, scale[, delta[, borderType]]]]]) - Canny算子
–edges = Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient]]]) - LOG算子
–dst = cv2.Laplacian(gaussian, cv2.CV_16S, ksize = 3)
–LOG = cv2.convertScaleAbs(dst)
經典知識:
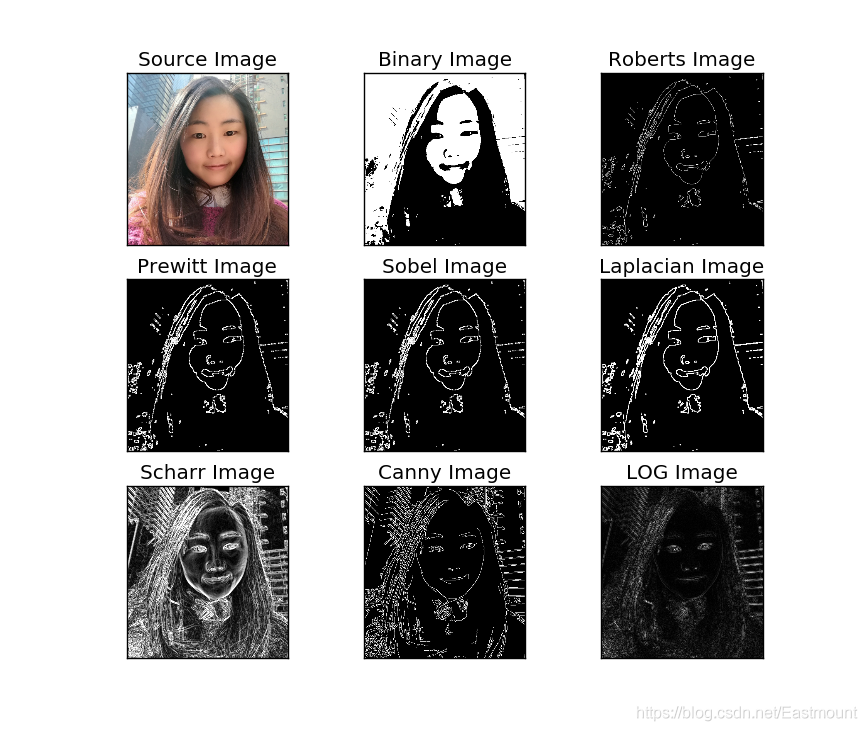
由于收集影像資料的器件或傳輸影像的通道存在一些質量缺陷,或者受其他外界因素的影響,使得影像存在模糊和有噪聲的情況,從而影響到影像識別作業的開展,一般來說,影像的能量主要集中在其低頻部分,噪聲所在的頻段主要在高頻段,同時影像邊緣資訊主要集中在其高頻部分,這將導致原始影像在平滑處理之后,影像邊緣和影像輪廓模糊的情況出現,為了減少這類不利效果的影響,就需要利用影像銳化技術,使影像的邊緣變得清晰,

影像銳化處理的目的是為了使影像的邊緣、輪廓線以及影像的細節變得清晰,經過平滑的影像變得模糊的根本原因是影像受到了平均或積分運算,因此可以對其進行逆運算,從而使影像變得清晰,
影像銳化和邊緣提取技術可以消除影像中的噪聲,提取影像資訊中用來表征影像的一些變數,為影像識別提供基礎,通常使用灰度差分法對影像的邊緣、輪廓進行處理,將其凸顯,影像銳化的方法分為高通濾波和空域微分法,
經典案例:
#encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取影像
img = cv2.imread('nv.png')
lenna_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#灰度化處理影像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#高斯濾波
gaussianBlur = cv2.GaussianBlur(grayImage, (3,3), 0)
#閾值處理
ret, binary = cv2.threshold(gaussianBlur, 127, 255, cv2.THRESH_BINARY)
#Roberts算子
kernelx = np.array([[-1,0],[0,1]], dtype=int)
kernely = np.array([[0,-1],[1,0]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Roberts = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Prewitt算子
kernelx = np.array([[1,1,1],[0,0,0],[-1,-1,-1]], dtype=int)
kernely = np.array([[-1,0,1],[-1,0,1],[-1,0,1]], dtype=int)
x = cv2.filter2D(binary, cv2.CV_16S, kernelx)
y = cv2.filter2D(binary, cv2.CV_16S, kernely)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Prewitt = cv2.addWeighted(absX,0.5,absY,0.5,0)
#Sobel算子
x = cv2.Sobel(binary, cv2.CV_16S, 1, 0)
y = cv2.Sobel(binary, cv2.CV_16S, 0, 1)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#拉普拉斯演算法
dst = cv2.Laplacian(binary, cv2.CV_16S, ksize = 3)
Laplacian = cv2.convertScaleAbs(dst)
# Scharr算子
x = cv2.Scharr(gaussianBlur, cv2.CV_32F, 1, 0) #X方向
y = cv2.Scharr(gaussianBlur, cv2.CV_32F, 0, 1) #Y方向
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
Scharr = cv2.addWeighted(absX, 0.5, absY, 0.5, 0)
#Canny算子
Canny = cv2.Canny(gaussianBlur, 50, 150)
#先通過高斯濾波降噪
gaussian = cv2.GaussianBlur(grayImage, (3,3), 0)
#再通過拉普拉斯算子做邊緣檢測
dst = cv2.Laplacian(gaussian, cv2.CV_16S, ksize = 3)
LOG = cv2.convertScaleAbs(dst)
#效果圖
titles = ['Source Image', 'Binary Image', 'Roberts Image',
'Prewitt Image','Sobel Image', 'Laplacian Image',
'Scharr Image', 'Canny Image', 'LOG Image']
images = [lenna_img, binary, Roberts,
Prewitt, Sobel, Laplacian,
Scharr, Canny, LOG]
for i in np.arange(9):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
女神的運行結果如下圖所示:
五.高階影像處理
Python影像處理第四部分為“高階影像處理”,主要包括Python影像特效、Python影像分割、Python傅里葉變換及霍夫變換和Python影像分類,
1.Python影像特效
推薦文章:
- [Python影像處理] 三十三.影像各種特效處理及原理萬字詳解(毛玻璃、浮雕、素描、懷舊、流年、濾鏡等)
核心內容:
- 影像毛玻璃特效
- 影像浮雕特效
–dst = filter2D(src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]]) - 影像油漆特效
- 影像素描特效
- 影像懷舊特效
- 影像光照特效
- 影像流年特效
- 影像水波特效
- 影像卡通特效
- 影像濾鏡特效
- 影像直方圖均衡化特效
- 影像模糊特效
經典知識:
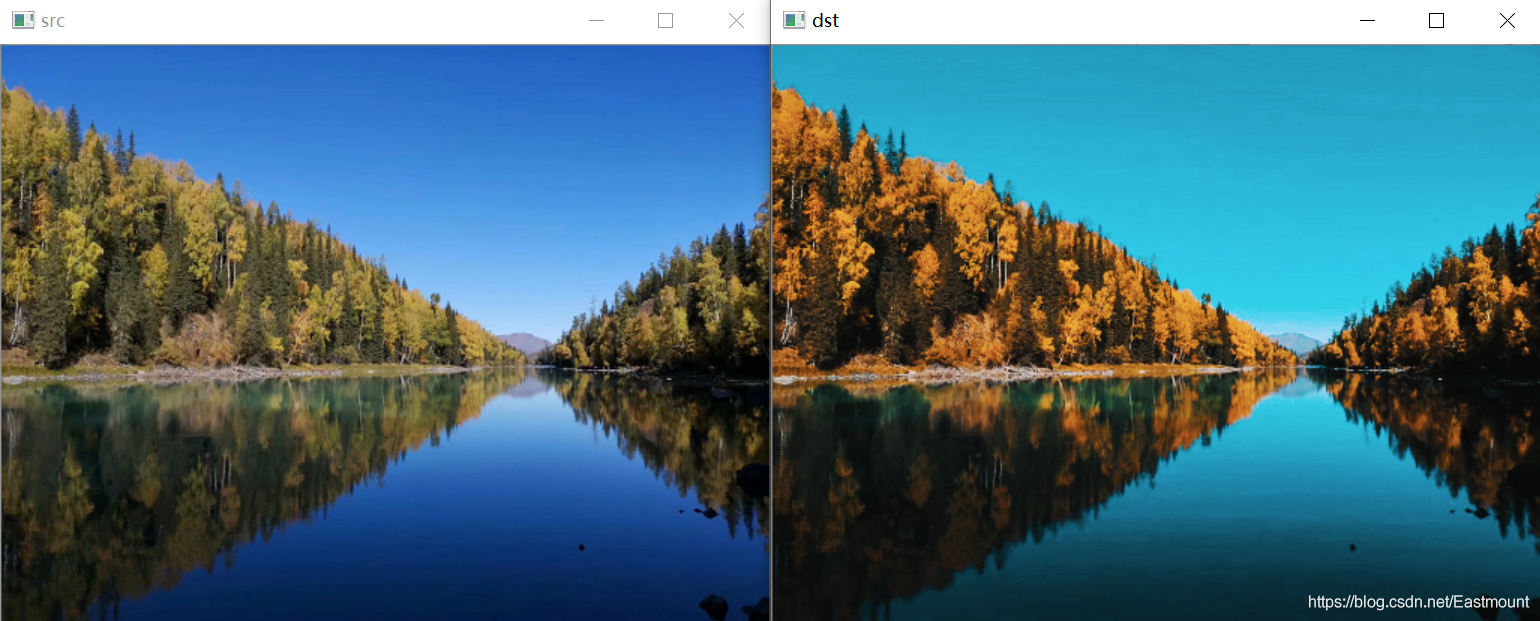
影像懷舊特效是指影像經歷歲月的昏暗效果,如圖所示,左邊“src”為原始影像,右邊“dst”為懷舊特效影像,
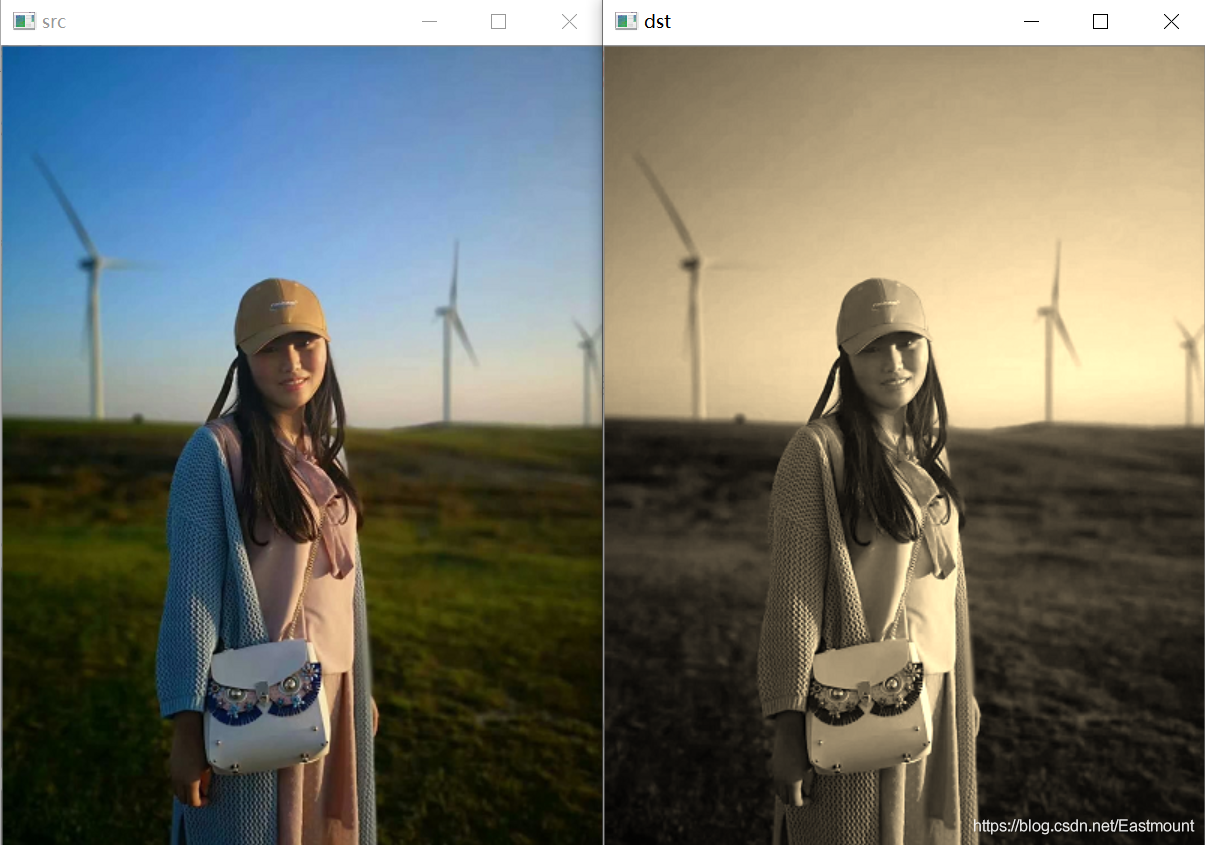
懷舊特效是將影像的RGB三個分量分別按照一定比例進行處理的結果,其懷舊公式所示,
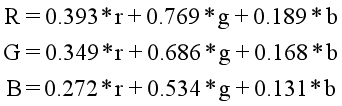
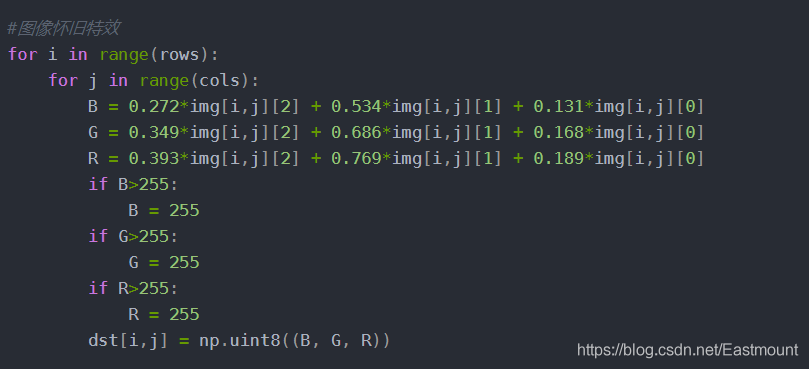
核心代碼如下:
濾鏡主要是用來實作影像的各種特殊效果,它在Photoshop中具有非常神奇的作用,濾鏡通常需要同通道、圖層等聯合使用,才能取得最佳藝術效果,本小節將講述一種基于顏色查找表(Look up Table)的濾鏡處理方法,它通過將每一個原始顏色進行轉換之后得到新的顏色,比如,原始影像的某像素點為紅色(R-255, G-0, B-0),進行轉換之后變為綠色(R-0, G-255, B-0),之后所有是紅色的地方都會被自動轉換為綠色,而顏色查找表就是將所有的顏色進行一次(矩陣)轉換,很多的濾鏡功能就是提供了這么一個轉換的矩陣,在原始色彩的基礎上進行顏色的轉換,
假設現在存在一張新的濾鏡顏色查找表,如下圖所示,它是一張512×512大小,包含各像素顏色分布的影像,該圖片建議大家去我github下載,

濾鏡特效實作的Python代碼如下所示,它通過自定義getBRG()函式獲取顏色查找表中映射的濾鏡顏色,再依次回圈替換各顏色,
經典代碼:
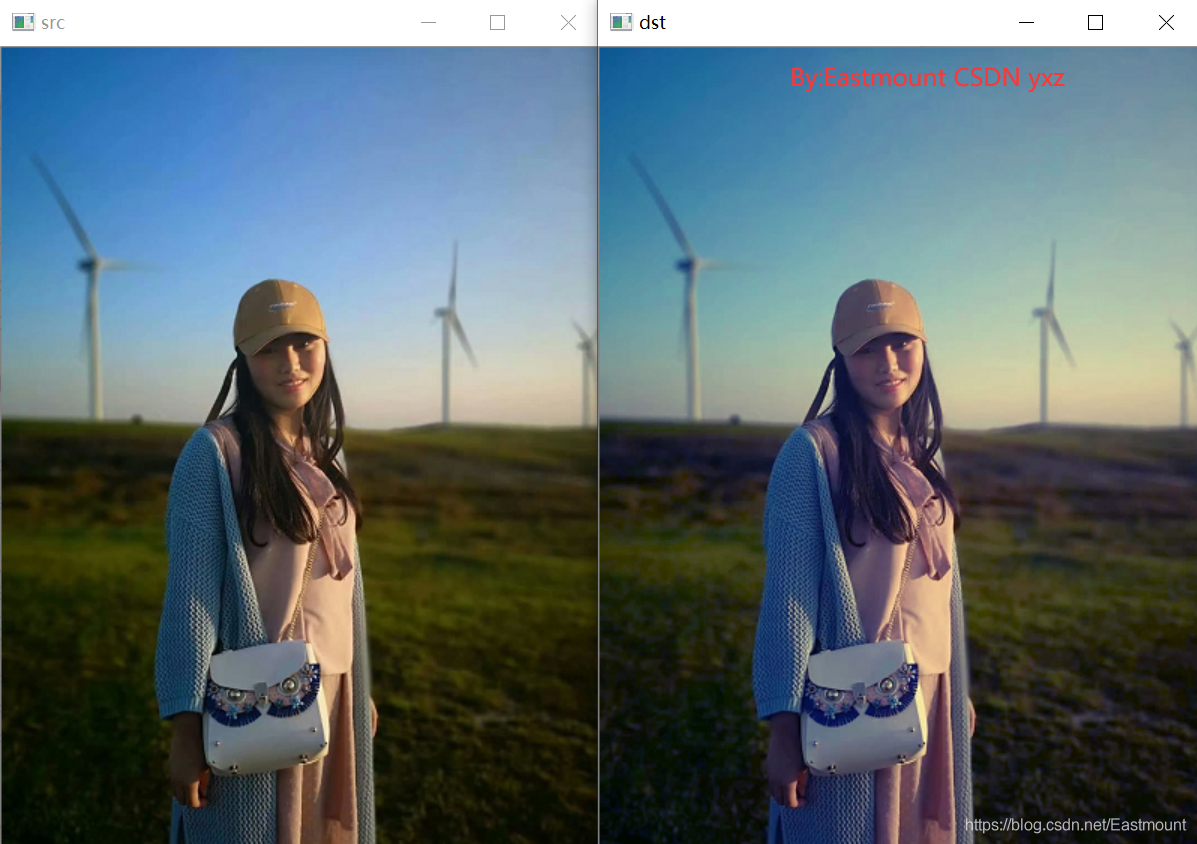
(1) 影像流年特效
#coding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import math
import numpy as np
#讀取原始影像
img = cv2.imread('nv.png')
#獲取影像行和列
rows, cols = img.shape[:2]
#新建目標影像
dst = np.zeros((rows, cols, 3), dtype="uint8")
#影像流年特效
for i in range(rows):
for j in range(cols):
#B通道的數值開平方乘以引數12
B = math.sqrt(img[i,j][0]) * 12
G = img[i,j][1]
R = img[i,j][2]
if B>255:
B = 255
dst[i,j] = np.uint8((B, G, R))
#顯示影像
cv2.imshow('src', img)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
輸出結果如下圖所示:
(2) 影像濾鏡特效
#coding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import math
import numpy as np
#獲取濾鏡顏色
def getBGR(img, table, i, j):
#獲取影像顏色
b, g, r = img[i][j]
#計算標準顏色表中顏色的位置坐標
x = int(g/4 + int(b/32) * 64)
y = int(r/4 + int((b%32) / 4) * 64)
#回傳濾鏡顏色表中對應的顏色
return lj_map[x][y]
#讀取原始影像
img = cv2.imread('nv.png')
lj_map = cv2.imread('table.png')
#獲取影像行和列
rows, cols = img.shape[:2]
#新建目標影像
dst = np.zeros((rows, cols, 3), dtype="uint8")
#回圈設定濾鏡顏色
for i in range(rows):
for j in range(cols):
dst[i][j] = getBGR(img, lj_map, i, j)
#顯示影像
cv2.imshow('src', img)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
女神照片的輸出結果如下圖所示:
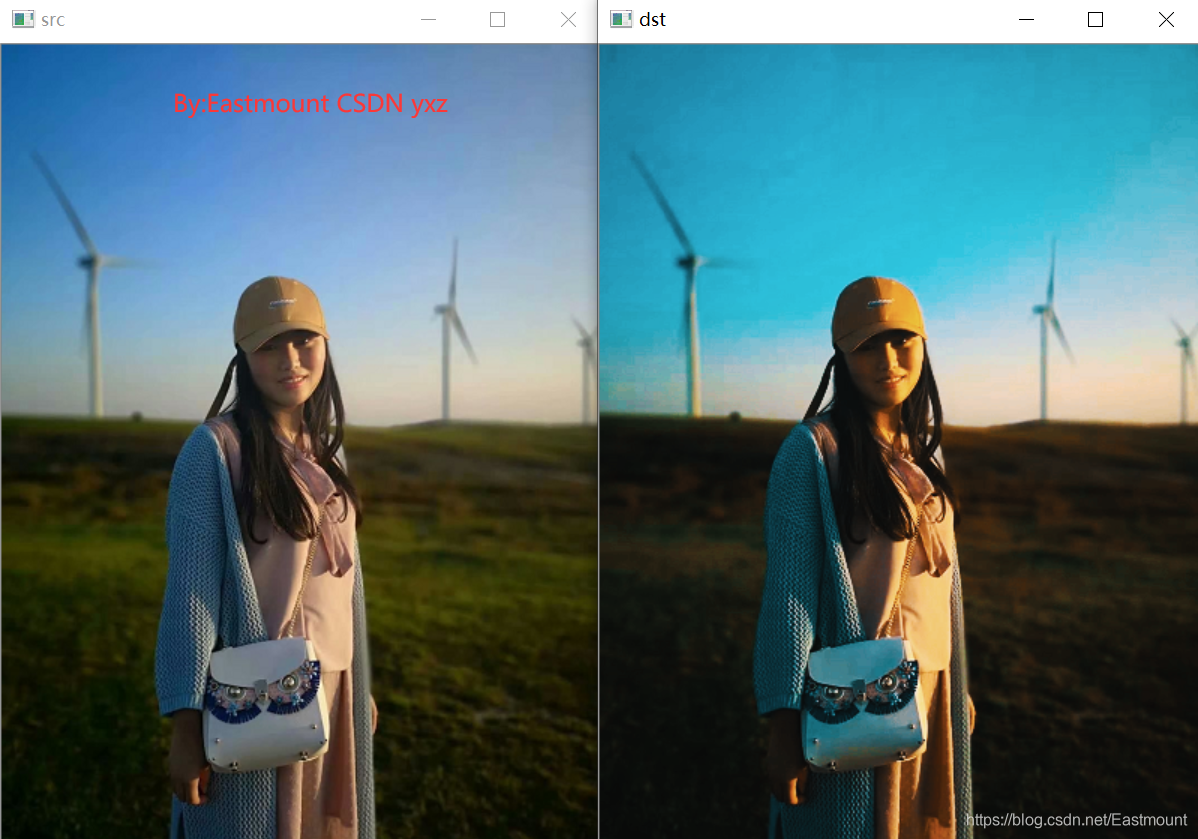
(3) 影像素描特效
#coding:utf-8
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
def dodgeNaive(image, mask):
# determine the shape of the input image
width, height = image.shape[:2]
# prepare output argument with same size as image
blend = np.zeros((width, height), np.uint8)
for col in range(width):
for row in range(height):
# do for every pixel
if mask[col, row] == 255:
# avoid division by zero
blend[col, row] = 255
else:
# shift image pixel value by 8 bits
# divide by the inverse of the mask
tmp = (image[col, row] << 8) / (255 - mask)
# print('tmp={}'.format(tmp.shape))
# make sure resulting value stays within bounds
if tmp.any() > 255:
tmp = 255
blend[col, row] = tmp
return blend
def dodgeV2(image, mask):
return cv2.divide(image, 255 - mask, scale=256)
def burnV2(image, mask):
return 255 - cv2.divide(255 - image, 255 - mask, scale=256)
def rgb_to_sketch(src_image_name, dst_image_name):
img_rgb = cv2.imread(src_image_name)
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
img_gray_inv = 255 - img_gray
img_blur = cv2.GaussianBlur(img_gray_inv, ksize=(21, 21),
sigmaX=0, sigmaY=0)
img_blend = dodgeV2(img_gray, img_blur)
cv2.imshow('original', img_rgb)
cv2.imshow('gray', img_gray)
cv2.imshow('gray_inv', img_gray_inv)
cv2.imshow('gray_blur', img_blur)
cv2.imshow("pencil sketch", img_blend)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite(dst_image_name, img_blend)
if __name__ == '__main__':
src_image_name = 'nv.png'
dst_image_name = 'sketch_example.jpg'
rgb_to_sketch(src_image_name, dst_image_name)
女神照片的輸出結果如下圖所示:
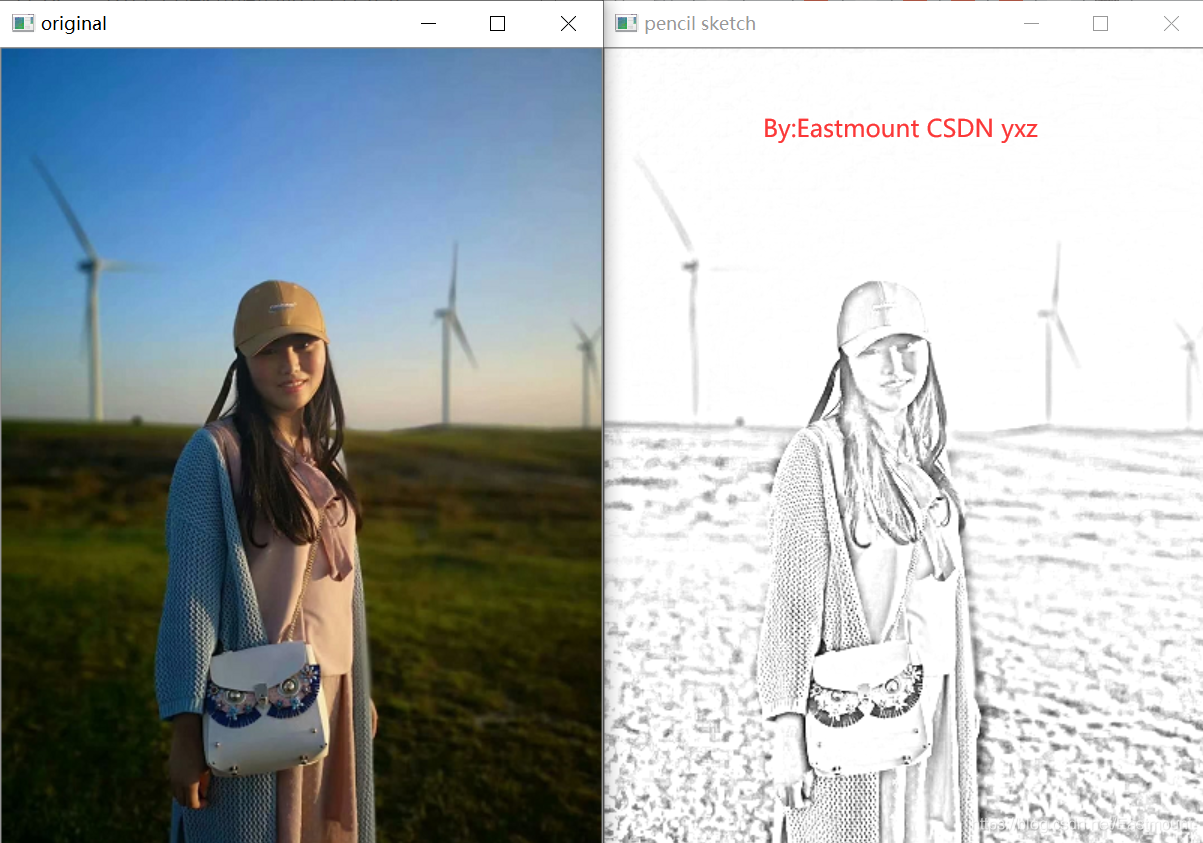
2.Python影像分割
推薦文章:
- [Python影像處理] 四十.全網首發Python影像分割萬字詳解(閾值分割、邊緣分割、紋理分割、分水嶺演算法、K-Means分割、漫水填充分割、區域定位)
核心內容:
- 影像分割概述
- 基于閾值的影像分割
–ret,thresh1=cv2.threshold(grayImage,127,255,cv2.THRESH_BINARY) - 基于邊緣檢測的影像分割
–Sobel = cv2.addWeighted(absX, 0.5, absY, 0.5, 0) - 基于紋理背景的影像分割
–mask, bgdModel, fgdModel = grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) - 基于K-Means聚類的區域分割
–retval, bestLabels, centers = kmeans(data, K, bestLabels, criteria, attempts, flags[, centers]) - 基于均值漂移演算法的影像分割
–dst = pyrMeanShiftFiltering(src, sp, sr[, dst[, maxLevel[, termcrit]]]) - 基于分水嶺演算法的影像分割
–markers = watershed(image, markers) - 影像漫水填充分割
–floodFill(image, mask, seedPoint, newVal[, loDiff[, upDiff[, flags]]]) - 文字區域定位及提取案例
– 灰度轉換、影像銳化、閾值處理、膨脹腐蝕
– findContours()函式尋找文字輪廓
經典知識:
影像分割(Image Segmentation)技術是計算機視覺領域的重要研究方向,是影像語意理解和影像識別的重要一環,它是指將影像分割成若干具有相似性質的區域的程序,研究方法包括基于閾值的分割方法、基于區域的分割方法、基于邊緣的分割方法和基于特定理論的分割方法(含圖論、聚類、深度語意等),該技術廣泛應用于場景物體分割、人體背景分割、三維重建、車牌識別、人臉識別、無人駕駛、增強現實等行業,如圖1所示,它將鮮花顏色劃分為四個層級,

影像分割的目標是根據影像中的物體將影像的像素分類,并提取感興趣的目標,從數學角度來看,影像分割是將數字影像劃分成互不相交的區域的程序,影像分割的程序也是一個標記程序,即把屬于同一區域的像索賦予相同的編號,
經典案例:
(1)基于紋理背景的影像分割
# -*- coding: utf-8 -*-
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
#讀取影像
img = cv2.imread('nv.png')
#灰度化處理影像
grayImage = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#設定掩碼、fgbModel、bgModel
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1,65), np.float64)
fgdModel = np.zeros((1,65), np.float64)
#矩形坐標
rect = (100, 100, 500, 800)
#影像分割
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5,
cv2.GC_INIT_WITH_RECT)
#設定新掩碼:0和2做背景
mask2 = np.where((mask==2)|(mask==0), 0, 1).astype('uint8')
#設定字體
matplotlib.rcParams['font.sans-serif']=['SimHei']
#顯示原圖
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.subplot(1,2,1)
plt.imshow(img)
plt.title(u'(a)原始影像')
plt.xticks([]), plt.yticks([])
#使用蒙板來獲取前景區域
img = img*mask2[:, :, np.newaxis]
plt.subplot(1,2,2)
plt.imshow(img)
plt.title(u'(b)目標影像')
plt.colorbar()
plt.xticks([]), plt.yticks([])
plt.show()
輸出結果如下圖所示:
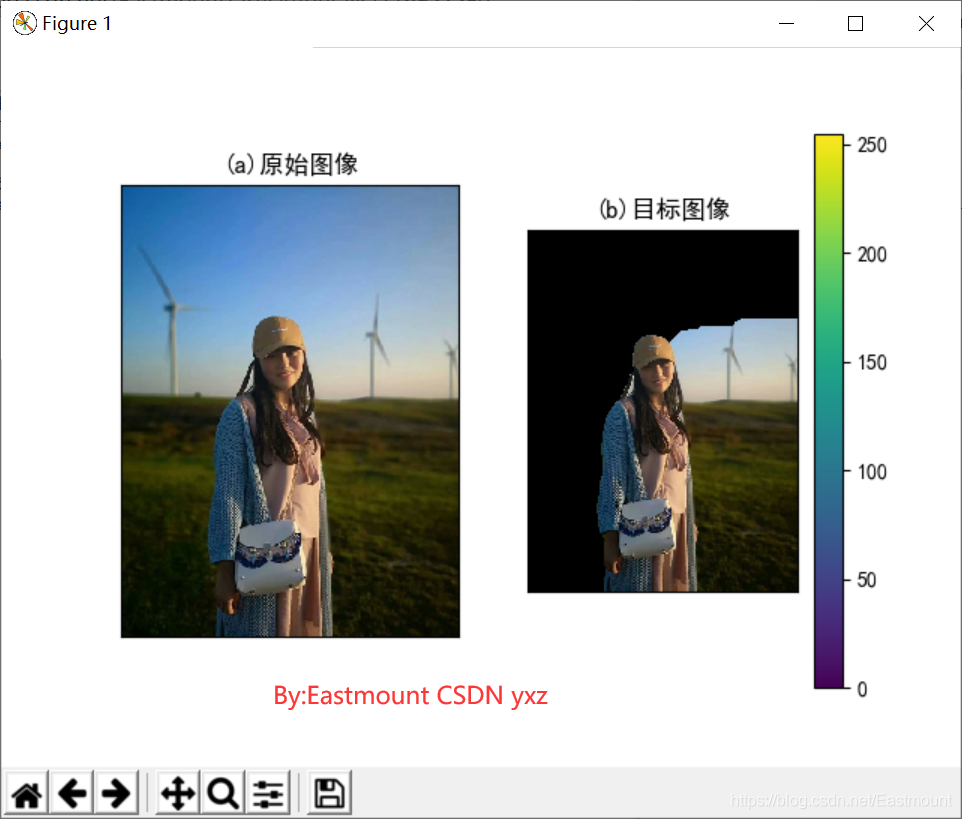
(2)基于均值漂移演算法的影像分割
# -*- coding: utf-8 -*-
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
import matplotlib.pyplot as plt
#讀取原始影像灰度顏色
img = cv2.imread('scenery.png')
#獲取影像行和列
rows, cols = img.shape[:2]
#mask必須行和列都加2且必須為uint8單通道陣列
mask = np.zeros([rows+2, cols+2], np.uint8)
spatialRad = 100 #空間視窗大小
colorRad = 100 #色彩視窗大小
maxPyrLevel = 2 #金字塔層數
#影像均值漂移分割
dst = cv2.pyrMeanShiftFiltering( img, spatialRad, colorRad, maxPyrLevel)
#影像漫水填充處理
cv2.floodFill(dst, mask, (30, 30), (0, 255, 255),
(100, 100, 100), (50, 50, 50),
cv2.FLOODFILL_FIXED_RANGE)
#顯示影像
cv2.imshow('src', img)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
輸出結果如下圖所示:
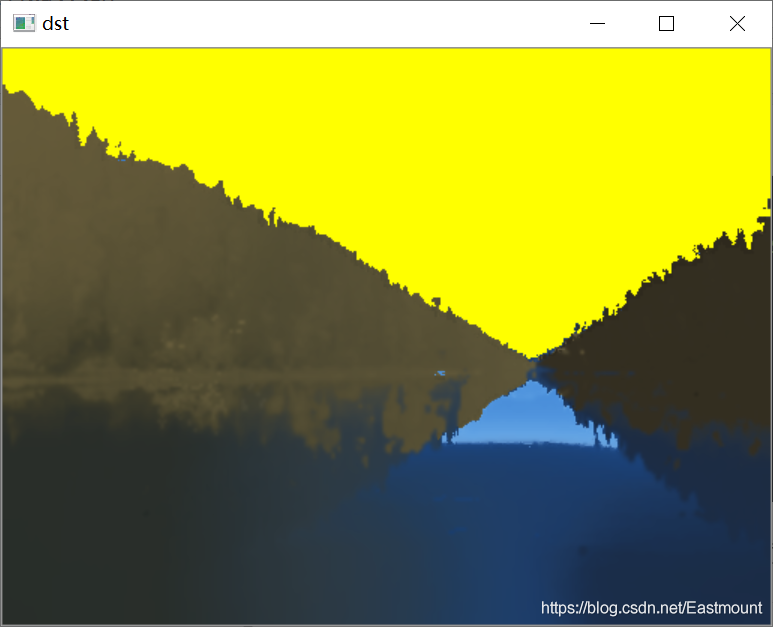
(3)影像漫水填充分割
# -*- coding: utf-8 -*-
#By:Eastmount CSDN 2021-08-20
import cv2
import random
import sys
import numpy as np
#使用說明 點擊滑鼠選擇種子點
help_message = '''USAGE: floodfill.py [<image>]
Click on the image to set seed point
Keys:
f - toggle floating range
c - toggle 4/8 connectivity
ESC - exit
'''
if __name__ == '__main__':
#輸出提示文本
print(help_message)
#讀取原始影像
img = cv2.imread('scenery.png')
#獲取影像高和寬
h, w = img.shape[:2]
#設定掩碼 長和寬都比輸入影像多兩個像素點
mask = np.zeros((h+2, w+2), np.uint8)
#設定種子節點和4鄰接
seed_pt = None
fixed_range = True
connectivity = 4
#影像漫水填充分割更新函式
def update(dummy=None):
if seed_pt is None:
cv2.imshow('floodfill', img)
return
#建立影像副本并漫水填充
flooded = img.copy()
mask[:] = 0 #掩碼初始為全0
lo = cv2.getTrackbarPos('lo', 'floodfill') #觀察點像素鄰域負差最大值
hi = cv2.getTrackbarPos('hi', 'floodfill') #觀察點像素鄰域正差最大值
print('lo=', lo, 'hi=', hi)
#低位位元包含連通值 4 (預設) 或 8
flags = connectivity
#考慮當前象素與種子象素之間的差(高位元也可以為0)
if fixed_range:
flags |= cv2.FLOODFILL_FIXED_RANGE
#以白色進行漫水填充
cv2.floodFill(flooded, mask, seed_pt,
(random.randint(0,255), random.randint(0,255),
random.randint(0,255)), (lo,)*3, (hi,)*3, flags)
#選定基準點用紅色圓點標出
cv2.circle(flooded, seed_pt, 2, (0, 0, 255), -1)
print("send_pt=", seed_pt)
#顯示影像
cv2.imshow('floodfill', flooded)
#滑鼠回應函式
def onmouse(event, x, y, flags, param):
global seed_pt #基準點
#滑鼠左鍵回應選擇漫水填充基準點
if flags & cv2.EVENT_FLAG_LBUTTON:
seed_pt = x, y
update()
#執行影像漫水填充分割更新操作
update()
#滑鼠更新操作
cv2.setMouseCallback('floodfill', onm ouse)
#設定進度條
cv2.createTrackbar('lo', 'floodfill', 20, 255, update)
cv2.createTrackbar('hi', 'floodfill', 20, 255, update)
#按鍵回應操作
while True:
ch = 0xFF & cv2.waitKey()
#退出
if ch == 27:
break
#選定時flags的高位位元位0
#此時鄰域的選定為當前像素與相鄰像素的差, 聯通區域會很大
if ch == ord('f'):
fixed_range = not fixed_range
print('using %s range' % ('floating', 'fixed')[fixed_range])
update()
#選擇4方向或則8方向種子擴散
if ch == ord('c'):
connectivity = 12-connectivity
print('connectivity =', connectivity)
update()
cv2.destroyAllWindows()
輸出結果如下圖所示:
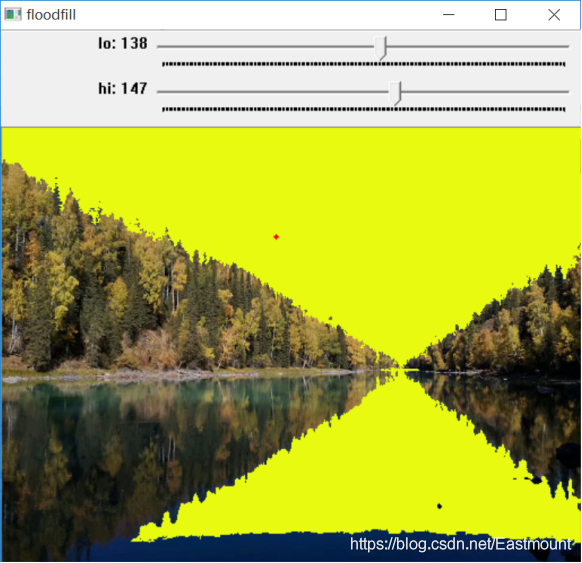
3.Python傅里葉變換與霍夫變化
推薦文章:
- [Python影像處理] 三十二.傅里葉變換(影像去噪)與霍夫變換(特征識別)萬字詳細總結
核心內容:
- 影像傅里葉變換概述
- 影像傅里葉變換操作
– Numpy實作傅里葉變換
fft2(a, s=None, axes=(-2, -1), norm=None)
– Numpy實作傅里葉逆變換
numpy.fft.ifft2(a, n=None, axis=-1, norm=None)
– OpenCV實作傅里葉變換
dst = cv2.dft(src, dst=None, flags=None, nonzeroRows=None)
– OpenCV實作傅里葉逆變換
dst = cv2.idft(src[, dst[, flags[, nonzeroRows]]]) - 基于傅里葉變換的高通濾波和低通濾波
– 高通濾波器
– 低通濾波器 - 影像霍夫變換概述
- 影像霍夫線變換操作
–lines = HoughLines(image, rho, theta, threshold[, lines[, srn[, stn[, min_theta[, max_theta]]]]])
–lines = HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) - 影像霍夫圓變換操作
–circles = HoughCircles(image, method, dp, minDist[, circles[, param1[, param2[, minRadius[, maxRadius]]]]])
經典知識:
傅里葉變換(Fourier Transform,簡稱FT)常用于數字信號處理,它的目的是將時間域上的信號轉變為頻率域上的信號,隨著域的不同,對同一個事物的了解角度也隨之改變,因此在時域中某些不好處理的地方,在頻域就可以較為簡單的處理,同時,可以從頻域里發現一些原先不易察覺的特征,傅里葉定理指出“任何連續周期信號都可以表示成(或者無限逼近)一系列正弦信號的疊加,”
傅里葉公式如下,其中w表示頻率,t表示時間,為復變函式,它將時間域的函式表示為頻率域的函式f(t)的積分,
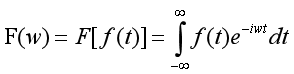
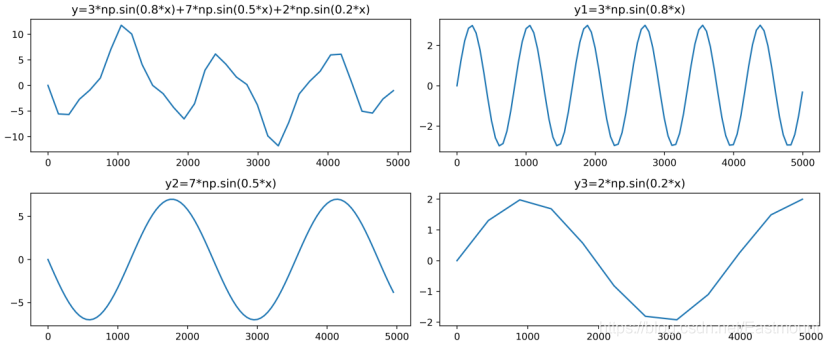
傅里葉變換認為一個周期函式(信號)包含多個頻率分量,任意函式(信號)f(t)可通過多個周期函式(或基函式)相加合成,從物理角度理解,傅里葉變換是以一組特殊的函式(三角函式)為正交基,對原函式進行線性變換,物理意義便是原函式在各組基函式的投影,如上圖所示,它是由三條正弦曲線組合成,其函式如下,
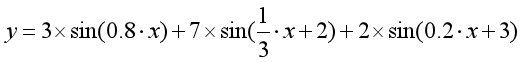
霍夫變換(Hough Transform)是一種特征檢測(Feature Extraction),被廣泛應用在影像分析、計算機視覺以及數位影像處理,霍夫變換是在1959年由氣泡室(Bubble Chamber)照片的機器分析而發明,發明者Paul Hough在1962年獲得美國專利,現在廣泛使用的霍夫變換是由Richard Duda和Peter Hart在1972年發明,并稱之為廣義霍夫變換,經典的霍夫變換是檢測圖片中的直線,之后,霍夫變換不僅能識別直線,也能夠識別任何形狀,常見的有圓形、橢圓形,
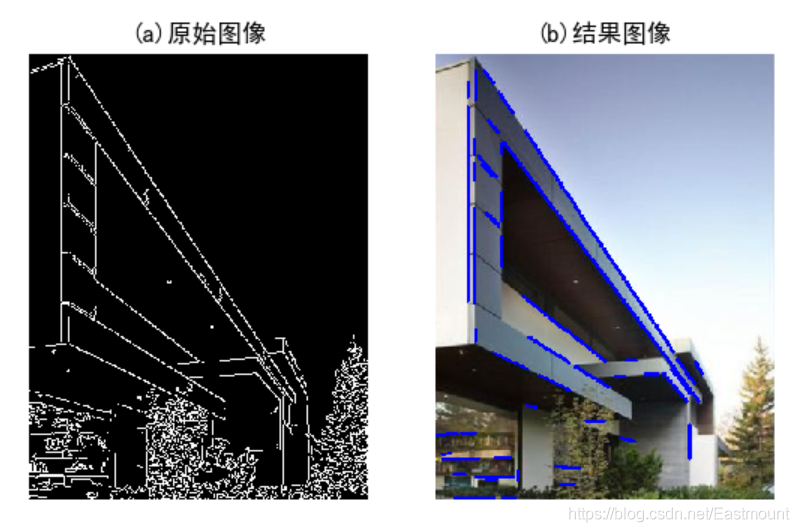
經典示例:
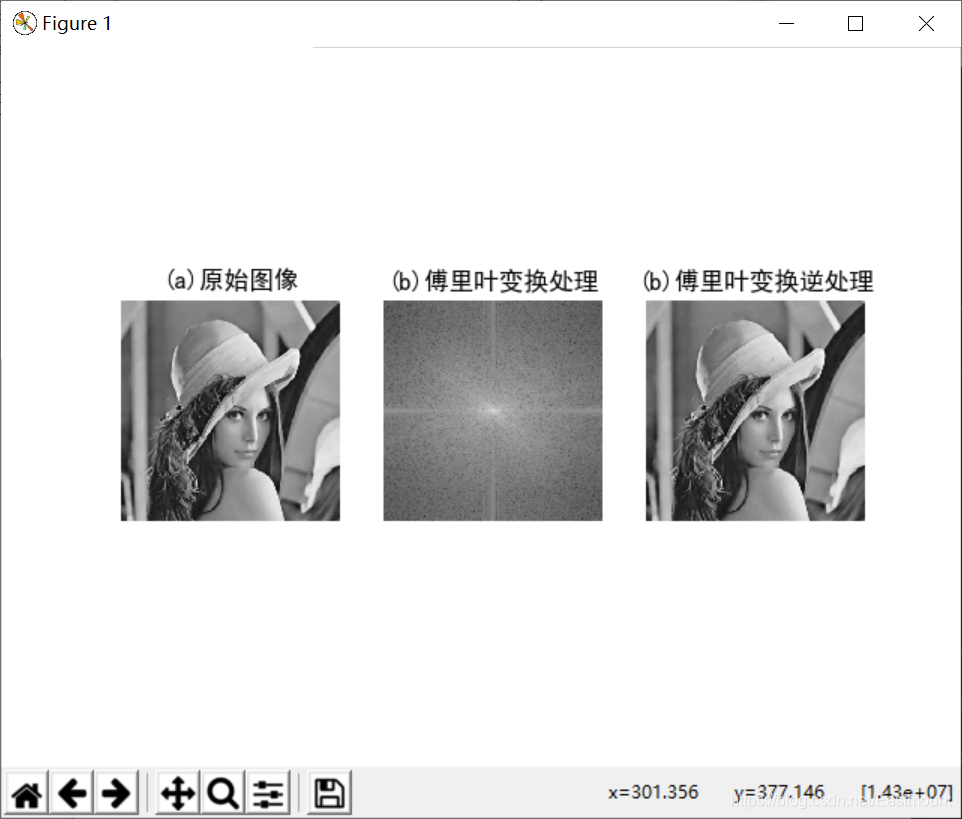
(1)傅里葉變換與逆變換
# -*- coding: utf-8 -*-
#By:Eastmount CSDN 2021-08-20
import numpy as np
import cv2
from matplotlib import pyplot as plt
import matplotlib
#讀取影像
img = cv2.imread('Lena.png', 0)
#傅里葉變換
dft = cv2.dft(np.float32(img), flags = cv2.DFT_COMPLEX_OUTPUT)
dftshift = np.fft.fftshift(dft)
res1= 20*np.log(cv2.magnitude(dftshift[:,:,0], dftshift[:,:,1]))
#傅里葉逆變換
ishift = np.fft.ifftshift(dftshift)
iimg = cv2.idft(ishift)
res2 = cv2.magnitude(iimg[:,:,0], iimg[:,:,1])
#設定字體
matplotlib.rcParams['font.sans-serif']=['SimHei']
#顯示影像
plt.subplot(131), plt.imshow(img, 'gray'), plt.title(u'(a)原始影像')
plt.axis('off')
plt.subplot(132), plt.imshow(res1, 'gray'), plt.title(u'(b)傅里葉變換處理')
plt.axis('off')
plt.subplot(133), plt.imshow(res2, 'gray'), plt.title(u'(b)傅里葉變換逆處理')
plt.axis('off')
plt.show()
輸出結果如下圖所示:
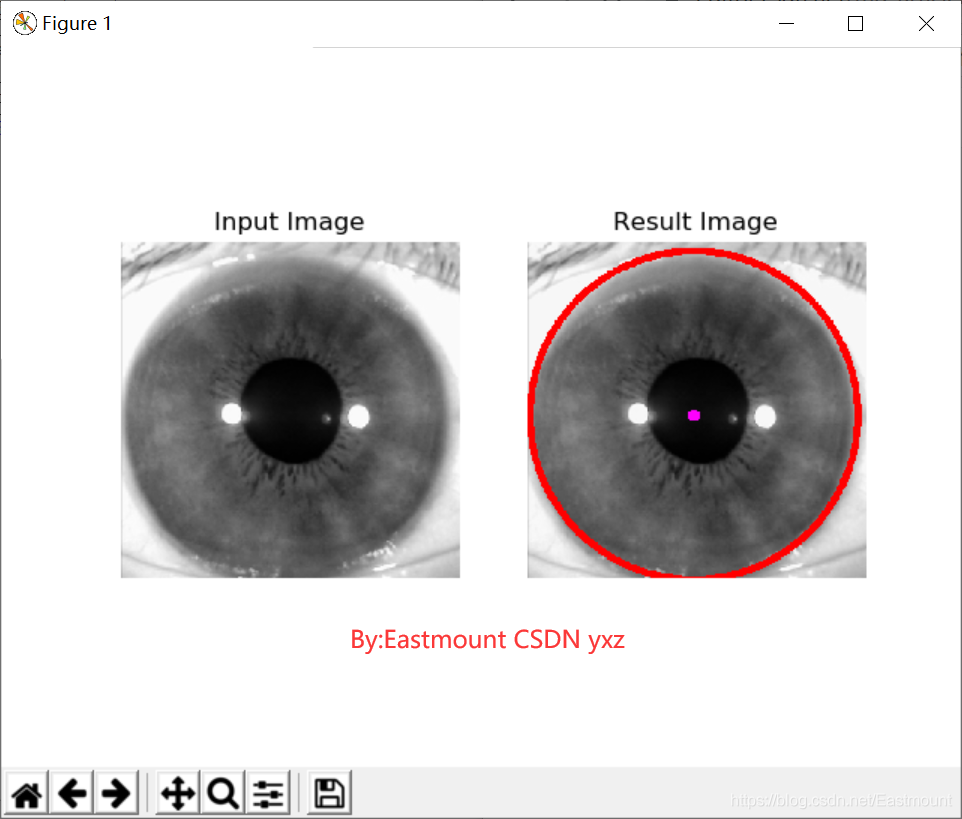
(2)霍夫變換識別圓
# -*- coding: utf-8 -*-
#By:Eastmount CSDN 2021-08-20
import cv2
import numpy as np
from matplotlib import pyplot as plt
#讀取影像
img = cv2.imread('eyes.png')
#灰度轉換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#顯示原始影像
plt.subplot(121), plt.imshow(gray, 'gray'), plt.title('Input Image')
plt.axis('off')
#霍夫變換檢測圓
circles1 = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT, 1, 20,
param1=100, param2=30,
minRadius=160, maxRadius=200)
print(circles1)
#提取為二維
circles = circles1[0, :, :]
#四舍五入取整
circles = np.uint16(np.around(circles))
#繪制圓
for i in circles[:]:
cv2.circle(img, (i[0],i[1]), i[2], (255,0,0), 5) #畫圓
cv2.circle(img, (i[0],i[1]), 2, (255,0,255), 8) #畫圓心
#顯示處理影像
plt.subplot(122), plt.imshow(img), plt.title('Result Image')
plt.axis('off')
plt.show()
輸出結果如下圖所示:
4.Python影像分類
推薦文章:
- [Python影像處理] 三十九.Python影像分類萬字詳解(貝葉斯影像分類、KNN影像分類、DNN影像分類)
核心內容:
- 影像分類概述
- 常見的分類演算法
– 樸素貝葉斯分類演算法
– KNN分類演算法
– SVM分類演算法
– 隨機森林分類演算法
– 神經網路分類演算法 - 基于樸素貝葉斯演算法的影像分類
- 基于KNN演算法的影像分類
- 基于神經網路演算法的影像分類
經典知識:
影像分類(Image Classification)是對影像內容進行分類的問題,它利用計算機對影像進行定量分析,把影像或影像中的區域劃分為若干個類別,以代替人的視覺判斷,
影像分類的傳統方法是特征描述及檢測,這類傳統方法可能對于一些簡單的影像分類是有效的,但由于實際情況非常復雜,傳統的分類方法不堪重負,現在,廣泛使用機器學習和深度學習的方法來處理影像分類問題,其主要任務是給定一堆輸入圖片,將其指派到一個已知的混合類別中的某個標簽,
在下圖中,影像分類模型將獲取單個影像,并將為4個標簽{cat,dog,hat,mug}分配對應的概率{0.6, 0.3, 0.05, 0.05},其中0.6表示影像標簽為貓的概率,其余類比,
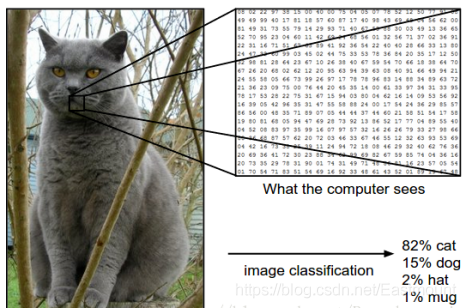
那么,如何撰寫一個影像分類的演算法呢?又怎么從眾多影像中識別出貓呢?
這里所采取的方法和教育小孩看圖識物類似,給出很多影像資料,讓模型不斷去學習每個類的特征,在訓練之前,首先需要對訓練集的影像進行分類標注,如圖2所示,包括cat、dog、mug和hat四類,在實際工程中,可能有成千上萬類別的物體,每個類別都會有上百萬張影像,

影像分類是輸入一堆影像的像素值陣列,然后給它分配一個分類標簽,通過訓練學習來建立演算法模型,接著使用該模型進行影像分類預測,具體流程如下:
- 輸入:輸入包含N個影像的集合,每個影像的標簽是K種分類標簽中的一種,這個集合稱為訓練集;
- 學習:第二步任務是使用訓練集來學習每個類的特征,構建訓練分類器或者分類模型;
- 評價:通過分類器來預測新輸入影像的分類標簽,并以此來評價分類器的質量,通過分類器預測的標簽和影像真正的分類標簽對比,從而評價分類演算法的好壞,如果分類器預測的分類標簽和影像真正的分類標簽一致,表示預測正確,否則預測錯誤,
經典示例:
# -*- coding: utf-8 -*-
# By: Eastmount CSDN 2021-08-20
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
#----------------------------------------------------------------------------------
# 第一步 切分訓練集和測驗集
#----------------------------------------------------------------------------------
X = [] #定義影像名稱
Y = [] #定義影像分類類標
Z = [] #定義影像像素
for i in range(0, 10):
#遍歷檔案夾,讀取圖片
for f in os.listdir("photo/%s" % i):
#獲取影像名稱
X.append("photo//" +str(i) + "//" + str(f))
#獲取影像類標即為檔案夾名稱
Y.append(i)
X = np.array(X)
Y = np.array(Y)
#隨機率為100% 選取其中的30%作為測驗集
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=0.3, random_state=1)
print(len(X_train), len(X_test), len(y_train), len(y_test))
#----------------------------------------------------------------------------------
# 第二步 影像讀取及轉換為像素直方圖
#----------------------------------------------------------------------------------
#訓練集
XX_train = []
for i in X_train:
#讀取影像
#print i
image = cv2.imread(i)
#影像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#計算影像直方圖并存盤至X陣列
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_train.append(((hist/255).flatten()))
#測驗集
XX_test = []
for i in X_test:
#讀取影像
#print i
image = cv2.imread(i)
#影像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#計算影像直方圖并存盤至X陣列
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_test.append(((hist/255).flatten()))
#----------------------------------------------------------------------------------
# 第三步 基于樸素貝葉斯的影像分類處理
#----------------------------------------------------------------------------------
from sklearn.naive_bayes import BernoulliNB
clf = BernoulliNB().fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
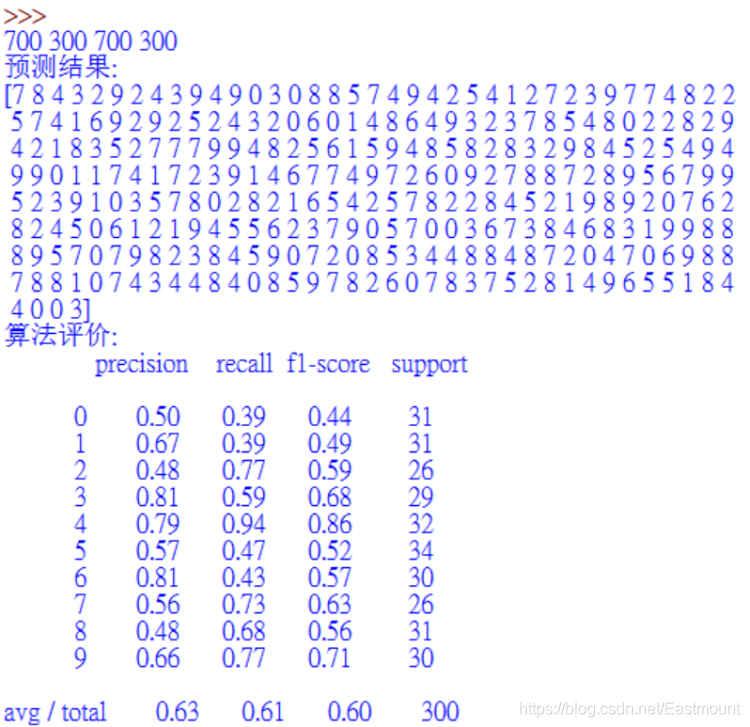
print('預測結果:')
print(predictions_labels)
print('演算法評價:')
print(classification_report(y_test, predictions_labels))
#輸出前10張圖片及預測結果
k = 0
while k<10:
#讀取影像
print(X_test[k])
image = cv2.imread(X_test[k])
print(predictions_labels[k])
#顯示影像
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
k = k + 1
實驗所采用的資料集為Sort_1000pics資料集,該資料集包含了1000張圖片,總共分為10大類,分別是人(第0類)、沙灘(第1類)、建筑(第2類)、大卡車(第3類)、恐龍(第4類)、大象(第5類)、花朵(第6類)、馬(第7類)、山峰(第8類)和食品(第9類),每類100張,如圖所示,
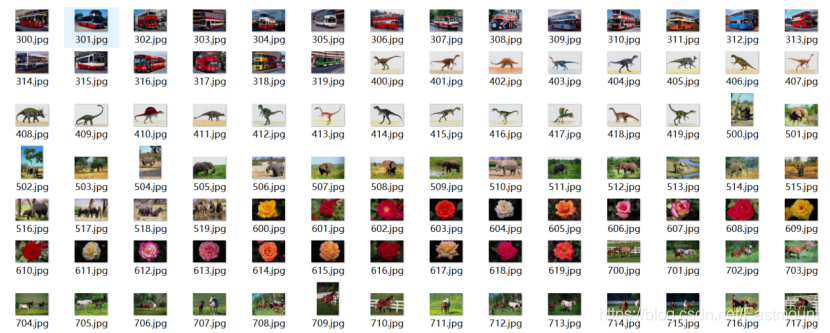
代碼中對預測集的前十張影像進行了顯示,其中“368.jpg”影像如圖所示,其分類預測的類標結果為“3”,表示第3類大卡車,預測結果正確,

使用樸素貝葉斯演算法進行影像分類實驗,最后預測的結果及演算法評價準確率(Precision)、召回率(Recall)和F值(F1-score)如圖16所示,
六.總結
寫到這里,本文就介紹完畢,如果你是一名Python初學者或想了解影像處理知識,真心推薦該系列,并且多實踐多寫代碼,最后希望文章對您有所幫助,
八月初又認識了很多朋友,也解答了許多學生和博友的問題,雖然自己技術不是很好,但真心感激這一路走來認識了許多伙伴,也享受相互交流的程序,感恩遇見,不負青春,
這半個月交流讓我印象深刻的是復旦、浙大和武大離職讀博想當老師的朋友,我們交流了許多學習心得并鼓勵前行;也有貴財計科、軟工、電商幾位學生作業的問題;以及家鄉貴財、貴大、興義師范、貴師大、貴理工選擇考研或已經讀研同學的咨詢,我們相互學習;當然還有許多創業、作業、學習或尋求正能量的交流,包括來自廣東、南航、中北、湖北工業、建筑轉NLP、安全或AI行業的博友,最讓我享受的是,許多我教過的學生或相互鼓勵前行的博友,經常祝福我們一家并保持良好的情誼,這或許就是分享的魅力,覺不亞于一次holy shit,教育的方式多種多樣,我享受這樣的交流和鼓勵方式,山川異域,攜手同行,
最后補充一句,父母能帶給孩子最好的禮物,或許就是“處于逆境時的應對能力”,希望小珞珞能堅強、健康、快樂的成長,女神也能美麗和幸福一輩子,愛你們喲,

(By:Eastmount 2021-08-20 晚上12點 http://blog.csdn.net/eastmount/ )
參考文獻:
- [1]羅子江. Python中的影像處理[M]. 北京:科學出版社, 2020.
- [2]岡薩雷斯. 數字影像處理(第3版)[M]. 北京:電子工業出版社, 2013.
- [3]阮秋琦. 數字影像處理學(第3版)[M]. 北京:電子工業出版社,2008.
- [4]Python官網. Python Software Foundation[EB/OL]. (2019-01-15). http://www.python.org.
- [5]楊秀璋, 顏娜. Python網路資料爬取及分析從入門到精通(分析篇)[M]. 北京:北京航天航空大學出版社, 2018.
- [6]毛星云, 冷雪飛. OpenCV3編程入門[M]. 北京:電子工業出版社, 2015.
- [7]Robert Laganiere. OpenCV2計算機視覺編程手冊[M]. 北京:科學出版社, 2013.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/295419.html
標籤:python