插入資料
pandas模塊沒有專門提供插入行的方法
插入資料主要是指插入一列新的資料
方法一
以賦值的方式在資料表的最右側插入列資料
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a['學號'] = ['01','02','03','04']
print(a)

方法二
用insert()函式在資料表的指定位置插入列資料
第1個引數為插入列的位置;第2個引數為插入列的列標簽;第3個引數以串列的形式給出插入列的資料,
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a.insert(0,'學號',['01','02','03','04'])
print(a)
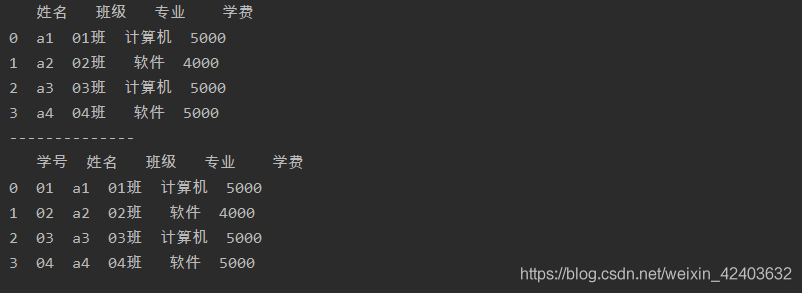
洗掉資料
洗掉列
drop()函式中直接給出要洗掉的列的列標簽就可以洗掉列
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(['專業','學費'],axis=1)
print(a)
 第1個引數以串列的形式給出要洗掉的行或列的標簽;第2個引數axis用于設定按行洗掉還是按列洗掉,設定為0表示按行洗掉(即第1個引數中給出的標簽是行標簽),設定為1表示按列洗掉(即第1個引數中給出的標簽是列標簽),
第1個引數以串列的形式給出要洗掉的行或列的標簽;第2個引數axis用于設定按行洗掉還是按列洗掉,設定為0表示按行洗掉(即第1個引數中給出的標簽是行標簽),設定為1表示按列洗掉(即第1個引數中給出的標簽是列標簽),
通過列序號來獲取列標簽,然后作為drop()函式的第1個引數使用
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(a.columns[[2,3]],axis=1)
print(a)

通過將列標簽以串列的形式傳遞給drop()函式的引數columns來洗掉列
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(columns=['班級','專業'])
print(a)

洗掉行
drop()函式,只不過需要將引數axis設定為0
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop([0,1],axis=0)
print(a)

通過行序號來獲取行標簽
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(a.index[[0,3]],axis=0)
print(a)

處理缺失值
查看缺失值
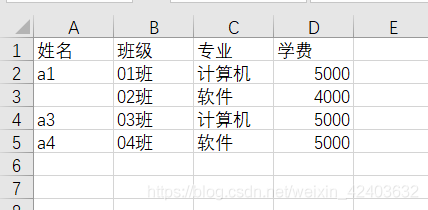
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)

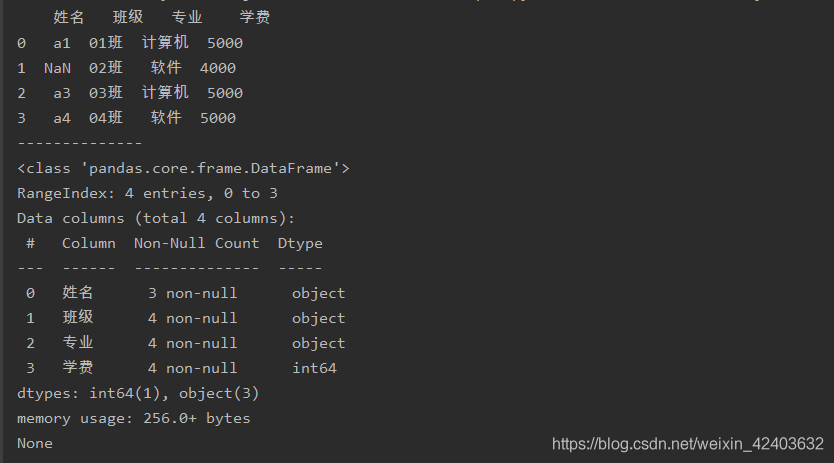
查看每一列的缺失值情況
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
print(a.info())
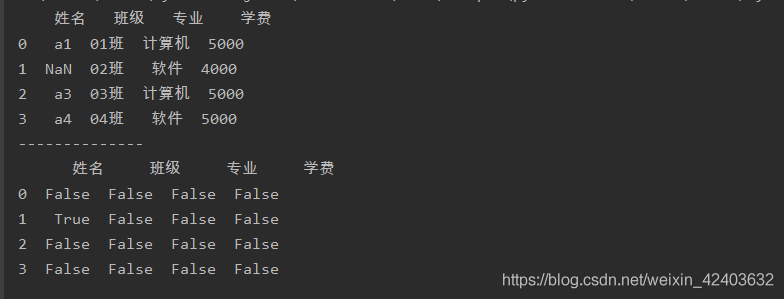
使用isnull()函式判斷資料表中的哪個值是缺失值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.isnull()
print(a)
洗掉缺失值
使用dropna()函式可以洗掉資料表中含有缺失值的行,默認只要某一行中有缺失值,該函式就把這一行洗掉
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.dropna()
print(a)
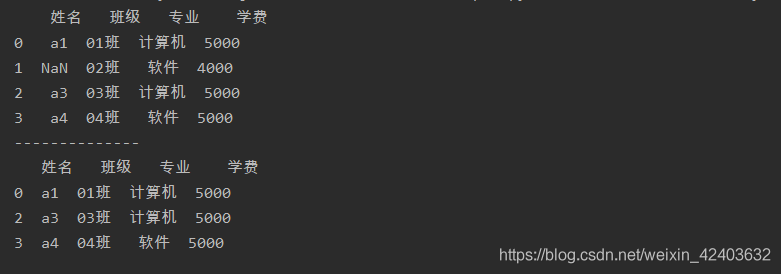
只想洗掉整行都為缺失值的行,則需要為dropna()函式設定引數how的值為’all’
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.dropna(how='all')
print(a)
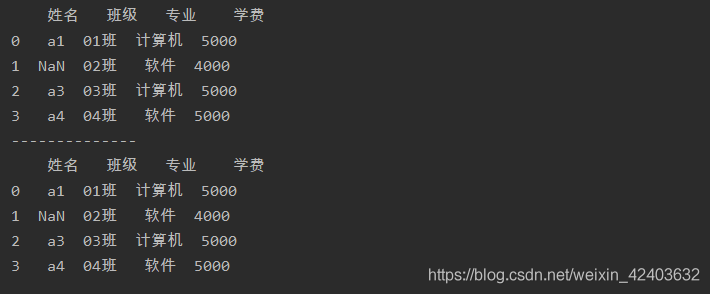
缺失值的填充
fillna()函式可以將資料表中的所有缺失值填充為指定的值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.fillna('a')
print(a)

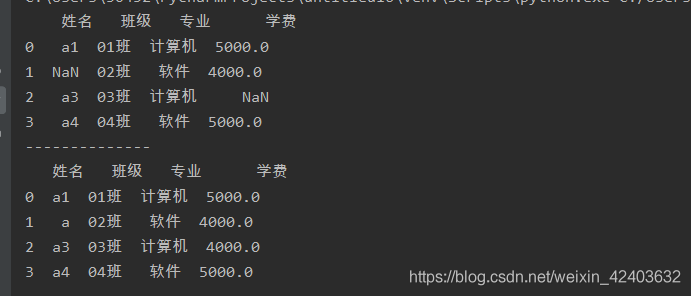
通過為fillna()函式傳入一個字典,為不同列中的缺失值設定不同的填充值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.fillna({'姓名':'a','學費':4000})
print(a)
處理重復值
洗掉重復行
drop_duplicates()函式,無須設定任何引數
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop_duplicates()
print(a)

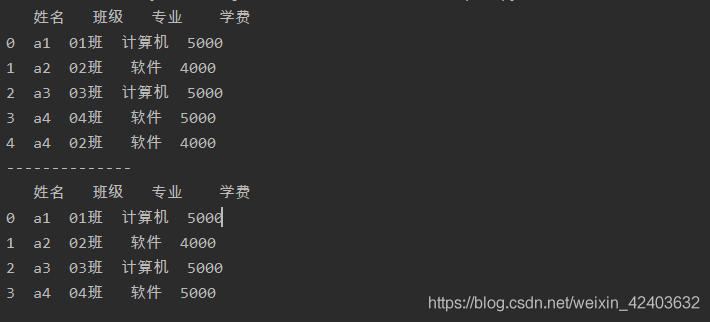
洗掉某一列中的重復值
drop_duplicates()函式添加引數subset,并設定該引數的值為要處理的列的標簽
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop_duplicates(subset='姓名')
print(a)
 keep設定為’first’,表示保留第一個重復值所在的行
keep設定為’first’,表示保留第一個重復值所在的行
keep設定為’last’ 保留最后一個重復值所在的行
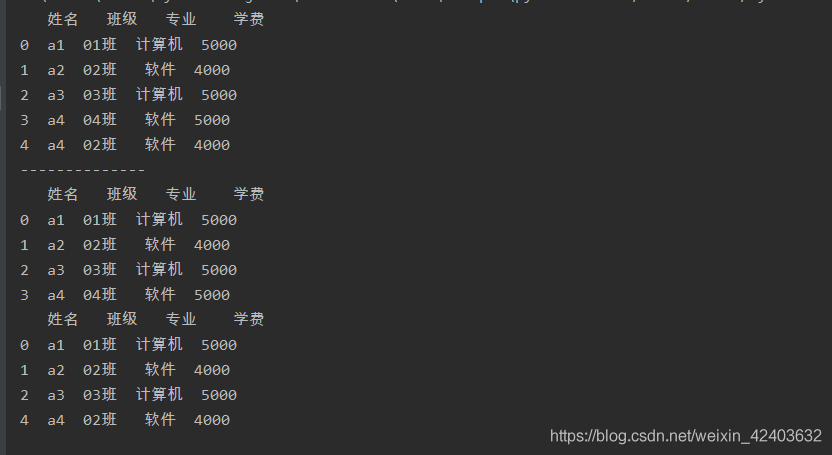
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.drop_duplicates(subset='姓名',keep='first')
print(b)
c = a.drop_duplicates(subset='姓名',keep='last')
print(c)
keep設定為False,表示把重復值一個不留地全部洗掉
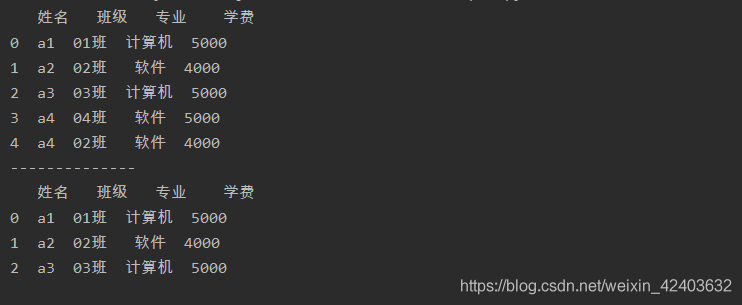
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.drop_duplicates(subset='姓名',keep=False)
print(b)
排序資料
sort_values()函式排序資料
引數ascending為True,表示升序排序
引數ascending為False,表示升序排序
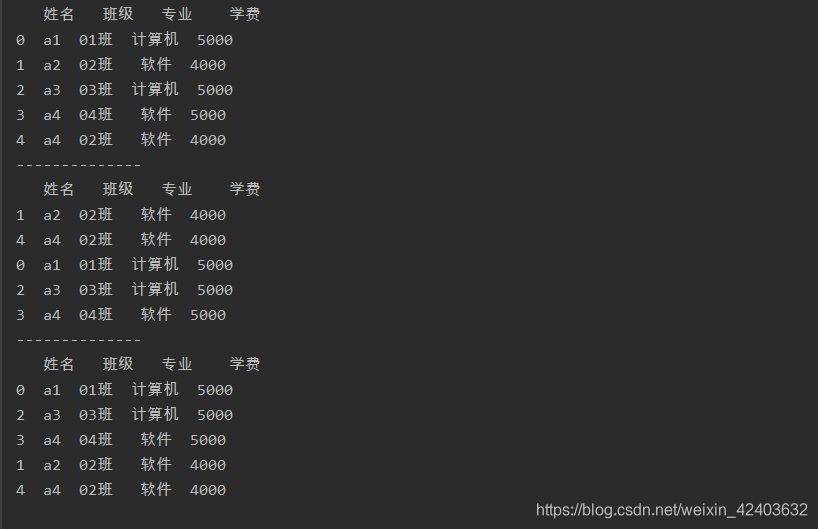
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.sort_values(by='學費',ascending=True)
print(b)
print('--------------')
c = a.sort_values(by='學費',ascending=False)
print(c)
用rank()函式獲取資料的排名
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a['學費'].rank(method = 'first',ascending=False)
print(b)
print('--------------')
c = a['學費'].rank(method = 'average',ascending=False)
print(c)
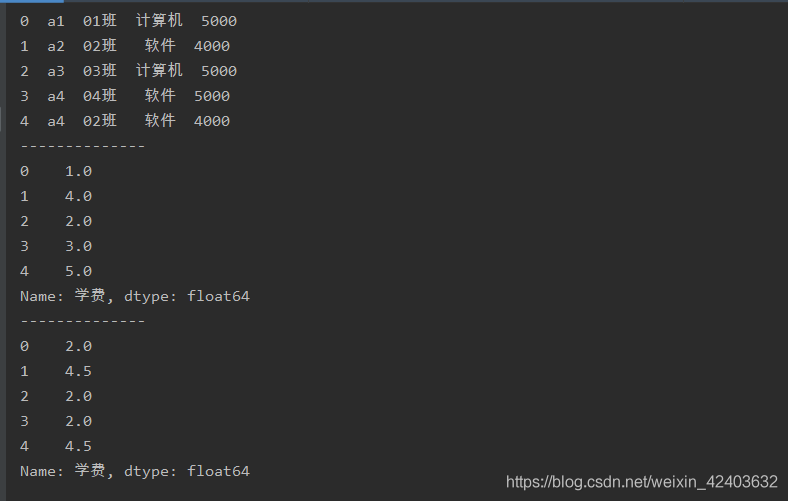
引數method設定為’first’,則表示在資料有重復值時,越先出現的資料排名越靠前
引數method設定為’average’,表示在資料有重復值時,回傳重復值的平均排名
篩選資料
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a[a['學費'] < 5000]
print(b)
print('--------------')
c = a[(a['學費'] < 5000) & (a['班級'] == '02班')]
print(c)
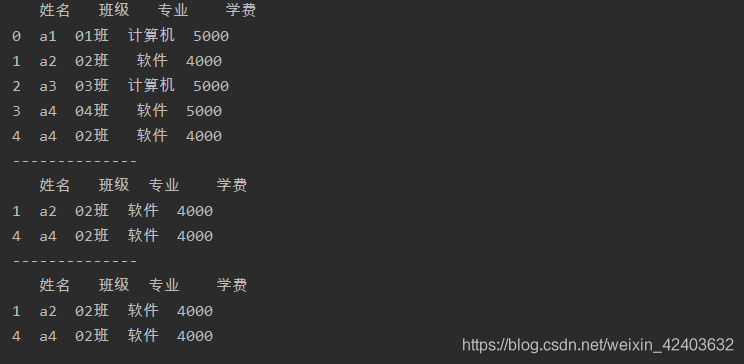
進行多條件篩選,并且這些條件之間是“邏輯與”的關系,可以用“&”符號連接多個篩選條件,
進行多條件篩選,并且這些條件之間是“邏輯或”的關系,可以用“|”符號連接多個篩選條件
注意:每個條件要分別用括號括起來,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/295649.html
標籤:python