目錄
前言
開始
分析(x0)
分析(x1)
分析(x2)
分析(x3)
分析(x4)
代碼
效果
我有話說
前言
emmmmmm, 大家好我叫善念,基本是每天更新一篇Python爬蟲實戰的文章,不過反響好像也不怎么好,都是幾百閱讀吧,我自認為我每篇文章都講解的非常仔細,大家感興趣可以去考評一下:
【Python】繞過反爬,開發音樂爬蟲,實作完美采集
【Python】純干貨,5000字的博文教你采集整站小說(附原始碼)
【Python】繞過X音_signature簽名,完美采集整站視頻、個人視頻
好與壞都能接受,精進是咱一直在做的事情
開始
目標網址
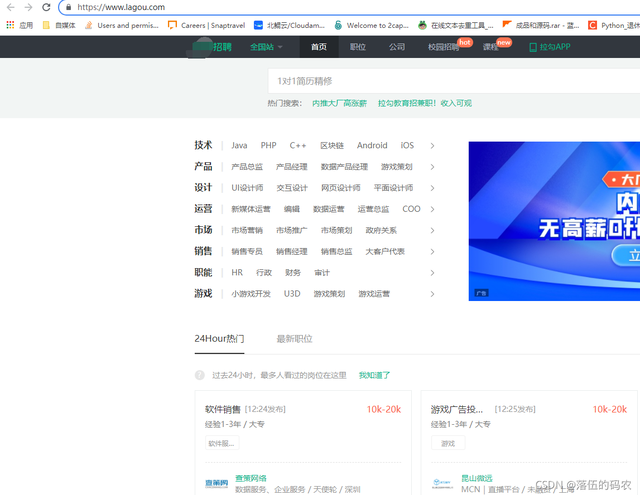
?
搜下Python相關的作業
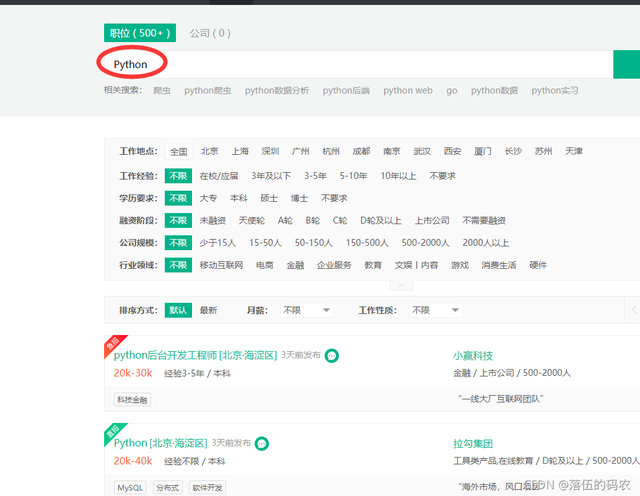
?
好了,這個頁面就是咱們想要采集的一些資料,
分析(x0)
這次直接點,查看網頁源代碼,搜一下我們需要采集的內容,看下源代碼中是否有咱們需要的資料:
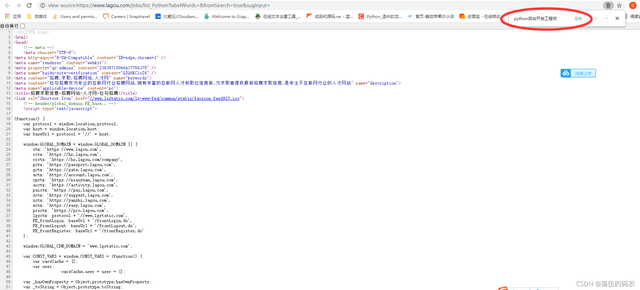
?
顯示的結果為0,也就是說資料不在咱們的網頁源代碼中,
但是它是在咱們的element網頁元素中的,這就是我反復強調的:網頁源代碼才是服務器傳給瀏覽器的原始資料,而網頁元素是網頁源代碼通過瀏覽器渲染后的資料(可能瀏覽器會執行某些源代碼中的JavaScript腳本而實作的效果)
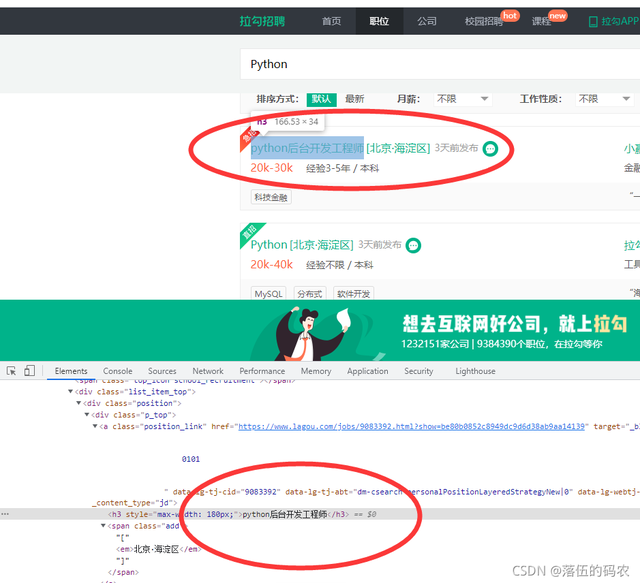
?
分析(x1)
既然網頁源代碼中沒有,元素中有,那么我們可以用selenium去進行一個資料采集,因為selenium采集的資料就是元素中的資料,但是缺點就是采集的速度慢,
不想速度慢,就繼續去分析,咱們抓一下包看看是不是瀏覽器執行了網頁原始碼中的JavaScript腳本從而呼叫了某個介面api生成了咱們需要的資料,重繪當前頁面抓包:
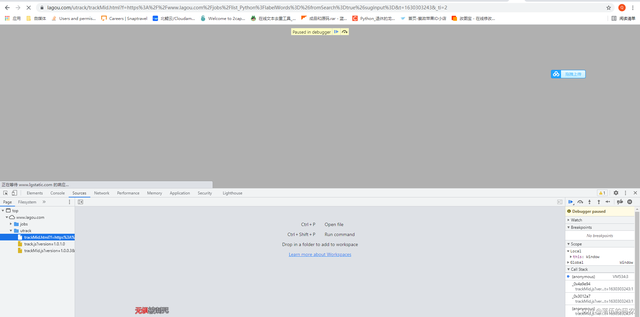
?
嘿嘿,可以看到出現了禁止除錯啊,開發人員寫了個JavaScript陳述句防止咱們除錯怎么辦?
點一下向右的箭頭,打開無視斷點,然后再點一下運行即可,
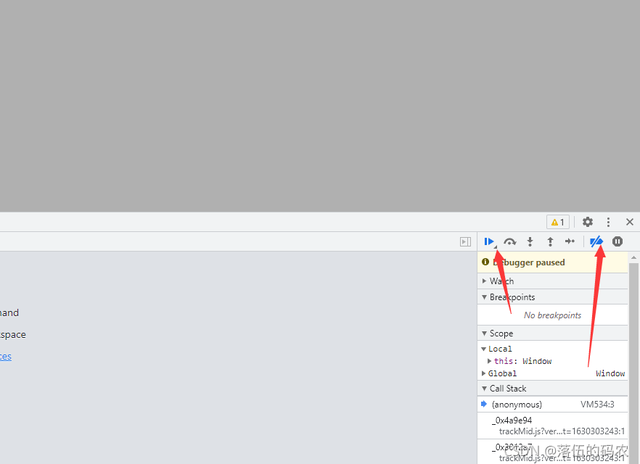
?
emmmmm看下抓到的資料
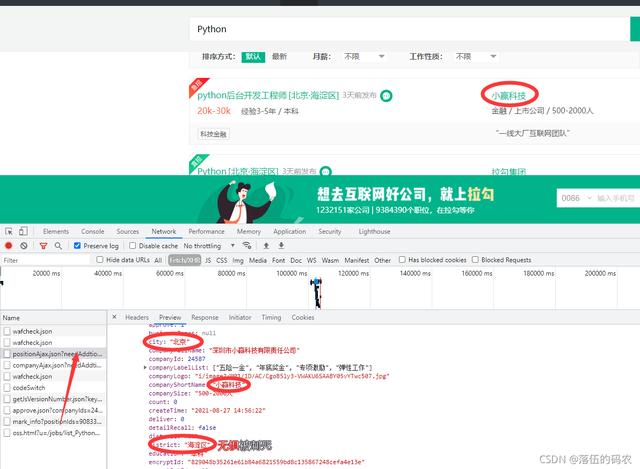
?
已經確認就是這個包了,然后咱們分析下這個請求

?
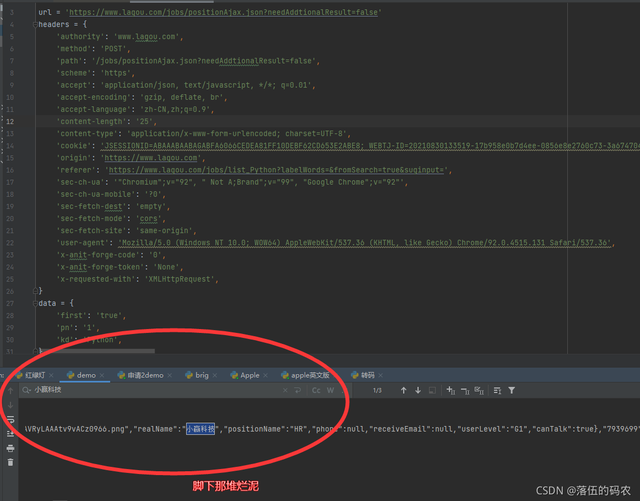
post請求,然后有這么三個引數:
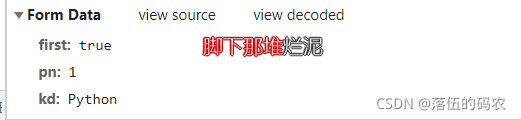
?
first不知道什么意思,pn為1(這是第一頁)kd為Python(搜的關鍵詞為Python),
說明說明?只要我們請求這個鏈接就可以得到想要的資料咯!
?
這里千萬注意,服務器會檢測cookies, 也就是咱們請求頭中一定要攜帶cookies!自己去測驗一下即可,
分析(x2)
那么第一頁咱們就愉快地采集下來了,用提取規則提取出想要的資料即可,
那么分析X1里面的一個點再重復講一下,服務器會檢測cookies, 也就是咱們請求頭中一定要攜帶cookies!
而cookies有時效性(比如你登錄了某某網站,那么短時間內無需重新登錄,而十天半個月后可能就需要你重新登錄了,就是這么個道理)
那么說明:我們在采集資料之前,首先去自動獲取網頁的cookies,然后再用這個cookies去采集資料,這樣就可以實作一個全自動化,而非手動去復制cookies
那么思路就清晰了:先白用戶(不攜帶cookies),requests訪問網站首頁得到服務器回傳的cookies,然后用這個cookies去post介面得到咱們需要的資料
到此為止,咱們也只是采集到了第一頁的資料,而如果咱們需要采集所有的資料呢?
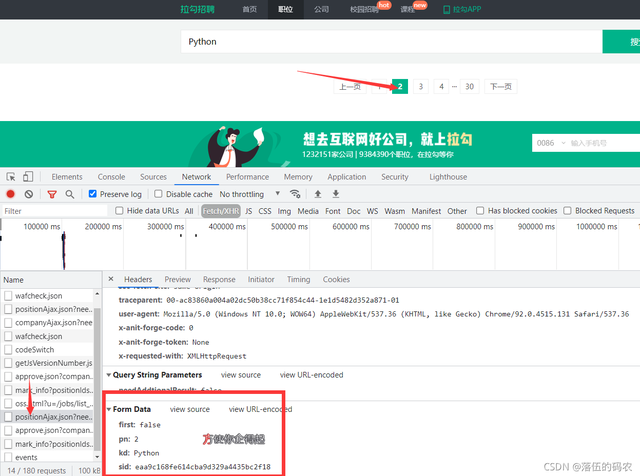
咱們繼續分析,如果要采集所有的頁碼上資料,我經常跟你們講的思路:先看看翻頁后咱們網站的變化,很明顯在這里咱們行不通了,因為資料是介面api生成的,所以呢,我們轉換下思路,翻頁后抓到第二頁的api看看與第一頁api的不同之處,
?
看得到,幾個變化的點,和不變化的點,首先post的地址是沒變的,而引數變了,
first變為了false,pn為頁碼變成了2,關鍵詞還是Python不變,新增了sid引數,
分析(x3)
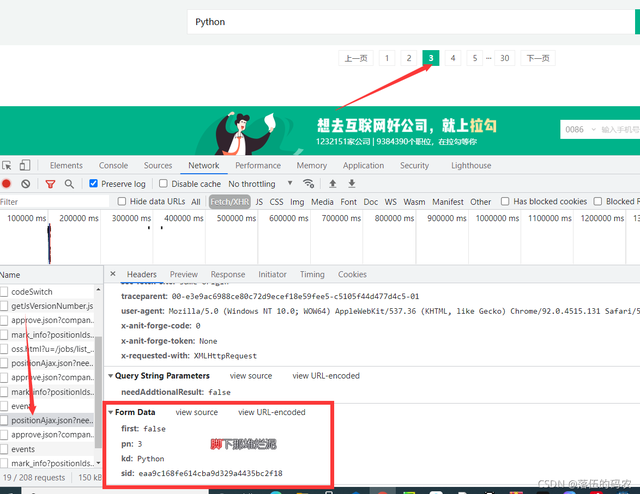
看下第三頁,是不是first還是FALSE,sid值也不變,如果不變就好辦了(也就是說第一頁與后面頁碼的引數不同而已),如果一直無限變化,咱們就需要找找變化的規律了,
?
看了第三頁的包,我知道事情好辦了,
規律總結:引數frist第一頁為ture,其它頁全為FALSE,pn隨頁碼變化,kd為自己搜索的關鍵詞,sid第一頁為空,后面的頁碼為固定值(這里我要跟大家解釋一下,其實你第一頁把這個sid引數傳入進去,一樣是可以訪問的,別問為什么,這個是作為一個高級爬蟲師的一個直覺),
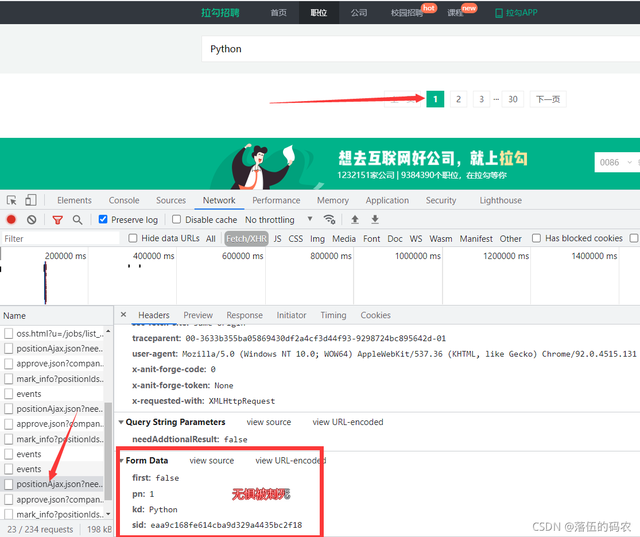
?
當我們翻到第一頁,果然真的是攜帶sid的.......而且first變為了FALSE,這就很神奇了,
神奇的點在哪?咱們前面抓首頁的包的時候,可以看到first為TRUE,sid是沒有這個引數的,那么也就是說是訪問了第一頁后生成了sid這個引數,然后把sid傳入到第二個頁碼介面的引數當中的,
如果說咱們如果直接把所有頁碼介面的引數都寫成四個,first都沒TRUE,sid為固定死,可行嗎?
不可行,除非你手動抓包去復制sid,因為sid是訪問了第一頁的資料后生成的......
如果理解不了多看看神奇的點在哪這一段話,
總結一下咱們現在需要做的事情就是去搞清楚sid這個值從何而來,
分析(x4)
直接ctrl+f搜一下即可,可以知道sid果然是第一頁的post后得到資料,
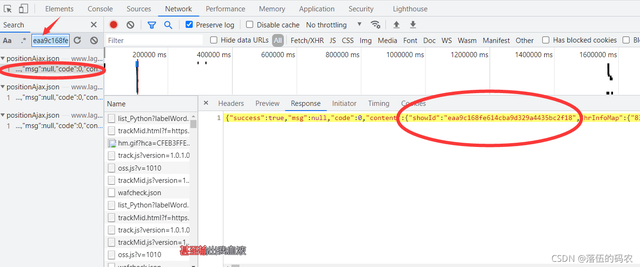
?
那么總思路就是,先訪問首頁獲取cookies,然后post第一頁得到sid,而第一頁的引數first為TRUE,sid為空,后面的頁碼first為FALSE,sid為第一頁post后得到的值,
......我剛手動翻頁的時候
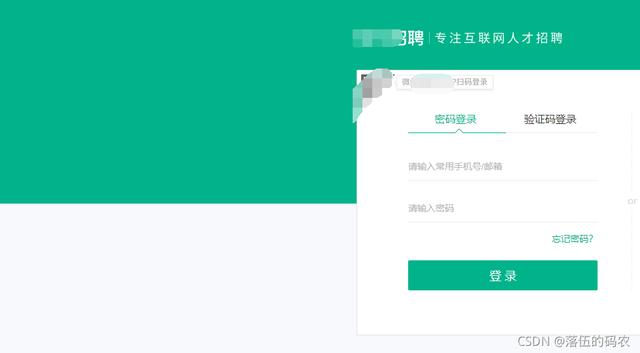
?
醉了,網站改版了,未登錄用戶操作次數過多會直接讓你去登錄......也就是說cookies只能去手動登錄后去復制了,因為這個登錄也有那個特殊的驗證碼,沒法去過,找打碼臺子也不劃算.....
沒辦法,委屈各位手動cookies了,
代碼
```
當然在學習Python的道路上肯定會困難,沒有好的學習資料,怎么去學習呢?
學習Python中有不明白推薦加入交流Q群號:928946953
群里有志同道合的小伙伴,互幫互助, 群里有不錯的視頻學習教程和PDF!
還有大牛解答!
```
import requests import time import sys cookies = '手動copy' url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' headers = { 'authority': 'www.lagou.com', 'method': 'POST', 'path': '/jobs/positionAjax.json?needAddtionalResult=false', 'scheme': 'https', 'accept': 'application/json, text/javascript, */*; q=0.01', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'content-length': '63', 'content-type': 'application/x-www-form-urlencoded; charset=UTF-8', 'cookie': cookies, 'origin': 'https://www.lagou.com', 'referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=', 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"', 'sec-ch-ua-mobile': '?0', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', # 'traceparent': '00-2a566c511e611ee8d3273a683ca165f1-0c07ea0cee3e19f8-01', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36', 'x-anit-forge-code': '0', 'x-anit-forge-token': 'None', 'x-requested-with': 'XMLHttpRequest', } sid = "" def get_data(flag, page, sid): data = { 'first': flag, 'pn': page, 'kd': 'python', 'sid': sid } return data for page in range(1, sys.maxsize): time.sleep(5) if page == 1: flag = True else: flag = False response = requests.post(url=url, headers=headers, data=https://www.cnblogs.com/pythonQqun200160592/p/get_data(flag, page, sid)) sid = response.json()["content"]['showId'] text = response.json()['content']['positionResult']['result'] print(text) with open("result.csv", "a", encoding='utf-8') as file: for cp in text: cp_msg = f"{cp['city']},{cp['companyFullName']},{cp['companySize']},{cp['education']},{cp['positionName']},{cp['salary']},{cp['workYear']}\n" file.write(cp_msg) print(f"第{page}頁爬取完成") print("爬取完成")
效果
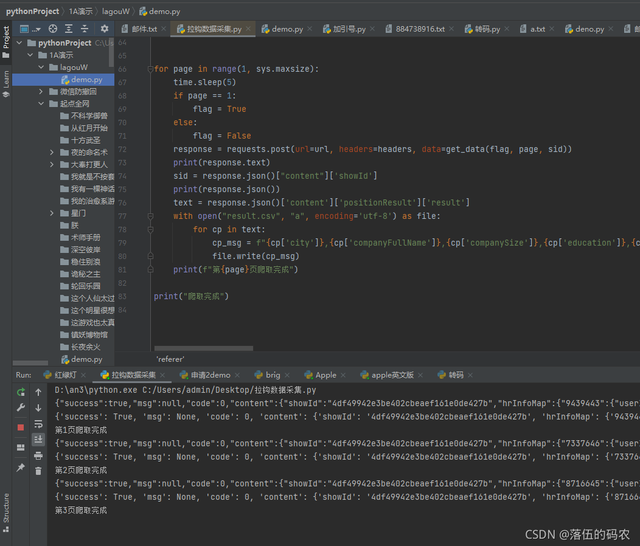
?
我有話說
—— 有一些人,
他們赤腳在你生命中走過,
眉眼帶笑,不短暫,也不漫長 .
卻足以讓你體會幸福,
領略痛楚,回憶一生 .

?
文章的話是現寫的,每篇文章我都會說得很細致,所以花費的時間比較久,一般都是兩個小時以上,
原創不易,再次謝謝大家的支持,
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
在代碼中

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296017.html
標籤:Python
上一篇:六、與用戶互動、運算子