借助于AI工具來實作驗證碼識別,內含python3示例
驗證碼識別的場景十分常見
本文主要討論作為普通開發者(缺乏/沒有Ai學術(教育/實踐)背景)的前提下,來低成本快速實作驗證碼識別
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
當然在學習Python的道路上肯定會困難,沒有好的學習資料,怎么去學習呢? 學習Python中有不明白推薦加入交流Q群號:928946953 群里有志同道合的小伙伴,互幫互助, 群里有不錯的視頻學習教程和PDF! 還有大牛解答!
本次測驗的驗證碼主要有兩種
1. 無干擾的純數字驗證碼
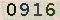
2. 有干擾的數字加字母驗證碼

1. 百度AI大腦
https://ai.baidu.com/tech/ocr/general
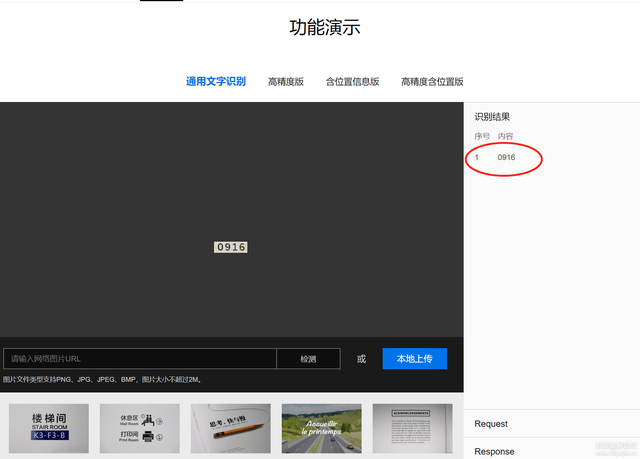
下邊我用python3來示例在
https://console.bce.baidu.com/ai/?fromai=1#/ai/ocr/app/list
這里新建應用
記錄appid, apikey, secret key
復制代碼 隱藏代碼 import requests import base64 import shortuuid from pprint import pprint #填上自己的app 資訊 appid = "" key = "" secret = "" def Token(): host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(key, secret) response = requests.get(host) # if response: # pprint(response.json()) return response.json()['access_token'] token = Token() request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" f = open('./code/code.png', 'rb') img = base64.b64encode(f.read()) params = {"image":img,"language_type":"CHN_ENG"} # access_token = '[呼叫鑒權介面獲取的token]' request_url = request_url + "?access_token=" + token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=https://www.cnblogs.com/pythonQqun200160592/p/params, headers=headers) pprint (response.json())
2 騰訊AI
https://ai.qq.com/product/ocr.shtml#common
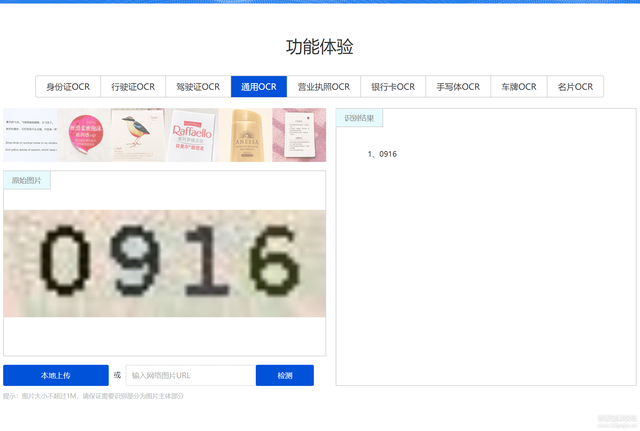
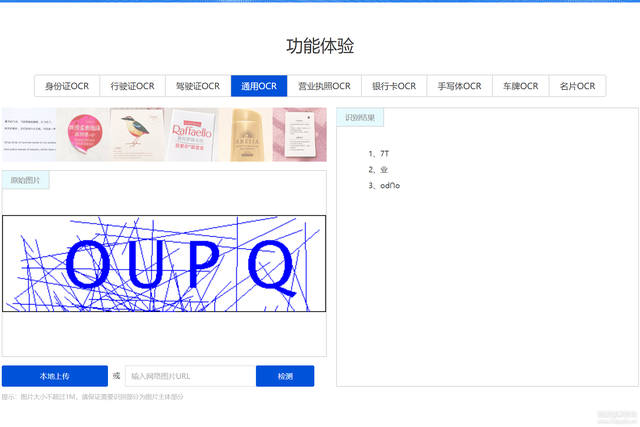
騰訊ocr示例在這里新建應用
https://ai.qq.com/console/application/create-app
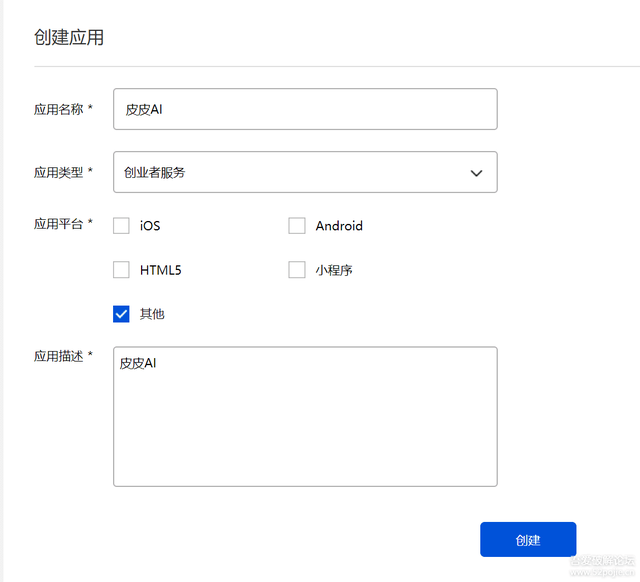
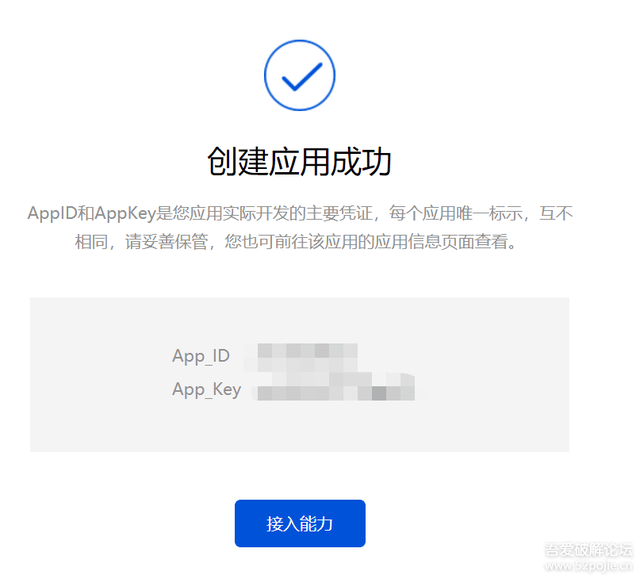
記錄以上app資訊 APP_ID,APP_Key
復制代碼 隱藏代碼 import base64, hashlib, json, random, string, time from urllib import parse import requests from pprint import pprint # 填寫app資訊 app_id = "" app_key = "" def GetAccessToken(formdata, app_key): dic = sorted(formdata.items(), key=lambda d: d[0]) sign = parse.urlencode(dic) + '&app_key=' + app_key m = hashlib.md5() m.update(sign.encode('utf8')) return m.hexdigest().upper() def RecogniseGeneral(app_id, time_stamp, nonce_str, image, app_key): host = 'https://api.ai.qq.com/fcgi-bin/ocr/ocr_generalocr' formdata = {'app_id': app_id, 'time_stamp': time_stamp, 'nonce_str': nonce_str, 'image': image} app_key = app_key sign = GetAccessToken(formdata=https://www.cnblogs.com/pythonQqun200160592/p/formdata, app_key=app_key) formdata['sign'] = sign try: r = requests.post(url=host, data=https://www.cnblogs.com/pythonQqun200160592/p/formdata, timeout=20) except requests.exceptions.ReadTimeout: r = requests.post(url=host, data=https://www.cnblogs.com/pythonQqun200160592/p/formdata, timeout=20) if (r.status_code == 200): return r.json() else: print(r.text) def Recognise(img_path): with open(file=img_path, mode='rb') as file: base64_data = base64.b64encode(file.read()) nonce = ''.join(random.sample(string.digits + string.ascii_letters, 32)) stamp = int(time.time()) recognise = RecogniseGeneral(app_id=app_id, time_stamp=stamp, nonce_str=nonce, image=base64_data, app_key=app_key) # for k, v in recognise.items(): # print(k, v) return recognise img_path = "./code/code.png" response = Recognise(img_path) pprint(response) code = response['data']['item_list'][0]['itemstring'].replace(" ", "") print(code)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296026.html
標籤:Python