撰寫 Verilog 代碼多年,至今才無意中發現了一種奇怪的語法,估計見過的這種的寫法的人,在 FPGA 開發者中不會超過 20% 吧,
直接來看代碼吧,先定義了一個簡單的模塊,名為 mod,
module mod(
input clk,
input din,
output reg [1:0] dout
);
always @(posedge clk)
dout <= {din, ~din};
endmodule
下面是對 mod 模塊進行例化,注意例化名后面的東西,
module top(
input clk,
input [3:0] din,
output [7:0] dout
);
mod u_mod[3:0] ( // 例化名后面跟了一個位寬定義,
.clk (clk ), // I
.din (din[3:0] ), // I 連接的位寬是單個 mod 所需要的4倍
.dout (dout[7:0] ) // O 連接的位寬是單個 mod 所需要的4倍
);
endmodule
雖然以前從來沒有見過這種寫法,但從代碼上大概可以推斷出這種寫法應該和 generate ... for ... 的作用是一樣的,但是寫法上要簡潔得多,
實驗一
使用 Vivado 對代碼進行綜合后,得到的原理圖如下,從圖上可以看到 mod 模塊的確是被例化了 4 次,頂層的 4 bits 的 din 分別連接到了 4 個 u_mod,4 個 din 的索引和 u_mod 的索引相同,din[0] 連接到了 u_mod[0],din[3] 連接到了 u_mod[3],4 個模塊的 dout 輸出后合并成了 8 bits,其中 u_mod[0] 的 2 bits 輸出連接到了 dout[1:0], u_mod[3] 的 2 bits 輸出連接到了 dout[7:6],
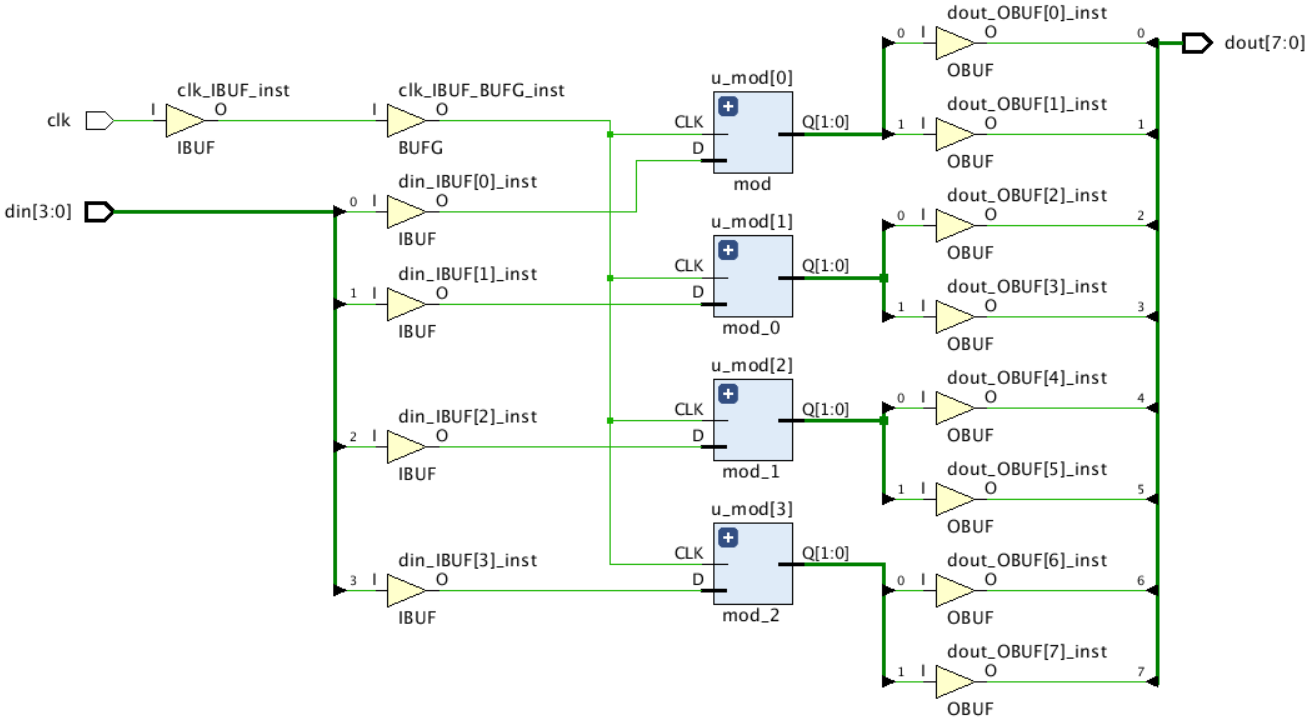
實驗二
為了進一步研究連接的順序,又做了如下實驗,模塊例化時的位寬由原來的 [3:0] 改為 [0:3],
mod u_mod[0:3] ( // 位寬定義進行反轉,
.clk (clk ), // I
.din (din[3:0] ), // I 連接的位寬是單個 mod 所需要的4倍
.dout (dout[7:0] ) // O 連接的位寬是單個 mod 所需要的4倍
);
再次綜合后,得到的原理圖如下,4 個 u_mod 和頂層的連接關系完全反了過來,din[0] 連接到了 u_mod[3],din[3] 連接到了 u_mod[0],輸出也是同樣的情況, u_mod[0] 的 2 bits 輸出連接到了 dout[7:6], u_mod[3] 的 2 bits 輸出連接到了 dout[1:0],
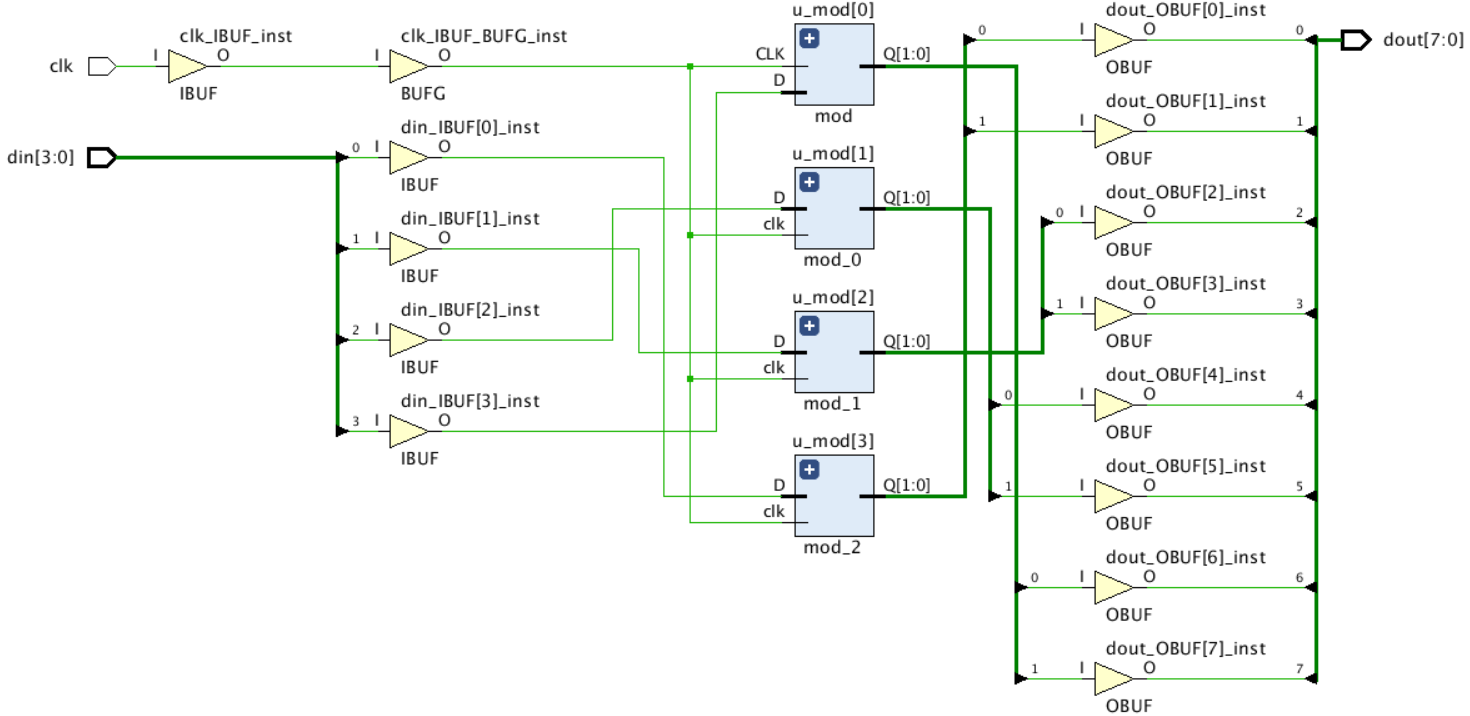
經過上面 2 個實驗,大概可以得出結論:模塊例化的順序總是從右到左的,連接頂層線序也是從右到左的,
實驗三
為了進一步論證,做了第三個實驗,把模塊例化的位寬還原,把頂層的埠定義的位寬進行反轉,再看一下會有什么效果,
module top(
input clk,
input [0:3] din,
output [0:7] dout
);
mod u_mod[3:0] (
.clk (clk ), // I
.din (din[0:3] ), // I
.dout (dout[0:7] ) // O
);
endmodule
din[0] 連接到了 u_mod[3],din[3] 連接到了 u_mod[0],和預期的一樣,u_mod[0] 的 2 bits 輸出連接到了 dout[6:7], u_mod[3] 的 2 bits 輸出連接到了 dout[0:1],仔細看會發現,每個 u_mod 輸出的 2 bits 和頂層的 dout 的 2 bits 是反過來連接的,u_mod[0].dout[0] 連接到了 dout[7],u_mod[0].dout[1] 連接到了 dout[6],這就是和上一個實驗不同的地方,這個實驗結果和上面做出的結論也是相符合的,
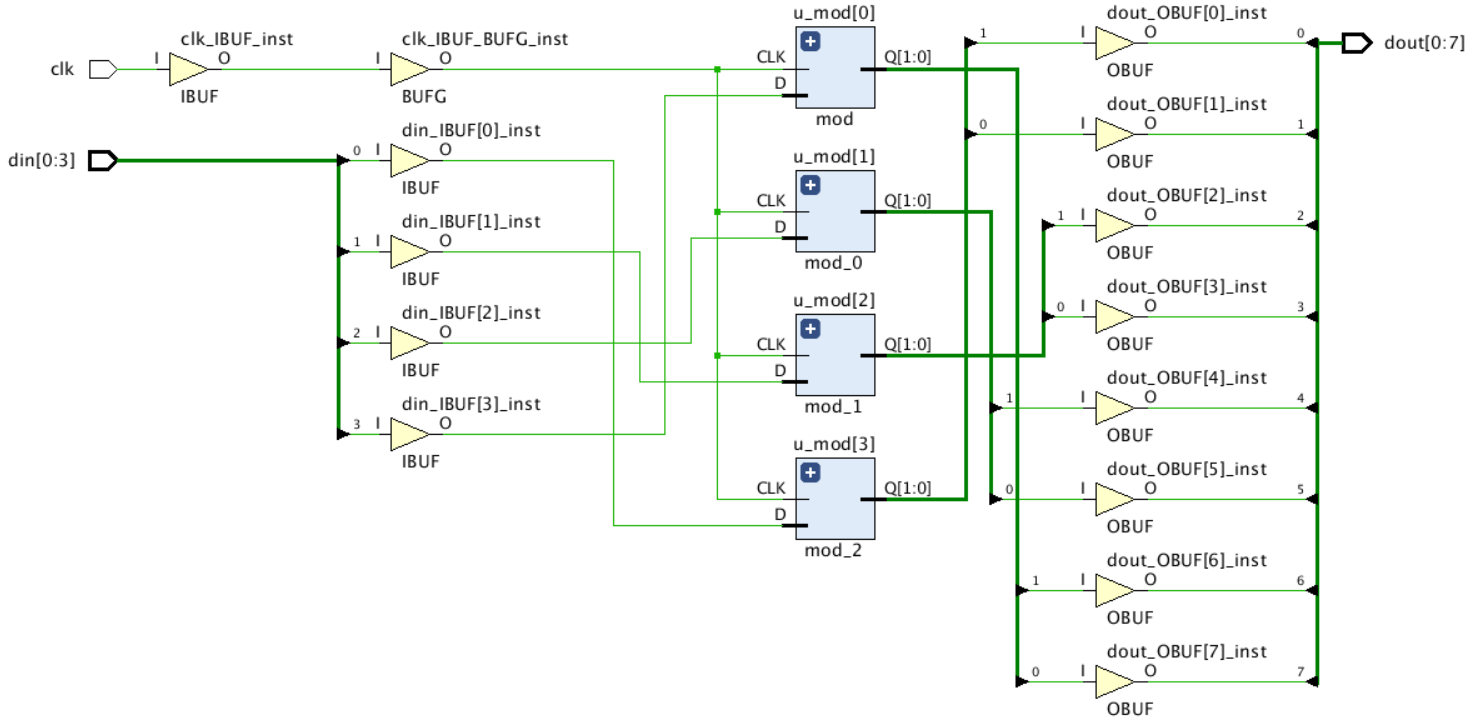
實驗四
上面的實驗中,頂層介面的輸入輸出位寬都是 mod 輸入輸出位寬的 4 倍,4 個 u_mod 連線獨立,不會有干擾,但如果把頂層的位寬減小,會有什么后果呢?于是又做了第四個實驗,mod 仍然例化 4 次,但是頂層 dout 位寬和 mod 的 dout 位寬相同,也就是說 4 個 u_mod 要共享頂層的 dout 埠,這樣會出錯嗎?
module top(
input clk,
input [3:0] din,
output [1:0] dout
);
mod u_mod[3:0] (
.clk (clk ), // I
.din (din[3:0] ), // I
.dout (dout[1:0] ) // O
);
endmodule
經過 Vivado 的綜合,并沒有報錯,并且生成了如下的原理圖,但是報出了 multiple drivers 的告警,從原理圖上可以看出,4 個 u_mod 的輸出全部連到了一起,造成了多驅動的錯誤,當進一步在 Vivado 中執行 Implementation 時,直接報錯,無法正常布線,(此處無報錯,并不是此種連接方式有問題,而是和 mod 的輸出相關,如果 mod 的輸出在某些條件下輸出高阻時,Implementation 是可以過的,只是輸出會用到三太門,)
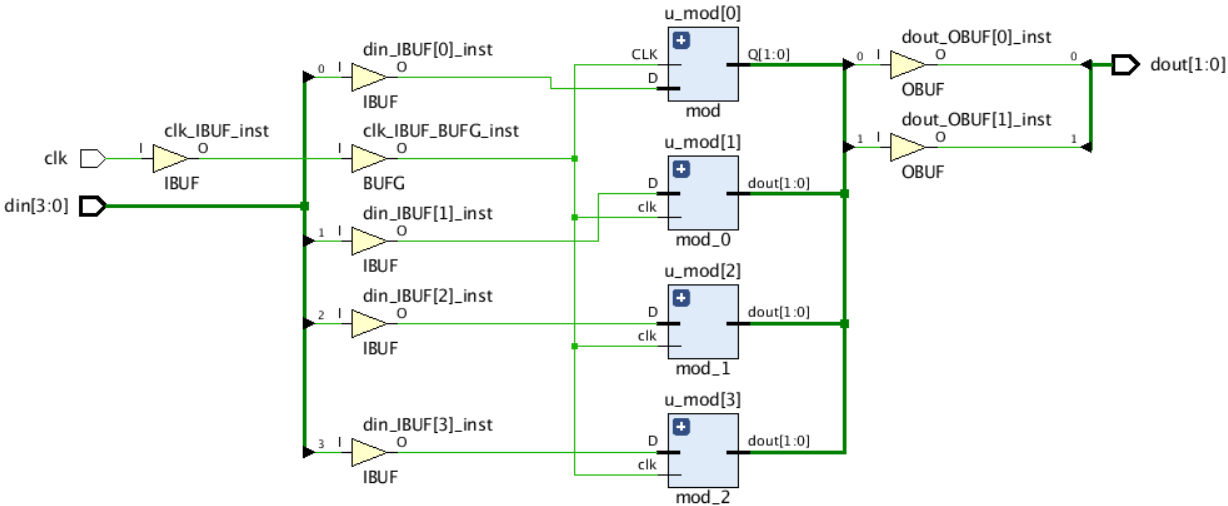
查詢規范
針對這種以陣列的方式批量例化模塊的代碼撰寫方法,我特意查詢了 IEEE Std 1364?-2005,在里面找到到如下兩段話,此種語法稱作實體陣列,
In order to specify an array of instances, the instance name shall be followed by the range specification. The range shall be specified by two constant expressions, left-hand index ( lhi ) and right-hand index ( rhi ), separated by a colon and enclosed within a pair of square brackets. A [lhi:rhi] range specification shall represent an array of abs(lhi-rhi)+1 instances. Neither of the two constant expressions are required to be zero, and lhi is not required to be larger than rhi . If both constant expressions are equal, only one instance shall be generated.
當需要定義實體陣列時,實體名稱后面應跟有范圍規范,范圍由兩個常量運算式指定,左側索引 ( lhi ) 和右側索引 ( rhi ),用冒號分隔并用一對方括號括起來,[lhi:rhi] 范圍表示一次性例化 abs(lhi - rhi) + 1 個實體,兩個常量運算式都不要求為零,并且 lhi 不一定需要比 rhi 大,如果兩個常量運算式相等,則只會生成一個實體,
- The bit length of each port expression in the declared instance-array shall be compared with the bit length of each single-instance port or terminal in the instantiated module or primitive.
- For each port or terminal where the bit length of the instance-array port expression is the same as the bit length of the single-instance port, the instance-array port expression shall be connected to each single-instance port.
- If bit lengths are different, each instance shall get a part-select of the port expression as specified in the range, starting with the right-hand index.
- Too many or too few bits to connect to all the instances shall be considered an error.
- 宣告的實體陣列時,需要對中每個埠運算式的位寬和單個模塊的埠位寬進行比較,
- 當埠運算式的位寬和單個模塊的埠位寬相同時,同一埠運算式連接到每個單實體埠,
- 如果位寬不同,則從埠運算式的右側索引開始,每個實體都會獲取的埠運算式的一部分,獲取寬度和單個模塊的埠寬度相同,
- 當連接到所有實體的位太多或太少都會視為錯誤,
上述翻譯可能不好理解,簡單歸納一下就是,與每個埠相連的信號的位寬只能和埠本身的位寬相同,或者為埠位寬的 N 倍(N為實體陣列的長度,即一次性例化模塊的個數),其他寬度都是違法的,還是上面的例子,我們一次性例化了 4 個模塊,即 N = 4,模塊的 dout 本身位寬為 2 bits,所以能夠連接到實體陣列 dout 的信號位寬只能是 2 bits 或者 8 bits,當為 2 bits 時,連接情況如同實驗四,當為 8 bits 時,連接情況同實驗一至實驗三,
其實在查規范的同時還發現了更稀奇的寫法,但是看看就明白了,不做解釋,??
nand #2 t_nand[0:7] ( ... );
nand #2 x_nand[0:3] ( ... ), y_nand[4:7] ( ... );
總結
這種實體陣列的寫法相對與 generate ... for ... 在代碼上看更簡潔,且不容易出錯,即便是出錯,編譯器也會檢查出來,但是對于不熟悉此語法的同學來說,可能會不好理解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296038.html
標籤:Verilog