目錄
前言
開始
分析(x0)
分析(x1)
采集的Python代碼
采集的效果
顏值檢測函式構造
facerg.py
排序原始碼
結果演示
完整的所有原始碼
視頻教程地址
我有話說
前言
大家好,我叫善念,這是連續更新Python爬蟲實戰案例的第七天,感覺很多的東西不怎么好寫,也不知道該寫什么案例了,
大家可以反饋給我一下想要采集哪個網站,或者需要post哪些網站的功能,或腳本、或一些基礎知識的講解,
好好寫文章,拒絕各種表情包二改別人文章,每一篇都現寫的原創干貨,沒那么多時間去耍嘴皮子逗你們開心,
開始
目標網站:某魚的顏值主播
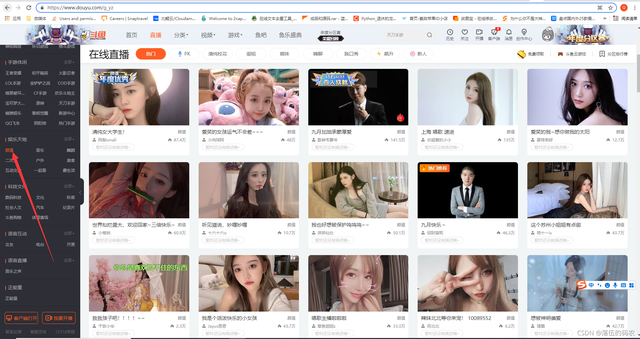
?
好吧,萬萬沒想到還有幾個男同胞......
咱們需要的東西就很簡單了,采集封面圖然后進行顏值檢測 ,對檢測出來的分數進行排名即可,
分析(x0)
簡單地查看了一下網頁的元素,可以看到咱們需要的圖片在li標簽的img標簽的src屬性中,而每一個li標簽都包含了一個主播的資訊,
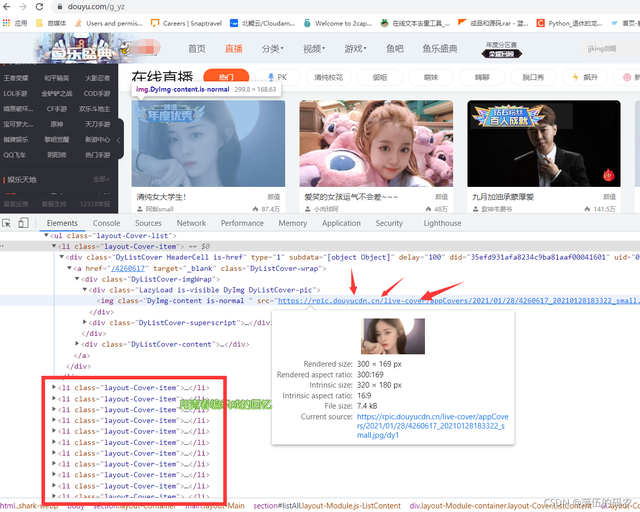
?
我多次講過像這種圖片的加載,極有可能是動態加載,就是當咱們拉動下滑條的時候圖片會自動重繪出來,就跟上期的【Python】完美采集某寶資料,到底A和B哪個是YYDS?(附完整源代碼和視頻教程)是一樣的,
那么如何看出來它是否是動態加載的呢?
1.教大家一個可以肉眼可查的方法,那就是直接手動快速拉動瀏覽器的下滑條,你會發現很多的圖片加載需要時間,剛出現的時候是一個白板,然后才加載出影像!
2.那就是直接查看網頁元素,如果是動態加載,而咱們的瀏覽器目前還沒有往下面滑,就說明下面的圖片肯定是沒加載出來的,
那么咱們直接看看后面的li標簽中是否有咱們的圖片資料:
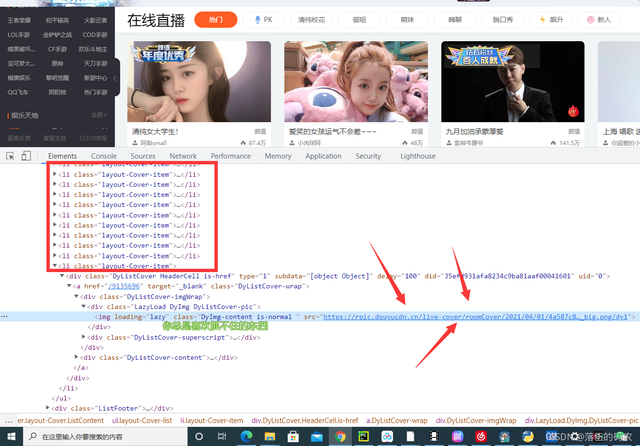
?
明顯這個圖的格式都不一樣,是打不開的,也就是個白板圖,
好吧那就說明這個又是個動態加載的網站,那么咱們就開始抓包,
分析(x1)
重繪一下網頁就抓到包了,可以看到這個東西呢它有rs1和rs6兩個圖,rs1是大圖另外一個是小圖,想采集哪個都行,我這里采集大圖,
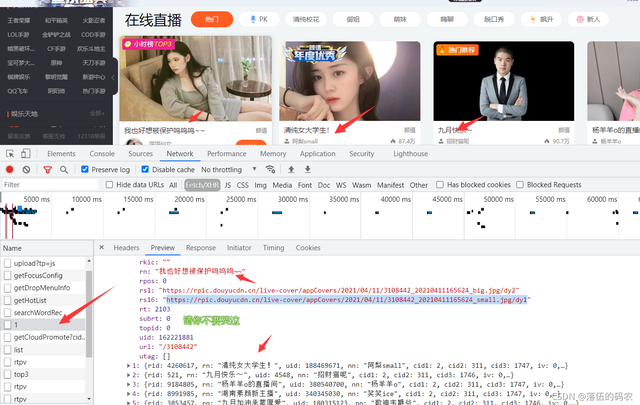
?
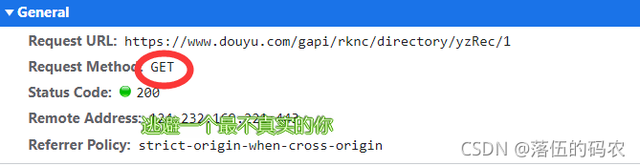
分析一下這個請求,是個get請求,說實話我都沒想到是get,那么就有點特殊的了,我們前面只分析了網頁元素,按道理咱們需要的資料在網頁源代碼中應該同樣有......不過也沒關系,自己去看看就好了,也不建議從源代碼中去獲取資料,
?
理由就是:可以看到第二頁與第一頁的網頁url是沒發生變化的發現沒?如果說你從網頁原始碼中去獲取,那么你可以獲取到第二頁的資料,第一頁該如何獲取呢?所以說千萬別從網頁源代碼中去提取資料,咱們沒辦法去構造url,

?
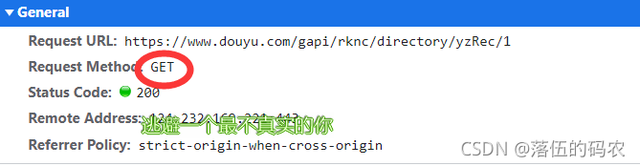
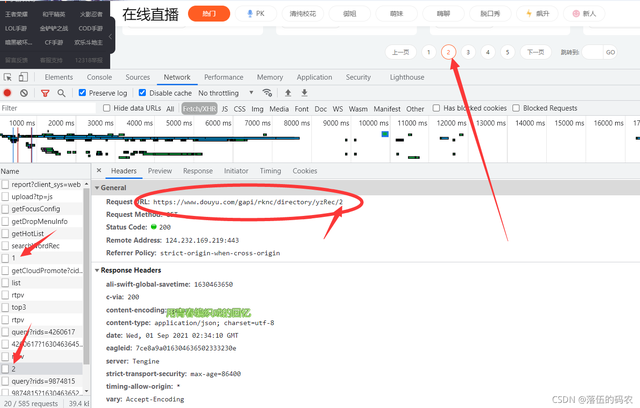
而你如果是包就很容易分析出,只需要把url后面的1改成2就是第二頁了,這點敏銳大家還是具備的吧?不相信抓下包就可以了,
?
?
是的吧,多頁采集的話構造下url即可 ,
采集的Python代碼
import requests import jsonpath import os from urllib.request import urlretrieve headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'} if not os.path.exists('./pic'): os.mkdir('./pic') for i in range(1, 100000): try: url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}' r = requests.get(url, headers=headers) names = jsonpath.jsonpath(r.json(), '$..nn') pngs = jsonpath.jsonpath(r.json(), '$..rs1') for name, png in zip(names, pngs): urlretrieve(png, './pic' + '/' + name + '.png') print(names) print(pngs) except: exit()
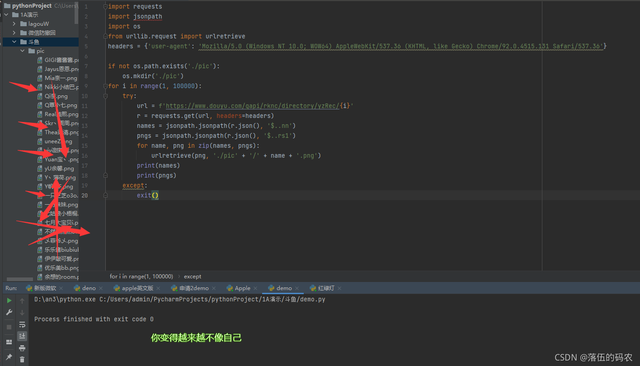
采集的效果
?
顏值檢測函式構造
注冊百度智能云:地址
按圖去選擇咱們需要的服務:
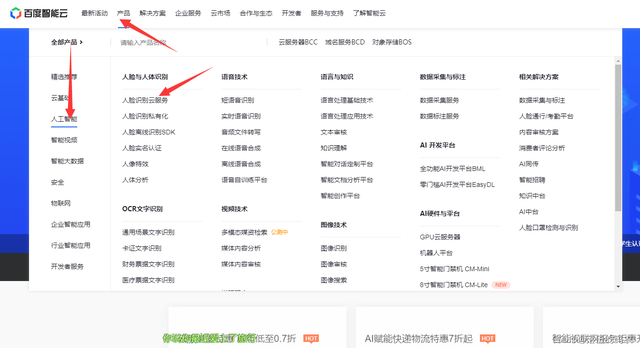
?
自己看下技術檔案:
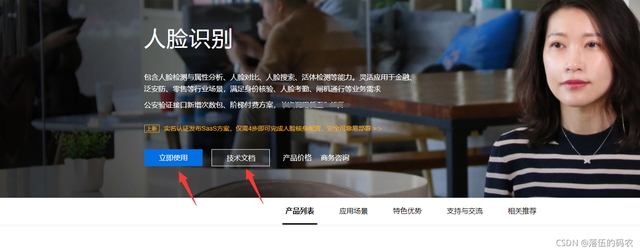
點擊立即使用——創建應用:
?
正常填寫就好
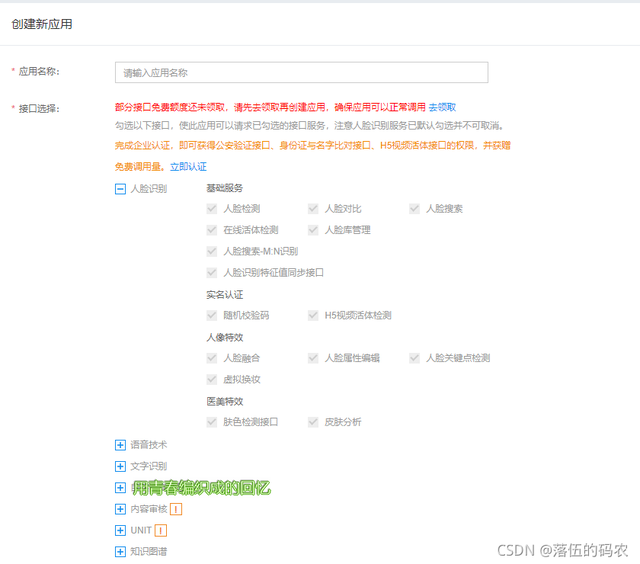
?
創建好后點擊——管理應用

?
拿到API Key與Secret Key

?
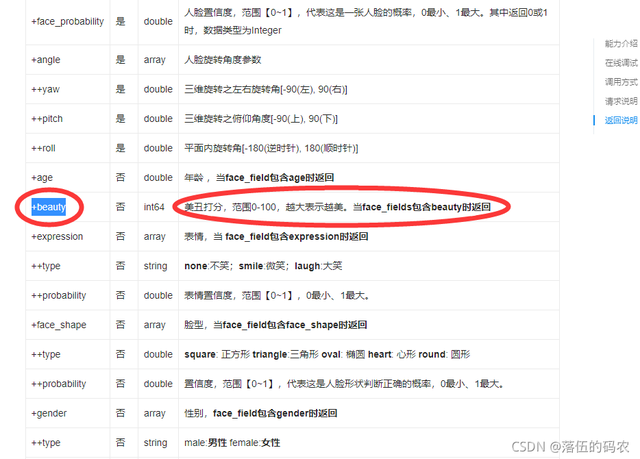
看下技術檔案,開始構建咱們的函式,不做過多講解
?
提示:模塊的安裝
pip install baidu-aip
?
facerg.py
#!/usr/bin/python3 # -*- coding: utf-8 -*- # @Time : 2019/5/7 23:20 # @Author : 善念 # @Software: PyCharm from aip import AipFace import base64 def face_rg(file_Path): """ 你的 api_id AK SK """ api_id = '你的id' api_key = 'ni de aipkey' secret_key = '你自己的key' client = AipFace(api_id, api_key, secret_key) with open(file_Path, 'rb') as fp: data = base64.b64encode(fp.read()) image = data.decode() imageType = "BASE64" options = {} options["face_field"] = 'beauty' """ 呼叫人臉檢測 """ res = client.detect(image, imageType, options) score = res['result']['face_list'][0]['beauty'] return score
排序原始碼
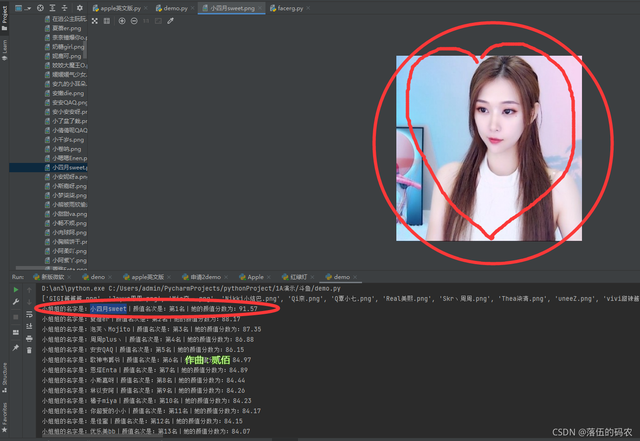
from facerg import face_rg path = r'圖片檔案夾路徑' images = os.listdir(path) print(images) yz = [] yz_dict = {} for image in images: try: name = image[0:-4] score = face_rg(path + '\\' + image) yz_dict[score] = name yz.append(score) except: pass yz.sort(reverse=True) for a, b in enumerate(yz): print('小姐姐的名字是:{}丨顏值名次是:第{}名丨她的顏值分數為:{}'.format(yz_dict[b], a+1, b))
結果演示
?
完整的所有原始碼
import requests import jsonpath import os from urllib.request import urlretrieve # headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'} # # if not os.path.exists('./pic'): # os.mkdir('./pic') # for i in range(1, 100000): # try: # url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}' # r = requests.get(url, headers=headers) # names = jsonpath.jsonpath(r.json(), '$..nn') # pngs = jsonpath.jsonpath(r.json(), '$..rs1') # for name, png in zip(names, pngs): # urlretrieve(png, './pic' + '/' + name + '.png') # print(names) # print(pngs) # except: # exit() from facerg import face_rg path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗魚\pic' images = os.listdir(path) print(images) yz = [] yz_dict = {} for image in images: try: name = image[0:-4] score = face_rg(path + '\\' + image) yz_dict[score] = name yz.append(score) except: pass yz.sort(reverse=True) for a, b in enumerate(yz): print('小姐姐的名字是:{}丨顏值名次是:第{}名丨她的顏值分數為:{}'.format(yz_dict[b], a+1, b))
把facerg.py當成一個自寫的模塊呼叫就好了,
我有話說
——當你毫無保留地信任一個人,最終只會有兩種結果,不是生命中的那個人,就是生命中的一堂課,
文章的話是現寫的,每篇文章我都會說得很細致,所以花費的時間比較久,一般都是兩個小時以上,每一個贊與評論收藏都是我每天更新的動力,
原創不易,再次謝謝大家的支持,
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
當然在學習Python的道路上肯定會困難,沒有好的學習資料,怎么去學習呢? 學習Python中有不明白推薦加入交流Q群號:928946953 群里有志同道合的小伙伴,互幫互助, 群里有不錯的視頻學習教程和PDF! 還有大牛解答!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296729.html
標籤:其他
上一篇:java修飾符
下一篇:并發編程之:Atomic