2021Java開發工程師必備知識,Java后端主流知識學習系列(一)(有用的客官建議三連!)
- 初 前言
- 一、Java基礎
- 二、作業系統
- 三、計算機網路
- 四、資料結構
- 五、演算法
- 六、資料庫
- 七、熱門框架技術
- 八、微服務分布式架構
- 九、服務器中間件
- 十、前沿技術
- 總結
初 前言
大家好,菜菜希望這個系列的文章能夠幫助各位大佬和菜菜自己,文章內容包含Java基礎+作業系統+計算機網路+資料結構+演算法+資料庫+熱門框架技術+微服務分布式架構+服務器中間件+前沿技術等,內容涵蓋較多,涉及知識面比較廣,當然也可以點擊目錄直達想看的內容哈,初衷是希望榷訓月累,量變引發質變,培養好我們自己!您覺得有用的話三連支持一下,菜菜感激不盡!!!

一、Java基礎
什么是JDK?
JDK 是 Java Development ToolKit 的簡稱,也就是 Java 開發工具包,JDK 是整個 Java 的核心,包括 Java 運行環境(Java Runtime Envirnment,簡稱 JRE),Java 工具(比如 javac、java、javap 等等),以及 Java 基礎類別庫(比如 rt.jar),
平時安裝的JDK會有以下幾部分(了解)
- bin:包含了最主要的是編譯器(javac.exe)
- include:Java 和 JVM 互動用的頭檔案
- lib:類別庫
- jre:Java 運行環境
JDK的三種型別
- J2SE:Standard Edition,標準版,是我們通常用的一個版本,從 JDK 5.0 開始,改名為 Java SE,
- J2EE:Enterprise Edition,企業版,從 JDK 5.0 開始,改名為 Java EE,
- J2ME:Micro Edition,主要應用于移動設備、嵌入式設備,從 JDK 5.0 開始,改名為 Java ME
Java的三種技術架構
- JAVAEE:Java Platform Enterprise Edition,開發企業環境下的應用程式,主要針對web程式開發;
- JAVASE:Java Platform Standard Edition,完成桌面應用程式的開發,是其它兩者的基礎;
- JAVAME:Java Platform Micro Edition,開發電子消費產品和嵌入式設備,如手機中的程式;
什么是JRE?
Java Runtime Environment:是Sun的產品,java程式的運行環境,java運行的所需的類別庫+JVM(java虛擬機), 是面向Java程式的使用者,而不是開發者,
如果安裝了JDK,會發同你的電腦有兩套JRE,一套位于 \jre 另外一套位于 C:\Program Files\Java\jre1.5.0_15 目錄下,后面這套比前面那套少了Server端的Java虛擬機,不過直接將前面那套的Server端Java虛擬機復制過來就行了,而且在安裝JDK可以選擇是否安裝這個位于 C:\Program Files\Java 目錄下的JRE,如果你只安裝JRE,而不是JDK,那么只會在 C:\Program Files\Java 目錄下安裝唯一的一套JRE,
Java 基本資料型別
變數就是申請記憶體來存盤值,也就是說,當創建變數的時候,需要在記憶體中申請空間,
記憶體管理系統根據變數的型別為變數分配存盤空間,分配的空間只能用來儲存該型別資料,
八種基本型別(四個整數型+兩個浮點型+字符型別+布爾型)
下表列出了 Java 各個型別的默認值
| 資料型別 | 位元組 (1位元組=8位) | 默認值 |
|---|---|---|
| byte | 8位 | 0 |
| short | 16 位 | 0 |
| int | 32位 | 0 |
| long | 64 位 | 0L |
| float | 32位 | 0.0f |
| double | 64 位 | 0.0d |
| char | 16 位 Unicode 字符 | ‘u0000’ |
| boolean | 一位 | false |
Java 參考資料型別
參考型別包括三種:
- 類 Class
- 介面 Interface
- 陣列 Array
參考型別一般是通過new關鍵字來創建,比如Integer num = new Integer(3);它存放在記憶體的堆中,可以在運行時動態的分配記憶體大小,生存期也不必事先告訴編譯器,當參考型別變數不被使用時,Java內部的垃圾回收器GC會自動回收走,參考變數中存放的不是變數的內容,而是存放變數內容的地址,
在引數傳遞時,基本型別都是傳值,也就是傳遞的都是原變數的值得拷貝,改變這個值不會改變原變數,而參考型別傳遞的是地址,也就是引數與原變數指向的是同一個地址,所以如果改變引數的值,原變數的值也會改變,這點要注意,
在java中,8種基本型別在java中都有對應的封裝型別,也就是參考型別:
- 整數型別 Byte、Short、Integer、Long
- 浮點數型別 Float、Double
- 字符型 Character
- 布爾型別 Boolean

二、作業系統
作業系統的四個特性
- 并發:同一段時間內多個程式執行(注意區別并行和并發,前者是同一時刻的多個事件,后者是同一時間段內的多個事件)
- 共享:系統中的資源可以被記憶體中多個并發執行的進執行緒共同使用
- 虛擬:通過時分復用(如分時系統)以及空分復用(如虛擬記憶體)技術實作把一個物理物體虛擬為多個
- 異步:系統中的行程是以走走停停的方式執行的,且以一種不可預知的速度推進
死鎖定義
在兩個或多個并發行程中,如果每個行程持有某種資源而又都等待別的行程釋放它或它們現在保持著的資源,在未改變這種狀態之前都不能向前推進,稱這一組行程產生了死鎖,通俗地講,就是兩個或多個行程被無限期地阻塞、相互等待的一種狀態,
死鎖產生條件(4個)
- 互斥條件:一個資源一次只能被一個行程使用
- 請求保持條件:一個行程因請求資源而阻塞時,對已經獲得資源保持不放
- 不可搶占條件: 行程已獲得的資源在未使用完之前不能強行剝奪
- 回圈等待條件;若干行程之間形成一種頭尾相接的回圈等待資源的關系
死鎖處理
- 預防死鎖:破壞產生死鎖的4個必要條件中的一個或者多個;實作起來比較簡單,但是如果限制過于嚴格會降低系統資源利用率以及吞吐量
- 避免死鎖:在資源的動態分配中,防止系統進入不安全狀態(可能產生死鎖的狀態)-如銀行家演算法
- 檢測死鎖:允許系統運行程序中產生死鎖,在死鎖發生之后,采用一定的演算法進行檢測,并確定與死鎖相關的資源和行程,采取相關方法清除檢測到的死鎖,實作難度大
- 解除死鎖:與死鎖檢測配合,將系統從死鎖中解脫出來(撤銷行程或者剝奪資源),對檢測到的和死鎖相關的行程以及資源,通過撤銷或者掛起的方式,釋放一些資源并將其分配給處于阻塞狀態的行程,使其轉變為就緒態,實作難度大
什么是銀行家演算法?
銀行家演算法(Banker’s Algorithm)是一個避免死鎖(Deadlock)的著名演算法,是由艾茲格·迪杰斯特拉在1965年為T.H.E系統設計的一種避免死鎖產生的演算法,它以銀行借貸系統的分配策略為基礎,判斷并保證系統的安全運行,
銀行家演算法的實作思想:
- 允許行程動態地申請資源,系統在每次實施資源分配之前,先計算資源分配的安全性,若此次資源分配安全(即資源分配后,系統能按某種順序來為每個行程分配其所需的資源,直至最大需求,使每個行程都可以順利地完成),便將資源分配給行程,否則不分配資源,讓行程等待,
作業系統分類
批處理作業系統、分時作業系統(Unix)、實時作業系統、網路作業系統、分布式作業系統、微機作業系統(Linux、Windows、IOS等)、嵌入式作業系統,

三、計算機網路
網路層次劃分
為了使不同計算機廠家生產的計算機能夠相互通信,以便在更大的范圍內建立計算機網路,國際標準化組織(ISO)在1978年提出了"開放系統互聯參考模型",即著名的OSI/RM模型(Open System Interconnection/Reference Model),它將計算機網路體系結構的通信協議劃分為七層,自下而上依次為:
- 物理層(Physics Layer)、資料鏈路層(Data Link Layer)、網路層(Network
Layer)、傳輸層(Transport Layer)、會話層(Session Layer)、表示層(Presentation
Layer)、應用層(Application Layer),
其中第四層完成資料傳送服務,上面三層面向用戶,除了標準的OSI七層模型以外,常見的網路層次劃分還有TCP/IP四層協議以及TCP/IP五層協議
TCP/IP協議
TCP/IP協議是Internet最基本的協議、Internet國際互聯網路的基礎,由網路層的IP協議和傳輸層的TCP協議組成,通俗而言:TCP負責發現傳輸的問題,一有問題就發出信號,要求重新傳輸,直到所有資料安全正確地傳輸到目的地,而IP是給因特網的每一臺聯網設備規定一個地址,
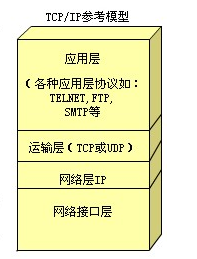
應用層:
- 向用戶提供一組常用的應用程式,比如電子郵件、檔案傳輸訪問、遠程登錄等,遠程登錄TELNET使用TELNET協議提供在網路其它主機上注冊的介面,TELNET會話提供了基于字符的虛擬終端,檔案傳輸訪問FTP使用FTP協議來提供網路內機器間的檔案拷貝功能,
傳輸層:
- 提供應用程式間的通信,其功能包括:一、格式化資訊流;二、提供可靠傳輸,為實作后者,傳輸層協議規定接收端必須發回確認,并且假如分組丟失,必須重新發送,
網路層 :
- 負責相鄰計算機之間的通信,
網路介面層:
- 這是TCP/IP軟體的最低層,負責接收IP資料報并通過網路發送之,或者從網路上接收物理幀,抽出IP資料報,交給IP層,
IP地址
IP地址是IP協議提供的一種統一的地址格式,它為互聯網上的每一個網路和每一臺主機分配一個邏輯地址,以此來屏蔽物理地址的差異,
首先出現的IP地址是IPV4,它只有4段數字,每一段最大不超過255,由于互聯網的蓬勃發展,IP位址的需求量愈來愈大,使得IP位址的發放愈趨嚴格,各項資料顯示全球IPv4位址可能在2005至2010年間全部發完(實際情況是在2019年11月25日IPv4位地址分配完畢),地址空間的不足必將妨礙互聯網的進一步發展,為了擴大地址空間,擬通過IPv6重新定義地址空間,IPv6采用128位地址長度,在IPv6的設計程序中除了一勞永逸地解決了地址短缺問題以外,還考慮了在IPv4中解決不好的其它問題,
DNS協議是什么?
DNS是域名系統(DomainNameSystem)的縮寫,該系統用于命名組織到域層次結構中的計算機和網路服務,可以簡單地理解為將URL轉換為IP地址,域名是由圓點分開一串單詞或縮寫組成的,每一個域名都對應一個惟一的IP地址,在Internet上域名與IP地址之間是一一對應的,DNS就是進行域名決議的服務器,
DNS命名用于Internet等TCP/IP網路中,通過用戶友好的名稱查找計算機和服務,
NAT協議是什么?
NAT網路地址轉換(Network Address Translation)屬接入廣域網(WAN)技術,是一種將私有(保留)地址轉化為合法IP地址的轉換技術,它被廣泛應用于各種型別Internet接入方式和各種型別的網路中,
原因很簡單,NAT不僅完美地解決了lP地址不足的問題,而且還能夠有效地避免來自網路外部的攻擊,隱藏并保護網路內部的計算機,
DHCP協議是什么?
DHCP動態主機設定協議(Dynamic Host Configuration Protocol)是一個局域網的網路協議,
使用UDP協議作業,主要有兩個用途:
- 給內部網路或網路服務供應商自動分配IP地址
- 給用戶或者內部網路管理員作為對所有計算機作中央管理的手段

四、資料結構
一些概念
資料
- 所有能被輸入到計算機中,且能被計算機處理的符號的集合,是計算機操作的物件的總稱,
資料元素
- 資料(集合)中的一個“個體”,資料及結構中討論的基本單位
資料項
- 資料的不可分割的最小單位,一個資料元素可由若干個資料項組成,
資料型別
- 在一種程式設計語言中,變數所具有的資料種類,整型、浮點型、字符型等等
邏輯結構
- 資料之間的相互關系
演算法五個特性
有窮性、確定性、可行性、輸入、輸出
演算法設計要求
正確性、可讀性、健壯性、高效率與低存盤量需求,(好的演算法)
時間復雜度
演算法的執行時間與原操作執行次數之和成正比,時間復雜度有小到大:O(1)、O(logn)、O(n)、O(nlogn)、O(n2)、O(n3),冪次時間復雜度有小到大O(2n)、O(n!)、O(nn)
空間復雜度
若輸入資料所占空間只取決于問題本身,和演算法無關,則只需要分析除輸入和程式之外的輔助變數所占額外空間,
物理結構/存盤結構
資料在計算機中的表示,物理結構是描述資料具體在記憶體中的存盤(如:順序結構、鏈式結構、索引結構、哈希結構)等

五、演算法
貪心演算法
在對問題求解時,總是做出在當前看來是最好的選擇,也就是說,不從整體最優上加以考慮,他所做出的是在某種意義上的區域最優解,
從問題的某一個初始解出發一步一步地進行,根據某個優化測度,每一步都要確保能獲得區域最優解,每一步只考慮一個資料,他的選取應該滿足區域優化的條件,若下一個資料和部分最優解連在一起不再是可行解時,就不把該資料添加到部分解中,直到把所有資料列舉完,或者不能再添加演算法停止,
基本思路
- 建立數學模型來描述問題
- 把求解的問題分成若干個子問題
- 對每個子問題求解,得到子問題的區域最優解
- 把子問題的解區域最優解合成原來問題的一個解
存在的問題
- 不能保證求得的最后解是最佳的
- 不能用來求最大值或最小值的問題
- 只能求滿足某些約束條件的可行解的范圍
貪心策略適用的前提是:區域最優策略能導致產生全域最優解,
實際上,貪心演算法適用的情況很少,一般對一個問題分析是否適用于貪心演算法,可以先選擇該問題下的幾個實際資料進行分析,就可以做出判斷,
貪心演算法的實作框架
從問題的某一初始解出發;
while (能朝給定總目標前進一步)
{
利用可行的決策,求出可行解的一個解元素;
}
由所有解元素組合成問題的一個可行解;
例題:
[背包問題]
有一個背包,背包容量是M=150,有7個物品,物品可以分割成任意大小, 要求盡可能讓裝入背包中的物品總價值最大,但不能超過總容量, 物品
A B C D E F G 重量 35 30 60 50 40 10 25 價值 10 40 30 50 35 40 30
這個例子,可以說很經典,
分析:
目標函式: ∑pi最大
約束條件是裝入的物品總重量不超過背包容量,即∑wi<=M( M=150)
(1)根據貪心的策略,每次挑選價值最大的物品裝入背包,得到的結果是否最優?
(2)每次挑選所占重量最小的物品裝入是否能得到最優解?
(3)每次選取單位重量價值最大的物品,成為解本題的策略?
貪心演算法是很常見的演算法之一,這是由于它簡單易行,構造貪心策略簡單,但是,它需要證明后才能真正運用到題目的演算法中,一般來說,貪心演算法的證明圍繞著整個問題的最優解一定由在貪心策略中存在的子問題的最優解得來的,
對于本例題中的3種貪心策略,都無法成立,即無法被證明,解釋如下:
(1)貪心策略:選取價值最大者,反例:
W=30
物品:A B C
重量:28 12 12
價值:30 20 20
根據策略,首先選取物品A,接下來就無法再選取了,可是,選取B、C則更好,
(2)貪心策略:選取重量最小,它的反例與第一種策略的反例差不多,
(3)貪心策略:選取單位重量價值最大的物品,反例:
W=30
物品:A B C
重量:28 20 10
價值:28 20 10
根據策略,三種物品單位重量價值一樣,程式無法依據現有策略作出判斷,如果選擇A,則答案錯誤,
值得注意的是,貪心演算法并不是完全不可以使用,貪心策略一旦經過證明成立后,它就是一種高效的演算法,比如,求最小生成樹的Prim演算法和Kruskal演算法都是漂亮的貪心演算法,
[最大整數]
設有n個正整數,將它們連接成一排,組成一個最大的多位整數,
例如:n=3時,3個整數13,312,343,連成的最大整數為34331213,
又如:n=4時,4個整數7,13,4,246,連成的最大整數為7424613, 輸入:n N個數 輸出:連成的多位數
演算法分析:
此題很容易想到使用貪心法,在考試時有很多同學把整數按從大到小的順序連接起來,測驗題目的例子也都符合,但最后測驗的結果卻不全對,按這種標準,我們很容易找到反例:12,121應該組成12121而非12112,那么是不是相互包含的時候就從小到大呢?也不一定,如12,123就是12312而非12123,這種情況就有很多種了,是不是此題不能用貪心法呢?
其實此題可以用貪心法來求解,只是剛才的標準不對,正確的標準是:先把整數轉換成字串,然后在比較a+b和b+a,如果a+b>=b+a,就把a排在b的前面,反之則把a排在b的后面,
@Test
public void testMaxNum() {
//有n個正整數,將它們連接成一排,組成一個最大的多位整數
//12112錯誤
//12121正解
// int[] nums = {12, 121};
int[] nums = {12, 123};
String result = maxNum(nums);
System.out.println("組成最大整數:" + result);
}
/**
* 根據給定的整陣列成最大的多位數
* @param nums
*/
public String maxNum(int[] nums) {
String result = "";
for (int i = 0; i < nums.length; i++) {
String num1 = nums[i] + "";
for (int j = 1; j < nums.length; j++) {
String num2 = nums[j] + "";
if ((num1 + num2).compareTo(num2 + num1) < 0) {
int temp = nums[j];
nums[j] = nums[i];
nums[i] = temp;
}
}
}
for (int i = 0; i < nums.length; i++) {
result += nums[i];
}
return result;
}
【紙幣找零問題】
假設1元、2元、5元、10元、20元、50元、100元的紙幣,張數不限制,現在要用來支付K元,至少要多少張紙幣?
代碼如下
public static void greedyGiveMoney(int money) {
System.out.println("需要找零: " + money);
int[] moneyLevel = {1, 5, 10, 20, 50, 100};
for (int i = moneyLevel.length - 1; i >= 0; i--) {
int num = money/ moneyLevel[i];
int mod = money % moneyLevel[i];
money = mod;
if (num > 0) {
System.out.println("需要" + num + "張" + moneyLevel[i] + "塊的");
}
}
}
(1)如果不限制紙幣的金額,那這種情況還適合用貪心演算法么,比如1元,2元,3元,4元,8元,15元的紙幣,用來支付K元,至少多少張紙幣?
經我們分析,這種情況是不適合用貪心演算法的,因為我們上面提供的貪心策略不是最優解,比如,紙幣1元,5元,6元,要支付10元的話,按照上面的演算法,至少需要1張6元的,4張1元的,而實際上最優的應該是2張5元的,
(2)如果限制紙幣的張數,那這種情況還適合用貪心演算法么,比如1元10張,2元20張,5元1張,用來支付K元,至少多少張紙幣?
同樣,仔細想一下,就知道這種情況也是不適合用貪心演算法的,比如1元10張,20元5張,50元1張,那用來支付60元,按照上面的演算法,至少需要1張50元,10張1元,而實際上使用3張20元的即可;
(3)所以貪心演算法是一種在某種范圍內,區域最優的演算法,
六、資料庫
什么是事務?
事務是應用程式中一系列嚴密的操作,所有操作必須成功完成,否則在每個操作中所作的所有更改都會被撤消,也就是事務具有原子性,一個事務中的一系列的操作要么全部成功,要么一個都不做,
事務的結束有兩種,當事務中的所以步驟全部成功執行時,事務提交,如果其中一個步驟失敗,將發生回滾操作,撤消撤消之前到事務開始時的所以操作,
事務四大特性
原子性( Atomicity )、一致性( Consistency )、隔離性( Isolation )和持續性( Durability)
原子性,要么執行,要么不執行
隔離性,所有操作全部執行完以前其它會話不能看到程序
一致性,事務前后,資料總額一致
持久性,一旦事務提交,對資料的改變就是永久的
MySQL的四種隔離級別來源
讀未提交
就是一個事務可以讀取另一個未提交事務的資料,
事例:老板要給程式員發工資,程式員的工資是3.6萬/月,但是發工資時老板不小心按錯了數字,按成3.9萬/月,該錢已經打到程式員的戶口,但是事務還沒有提交,就在這時,程式員去查看自己這個月的工資,發現比往常多了3千元,以為漲工資了非常高興,但是老板及時發現了不對,馬上回滾差點就提交了的事務,將數字改成3.6萬再提交,
分析:實際程式員這個月的工資還是3.6萬,但是程式員看到的是3.9萬,他看到的是老板還沒提交事務時的資料,這就是臟讀,
讀提交
就是一個事務要等另一個事務提交后才能讀取資料,
事例:程式員拿著信用卡去享受生活(卡里當然是只有3.6萬),當他埋單時(程式員事務開啟),收費系統事先檢測到他的卡里有3.6萬,就在這個時候!!程式員的妻子要把錢全部轉出充當家用,并提交,當收費系統準備扣款時,再檢測卡里的金額,發現已經沒錢了(第二次檢測金額當然要等待妻子轉出金額事務提交完),程式員就會很郁悶,明明卡里是有錢的…
分析:這就是讀提交,若有事務對資料進行更新(UPDATE)操作時,讀操作事務要等待這個更新操作事務提交后才能讀取資料,可以解決臟讀問題,但在這個事例中,出現了一個事務范圍內兩個相同的查詢卻回傳了不同資料,這就是不可重復讀,
重復讀
就是在開始讀取資料(事務開啟)時,不再允許修改操作,
事例:程式員拿著信用卡去享受生活(卡里當然是只有3.6萬),當他買單時(事務開啟,不允許其他事務的UPDATE修改操作),收費系統事先檢測到他的卡里有3.6萬,這個時候他的妻子不能轉出金額了,接下來收費系統就可以扣款了,
分析:重復讀可以解決不可重復讀問題,寫到這里,應該明白的一點就是,不可重復讀對應的是修改,即UPDATE操作,但是可能還會有幻讀問題,因為幻讀問題對應的是插入INSERT操作,而不是UPDATE操作,
序列化
Serializable 是最高的事務隔離級別,在該級別下,事務串行化順序執行,可以避免臟讀、不可重復讀與幻讀,但是這種事務隔離級別效率低下,比較耗資料庫性能,一般不使用,
MySQL的索引
| 索引 | 區別 |
|---|---|
| Hash | hash索引,等值查詢效率高,不能排序,不能進行范圍查詢 |
| B+ | 資料有序,范圍查詢 |
索引的優缺點
- 索引最大的好處是提高查詢速度,
- 缺點是更新資料時效率低,因為要同時更新索引
- 對資料進行頻繁查詢進建立索引,如果要頻繁更改資料不建議使用索引,
InnoDB索引和MyISAM索引的區別
- 一是主索引的區別,InnoDB的資料檔案本身就是索引檔案,而MyISAM的索引和資料是分開的,
- 二是輔助索引的區別:InnoDB的輔助索引data域存盤相應記錄主

七、熱門框架技術
Spring
到目前為止,Spring 仍然是最流行的 Java 開發框架,并且幾乎應用在了所有地方 —— 從流媒體平臺到在線購物, 它的設計目的是為 基于 Java EE 平臺的 Java 應用程式創建后端,Spring 框架基于依賴注入的功能(控制元件反轉 IOC 的一部分),它是在 Java 中構建業務應用程式的理想解決方案:微服務、復雜的資料處理系統、云應用程式或快速、安全且回應迅速的 Web 應用程式, Spring 的特點是輕量級且易于實作和使用,生態非常活躍,因此完全可以預計 2021 年 Spring 將會更加普及,也會有更多強大的功能,對于 Java 開發者而言,Spring 仍然是不得不學的優秀框架,
Spring的初衷:
- 1、JAVA EE開發應該更加簡單,
- 2、使用介面而不是使用類,是更好的編程習慣,Spring將使用介面的復雜度幾乎降低到了零,
- 3、為JavaBean提供了一個更好的應用配置框架,
- 4、更多地強調面向物件的設計,而不是現行的技術如JAVA EE,
- 5、盡量減少不必要的例外捕捉,
- 6、使應用程式更加容易測驗,
Spring的目標:
- 1、可以令人方便愉快的使用Spring,
- 2、應用程式代碼并不依賴于Spring APIs,
- 3、Spring不和現有的解決方案競爭,而是致力于將它們融合在一起,
Spring的基本組成:
- 1、最完善的輕量級核心框架,
- 2、通用的事務管理抽象層,
- 3、JDBC抽象層,
- 4、集成了Toplink, Hibernate, JDO, and iBATIS SQL Maps,
- 5、AOP功能,
- 6、靈活的MVC Web應用框架,
八、微服務分布式架構
微服務的誕生
微服務是基于分而治之的思想演化出來的,過去傳統的一個大型而又全面的系統,隨著互聯網的發展已經很難滿足市場對技術的需求,于是我們從單獨架構發展到分布式架構,又從分布式架構發展到 SOA 架構,服務不斷的被拆分和分解,粒度也越來越小,直到微服務架構的誕生,
分布式事務
分布式事務顧名思義就是要在分布式系統中實作事務,它其實是由多個本地事務組合而成,
分布式事務場景如何設計系統架構及解決資料一致性問題,個人理解最終方案把握以下原則就可以了,那就是:大事務=小事務(原子事務)+異步(訊息通知),解決分布式事務的最好辦法其實就是不考慮分布式事務,將一個大的業務進行拆分,整個大的業務流程,轉化成若干個小的業務流程,然后通過設計補償流程從而考慮最終一致性,
九、服務器中間件
RocketMQ:
為什么使用mq?具體的使用場景是什么?
mq的作用很簡單,削峰填谷,以電商交易下單的場景來說,正向交易的程序可能涉及到創建訂單、扣減庫存、扣級訓動預算、扣級訓分等等,每個介面的耗時如果是100ms,那么理論上整個下單的鏈路就需要耗費400ms,這個時間顯然是太長了,
如果這些操作全部同步處理的話,首先呼叫鏈路太長影響介面性能,其次分布式事務的問題很難處理,這時候像扣減預算和積分這種對實時一致性要求沒有那么高的請求,完全就可以通過mq異步的方式去處理了,同時,考慮到異步帶來的不一致的問題,我們可以通過job去重試保證介面呼叫成功,而且一般公司都會有核對的平臺,比如下單成功但是未扣級訓分的這種問題可以通過核對作為兜底的處理方案,
使用mq之后我們的鏈路變簡單了,同時異步發送訊息我們的整個系統的抗壓能力也上升了,
異步,解耦,消峰,MQ的三大主要應用場景,
異步處理
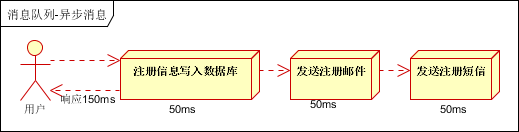
用戶注冊后,需要發送注冊郵件和注冊短信,傳統的做法:
將注冊資訊寫入資料庫成功后,發送注冊郵件,再發送注冊短信,以上三個任務全部完成后,回傳給客戶端
引入訊息佇列(mq),異步處理,
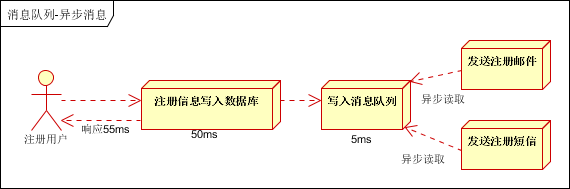
應用解耦
交易系統作為淘寶/天貓主站最核心的系統,每筆交易訂單資料的產生會引起幾百個下游業務系統的關注,包括物流、購物車、積分、流計算分析等等,整體業務系統龐大而且復雜,訊息佇列
MQ 可實作異步通信和應用解耦,確保主站業務的連續性,
削峰填谷
諸如秒殺、搶紅包、企業開門紅等大型活動時皆會帶來較高的流量脈沖,或因沒做相應的保護而導致系統超負荷甚至崩潰,或因限制太過導致請求大量失敗而影響用戶體驗,訊息佇列 MQ 可提供削峰填谷的服務來解決該問題,
十、前沿技術
架構&云計算
2020 年,微服務領域出現了一個新詞匯:“宏服務”(Macro Services)由Uber團隊提出,宏服務其實并不是一個全新的架構,而是一種在單體和微服務間取得平衡的理念,
目前,微服務的發展增加了系統的復雜性,微服務日趨細化、復用率達到頂峰,服務之間的關系變得愈加復雜,維護成本增加,在這種情況下,技術人員提出了“宏服務”,它只是個整體式程式,其中所有業務服務都作為單個程式包部署在應用程式服務器中,并共享同一個資料庫(物理上和邏輯上),它不太復雜,服務之間奉行緊密耦合,
2021 年,化繁為簡仍然會是微服務的重點課題,
腦機介面幫助人類超越生物學極限
鏈接

大資料&人工智能
隨著 IT 基礎設施加速往云上遷移,云原生正在成為新一代資料架構的主流標準,越來越多企業客戶從 On-Premise 的數倉方案轉向基于云(包含公有云和私有云)的解決方案,這種趨勢在美國toB市場已經被廣泛接受,在國內toB 市場也方興未艾,新的一年大資料與云的融合還會繼續加深,大資料領域將加速擁抱“融合”或“一體化”演進的新方向,
總結
俗話說是笨鳥先飛,我還得笨鳥多飛《活著》

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296867.html
標籤:java
上一篇:SpringBoot2.5解決跨域問題2021年秋季新方法 SpringBoot+Vue前后端分離解決session不一致的問題