歡迎進來學習的小伙伴,本文將會帶你揭開真相~
【學習背景】
不管你是學生,還是職場小白,還是入行Java幾年的小伙伴,相信很多小伙伴在面試Java作業崗位時,發現
LinkedList和ArrayList這兩者相關的問題基本是必面的~
但是當面試官問到LinkedList和ArrayList的區別時,可能很多準備得不夠充分的小伙伴第一反應給出的回答僅僅是這樣的:
- LinkedList底層資料結構是鏈表,添加和洗掉元素效率比ArrayList高~
- ArrayList底層資料結構是陣列,查詢效率比LinkedList高~
有點毛病,而且僅僅是這樣回答,面試官可能不會懟你,但是肯定是不滿意的哇,也可能會繼續問:
面試官:哦,還有嗎?
應聘者:沒了~
面試官:大意了啊,你說的效率高是有通過JMH驗證尾插法添加元素的效率嗎?
應聘者:尾插法???
面試官:嗯,從資料結構的尾部添加資料,不過這里先不試了,回去再自己學習驗證下結論吧~
應聘者:哦…[臉紅emoj]…

回本正題,那么本文最主要目的就是通過JMH工具驗證LinkedList添加元素真的比ArrayList快嗎?
可能有些小伙伴會問JMH是啥?直接使用 for回圈+時間戳System.currentTimeMillis() 盤它看看效率不行嗎? 我想說的是你的想法針不戳,但針滴不行啊,你可以百度看看為啥,進入正文吧,JMH屬于Oracle官方Open JDK提供的一款性能測驗工具,文中會進行介紹~
當然除了這個問題,本文也會將ArrayList和LinkedList進行分析和面試總結,加深對這兩者的認識,也希望能幫助到有需要的小伙伴~
學習目錄
- 一、ArrayList和LinkedList
- 1.1 ArrayList
- 1.1.1 ArrayList特性
- 1.1.2 ArrayList常用API
- 1.1.3 ArrayList常見面試題(附參考答案)
- 1.2 LinkedList
- 1.2.1 LinkedList特性
- 1.2.2 LinkedList常用API
- 1.2.3 LinkedList常見面試題(附參考答案)
- 二、JMH測驗ArrayList和LinkedList性能
- 2.1 JMH是什么?
- 2.2 JMH應用場景?
- 2.3 JMH測驗ArrayList和LinkedList(揭開真相)
- 2.3.1 代碼實作
- 2.3.2 結果分析
- 2.3.3 結果分析(圖形)
- 2.3.4 真相總結
- 附錄
進入正文~
一、ArrayList和LinkedList
1.1 ArrayList
1.1.1 ArrayList特性
- ? 繼承
AbstractList抽象類,實作List介面,還實作了RandomAccess快速隨機訪問以及Cloneable, java.io.Serializable克隆和序列化- ? 底層資料結構是陣列,連續記憶體空間,使用for回圈遍歷效率最高,尾部添加和洗掉元素時效率也很高,非執行緒安全
- ? 陣列容量動態自增,當容量大于當前陣列容量時進行擴容,容量大小增加50%,每次擴容都會開辟新空間,并且進行新老陣列的復制重排
- ? 【JDK1.7之前版本】擴容后容量大小比【JDK1.7及之后版本】多1個容量
JDK1.7之前版本擴容關鍵原始碼
int newCapacity = (oldCapacity * 3)/2 + 1 )
JDK1.7及之后版本擴容關鍵原始碼(PS:>>右移相當于除2的n次方,<<左移相當于乘2的n次方)
int newCapacity = oldCapacity + (oldCapacity >> 1)
1.1.2 ArrayList常用API
- ?增:效率
add(E e) > add(int index,E element)- ?刪:效率
remove(E e) < remove(int index)- ?改:
set(int index,E element)- ?查:
get(int index)
1.1.3 ArrayList常見面試題(附參考答案)
(1)ArrayList實作了RandomAccess介面,但是實際介面中什么都沒做,它有什么作用嗎?
RandomAccess是Java中的一個標志介面,只要實作該介面,就擁有快速隨機訪問的特性,
(2)ArrayList幾個重要屬性各自的含義?
ArrayList底層主要屬性有elementData物件陣列、size集合大小(陣列中已存盤的元素個數,非陣列容量大小)、DEFAULT_CAPACITY默認容量為10(new實體化時陣列初始化容量大小為0,執行add添加元素時才指定初始化容量為DEFAULT_CAPACITY)~
(3)ArrayList 屬性elementData陣列使用了transient修飾,作用是什么?
- 使用
transient關鍵詞修飾屬性,表示不能被外部方法序列化ArrayList的elementData陣列是動態擴容的,并非所有被分配的記憶體空間都存盤了資料,如果采用外部序列化法實作序列化,那整個elementData都會被序列化ArrayList為了避免這些沒有存盤資料的記憶體空間被序列化,內部提供了兩個私有方法writeObject以及readObject來自我完成序列化與反序列化,從而在序列化與反序列化陣列時節省了空間和時間,
(4)?ArrayList如何添加元素效率最高?
ArrayList新增元素的方法有兩種,一種是直接添加元素,另外一種是添加元素到指定位置- 使用ArrayList的
add(E e)方法直接添加元素,默認將元素添加到陣列尾部,在沒有發生擴容的情況下,不會有陣列的復制重排程序,效率最高- 添加元素到指定位置,會導致在該位置后的所有元素都需要進行復制排列,時間復雜度
O(n)-線性復雜度,效率不高- 所以,如果在
ArrayList初始化時指定合適的陣列容量大小,直接添加元素到陣列尾部,那么ArrayList添加元素的效率反而比LinkedList高
(5)?ArrayList使用哪種方式遍歷查找效率最高?
ArrayList使用for回圈遍歷查找效率最高,因為ArrayList底層資料結構為陣列,陣列是一塊連續記憶體的空間,并且ArrayList實作了RandomAccess介面標志,意味著ArrayList擁有快速隨機訪問特性,對于元素的查找,時間復雜度為O(1)-常數復雜度,效率最高,
(6)?ArrayList在foreach回圈或迭代器遍歷中,呼叫自身的remove(E e)方法洗掉元素,會導致什么問題?
- 會拋
ConcurrentModificationException例外,原因是集合修改次數modCount和迭代器期望修改次數expectedModCount不一致- foreach回圈相當于迭代器,在迭代器遍歷中,使用
ArrayList自身的remove(E e)方法洗掉元素,內部會進行modCount++,但并不會進行迭代器的expectedModCount++,因此導致進入下一趟遍歷呼叫迭代器的next()方法中,內部比對兩者不一致拋出ConcurrentModificationException例外- 目前開發規范都是禁止在迭代器中使用集合自身的
remove/add方法,如果要在回圈中洗掉元素,應該使用迭代器的remove洗掉,也可以使用for回圈進行remove洗掉元素,不過需要角標減1(i--)
(7)?ArrayList初始化容量大小足夠的情況下,相比于LinkedList在頭部、中間、尾部添加的效率如何?
- 頭部:
ArrayList底層結構是陣列,陣列是一塊連續的記憶體空間,添加元素到陣列頭部時,需要對頭部以后的所有資料進行復制重排,時間復雜度為O(n)LinkedList底層結構是鏈表,添加元素到頭部時,會先通過二分法查找找到指定位置的節點元素,而頭部處于前半部分第一個,找到節點就回傳,再進行新節點創建和指標變換,時間復雜度為O(logN)-對數復雜度- 中間:
ArrayList添加元素到陣列中間,往后的所有資料需要都進行復制重排,時間復雜度為O(n);LinkedList添加元素到中間,二分法查找發揮的作用最低,不論從前往后,還是從后往前,鏈表被回圈遍歷的次數都是最多的,效率最低,時間復雜度為O(n)- 結尾:
ArrayList添加元素尾部,不需要進行復制重排陣列資料,效率最高,時間復雜度為O(1)LinkedList添加元素到尾部,不需要查找元素,效率最高,但是多了新節點物件創建以及變換指標指向物件的程序,效率比ArrayList低一些,時間復雜度為O(1)
(8)?ArrayList為什么是非執行緒安全的?
- 因為
ArrayList添加元素時,主要會進行這兩步操作,一是判斷陣列容量是否滿足大小,二是在陣列對應位置賦值,這2步操作在多執行緒訪問時都存在安全隱患- 第1個隱患是,判斷陣列容量是否滿足大小的
ensureCapacityInternal(size+1)方法中,可能多個執行緒會讀取到相同的size值,如果第1個執行緒傳入size+1進行判斷容量時,剛好滿足容量大小,就不會進行擴容,同理,其他執行緒也不會進行擴容,這樣就會導致進行下一步其他執行緒在陣列對應位置賦值時,拋出陣列下標越界ArrayIndexOutOfBoundsException例外- 第2個隱患是,在陣列對應位置賦值
elementData [size++] = e; 實際上會被分解成兩步進行,先賦值elementData [size] = e;再進行size=size+1;可能第1個執行緒剛賦值完,還沒進行size+1,其他執行緒又對同一位置進行賦值,導致前面執行緒添加的元素值被覆寫,
1.2 LinkedList
1.2.1 LinkedList特性
- ?繼承
AbstractSequentialList抽象類,實作了List介面,還實作了Deque雙向佇列以及Cloneable, java.io.Serializable克隆和序列化- ?底層資料結構是雙向鏈表,在頭部和尾部添加、洗掉元素效率比較高,非執行緒安全
- ?JDK1.7后
Entry<E> header屬性被替換為Node<E> first和Node last`首尾節點屬性
替換3點優勢:
first/last屬性能更清晰地表達鏈表的鏈頭和鏈尾概念first/last方式可以在初始化LinkedList的時候節省new一個Entryfirst/last方式最重要的性能優化是鏈頭和鏈尾的插入洗掉操作更加快捷了,
1.2.2 LinkedList常用API
- ?增:效率
add(E e) > add(int index,E element)- ?刪:效率
remove(E e) < remove(int index)- ?改:
set(int index,E element)- ?查:
get(int index)
1.2.3 LinkedList常見面試題(附參考答案)
(1)LinkedList為什么不能實作RandomAccess介面?
- 因為LinkedList底層資料結構是鏈表,記憶體地址不連續,只能通過指標來定位,不支持隨機快速訪問,所以不能實作
RandomAccess介面
(2)LinkedList幾個重要屬性各自的含義?
LinkedList底層主要屬性有size集合大小(鏈表長度)、first鏈表頭部節點、last鏈表尾部節點,并且也都使用transient修飾,表示不能外部序列化與反序列化,內部自己實作了序列化與反序列化,
(3)LinkedList默認添加元素是怎么實作的?
LinkedList添加元素的方法主要有直接添加和指定位置添加- 直接添加元素有
add(E e)方法和addAll(Collection c)方法,指定位置添加元素有add(int index,E element)、addAll(int index,Collection c)方法- 直接添加元素默認添加到鏈表尾部,不需要先查找節點,直接通過尾部節點,創建新節點和變換指標指向新節點
- 指定位置添加元素,會先使用二分法查找到該位置對應的節點,再通過該節點,創建新節點和變換指標指向新節點
(4)LinkedList使用哪種方式遍歷效率最高?
- LinkedList底層資料結構是雙向鏈表的,使用
foreach回圈或iterator迭代器遍歷效率最高,通過迭代器的hasNext()、next()快速遍歷- 需要注意的是盡量避免使用
for回圈遍歷LinkedList,因為每一次回圈,都會使用二分法查找到指定位置的節點,效率極其低下,
(5)LinkedList使用Iterator迭代器遍歷時,進行remove(E e)操作,迭代器的指標會發生什么變化?
LinkedList使用迭代器遍歷,內部自己實作的是ListIterator介面,主要有lastReturned最后回傳節點、next下一節點、nextIndex下一指標以及expectedModCount期望修改次數4個重要屬性,其中nextIndex下一指標從0開始LinkedList迭代器遍歷時,每進行一趟遍歷,都會經過hasNext()、next()操作,并且在next()方法中,進行了nextIndex++操作- 當進行到某一趟遍歷,呼叫
remove()進行操作元素,會通過lastReturned進行解鏈,并且將next = lastReturned和nextIndex--操作,也就是迭代器的下一指標會減一
(6)LinkedList默認位置添加元素和指定位置添加元素分別怎么實作,哪種性能更高?
LinkedList使用add(E e)方法添加元素時,會默認添加到尾部位置,時間復雜度是O(1)-常數復雜度,效率最高,
(7)List集合迭代器遍歷使用Iterator和ListIterator有什么不同?
- 都是迭代器,都可以用來遍歷對應的實作類
Iterator允許遍歷所有實作Iterator介面的實作類,而ListIterator只能遍歷List集合- 兩者都有
hasNext()、next()、remove()方法正向操作串列,ListIterator還可以進行逆向操作串列和往集合中添加元素
二、JMH測驗ArrayList和LinkedList性能
2.1 JMH是什么?
官方介紹
簡單介紹
JMH全稱Java Microbenchmark Harness(Java微基準套件),是Oracle 官方Open JDK提供的一款Java微基準性能測驗工具,主要是基于方法層面的基準測驗,納秒級精確度~
2.2 JMH應用場景?
【典型應用】
- 精確驗證某個方法執行時間
- 測驗介面不同實作的吞吐量
- 等等…
日常開發及優化Java代碼時,當定位到熱點方法,想進一步優化熱點方法的性能時,可以通過JHM精確驗證某個方法執行時間,根據測驗結果不斷進行優化~
2.3 JMH測驗ArrayList和LinkedList(揭開真相)
應用場景不在于有多少,在于你用不用得到,這里我們就利用JMH精確驗證某個方法執行時間,來驗證本文的主題LinkedList添加元素真的比ArrayList快?
大致思路:
分別實作
LinkedList和ArrayList默認添加元素即尾部添加元素的方法~
利用JMH分別對兩個方法進行基準測驗,根據測驗結果進行分析性能~
2.3.1 代碼實作
(1)添加依賴
需要依賴jmh-core和jmh-generator-annprocess兩個架包,可以去Maven官網下載~
Maven工程直接在pom.xml中添加依賴如下:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.26</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.26</version>
<scope>provided</scope>
</dependency>
(2)添加元素方法
package com.justin.java;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.Throughput) //基準測驗型別:吞吐量(單位時間內呼叫了多少次)
@OutputTimeUnit(TimeUnit.MILLISECONDS) //基準測驗結果的時間型別:毫秒
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) //預熱:2 輪,每次1秒
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS) //度量:測驗5輪,每輪1秒
@Fork(1) //Fork出1個執行緒來測驗
@State(Scope.Thread) // 每個測驗執行緒分配1個實體
public class ArrayAndLinkedJmhTest {
private List<Object> arrayList;
private List<Object> linkedList;
@Param({"10", "100", "1000"})
private int count; //分別測驗不同個數的添加元素
@Setup(Level.Trial)
public void init() {
arrayList = new ArrayList<>();
linkedList = new LinkedList<>();
}
public static void main(String[] args) throws RunnerException {
//啟動基準測驗
Options opt = new OptionsBuilder()
.include(ArrayAndLinkedJmhTest.class.getSimpleName()) //要匯入的測驗類
.output("C:\\Users\\Administrator\\Desktop\\ArrayAndLinkedJmhTest.log") //輸出測驗結果的檔案
.build();
//執行測驗
new Runner(opt).run();
}
@Benchmark
public void arrayListAddTest() {
for (int i = 0; i < count; i++) {
arrayList.add("Justin");
}
}
@Benchmark
public void linkedListAddTest() {
for (int i = 0; i < count; i++) {
linkedList.add("Justin");
}
}
}
注解說明
| 注解 | 說明 |
|---|---|
@BenchmarkMode(Mode.AverageTime) | 基準測驗型別: AverageTime表示平均時間 |
@OutputTimeUnit(TimeUnit.NANOSECONDS) | 基準測驗結果的時間型別:NANOSECONDS表示微秒 |
@Warmup(iterations = 5) | 預熱:iterations指定預熱迭代幾輪 |
@Measurement(iterations = 10) | 度量:iterations 指定迭代幾輪 |
@Fork(2) | Fork出2個執行緒來測驗 |
@State(Scope.Thread) | 每個測驗執行緒分配1個實體 |
@Param({"10", "100", "1000"}) | 指定某項引數的多種情況,數值根據實際給定 |
@Setup(Level.Trial) | 初始化方法,在全部Benchmark運行之前進行 |
@BenchmarkMode | 用在方法上,表示該方法要進行基準測驗,類似JUnit的@Test |
@TearDown(Level.Trial) | 結束方法,在全部Benchmark運行之后進行 |
更多官方Sample:
OpenJDK Samples
GitHub OpenJDK Samples
由于添加元素消耗的記憶體比較大,idea執行基準測驗程序中可能會出現記憶體泄露的報錯:java.lang.OutOfMemoryError: Java heap space
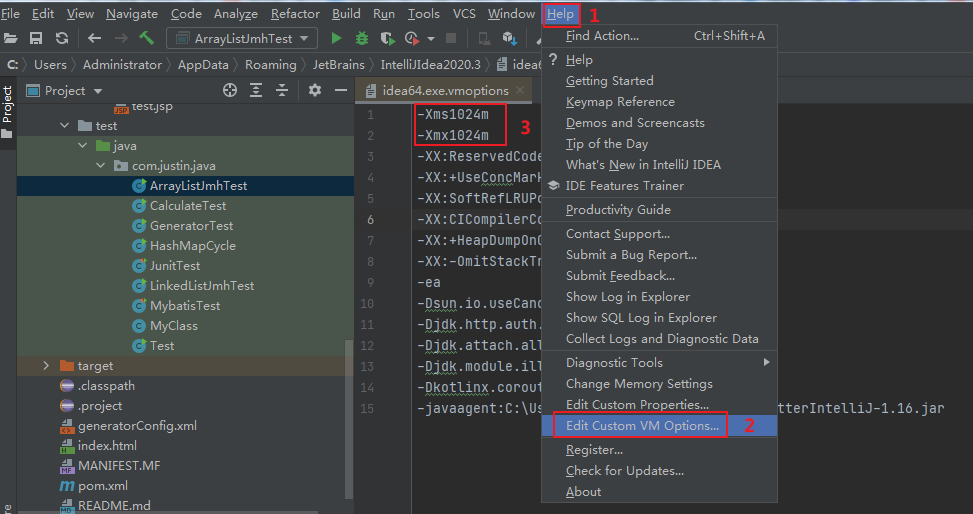
加大JVM的記憶體引數值即可,例如idea中調整方式:
Help -> Edit Custom VM Options…
2.3.2 結果分析
分析輸出的結果檔案ArrayAndLinkedJmhTest.log,輸出的內容很多,只要前面沒有error都不用管,直接拉到最后看Score結果~
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 74.287 ± 1.629 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 371.329 ± 23.952 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 3118.537 ± 38.943 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 95.773 ± 1.261 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 907.471 ± 13.856 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 8901.777 ± 108.044 ns/op
示例中我們使用注解的是@BenchmarkMode(Mode.AverageTime)和OutputTimeUnit(TimeUnit.NANOSECONDS),因此測驗的結果是ns/ops(每次呼叫需要多少微秒),每次呼叫添加相同的元素,平均時間越高,表明效率越低~
對應的結果指標是Score,可以看到ArrayList添加元素從少到多,效率都吊打LinkedList~
不過,細心的同學可能發現了,ArrayList之所以吊打LinkedList這么猛,是因為代碼中ArrayList指定了合適的初始化容量大小
List<Object> arrayList = new ArrayList<>(count);
加上添加元素默認是在尾部進行,可謂是如虎添翼,ArrayList底層資料結構是陣列,陣列是一塊連續的記憶體空間,從陣列尾部添加資料時,不需要進行任何陣列資料的復制重排,效率最高,時間復雜度為O(1)
ArrayList默認添加元素的關鍵原始碼
//關鍵原始碼1
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
...
//關鍵原始碼2
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
...
//關鍵原始碼3
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
...
//關鍵原始碼4
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
雖然LinkedList添加元素到尾部,也不需要查找元素,效率也是最高的,但是多了新節點物件創建以及變換指標指向物件的程序,時間復雜度為O(1)~
LinkedList默認添加元素原始碼
public boolean add(E e) {
linkLast(e);
return true;
}
...
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
OK,那么問題來了,ArrayList默認初始化容量,添加元素的效率還能吊打LinkedList嗎?
我們來測驗一下,首先修改測驗代碼中arrayListAddTest方法,去掉指定count~
List<Object> arrayList = new ArrayList<>();
ArrayList默認初始化容量添加元素,前面指定最大添加元素是1000數量級,測出的效率可能不是很明顯,我這里再加個10000級別的(跑的好慢,差不多半個小時)`
@Param({"10", "100", "1000","10000"})
private int count; //指定添加元素的不同個數,便于分析結果
重新跑一次,看測驗結果~
ArrayList默認容量大小的測驗結果:
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 59.312 ± 1.726 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 560.263 ± 25.140 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 5144.459 ± 156.745 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 10000 avgt 20 49326.440 ± 1810.873 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 100.151 ± 2.699 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 976.157 ± 55.646 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 9472.496 ± 314.018 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10000 avgt 20 91279.112 ± 2883.922 ns/op
比對前面的ArrayList指定合適容量大小的測驗結果:
Benchmark (count) Mode Cnt Score Error Units
ArrayAndLinkedJmhTest.arrayListAddTest 10 avgt 20 74.287 ± 1.629 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 100 avgt 20 371.329 ± 23.952 ns/op
ArrayAndLinkedJmhTest.arrayListAddTest 1000 avgt 20 3118.537 ± 38.943 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 10 avgt 20 95.773 ± 1.261 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 100 avgt 20 907.471 ± 13.856 ns/op
ArrayAndLinkedJmhTest.linkedListAddTest 1000 avgt 20 8901.777 ± 108.044 ns/op
可以看到ArrayList使用默認容量大小進行添加元素時,雖然ArrayList多了陣列擴容的程序,但是由于在尾部添加元素,效率還是比LinkedList添加元素效率高,只不過沒有指定合適初始化容量大小時差距那么明顯~
那么在什么情況下LinkedList才比ArrayList添加元素效率高?
答案是:頭部和中間添加元素~
ArrayList在資料結構頭部和中間添加元素比LinkedList效率低~
ArrayList越往陣列前面添加元素,效率越低,頭部添加資料,會導致后面的全部陣列元素都要進行賦值重排,效率最低~
LinkedList往陣列前面添加元素,效率也會變低,但是由于底層采用了二分查找(中間劃分,從前往后或從后往前遍歷查找位置)頭部和尾部添加元素的效率都是最高的,只有中間添加元素時,二分查找發揮的作用最小,因此效率最低~~
本文只驗證尾部添加元素(默認添加元素),頭部、尾部添加元素的效率對比,具體可以自行通過JMH驗證下~
2.3.3 結果分析(圖形)
前面JVM輸出的普通結果檔案,雖然拉到能直接看到結果,不過有點不太直觀,這里我們將 main方法的輸出檔案部分進行改造一下,重新執行輸出json結果檔案~
public static void main(String[] args) throws RunnerException {
//1、啟動基準測驗:輸出json結果檔案(用于查看可視化圖)
Options opt = new OptionsBuilder()
.include(ArrayAndLinkedJmhTest.class.getSimpleName()) //要匯入的測驗類
.result("C:\\Users\\Administrator\\Desktop\\ArrayAndLinkedJmhTest.json") //輸出測驗結果的json檔案
.resultFormat(ResultFormatType.JSON)//格式化json檔案
.build();
//2、執行測驗
new Runner(opt).run();
}
執行程序中可能看到ArrayAndLinkedJmhTest.json沒有寫入內容,不用管,最后執行完會重繪到檔案中~
根據json結果檔案利用以下推薦的圖形化工具展示圖形化結果~
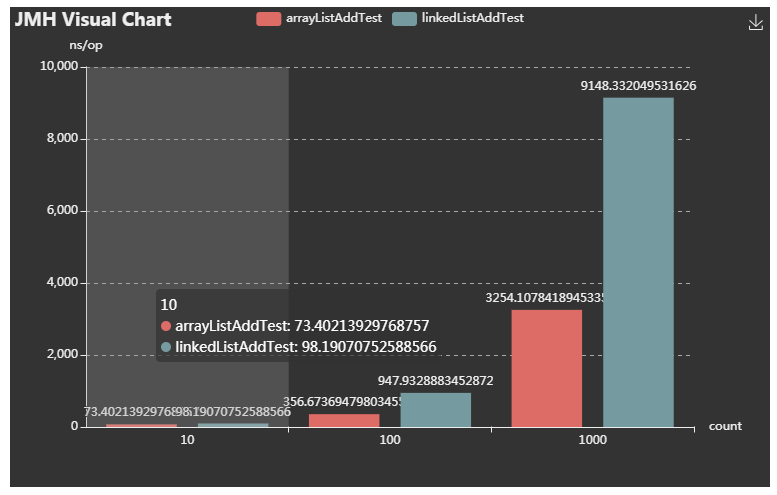
-
JMH Visual Chart:http://deepoove.com/jmh-visual-chart/
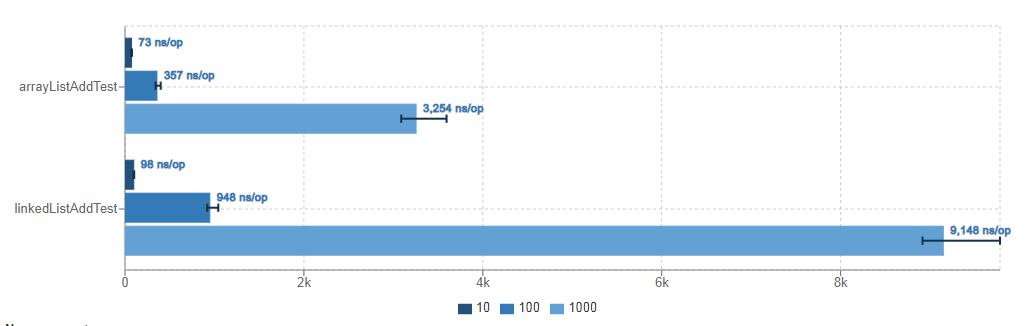
-
JMH Visualizer:https://jmh.morethan.io/
2.3.4 真相總結
LinkedList真的比ArrayList添加元素快嗎?
通過Oracle官方Open JDK提供的Java微基準測驗工具JMH進行測驗,結合ArrayList和LinkedList自身的特性總結真相如下:
(1)
LinkedList添加元素不一定比ArrayList添加元素快~
(2)ArrayList底層資料結構是陣列,陣列是一塊連續的記憶體空間,從陣列尾部添加資料時,不需要進行任何陣列資料的復制重排,效率最高,時間復雜度為O(1)~
(3)LinkedList添加元素到尾部,也不需要查找元素,效率也是最高的,時間復雜度為O(1),不過會有新節點物件創建以及變換指標指向物件的程序~
(4)兩者的添加元素的性能,通過Oracke官方Open JDK提供的JMH性能測驗工具測驗后發現,當ArrayList指定合適的初始化容量大小時,并且在資料結構尾部添加資料時,效率會遠遠大于LinkedList~
(5)但是實際開發當中,很多時候開發者撰寫new ArrayList實體化的代碼時,都沒有指定容量或者比較難預測到合適的初始化容量大小,添加元素時默認容量指定10,動態擴容,因此我也使用JMH對這種默認容量的情況進行測驗,不過發現即便不指定初始化容量大小,ArrayList添加元素效率還是比LinkedList添加元素效率高一些~
(6)最后再利用JMH在資料結構頭部和尾部進行添加元素測驗(我這里沒測,沒測的大家也可以假裝測了),此時發現==LinkedList添加元素的效率就比ArrayList高==~
原因是:
ArrayList越往陣列前面添加元素,效率越低,頭部添加資料,會導致后面的全部陣列元素都要進行賦值重排,效率最低~
LinkedList往陣列前面添加元素,效率也會變低,但是由于底層采用了二分查找(中間劃分,從前往后或從后往前遍歷查找位置)頭部和尾部添加元素的效率都是最高的,只有中間添加元素時,二分法則發揮的作用最小,因此效率最低~~
通過正文及總結,你領悟到真相了嗎?
如果領悟到了,那下次面試官再問LinkedList和ArrayList哪個快,把這篇文章丟給他看,哈哈哈!!!
附錄
舉一:
LinkedList真的比ArrayList添加元素快?
反三:
ArrayList和LinkedList遍歷的效率如何?
String和StringBuilder字串拼接效率如何?
HashMap那種遍歷方式的效率更高?
舉一反三,你學廢了?有空的小伙伴可以根據舉一學到的技能,驗證一下反三,肝完了,小伙伴們!!!!!
原創不易,覺得有用的小伙伴來個一鍵三連(點贊+收藏+評論 )+關注支持一下,非常感謝~


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/296870.html
標籤:java
上一篇:JAVA結構化編程