Selenium介紹
Selenium 是一個用于Web應用程式測驗的工具,Selenium測驗直接運行在瀏覽器中,就像真正的用戶在操作一樣,
支持的瀏覽器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等,它在python的領域里的參考能使初學者大大的省去決議網頁中代加密的一些麻煩,
*特別適合小白練手
Selenium安裝
1.首先要下載一個python的環境,最新的python環境里有繼承好的pip工具包(這塊知識見python官網操作)
2.下載瀏覽器的驅動(我這邊以谷歌瀏覽器,你們也可以下載其他的)
打開https://npm.taobao.org/mirrors/chromedriver鏈接(這個是谷歌瀏覽器的驅動),先找到自身瀏覽器的版本進行下載,找自身瀏覽器版本方法見下圖1,圖2
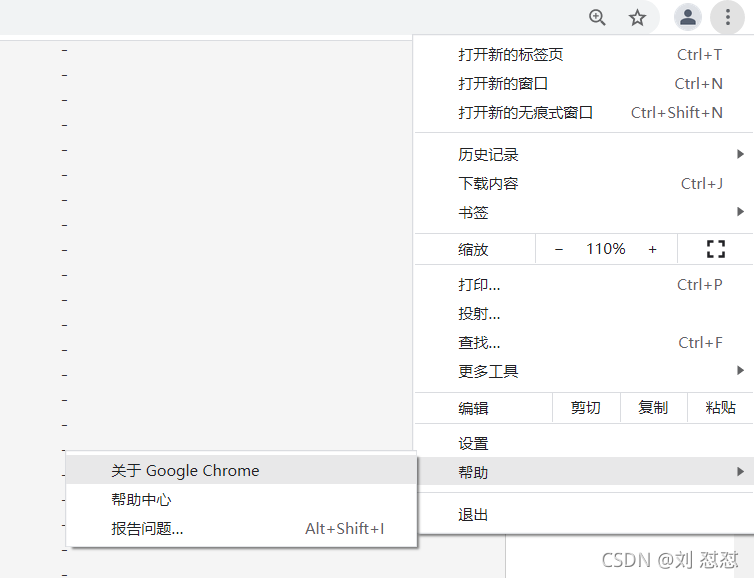
圖1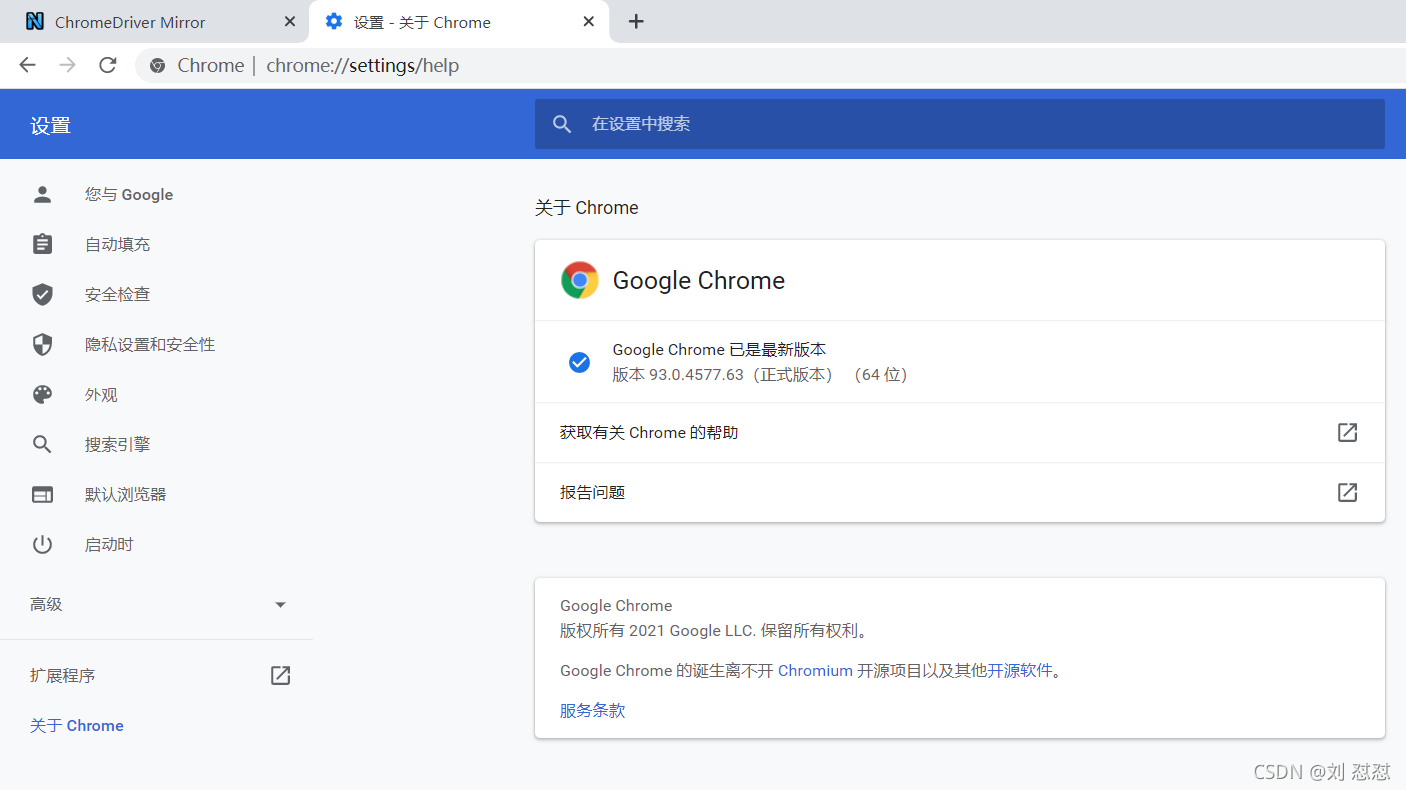
圖2
我這里的是93.0.4577.63接著在驅動下載頁面下載自己的版本的驅動,(如果沒有自己的版本就找這個版本之前的一個) 見下圖3
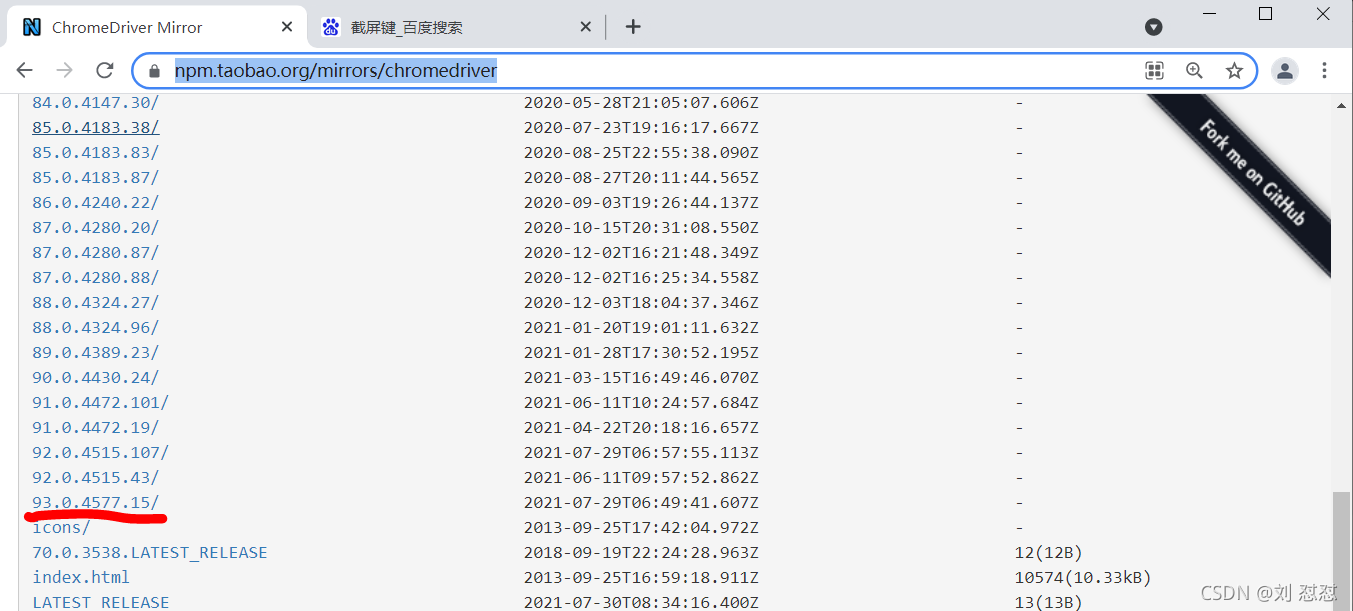
圖3
下載好后把解壓好的包安裝在自己的python環境下,
找python環境目錄的方法:1.打開python--------右擊----選擇運行 圖4 做記號的就是我的路徑
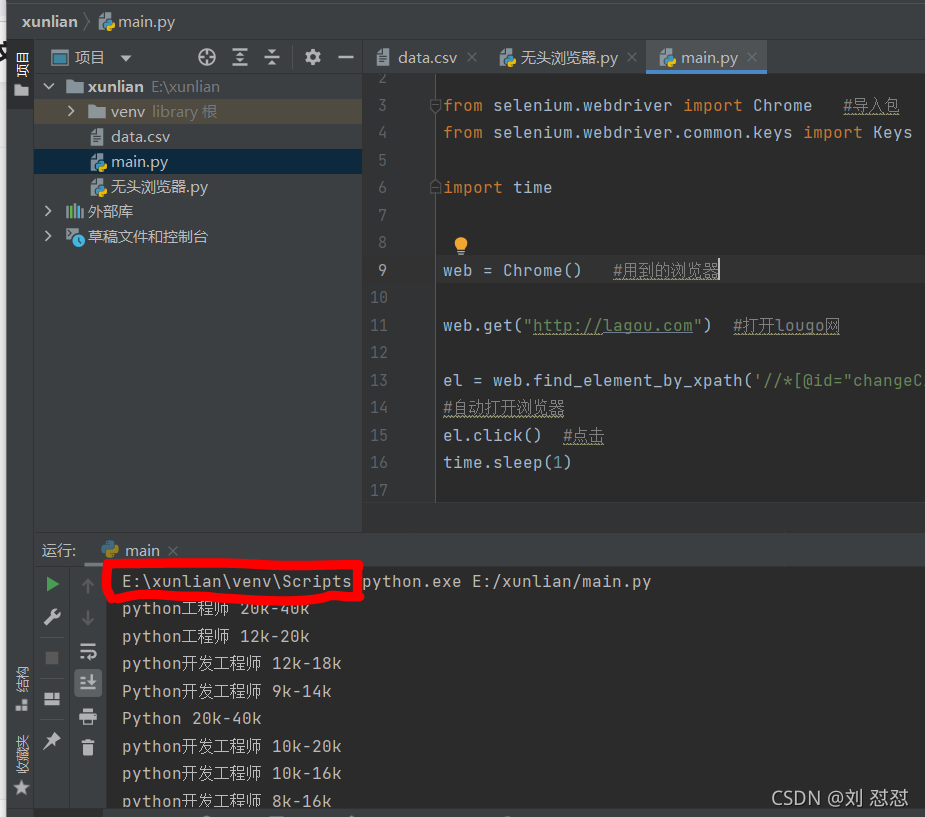
圖4
把下好的復制到相應的路徑下就可以了如圖5
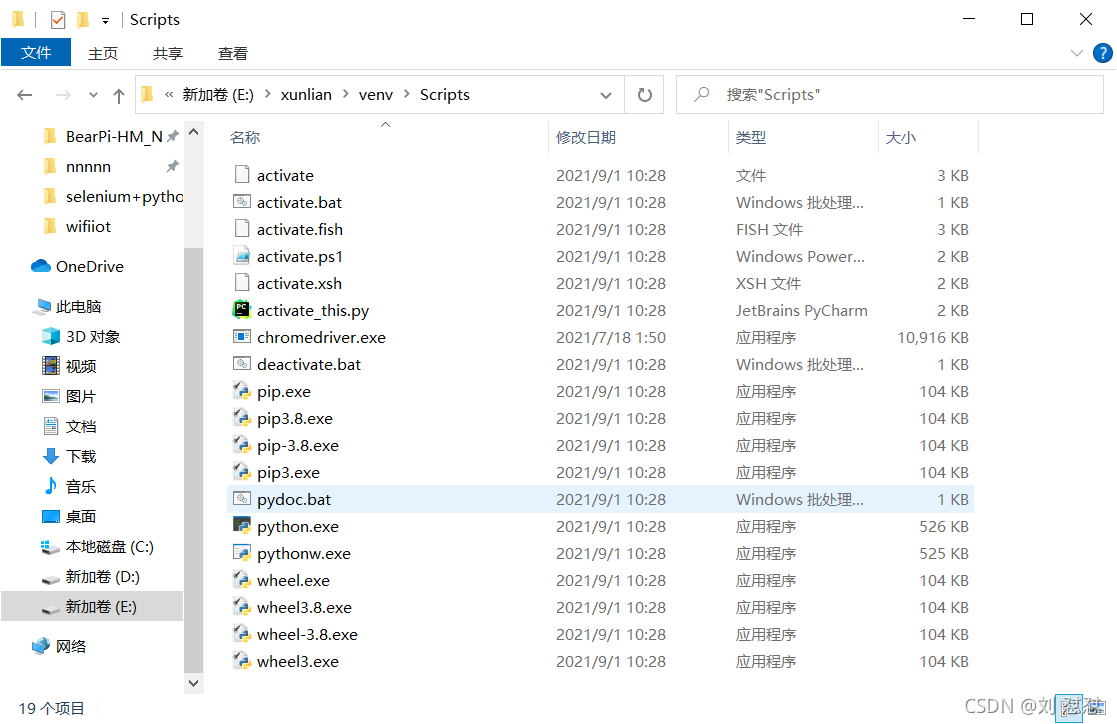
圖5
電影榜單的抓取
工具:PyCharm 2021.2
python編譯環境:python3.8
首先匯入需要的依賴包 在python終端中打入
pip install selenium決議網頁:
首先打開網址https://www.endata.com.cn/BoxOffice/BO/Year/index.html 按F12打開代碼解釋器
進行一個決議,我們測驗代碼是否能自動的打開瀏覽器
from selenium.webdriver import Chrome
web = Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
經過測驗是能打開需要的網址的,接著我們要爬的是每一年度第一的觀影榜單,我們利用xpath進行一個定位,
sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]')#定位一個下拉串列xpath不會定位的見下圖
定位到的位置
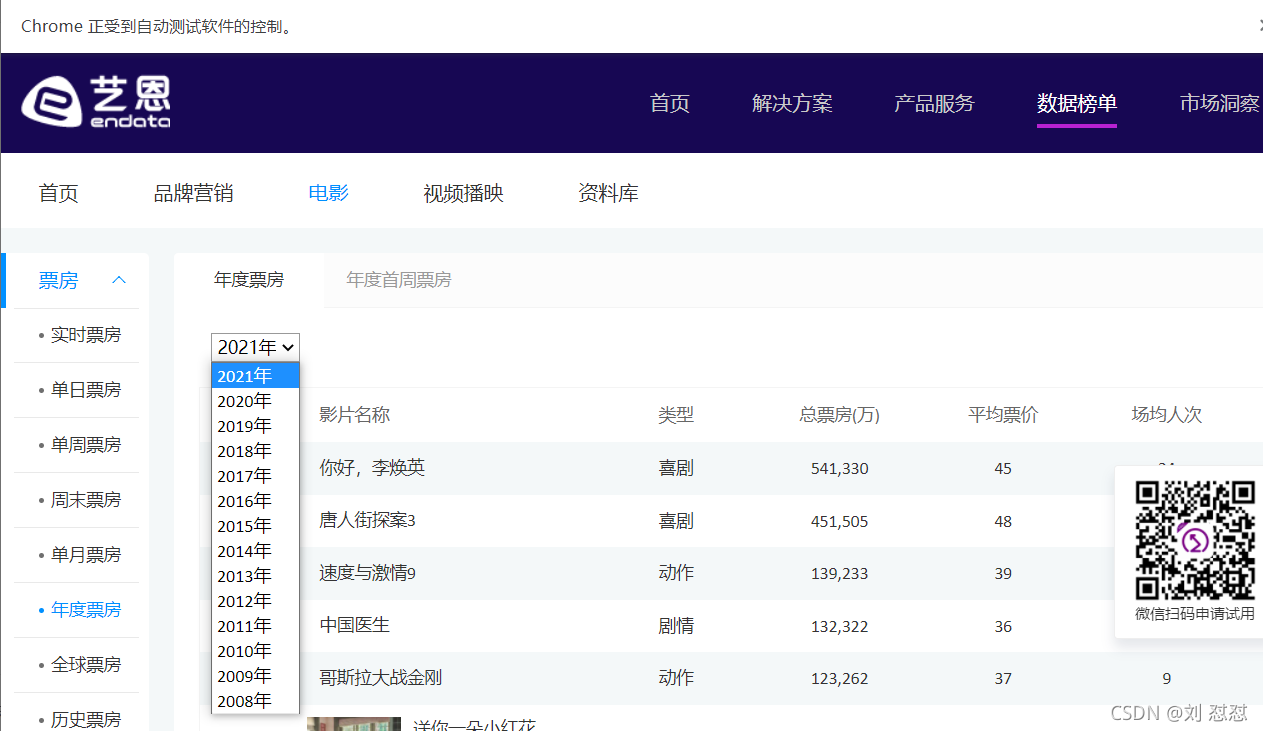
我們觀察到這里有一個下拉串列,我們需要對下拉串列進行一個封裝然后根據索引(這里直接根據options)進行一個遍歷查找(這塊涉及到前端知識點下拉串列)
sel = Select(sel_el)
for i in range(len(sel.options)):
sel.select_by_index(i)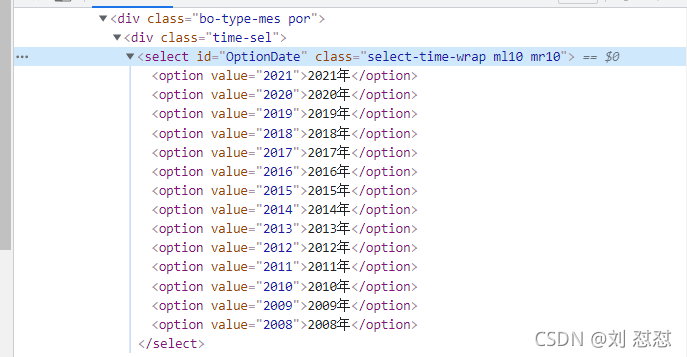
最后找到你要爬取的內容,我這爬取的是電影名稱和票房
table = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[2]/a/p').text
piaofang = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[4]').text把爬取的內容保存到當前目錄檔案下,最后一部進行代碼段的整合
整合代碼段:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
web =Chrome()
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
with open('data.csv', 'w', encoding='utf-8') as f: #打開檔案,進行寫入
sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]')#定位一個下拉串列
#對元素進行包裝
sel = Select(sel_el)
for i in range(len(sel.options)): #前端的下拉串列的
sel.select_by_index(i)
time.sleep(2) #進行一個2s的休眠
table = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[2]/a/p').text #定位要找的東西位置
piaofang = web.find_element_by_xpath('//*[@id="TableList"]/table/tbody/tr[1]/td[4]').text
nianfen = web.find_element_by_xpath('//*[@id="OptionDate"]/option[1]').text
f.write(table)
f.write('\r')
f.write(piaofang)
f.write('\r\n')
f.close()
web.close()
print("爬取完畢")
效果展示:
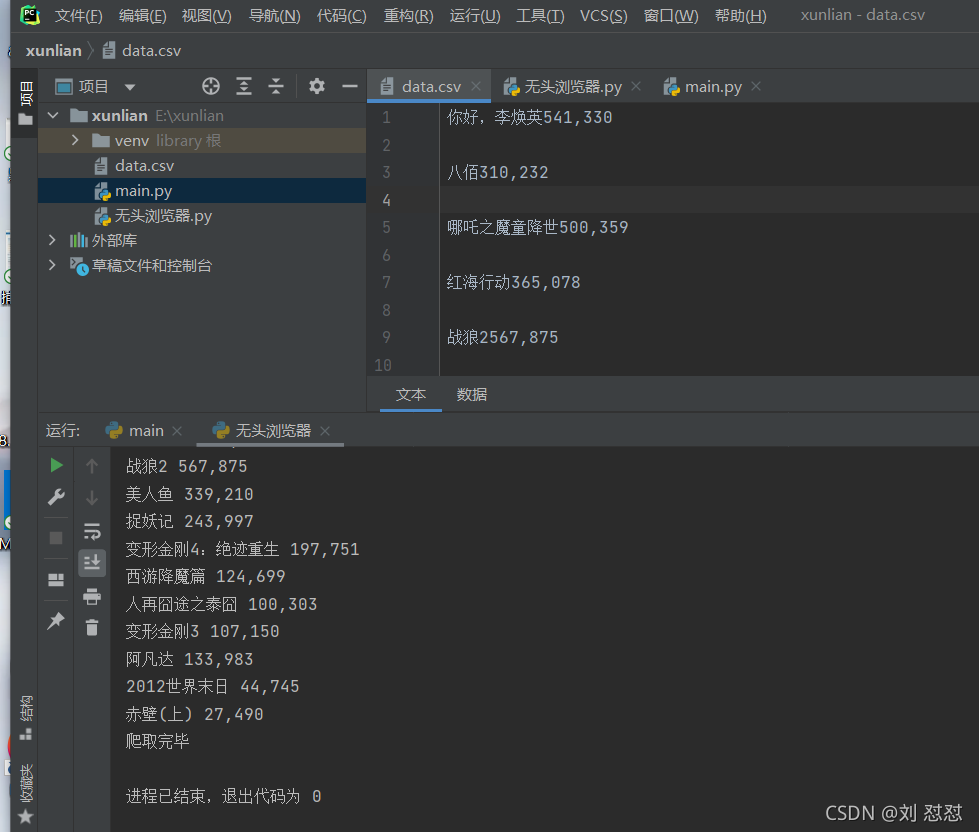
總結:
安裝驅動有不明白的地方可以提出來哦,讓我們一起努力一起學習,有那寫的不對的還請各位大佬指正,感覺寫的還行的,給個小贊,小編也有寫下去的動力
💖💖💖💖💖💖

💖💖💖💖💖💖💖
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297304.html
標籤:python