朋友們,一年一度的中秋悄然而至,為了回應這次節日,特意寫了這篇文章,希望能和大家一起學習,
中秋節介紹
中秋節,又稱祭月節、月光誕、月夕、秋節、仲秋節、拜月節、月娘節、月亮節、團圓節等,是中國民間的傳統節日,
中秋節自古便有祭月、賞月、吃月餅、玩花燈、賞桂花、飲桂花酒等民俗,流傳至今,經久不息,
每年中秋節到,總會去姥姥那里送中秋,并買上各種各樣的月餅,那個時候科技并不怎么發達,不僅沒有這么多形形色色的月餅,也不知道哪些月餅賣得好? 月餅的價格分布是怎樣的呢? 什么地方的月餅銷量最高呢? 簡直有十萬個為什么,希望別人給我們解答,
隨著科技的飛速發展,互聯網溝通了你我他,通過淘寶上月餅的銷量,就可以解決我們想要知道的好多問題,基于此,我爬取了淘寶上4000多條月餅的銷售資料,為大家展示了一幅漂亮的可視化大屏,解決大家心目中的問題,

selenium模塊的安裝與配置
這次爬取淘寶,采用的是最簡單的方式:Selenium控制Chrome瀏覽器進行自動化操作,中途只需要掃碼登陸一次,即可完成整個資料的爬取,
1)安裝selenium庫
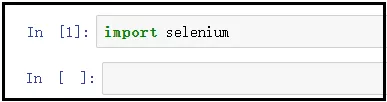
pip install selenium
檢驗是否安裝成功:
2)chromedriver驅動的配置
配置chromedriver驅動,一定要注意“驅動”和“谷歌瀏覽器”版本一定是要相匹配,否則不能使用,
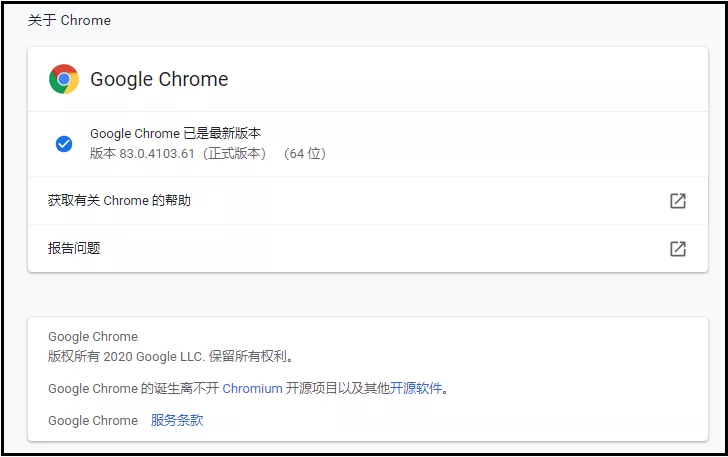
① 檢查谷歌瀏覽器的版本
這里首先提供一個詳細的地址供大家查看:
https://jingyan.baidu.com/article/95c9d20d74a1e8ec4f756149.html
點擊“右上角三個點” --> 點擊“設定” --> 點擊 “關于chrome”,出現如下界面,
② 下載chromedriver驅動
這里再次提供一個詳細的地址,供大家選擇各種版本驅動程式:
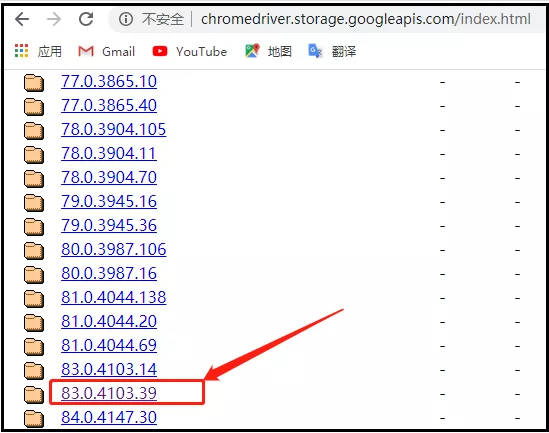
http://chromedriver.storage.googleapis.com/index.html
從上面的圖中可以看出,谷歌瀏覽器的版本是【81.0.4044.138】,這里我們選擇的對應版本的驅動,如下圖所示,
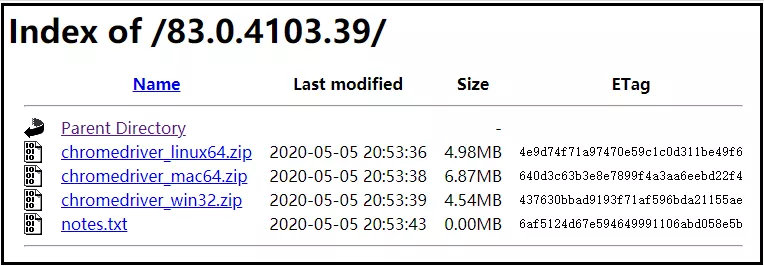
點進該檔案后,可以根據我們的作業系統,選擇對應的驅動,
③ chromedriver驅動的配置
解壓上述下載好的檔案,并將解壓后我們得到的chromedriver.exe檔案,需要放到python的安裝路徑下(和python.exe放在一起),
首先,你可以查看你的python解釋器安裝在哪里!
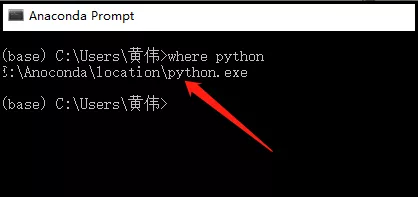
然后,將chromedriver.exe放置和python.exe在一起,
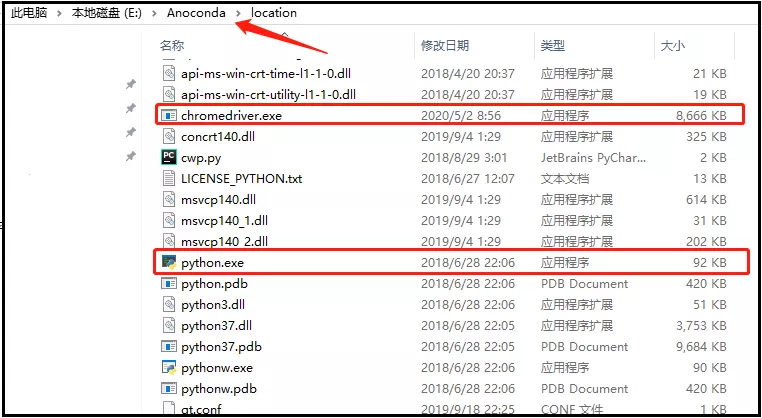
3)檢驗selenium是否可用
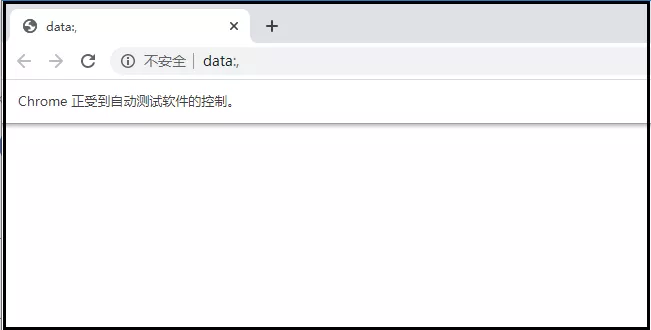
使用如下兩行代碼,如果谷歌瀏覽器成功被驅動打開,證明上述安裝和配置沒問題,
from selenium import webdriver
browser = webdriver.Chrome()
結果如下:
4)一個小案例展示selenium的操作效果
from selenium import webdriver
import time
# 創建瀏覽器物件,該操作會自動幫我們打開Google瀏覽器視窗
browser = webdriver.Chrome()
# 呼叫瀏覽器物件,向服務器發送請求,該操作會打開Google瀏覽器,并跳轉到“百度”首頁
browser.get("https://www.baidu.com/")
# 最大化視窗
browser.maximize_window()
# 定位“抗擊肺炎”鏈接內容
element = browser.find_element_by_link_text("抗擊肺炎")
# 為了更好的展示這個效果,我們等待3秒鐘
time.sleep(3)
# 點擊上述鏈接
element.click()
# 我們再讓瀏覽器停留3秒鐘后,再關閉瀏覽器
time.sleep(3)
# 操作會自動關閉瀏覽器
browser.close()
"""
效果這里就不展示了,大家自行下去嘗試!
"""
爬蟲完整帶啊嗎
from selenium import webdriver
import time
import csv
import re
# 搜索商品,獲取商品頁碼
def search_product(key_word):
# 定位輸入框
browser.find_element_by_id("q").send_keys(key_word)
# 定義點擊按鈕,并點擊
browser.find_element_by_class_name('btn-search').click()
# 最大化視窗:為了方便我們掃碼
browser.maximize_window()
# 等待15秒,給足時間我們掃碼
time.sleep(15)
# 定位這個“頁碼”,獲取“共100頁這個文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# 需要注意的是:findall()回傳的是一個串列,雖然此時只有一個元素它也是一個串列,
page = re.findall("(\d+)",page_info)[0]
return page
# 獲取資料
def get_data():
# 通過頁面分析發現:所有的資訊都在items節點下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
# 引數資訊
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 價格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人數
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 旗艦店
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 發貨地
address = item.find_element_by_xpath('.//div[@class="location"]').text
#print(pro_desc, pro_price, buy_num, shop, address)
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
def main():
browser.get('https://www.taobao.com/')
page = search_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("*" * 100)
print("正在爬取第{}頁".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num*44))
browser.implicitly_wait(15)
get_data()
page_num += 1
print("資料爬取完畢!")
if __name__ == '__main__':
key_word = input("請輸入你要搜索的商品:")
browser = webdriver.Chrome()
main()
資料清洗
資料清洗很重要,這個對于我們后續做可視化展示,極其重要,因此我們需要根據后面要做的圖形,然后進行對應的進行資料清洗,
爬取到的原始資料如下:
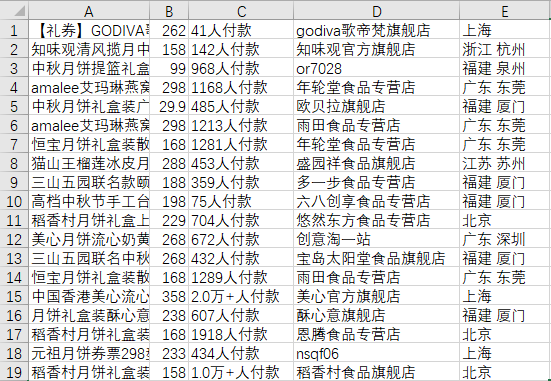
整個資料看上去算是比較干凈,但是還是有幾個地方指的我們處理一下,
- 1.爬取到的原始資料沒有列名,我們需要添加一個新列名;
- 2.整個爬蟲程序中,會出現重復資料,我們需要提前去重處理;
- 3.將購買人數為空的記錄,替換成0人付款;
- 4.將購買人數轉換為銷量(注意部分單位為萬);
- 5.洗掉無發貨地址的商品,并提取其中的省份;
# 導包
import pandas as pd
import numpy as np
import re
# 匯入爬取得到的資料
df = pd.read_csv("月餅.csv", engine='python', encoding='utf-8-sig', header=None)
df.columns = ["商品名", "價格", "付款人數", "店鋪", "發貨地址"]
df.head(10)
# 去除重復值
print(df.shape)
df.drop_duplicates(inplace=True)
print(df.shape)
# 處理購買人數為空的記錄
df['付款人數'] = df['付款人數'].replace(np.nan,'0人付款')
# 提取數值
df['num'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['付款人數']] # 提取數值
df['num'] = df['num'].astype('float') # 轉化數值型
# 提取單位(萬)
df['unit'] = [''.join(re.findall(r'(萬)', i)) for i in df['付款人數']] # 提取單位(萬)
df['unit'] = df['unit'].apply(lambda x:10000 if x=='萬' else 1)
# 計算銷量
df['銷量'] = df['num'] * df['unit']
# 洗掉無發貨地址的商品,并提取省份
df = df[df['發貨地址'].notna()]
df['省份'] = df['發貨地址'].str.split(' ').apply(lambda x:x[0])
# 洗掉多余的列
df.drop(['付款人數', '發貨地址', 'num', 'unit'], axis=1, inplace=True)
# 重置索引
df = df.reset_index(drop=True)
df.to_csv('清洗完成資料.csv',encoding="gbk")
看看清洗后的資料:
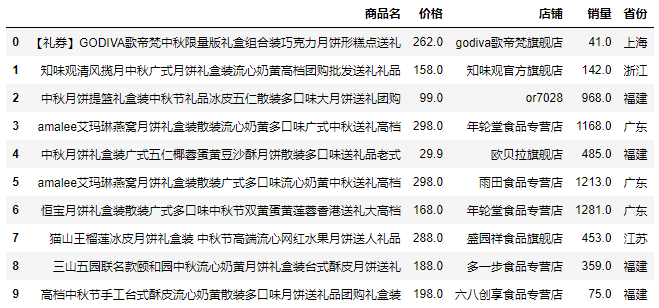
資料可視化
可視化是整個文章的亮點所在,所謂“字不如表、表不如圖”,整個可視化大屏我們基于以下五個問題開展而來,
- 1.月餅銷量Top10的柱形圖;
- 2.店鋪月餅銷量Top10的柱形圖;
- 3.全國月餅銷量的地域分布地圖;
- 4.不同價格區間的月餅銷量圓環圖;
- 5.月餅銷售關鍵字的詞云圖;
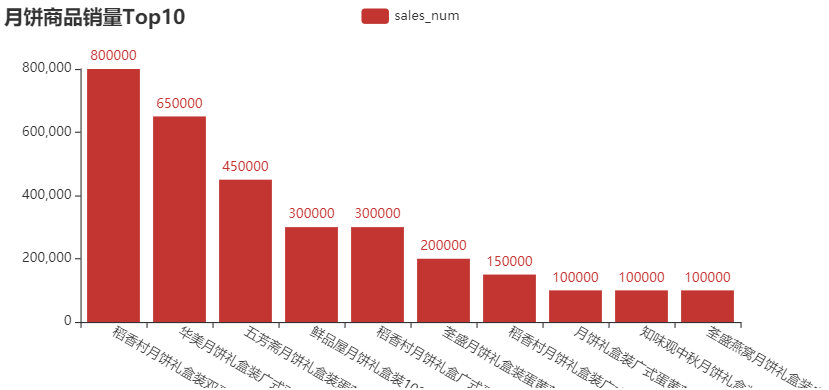
1)月餅銷量Top10的柱形圖
# 匯入包
from pyecharts.charts import Bar
from pyecharts import options as opts
# 計算top10店鋪
shop_top10 = df.groupby('商品名')['銷量'].sum().sort_values(ascending=False).head(10)
# 繪制柱形圖
bar0 = Bar(init_opts=opts.InitOpts(width='750px', height='350px'))
bar0.add_xaxis(shop_top10.index.tolist())
bar0.add_yaxis('sales_num', shop_top10.values.tolist())
bar0.set_global_opts(title_opts=opts.TitleOpts(title='月餅商品銷量Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
#bar0.render("月餅商品銷量Top10.html")
bar0.render_notebook()
結果如下:
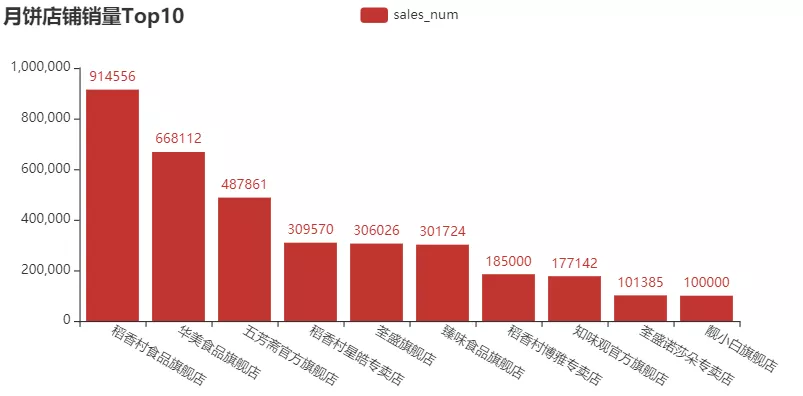
2)店鋪月餅銷量Top10的柱形圖
# 匯入包
from pyecharts.charts import Bar
from pyecharts import options as opts
# 計算top10店鋪
shop_top10 = df.groupby('店鋪')['銷量'].sum().sort_values(ascending=False).head(10)
# 繪制柱形圖
bar1 = Bar(init_opts=opts.InitOpts(width='750px', height='350px'))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('sales_num', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='月餅店鋪銷量Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
#bar1.render("月餅店鋪銷量Top10.html")
bar1.render_notebook()
結果如下:
3)全國月餅銷量的地域分布地圖
from pyecharts.charts import Map
# 計算銷量
province_num = df.groupby('省份')['銷量'].sum().sort_values(ascending=False)
# 繪制地圖
map1 = Map(init_opts=opts.InitOpts(width='750px', height='350px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='各省份月餅銷量分布'),
visualmap_opts=opts.VisualMapOpts(max_=300000)
)
#map1.render("各省份月餅銷量分布.html")
map1.render_notebook()
結果如下:

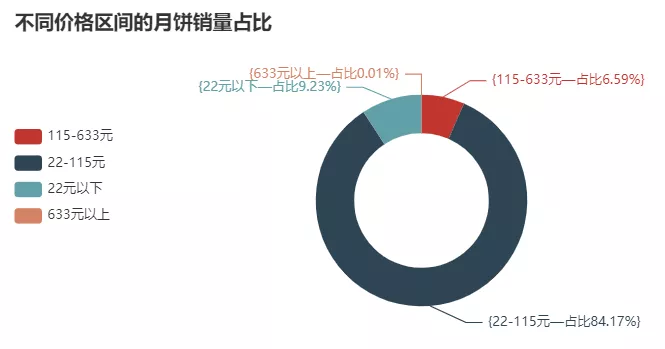
4)不同價格區間的月餅銷量圓環圖
from pyecharts.charts import Pie
def price_range(x): #按照淘寶推薦劃分價格區間
if x <= 22:
return '22元以下'
elif x <= 115:
return '22-115元'
elif x <= 633:
return '115-633元'
else:
return '633元以上'
df['price_range'] = df['價格'].apply(lambda x: price_range(x))
price_cut_num = df.groupby('price_range')['銷量'].sum()
data_pair = [list(z) for z in zip(price_cut_num.index, price_cut_num.values)]
print(data_pair)
# 餅圖
pie1 = Pie(init_opts=opts.InitOpts(width='750px', height='350px'))
# 內置富文本
pie1.add(
series_name="銷量",
radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(formatter='{{b}—占比{d}%}'),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
title_opts=opts.TitleOpts(title='不同價格區間的月餅銷量占比'))
#pie1.render("不同價格區間的月餅銷量占比.html")
pie1.render_notebook()
結果如下:
5)月餅銷售關鍵字的詞云圖
import jieba
import jieba.analyse
txt = df['商品名'].str.cat(sep=',')
# 添加關鍵詞
jieba.add_word('粽子', 999, '五芳齋')
# 讀入停用詞表
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加停用詞
stop_words.extend(['logo', '10', '100', '200g', '100g', '140g', '130g', '月餅', '禮盒裝'])
# 評論欄位分詞處理
word_num = jieba.analyse.extract_tags(txt,
topK=100,
withWeight=True,
allowPOS=())
# 去停用詞
word_num_selected = []
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
key_words = pd.DataFrame(word_num_selected, columns=['words','num'])
結果如下:

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297306.html
標籤:python