引言
Netty作為高性能的網路通信框架,它是IO模型演變程序中的產物,Netty以Java NIO為基礎,是一種基于異步事件驅動的網路通信應用框架,Netty用以快速開發高性能、高可靠的網路服務器和客戶端程式,很多開源框架都選擇Netty作為其網路通信模塊,本文主要通過分析IO模型的優化演進之路,比較不同IO模型的異同,讓大家對于Java IO模型有著更加深刻的理解,我想這也是Netty如何實作高性能網路通信理解的重要基礎,話不多說,我們趕緊發車了,
PS:文末有是彩蛋哦!
IO模型
1、什么是IO
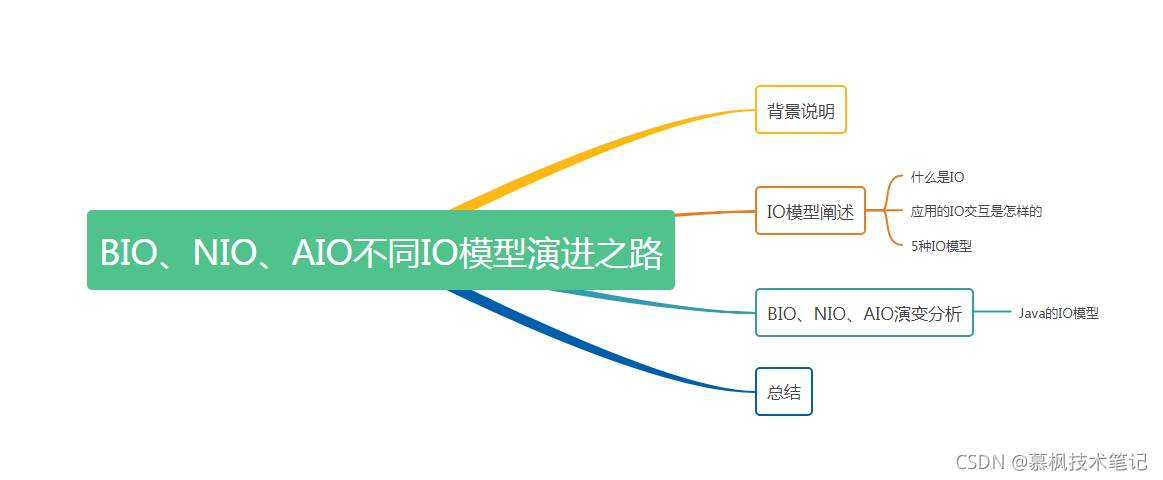
在闡述BIO、NIO、AIO之前,我們先來看下到底什么是IO模型,我們都知道無論是程式還是平臺,它們的功能高度抽象之后其實可以描述為這樣一個程序,即為通過外部條件以及資料的輸入,經程序式或者平臺的處理產生了新的輸出,IO模型實際上就是描述了計算機世界中的輸入和輸出程序的模式,
對于計算機來說,其鍵盤以及滑鼠等就是輸入設備,顯示幕以及磁盤等就是輸出設備,舉個栗子,如果我們在計算機上寫一篇設計檔案并進行保存,實際就是通過鍵盤對計算機進行了資料輸入,完成設計檔案后將其保存輸出到了計算機的磁盤上,
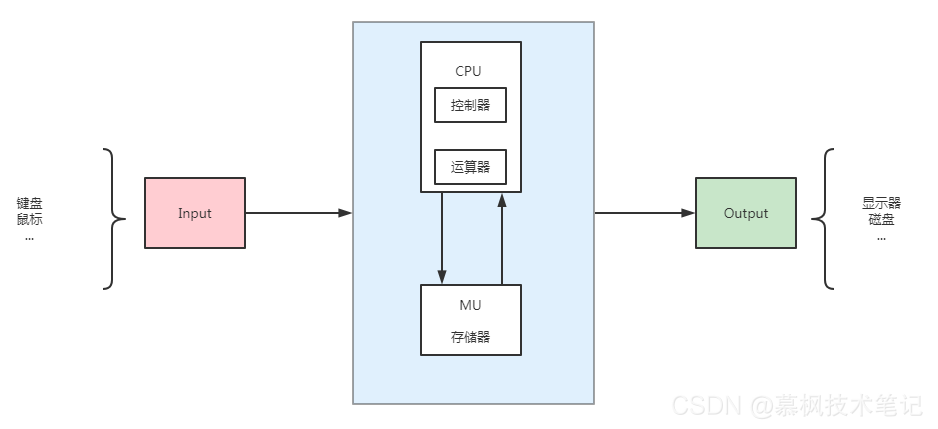
上圖中的IO描述,即為著名的計算機馮諾依曼體系,它大致描述了外部設備與計算機的IO互動程序,
2、應用程式IO互動
上文中我們介紹了計算機與外部設備互動的大致程序,那么我們的應用程式是如何進行IO互動的呢?我們平時撰寫的代碼不會獨立的存在,它總是被部署在linux服務器或者各種容器中,應用程式在服務器或者容器中啟動后再對外提供服務,因此網路請求資料首先需要和計算機進行互動,才會被交由到對應的程式去進行后續的業務處理,
在Linux的世界中,檔案是用來描述Linux世界的,目錄檔案、套接字等都是檔案,那檔案又是什么鬼呢?檔案實際就是二進制流,二進制流就是人類世界與計算機世界進行互動的資料媒介,應用從流中讀取資料即為read操作,當把流中的資料進行寫入的時候就是write操作,但是linux系統又是如何區分不同型別的檔案呢?實際是通過檔案描述符(File Descriptor)來進行區分,檔案描述符其實就是個整數,這個整數實際是一個索引值,指向內核為每一個行程所維護的該行程打開檔案的記錄表,所以對這個整數的操作、就是對這個檔案(流)的操作,
就拿網路連接來說,我們創建一個網路socket,通過系統呼叫(socket呼叫)會回傳一個檔案描述符(某個整數),那么后續對socket的操作就會轉化為對這個描述符的操作,主要涉及的操作包括accept呼叫、read呼叫以及 write呼叫,這里所說的各種呼叫就是程式通過Linux內核與計算機進行互動,那么問題又來了,這個計算機內核又是什么鬼,(PS:關于內核不是本文的重點,這里就簡單和大家說明下)
//socket函式
socket(PF_INET6,SOCK_STREAM,IPPROTO_IP)
但是實際上應用程式并不是直接從計算機中的網卡中獲取資料,也就是說大家撰寫的程式并不是直接操作計算機的底層硬體,
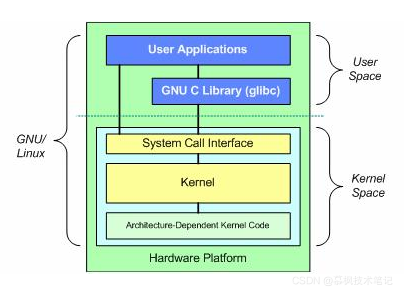
如上圖所示,在Linux的結構體系中,用戶的應用程式都是通過Linux Kernel內核來操作計算機硬體,那么為什么應用程式不能直接與底層硬體進行互動還需要在中間再加一層內核呢?主要有以下幾點考慮,
(1)計算機資源統一管理
Linux內核的作用就是行程調度管理,同時對cpu、記憶體等系統資源進行統一管理,因此內核管理的都是系統極其敏感的資源,采用內核制是為了實作系統的網路通信,用戶管理,檔案系統等安全穩定的行程管理,避免用戶應用程式破壞系統資料,
(2)底層硬體呼叫統一封裝
試想一下,如果沒有內核這層系統行程,那么每個用戶應用程式和硬體互動的時候都需要自己實作對應的硬體驅動,這樣的設計很難讓人接受,按照面向物件的設計思想,硬體的管理統一由Kernel內核負責,Kernel向下管理所有的硬體設備,向上提供給用戶行程統一的系統呼叫,方便應用程式可以像程式呼叫一樣進行系統硬體互動,
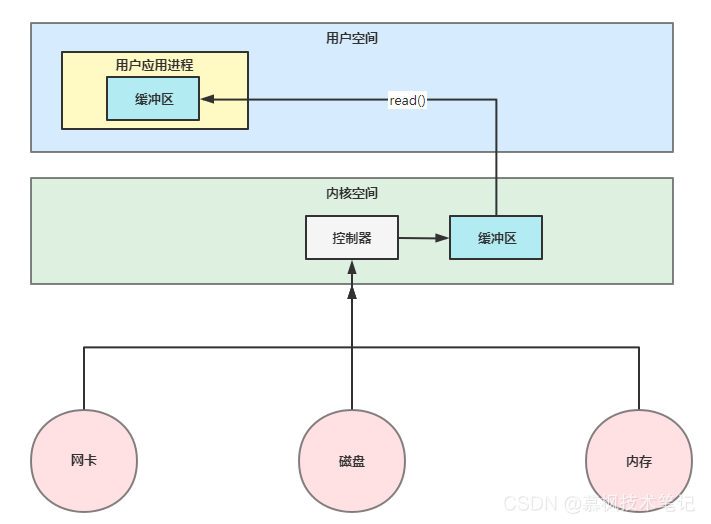
3、5種IO模型
(1)阻塞型IO
當用戶應用行程發起系統呼叫之后,在內核資料沒有準備好的情況下,呼叫一直處于阻塞狀態,直到內核準備好資料后,將資料從內核態拷貝到用戶態,用戶應用行程獲取到資料后,本次呼叫才算完成,就好比你是外賣小哥,你到商家去取餐,商家的外賣還沒有準備好,所以你只能在取餐的地方一直等待著,直到商家將做好的外賣準備好,你才能拿了外賣去送餐,
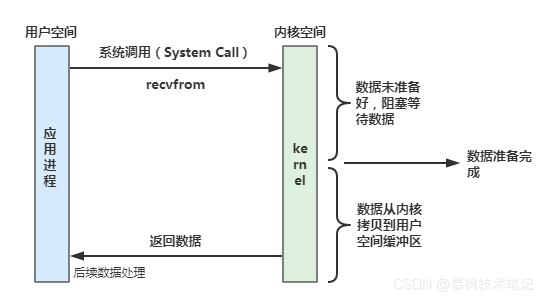
(2)非阻塞型IO
非阻塞IO式基于輪詢機制的IO模型,應用行程不斷輪詢檢查內核資料是否準備好,如果沒有則回傳EWOULDBLOCK,行程繼續發起recvfrom呼叫,此時應用可以去處理其他業務,當內核資料準備好后,將內核資料拷貝至用戶空間,這個程序就好比外賣小哥在等待取餐的時候不斷問商家外賣做好了沒(這個外賣小哥比較著急,送餐時間比較臨近了),每隔30s問一次,直到外賣做好送到,
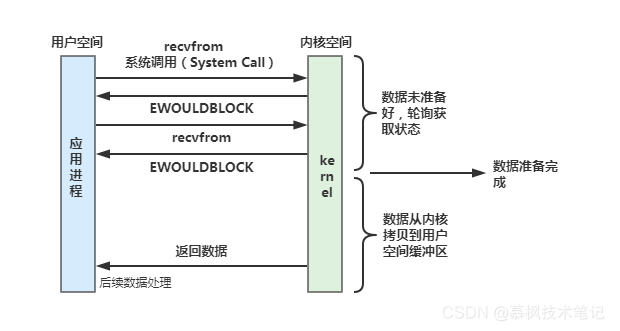
(3)多路復用IO
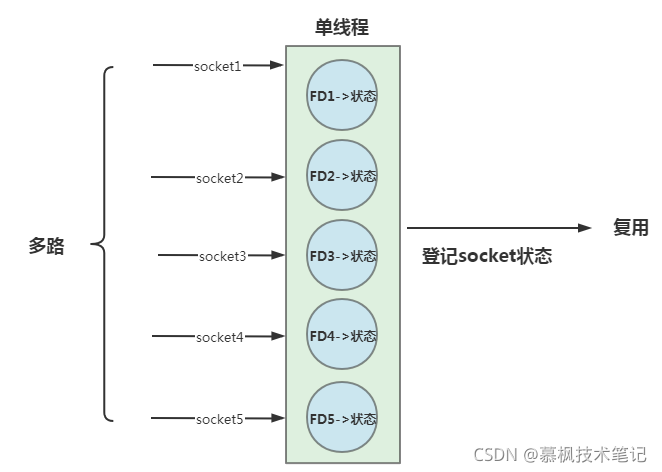
Linux主要提供了select、poll以及epoll等多路復用I/O的實作方式,為什么會有三個實作呢?實際上他們的出現都是有時間順序的,后者的出現都是為了解決前者在使用中出現的問題,
在實際場景中,后端服務器接收大量的socket連接,IO多路復用是實際是使用了內核提供的實作函式,在實作函式中有一個引數是檔案描述符集合,對這些檔案描述符(FD)進行回圈監聽,當某個檔案描述符(FD)就緒時,就對這個檔案描述符進行處理,
下面我們分別看下select、poll以及epoll這三個實作函式的實作原理:
select:
select是作業系統的提供的內核系統呼叫函式,通過它可以將一組FD傳給作業系統,作業系統對這組FD進行遍歷,當存在FD處于資料就緒狀態后,將其全部回傳給呼叫方,這樣應用程式就可以對已經就緒的IO流進行處理了,
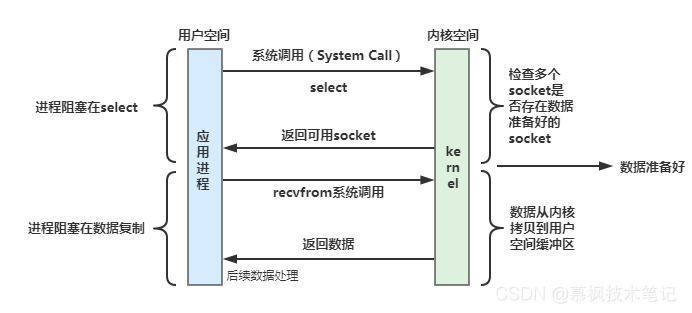
select在使用程序中存在一些問題:
(1)select最多只能監聽1024個連接,支持的連接數較少;
(2)select并不會只回傳就緒的FD,而是需要用戶行程自己一個一個進行遍歷找到就緒的FD;
(3)用戶行程在呼叫select時,都需要將FD集合從用戶態拷貝到內核態,當FD較多時資源開銷相對較大,
poll:
poll機制實際與select機制區別不大,只是poll機制去除掉了監聽連接數1024的限制,
epoll:
epoll解決了select以及poll機制的大部分問題,主要體現在以下幾個方面:
(1)FD發現的變化:內核不再通過輪詢遍歷的方式找到就緒的FD,而是通過異步IO事件喚醒的方式,當socket有事件發生時,通過回呼函式將就緒的FD加入到就緒事件鏈表中,從而避免了輪詢掃描FD集合;
(2)FD回傳的變化:內核將已經就緒的FD回傳給用戶,用戶應用程式不需要自己再遍歷找到就緒的FD;
(3)FD拷貝的變化:epoll和內核共享同一塊記憶體,這塊記憶體中保存的就是那些已經可讀或者可寫的的檔案描述符集合,這樣就減少了內核和程式的記憶體拷貝開銷,
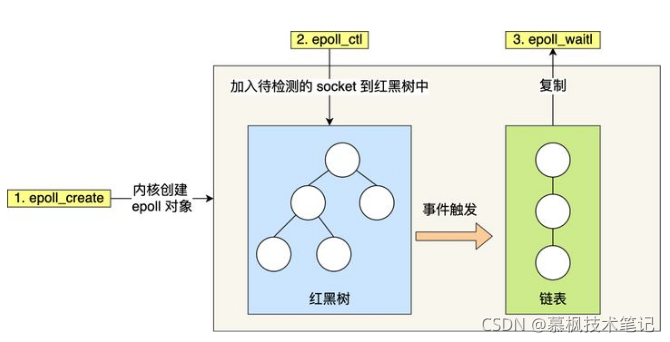
(該圖片來自于網路)
(4)信號驅動IO
系統存在一個信號捕捉函式,該信號捕捉函式與socket存在關聯關系,在用戶行程發起sigaction呼叫之后,用戶行程可以去處理其他的業務流程,當內核將資料準備好之后,用戶行程會接收到一個SIGIO信號,然后用戶行程中斷當前的任務發起recvfrom呼叫從內核讀取資料到用戶空間再進行資料處理,
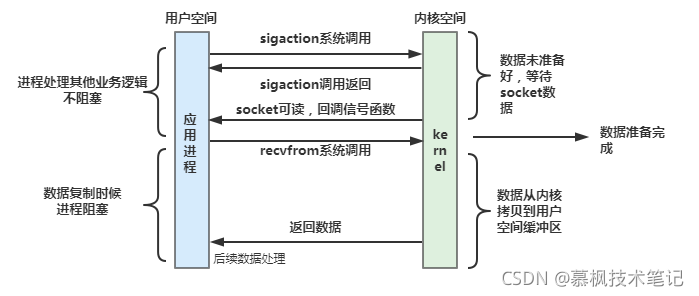
(5)異步IO
所謂異步IO模型,就是用戶行程發起系統呼叫之后,不管內核對應的請求資料是否準備好,都不會阻塞當前行程,立即回傳后行程可以繼續處理其他的業務,當內核準備好資料之后,系統會從內核復制資料到用戶空間,然后通過信號通知用戶行程進行資料讀取處理,
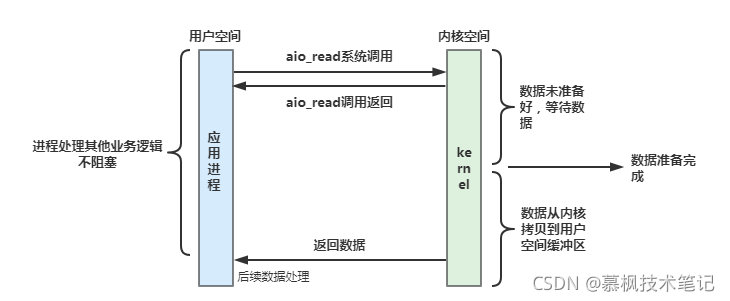
Java中的IO模型
上文中我們闡述了Linux本身存在的幾種IO模型,那么對應到Java程式世界中,Java也有對應的IO模型,分別是BIO、NIO以及AIO三種IO模型,它們都提供了和IO有關的API,這些API實際也是依賴系統層面的IO完成資料處理的,因此Java的IO模型,實際就是對系統層面IO模型的封裝,接下來我們來一起看下Java的這幾種IO模型,
BIO
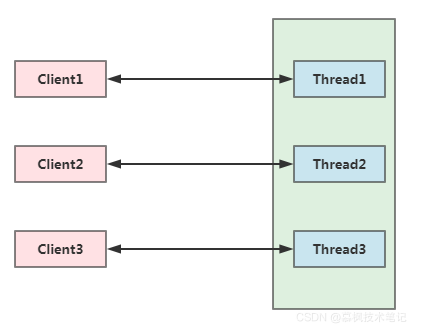
BIO即為Blocking IO,顧名思義就是阻塞型IO模型,當用戶行程向服務端發起請求后,一定等到服務端處理完成有資料回傳給用戶,用戶行程才完成一次IO操作,否則就會阻塞住,像個癡心漢傻傻的一直等待資料回傳,當資料完成回傳后用戶執行緒才會解除block狀態,因此在整個資料讀取程序中會發生阻塞,
另外從下圖我們可以看出來,每一個客戶端連接,服務端都有對應的處理執行緒來處理對應的請求,還是以餐廳吃飯的例子,你到餐廳去吃飯,假如每來一個消費者,餐廳都用一個服務員來接待直到消費者吃飽喝足走出餐廳,那么這個餐廳得配置多少個服務員才合適?這么多服務員,餐廳的老板估計得賠的內褲都沒了,
因此在網路連接不多的情況下,BIO還能發回作用,但是當連接數上來后,比如幾十萬甚至上百萬連接,BIO模型的IO互動就顯得心有余而力不足了,當連接數不斷攀高時,BIO模型的IO互動方式存在以下幾種弊端,
(1)頻繁創建和銷毀大量的執行緒會消耗系統資源給服務器造成巨大的壓力;
(2)另外大量的處理執行緒會占用過多的JVM記憶體,你的程式不要干其他事情了,都被大量連接執行緒給占滿了;
(3)實際上執行緒的背景關系切換成本也是很高的,
基于BIO模型在處理大量連接時存在上述的問題,因此我們需要一種更加高效的執行緒模型來應對幾十萬甚至上百萬的客戶端連接,
NIO
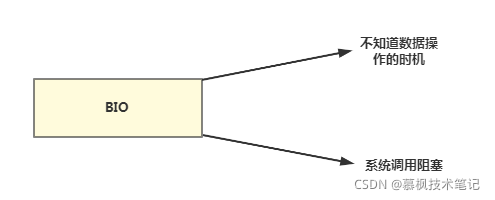
通過上文的分析,由于在BIO模型下,Java中在進行IO操作時候是沒辦法知道什么時候可以讀資料或者什么時候可以寫資料,BIO又是一個實在孩子因此沒有什么好的辦法只能在哪里傻等著,由于socket的讀寫操作不能進行中斷,因此當有新的連接到來時,只能不斷創建新的執行緒來處理,從而導致存在性能問題,
那么如何解決這個問題呢?我們都知道問題的根源就是BIO模型中我們不知道資料的讀取與寫入的時機,才導致的阻塞等待,那么如果我們能夠知道資料讀寫的時機,是不是就不用傻傻的等著回應,也不用再創建新的執行緒來處理連接了,
為了提升IO互動效率,避免阻塞傻等的情況發生,Java 1.4中引入了NIO,對于NIO來說,有人稱之為Non-blocking IO,但是我更愿意稱之為New IO,因為它是一種基于IO多路復用的IO模型,而不是簡單的同步非阻塞的IO模型,所謂IO多路復用指的就是用同一個執行緒處理大量連接,多路指的就是大量連接,復用指的就是使用一個執行緒來進行處理,
那我們先來看看同步非阻塞模型有什么問題,NIO 的讀寫以及接受方法在等待資料就緒階段都是非阻塞的,如上文中的描述,同步非阻塞模式下應用行程不斷向內核發起呼叫,詢問內核資料完成準備,相對于同步阻塞模型有了一定的優化,通過不斷輪詢資料是否準備好,避免了呼叫阻塞,但是由于應用不斷進行系統IO呼叫,在此程序中十分消耗CPU,因此還有進一步優化的空間,此時就該IO多路復用模型上場一展拳腳了,而Java的NIO正是借助于此實作了IO性能的提升,(這里以epoll機制來進行說明)
Java NIO基于通道和緩沖區的形式來處理流資料,借助于Linux作業系統的epoll機制,多路復用器selector就會不斷進行輪詢,當某個channel的事件(讀事件,寫事件,連接事件等等)準備就緒的時候,就是會找到這個channel對應的SelectionKey,去做相應的操作,進行資料的讀寫操作,
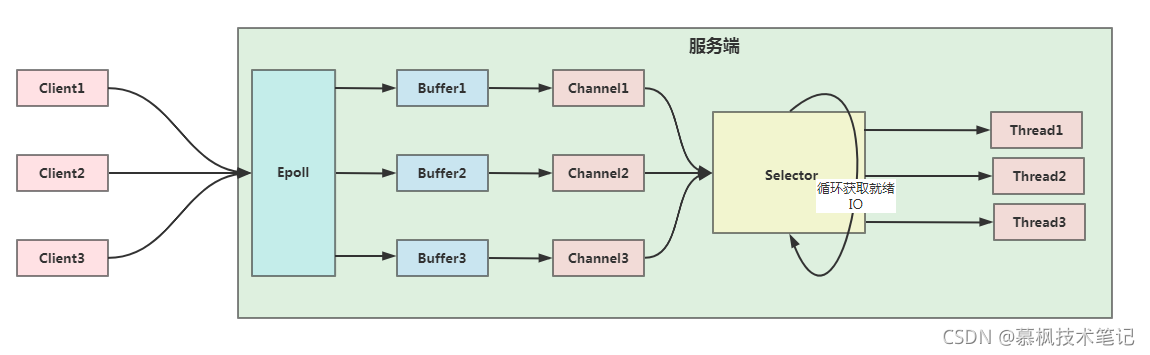
AIO
所謂AIO(Asynchronous IO)就是NIO第二代,它是在Java 7中引入的,是一種異步IO模型,異步IO模型是基于事件和回呼機制實作的,當應用發起呼叫請求之后會直接回傳不會阻塞在那里,當后臺進行資料處理完成后,作業系統便會通知對應的執行緒來進行后續的資料處理,
從效率上來看,AIO 無疑是最高的,然而,美中不足的是目前作為廣大服務器使用的系統 linux 對 AIO 的支持還不完善,導致我們還不能愉快的使用 AIO 這項技術,Netty實際也是使用過AIO技術,但是實際并沒有帶來很大的性能提升,目前還是基于Java NIO實作的,
總結
本文主要從計算機IO互動出發,分別給大家介紹了什么是IO模型以及常見的五種IO模型,介紹了這幾種IO模型的優缺點,從系統優化演進的角度分析了Java BIO、NIO以及AIO演化之路,從設計者的角度分析Java BIO存在的不足,我們再來回顧下整個演程序序的脈絡,
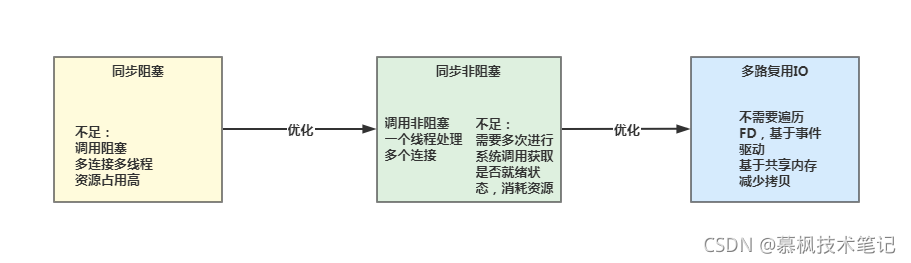
在后續的文章中,筆者將繼續帶大家深入研究的Netty作為高性能網路通信框架的奇妙之處,敬請期待哦,
我是慕楓,感謝各位小伙伴點贊、收藏和評論,文章持續更新,我們下期再見!
真正的大師永遠懷著一顆學徒的心
微信搜索:慕楓技術筆記,優質文章持續更新,我們有學習打卡的群可以拉你進,一起努力沖擊大廠,另外有很多學習以及面試的材料提供給大家,
幾乎全新的鍵盤,自己就用了兩次,有朋友送了另外的鍵盤,本來打算在咸魚上賣掉的,后來想想不如在我的公眾號以及CSDN粉絲中抽一位直接送了,沒有套路,全國包郵送,快來領取秋天的第一個雷蛇鍵盤吧,


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297569.html
標籤:java