摘要
本文討論關系資料庫設計相關的一些內容,涉及關系模型,表結構設計等內容,以學生選修課程講述設計程序,在盡量講清楚設計要領的前提下,簡化設計內容,
本文基于MySQL資料庫為基礎,適合有一定關系型資料庫基礎的人閱讀,
物體-關系模型(E-R)
首先搞清楚什么是E-R資料模型?它有什么用?
E-R模型在將現實世界中事實的含義和相互關聯映射到概念模式方面非常有用,因此,許多資料庫設計工具都利用了E-R模型的概念,E-R模型所采用的三個主要概念是:物體集、關系集和屬性,
物體:物體是世界中可以區別于其他物件的“事件”或者“物體”,例如,學校里的每個學生、學生選修的每門課程等都是一個物體,屬性:屬性是物體集中每個成員具有的描述性性質,例如,學生的姓名,學號等,物體集:物體集就是就有相同型別及屬性的物體集合,比如,學校里的所有學生,學生選修的所有課程等,關系:關系是多個物體間的相互關聯,例如,小明選修幼ò肝程,關系集:關系集是同類關系的集合,例如,所用學生選修課程的集合,
既然知道了E-R資料模型的作用,下面就讓我們來畫出學生選修課程的E-R圖吧,
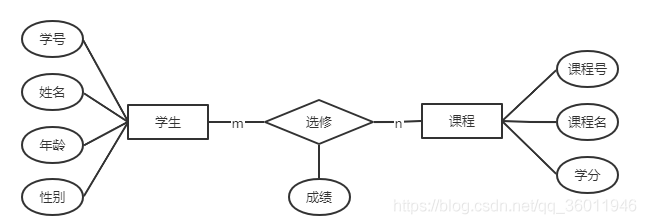
其中,(學號,姓名,年齡,性別)為學生的屬性,(成績)為選修關系的屬性,(課程號,課程名,學分)為課程的屬性,學生和課程之間的關系是多對多,即一個學生可以選擇多門課程,一門課程可以被多個學生選修,
關系表設計
從上面的E-R圖,我們一眼就能看出他們之間的聯系,那該如何設計關系模式呢?
我們要知道,關系資料庫設計的目的是為了生成一組關系模式,使我們能夠既不必存盤不必要的冗余資訊,又能方便地獲取資訊,為了是我們方便的達到這個目的,范式設計應運而生,
Boyce-Codd范式
我們所知道的令人滿意的范式之一是Boyce-Codd范式(BCNF),如果對F+中所有形如 α→β 的函式依賴,其中 α?R 且 β?R,下面的定義至少有一個成立:
- α→β 是平凡函式依賴(即 β ? α),(一般來說,平凡函式依賴并沒有討論意義,討論的都是非平凡函式依賴,即 β ?? α 的情況)
- α 是模式R的超碼,
考慮如下關系模式及其相應的函式依賴:
- 學生 = (學號,姓名,年齡,性別)
學號 → 姓名 年齡 性別
- 課程 = (課程號,課程名,學分)
課程號 → 課程名 學分
- 選修 = (學號,課程號,成績)
學號 課程號 → 成績
以上模式均屬于BCNF,就拿第一組關系模式來說,學生上僅有的非平凡函式依賴,箭頭左側是學號,學號是該模式的一個候選碼(候選碼屬于超碼的子集),沒有破壞BCNF的定義,
其實并不是每個BCNF都能保持函式依賴的,例如:
Banker-schema = (branch-name,customer-name,banker-name)
它表示的是一個客戶在某一分支機構有一個銀行賬戶負責人,它要求滿足的函式依賴集F為
- banker-name → branch-name
- branch-name customer-name → banker-name
顯然,Banker-schema不屬于BCNF,因為 banker-name 不是超碼,
我們可以將它分解得到如下的BCNF:
Banker-branch-schema = (banker-name,branch-name)
Customer-banker-schema = (customer-name,banker-name)
分解后的模式只保持了banker-name → branch-name,而branch-name customer-name → banker-name的依賴沒有保持,
第三范式
當我們不能同時滿足以下三個設計目標:
- BCNF,
- 無損連接,
- 保持函式依賴,
我們可以放棄BCNF而接受相對較弱的第三范式(3NF),因為3NF總能找到無損連接并保持依賴的分解,
具有函式依賴即F的關系模式R屬于3NF,只要F+中所有形如 α→β 的函式依賴,其中 α?R 且 β?R,下面的定義至少有一個成立:
- α→β 是平凡函式依賴(即 β ? α),
- α 是模式R的超碼,
- β - α 中的每個屬性 A 都包含在R的候選碼中,
回到Banker-schema的例子中,我們已經看到了沒能將該關系模式轉化成BCNF而又保持依賴和無損連接的分解,但改模式屬于3NF,在Banker-schema中,候選碼是{branch-name,customer-name},所以Banker-schema上不包含候選碼的就只有banker-name,
而形如 α → banker-name 的非平凡函式依賴都是以{branch-name,customer-name}作為 α 的一部分,由于{branch-name,customer-name}是候選碼,所以符合3NF的定義,
每個BCNF都屬于3NF,因為BCNF的約束比3NF更嚴格,
存盤引擎的選擇
關系模式一但確定,基本的資料庫表結構就確定了,接下來就是表結構的詳細設計了,這里先從存盤引擎開始,MySQL提供的各種存盤引擎都是根據不同的用例設計的,
下表概述了MySQL提供的一些存盤引擎,
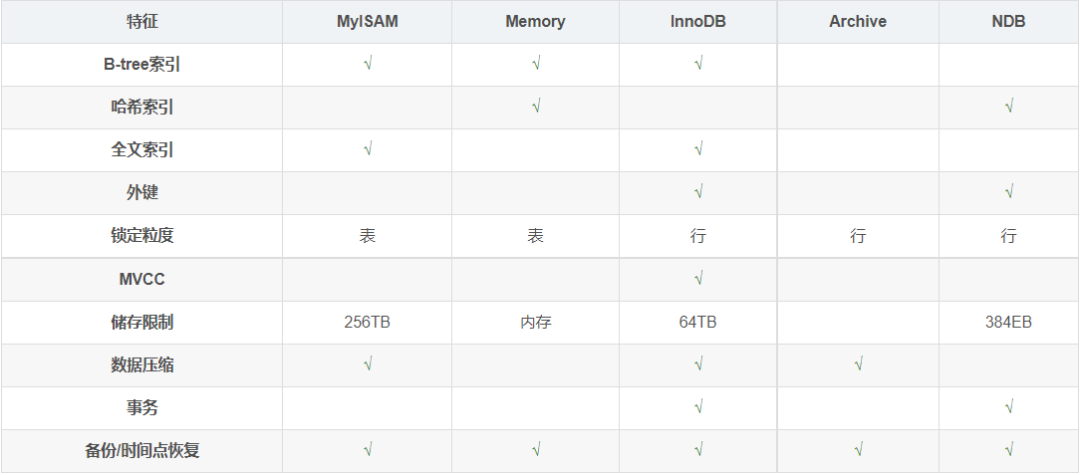
最常用的兩種存盤引擎:MyISAM和InnoDB,
- MyISAM:MySQL 5.5.5以前,MyISAM作為MySQL的默認存盤引擎,
- InnoDB:MySQL 5.5.5以后,InnoDB作為MySQL的默認存盤引擎,
另外,關注公眾號Java技術堆疊,在后臺回復:面試,可以獲取我整理的 MySQL 系列面試題和答案,非常齊全,
何如選擇?
選擇標準: 根據應用特點選擇合適的存盤引擎,對于復雜的應用系統可以根據實際情況選擇多種存盤引擎進行組合,但是要知道組合使用的缺點:
- InnoDB和非InnoDB存盤引擎的組合對比,僅使用InnoDB存盤引擎可以簡化備份和恢復操作,MySQL Enterprise Backup對使用InnoDB存盤引擎的所有表進行熱備份,對于使用MyISAM或其他非InnoDB存盤引擎的表,它會執行“熱”備份,資料庫會繼續運行,但這些表在備份時不能修改,
下面是常用存盤引擎的適用環境:
- InnoDB:事務型業務場景首選,
- MyISAM:非事務型的大多數業務場景,
- Memory:資料保存到記憶體中,能提供極速的訪問速度,(個人覺得可以使用Redis等NoSQL資料庫代替)
字符集選擇
存盤引擎之后就是確定字符集,字符集的選擇十分重要,不管是MySQL還是Oracle,如果在資料庫創建階段沒有正確選擇字符集,那么在后期需要更換字符集的時候將要付出高昂的代價,
如何選擇?
建議在能夠完全滿足應用當下和未來幾年發展的前提下,盡量使用小的字符集,應為更小的字符集意味著能夠節省空間、減少網路傳輸位元組數,同時由于存盤空間小間接的提升了系統的性能,
不同的資料庫有不同的字符集應用級別,分別為服務器級別、庫級別、表級別、欄位級別,通常推薦使用庫級別或者表級別,因為庫級別或者表級別在保有靈活性的同時,兼顧資料間字符集的統一,這可以給開發省去很多處理字符集的麻煩,
資料型別的選擇
選擇原則
前提:使用合適的存盤引擎,
選擇原則:為了獲得最佳的存盤,您應該在所有情況下嘗試使用最精確的型別,
固定長度和可變長度
char 與 varchar
下面這個例子說明二者的區別:
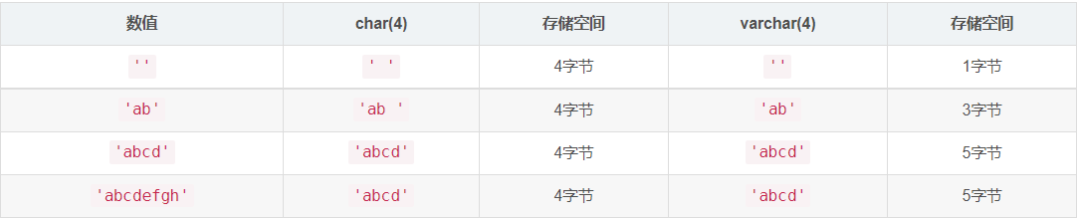
請注意上表中最后一行的值只適用不使用嚴格模式時;如果 MySQL 運行在嚴格模式,超過列 長度的值不保存,并且會出現錯誤,
從 CHAR(4)和 VARCHAR(4)列檢索的值并不總是相同,因為檢索時從 CHAR 列洗掉了尾部的空 格,通過下面的例子說明該差別:
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO vc VALUES ('ab ', 'ab ');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;
+---------------------+---------------------+
| CONCAT('(', v, ')') | CONCAT('(', c, ')') |
+---------------------+---------------------+
| (ab ) | (ab) |
+---------------------+---------------------+
1 row in set (0.06 sec)
對于InnoDB資料表,內部的行格式沒有區分固定長度和可變長度列,所有資料化行都使用指向資料列值的頭指標,因此在本質上,使用固定長度的CHAR列不一定比使用可變長度的VARCHAR列要好,
因為,主要的性能因數是資料行使用的存盤總量,對于占用空間來說,CHAR總是大于等于VARCHAR,所以,使用VARCHAR來最小化行資料的存盤總量,進而減少磁盤I/O頻率,
text 和 blob
在使用text或者blob型別的欄位是需要注意一下幾點,以便獲得更好的性能:
- 執行大量的洗掉和更新操作后,會留下很”空洞“,需要定期optimize table進行碎片整理;
- 避免查詢大型的text和blob,查詢大型的text和blob會使一頁能裝下的資料量減少,增加磁盤I/O壓力,
- 把text和blob分離到單獨的表中,這會把原來表中的資料列轉變為更短的固定長度的資料行格式,這個十分有用,
浮點數和定點數
在MySQL中float、double是浮點數,decimal是定點數,
浮點數優勢:在長度一定的情況下,浮點數能表示更大的資料范圍,
浮點數缺點:精度問題,
友情提醒:在有關金錢交易方面浮點數慎用!!!
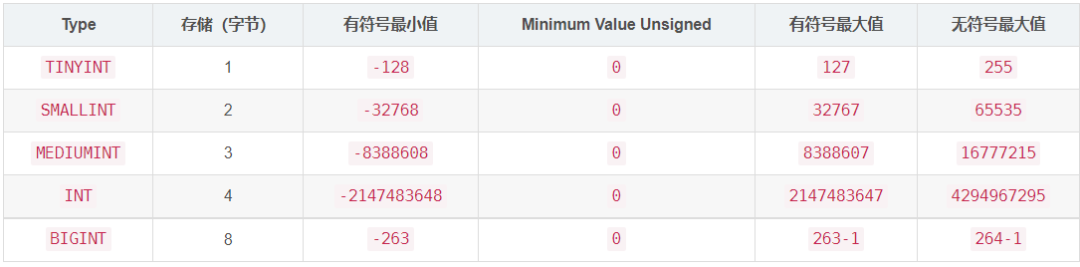
整數
MySQL支持SQL標準整數型別INTEGER(或INT)和SMALLINT,作為標準的擴展,MySQL還支持整數型別TINYINT、MEDIUMINT和BIGINT,下表顯示了每個整數型別所需的存盤空間和范圍,
索引設計
設計原則
- 搜索的索引列,不一定是所要選擇的列,最適合索引的列是出現在 WHERE 子 句中的列,或連接子句中指定的列,而不是出現在 SELECT 關鍵字后的選擇串列中的列,
- 使用惟一索引,對于惟一值的列,索引的效果最好,而具有多個 重復值的列,其索引效果最差,
- 使用短索引,如果對字串列進行索引,應該指定一個前綴長度 ,例如,如果有一個 CHAR(200) 列,如果在前 10 個或 20 個字符內,多數值是惟一的, 那么就不要對整個列進行索引,
- 利用最左前綴,每個額外的索 引都要占用額外的磁盤空間,并降低寫操作的性能,
- 不要過度索引,
- 考慮在列上進行的比較型別,如果是在列上做函式運算,對其進行索引將毫無意義,
示例
針對上面提到的學生選課E-R圖,給出設計結果和說明:
表1-1 學生資訊表(Student)
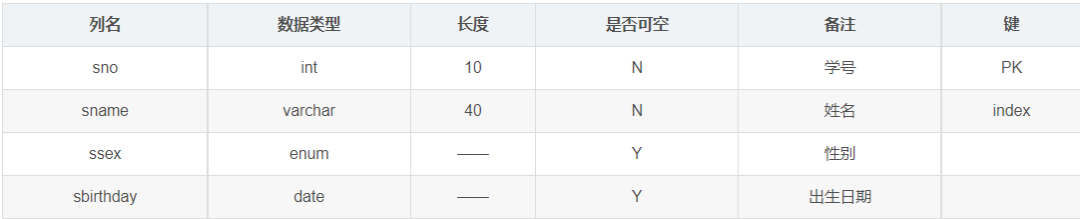
表1-2 課程資訊表(Course)

表1-3 選課成績表(SC)

- Student中姓名的長度是40,這里把外國人也考慮進來了;
- Student中性別定義成列舉,主要是列舉意義簡明;
- Student中沒有存年齡,而存盤的出生日期,是因為年齡并不是一成不變的,并且能夠通過出生日期正確計算,
- SC中成績使用的是double而不采用decimal,主要是因為成績并不需要那么高的精確度,
- SC中(sno,cno)作為聯合主鍵而不是獨立主鍵,由于現階段markdown無法合拼行,所以無法編輯,
參考
- (美)Abraham Silberschatz等.資料庫系統概念.北京:機械工業出版社,2012
- MySQL 5.7 Reference Manual
- [eimhe.com]網易技術部的MySQL中文資料.
原文鏈接:https://blog.csdn.net/qq_36011946/article/details/105305063
著作權宣告:本文為CSDN博主「pikaxiao」的原創文章,遵循CC 4.0 BY-SA著作權協議,轉載請附上原文出處鏈接及本宣告,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.別在再滿屏的 if/ else 了,試試策略模式,真香!!
3.臥槽!Java 中的 xx ≠ null 是什么新語法?
4.Spring Boot 2.5 重磅發布,黑暗模式太炸了!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/297702.html
標籤:Java
上一篇:系統呼叫跟蹤——分析(一)